基于Transformer方法的任意风格迁移策略
2023-11-22孙梅婷代龙泉唐金辉
孙梅婷,代龙泉,唐金辉
南京理工大学计算机科学与工程学院,南京 210094
0 引言
任意风格迁移技术(arbitrary style transfer)旨在寻求一种通用的风格转换方法,对于给定的任意一幅风格图像,都能依据其样式特点对内容图像进行渲染,生成同时具备内容图像语义结构和风格图像样式纹理的艺术化合成图像。风格迁移作为图像处理领域的重要分支,广泛应用于日常生活中的照片和视频处理软件中,为用户提供多种多样的视觉效果,而任意风格迁移方向提高了风格迁移技术的通用性和灵活性,因此受到广泛关注。
在风格迁移研究中,物体、结构和语义被广泛视为图像的内容表示,颜色、纹理和笔触被广泛视为图像的风格表示。因此,传统风格迁移技术(Haeberli,1990;Hertzmann,1998;Efros 和Freeman,2001;Hertzmann 等,2001;Winnemöller 等,2006)通过对纹理、线条等图像低级信息进行抽象处理来实现图像的艺术化转变。虽然有一定的风格化成果,但是因为只利用了图像的表征信息,缺乏整体语义的思考,因此存在视觉效果不佳、处理时间长等不足。
随着深度学习在各个领域开花结果,神经风格迁移(neural style transfer)方法应运而生,利用卷积神经网络(convolutional neural network,CNN)自适应提取图像特征,能够更好地建模图像的内容和风格表征。Gatys 等人(2016)首次将卷积神经网络应用到风格迁移任务中,将网络提取的图像特征视为内容表示,将特征间的相关性视为风格表示,通过分离与重组,融合内容图像和风格图像,虽然能够产生良好的风格效果,但是其中用到的图像迭代优化过程存在风格化速度慢、耗时长等弊端。考虑到生成对抗网络(generative adversarial networks,GAN)(Goodfellow等,2014)优秀的图像生成能力,一些工作(Zhu等,2017;Chen 等,2018;Hicsonmez 等,2020;Kotovenko 等,2019)将GAN 应用于风格迁移领域,通过训练网络模型,实现快速风格化。尽管这类方法提高了风格化速率,同时能够生成栩栩如生的风格化图像,但其网络模型受限于GAN 网络框架,只能实现有限风格种类的渲染效果,缺乏灵活性,如果要应用于不同风格则需要对每一种风格单独训练一个模型,增加了训练成本。得益于条件生成网络(conditional adversarial network,cGAN)(Mirza 和Osindero,2014)的出现,Yanai(2017)使用条件网络直接从风格图像中生成条件信号,控制网络生成的风格,实现了任意风格的转换。
GAN 中的判别器学习分辨特定类别图像的真实性,在一定程度上约束了生成图像风格的多样性。为了提高生成网络的灵活性,实现任意的艺术化风格转换效果,后续工作更加关注图像的编码—转换—解码过程,旨在寻求能够更好地分离、融合内容信息与风格信息的方法。任意风格迁移方法中,在内容图像中引入风格信息的主要手段可以大致分为基于统计信息和基于图像块两种。前者使用图像分布统计数值表示风格信息(Huang 和Belongie,2017;Li等,2017;Luan 等,2017;Wang 等,2020;Xie 等,2020),如均值、方差和协方差等,通过整体调整内容图像的分布,使其符合风格图像数据分布,从而获得与风格图像相同的样式特征。后者将图像划分为图像块,用图像块作为风格特征的表示(Chen 和Schmidt,2016;Sheng 等,2018),通过将风格图像块替换到内容图像中,使得内容图像具备风格图像的纹理表征。
CNN 作为风格迁移领域中使用的主流网络框架,能够有效提取图像的内容特征和风格特征,但是卷积操作限制了网络的感受野范围,不利于图像全局信息的捕获,若需要获取更大范围的感受野,则需要堆叠更深的网络层,不利于网络训练。而Transformer(Vaswani 等,2017)恰好能弥补卷积网络的不足。Transformer网络结构最早在自然语言处理领域(natural language processing,NLP)的机器翻译任务中提出,它的网络主体结构由注意力网络层堆叠而成,这使得它可以轻松捕获句子中单词间存在的长距离依赖关系,加深网络对每个单词的理解,提高句子翻译的合理性和准确性。通过抽象句子翻译过程,可以发现基于图像块的风格迁移方法与句子翻译任务有异曲同工之处。句子翻译过程可以看做是单词到单词的转换过程,而基于图像块的风格迁移过程可以视为图像块到图像块(特征到特征)的替换问题,如图1 所示。句子可以表示为由单词构成的序列,则句子翻译过程即为依据输入的单词序列信息预测输出单词的过程;依此思路,将图像按固定尺寸划分,则图像可以表示成由图像块构成的序列,每次从风格图像块序列中选择合适的风格图像块替换内容图像序列中对应的内容图像块,将内容图像块序列中所有的图像块都替换完毕后得到风格化图像块序列,将序列重新排列后获得最终的风格化图像。

图1 句子翻译和基于图像块的风格迁移之间的相似性Fig.1 Similarity between sentence translation and patch-based style transfer((a)sentence translation:word-to-word translation;(b)style transfer:patch-to-patch translation)
依据上述分析,将Transformer 应用于风格迁移任务是合理的和可行的。但是,直接使用Transformer 完成全部的图像处理任务,仍存在一些问题。1)Transformer 缺乏归纳偏置(inductive bias),难以获取图像先验信息,因此在训练中收敛速度较慢;2)缺乏有效的特征提取手段;3)图像相较于句子,序列长度更长,导致注意力网络层计算消耗更大。而卷积网络能够弥补Transformer 存在的不足,因此将二者结合能更好地实现风格迁移效果。综上所述,本文主要贡献包括以下几点:1)提出一个用于任意风格迁移任务的混合网络,同时结合CNN 和Transformer网络优势,使用卷积操作提取图像特征,提供图像先验知识,便于局部信息的融合;使用Transformer捕获特征间的内在联系,丰富特征表示,提供全局信息交互能力;2)引入判别网络,更好地度量生成的风格化图像和现实中真实风格图像间的差异,减少不合理纹理的产生,提升画面渲染的光滑度;3)通过与其他任意风格迁移方法进行定性和定量比较,表明本文网络能够生成画面更光滑、真实性更高、风格特征更明显的高质量风格化图像。
1 相关工作
鉴于CNN 能够建模复杂的、手工设计难以捕获和表示的图像特征,已经广泛用做图像处理任务中的编码和解码网络。图像输入编码网络中提取特征,特征经由转换网络生成风格化特征,风格化特征再输入到解码网络中得到最终的风格化图像,这种编码—转换—解码的处理流程是任意风格迁移任务中常使用的网络框架。
在结构丰富多样的CNN 中,预训练的VGG(Visual Geometry Group)网 络(Simonyan 和Zisserman,2015)是任意风格迁移方法中常见的编码网络结构。它作为特征提取器,为网络提供可靠的图像特征提取能力,同时因为其本身已经具备良好的学习能力,所以在网络训练过程中,它可以指导网络其他部分的学习,稳定网络的训练过程,加速网络模型的收敛。不同于直接引入VGG 网络的方法(Huang和Belongie,2017;Li 等,2017;Luan 等,2018;Park 和Lee,2019;Yao 等,2019;Wang 等,2020;Chen 等,2021a;Deng 等,2021),Sheng 等人(2018)综合考虑网络编码与解码过程,在VGG 网络结构中增添中间链接结构,将提取的特征信息引入到图像解码过程中,增强了解码网络的稳定性与图像重建能力。Chen 和Schmidt(2016)分别在图像空间与特征空间进行风格迁移实验,表明直接对图像进行处理生成的风格化结果,虽然有颜色的改变,但是风格特征并不明显;而在特征空间进行处理生成的风格化结果具备更加优越的风格特征,说明在任意风格迁移任务中,使用CNN表示图像复杂信息是必要的。
除了CNN,本文还使用了其他理论知识和关键技术。
1.1 判别网络
网络训练时,由于人力与物力的局限,有时难以收集明确的标签数据集,Goodfellow等人(2014)提出GAN 网络,在其中使用判别网络分辨生成结果的真实性,以此促使生成网络提升图像生成能力。
在有限风格种类迁移中,Chen 等人(2018)提出了专门用于图像卡通化的网络结构,促使生成图像具备卡通图像高度简化、边缘清晰和色彩平滑的特点。Kotovenko 等人(2019)通过在内容图像与风格样本中寻找相似语义内容,使网络学习特定风格是如何改变内容细节的,从而提高网络对其他内容对象的渲染质量。Hicsonmez 等人(2020)则将图像的形态特征和边缘轮廓等低级信息引入风格转换过程中,协助网络更好地保留内容,实现插图类型图像的生成。
在任意风格种类迁移中,Chen 等人(2021a)使用判别网络分辨真实风格图像和虚假的生成图像,提高了风格化图像中颜色渲染的和谐性与纹理样式的合理性。
1.2 注意力机制
注意力机制(attention mechanism)即对观察事物的不同部分倾注不同程度的关注,依此方式过滤冗杂信息,保留关键信息。在人类日常生活中,注意力协助大脑快速、高效地处理海量信息,加快反应速度,辅助关键信息记忆。为了使神经网络学习数据间存在的关联性,提高数据处理能力,有些工作引入了注意力机制。
在计算机视觉领域,Lee 等人(2019)应用注意力调整风格权重,使网络关注重要的风格特征,提高卷积神经网络的表示能力。Fu 等人(2019)利用注意力建模全局信息的能力,同时捕获特征在空间和通道维度的上下文关系,生成了更精确的图像分割结果。Zhang 等人(2019)将自注意力融入GAN 网络,与卷积操作相辅相成,实现长距离、多尺度建模。
在风格迁移领域,注意力机制能够帮助网络关注内容图像的主要语义结构和风格图像的关键纹理笔触。Park和Lee(2019)提出风格注意力网络,将内容特征表示为风格特征的加权和,灵活且有效地融合了风格信息。为了丰富生成图像中风格笔触的多样性,Yao等人(2019)使用K-means方法将内容特征聚类分区,并用注意力捕获分区间依赖关系,指导不同尺度特征的融合过程。Deng 等人(2020)在内容图像上使用空间注意力增强内容表征,在风格图像上使用通道注意力增强风格表征,自适应地分离内容和风格特征,从而生成语义化渲染效果。
注意力机制协助网络使用主要风格特征绘制主要内容结构,实现语义感知的风格化渲染效果。
1.3 Transformer
图像可以看做由像素点构成的“句子”,相较于卷积操作需要堆叠多层卷积层来获得更大感受野内像素间的依赖关系,Transformer 能够更方便地建模长距离依赖,因此越来越多的研究人员探索将Transformer应用在图像处理任务中(刘花成 等,2022)。
Transformer 遵循编码—解码的网络结构,整体结构如图2 所示。网络由多头注意力网络层(multihead self-attention,MSA)、前向网络层(feed-forward network,FFN)和层标准化网络层(layer normalization,LN)构成。图2 中的l符号表示编码层和解码层的层数,Add 符号表示相加操作,Embedding 网络层将序列映射到更高维度。Vaswani 等人(2017)介绍了Transformer网络的具体实现细节。

图2 Transformer网络结构Fig.2 Network architecture of Transformer
在分类、分割和检测任务中,Dosovitskiy 等人(2021)将图像划分为固定大小的图像块,构造与句子类似的序列化数据,输入Transformer 编码器处理后,得到图像分类结果。Liu等人(2021)以滑动窗口形式计算图像的局部注意力,降低网络计算量。
在图像生成、超分辨率等需要生成图像的任务中,Parmar 等人(2018)将图像生成任务视为像素点回归任务,搭建Image Transformer 网络,以逐像素预测的方式生成图像。Esser 等人(2021)将Transformer优秀的表达能力与CNN 自带的归纳偏置相结合,实现高分辨率图像合成结果。上述两种方法均以回归方式生成图像,前者使用像素,后者使用特征,因为需要逐个预测,因此生成速度较慢。
Chen 等人(2021b)使用卷积网络处理图像,使用Transformer处理特征,在超分辨率、去雨和去噪等图像处理任务上均取得了优异成果。Jiang 等人(2021)使用Transformer网络结构搭建了第一个没有卷积操作的生成对抗网络TransGAN,使用数据增强、多任务联合训练和局部注意力初始化等策略,增强图像块间连接的光滑度。可以看出,没有卷积网络的辅助,则需要更多的策略辅助网络训练。
尽管Transformer在图像处理任务中得到了广泛关注,但是将其应用于任意风格迁移领域的研究屈指可数。鉴于风格迁移过程与句子翻译过程的相似性,引入Transformer实现特征转换,有助于为风格迁移领域注入新的活力。
2 研究方法
为了挖掘Transformer 在任意风格迁移领域的潜力,本文提出了融合Transformer 网络结构的任意风格迁移网络,将从网络结构和损失函数两方面对其进行详细介绍,同时为了便于读者理解本文方法与Transformer 网络结构之间存在的联系,Transformer 相关网络层符号表示均与1.3 节保持一致。
2.1 网络结构
图3 展示了提出的任意风格迁移网络的整体结构,该网络输入内容图像Ic和风格图像Is,输出风格化图像Ics。网络整体遵循对抗生成网络框架,图中生成网络G负责学习生成高质量的风格化图像,判别网络D则负责学习判断输入是否为真实风格图像。

图3 基于Transformer的任意风格迁移网络结构Fig.3 Network architecture for Transformer-based arbitrary style transfer
生成网络G由3 部分构成,分别为图像编码网络、风格转换网络和图像解码网络,在图3 中分别以Enc、T和Dec表示。图像的风格化过程如下:
首先,将内容图像Ic和风格图像Is输入编码网络Enc中,提取内容特征fc和风格特征fs,具体为
随后,将fc和fs输入风格转换网络T 中,依据二者元素间的相关性,将内容特征替换为对应的风格特征,得到风格化特征fcs,具体为
最后,风格化特征fcs经由解码网络Dec 解码回图像域,生成风格化图像Ics,具体为
上述生成过程为常见的编码—转换—解码风格迁移方式,为了促使生成网络生成更加真实的艺术化结果,增添一个判别网络,度量生成的风格化图像与真实风格图像间的分布差异,拉近二者的距离。判别网络D在训练过程中,学习为真实风格图像分类标签1(real),为生成的风格化图像分类标签0(fake),即
2.1.1 图像编码网络
卷积网络种类众多,鉴于风格迁移任务不仅需要图像深层信息理解内容语义结构,而且需要图像浅层信息辅助风格纹理笔触的表现,因此使用残差网络(He等,2016)作为编码网络,同时将网络中第1层7 × 7大小的卷积核改为3 × 3,保留更多的线条纹理细节。因为风格转换网络中用到了Transformer网络结构,为了降低网络中注意力网络层的计算量,在残差网络块中使用平均池化层,降低图像尺寸。平均池化层缩放因子设置为2,设训练时输入图像宽高为2x像素,编码出来的特征宽高固定为2y像素,则编码网络中包含的残差块有x-y层。
将内容图像Ic∈R3×H×W和风格图像Is∈R3×H×W输入编码网络中,生成尺寸较小的内容特征fc∈Rc×h×w和风格特征fs∈Rc×h×w。其中,H和W分别表示图像的高度和宽度,c,h和w分别表示提取特征的通道数、高度和宽度,H=W=2x,h=w=2y。
2.1.2 风格转换网络
原始Transformer网络包含编码器和解码器两部分,编码器建模句子单词间的关联性,解码器部分依据编码器编码结果及之前输出的单词,预测当前位置单词的概率分布。依据解码部分的特点,可以将其视为基于块替换的风格迁移方法,即依据风格特征,替换内容特征。该部分网络尽量遵循原始Transformer 结构(Vaswani 等,2017),考虑到风格迁移的输入为两幅图像,为了使网络更好地学习内容图像和风格图像的特点,在原始Transformer 结构的基础上额外增加一个编码器,构成一个由两个编码器和一个解码器组成的风格转换网络。两个编码器为内容编码器CTE(content Transformer encoder)和风格编码器STE(style Transformer encoder),解码器用TD(Transformer decoder)表示,转换网络结构如图4所示。

图4 风格转换网络结构Fig.4 The style transformation network structure
风格转换网络接收内容特征fc和风格特征fs作为其输入,输出风格化特征fcs∈Rc×h×w。网络中的unfold 操作使用高度和宽度为P的滑动窗口在特征上以步长P进行滑动,滑动过程中将窗口内所有数据合并在通道维度上,将输入的特征展开为特征序列的形式。经过unfold 操作处理后,得到内容特征序列fc→seq∈Rc′×L和风格特征序列fs→seq∈Rc′×L,其中,c′=c×P2为特征块编码长度,L=hw∕P2为序列长度。
为了利用序列中蕴含的特征顺序信息,分别为内容特征序列添加内容位置编码posc,为风格特征序列添加风格位置编码poss,其中位置编码与序列形状相同,便于二者相加。添加位置信息后将内容特征序列fc→seq输入内容编码器CTE中处理,将风格特征序列fs→seq输入风格编码器STE 中处理,得到内容编码器的输出fcmemory和风格编码器的输出fsmemory,上述过程具体表示为
将内容编码器和风格编码器输出的fcmemory和fsmemory作为解码器TD的输入,求取风格化特征序列fcs→seq,具体为
依靠解码器中第2 层注意力网络层MSA(multihead self-attention)可以达到引入风格信息的目的,该过程可表示为
式中,Qc为内容信息,来自,Ks和Vs均为风格信息,来自。Vaswani 等人(2017)具体介绍了MSA注意力操作,该过程可理解为求取内容信息Qc和风格信息Ks间的相关性,使用softmax 激活函数将二者的相关性转换为权重值,将权重值与风格信息Vs相乘得到应引入的风格信息量,最后将内容信息Qc加上风格信息量,得到同时具有内容信息和风格信息的Qcs。Qcs为fcs→seq中的信息。
使用合并操作fold 将风格化特征序列fcs→seq调整回图像的排列形式,得到风格化特征fcs∈Rc×h×w,其形状与输入的内容特征相同,便于后续图像解码网络结构的设计与实现。
2.1.3 图像解码网络
解码网络同样由残差网络块搭建而成,与编码网络相反,解码网络需要将尺寸较小的特征上采样到原始图像的大小,因此在该部分残差块中使用最近邻插值操作成倍增加特征尺寸。解码网络结构与编码网络结构对称,便于网络学习对称的映射关系。
将风格转换网络输出的风格化特征fcs输入解码网络中,生成风格化图像Ics,。其中,Ics∈R3×H×W与原始内容图像Ic尺寸相同。
2.1.4 判别网络
通常,任意风格迁移任务只由生成网络组成,使用风格损失函数约束生成的风格化效果。然而在实际中,使用数据分布表示风格信息的方式,对风格特点进行抽象和量化,可能会损失一些分布无法建模的风格特征信息。为了更好地度量生成的风格化图像和现实中真实风格图像间的差异,本文引入一个判别网络,学习分辨真实和虚假的风格图像,从而督促生成网络生成更加栩栩如生、贴近现实的艺术化图像。
判别网络遵循Chen 等人(2021a)工作中的设置,由3 个判别器组成,分别分辨原始图像尺寸、1∕2图像尺寸和1∕4 图像尺寸下输入图像的真实性。通过综合不同视野范围下的判别结果,强化网络的判别能力,实现多尺度风格差异度量。
2.2 损失函数
风格迁移的目的是在保证内容图像结构轮廓的前提下,使其具有与风格图像相同的色调和笔触,因此,使用内容损失函数和风格损失函数对生成结果进行约束。
使用感知内容损失(Johnson 等,2016)约束生成图像中的结构保留效果,该损失在高维空间中度量特征间的差异,能够在保留语义信息的情况下,为结构轮廓提供合理的风格形变,其定义为
式中,φi(·)表示预训练VGG-19 网络(Simonyan 和Zisserman,2015)中Relui-1层提取的特征(·)表示特征的均值—方差标准化版本,使用标准化版本是为了降低风格信息的影响。
风格损失定义为
式中,μ(·)和σ(·)表示特征的均值和方差,N为使用的网络层数量,在本文中设置为5,即在多尺度特征上约束生成图像的风格分布。
任意风格迁移过程是无监督网络训练过程,因为缺少明确真值图像的强力约束,所以只能将风格信息建模为均值—方差的分布来约束风格化效果。这种风格损失考虑了图像整体风格分布情况,但是缺乏对局部纹理细节、笔触的考量。因此,本文引入一个判别网络,协助分辨人眼观察不到的风格特征和风格分布难以表示的细节。判别网络带来的对抗损失函数定义为
式中,G(Ic,Is)=Dec(T(Enc(Ic),Enc(Is))),表示生成图像,D为判别器,判别输入的图像是真实的还是网络生成的,E为期望,C和S分别表示内容图像和风格图像的集合,有Ic∈C,Is∈S。判别网络通过与生成网络进行对抗训练,学习更能分辨风格信息的关键图像特征;生成网络为了迷惑判别网络,学习生成更接近真实图像的艺术化结果。
网络的总损失函数由内容损失、风格损失和对抗损失组成,即
式中,λc,λs和λadv分别表示内容损失权重、风格损失权重和对抗损失权重。
3 实验与分析
3.1 实验设置
本文网络基于PyTorch深度学习框架搭建,使用的内容数据集为MS-COCO(Microsoft common objects in context),风格数据集为WikiArt(WikiArt dataset),每个数据集均包含大约80 000 幅训练图像。在网络训练阶段,输入图像统一裁剪为256 ×256 像素。网络学习率设置为0.000 1,使用两个Adam优化器分别对生成网络和判别网络进行优化,前者参数设置β1=0.9和β2=0.999,后者参数设置为β1=0.5和β2=0.999。风格转换网络中,网络层数l设置为6。总损失函数中,权重参数λc、λs和λadv均设置为1。
3.2 实验结果
从定性和定量两方面对提出的任意风格迁移方法进行分析与比较,并进行消融实验,验证引入判别网络的必要性。
3.2.1 风格化效果比较
与5 个先进的任意风格迁移方法进行比较,包括AdaIN(adaptive instance normalization)(Huang 和Belongie,2017)、WCT(whitening and coloring transforms)(Li 等,2017)、SANET(style-attentional network)(Park 和Lee,2019)、AAMS(attention-aware multi-stroke)(Yao 等,2019)和A-Net(Avatar-Net)(Sheng 等,2018),图5 展示了各方法生成的风格化图像。

图5 与现有任意风格迁移方法生成效果进行比较Fig.5 Comparison the generated results with existing arbitrary style transfer methods((a)content images;(b)style images;(c)AdaIN;(d)WCT;(e)SANET;(f)AAMS;(g)A-Net;(h)ours)
图5(a)和图5(b)分别为内容图像和风格图像,剩余依次为各任意风格迁移方法生成的结果。画家作品拥有繁复多样的色彩、笔触等纹理信息,AdaIN整体调整内容特征分布实现风格渲染,能够保留较好的结构轮廓,但是因为简化了风格信息的表示,所以生成结果风格特点不够明显,如图5(c)所示。WCT 通过修改特征2 维统计信息实现风格化效果,能更好地捕获风格特点,但是在高维空间调整风格,图像的内容特征也更容易受到影响,如图5(d)所示,图像的结构发生了形变。直接使用风格图像块替换内容图像块能更好地引入风格笔触纹理,SANET 使用注意力将内容特征块替换为风格特征块的加权和,生成结果较好地保留了结构和样式信息,但同时引入了不合理的风格内容结构,如图5(e)第1行图像中嘴巴部分。AAMS绘制多笔触风格化图像,画面整体较为平滑,但是受到区域聚类操作效果的影响,生成图像轮廓不够清晰,同时图像中主体细粒度笔触在背景粗粒度笔触的映衬下略显突兀,如图5(f)所示。A-Net生成的图像较好地保留了风格特点,但是其结果依赖于纹理块划分的大小,当输入图像尺寸较小时,生成结果中内容轮廓有些难以分辨。与AdaIN 和WCT 相比,本文网络基于块替换方法,能更好地融合风格图像的样式特征,如图5(h)所示,生成的风格化图像与风格图像拥有相似的色彩表现。加之本文使用判别网络分辨风格图像的真实性,拉近了生成结果与真实风格图像间的距离,提高了生成图像的光滑和细腻程度,如图5(h)第1 行人像所示,线条流畅,脸部区域干净,无其他多余纹理,还有第4、5 行图像的背景部分,都绘制得更加清爽,更好地突出了画面中的主体。
3.2.2 用户调查
通过用户调查,观察用户更喜欢哪一种任意风格迁移方法生成的风格化图像。随机选取网络生成的15 幅风格化图像构建调查问卷,问卷中使用的图像为256 × 256 像素。要求参与调查的用户综合考虑内容和风格因素,在每题中选择他们最喜欢的风格化图像,调查结果如图6所示。
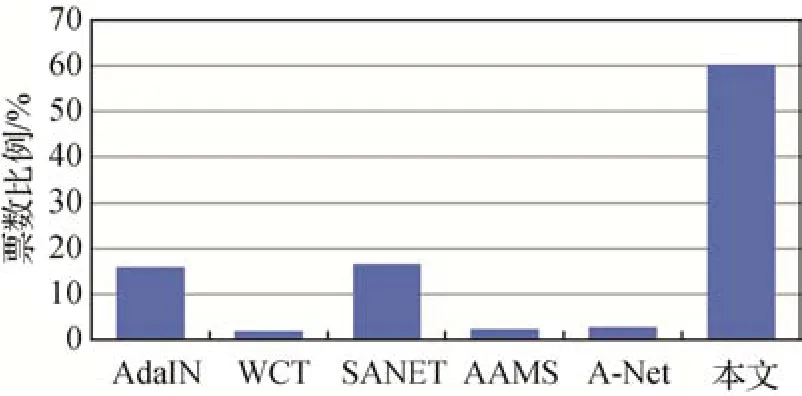
图6 用户调查结果Fig.6 Survey results of users
3.2.3 速度比较
表1展示了各个任意风格迁移方法在256 × 256像素和512 × 512 像素图像上进行风格化处理的平均时间。

表1 风格化速度比较Table 1 Execution time comparison /s
所有方法模型均在相同实验环境下运行,表1中结果为使用单张NVIDIA RTX A6000 GPU 运行400 次风格迁移过程求取的平均风格化速率。本文方法相较AdaIN 和SANET 速度慢了5~8倍,但是相较于WCT、AAMS 和A-Net 方法风格化速度更快,因此,本文网络的风格化速率整体属于可接受范围内。当图像尺寸增至512 × 512 像素时,风格化速度变化不大,表明了本文网络的稳定性。
3.2.4 与基于Transformer的风格迁移方法比较
Deng 等人(2022)使用Transformer 网络捕获图像全局信息,解决内容信息泄露问题,同时提出更适用于图像风格迁移任务的内容感知位置编码(content-aware positional encoding,CAPE)方法,使得在图像尺寸变化时位置编码信息不变。本文方法与其不同之处在于:1)本文编、解码网络使用残差结构,引入图像低级纹理信息,增强图像特征的表示能力;2)本文编、解码网络一同训练,使编码网络学习提取适合风格迁移的图像特征;3)本文使用判别网络度量生成图像,依此提高生成图像的真实性。
本文与Deng等人(2022)在256像素图像上的风格迁移效果如图7 所示。可以看到,Deng 等人(2022)方法生成图像的纹理细节丰富、背景干净;本文方法生成图像具有风格图像的绘制笔触,如图7(c)第1 行的图像,具有油画质感,但是过多的笔触造成背景有些杂乱。

图7 与Deng等人(2022)方法进行比较Fig.7 Compare with Deng et al.(2022)((a)content images;(b)style images;(c)ours;(d)Deng et al.,(2022))
3.3 消融实验
本文设计消融实验以验证判别网络的有效性,实验结果如图8所示。

图8 比较有无判别网络生成的风格化图像效果Fig.8 Compare the performance of stylized images generated with and without discriminative networks((a)content images;(b)style images;(c)without discriminative networks;(d)with discriminative networks)
1)配置1。去掉判别网络后,网络训练的基本配置包括内容损失函数和风格损失函数。从图8(c)的风格化效果来看,生成图像保留了良好的内容结构,这得益于网络中残差结构引入了浅层表征信息。但是,图像上也出现了轻微的棋盘效应,画面中显示出规则性块状纹理;而从风格来看,尽管生成图像拥有目标风格分布,但是其风格笔触较为简单,例如当参考风格为油画类型时,生成图像过于光滑,没有油画特有的笔触信息,风格特点不够突出。
2)配置2。引入判别网络后,在配置1 的基础上,增加对抗损失函数对网络训练过程进行约束,图8(d)展示了该配置下图像的风格化效果。可以看出,生成图像有了更明显的结构抽象效果,选择性地忽略了一些细节表现,降低了大面积区域多余纹理的出现,提升了画面渲染的简洁度和平滑度,更好地突出了画面主体部分。当参考图像为油画风格时,能够体现油画笔触特征,使其看起来更像画家创作的艺术作品。
3.4 其他应用方向
本文提出的任意风格迁移网络可以在不修改训练阶段网络结构的情况下完成其他的风格转移任务。
3.4.1 内容—风格权衡
除了在训练时调整内容损失函数和风格损失函数权重比控制风格化程度,训练好的网络在测试阶段也能够实现任意程度的风格化渲染效果。使用风格化权重α控制内容重建特征fcc和风格化特征fcs各自所占比例,实现风格化程度调整。具体为
式中,Control表示内容—风格的权衡操作,fcc是将两幅相同内容图像输入网络生成的内容重建特征,α表示权衡比,取值范围为[0,1]。当α=0时,网络生成原始内容图像Ic,当α=1时,网络生成标准风格化图像Ics。随着α值的增加,生成图像的风格特征越来越明显,与风格图像特征越来越相似,如图9所示。

图9 控制权衡参数实现不同程度的风格化效果Fig.9 Control trade-off parameters to achieve different levels of stylized performance
3.4.2 风格插值
以在两幅风格图像间进行风格插值为例,生成的风格化图像如图10 所示,图中s1∶s2形式的数据用来计算风格插值权重,计算过程为

图10 使用不同插值权重生成的混合风格化效果Fig.10 Hybrid stylized results generated using different interpolation weights
3.4.3 区域绘制
本文模型不仅可以整体绘制风格化图像,还可以使用不同的风格特征绘制内容图像中的不同区域,即
式中,fc|s1为使用内容图像Ic和风格图像Is1生成的风格化特征,fc|s2表示使用Ic和风格图像Is2生成的风格化特征,mask为输入的二值图像,用以将内容图像划分为不同的区域,⊙表示元素间点乘操作。区域绘制效果如图11 所示。可以看到,生成结果中人像主体与背景拥有不同的样式风格,但是二者在边界处融合自然,提高了图像整体的表现力。

图11 使用不同风格特征绘制内容图像不同区域的生成效果Fig.11 Results for drawing different areas of content images using different style features
4 结论
鉴于风格转换过程与句子翻译过程间的相似性,本文提出一种结合卷积神经网络特征提取能力和Transformer网络全局依赖性捕获能力的混合网络模型,用于图像的任意风格迁移任务。首先,在卷积网络中引入残差连接,为提取的图像高级特征增添低级纹理信息,提高特征的表示能力和网络保留物体清晰结构的能力;其次,使用Transformer优秀的相关性建模能力,为特征增添全局信息,同时完成语义感知的特征块替换过程;针对风格信息难以用数值精确表示的问题,引入判别网络度量风格化效果。实验结果表明,本文网络相较其他方法能高效地生成高质量的风格化图像。
尽管本文网络能够实现良好的风格化效果,但仍存在一些问题需要完善。如,判别网络将风格判别过程视为一个二分类问题,即生成图像和真实风格图像,因此判别网络学习的是两个图像域之间的差异。如何调整判别网络使其能判别任意风格特征是后续研究工作的重要方向。
