基于深度神经网络的图像风格化方法综述
2022-05-07涂鹏琦高常鑫
涂鹏琦 高常鑫 桑 农
图像的风格是指一幅图像或一个域所有图像共有的触点、纹理、色彩等特征,如艺术图和照片表示两种不同的图像风格.图像风格化旨在通过风格化模型,将一幅图像在保持语义内容不变的同时从原始风格转换为参考图像或目标域定义的风格,即具有某一风格的原始图像通过风格化模型转换为另一个风格的风格化图像.强大的风格转换能力和多样有趣的风格化结果使图像风格化技术在社交、艺术创作和数据生产等领域都有着广泛的应用.
近年来,深度神经网络由于强大的特征提取和表达能力,受到学术界和工业界的广泛关注,并在图像生成[1-8]、图像到图像转换[9-22]、图像编辑[23-26]和图像风格化[27-32]等任务上取得重大的技术突破.在此背景下,越来越多的研究者尝试使用深度神经网络完成图像风格化任务,提出各种基于深度神经网络的方法,解决图像风格化任务中存在的问题.
Gatys等[27,33]首先提出图像风格化的概念,并提出基于优化(Optimization-Based)的图像风格化方法,这也是图像风格化研究初期采用的主要方法.为了提高风格化的速度和效率,Johnson等[34]和Ulyanov等[35]先后提出使用前向深度神经网络代替缓慢的优化过程,并提出相应的内容损失函数和风格损失函数,用于网络训练,为基于前向深度神经网络的图像风格化研究奠定基础.此外,生成对抗网络(Generative Adversarial Network, GAN)[36]的提出,以及它在各种图像生成和图像到图像转换任务上的突出表现,使很多基于GAN的图像风格化方法被提出,改善已有方法的效果和性能,大幅促进图像风格化的研究进程.因此,基于前向深度神经网络的图像风格化方法和基于GAN的图像风格化方法也成为目前图像风格化研究中采用的主要方法.
本文根据风格的定义方式,将基于深度神经网络的图像风格化方法划分为两类:基于参考的图像风格化方法和基于域的图像风格化方法.
在基于参考的图像风格化方法中,风格由单幅图像定义,即目标风格由参考图像决定.深度神经网络的输入为原始图像和参考图像.深度神经网络通过训练,学习如何在保持原始图像语义内容的同时将其风格转换为参考图像的风格,所以在这类方法中原始图像称为内容图像,参考图像称为风格图像.基于参考的图像风格化方法的优点在于,目标风格由参考图像定义,对于训练完成的模型,可根据参考图像的不同实现任意目标风格的转换.不足之处主要有如下两方面.一方面由于目标风格由参考图像定义,因此对于模型训练时未出现的参考图像,模型对其代表风格的转换能力较弱,风格化结果较差.另一方面,由于模型很难“干净地”学到参考图像的风格,其风格化过程会无法避免地保留一些原始图像的风格信息,同时引入参考图像的一些语义内容信息.当原始图像和参考图像差距过大时,风格化过程中保留的原始图像的风格信息会使生成的风格化图像出现不同程度的风格失真,即出现欠风格化问题.引入参考图像的语义内容信息会使生成的风格化图像出现不同程度的内容失真,即产生过度风格化问题.
在基于域的图像风格化方法中,风格是由一个域的所有图像共同定义.该任务涉及两个域:定义原始风格的源域和定义目标风格的目标域,分别由训练时使用的原始图像集合和目标图像集合表达,该任务此时就转化为从源域到目标域的图像到图像转换任务.鉴于GAN在图像到图像转换任务上的突出表现,此类方法常采用GAN学习源域到目标域的映射关系,完成两者之间的转换.基于域的图像风格化方法的优点在于,目标风格由目标域的所有图像共同定义,更鲁棒,模型能学到更“干净的”风格.因此,模型在向目标风格转换的风格化任务上较鲁棒,更多地保留源域图像的语义内容信息,风格化结果更真实自然.不足之处在于,由于该类方法中目标风格由目标域的所有图像共同定义,因此训练完成的模型只能完成单一目标风格的转换,无法实现任意目标风格的转换,存在一定的局限性.
1 基于参考的图像风格化方法
基于参考的图像风格化方法需要解决如何在保持原始图像语义内容不变的同时将其风格转化为参考图像的风格的问题.问题的关键是如何获取图像的语义内容信息和风格信息,并完成目标风格的转换.根据近年来风格化过程中的特征处理方式,基于参考的图像风格化方法可划分为两类:基于特征解耦的图像风格化方法和基于特征融合的图像风格化方法.
1.1 基于特征解耦的图像风格化方法
基于特征解耦的图像风格化方法是指将图像的特征解耦为包含语义内容信息的内容特征和包含风格信息的风格特征,再交换原始图像和参考图像的风格特征,完成风格的转换.该类方法在图像风格化研究初期采用较多,图像风格化过程如图1所示.
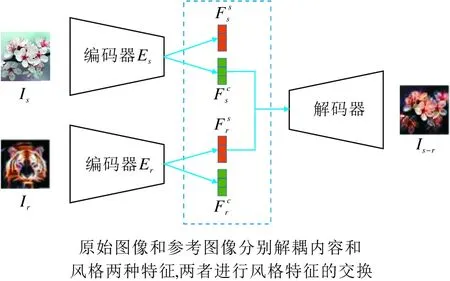
图1 基于特征解耦的图像风格化过程Fig.1 Image stylization process based on feature decoupling

Gatys等[27,33]首先提出神经风格迁移(Neural Style Transfer, NST)的概念和相应的基于优化的图像风格化方法,同时也是第一个基于特征解耦的图像风格化方法.在方法中,结合原始图像的内容特征和参考图像的风格特征,不断迭代以优化生成的风格化图像,并使用Gram矩阵衡量风格化图像和参考图像之间的风格相似性.在图像风格化研究领域,学者们先后提出基于特征解耦的图像风格化方法.Li等[37]提出使用马尔科夫随机场(Markov Random Field, MRF)正则化器代替Gram矩阵以衡量图像间的风格相似性,MRF在计算时考虑风格化图像和参考图像的语义相关性,采用基于块(Patch)的方式进行匹配并计算风格相似度.基于MRF的模型优化进一步提升生成的风格化图像的质量.
尽管上述方法已获得较高质量的风格化图像,但都是基于优化的,需要经过多次迭代才能获得较高质量的风格化图像,在实际应用中非常耗时.为了加快风格化过程,Johnson等[34]和Ulyanov等[35]先后提出使用前向深度神经网络代替缓慢的优化过程,并提出用于前向深度神经网络训练的感知损失.感知损失包括衡量语义内容差距的内容损失和衡量风格差距的风格损失.首先利用VGG网络[38]提取原始图像Is和风格化图像Is-r,在网络各层的特征进行对比,即得到表示两者语义内容差距的内容损失:
其中,φ表示VGG网络,j表示网络的第j层,Cj表示网络第j层对应特征图的通道数,Hj、Wj表示网络第j层对应特征图的高和宽.进而,再使用VGG网络提取参考图像Ir和风格化图像Is-r在网络各层的特征,在分别计算Gram矩阵后进行对比,得到表示两者风格差距的风格损失:
其中Gram表示计算Gram矩阵值.前向深度神经网络的应用使图像风格化的速度提升2~3个量级,实现实时的图像风格化,而基于前向深度神经网络的方法也逐渐成为图像风格化的主流方法.
随着GAN的提出,及其在图像生成和图像到图像转换等领域的突出表现,研究者们尝试利用GAN在图像风格化领域取得新的突破.Huang等[39]提出MUNIT(Multimodal Unsupervised Image-to-Image Translation),Lee等[40]提出DRIT(Diverse Image-to-Image Translation via Disentangled Representa-tions).这两种方法实质上都可归为基于特征解耦的图像风格化方法.MUNIT和DRIT网络结构基本一致,只在一些网络层上存在差异,具体网络结构如图2所示.
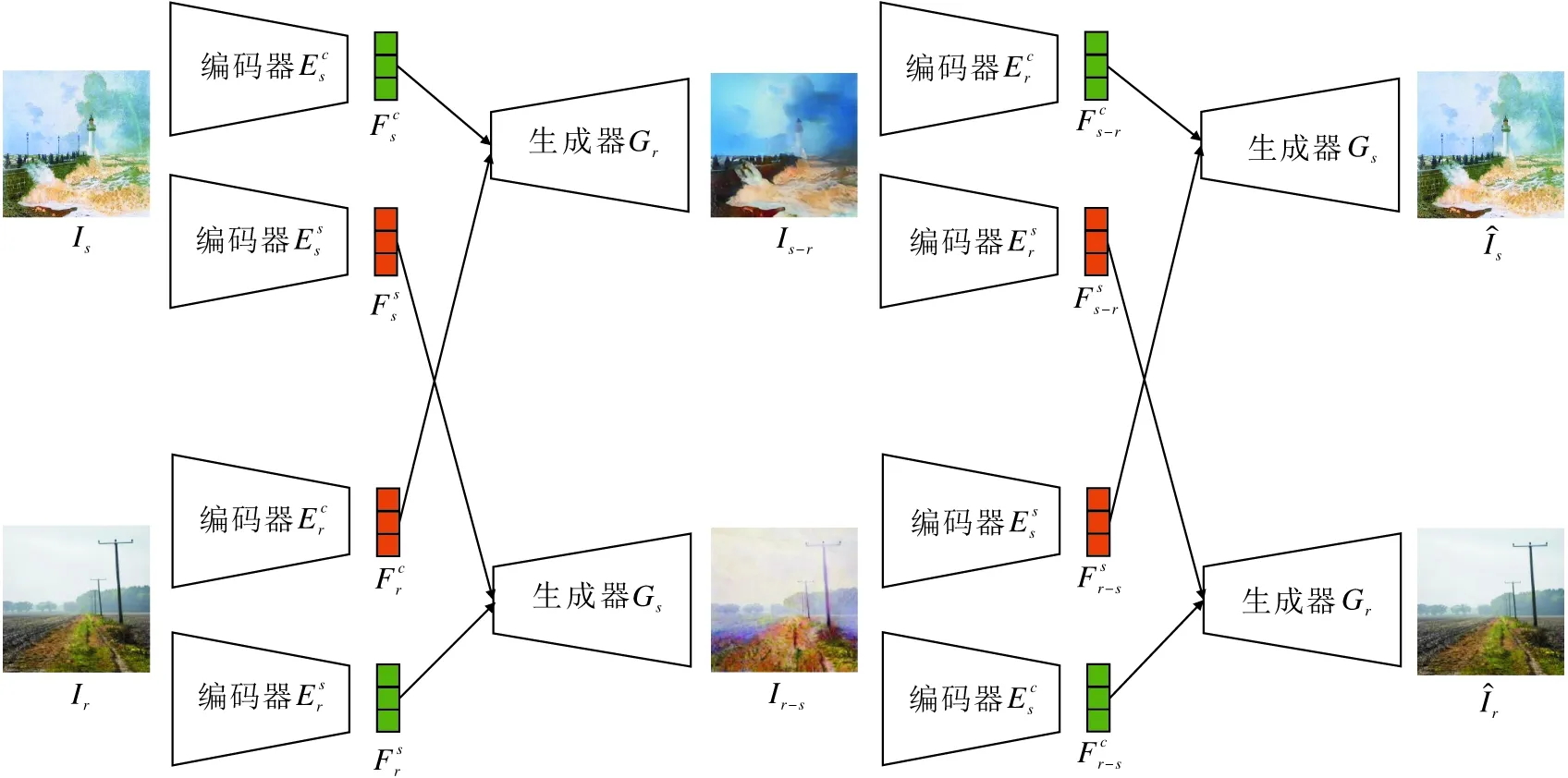
图2 MUNIT和DRIT网络结构图Fig.2 Network architecture of MUNIT and DRIT
该训练过程涉及的损失函数如下.
1)生成对抗损失:
用于约束生成的风格化图像Is-r和参考图像Ir风格分布的一致性,其中,G表示生成器,D表示判别器.
2)KL损失:
3)循环一致性损失:
相比文献[27]、文献[33]~文献[35]、文献[37]方法,MUNIT和DRIT主要有两方面改进.
1)引入GAN,更容易学到目标风格的分布,获得更真实的风格化图像.
2)将风格特征的分布约束为标准正态分布,推理时既可通过参考图像编码产生风格特征,也可直接从标准正态分布随机采样得到风格特征,增加风格化结果的多样性.
尽管基于特征解耦的图像风格化方法已获得较高质量的风格化图像,但通过对图像分别编码的解耦方式很难将风格特征和内容特征“干净地”解耦,导致风格特征中包含内容信息,而内容特征中包含风格信息,使得由原始图像转换得到的风格化图像会保留较多的原始图像的风格信息或引入较多参考图像的内容信息.一方面,当参考图像与原始图像的风格信息相差较大时,生成的风格化图像会由于保留较多原始图像的风格信息,出现欠风格化问题.另一方面,当参考图像与原始图像的内容信息相差较大时,生成的风格化图像会由于呈现较多风格图像的内容信息,出现过度风格化问题.
1.2 基于特征融合的图像风格化方法
基于特征融合的图像风格化方法是指分别提取原始图像和参考图像的特征,再采用特征融合模块,融合两者特征后,得到包含原始图像语义内容信息和参考图像风格信息的特征,完成风格的转换.该类方法是目前基于参考的图像风格化的主流方法,图像风格化过程如图3所示.
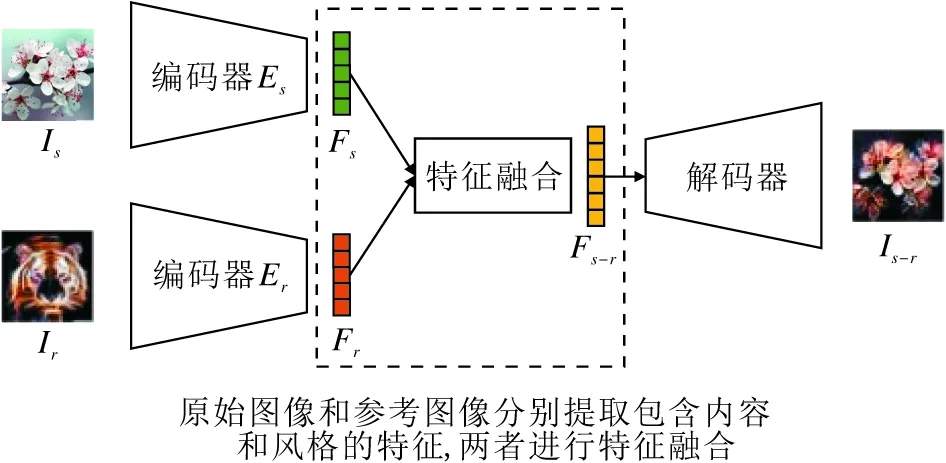
图3 基于特征融合的图像风格化过程Fig.3 Image stylization process based on feature fusion
基于特征融合的图像风格化方法在进行风格化时,原始图像Is通过编码器Es,得到图像特征Fs,参考图像Ir通过编码器Er,得到图像特征Fr,然后将Fs和Fr通过特征融合模块,得到融合后的特征Fs-r,再经过解码器得到风格化图像Is-r.这里编码器Es和Er可为同个编码器,一般采用预训练的VGG网络[38].
Chen等[41]首先提出基于块的特征融合方式,采用预训练的VGG网络φ分别提取原始图像Is的特征图φ(Is)和参考图像Ir的特征图φ(Ir).再分别将φ(Is)和φ(Ir)划分为同样大小有重叠的特征图块,对每个原始图像特征图块,将它和相关性最强的参考图像特征图块交换.然后使用交换后的特征图块构建新的特征图,得到重建的特征图φs-r(Is,Ir).最后将φs-r(Is,Ir)输入生成器,得到风格化图像Is-r.
虽然Chen等[41]提出的应用基于块的特征匹配和交换进行特征融合的方式可获得较高质量的风格化图像,但是这种基于特征匹配和交换的特征融合方式计算量较大,较耗时.
此外,当参考图像和原始图像差距较大时,对匹配的特征直接进行交换的方式可能会引入较多参考图像的语义内容信息,使风格化图像丢失较多原始图像的语义内容信息.
为了解决这些问题,Li等[42]提出新的特征融合方式——WCT(Whitening and Coloring Transforms),在特征层面上提出风格的表示方式,即风格应由图像特征的协方差矩阵表示,并基于此理论提出使用原始图像特征图的协方差矩阵匹配参考图像特征图的协方差矩阵进行特征融合的方式.WCT的提出加快基于特征融合的图像风格化过程的处理速度,并获得较高质量的风格化图像,为后续的基于特征融合的图像风格化研究奠定基础.
为了进一步提高风格化图像的质量,Huang等[28]提出用于图像风格化的特征融合方式——AdaIN(Adaptive Instance Normalization).他们认为图像的风格是由其特征图的统计量均值和方差决定的,并提出使用参考图像特征图的均值和方差对原始图像特征图进行调制,使调制后的特征图和参考图像特征图的方差和均值一致.AdaIN的提出大幅加快图像风格化的处理速度,达到实时图像风格化的水平,也进一步提升风格化图像的质量.同时,AdaIN的提出也为基于特征融合的图像风格化方法提供新的研究方向和思路,学者们先后提出基于此的新方法,而AdaIN也成为基于特征融合的图像风格化方法主要采用的特征融合方式.
为了进一步提升风格化过程中特征融合的准确性和鲁棒性,Park等[43]提出SANet(Style Atten-tional Network).首先使用预训练的VGG网络提取原始图像Is和参考图像Ir的特征图Fs和Fr,然后采用SANet进行特征融合,SANet结构图如图4所示.
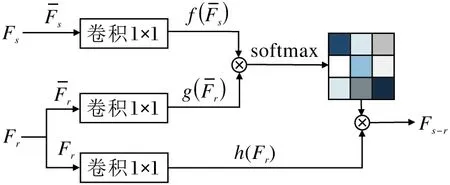
图4 SANet结构图Fig.4 Architecture of SANet
经过SANet可得到融合后的特征:
Wf、Wg和Wh表示可学习矩阵,
AdaIN[28]、WCT[42]和SANet[43]的提出对基于特征融合的图像风格化方法具有重大意义,后续提出的该类方法基本都是在这3种方式的基础上进行特征融合.
An等[44]为了在风格化过程中尽可能地保留原始图像的语义内容信息,改进网络结构,采用完全可逆的编码器-解码器结构ArtFlow,即解码器是编码器的逆过程.整个过程的可逆性使风格化过程中原始图像的语义内容信息得到更多的保留,提升风格化图像的质量.
尽管基于特征融合的图像风格化方法在一定程度上解决风格化过程的欠风格化和过度风格化问题,获得较高质量的风格化图像,但是当参考图像和原始图像差距较大时,仍不能完全解决上述问题.这也是未来基于参考的图像风格化方法的研究热点.
综上所述,基于参考的图像风格化的代表性方法Optimized-Based[27]、AdaIN[28]、WCT[42]、SANet[43]和ArtFlow[44]的特点可总结如表1所示.

表1 基于参考的图像风格化的代表性方法的特点Table 1 Characteristics of representative methods in reference-based image stylization
2 基于域的图像风格化方法
基于域的图像风格化方法是指对两个域进行转换,每个域定义一种风格,通过对域的转换完成对风格的转换,实现图像风格化.这类方法一般都是采用GAN的网络结构,图像风格化过程如图5所示.
图5 基于域的图像风格化过程Fig.5 Image stylization process based on domain
在基于域的图像风格化方法进行风格化时,源域图像Is通过源域到目标域的生成器Gs-t,得到具有目标域风格的风格化图像Is-t.
Zhu等[10]首先提出用于未配对图像到图像转换的CycleGAN,在基于域的图像风格化方法中,源域到目标域的转换也是未配对的,因此 CycleGAN可用于基于域的图像风格化.CycleGAN包含两个过程:源域到目标域到源域的风格转换和目标域到源域到目标域的风格转换.这两个训练过程类似,现只选择其中一个介绍,采用的网络结构如图6所示.
①m ≥ 2,于是得pm|pi,即pm-1|i,i.e.i=pm-1,2pm-1,···,pm,故bi∈ Z(G),此时(biaj)p=bipajp=1,即j=pn-1,2pn-1,···,pn,从而易得p阶元的个数为p2-1,p阶子群个数为p+1.由引理6可知P∗(G)的连通分支个数k(P∗(G))=p+1.② m=1,此时G=Mp(n,1)= 〈a,b:apn=bp=1,ab=a1+pn-1〉,容易计算

图6 CycleGAN网络结构图Fig.6 Network architecture of CycleGAN
CycleGAN的提出为未配对图像到图像转换提出一种新的解决思路,也为基于域的图像风格化研究奠定基础,后续基于域的图像风格化方法基本都是采用CycleGAN作为基本的网络框架.
Liu等[45]在CycleGAN的基础上,根据源域和目标域特征潜层空间共享的假设,即源域图像Is和目标域图像It的特征符合同种分布(标准正态分布),提出UNIT(Unsupervised Image-to-Image Tran-slation).在UNIT中,网络的训练包括2个并行的训练过程:图像的重建和图像的风格转换.图像的重建过程是指针对源域和目标域训练相应的变分自编码器(Variational Autoencoder, VAE)[46],源域的VAE包括编码器Es和解码器Gs,目标域的VAE包括编码器Et和解码器Gt.图像的风格转换过程是指将源域图像Is通过该域VAE对应的编码器Es,得到符合某一分布的特征Fs,根据源域和目标域特征潜层空间共享的假设,Fs再经过目标域VAE对应的解码器Gt,得到具有目标域风格的风格化图像Is-t.
UNIT的提出为基于域的图像风格化研究提供一种特征潜层空间的研究视角,大幅推动图像风格化的研究进程.
由于CycleGAN[10]中循环一致性损失的约束,采用CycleGAN作为基本网络框架的方法在存在形变的图像风格化任务上往往会产生较差的风格化结果.为了解决这个问题,Kim等[47]提出U-GAT-IT(Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation).U-GAT-IT采用的网络结构同样是CycleGAN,但是在此基础上引入注意力模块和自适应的层-实例正则化(Adaptive Layer-Instance Normalization, AdaLIN).注意力模块指导模型根据辅助分类器获得特征图通道方向的注意力权重,使加权后的特征图能将注意力集中在源域和目标域区别最大的区域,同时也是容易发生形变的区域,促进风格化过程中这些区域的形变.
AdaLIN是指在进行正则化时,采用层正则化和实例正则化,再采用可学习的权重系数对这两种正则化的结果进行加权.通过两种正则化方式的结合,更精确地控制风格化图像的形状和纹理.U-GAT-IT的提出为采用CycleGAN的基于域的图像风格化方法在需要形变的图像风格化任务上提供一种有效的解决方式,提升该任务中风格化图像的质量.
尽管基于域的图像风格化方法能在保留源域图像语义内容信息的基础上学习目标域的风格,完成目标域风格的转换,但是已有方法仍很难学到完全由目标域所有图像共同定义的风格,不可避免地都会学到目标域中一些特定图像才有的风格特征,使不同风格化图像的风格存在较大差异.该问题也是后续基于域的图像风格化研究需要重点关注的问题.
综上所述,基于域的图像风格化中代表性方法CycleGAN[10]、UNIT[45]、U-GAT-IT[47]、Council-GAN[48]的特点总结如表2所示.

表2 基于域的图像风格化方法中代表性方法的特点Table 2 Characteristics of representative methods in domain-based image stylization
3 实验及结果分析
3.1 基于参考的图像风格化方法对比
本节主要从运行速度和效果上对比基于参考的图像风格化方法,其中运行速度指生成一幅风格化图像需要的时间,效果指生成的风格化图像的质量.该类方法对比时无固定的数据集,本文选取相关论文中常用的原始图像和参考图像作为测试数据进行对比.
本文选取Optimization-Based[27]、AdaIN[28]、WCT[42]、Avatar-Net[49]、SANet[43]和ArtFlow[44]进行运行速度和效果的对比,运行速度对比结果如表3所示,其中黑体数字表示最优值.
由表3可知,Optimization-Based因为需要多次迭代优化,生成一幅风格化图像所需时间最长.采用前向深度神经网络的方法WCT、AdaIN、Avatar-Net、SANet和ArtFlow生成一幅风格化图像所需时间较短,相比Optimization-Based,提升2~3个量级.对比表明前向深度神经网络的使用大幅提升图像风格化的处理速度.相比WCT和Avatar-Net,AdaIN、SANet和ArtFlow进行特征融合时需要的矩阵运算更简单,生成一幅风格化图像所需时间更短,能实现实时的图像风格化.
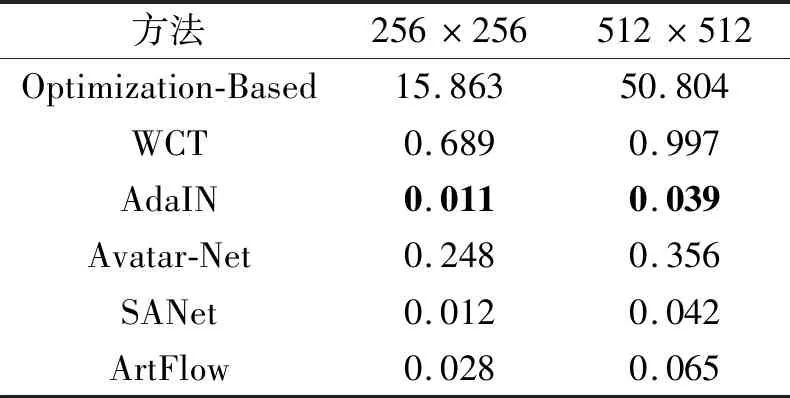
表3 各方法的运行时间对比Table 3 Running time comparison of different methods s
各方法生成的风格化图像对比如图7所示.由图可知,SANet和ArtFlow生成的风格化图像在语义内容信息保留上效果较优,特别是一些关键的纹理细节,如SANet和ArtFlow生成的风格化图像能完整保留原始图像额头的皱纹、发梢等纹理细节,而Optimization-Based、WCT和AdaIN生成的风格化图像都会存在不同程度的语义内容信息丢失问题,这表明SANet和ArtFlow在风格化过程中对于语义内容信息保留的有效性.进一步可发现,WCT、AdaIN、Avatar-Net、SANet、ArtFlow生成的风格化图像和参考图像的风格一致性更高,而Optimization-Based生成的风格化图像和参考图像的风格一致性存在较大波动,表明Optimization-Based得到的风格化图像的质量会较依赖于优化过程中的迭代次数,向不同风格转换时需要的迭代次数存在较大差异.

(a)内容图像(a)Content images
3.2 基于域的图像风格化方法对比
基于域的图像风格化方法都能实现实时的图像风格化,生成一幅风格化图像所需时间都在一个量级,因此通常只对各方法的风格化结果进行定量和定性的对比.
本文选取CycleGAN[10]、UNIT[45]、U-GAT-IT[47]、Council-GAN[48]、CUT(Contrastive Unpaired Transla- tion)[50]和SPatchGAN[51],在selfie2-anime、Celeb- A2anime、vangogh2photo、monet2photo数据集上进行对比.
selfie2anime数据集在U-GAT-IT[47]中被使用,包含人脸和动漫人脸两种风格.训练集包含3 400幅人脸图像和3 400幅动漫人脸图像.测试集包含100幅人脸图像和100幅动漫人脸图像.
CelabA2anime数据集是本文构建的,人脸图像从CelebA数据集上筛选,动漫人脸图像来自selfie2-anime数据集,同样包含人脸和动漫人脸两种风格.训练集包含3 400幅人脸图像和3 400幅动漫人脸图像.测试集包含100幅人脸图像和100幅动漫人脸图像.
vangogh2photo数据集在CycleGAN[10]中被使用,包含艺术图像和照片两种风格.训练集包含400幅艺术图像和6 287幅照片图像.测试集包含400幅艺术图像和751幅照片图像.
monet2photo数据集在DRIT[40]中被使用,同样包含艺术图像和照片两种风格.训练集包含1 811幅艺术图像和6 452幅照片图像.测试集包含400幅艺术图像和751幅照片图像.
在定量对比方面,采用的定量指标分别为FID(Frechet Inception Distance)和结构相似性(Structural Similarity, SSIM).FID指目标域图像和风格化图像特征之间的最大均方差,这里特征是采用 Inception V3网络[52]提取的.FID值越低表示目标域图像和风格化图像之间的风格一致性越高.SSIM指源域图像和风格化图像之间的结构相似度,包括亮度、对比度和结构.SSIM值越高,表示源域图像和风格化图像的结构一致性越高.
各方法的FID、SSIM值对比如表4所示,表中黑体数字表示最优值.

表4 各方法的FID和SSIM值对比Table 4 Comparison of FID score and SSIM score of different methods
由表4可知,对比FID值可发现,各方法在不同类型的图像风格化任务上表现存在差异,在selfie2anime、CelebA2anime数据集上从人脸到动漫人脸的图像风格化任务中,SPatchGAN的FID值均最低,CUT、U-GAT-IT、Council-GAN、CycleGAN、UNIT的FID值依次升高,表明U-GAT-IT生成的动漫人脸图像和目标动漫人脸域的风格一致性最高,CUT、U-GAT-IT、Council-GAN、CycleGAN和UNIT生成的动漫人脸图像和目标动漫人脸域的风格一致性依次降低.在vangogh2photo、monet2photo数据集上从艺术图像到照片的图像风格化任务中,UNIT的FID值均最低,SPatchGAN、CUT、U-GAT-IT、Council-GAN和CycleGAN的FID值依次升高,表明UNIT生成的照片图像和目标照片域的风格一致性最高,SPatch-GAN、CUT 、U-GAT-IT、Council-GAN和CycleGAN生成的照片图像和目标照片域的风格一致性依次降低.
对比SSIM值可发现,各方法在不同类型的图像风格化任务上的表现同样存在差异,在selfie2-anime、CelebA2anime数据集上从人脸到动漫人脸的图像风格化任务中,SPatchGAN的SSIM值均最高,CUT、U-GAT-IT、CycleGAN、Council-GAN、UNIT的SSIM值依次降低,表明SPatchGAN生成的动漫人脸图像和原始人脸图像的结构一致性最高,CUT、U-GAT-IT、CycleGAN、Council-GAN、UNIT生成的动漫人脸图像和原始人脸图像的结构一致性依次降低.在vangogh2photo、monet2photo数据集上从艺术图像到照片的图像风格化任务中,U-GAT-IT和SPatch-GAN的SSIM值分别取得最高值,Council-GAN、CUT、UNIT、CycleGAN的SSIM值依次降低,表明U-GAT-IT和SPatchGAN生成的照片图像和原始艺术图像的结构一致性较高,Council-GAN、CUT、UNIT、CycleGAN生成的照片图像和原始艺术图像的结构一致性依次降低.
各方法在4个数据集上生成的风格化图像对比分别如图8和图9所示.由图可发现,在selfie2-anime、CelebA2anime数据集上从人脸到动漫人脸的图像风格化任务中,SPatchGAN、CUT、U-GAT-IT、Council-GAN生成的动漫人脸图像质量更高,在语义内容信息的保留和风格一致性上表现更优,而UNIT和CycleGAN生成的动漫人脸图像质量相对较低,在语义内容信息的保留和风格一致性上存在不同程度的问题,特别是生成动漫人脸的头发和鬓角处会出现较大的失真.在vangogh2photo、monet2-photo数据集上从艺术图像到照片的图像风格化任务中,SPatchGAN、U-GAT-IT、UNIT生成的照片图像质量更高,在语义内容信息的保留和风格一致性上表现更优,而CUT、Council-GAN、CycleGAN生成的照片图像质量相对较低,在语义内容信息的保留和风格一致性上同样存在一些问题,如CUT、Council-GAN、CycleGAN生成的照片图像会出现严重的语义内容信息丢失问题.
整体上,各方法在不同类型的图像风格化任务上的表现存在差异,SPatchGAN、Council-GAN、UGA-TIT综合表现更优,表明SPatchGAN中提出的基于统计特征的判别器能有效帮助模型学习目标风格的分布,U-GAT-IT中提出的注意力机制和AdaLIN在风格化过程中能帮助模型更好地学习目标风格,对语义内容和风格的控制更精确,Council-GAN中提出代替循环一致性约束的多个GAN的协同约束更适合图像风格化任务,能帮助模型更好地学习目标风格.UNIT在从艺术图像到照片的图像风格化任务上表现更优,表明这两类风格的特征潜层空间一致性较高,特征潜层空间共享的假设更适合此类风格化任务.

(a)原始图像(a)Original images

(a)原始图像(a)Original images
4 问题与展望
4.1 存在的问题
尽管已有的基于深度神经网络的图像风格化方法获得较高质量的风格化图像,但仍存在一些问题.
1)泛化性难以保证.这是基于深度神经网络的方法在实际应用中都会存在的问题.基于深度神经网络的风格化模型训练完成后,在实际应用时,对于在训练中未出现过的、与训练数据集中的图像差异较大的图像,模型生成的风格化图像质量较低,会出现不同程度的失真.提高图像风格化方法的泛化性仍是图像风格化研究领域的难点问题.
2)欠风格化和过度风格化问题.尽管已有的图像风格化方法在一定程度上解决风格化过程的欠风格化和过度风格化问题,并获得较高质量的风格化图像,但是当参考图像和原始图像差距较大时,该问题仍不能得到完全解决.生成的风格化图像要么出现欠风格化问题,保留过多原始图像的风格信息,和参考图像的风格一致性较低,要么出现过度风格化问题,丢失较多原始图像的语义内容信息.解决该问题是图像风格化研究领域急需解决的问题.
3)难以学到想要的风格.当采用GAN的风格化模型训练时,模型收敛后,不同迭代周期可能会学到不同的风格分布,导致同幅源域图像生成的风格化图像可能会存在较大差异,难以学到想要的风格.在模型收敛后学到基本相同的风格分布或学到想要的风格,是图像风格化研究领域需进一步研究的问题.
4)缺乏可解释性.虽然基于深度神经网络的图像风格化方法可从人类认知的角度进行风格的定义和转换,根据图像间的相似性定义风格,利用训练完成的深度神经网络模型实现风格转换,有一定的可解释性.但是,风格转换是在由深度神经网络映射的潜层空间上进行,而潜层空间中特征的含义难以解释,不同方法潜层空间中特征的含义可能会存在较大的差异,导致这类方法仍不具备可以让人类能理解的解释性.
5)设计缺乏理论指导.虽然近年来图像风格化受到学者们的广泛关注,并取得不错成果,但是关于图像风格化的理论研究却很少.大部分方法设计的初衷都是来源于人类认知过程中的启发或猜测,并无理论保证或指导.
4.2 未来展望
通过对当前基于深度神经网络的图像风格化方法的梳理及已有相关方法存在问题的分析,可展望未来图像风格化领域的研究方向.
1)从数据和模型两个角度提升图像风格化模型的泛化性.在数据层面,一方面增加训练时的数据量,即增加训练数据集上图像的种类数,另一方面对训练数据进行数据增强操作,如翻转、裁剪等操作,提高数据的多样性.在模型层面,考虑多个参考图像在模型映射的特征潜层空间进行线性插值等操作,进行风格特征的融合,使模型能学习更多样的风格特征.从数据和模型两个角度出发,使模型学习更多种类的风格和风格特征,提高风格化模型的泛化性.
2)从网络结构和损失函数两个角度解决欠风格化和过度风格化问题.在网络结构层面,采用级联的特征融合结构,如将WCT、AdaIN和SANet进行相应的联合,在风格化过程中进行更精细化的特征融合.在损失函数层面,设计损失函数,对生成的风格化图像的语义内容信息和风格信息进行更严格的约束,如使用多细粒度的轮廓损失约束风格化图像和原始图像多细粒度轮廓的一致性,使用多尺度的风格特征损失,约束风格化图像和参考图像在各层多个尺度风格特征上的一致性.
3)建立不同风格化图像的联系,学习想要的风格.例如,在模型训练中后期,约束同幅源域图像在不同迭代周期中生成的风格化图像的一致性,降低差异性,使模型能学到基本相同的风格分布或学到想要的风格,不会因为迭代周期的不同而学到不同的风格分布.
4)研究可解释的图像风格化方法.已有多数图像风格化方法常只从人类认知角度给出简单的定性解释,说明方法在风格转换方面的有效性.虽然风格化中间过程的一些可视化结果可部分说明为什么这些方法会起作用,但方法中的网络结构、损失函数和训练策略等如何在风格化过程中起作用缺乏可靠的解释.因此,设计可解释的图像风格化方法,更好地让风格化模型像人一样学习是未来值得研究的问题.
5)基于参考的图像风格化方法能对风格化过程进行更精确的控制,基于域的图像风格化方法能学习更鲁棒的风格分布,因此可结合这两种方法.采用基于域的图像风格化方法中风格的定义方式,即风格由目标域的所有图像共同定义,但采用基于参考的图像风格化方法的网络框架,添加额外的约束.例如,在模型训练时,每次迭代从源域随机采样一幅图像作为原始图像,从目标域随机采样两幅图像作为参考图像,对于模型生成的两幅风格化图像,通过相应的损失函数约束其风格的一致性,即确保模型学到完全由目标域所有图像共同定义的风格.在推理时,对于同幅原始图像,从目标域随机选取一幅图像作为参考图像,在一定程度上可保证模型生成的风格化图像风格的一致性,学到更鲁棒的风格分布.
