面向食品贮藏领域的知识图谱构建方法研究
2023-11-27谢镇玺李朋骏王金龙熊晓芸
辛 辉,谢镇玺,李朋骏,王金龙,熊晓芸
青岛理工大学 信息与控制工程学院,山东 青岛266525
民以食为天,食品不仅是人类赖以生存的必需品,而且也是社会发展的物质基础。伴随着国家综合实力的不断飞跃,人们对食品的追求从满足温饱变为优质健康[1],那么食品贮藏必然是追求高质量饮食不可缺少的关键环节。科学贮藏的意义在于保持食物的品质,减少浪费,真正将建设资源节约型社会落到实处[2],是我国致力于建设资源节约型社会这一国家发展决策的重要着力点。同时人们如何居家贮粮,食品产业如何调配贮藏环节,餐饮企业如何维护食品贮藏都是亟待解决的问题。合理的贮藏条件与方式能够保证食品营养品质、饮食健康以及能源损耗,而现如今处于信息指数爆炸的时代,相关知识分散杂乱,质量参差不齐,而且食品贮藏是具备专业性的特定领域,人们有效便捷地获取想要的知识信息是比较困难的。
面对纸质技术书籍、电子学术期刊文献、网络资源信息以及企业实验数据库信息等海量多源异质数据存在信息过载[3]、数据冗余、查询困难等问题,知识图谱技术便为整合高质量贮藏知识、理解海量食品数据提供了应用前景和实际意义。知识图谱具备良好的可读性、扩展性和解释性[4],针对多而杂的数据完成结构化系统化表示,得到<实体,关系,实体>三元组,从而构建语义网,为数据分析、智能检索、决策选择等提供支持。知识图谱在医疗、金融、工业等领域的应用取得了可观的成果[5],然而当前食品领域知识图谱研究相对匮乏。在国外,Damion 等人[6]于2018 年提出了FoodOn 本体概念,为营养、食品安全等相关知识提供了一套标准化语义表示。Steven 等人[7]于2019 年提出了相对全面的食品饮食方向图谱构建方法FoodKG,以及后续在此基础上的健康、个性化推荐等研究[8]。在国内,目前相关研究也处在起步阶段,而针对食品贮藏相关信息智能化以及图谱构建鲜有关注。本文依据蕴含的研究价值和信息特点提出了一整套食品贮藏知识图谱(food storage knowledge graph,FSKG)构建框架,极大地利用与组织多源异质信息,依托于本文设计的超节点概念模式,采取深度学习等技术完成抽取,结构化表达出大数据中食品贮藏知识,为普通居民、相关从业者和研究人员提供知识库保障[9],并为该领域后续研究提供参考。本文的主要贡献如下:
(1)对多源异构的食品贮藏数据进行分析,构建领域本体并提出了超节点概念表示模式,从领域知识视角出发以弥补图谱三元组知识表示的缺陷。
(2)设计了改进的融合多特征的命名实体识别模型,结合食品贮藏语义和文字信息进行特征编码,以提高领域知识的识别性能。
(3)基于超节点的表达模式,提出了多元关系抽取算法与多分类模型相结合来完成关系抽取,然后采取基于词典和相似度匹配的方法完成数据融合。
(4)构建了食品贮藏数据集和食品别名词典,并通过实验验证所提出的FSKG框架的可行性和有效性。
1 相关工作
知识图谱作为一种由概念、关系和实例构成的知识表示模型,既能满足人类理解的知识组织结构,又有利于计算机模拟和处理知识。自2012年谷歌公司正式提出知识图谱的现代化定义以来[10],在通用领域中已有如YAGO[11]、Freebase[12]、CN-DBpedia[13]、OpenKG平台(openkg.cn)等具有代表性的大型知识图谱。通用领域知识图谱往往涵盖现实世界的大量常识内容,涉及知识跨度广泛,但面对特定领域场景,从知识深度和专业性上通用知识图谱则表现得相对乏力。作为通用知识图谱的衍生,领域知识图谱弥补了上述缺点,同时具有知识质量高、知识粒度细等特点,且更加专注于领域数据特征和应用需求[14]。
对于知识图谱的构建流程可以分为自顶向下(topdown)和自底向上(bottom-up)两种[15]。其中自顶向下是从本体构建的角度出发完成模式层设计,然后利用本体的模式信息完成知识抽取,依据规范分明的概念框架完成图谱构建,这种方式适用于专业性高、知识范围明确的领域知识图谱构建;而自底向上的方式则以底层数据信息为起点,无监督聚类抽取知识,归纳整合得到本体,缺乏显性类型约束,更适用于数据量大、知识范围较广的通用知识图谱[10]。
由于食品贮藏的知识专业性和领域特征,本文采取自顶向下的方式来完成知识图谱构建。从技术视角来看,领域知识图谱构建包括采取本体构建方法完成上层本体的逻辑抽象,以及利用自然语言处理(natural language processing,NLP)技术完成知识抽取、知识融合等特定任务,遵循本体规范,从多源异构数据中获取领域知识,并根据语义对不同数据源的信息进行融合,最终存储形成知识图谱。知识抽取包括实体识别和关系抽取等方面,通常采用基于规则和基于机器学习的方法实现。基于规则的方法常常需要针对特定领域匹配规则,对实体和关系进行设定。虽然存在可移植性较差、泛化能力不高的问题,但在特定领域中具备较高的准确性,并对于抽取表述规范、概念间关联性较强的数据信息表现出一定的优势。李峰等人[9]在构建遥感应用领域知识图谱时,针对同一论文摘要文本中的实体关系按照共现频次完成规则抽取。钱智勇等人[16]采取规则的方式建立正则表达式,完成对注疏语句和例证句子中实体的抽取,最后完成古代辞书知识图谱的构建。而对于基于机器学习的方法常常使用隐马尔可夫模型(hidden Markov model,HMM)、条件随机场(conditional random field,CRF)等方法来处理实体识别问题。随着神经网络的强势发展,长短期记忆网络(long short-term memory,LSTM)、门控循环单元(gated recurrent unit,GRU)模型等方法进一步提高了实体识别的性能。近年来以BERT(bidirectional encoder representation from transformers)为代表的预训练模型结合了迁移学习的思想,以丰富的语义表征信息使识别效果达到了新的高度。对于关系抽取,机器学习方法通常将其作为二分类或多分类问题进行处理,将语句的特征向量作为输入,以卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)、长短期记忆网络等模型来完成关系类别预测,研究人员对特征嵌入、模型改进等方面进行创新,进一步提升了抽取效果。王春雨等人[10]在研究船舶舾装设计经验知识图谱的构建方法时,采取基于优化的多层神经网络完成实体识别,接着应用基于嵌入的BERT分类模型完成关系抽取。袁琦等人[17]在构建宠物知识图谱时,针对非结构化数据采取CRF与症状词典相结合的方法完成实体抽取。徐春等人[18]借助改进的BERT预训练模型与指针网络相融合,对实体和关系进行联合抽取来实现对旅游知识图谱的构建。聂同攀等人[15]构建故障诊断领域知识图谱,采取双向LSTM 从非结构化文本中抽取实体,然后在双向LSTM中引入注意力机制来获取实体间的关系信息。
在构建知识图谱的过程中,由于异构数据多源,表述方式多样,通过知识融合完成对抽取数据的整合,解决实体、关系等产生的冗余,旨在提高图谱质量。知识融合主要集中在实体对齐任务上,即解决不同名称表达相同实体的问题。Zhou 等人[19]在构建移动应用知识图谱过程中,采取规则挖掘与知识图谱嵌入的方法完成各应用市场之间应用程序相关的实体对齐任务。周炫余等人[20]提出一种基于层次过滤的知识融合模型,实现百科及教程文本的实体对齐。李峰等人[9]将不同语料抽取产生的实体集合采取字符串相似度计算的方法判断实体间的相似性,并将相似度超过阈值且名称较长的名称作为统一实体。杨波等人[21]采取融合CNN和余弦相似度的实体链接模型完成企业实体融合。一般情况下,在完成实体对齐任务后,包含对应实体的三元组会完成替换,进而去掉重复的三元组。但面对本文研究的食品贮藏领域中无法由简单三元组表征的复杂关系,抽取时会产生一定的冗余,故按照其数据特征对知识融合方法做了进一步改进。
2 食品贮藏知识图谱构建框架
本文将食品贮藏领域与知识图谱技术相结合,提出了一整套食品贮藏知识图谱构建框架,就领域内存在的多种概念间的复杂联系,提出了多元关系的表达模式和知识构建方法,以弥补如今大多数知识图谱仅用<头实体,关系,尾实体>表示而无法表征更多复杂知识的问题,同时也为相关研究和应用提供新的思路。FSKG构建框架如图1 所示,依据对领域内数据资源的分析,完成模式层设计,然后根据知识特征采取改进的方法进行知识抽取,并通过知识融合手段消除数据冗余,最后完成知识存储。下文将对具体环节进行阐述。

图1 食品贮藏知识图谱构建框架Fig.1 Construction framework of food storage knowledge graph
2.1 数据资源分析
据研究发现,现阶段大多数的领域知识图谱研究所关注的抽取知识往往集中在特定的某一类或某几类数据,而对于本领域其他异构信息却不能很好地体现其领域知识图谱的泛化能力。同样,食品贮藏数据也具有专业性强、数据结构多样、概念错综复杂、信息载体多元等特点,而为探索一套完备且泛化性高的知识图谱构建技术,首先需要保证食品贮藏信息源多元且全面。从知识的组织形式上来看,食品贮藏数据包含结构化、半结构化和非结构化数据。其中结构化数据主要包括国家标准委等规范文件、文档书籍中的数据表格,诸如食品冷藏参数表、苹果部分品种贮藏条件表等,还包括食品企业等机构内部私有数据,往往以关系型数据存储在MySQL、Oracle 等数据库中,如食品分类表、食品信息表、贮藏条件表等。上述数据的缺陷在于无法高效地查询检索,不易真实表达业务场景,这也正是构建图谱的需求和优势所在。而半结构化数据包括维基百科、食品相关网站中的html 网页数据,如食品别名、适宜贮藏温度等信息,以及一些MangoDB 等非关系型数据以json数据格式保存。
非结构化数据是构建知识图谱过程中重点和难点所在,因其具备丰富的语义信息和数据价值,本文将分为如下几类数据进行分析构建。
(1)教材及技术类书籍,知识整合规范,专业性和权威性强,作为FSKG知识元的主体内容,比如《食品安全保藏学》《食品贮藏保鲜技术》等。
(2)科普读物,食品类型更加集中于常见品种,表述相对宽泛,涉及温度、湿度等一系列参数,表达粒度相对较粗,可以作为构建图谱的知识补充,例如《常用食品的贮藏与保鲜》《食品保藏的秘密》等。
(3)科研文献,这类数据往往理论性较强,专业术语复杂,为保证抽取知识的高效性,抽取数据以文献的摘要部分为主。食品贮藏类文献往往集中发表在食品以及农业类期刊的贮藏保鲜、包装贮运等栏目中。
(4)网络论坛文章,主题鲜明,篇幅相对较短,有时候表述不太规范,需要后期通过知识融合完成数据规范,又因缺乏权威背书,抽取构建过程中可以作为补充数据。这类数据包括例如食品论坛、海尔冰箱社群、微信公众号文章等。
2.2 数据模式设计
知识图谱从逻辑的角度分为模式层与数据层。模式层是整个知识图谱的核心部分[22],主要完成专业术语上的语义规范,消除不同数据源中同一概念的歧义,对数据层知识抽取完成约束。食品贮藏相关的资源蕴含着重要的信息价值,涉及到食物品种分类、生理病虫害特性、各种工农业技术及参数指标、生产生活中的方法经验等。本文按照斯坦福七步法[23]的设计思路,并参考食品专业研究者以及企业专家等相关领域专家建议,针对食品贮藏领域的内容抽象概括完成本体构建。
在分析设计过程中,食品贮藏数据主要存在以下一些特点:领域数据中大多数以食品为主体进行表述,一般包含相关的温度、湿度、贮藏时间、使用贮藏技术等信息,且往往伴随着对食品品种关系、化学生物特性、病虫害腐败现象的表述;一些文本则会以具体贮藏操作行为进行表述,例如“充分冷却”“加盖密封”等,以及操作方式防止或者缓解“冷害”“腐败”等现象;食品贮藏数据条件往往是在特定场景下存在的,若变换为其他场景则各种条件将会发展变化,例如一些贮藏场景的表述为“广大农村地区常用”“家庭中贮藏”“遮光封闭条件下”“冷库中进行”等。按照上述数据特点和方法将食品贮藏领域知识分成10种实体类型,详细信息如表1所示。

表1 实体类型表Table 1 Entity type
为了完整描述食品贮藏领域的语义网络,需要明确实体与实体之间的关系,本文将其定义为普通关系和多元限定关系两大类。其中普通关系指领域概念之间的常规关系,即以二元一阶谓词逻辑表示,包括食品与食品的“包含”关系、“贮藏条件相似”关系、“不可混合贮藏”关系;食品与贮藏特性以及病虫害败坏现象的“具有特性”关系;保藏方法或者贮藏操作与病虫害败坏现象的“防止/缓解”关系。详细描述如表2所示。

表2 普通关系类型表Table 2 Common relation type
根据对食品贮藏数据的特性分析发现,包括贮藏温度、空气状况、贮藏时间、保藏方法、贮藏操作、场景以及包装在内的7 类实体在文本描述中常常作为相互制约的条件约束表征某一食品的贮藏知识。例如“芒果的气调贮藏法下要保证5%氧气和5%二氧化碳,寿命可达20天。”食品“芒果”在“气调贮藏法”“5%氧气”“5%二氧化碳”的条件限制下贮藏时间为“20天”。由于这些实体并不是食品的特征且实体间存在隐含的限制关系,不能将其作为食品属性的概念来简单处理。同时如果显式地以二元关系表示出来会使整个语义网络复杂且冗余,同时也存在知识表示的缺陷。而本文借鉴Freebase 知识图谱中的复合值类型(compound value types,CVT)[24]提出了超节点的概念来表达多元实体间的限定关系。超节点不代表实际数据,而是作为虚拟节点连接食品实体与其他多个制约条件实体,它既表示父节点食品实体与其叶子节点实体间的条件关系,又表达在父节点已知的条件下各叶子节点两两之间的限制关系,达到食品贮藏领域下特定复杂知识的表征。经上述分析设计得到食品贮藏知识图谱的模式层设计,如图2所示。

图2 食品贮藏知识图谱模式层Fig.2 Schema layer of food storage knowledge graph
2.3 数据预处理
由第2.1节分析可知,对于结构化数据,其原始各字段语义明确,故按照模式层与其具体语义设计相应的字段映射规则[25],保证异构数据在完成知识图谱构建后的完整性和一致性,提取出对应的实体组。比如就苹果部分品种贮藏条件和贮藏期表而言,由品种、温度、相对湿度、贮藏期4 列组成,按照规则映射成为模式层中多元限定关系下的实体组,形成譬如<元帅,0~1 ℃,相对湿度95%,3~5月>,<金冠,0~2 ℃,相对湿度95%,2~4月>等,为后续知识融合与知识存储做准备。对于半结构化数据,本文采取Scrapy 框架爬取维基百科等相关网站,获取食品、别名、贮藏特性相关的半结构化网页数据,将别名字段构建成为食品别名词典为后续知识融合提供数据支撑,而将爬取的其他短文本信息作为待抽取的数据源集合。
相比结构化和半结构化数据,处理非结构化数据抽取是最为复杂,也是自然语言处理的重点研究对象。其中对于包括文本描述,以及包括图、表等结构化数据的纸质书籍,利用光学字符识别技术(optical character recognition,OCR)将纸质数据处理为计算机可以处理的格式[26],本文采取基于深度学习的PaddleOCR开源技术框架完成纸质书籍到文本形式转换,并进行数据清洗工作,如统一格式、转换识别非法字符、清除空格、剔除无效文本、筛选有效可构成语料的文本数据。对于网络数据中知网数据库文献、网络文章和论坛评论同半结构化数据一样进行爬取,并经正则表达式清除无关标签,完成数据清洗后形成语料数据。
2.4 融合多特征的实体抽取
结构化和半结构化数据抽取工作已在数据处理中完成,故本文不再过多赘述。而对于非结构化数据,实体及关系隐藏在自然语言文本中,则需要进行识别抽取,这是实现大规模知识图谱构建过程中的关键工作和技术难点。实体抽取完成自然语言处理中的命名实体识别(named entity recognition,NER)任务,随着自然语言处理技术和硬件算力的发展,目前采用深度学习的NER 技术则是较为广泛和高效的方法[27]。针对食品贮藏领域的数据特点,本文设计了一种融合多特征的命名实体识别模型,分为特征编码层、上下文信息提取层、输出层三层结构,模型采取了迁移学习的思想来获取先验语义信息,同时融合食品贮藏数据的字符特征,确保模型的泛化效果,有效解决了大规模语料标注和抽取效果不明显等限制性问题[28]。模型完成实体抽取的工作原理如图3所示。

图3 实体抽取工作原理图Fig.3 Working principle diagram of entity extraction
首先在特征编码层中引入BERT预训练模型,充分利用上下文的关联语义,学习到丰富的特征表示信息,能够解决不同语境下的词多义性的表征[29]。例如在食品贮藏文本中,“意大利”在不同语境下既有可能表达为食品产地,也有可能是一种葡萄品类。BERT 在预训练中分别融入字符嵌入token、句子嵌入segment以及位置嵌入position 三类特征,经过多重双向Transformer 编码器得到丰富表征的动态词向量,从而理解句子以及词语间的位置和语义关系[30]。同时为了提升食品贮藏文本的识别效果,本文进一步融合了字粒度的部首信息,来增强特征空间中的语义嵌入。相较于英文,汉字中的部首信息能够使字符信息表达更加准确,一般情况下同部首字义相近[31],例如“椒”“柚”“梨”等部首为“木”,属于植物性食品;“粉”“糖”“糕”等部首为“米”,属于碳水类食品;再例如“螟”“螨”“蚜”等部首为“虫”,常常出现在食品病虫害类型实体的表述当中。本文以汉字码表作为部首对照字典,对于输入的文本进行部首特征映射,如将图3 中的输入文本“蘑菇的冷冻保鲜法……”转换为“艹艹白冫冫亻鱼氵……”,接着对映射后的序列采用已学习部首信息的word2vec 模型来获取部首向量,然后通过全连接层提取上下文特征,计算公式如下:
其中,xi为字符的部首表示,feature_dic 为部首对照字典,ci为输入字符,word2vecrad表示经部首特征训练后的词向量模型,ri表示xi的特征嵌入,ei表示最后输出的部首特征向量,dense 表示全连接操作。最后经字粒度的特征提取后将部首特征向量Er与BERT动态词向量Eb进行拼接,作为接下来模型的输入。
第二层上下文信息提取层将融合了多重特征的词向量由BiLSTM神经网络模型继续捕获文本特征,有效解决远距离依赖问题,完成上下文信息提取,进行实体识别,经过解码输出字符在各类实体的预测分数。但由于其作为实体识别概率值是相对独立的,无法学习到输出序列标注的约束条件,需要在第三层输出层中使用CRF概率模型来解决。这是因为经过BiLSTM模块输出可能会出现以I-food预测标签为实体首部的情况,或在B-food 之后紧接着I-method 这样与语法结构相悖的序列。在BIO标注体系下缺少相关约束条件,例如实体开头字符的预测标签须为B-xxx,label_a 类型的I-label_a后面不能出现label_b 类型的I-label_b 预测标签。对此在输出层中使用CRF模型学习前后标签的依赖约束,通过转移分数矫正上一层发射分数的偏差,降低出现无效标签的概率,从而计算得到概率值最大的预测标签。最后得到与输入文本一一对应的最佳预测标注序列,完成对实体的抽取任务。
2.5 关系抽取
在完成实体抽取任务之后,关系抽取则是挖掘海量食品贮藏相关数据知识价值的另一个核心步骤。关系抽取旨在从文本中抽取出二元或者多元实体间的语义关系[32],由于食品贮藏实体间语义的特殊性和复杂性,本文按照模式层设计采取基于规则和深度学习两类方法来完成抽取工作。
2.5.1 基于规则的关系抽取
基于规则的方法应用在具有多元限定关系的实体之间,首先选择在实体抽取任务中含有特定类型实体的语料作为接下来规则抽取的数据,其中抽取到的实体包含食品以及贮藏温度、空气状况、贮藏时间、保藏方法、贮藏操作、场景、包装7 类实体中一类或多类。然后发掘数据中的表述规律,设计抽取规则算法完成关系抽取,通过对相关语料分析可以总结出:
(1)绝大部分语料都是以食品类型实体作为主语进行表述,且一条语料以一种食品居多,常常出现在句子开头。
(2)贮藏温度等7 类实体在文本中不单独存在,而是依附于食品实体,表述中具有多元限定关系的实体往往在一句话或者相同句式内。
(3)贮藏温度、贮藏时间和保藏方法3 类实体根据实际语义可知,同种类型实体不会同时出现在一个超节点下,即以上3种类型的同种实体间不构成多元限定关系。
(4)在一条语料当中,多个贮藏条件(即一个超节点下具有多元限定关系的实体组成一个贮藏条件)往往以“;”或者以不同的保藏方法、贮藏温度实体作为界限来划分,语料在进行实体抽取后的实体序列常常具有规律性。比如抽取的正则实体序列为“(食品,贮藏温度,空气状况(,(贮藏操作|场景|包装))*)+”,可以表达“龙眼贮藏适宜温度3~5 ℃,氧含量3%~5%,二氧化碳5%~8%;巨峰适宜温度0%,氧含量3%~4%,二氧化碳含量5%~6%。”
(5)对于多个食品类型实体的表述往往呈并列形式出现,常用“和”“;”以及“、”隔开或采取相同句式表述。例如“白梨和沙梨适宜贮温一般为0~1 ℃,大多西洋梨和秋子梨适宜贮温-1~0 ℃”“各种罐头、饮料、油料、干制食品等都适宜在常温下贮藏和流通”。
本文基于食品贮藏领域内数据特点设计规则匹配关系抽取算法,完成对多元实体对应关系的筛选与结合,继而完成多元限定关系中实体序列的抽取。需要说明的是,对于输入的每一条语料C都有与之对应的经实体抽取任务后得到的实体组E和实体类型组M。分割文本c、分割实体类型组mc[h..t]和分割实体组ec[h..t]同样也一一对应,h、t表示从M和E中分割的头位置和尾位置。算法中步骤6 表示将实体类型组与正则实体序列进行匹配,若匹配结果不空则完成数据提取。步骤9 旨在匹配那些缺少上文已提及食品指代的分割文本中的多元限定关系,其中mc-1[h′..t′]表示上一条分割文本的分割实体类型组。
算法规则匹配关系抽取算法
2.5.2 基于BERT的关系分类
关系抽取任务应用深度学习方法进行高效解决,则可以将其建模为多标签分类问题。对于模式层构建中的五种普通关系,本文采取基于BERT的关系分类模型[33],使用预训练模型来获得丰富语义的特征向量,提升关系抽取的效果[34]。与BERT在实体抽取任务的作用不同在于,本文不仅进行句子embedding 表征信息,同时又结合了实体以及实体位置信息,经由特征向量对关系分类进行预测。
抽取模型的输入信息包含实体的文本,以及待抽取关系的头尾实体信息。在数据预处理时,以特殊标识符表示待确定关系的两个实体位置,其中实体位置前后加“#”表示,尾实体位置前后加“$”表示。并以[CLS]作为句子的开始,以[SEP]作为句子结束。然后采取BERT模型特征提取后将句子信息特征、实体语义特征和实体位置信息拼接,经全连接层和softmax 层完成关系分类的概率预测,最终输出待预测的结果。普通关系抽取工作原理如图4 所示,图中关系标签3 为关系“不可混合贮藏”的编码信息。

图4 普通关系抽取工作原理图Fig.4 Working principle diagram of common relation extraction
2.6 知识融合
由于食品贮藏领域数据多元,文字表述存在差异,对于同一个概念的描述会存在差异,常常会抽取不同的实体却表达同一种语义概念,经过抽取任务后完成存储会使知识产生大量冗余并占有额外的存储空间,因此需要进行实体对齐。例如“洋葱和土豆这两种蔬菜却并不适合放在一起。”中的“土豆”和语句“马铃薯的贮藏方式很多,依据各地不同条件可做堆藏、窖藏、沟藏等。”的“马铃薯”表达为同一种食品名称;还有“水果蔬菜”对应“果蔬”的略写,“软饮料”对应“软饮”的表达;对于贮藏温度的表达“1 ℃~2 ℃”“1~2 摄氏度”,若不进行处理则会按照不同的实体进行存储;针对其他类型实体,比如贮藏方法中的“气调贮藏”和“气调贮藏法”的表述需要进行知识合并。针对多元限定关系同样也会产生关系冗余的情况,这是由于在完成关系抽取和实体对齐任务后,会出现不同的多元限定关系实体组内含有多个相同实体。例如r1=[“金冠”,“0~2 ℃”,“3个多月”],r2=[“金冠”,“0~2 ℃”,“相对湿度95%”,“3 个多月”],对于“金冠”的同一个贮藏条件(由于r1⊆r2),显然r2对应的原文本比r1描述得更全面,那么r1相对于r2来说则作为冗余信息存在。由于食品贮藏条件复杂,实体间关系相互制约,只有当多元限定关系实体组之间存在包含关系时,认为该食品在相同贮藏条件下存在冗余,否则作为不同的贮藏方式进行存储。
根据上述分析,本文采取依据词典和相似度匹配的知识融合方法,流程图如图5所示。经关系抽取任务后将实体分成实体对和多元组两类,识别为多元组中的实体在经过实体对齐任务后,需要额外判断是否存在冗余多元信息,完成超节点对齐任务,即消除多元限定关系冗余。首先依次输入组内实体判断类型,若输入实体为“食品”类型,则利用食品别名词典进行匹配查找,若找到则依据词典中主名进行替换,若没有找到则进入相似度匹配计算。对于含有数值信息的实体类型(贮藏时间、贮藏温度、空气状况),需进行标准化处理,即将实体内容统一为“(描述)+数值范围+单位/%”,若与已更新实体表述相同则视为同一实体。针对食品贮藏领域数据,经上述两类实体对齐处理即可消除较大比例的冗余信息,故对于剩余类型实体,本文采取快捷且效果良好的余弦相似度算法来匹配实体间的相似性,采用sklearn中tfidf工具完成实体词汇级别的向量化表示,依次计算其与图谱中同类型各实体间的余弦相似度S,计算公式如下:

图5 知识融合流程图Fig.5 Knowledge fusion flowchart
其中,E和X表示实体的词向量,n表示向量维度,ei和xi分别表示E和X的第i个分量,S越大表示两向量的余弦相似性越强,即两实体语义越接近,选择超过设定阈值且数值最大的实体作为融合对象,若匹配失败则作为新的实体,依次循环上述过程完成组内实体对齐任务。由于上述处理可能会存在一定的误差,为保证准确性,在循环结束后应辅助校验未匹配成功的实体是否需要实体对齐。若是实体对中的实体则完成实体对齐任务,取得新的三元组或链接到图谱中已有的节点中完成数据库更新。若是多元组内的实体,则继续完成超节点对齐,即遍历图谱中超节点下多元限定关系中实体集合是否与输入多元组集合有包含关系,若没有则作为新的多元限定关系以超节点形式存储在知识图谱当中,反之取两者的超集(superset)作为存储在图谱中的内容来更新数据库。经过知识融合后,使得知识元质量得到提升,节省了存储空间。
3 实验分析
3.1 实体抽取
按照第2.1 节中非结构化数据的划分方式,分别选取韩艳丽编著的《食品贮藏保鲜技术》、刘兴华编著的《食品安全保藏学》、王城荣编著的《常用食品的贮藏与保鲜》以及105 篇科研文献摘要、50 篇网络短文作为数据来源,经数据预处理相应操作后,共获得13万字的语料,从中随机抽取2 000条作为命名实体识别的数据集,训练集和测试集比例为8∶2,数据预处理后待抽取语料示例图如图6所示。

图6 待抽取语料示例Fig.6 Examples of unextracted corpus
本文采取BIO 实体标注方法完成对语料中字符的表征,其中B表示命名实体的开头字符,I表示命名实体的剩余字符,O表示所有命名实体以外的字符。语料共有21种标签,命名实体标注示例如表3所示。实体识别模型的BERT预训练模型版本采用BERT-Base-Chinese,训练批量大小为16,最大序列长度为246,部首特征向量维度为32,BiLSTM隐藏层维数为128,学习率为5E-5,训练轮次为50。
为了验证本文提出模型的性能优势,分别选取在命名实体识别中常用的BiLSTM-CRF、BERT-CRF、Word2vec-BiLSTM-CRF、BERT-BiLSTM-CRF模型在构建的食品贮藏数据集上进行对比实验,实验结果采取召回率R、精确率P和F1 分数三种评价指标。实验结果如表4所示,本文融合多特征的实体识别模型识别效果最佳,其中F1 值为91.07%,比直接融合动态词向量的BERT-BiLSTM-CRF 模型以及采取传统静态特征向量的Word2vec-BiLSTM-CRF 模型分别在F1 值上提高1.52 个百分点和13.03 个百分点,相较于没有学习语义特征进行随机编码的BiLSTM-CRF 模型识别效果更有优势,证明本文模型能够有效捕获食品贮藏文本中的语义特征和上下文信息来完成实体抽取任务。采用本文模型对于10 类不同类型实体抽取的实验结果如表5 所示,分析可知其中“贮藏时间”“食品”等实体类型识别效果最好,原因在于这些类型在表述上较为规范,且模型在这些类型实体上的语义特征提取表现较好;然而对于“贮藏操作”“场景”等实体类型识别效果相对一般,这是由于与其他类型实体相比包含该类实体的文本相对较少,模型学习特征稍显欠缺,同时该类型实体表述方式往往相对复杂,标注可能存在部分偏差。

表4 不同模型的识别结果对比Table 4 Comparison of recognition results of different models 单位:%
3.2 关系抽取与知识融合
3.2.1 基于规则的关系抽取
规则匹配关系抽取算法主要完成对实体间的多元限定关系进行匹配抽取,其详细流程已在第2.5.1 小节中阐述。首先将经实体抽取任务后具有实体标签的文本和原实体标注语料作为候选数据,然后根据实体标签类别对候选数据进行筛选,剔除仅含有例如“食品”或者“食品”“贮藏特性”等不具备多元限定关系的句子,共计得到2 104条待抽取语料,对应2 104组实体组15 649个实体。将待抽取语料、对应实体组和实体类型组作为算法的输入,保证实体序列要与语料中的语序保持一致,经过算法中正则表达式以及文本匹配方法抽离出存在多元限定关系的实体集合。经过规则匹配关系抽取算法循环遍历所有输入语料,输出得到多元限定关系实体组,并以json 格式进行存储,为后续实体融合与知识存储做准备。抽取结果示例如图7 所示,共计抽取2 638组多元限定关系。图8 展示了抽取得到的多元限定关系中各类型实体的占比情况,其中除食品类型外,保藏方法和空气状况类型实体相对较多。

图7 实体组抽取结果示例Fig.7 Examples of entity group extraction results

图8 多元限定关系中各类型实体占比情况Fig.8 Proportion of various types of entities in multi-restricted relation
3.2.2 多分类关系抽取
本文同样从第3.2.1小节提及的候选数据中选择具有潜在普通关系的文本作为关系分类实验的语料,即句子中包含“食品”“病虫害/败坏现象”“保藏方法”“贮藏操作”“食品贮藏特性”5种实体类型,共计得到2 040条语料,并完成6类关系标注,包括5种普通关系和未知关系。由于语料中对于“贮藏条件相似”“不可以混合贮藏”2类关系的知识较少,即与其他关系类型数据分布不均衡,故采取数据增强的方法来弥补相对其他长尾类型关系的影响,共计构建4 063 条语料,关系编码、各关系数量以及抽取文本示例如表6所示。需要注意的是,其中数据增强获得的语料仅作为模型训练数据,而不能作为图谱构建的知识元。标注语料按照8∶2 的比例划分训练集和验证集,训练模型中使用的BERT预训练模型为BERT-Chinese-base,训练批量大小为32,最大序列长度为128,学习率为3E-5,训练轮次为30。经过实验验证各类关系的评价分数如表7 所示,平均F1 值达到94.14%,分类效果较好。相比于实体识别任务和多元限定关系,普通关系的表述相对单一,文本中常常会出现“具有”“防止”“相类似”“包括”等内容,使得模型学习到的数据特征较为准确。依据评价指标和具体抽取情况表明,利用基于BERT的分类模型抽取效果较好。

表6 普通关系抽取示例Table 6 Examples of common relation extraction

表7 普通关系抽取实验结果Table 7 Experimental results of common relation extraction单位:%
3.2.3 知识融合
将完成规则抽取和模型抽取的数据分成三元组和多元组两类,作为本文提出的知识融合方法的输入项,融合过程中包括食品别名词典的检索,向量化相似性比较,多元组集合重叠等。其中构建食品别名词典采取Scrapy框架爬取相关网站常见的食品别名,共计食品种类为766种,别名数量4 360个,并以json格式存储以方便算法中字符查找匹配,同时将余弦相似度阈值设置为0.7。经过知识融合方法后获得高质量实体关系组,完成实体对齐和多元限定关系的冗余消除,融合前后的知识对比效果如表8所示。

表8 知识融合前后示例Table 8 Examples of before and after knowledge fusion
4 知识图谱可视化和语义检索
将抽取得到的知识进行合适的存储与表示是构建知识图谱的重要环节,本文选取开源图数据库Neo4j(neo4j.com)存储食品贮藏领域知识图谱。Neo4j 具备处理庞杂数据敏捷和查询速度快等优势,同时还具备直观、易于理解的可视化前端,但在Neo4j 中常常以三元组的形式进行表示。然而本文提出的超节点表示方式可以很好地嵌入到Neo4j当中,从而避免两两实体间错乱复杂的关系表示形式,大大减少关系数据的存储量。
将相关的各类异构数据资源利用本文的知识图谱构建框架技术,在Neo4j 数据库中完成存储,构建可视化食品贮藏知识图谱用于各类语义检索。为了提升存入速度,本文使用Neo4j提供的Py2neo工具包批量导入数据,将抽取完成的数据转换为csv 格式,使用Node、Relationship 等方法完成实体和关系的创建,同时使用merge方法完成节点与边的导入。共计导入10 211个实体,普通关系2 697 组,多元限定关系2 419 组。图9 展示了食品贮藏知识图谱构建的整体可视化效果,图10和图11分别展示具有多元限定关系和普通关系的部分图谱示例,有效表达出食品不同条件下的贮藏知识和相互之间的关联关系。
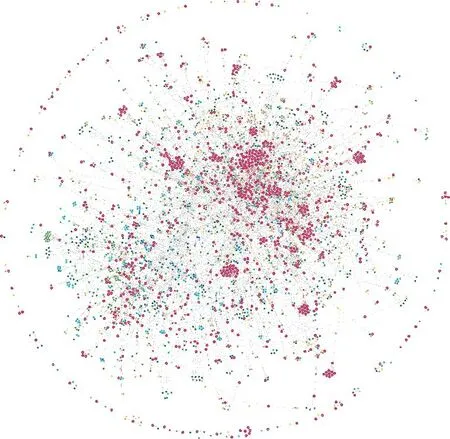
图9 食品贮藏知识图谱可视化Fig.9 Visualization of food storage knowledge graph
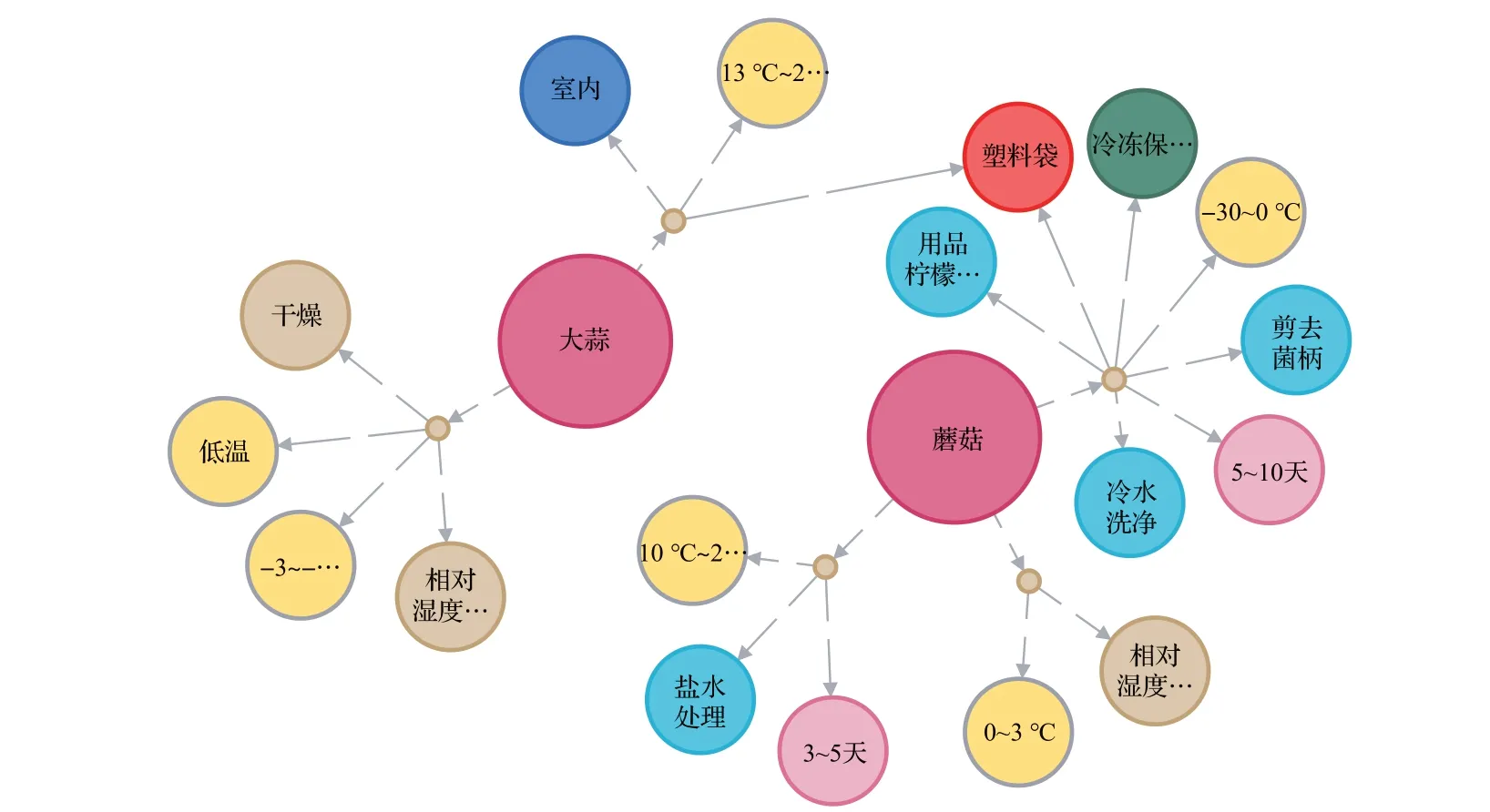
图10 具有多元限定关系的部分图谱示例Fig.10 Examples of part of knowledge graph in multi-restricted relation
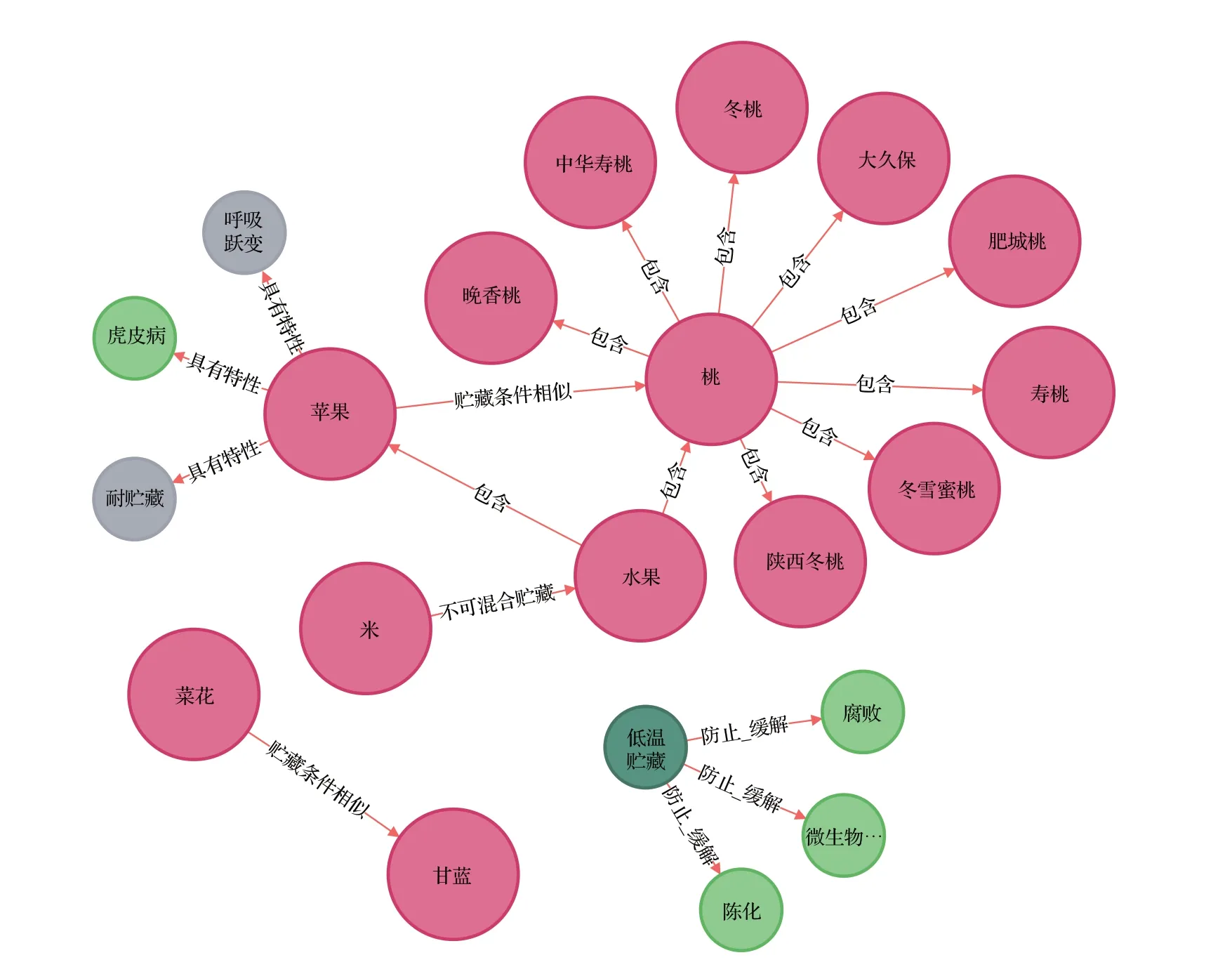
图11 具有普通关系的部分图谱示例Fig.11 Examples of part of knowledge graph in common rela-tion
通过构建的图谱可视化结构,可以直观看到“苹果”与哪些食品不宜贮藏在一起,在哪些贮藏条件下温度湿度等的不同,具体“苹果”有哪些品种以及贮藏方式等。为了更精准的语义检索,可以使用Cypher 语言进行查询。例如查询“葡萄”有哪些贮藏特性且适合在什么条件下贮藏,可以通过“match(n:food{name:“葡萄”})-[r1:`具有特性`]->(p)returnn,punion match(n:food{name:“葡萄”})-[r2:` `]->(m)-[r3:` `]->(p)returnn,p”查询可知“葡萄”较耐贮藏,且适宜在2℃、湿度78%下采取窖藏法贮藏。再者例如查询如何防止“高粱米”在存储过程中变味的现象,通过“match(n:food{name:“高粱米”})-[r1:`具有特性`]->(p:bad{name:“变味”})<-[r2:`防止/缓解`]-(q)returnn,p,q”可知贮藏“高粱米”时应该保证“风晾降湿”来防止“变味”“裂纹”。将繁杂的食品贮藏数据通过本文的知识图谱构建技术形成结构化知识表达,便于知识理解与高效查询,可以多角度地获取想要的知识,为后续该领域的相关建设与应用提供帮助。
5 结束语
本文在大数据的社会背景和食品贮藏研究的背景下,针对食品贮藏领域数据海量异构、资源利用率较低和缺乏系统化表示等问题,提出了一套较为完整的食品贮藏知识图谱构建框架,包含了不同结构不同来源的数据处理方法。本文首先针对领域内数据特点提出了多元关系的表达模式,设计了融合多特征的实体抽取模型和多元关系抽取算法完成知识抽取,其次利用构建的食品别名词典和相似性匹配算法完成知识融合,然后将形成的结构化知识通过图数据库Neo4j 进行存储和可视化表达。本文分别将技术书籍、科学文献、网络文章等作为数据源进行实验验证,充分证明了所提出框架的合理性和有效性,为食品贮藏相关研究开辟了新的智能视角,同时也为其他领域数据分析表达和知识图谱构建提供借鉴。未来将在完善FSKG构建以及自动问答、知识补全等方面开展研究。
