基于SimCC-ShuffleNetV2的轻量化奶牛关键点检测方法
2023-11-23宋怀波华志新马宝玲温毓晨孔祥凤许兴时
宋怀波 华志新 马宝玲 温毓晨 孔祥凤 许兴时
(1.西北农林科技大学机械与电子工程学院, 陕西杨凌 712100;2.农业农村部农业物联网重点实验室, 陕西杨凌 712100)
0 引言
奶牛关键点指奶牛身体部位重要的关节位置,如头部、肩部、腿关节等[1]。关键点相连的骨架作为姿态的最直观体现,可以帮助实现奶牛动作行为的非接触识别,从而为姿态表征的疾病预警提供重要技术支持。同时,关键点检测还是牲畜体尺测量与身体部位分割的前置任务,可为奶牛的体重与体况分析提供更为高效的数据支撑。综上,开展奶牛关键点检测技术的研究和应用,将有助于提高养殖效率和健康水平,具有重要研究价值[2]。
传统关键点检测方法通过人工提取图像或视频中的关键点特征,如关节点之间的空间位置关系等,再通过机器学习算法进行学习和匹配其特征及规律[3]。JIA等[4]通过骨架对奶牛不同身体部位进行划分用以评估其清洁度。该研究在获得奶牛骨架图的过程中采取特征距离变换,细化与特征检测等步骤,然后计算相邻的骨架路径,并与数据库中的模板进行相似度匹配以获得最佳匹配结果,最后确定每个骨骼分支所属的类别后,将身体分为不同部分。结果表明,侧视图与后视图的平均身体部位分割精度分别为96%和91%,为奶牛的分割任务提供了借鉴。但该骨架提取方法受人为设计特征完备性较差、机器学习算法的特征提取和泛化能力较弱的影响,在实际生产过程中难以应用。
随着深度学习的应用,关键点检测技术取得了较多进展。基于卷积神经网络(Convolutional neural networks,CNN)的方法[5]无需手动设计特征,从整幅图像中学习关键点表征,可以实现端对端的检测,具有良好的特征提取能力和泛化能力,常见的关键点检测网络包括Hourglass[6]、 DeepPose[7]、 OpenPose[8]、HRNet[9]等。诸多研究也将深度学习网络应用于奶牛关键点检测中,RUSSELLO等[10]使用T-LEAP姿态估计模型,将LEAP模型修改为时间序列模型,从图像序列中检测关键点从而预估奶牛姿态,试验结果表明,在奶牛目标上的平均正确关键点的预估比例(Percentage of correct keypoints,PCK)为93.8%。同时,奶牛关键点检测是实现体尺测量、动作识别等任务的基础[11]。其中,体尺测量用于评估牲畜体型的大小,体尺关键点检测的准确度直接影响体尺测量的精度。赵宇亮等[12]为了对猪只的5项体尺指标进行非接触式测量,首先在DeepLabCut上选取EfficientNet-b6模型作为最优主干网络进行猪只体尺关键点检测,其测试集误差为5.13像素;在此基础上,通过3D坐标转换实现深度图像上关键点坐标的映射,并对离群特征点进行优化,最后提取体尺曲线进行计算。奶牛关键点连接的骨架是姿态的最直观表征,奶牛的姿态数据可用于统计其基本运动行为时间。LI等[13]为了准确识别奶牛的基本运动行为(走、站、躺),利用HRNet提取奶牛骨架信息,在平行的二维卷积特征中以热图的形式添加对应的奶牛关键点与骨架信息,并选取了400个包含该4种行为的奶牛视频进行训练与测试,结果表明,经过5次交叉验证,最终分类精度为91.80%。
上述关键点检测研究大多基于手工提取,难以实际应用;或者依赖于DeepLabCut[14]平台,泛化性不足,且无法解决多目标间关键点的连接问题。目前基于深度学习的主流算法具备较高的准确率,但其网络复杂程度也较高。为解决上述问题,本研究借鉴ShuffleNetV2模型的轻量化性能及SimCC所具有的高效简单的关键点坐标分类能力,提出SimCC-ShuffleNetV2轻量化模型,以期构建一种实时性强、精度高、鲁棒性强的奶牛关键点检测方法,为奶牛动作识别等研究奠定基础。
1 材料与方法
1.1 材料
本研究视频数据采集于陕西省杨凌科元克隆有限公司,采用DS-2DM1-714型圆顶摄像机(海康威视)进行拍摄,摄像机速率为25 f/s,分辨率为704像素×480像素。如图1所示,摄像机架设于背靠牛棚的长走廊外,目标与摄像机之间的围栏遮挡了一些关键点,会对骨架提取任务造成一定的干扰。
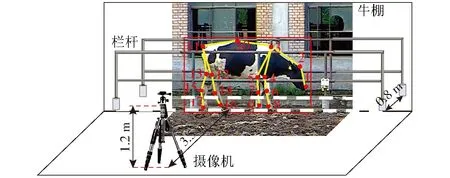
图1 数据采集与标注方式Fig.1 Data collection and annotation methods1.鼻子 2.额头 3.颈根 4.右前腿根 5.左前腿根 6.右前膝 7.左前膝 8.右前蹄 9.左前蹄 10.背部 11.尾根 12.右后腿根 13.左后腿根 14.右后膝 15.左后膝 16.右后蹄 17.左后蹄
如图1所示,本研究以最大的动物姿态数据集AP-10k为参考[15],设计了奶牛关键点及骨架结构。从视频中截取1 800幅图像用于关键点检测任务,为了有效模拟奶牛姿态的变化,采用镜像翻转的方式扩充数据集至3 600幅。标注奶牛的边界框与关键点后将其保存为COCO格式,并按照6∶2∶2的比例分为训练集、验证集和测试集。
由于奶牛动作及姿态变化多样且易受遮挡、光照等因素影响,奶牛关键点检测的准确性不高。为了增强模型的鲁棒性,采集了不同情况的奶牛图像:①正面视角:奶牛朝正面摄像头时,关节位置会产生一定的形变。②关键点缺失:奶牛目标位于图像边缘时,部分关键点会缺失。③躺卧姿态:奶牛在躺卧姿态下,某些关节点会被遮挡。④小目标:拍摄距离较远时会造成奶牛目标在图像中占据的比例较小。训练集和测试集中均包含了各种影响因素下的奶牛图像,且在训练集和测试集中的比例基本保持一致。
1.2 试验平台
试验在Windows 10系统下进行,处理器为Intel(R) Core(TM) i5-11400F,图形处理器为Nvidia RTX2080Ti。深度学习框架为PyTorch,编程平台为PyCharm,编程语言为Python,所有算法均在相同环境下运行。
1.3 总体技术路线
本研究总体技术路线如图2所示,首先将图像送入SimCC-ShuffleNetV2模型,关键点检测过程类似于编解码,ShuffleNetV2用于提取并编码17个关键点表征。SimCC用于对水平轴和垂直轴执行坐标分类,最后解码出关键点坐标。为了验证模型的有效性,将SimCC-ShuffleNetV2应用于行为识别任务。从400段包含4种动作(行走、站立、躺卧、跛行)的视频中提取出骨架信息,并将骨架序列送入ST-GCN(Spatial temporal graph convolutional networks)[16]网络训练,ST-GCN利用时空图卷积来提取骨架序列间的时空信息,并将时空特征融合起来,最后输出动作分类结果。
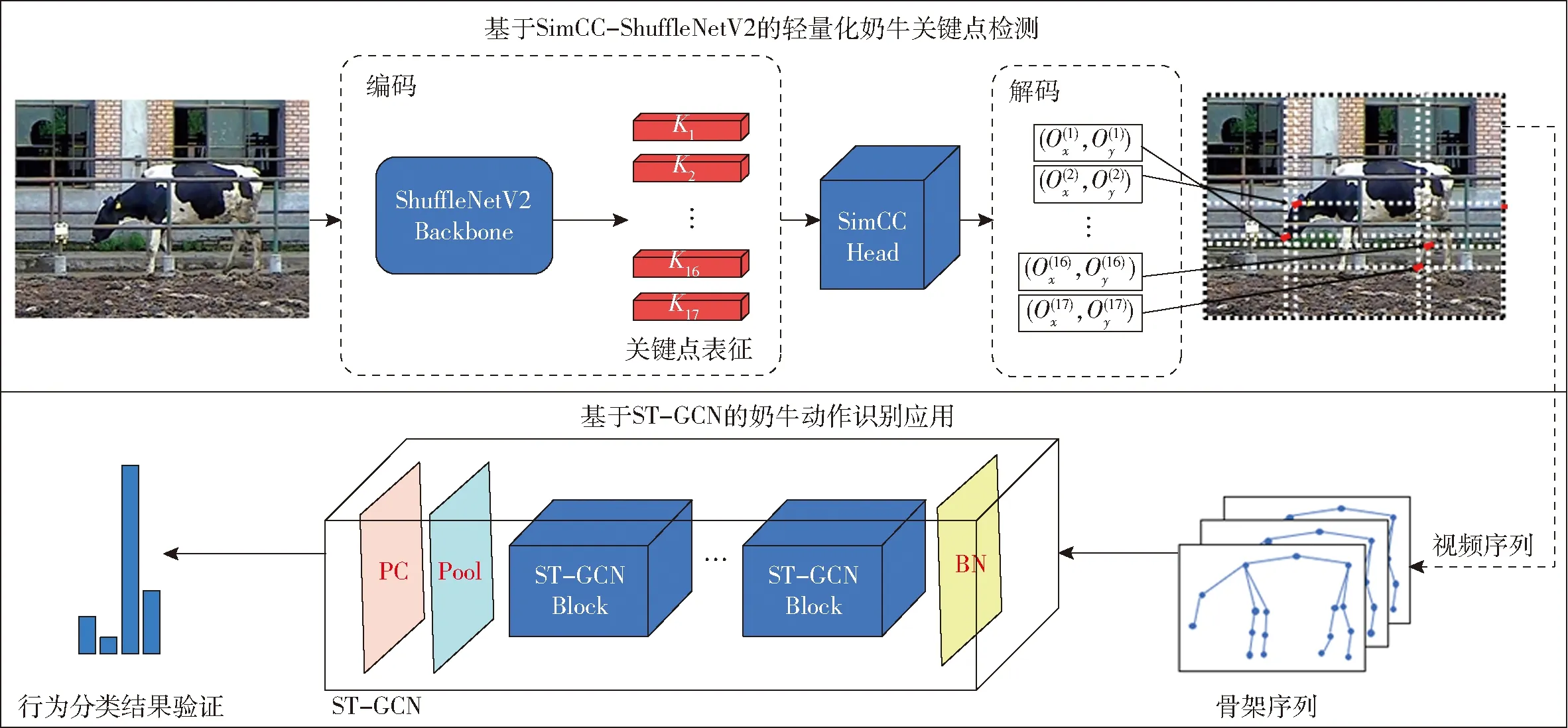
图2 总体技术路线Fig.2 Overview of the proposed method
1.4 ShuffleNetV2网络结构
ShuffleNetV2[17]为主干特征提取网络,结构如图3所示,其中Conv为卷积操作,DWConv(Depthwise convolution)为深度卷积。
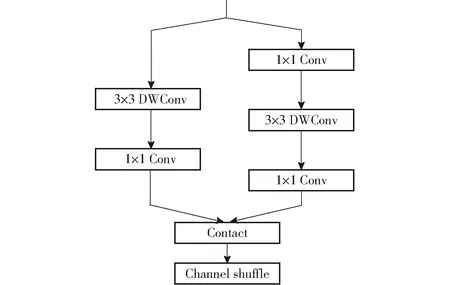
图3 ShuffleNetV2结构Fig.3 Structure of ShuffleNetV2
分组卷积操作让不同的卷积核学习不同的特征,从而提高模型的表达能力。左右分支连接后将输出特征进行通道混洗,从而达到不同通道间信息交换的目的,有利于增加模型的非线性表示能力。上述结构在保持网络准确性的同时,具有更高的计算效率和更小的模型参数,故本研究将其作为主干网络。
1.5 SimCC结构
SimCC[18]在网络中作为检测头,SimCC模块采用坐标分类的思路,将不同坐标值划分为不同类别,从水平与垂直维度将关键点坐标进行分类,从而实现关键点检测,其结构如图4所示。
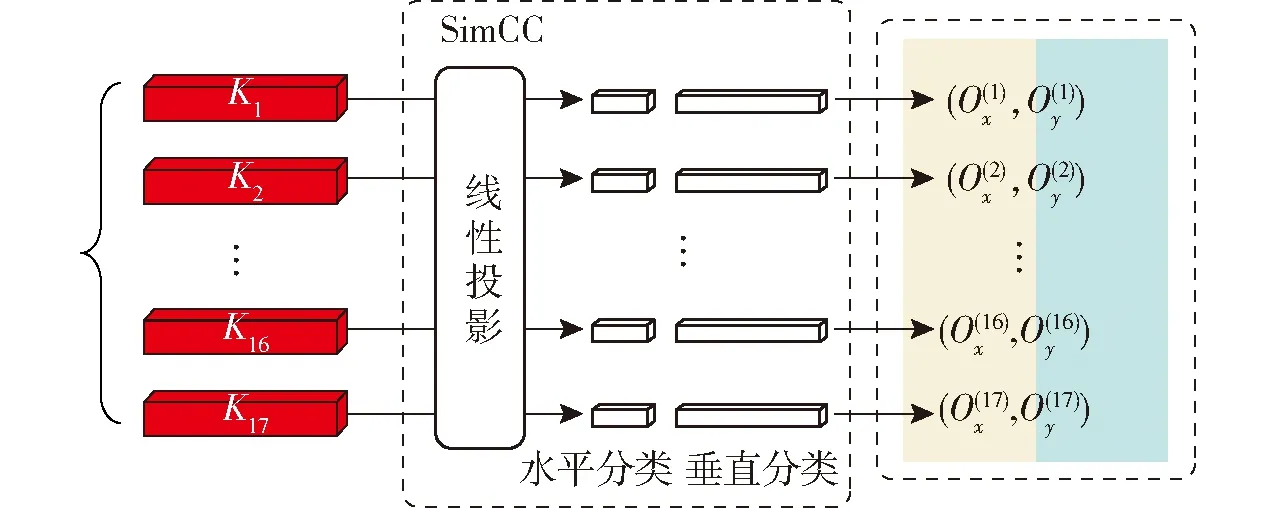
图4 SimCC结构Fig.4 Structure of SimCC
在主干网络提取特征时,关键点由(n,H′,W′)展平至(n,H′×W′),即输出n个关键点的一维向量。再通过线性投影将坐标编码为n个SimCC表征,表征后的坐标可以通过两条独立的一维向量来描述:
p′=(round(xpk),round(ypk))
(1)
式中 round——线性投影
(xp,yp)——表征前的坐标
p′——表征后的坐标
k——缩放因子
经过线性投影后,输出的特征图维数为W×k维和H×k维。缩放因子k(k>1)的作用是使一维向量长度超过图像边长,关键点定位精度增强到亚像素级别。在坐标解码过程中,给定的第p个关键点表征输入至仅一个线性层的水平和垂直坐标分类器。需将坐标还原到图像尺度,要将分类的最大概率所在位置除以缩放因子,计算公式为
(2)
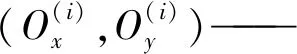
(Ox(i),Oy(i))——解码前的位置坐标
argmax——取最大值操作
与直接基于像素点回归的模型不同,SimCC将定位问题转化为分类问题,可以避免回归模型存在的训练难度高、容易受到噪声和异常值影响等问题,具有更高的精度和鲁棒性。基于热力图的关键点检测方法通过显式地渲染高斯热图,让模型输出目标概率分布。由于特征提取时需要进行多次卷积和下采样操作,通常导致生成的热力图尺寸小于图像原尺寸,因此将坐标映射回原图时会存在不可避免的量化误差。而SimCC采用两个方向上、长度大于原图像尺寸的一维向量对关键点进行表征,坐标表征为数值,精度不受缩放影响,避免了量化误差。
1.6 关键点检测评价指标
OKS(Object keypoint similarity)[19]是一种用于衡量关键点预测值与真实值间相似度的度量指标。计算OKS时要首先提取关键点预测值与真实值间的特征向量,然后使用欧氏距离来计算两个特征向量的相似度,基于这种相似度计算,可以进行关键点的匹配和识别。OKSp的计算公式为
(3)
式中OKSp——第p个目标的OKS
δ——用于选取可见点的计算函数
pi——第p个目标的第i个关键点
dpi——关键点预测值与真实值间的欧氏距离
vpi——关键点的可见性
sp——目标边界框的面积
σi——第i个关键点标注值和实际值间的标准偏差
模型的准确度采用平均精度(Average precision,AP)来衡量,AP值越高,说明模型的准确度越高。OKS类似于目标检测中的交并比(IOU)[20],用于计算关键点检测的AP。当OKS大于给定阈值T时,检测结果视为真阳性,精度(Precision,P)指检测结果真阳性的比例,召回率(Recall,R)指所有真实标注中的关键点被检测到的比例,然后计算PR曲线与坐标轴所围面积即为AP。其中AP50表示OKS阈值为0.50时的AP,AP50:95表示在OKS阈值从0.50到0.95之间,步长为0.05时的平均AP。
此外,本研究所提出的SimCC-ShuffleNetV2为轻量级模型,因此浮点运算量(Floating point operations, FLOPs)、参数量(Params)与检测速度作为重要的轻量化评估指标也纳入评价。浮点运算量的计算方式是将各层参数量乘以输入数据的维度,然后对所有层的结果求和。参数量表示模型中的参数数量,通常用于衡量模型的复杂度和容量。
2 结果与分析
2.1 SimCC-ShuffleNetV2训练结果
本研究中共训练200轮次,网络训练过程损失值与AP50的变化曲线如图5所示。

图5 训练过程Fig.5 Training process
SimCC-ShuffleNetV2的网络参数空间较小且层数较低,训练过程中更容易找到全局或局部最优解,故曲线收敛较快,当迭代次数达到50次左右时,模型学习效果已经达到饱和,关键点损失值稳定在0.15左右,AP50稳定在93%左右。
2.2 关键点检测效果
SimCC-ShuffleNetV2在测试集上的AP50:95为88.07%,AP50为97.76%,参数量为1.31×106,浮点运算量为1.5×108,检测速度为10.87 f/s。不同情况下关键点可视化效果如图6所示,标示出17个关键点并绘制出骨架。奶牛朝向摄像头位于正面视角时,关节位置会产生一定的变化,训练集中此类图像较少,但检测效果同样良好,表明模型的泛化能力较强。奶牛在躺卧姿态下,有些关节点会被遮挡,模型检测时会预测被遮挡关键点的位置,虽然结果有一定偏离,但整体效果依然能准确反映奶牛姿态。在远距离情况下,此时奶牛目标较小,模型依然能准确标示出关键点位置,表明模型对小目标同样敏感。针对上述情况,一般采用尺度变换和多尺度融合技术来提高模型检测的准确性,而SimCC-ShuffleNetV2对正面视角、躺卧姿态与远距离情况下亦能准确检测,表明模型具备良好的性能。

图6 不同情况下的关键点检测效果Fig.6 Keypoint detection effects in different situations
2.3 关键点误检分析
如图7所示,虚线框所指的缺失关键点被错误检测在非奶牛身体部位。模型检测效果较差的可能原因在于,本研究中数据集中包含的此类图像较少,模型可能会过拟合,缺失关键点被误认为是图像中某些类似的局部特征。此外,当奶牛关键点缺失时造成的姿态约束条件、关节角度等先验信息缺失也可能会导致模型误判。

图7 关键点误检Fig.7 Error detection of keypoint
3 结果与讨论
3.1 不同关键点检测算法性能比较
为了评估SimCC-ShuffleNetV2模型对奶牛关键点检测的性能,在相同条件下,分别基于DeepPose、HRNet两种经典关键点检测算法对同一数据集进行训练,其中DeepPose为直接基于回归的模型,HRNet为基于热力图的模型。采用AP50:95、浮点运算量、参数量与检测速度对训练完成后的模型进行评估。3种检测算法的性能指标如表1所示。对比其结果可知,SimCC-ShuffleNetV2的AP分别比DeepPose和HRNet提高23.65、2.16个百分点。检测速度比DeepPose减少7.44 f/s,比HRNet提高4.78 f/s。其参数量分别比DeepPose和HRNet减少2.23×107和2.72×107,浮点运算量分别减少 8.93×109、1.718×1010。DeepPose直接基于回归方式无需过多后处理且主干网络为结构简单的Alexnet[21],故检测速度较快。但同时Alexnet的学习能力有限,而且直接在图像像素点中回归坐标较为困难,故精度较低。HRNet能一直保持高分辨率的表征,生成的热力图尺寸也为高分辨率,预测的关键点在空间上更精确。但由于其复杂的网络结构带来了巨大计算量从而导致检测速度较慢。而SimCC-ShuffleNetV2在拥有最高准确度的同时有较快的检测速度,实现了精度与速度的良好平衡。

表1 不同关键点检测算法性能比较Tab.1 Comparison of different keypoint detection models
3.2 不同主干网络性能比较
主干网络是用于特征提取的主要组件,为了对比不同主干网络对模型性能的影响,保持SimCC为检测头,分别测试以Res-50[22]、ResNeSt-50[23]、MobileNetV2[24]作为主干网络的模型性能。如表2所示,ShuffleNetV2为主干网络时的AP分别比Res-50、ResNeSt-50和MobileNetV2提高1.96、3.87、3.16个百分点,检测速度分别提高5.14、4.19、3.05 f/s;参数量分别比Res-50、ResNeSt-50和MobileNetV2减少3.54×107、3.74×107、9.8×105,浮点运算量分别少5.36×109、6.63×109、1.60×108。ShuffleNetV2为主干网络时,AP最高,浮点运算量与参数量最小,检测速度最快,说明ShuffleNetV2能在保持与更大网络相同精度的前提下,还能有更小的模型体积和浮点运算量。且对比同为轻量化网络的MobileNetV2,同样有更出色的性能与速度。
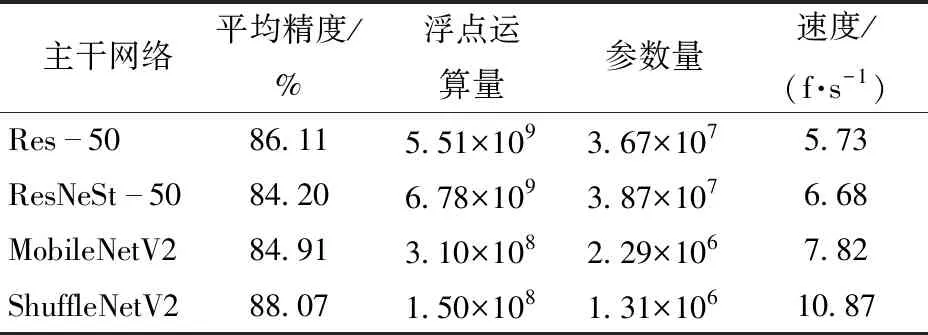
表2 不同主干网络性能比较Tab.2 Comparison of different backbones
3.3 不同检测头性能比较
为了评估不同检测头对模型性能的影响,保持ShuffleNetV2为主干网络,对比测试了以热力图为检测头的模型。其结果如表3所示,SimCC作检测头时比以热力图作为检测头时的AP提高2.03个百分点,检测速度提高3.97 f/s;参数量减少6.24×106,浮点运算量减少1.22×109。此外,在SimCC检测头的浮点运算量为3×106,参数量为5.6×104,相较于整体模型,其浮点运算量与参数量可忽略不计。而基于热力图的检测头的浮点运算量为1.24×109,在整个模型中占比为90.8%;参数量为6.29×106,在整个模型中占比为83.3%,基于热力图的检测头占据了网络大部分的浮点运算量与参数量,导致模型检测速度较低。

表3 不同检测头的性能比较Tab.3 Comparison with Heatmap-based method
如图8所示,热力图表征图像中每一个关键点的概率分布。热力图由图像进行卷积和池化操作得到,需要大量的计算成本和内存开销[25]。SimCC作为检测头无需高分辨的热力图即可实现良好的检测效果,将关键点检测问题转换为分类问题从而降低了计算成本和内存开销,可大幅提高模型的计算速度。

图8 热力图表征Fig.8 Heatmap representation
3.4 基于ST-GCN的奶牛动作识别应用
为了验证SimCC-ShuffleNetV2的有效性,将模型用于奶牛运动视频中提取出骨架序列,并送入ST-GCN网络以实现动作识别。人工筛选了400段视频作为动作识别的数据,每段时长约为(10±4)s,如图9所示,动作行为包含躺卧、站立、行走、跛行(每种动作100段视频)。

图9 不同动作行为Fig.9 Different actions
如图10所示,ST-GCN是基于骨架序列的动作识别方法,其中Attention(Spatial attention)为空间注意力机制,GCN(Graph convolutional network)为图卷积网络,TCN(Temporal convolutional network)为时间卷积网络。该模型使用图卷积神经网络处理骨架视频序列,然后使用CNN提取特征,最后通过分类器选取具有最高概率的类别。分类准确率是衡量ST-GCN效果的主要指标,即正确预测视频样本占视频样本总数的百分比。
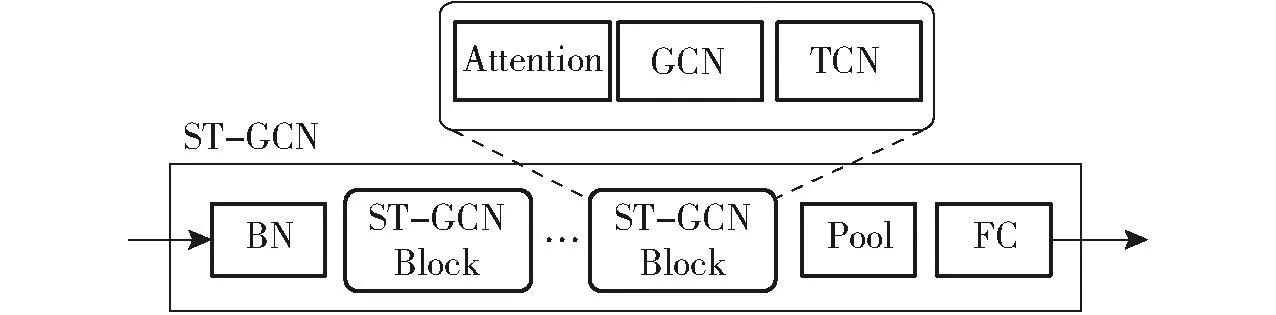
图10 ST-GCN结构Fig.10 Structure of ST-GCN
如图11所示,动作分类结果标示在视频左上角,ST-GCN能对不同的动作进行有效的区分。同时SimCC-ShuffleNetV2提取的骨架序列送入训练后,ST-GCN在测试集上的分类准确率为84.56%。表明SimCC-ShuffleNetV2能良好地表征奶牛的姿态以供ST-GCN网络学习。

图11 动作识别效果Fig.11 Action detection effects
4 结论
(1)ShuffleNetV2作为轻量化网络,其特有结构能保持与大模型相当精度的同时更加轻量,有利于实现高效的特征提取,更加适合于实际应用场景。
(2)SimCC将关键点检测问题转换为分类问题,从而降低了问题的复杂度,更加简单和高效。相较于基于回归的方式,模型精度更高;相较于基于热力图的方式,模型能在保持相当精度的情况下更加轻量。
(3)ST-GCN的分类准确率达到了84.56%,表明SimCC-ShuffleNetV2是良好的关键点提取器,在动作识别任务中有良好的应用前景。
