边界回归的谓语中心词识别
2023-11-27陈艳平唐瑞雪黄瑞章秦永彬
郭 晓,陈艳平,唐瑞雪,3,黄瑞章,秦永彬
1.贵州大学 公共大数据国家重点实验室,贵阳550025
2.贵州大学 计算机科学与技术学院,贵阳550025
3.贵州财经大学 信息学院,贵阳550025
谓语中心词是中文句子中核心的语法单元,句子中的语法单位(如主语、宾语、状语和补语等)都通过谓语中心词进行关联。因此,识别谓语中心词可以有效解析句子的语法结构,清晰地理解句子的语义,快速捕获句子的有效信息,为提炼句子的主要内容提供有效支撑。然而中文句子中通常存在多个动词,由于中文词语没有形态特征,为谓语中心词的识别带来挑战。例如在“货物通过快递站运输至乌鲁木齐”句子中“通过”和“运输”都是动词。但是“通过快递站”用来表示运输的方式,其中“通过”是非谓语动词,而“运输”才是句子的谓语中心词。因此识别谓语中心词,有助于划分句子结构,理解语法成分和语义信息表达,从而支撑知识图谱构建、摘要生成、机器翻译等自然语言应用。
随着深度学习的发展,目前多采用序列标注模型[1-2]来识别谓语中心词。该方法通过输出一条最大概率路径,对输入序列的每一个字标注一个类型标签的方式进行识别。然而,由于谓语中心词具有复杂的动词结构,例如“持刀行凶的歹徒被捕获归案”,其中“抓捕归案”为具有并列结构的谓语中心词,采用传统的序列标注模型,容易将“抓捕归案”标注为“抓捕”和“归案”两个谓语中心词,导致难以解析句子的语法结构。
最近,基于跨度[3-5]的方法在命名实体识别任务方面取得了不错的效果。跨度是指句子中的字符子串。通过将给定句子序列按跨度进行划分,枚举句中所有的子序列,然后预测每一个序列的类型,可以在识别中有效利用面向跨度的全局语义特征。但是由于中文句子的谓语中心词具有唯一性,正样本只有一个,通过枚举跨度的方式会产生大量的负样本,从而导致严重正负样本不平衡问题。另外,谓语中心词及高度重叠的负例样本之间共享相同的上下文,高度重叠的跨度语义相近,容易产生误报。
针对现有方法在谓语中心词识别中的不足之处,本文基于跨度提出了一种边界回归谓语中心词识别方法。首先,通过BERT(bidirectional encoder representations from transformers)[6]得到句子中每个字的抽象语义表示,并利用BiLSTM(bidirectional long short-term memory)[7]获取句子中的上下文语义依赖特征。其次,利用边界识别方法,定位可能的谓语中心词边界。通过边界组合生成跨度,从而减少负样本数量,缓解谓语中心词识别中的数据不平衡问题和降低计算复杂度。然后,通过跨度回归模块计算跨度边界与谓语中心词的偏移量[8],调整跨度边界位置,提高跨度边界的准确度。最后,在输出端加入约束机制限制跨度数量,确保谓语中心词的唯一性。
本文的主要贡献如下:
(1)识别谓语中心词在句子中可能的边界。通过边界组合生成跨度,从而减少跨度样本中的正负样本不平衡问题。
(2)使用跨度边界回归方法计算跨度与谓语中心词的偏移值,更新跨度在句子中的位置,提高跨度识别中边界的准确性。
本文提出的模型在谓语中心词开发数据上进行验证,在测试集获得了84.41%的F值,有效提升了谓语中心词的识别性能。
1 相关研究
识别谓语中心词是理解句子语义和划分句子结构的关键。谓语中心词在句子中起到组织主语、宾语和状语等元素的作用。由于中文句子谓语中心词结构复杂和一词多义的现象,导致识别谓语中心词变得非常困难。目前关于谓语中心词识别的研究主要可以分为四类:基于规则的方法、基于统计的方法、基于规则与统计学习相结合的方法和基于深度学习的方法。
基于规则的方法中,李国臣等人[9]提出了利用主语和谓语的关系来识别谓语中心词的方法。该方法包括使用谓语中心词候选项的静态语法特征和动态语法特征,通过主语候选项的连接使得句子结构清晰,然后判断句子类型,从而识别谓语中心词。穗志方等人[10]提出了一种汉语句子分析方法,即“骨架依存分析法”。这种方法依靠的是英语例句中的谓语中心词来识别相应的汉语例句中的谓语中心词。此类方法通过分析句子结构和语义规则来识别谓语,只适用于少数结构清晰和语义明确的语句,无法在大规模的数据集上实现谓语中心词的自动识别。
基于统计学习的方法中,张宜浩等人[11]提出了基于支持向量机分类算法的谓词自动识别方法。该方法通过信息增益和同义词词林进行特征构建。汪红林等人[12]通过组合谓语的特征,使用最大熵分类器识别谓语中心词。
基于规则与统计学习相结合的方法中,龚小谨等人[13]提出了一种规则和特征学习相结合的谓语识别方法。该方法通过固定搭配将字组合成一个整体,排除不可能成为谓语的词,然后利用规则筛选出可能的准谓语,再利用特征学习识别出谓语。韩磊等人[14]提出一种词法和句法特征相融合的方法,结合C4.5[15]机器学习和规则进行谓词识别。首先利用句子的词法信息和句法信息进行特征提取,使用规则进行词法特征过滤,最后使用C4.5 进行谓词识别。该方法通过人工构造的规则,很难考虑到所有谓语存在的形式和结构,模型的泛化能力差,不适用于大规模数据的识别。
基于深度学习的方法中,李婷等人[1]使用一种基于神经网络的Attentional-BiLSTM-CRF中文谓语动词识别模型。该模型通过注意力机制聚焦于句子的谓语信息,利用BiLSTM获取上下文信息,最后使用CRF(conditional random field)[16]生成一条序列标注路径,标注出谓语中心词。黄瑞章等人[17]使用一种基于Highway-BiLSTMSoftmax网络的深度学习模型。该模型利用多层BiLSTM获取句子内部依赖,使用Highway[18]网络来缓解梯度消失,最后通过softmax函数进行归一化处理。靳文繁[19]使用多层堆叠的BiLSTM 网络获取句子的抽象语义依赖信息,并且引入Highway网络连接模型中的每个层,然后使用边框回归的深度学习模型和多目标学习框架学习分类置信度和位置偏移量。但是谓语中心词由汉字组成,复杂的词语结构导致了谓语中心词识别不完整的现象。
2 模型
本文提出边界回归的模型主要由三个模块组成,如图1所示。从左到右分别为编码模块、边界识别模块和跨度回归模块。
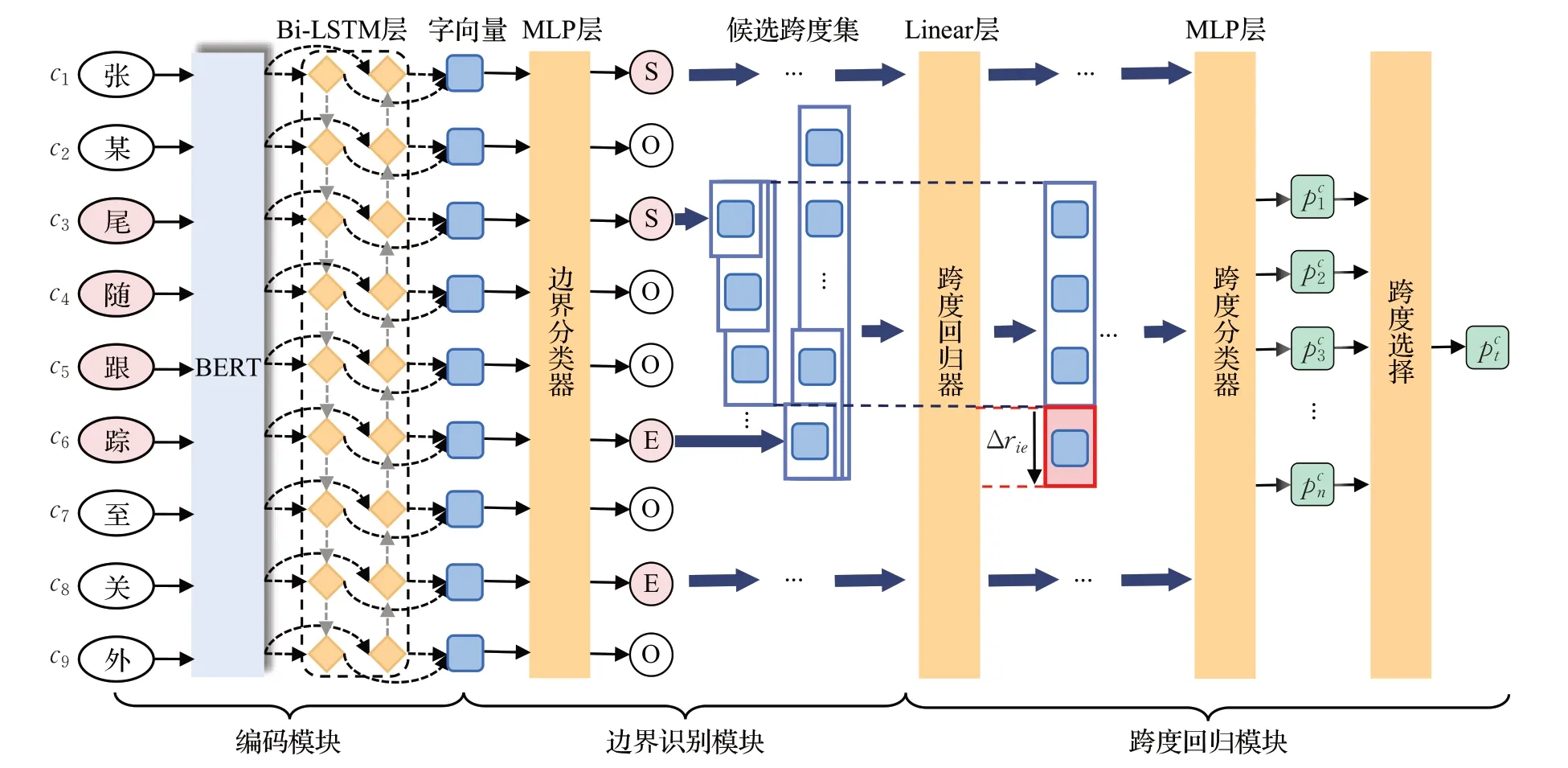
图1 边界回归模型Fig.1 Boundary regression model
首先,使用BERT 预训练语言模型和BiLSTM 作为编码模块,将句子序列生成结合上下文的字符向量表示。使用边界分类器识别出句子中谓语中心词的边界位置,并且生成不同的跨度。然后,通过跨度回归器计算偏移量后更新跨度的边界位置,再将跨度输入跨度分类器进行识别。最后,通过约束策略,输出唯一的跨度。各模块分别详细介绍如下。
2.1 编码模块
假设输入模型的句子为S={c1,c2,…,cn},其中ci表示句子中的第i个字,n是句子S的长度。通过BERT模型提取句子S中深层的语义特征信息,并且输出融合全文语义的连续稠密向量Z={z1,z2,…,zn}。然后,将Z输入BiLSTM来捕获句子中的双向语义依赖,生成句子的向量表示H={h1,h2,…,hn},其中hi∈Rd是字的向量表示,d表示字向量的维度。每个字向量的表示都融合了句子中的上下文特征和语义依赖。该过程的形式化表示如下:
2.2 边界识别模块
如果直接枚举所有的跨度进行跨度分类,会导致严重的数据不平衡和高计算复杂度的问题。因此,设计了谓语中心词边界分类器,通过识别出谓语中心词的边界,并将边界进行组合生成跨度,从而减少负样本的数量。
首先,使用边界分类器,将句子中的每个字ci相应的向量表示hi输入边界分类器来预测成为边界的概率,计算公式如下:
式中,MLP(multi-layer perceptron)[20]是由两层Linear层和GELU[21]激活函数构成。
其次,将识别出的边界进行组合,生成候选的谓语中心词。假设边界分类器预测出字符csi(1 ≤si≤n)为谓语中心词的开始边界,则需要以该字符的位置si作为跨度的开始边界。然后,通过组合不同的结束边界ei∈[si+1,si+2,…,si+m]生成跨度di=(si,ei)(1 ≤si≤ei≤n),其中di表示第i个连续的字符序列{csi,csi+1,…,cei},m为预先定义的最大跨度长度。若边界分类器预测的字符cej(1 ≤ej≤n)为谓语中心词的结束边界,则需要通过组合开始边界sj∈[ej-1,ej-2,…,ej-m]生成跨度dj=(sj,ej)(1 ≤sj≤ej≤n)。最后,将所有生成的跨度合并为候选跨度集D={d1,d2,…,dk},其中k是跨度的数量。
2.3 跨度回归模块
通过边界识别生成的跨度减少了负样本的数量,同时提高了跨度的质量。然而,很多跨度互相之间高度重叠,共享相同的上下文,导致识别出的谓语中心词存在边界不匹配的问题。因此,设计了跨度回归器,通过捕获跨度外部语义来更新跨度的位置,有效提升跨度的准确率。为了计算更新跨度的偏移量,对于每个跨度di∈D,将最大池化的跨度表示和跨度边界外部的向量表示拼接起来,获得跨度的向量表示。然后输入跨度回归器来计算跨度边界相对于真实谓语中心词的偏移量Δri,更新识别跨度在句子中的位置。其中,边界偏移量的计算公式如下:
式中,MaxPooling[22]是最大池化操作,[;]表示拼接操作,Δri由跨度开始边界的偏移量和跨度结束边界的偏移量组成,W∈R3d×2,b∈R2,是可学习参数。
利用计算出的偏移值来更新跨度的开始边界和结束边界。计算如下:
式中,MaxPooling 是最大池化操作,[;]表示拼接操作,MLP由两层Linear和GELU激活函数组成。
为了避免句子中谓语中心词的跨度数量大于1 的现象,本文在边界分类器后,通过添加约束条件,筛选预测概率值最高的跨度为谓语中心词的位置。计算公式如下:
式中,为预测概率最高值。
2.4 损失函数
本文采用多目标框架,同时识别跨度的类别和偏移量。总损失函数结合了边界识别、跨度回归和跨度分类的损失。对于边界识别采用的损失函数为二分类交叉熵损失,损失函数定义如下:
式中,为真实值,为预测的概率。
跨度回归的损失函数采用SmoothL1[23]函数,损失函数定义如下:
对于跨度分类损失采用Focal Loss[24]函数解决正负样本比例失衡的问题。损失函数定义如下:
式中,wi为计算第i个跨度的权重,γ为Focal Loss 的调焦参数为跨度真实类别,为预测的概率。
最后,对边界分类、跨度回归和跨度分类的总损失计算如下:
式中,β(·)∈[0,1],是上述三个任务的超参数集。在训练期间调整三个子任务的相对重要性。
3 实验
3.1 数据集
实验所使用的数据集来自于“中国裁判文书网”中的762 篇法院刑事判决书。在中文谓语中心词识别领域还缺少公共的数据集支持,因此使用此数据集作为本文的训练和评测模型的数据集。此数据集由法院刑事判决书的案情部分组成,且标注规范与Chen 等人[25]的标注规范相同。此数据集共标注了7 022 条句子,其中谓语中心词有7 022个。谓语中心词可以划分为如下几种类别。
(1)单谓语中心词:谓语中心词由一个及物动词或非及物动词组成,没有修饰语和补语。此类的谓语中心词,以词典收率为准。此数据集中单谓语动词有4 353个。
(2)复合结构的谓语中心词:谓语中心词具有重复结构且至少包含一个重复出现的动词,例如“跌跌撞撞”“比划比划”等。此数据集中复合结构的谓语中心词有24个。
(3)同义并列的谓语中心词:谓语中心词由表达相关语义的关联动词组成,或者由相同词义类型的动词组成,例如“抓捕/归案”“驱车/行驶”等。此数据集中同义并列的谓语中心词有272个。
(4)带修饰或带补语的谓语中心词:谓语中心词带有修饰符、补语和事态标记的动词,例如“(取)出“”(扭)开”等。此数据集中带有修饰符的谓语中心词有1 651个。
(5)其他特殊表达的谓语中心词:谓语中心词由其他名词或者形容词作动词以及谚语、习语、成语和典故等充当句子的谓语中心词,例如“心生不满”“过河拆桥”等。此数据集中其他特殊表达的谓语中心词有116个。
此数据集合以6∶2∶2的比例划分为训练集、验证集和测试集。
3.2 评价指标
实验使用的评价指标包含准确率P、召回率R和测度值F,以此来评价该模型识别谓语中心词的效果,评价指标具体公式如下:
式中,TP为实际为正例且预测为正例的数量,FP为实际为负例但预测为正例的数量,FN 为实际为正例但预测为负例的数量。
3.3 实验参数设置
本文的边界回归模型在Python3.8 和Pytorch1.7.1的环境下进行实验。使用BERT和BiLSTM将句子序列生成结合上下文的字符向量表示。边界分类器由两个Linear 层和一个GELU 激活函数构成,跨度回归器是一个Linear层,跨度分类器也同样由两个Linear层和一个GELU 激活函数构成。实验采用Adam[26]优化器。参数设置如表1所示。

表1 参数设置Table 1 Parameter setting
3.4 对比实验
3.4.1 与其他模型的对比实验
为了验证模型的有效性,本文模型与其他四种模型在谓语中心词的数据集上进行了对比实验。所使用的其他四种模型分别为BiLSTM+CRF[27]模型、BiLSTM+Attention+CRF[1]模型、Highway+BiLSTM[17]模型、BERT+BiLSTM+CRF[28]模型。对比实验结果如表2所示。

表2 不同模型实验结果对比Table 2 Comparison of experimental results of different models
BiLSTM+CRF[27]为目前最常用的序列标注模型。此模型可以捕获句子双向的语义信息,可以计算整个标记序列的联合概率分布,并选取全局最优输出节点的条件概率。该模型的缺点是难以捕获句子深层语义,只能学习句子中近距离的语义特征。对于长序列,依然无法很好地传输序列的远点信息。因此,该模型很难准确地识别出谓语中心词语的位置,导致性能偏低。
由李婷等人[1]提出的BiLSTM+Attention+CRF 模型在BiLSTM+CRF模型上添加了注意力机制。注意力机制弥补了BiLSTM对于远点信息捕捉的缺失,自注意力机制没有依赖字与字之间的顺序,而是通过计算字与字之间的权重,从而捕获全局与局部的关联。此模型性能相比上一个模型有所提升。
由黄瑞章等人[17]提出的Highway+BiLSTM 网络在训练阶段使用了预训练的汉语维基百科向量字嵌入初始化。利用Highway 有效缓解了随着模型深度加深而导致梯度消失的问题。使用多层BiLSTM 构成识别谓语中心词的模型,Softmax输出预测概率。相比上述两个模型,该模型利用多层BiLSTM堆叠而成,使用Highway来解决梯度消失问题,并且有效地提升了谓语中心词识别的准确度。
谢腾等人[28]使用BERT+BiLSTM+CRF 模型进行中文实体识别。本文将此模型进行了谓语中心词识别,使用BERT-large预训练模型代替了word2vec[29]方式,对输入句子进行向量表示。BERT模型已经是在大规模语料基础上训练好的参数,在训练时只需要在此基础上更新参数,可以更好地捕获词语和句子的表示。使用BiLSTM来获取上下文的语义依赖,最后使用CRF输出预测的标签序列。
本文使用的边界回归模型,F值达到了84.41%,相比BERT+BiLSTM+CRF模型的F值提高1.7%,表明了本文方法的有效性。本文模型选用BERT和BiLSTM作为编码模块,可以更好地捕捉语句和词语的关系,并且能够获取双向语义依赖。使用边界分类器识别边界,然后以边界生成跨度,可以使得跨度与谓语中心词高度重叠,并且避免了枚举跨度产生的大量负例而造成的分类干扰。其次,依靠边界生成的跨度,可能与谓语中心词存在偏差,通过跨度回归器,动态调整跨度的边界可以有效地提高跨度的准确率。该模型通过结合边界识别和回归的优势,将谓语中心词的识别通过先确定所在句中位置,再动态调整跨度的方法,可以有效地识别出谓语中心词。
3.4.2 边界分类的影响
为了验证边界分类的准确性对识别谓语中心词性能的影响。本文选用识别开始边界方法、识别结束边界方法以及同时识别开始和结束边界方法进行了对比实验。在测试集上的实验结果如图2所示。
识别开始边界方法只单独识别谓语的开始边界字的位置,然后作为跨度的开始位置生成候选跨度集。识别结束边界方法则是只识别结束边界字的位置并生成候选跨度集,而开始和结束边界同时识别则是将两者同时生成跨度组成候选跨度集。开始和结束边界同时识别的方法相比只识别开始边界方法在测试集的实验结果的F值提高了0.66 个百分点,并且与只识别结束边界方法在测试集的F值提高了0.3 个百分点。该实验验证了对不同边界分类的准确性会提高生成跨度的质量,从而提高识别谓语中心词的性能。
3.4.3 跨度生成策略的影响
为了验证跨度生成方式对识别谓语中心词性能的影响,本文选用三种方式进行对比实验。其中一种为枚举跨度方法。另外两种是通过识别的边界筛选跨度方法:边界过滤跨度方法和边界生成跨度方法。
边界过滤跨度方法采用的是枚举所有的跨度。以识别出的边界字为中心,将跨度开始边界位置大于等于边界且结束边界位置小于等于边界的跨度组成候选跨度集。边界生成跨度方法是以识别为开始边界字的位置作为跨度的开始边界,从预设的长度集合中选取不同位置的结束边界组成跨度。然后以识别为结束边界字的位置作为跨度的结束边界,以同样的集合,选取不同的开始边界组成跨度,再将两者生成的跨度去重,生成候选跨度集。在测试集上的实验结果如表3所示。
经统计枚举跨度的数量是边界生成跨度数量的13倍,并且通过添加边界识别模块筛选的跨度可以有效防止非谓语动词的干扰。边界生成的跨度相比枚举的跨度在测试集上的实验结果F值提高了0.30个百分点,验证了边界识别模块的有效性。后两种方法是依据边界筛选跨度的不同策略。虽然两种方法都减少了跨度的数量,但边界过滤方法的跨度数量仍然是边界生成跨度数量的两倍,并且边界过滤跨度方法筛选出的跨度与真实谓语中心词的重叠率较低。因此通过识别边界筛选候选跨度集的方法,选用跨度生成方式更为合适。边界过滤跨度与边界生成跨度方法相比,边界生成跨度方法在测试集的实验结果的F值提高了0.10 个百分点,证明了边界生成跨度方法比边界过滤跨度方式更加有效。
3.4.4 消融实验
为了验证边界回归模型的有效性,本文设计了消融实验,“-边界识别”表示去掉边界识别模块,“-跨度回归”表示去掉跨度回归模块。在测试集上的实验结果如图3所示。
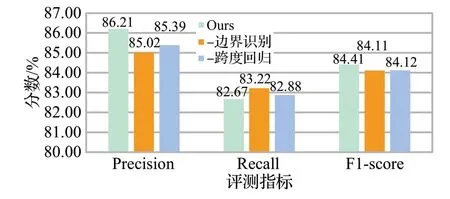
图3 消融实验Fig.3 Ablation experiment
模型去掉边界识别模块后,从图3可以看出会导致模型F值下降0.30个百分点。边界识别模块在模型中用于生成跨度,确定谓语中心词位置。去掉边界识别模块,会枚举所有的跨度,无法避免非谓语动词的干扰并且生成大量的负样本,导致正负样本不平衡。
模型去掉跨度回归模块后,从图3可以看出模型F值下降0.29 个百分点。跨度回归模块在模型中用于捕获更多的语义信息,提高跨度准确性。去掉跨度回归模块后无法捕获其他语义动态调整跨度的边界,降低了跨度的准确性。因此边界识别模块和跨度回归模块在本文的模型中必不可少。
3.4.5 运行时间分析
本文模型通过边界识别模块可以降低计算量,减少运行时间。因此在测试集上进行运行时间的测量,实验结果如表4所示,其中“-边界识别”表示去掉边界识别模块。

表4 运行时间的实验结果Table 4 Experimental results of running time
经实验表明,去掉边界识别模块的模型与包含边界识别模块的模型在同一块20 GB 的P40GPU 上使用测试集进行测试,去掉边界识别模块要比包含边界识别模块的运行时间长80 s,并且包含边界识别模块的模型F值提高了0.30 个百分点。其原因是边界识别模块会减少大量的负样本,提高跨度的重叠率。
4 结束语
本文提出了一种边界回归的方法应用于谓语中心词识别的任务。利用边界识别生成跨度可以解决正负样本不平衡问题并且降低计算量。结合回归方法通过捕获跨度外部语义调整跨度的边界位置,可以提高跨度的准确性。该模型在裁判文书生成的数据集上取得了较好的实验效果,证明了该模型识别谓语中心词的有效性。此外,通过识别谓语中心词可以抽取裁判文书的关键案情信息,以便后续的案件分析,从而能有效支撑罪名预测、法条推荐、辅助量刑等智能化辅助审判工作。该模型对边界分类的准确性有待提升,边界识别不准确将导致产生的跨度与谓语中心词的偏离较大,进一步提高识别边界的准确率是下一步的重点研究工作。
