高校学业文本命名实体识别及数据集构建研究
2023-11-27苑迎春王克俭
何 晨,苑迎春,2,王克俭,2,陶 佳
1.河北农业大学 信息科学与技术学院,河北 保定071001
2.河北省农业大数据重点实验室,河北 保定071001
教育部2020 年发布的全国教育事业统计结果显示,全国共有普通高校2 668所,其中本科院校1 265所,全国各类高等教育在校学生总规模达4 002 万人[1]。高等教育的普及致使出现学业问题的学生数量不断增多,与高校现有教学管理师资力量出现了极大的不平衡。教育部发布的信息显示,当前我国高等学校平均每学年因学业等原因退学的本专科学生人数已超过10 万人,每学年因各种学业问题延期毕业与肄业的学生数量更是居高不下[2]。因此,学业问题成为亟待解决的重要问题。当前,国家修订了《高等学校学生行为准则》《普通高等学校学生安全教育及管理暂行规定》等一系列规章制度,且全国高校都编撰了具有一定体系的学业管理规定,为大学学业领域进行实体命名识别数据集的构建提供了大量文本数据。
Rau[3]首次提出了命名实体识别任务,作为信息抽取中的基本工作,该技术一直以来得到众多学者在不同广度与深度上的关注和研究[4-6]。命名实体识别即文本语义信息挖掘[7],从文本的语义表征层面出发,对上层关系抽取[8]以及领域知识图谱[9]构建起到了决定性作用,精准的命名实体识别有利于后续工作的顺利开展。通过完成实体识别任务,抽取出文本中的关键实体,从而有效构建三元组(<头实体h,关系r,尾实体t>[10])。传统识别方法主要依赖于大量人工标注构建的手工模版、专家先验知识构建的词典和具有统一文本格式所建立的正则表达式开展研究。以隐马尔可夫(hidden Markov model,HMM)[11]、条件随机场(conditional random field,CRF)[12]为主流的传统识别模型,依据统计方法选用最大预测概率进行输出,其中CRF模型被广泛使用。随着深度学习的不断发展,基于深度学习的文本语义方法作为实体抽取的主流技术被众多学者引入。长短期记忆(long short-term memory,LSTM)[13]网络与双向长短期记忆(bidirectional long short-term memory,BiLSTM)[14]网络被先后提出。深度学习模型通过文本语言的前后向感知,开展对字词向量以及位置向量的自动学习,使得面向各行业领域、地域和组织机构等目标的实体识别准确率有了显著提升。
在教育领域,程哲[15]提出了针对中学某一特定学科的命名实体识别方法,但针对高校学业领域的相关文本信息抽取,目前还未有相关学者进行研究。鉴于当前我国高校大量存在的学业问题,开展面向具有普遍性和通识性的高校学业管理的命名实体识别方法研究变得极为迫切。构建高校学业领域数据集并完成命名实体识别研究,作为构建知识图谱的首要工作,为实现基于知识图谱的高校学业智能问答服务研究提供了有效支撑。同时也能辅助学生便捷、高效、自助式完成学业问答,实现学业自我管理,从而顺利完成学业。并且可以提升教辅人员解决学生学业问题的效率,减轻工作压力。高校学业领域与普通领域文本存在很大区别,具体表现在:(1)高校领域中包含大量的专业领域词汇。(2)相同类别的高校领域实体具有不同表述方式。(3)高校学业实体大多存在实体嵌套特点。(4)在确保最小细粒度类别划分的情况下,实体的类别标注需要更加精准。
为解决上述问题,本文的主要研究内容为以下四点:(1)收集高校学业管理规定文件,提出一种适用于学业领域的实体分类标准。(2)按照公开数据集NLPCCKQBA 构建高校学业问答文本数据集。(3)将构建后的数据集作为实验对象,通过公开数据集确定命名实体识别模型,再对分类后的数据集进行测试。(4)评价分类后数据集在命名实体识别主流模型中的表现。
1 高校学业文本数据
本文原始数据取自《中华人民共和国高等教育法》[16]、《国家教育考试违规处理办法》[17]、《普通高等学校学生管理规定》[18](教育部令第41号)以及某高校普通本科学生专业培养与专业分流实施办法等(该办法为适应国家高考制度改革,结合学校实际所制定)。层级上按照普通高等学校学生管理规定划分为7 个大类,如表1 所示。每一类别分别针对高校和学生做出相应规定,管理规定原始数据样例如表2所示。

表1 普通高等学校学生管理规定Table 1 Management regulations on students in institutions of higher education

表2 管理规定原始数据样例Table 2 Raw data samples of management regulations
2 高校学业问答文本原始数据集构建
由于国家出台的相关管理规定旨在为各高校提供学业管理方向,规定学业管理内容,仅依据国家规定进行高校学业领域数据集构建,不足以表示实际应用情况。本文采用经国家规定、学校章程以及学校实际情况所制定的某高校普通本科学生专业培养与专业分流实施办法等相关文件作为高校具体实施学业管理规定样例。该类文件共计13 万余字,涵盖学生综合素质测评办法、奖励管理办法、违纪处分实施办法等内容,从实际层面详细制定了高校在校学生的学业管理细则,由此构建的数据集具有实用性和代表性。
NLPCC-KQBA数据集由中国计算机学会(CCF)举办的中文信息技术专业委员会年度学术会议发布。该数据集由包含14 609个问答对的训练集和包含9 870个问答对的测试集组成,并提供一个知识库,包含6 502 738个实体、587 875个属性以及43 063 796个三元组。作为命名实体识别通用数据集,本文将高校学业领域相关管理规定和收集到的学业问题仿照NLPCC数据集完成知识库与问答对的构建,如表3所示。

表3 数据集构建的知识库和问答对样例Table 3 Knowledge base and question-answer pair examples constructed from datasets
3 高校学业文本分类与特性分析
通过对高校学业管理规定和在校学生普遍存在的问题进行汇总分析,可知高校学业主要涵盖领域包括学生日常行课的基本要求、考试形式、学分修读、学籍异动和专业变动等方面。其中学生对于修读专业的选课类别、课程重修限制、所学科目考试规定与参加补考要求等最为关注。因此,在满足国家针对学生培养方案的基本需求上,本文参照学生关注点,融合高校专业学业管理人员的专家知识,对高校学业文本进行命名实体识别的类别划分。在确保类别不重叠、种类精简且涵盖范围全面的原则下完成划分,共计分为八大类,分别为考试(EXAM)、课程(C)、选课(CV)、学分(CR)、学籍(STAT)、转专业(CMJR)、毕业(GRAD)和其他(ELSE)。最终实现以最小粒度为出发点,对学生提出的学业问题文本进行命名实体识别操作。例如问题文本描述为“课程既有理论课又有实验课,选其中之一可以吗?”,则将“理论课”“实验课”均标注为课程(C)实体。表4 为高校学业领域文本命名实体类别与样例。
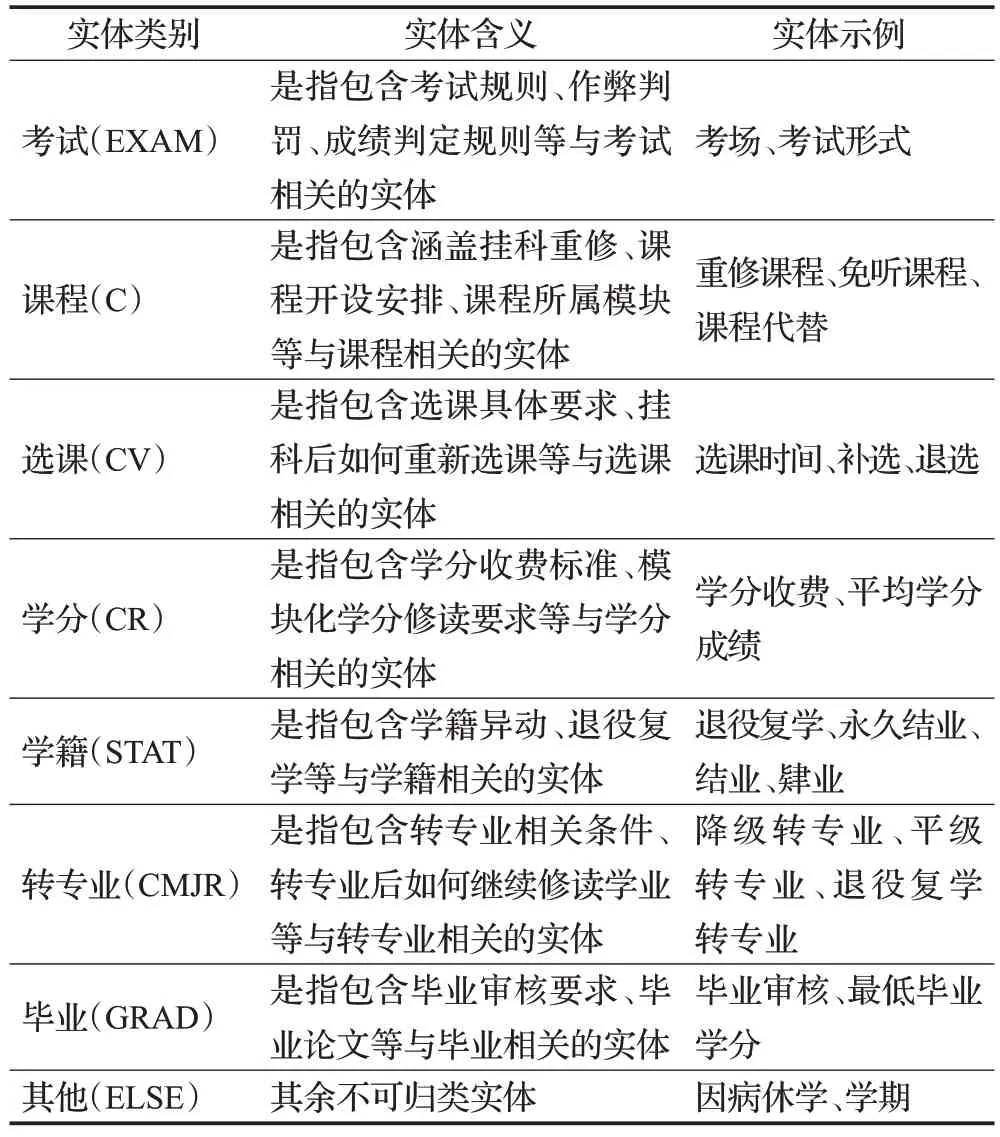
表4 高校学业领域文本命名实体类别与样例Table 4 Types and examples of text named entity in academic fields of universities
学业领域的命名实体识别目标与通用领域中地点、人物和组织等待识别实体存在较大区别。更是由于面向群体的独特性以及各高校规范细则存在差异化(以修读课程编号为例),难以获取具有较高普遍性的海量实验语料。上述各命名实体类别还存在独特的领域特性。
(1)考试(EXAM)类别中,多数的问题文本中不会直接提及名词“考试”。例如“规定以外的笔或者纸答题或者在试卷规定以外的地方书写姓名、考号或者以其他方式在答卷上标记信息”这一文本,其所表述含义实为该行为是否会被认定为考试作弊。为保证该领域分类精简,实体不再被继续划分为“作弊”类别,本文依靠深度学习模型准确识别问题文本语义,确保表述实体识别时实现正确标注并分类。
(2)名词因该领域独特性,在不同语句中充当的成分不同会影响命名实体识别的最终标注结果。例如“退役复学哪些课程免修?”中的“退役复学”作为课程免修的限制性条件,并非为构成三元组的实体组成部分。而在“退役复学转专业有条件限制吗?”中的“退役复学转专业”可识别为一个实体,且应将其归为转专业(CMJR)类。
(3)学生在进行提问时,大多问题会包含多个相同类别的实体。例如“毕业审核通过,但是毕业设计或者毕业实习不合格怎么办?”中包含“毕业设计”与“毕业实习”两个待识别实体,且该问题应构成的三元组形式为<毕业设计 毕业实习,不合格,无法顺利毕业>。因此,只有合理抽取出实体才可以正确构造所需的三元组,使得问题的回答合理有效,并构建出无误的高校学业领域知识图谱。
由此可见,高校学业领域的命名实体识别包含众多的专业名词、不明确指向性实体以及涉及到上下文位置关联性实体。对实体合理地进行类别划分,并结合专家的先验知识进行实体数据集的标注与构造,可为顺利开展高校学业领域文本命名实体识别工作提供有力支撑。
4 高校学业领域实验数据集构建
在高校学业实验语料处理方面,如上所述,本次处理结合教育部《普通高等学校本科专业类教学质量国家标准》规定以及学业管理领域专家的意见,合理按照实体类别划分标准将自建专业领域实验语料进行实体标注。整体采用了BIO标注策略,结合所提出的语料标签设置完成标注工作。以实体类别“考试”为例,与考试内容相关实体的开始部分以“B-EXAM”表示,剩余实体内容标注为“I-EXAM”,句中其余成分均标注为“O”。高校学业领域实验语料标签设置情况如表5所示。
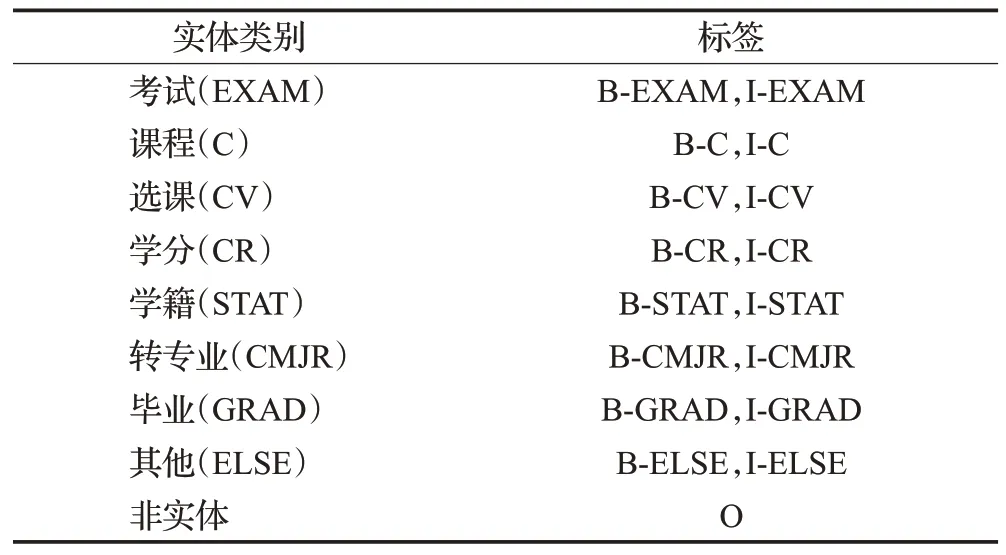
表5 高校学业领域实验语料标签设置Table 5 Label setting of experimental corpus in academic field of universities
引用高校学业问答原始数据集文本即表3 中原始问句样例,举例说明命名实体识别数据集进行人工标注的过程。样例问句内容为“选课的学分限制是什么?”,参照NLPCC-KQBA 公开数据集格式标准进行标注,具体标注格式如表6所示。

表6 NLPCC-KQBA数据集标注格式Table 6 Annotation format of NLPCC-KQBA dataset
根据表6 公开数据集标注格式以及本文提出的高校学业领域文本分类标准,同专业学业管理人员确定文本所包含实体并进行相应标注工作。按照表5所示标签完成所有高校领域文本标注工作,标注后的数据如表7所示。

表7 高校学业领域标注后数据集Table 7 Annotated dataset in academic field of universities
5 实验
5.1 实验环境与参数设置
实验采用3.8.5版本的Python编程语言,分别对公开数据集NLPCC-ICCPOL 2016 KQBA、NLPCC-ICCPOL 2018 KQBA和实验数据集进行对比实验。所有实验程序均部署于配置为i7-10700 CPU、16 GB内存、NVIDIA GeForce RTX 3060 12 GB显卡、1 TB硬盘并安装Windows 10操作系统的主机上。
首先验证BiLSTM-CRF模型的命名实体识别效果,分别选用了机器学习方法的HMM 和CRF 模型以及深度学习方法的BiLSTM 模型进行对比实验。该实验在NLPCC-ICCPOL 2016 KQBA 与NLPCC-ICCPOL 2018 KQBA公开数据集上进行,展现BiLSTM模型的双向长短期特征提取的优势和命名实体识别的稳定性,以及同CRF 模型组合后的整体性能。然后将该模型运用到实验数据集进行命名实体识别实验,证明本文构建的高校学业领域数据集的可用性。
实验中BiLSTM模型的训练参数设置分别为:学习速率lr为0.001,epoch 迭代次数为100 次,词向量维数为128,隐向量维数为128。CRF 模型中L1 正则化系数与L2正则化系数均为0.1,最大迭代次数为100次。
实验结果采用评价指标分别为准确率(precision,P)、召回率(recall,R)和F1值(F1-score)三个常用指标。准确率为实体被正确识别个数与识别实体总个数的比值,召回率为正确识别实体个数与测试集合中实体总数比值,F1 值为准确率与召回率的调和平均数。通过上述三个指标来体现模型的命名实体识别性能。
5.2 实验结果与分析
本文共进行了三组对比实验,分别开展了HMM、CRF、BiLSTM 和BiLSTM-CRF 四种模型在NLPCCICCPOL 2016 KQBA、NLPCC-ICCPOL 2018 KQBA公开数据集中命名实体识别的效果分析,四种模型在未分类下的高校学业文本数据集中命名实体识别的适用性分析,四种模型针对分类标注后数据集中命名实体识别的效果分析。
(1)各模型对公开数据集的对比实验
表8为无预训练下面向NLPCC-ICCPOL 2016 KQBA和NLPCC-ICCPOL 2018 KQBA公开数据集,分别进行机器学习命名实体识别方法与深度学习命名实体识别方法的对比结果。由所得数据可知,将CRF模型与BiLSTM模型结合后,在开放领域的准确率、召回率和F1 值三个评价指标对比命名实体识别效果均优于其他模型,具有更强的识别能力。因此,BiLSTM-CRF模型的识别效果可有效说明本文构建的高校学业数据集是否合理有效。
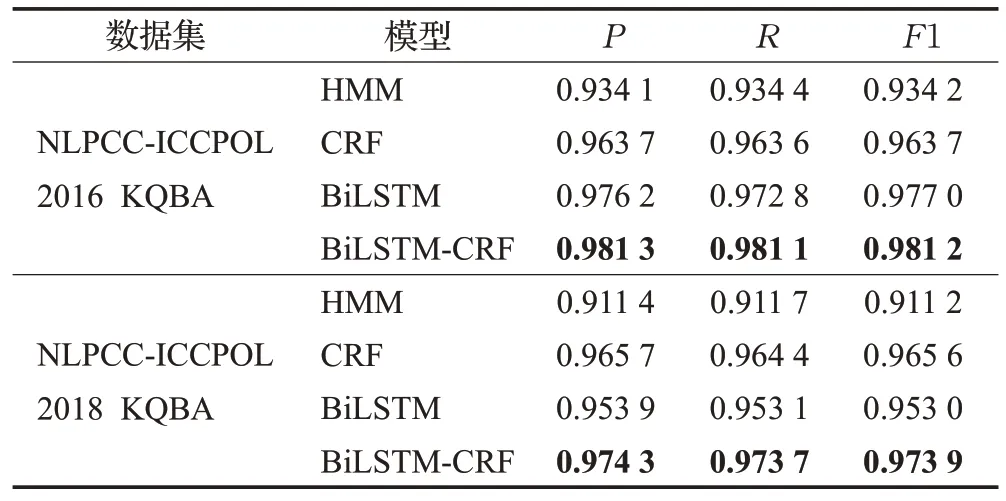
表8 NLPCC语料下不同模型对比实验结果Table 8 Results of experiments comparison of different models with NLPCC corpus
为确保对比实验的公平性,机器学习命名实体识别方法CRF的最大迭代次数与深度学习命名实体识别方法BiLSTM 的epoch 均设定为100 次。由实验数据可知,HMM模型的识别效果较差,综合评价指标F1 分别仅达到了93.42%、91.12%。其原因是隐马尔可夫模型存在两个假设:一是输出的观测之间是严格独立的;二是状态的转移只与当前状态的前一状态有关。其无法将待标注文本信息有效结合,单一地限定在了状态与观测值之间。而CRF 模型在HMM 模型的基础上进行了改善,合理引入了全局概率,且该模型在归一化操作时也从局部面向了整体。因此,在机器学习模型上CRF模型较HMM 模型的性能得到有效提升。基于深度学习神经网络的BiLSTM 模型为该领域的主流模型,在LSTM 模型的基础上通过双向对文本字符序列进行学习,相较机器学习中的模型CRF 仍存在一定的提升空间。对两种不同类型的方法进行有效结合后,分别利用BiLSTM 模型的双向学习能力和CRF 模型对标注的全局性优势,在各项评价指标上均达到了较优的实体命名识别效果,实体命名识别的准确率在NLPCC-ICCPOL 2018 KQBA 上达到了97.43%,相较单一BiLSTM 模型提升了2.1%。
(2)各模型对学业领域数据集的对比实验
将构建完成的高校学业问答文本进行了十折交叉验证实验,将其随机分成10 份,每次选择9 份作为训练集,剩余1 份作为测试集进行HMM、CRF、BiLSTM 和BiLSTM-CRF模型的对比实验。表9为对比实验结果,其中加粗部分为每份测试集下准确率与F1 值最优结果。
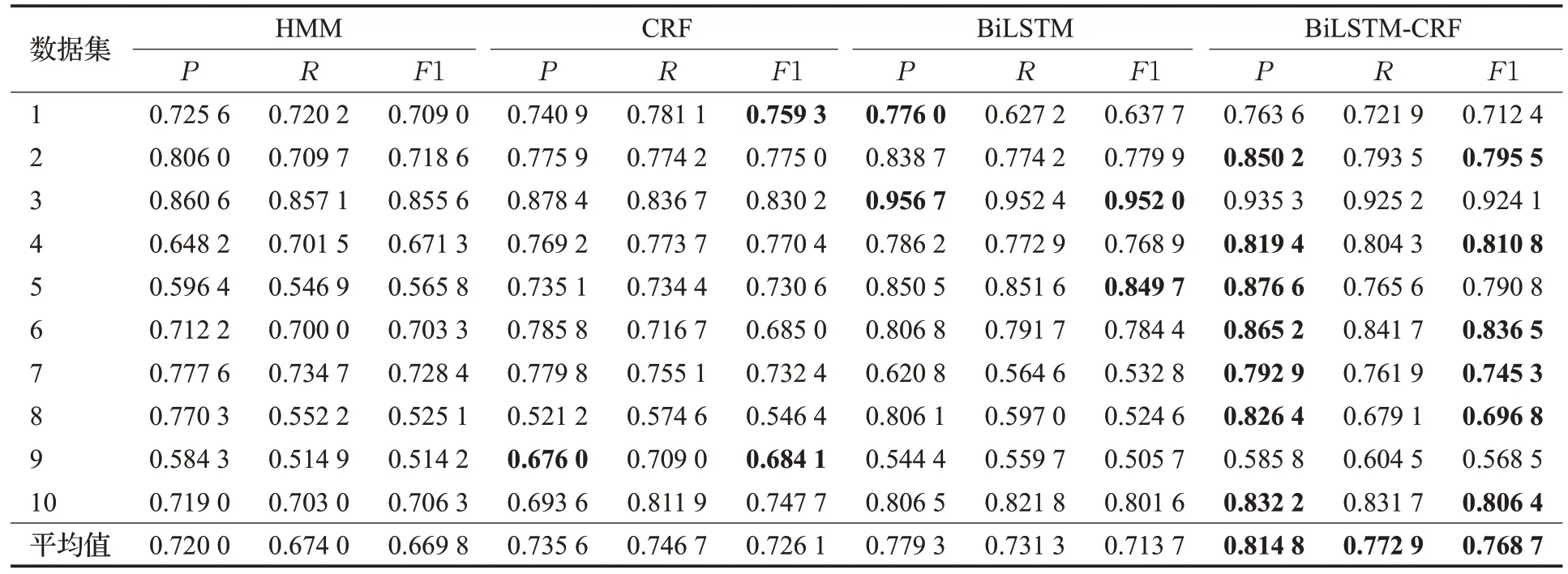
表9 高校学业问答数据集下各模型对比实验Table 9 Comparative experiment of various models for college academic question answering datasets
由于对比实验文本发生调整,对参与训练的BiLSTM模型参数进行微调,学习率调升至0.005,且为避免过拟合,将迭代次数修改为50 次。根据上述实验结果分析可知,在该领域BiLSTM仍可有效利用双向长短期提取特性的独特优势学习领域文本中所包含的专业术语。但因存在实体嵌套等问题,相较机器学习模型,F1 值提升范围仅保持在5%~10%之间。通过CRF 模型的辅助后,整体模型将F1 值平均提升了6.55%。通过对比各命名实体识别模型在同一数据集下进行十折交叉验证实验的结果中F1 值的平均值和方差可知,BiLSTM-CRF模型的整体识别效果优于其他模型,识别不具有偶然性。HMM 模型与CRF 模型在命名实体识别时并不对训练集进行有效学习,仅凭借其前向算法或全局特性对测试集进行实体标注。同时也说明了BiLSTM-CRF 模型在该领域的实体命名识别上较为稳定,具有更佳的综合识别效果。
(3)各模型对不同类别命名实体识别对比实验
为更好地进一步验证经分类后所构建的高校学业命名实体识别数据集效果,根据表9 实验结果,选取该模型识别效果最优数据集完成分类标注。对各模型进行不同类别命名实体识别的对比实验,表10 为对比实验结果。

表10 各模型对不同类别命名实体识别实验的F1 值对比Table 10 Comparison of F1 values of each model for different types of named entity recognition experiments
如上文所述,学生对“学分”领域、“转专业”领域以及“选课”领域提问相对较多,故CR 实体、CV 实体和CMJR 实体在文本中大量存在。且该类别实体大部分包含相同内容,例如“最低毕业学分”与“平均学分成绩”两实体均包含学分字样,在双向循环网络中通过模型对实体上下文顺序特征的有效学习,会更好地提取文本特征。因此,在本实验中对CR 实体进行命名实体识别时具有最佳的F1 值。
在包含C 实体的文本中,不仅存在中文文本实体,还存在以课程编号为待识别实体文本。例如,“课程号是BL1623000S 和BY1623000 两种都是实验课,两者有何区别?”问题中,存在“BL1623000S”与“BY1623000”两实体。该类别实体的组成会存在更细粒度元素,使得命名实体识别难度增大。因此在所有模型中C 实体的评价指标F1 值相较其他实体识别结果偏低。
CMJR 实体是针对转专业领域构建的实体,CV 实体是针对选课领域构建的实体。由于转专业后的学生大多需要重新进行选课,二者实体会更为频繁地出现在同一识别文本中,且部分实体还存在实体嵌套关系。针对此类实体需对学生问题进行合理分析,判别嵌套实体在语义层面应如何标注。BiLSTM-CRF 模型通过词语在句中的前后顺序,可更好地捕捉句间的字词距离的依赖关系。对比模型HMM与CRF,本文方法在该类别进行命名实体识别时F1 值提升了5%左右,达到了91%以上。
(4)深度模型时间性能对比
对基准模型BiLSTM 与组合模型BiLSTM-CRF 分别在未分类下BIO 标注的高校学业数据集和经过专家先验知识标注后的高校学业数据集上耗费的训练时间进行分析,检测模型的时间性能。使用训练过程中的最后一个epoch所花费时间,进行时间性能对比。由表11实验结果可知,经过分类标注后的数据集,BiLSTM 模型耗费时间提升了40%,BiLSTM-CRF耗费时间提升了32%,而实体识别的精准率提升了9%。实验结果证明了组合模型BiLSTM-CRF通过较低的时间成本,有效地提升了实体的识别效果。

表11 不同数据集下深度模型训练时间Table 11 Deep model training time for different datasets
6 结束语
高校学业文本的命名实体识别可以帮助教辅工作人员快速便捷地提取学生所存在问题的关键信息,缓解教学工作带来的压力,同时也为高校学业领域知识图谱的构建以及智能问答系统的研发奠定了基础,从而实现学生学业困惑的自助检索,并提升精准度和查询效率。本文提出一种高校学业文本命名实体识别数据集的构造方法,针对领域特性结合专家先验知识给出了实体分类标准,并依据该标准仿照公开数据集格式完成分类标注。在确保涵盖内容全面以及实体细粒度划分合理的标准下,共包含8 类实体关系,可应用于高等学校学业领域的命名实体识别任务。
本文首先在公开数据集验证了BiLSTM-CRF 等4种识别模型的有效性,之后通过选用模型证明了所构建的高校学业文本原始数据集可以为命名实体识别任务提供实验数据。各模型在分类标注后数据集上的标注效果,证明了本文提出的分类标准与构造方法具有普遍性与实用性,为构建高校学业领域知识图谱的命名实体识别任务做出了贡献,响应了教育部信息技术与教育教学相融合的号召,为智能化高校教育开展打下了坚实基础。
本文的研究重点放在了高校学业文本命名实体识别的数据集构建方面,且标注范围仅针对学生日常出现的问题以及工作积累的学业问题,可能存在学业领域内细小问题未涉及等情况,未来还需不断细化完善该工作。
