深度学习多模态图像语义分割前沿进展
2023-11-22赵什陆张强
赵什陆,张强
西安电子科技大学机电工程学院,西安 710071
0 引言
图像语义分割是当今计算机视觉领域中极具挑战性的热点问题之一。不同于图像去雨、去雾、去模糊等低层次视觉任务,图像语义分割旨在将视觉场景分解为不同的语义类别实体,实现对图像中每个像素的类别预测,是许多视觉场景理解系统中不可或缺的重要组成部分。随着深度学习技术的不断创新与发展,大量图像语义分割算法相继提出,在自动驾驶、智慧农业、地质监测和军事侦察等领域均取得了显著的成就。
2015 年,Long 等人(2015)提出了一个里程碑式的工作,即全卷积网络(fully convolutional network,FCN),为图像语义分割任务定义了全新的范式,同时引起了基于深度学习的图像语义分割研究热潮。到目前为止,研究者们已经贡献了大量高效的基于深度学习的图像语义分割算法以及用于算法训练的大规模数据集,并取得了很好的效果。不过,现有的基于深度学习的图像语义分割工作大多利用可见光(red-green-blue,RGB)图像实现场景内容感知,可见光相机对于场景光照变化的鲁棒性较差,且缺乏对烟、雾、霾、雨、雪的穿透功能。受限于其成像机理,可见光相机难以在不良光照条件以及恶劣天气情况下捕获足够有效的场景信息。此外,可见光相机还难以提供场景相关的空间结构信息以及三维布局信息,无法应对具有目标外观相似、场景区域多且变化大等特点的复杂场景。
随着图像传感器技术的不断发展与进步,不同模态(即基于不同成像机理)的图像传感器在军用以及民用领域日益普及。除可见光相机外,目前较为常见的图像传感器主要为热红外成像仪以及深度相机等。不同于可见光相机,深度相机能够获取成像场景中目标距离相机光心的物理距离,而热红外成像仪则能够在各种不良光照、天气条件下反映场景中温度在绝对零度(-273 ℃)以上物体的热辐射特性,进而提供精确的目标轮廓信息以及语义信息。但是,相对于RGB 图像,深度图像和热红外图像通常缺乏一定的颜色、纹理等细节信息。考虑到在大多数复杂场景下单一模态图像难以提供完整的场景知识,导致无法获得精确的语义分割结果,因此,对于多模态图像语义分割技术的研究具有重要的现实意义。通过联合利用不同模态图像间的互补特性,有助于更为全面、准确地实现场景信息的学习与推理。
然而,目前还鲜有综述性文献对基于深度学习的多模态图像语义分割研究进行总结和分析。Hu等人(2018)和Noori(2021)为基于深度学习的可见光—深度(RGB-depth,RGB-D)图像语义分割方法提供了简单的综述,但其调研还不够充分,同时也缺少对已有方法的分类和解析。Zhang等人(2021a)调研了多模态图像语义分割算法,但仅从融合阶段的角度将其划分为早期融合、中期融合和晚期融合,缺乏更为系统的分类和汇总。不同于上述工作,本文将对现有的基于深度学习的可见光—热红外(RGBthermal,RGB-T)图像和RGB-D图像语义分割算法进行详细且深入的调研,以便读者了解领域内研究现状以及发展趋势。
本文的主要贡献包括:首先对目前已有的基于深度学习的RGB-T∕RGB-D 图像语义分割算法进行详尽调研,从算法的核心思想出发,对其进行归纳、分析和对比;随后详细介绍了RGB-T∕RGB-D 图像语义分割算法常用的客观评测指标和数据集,并提供现有方法在不同数据集下的性能对比;最后对基于深度学习的多模态图像语义分割未来可能的研究方向进行梳理和讨论。
1 深度学习RGB-T图像语义分割模型
“编码器—解码器”结构(Badrinarayanan 等,2017)是基于深度学习的图像语义分割方法中最为常用的范式,其中编码器用于提取图像特征,解码器则用于图像特征恢复以及分割结果预测。该结构的优势已经在基于深度学习的RGB 图像语义分割领域得到广泛证明。因此,目前绝大多数基于深度学习的RGB-T 图像语义分割模型也都延续了“编码器—解码器”结构的设计,并在此基础上针对如何有效利用多模态图像间的互补特性进行了深入的研究。基于深度学习的RGB-T 图像语义分割可以看做是一个典型的流水线处理过程,包含单模态图像特征提取、多模态图像特征融合和语义分割结果预测3 个步骤。其中,对于单模态图像特征提取部分,现有方法均采用预训练的分类网络(如VGG(Visual Geometry Group)(Simonyan 和Zisserman,2015)、ResNet(residual network)(He 等,2016))实现,本文将不再对这些分类网络的结构进行详细描述,相应内容可参考综述性文献(张珂 等,2021)。
依据算法侧重点不同,本文将目前已有的基于深度学习的RGB-T 图像语义分割方法划分为3 类,即基于图像特征增强的方法、基于多模态图像特征融合的方法和基于多层级图像特征交互的方法。
1.1 基于图像特征增强的方法
基于图像特征增强的方法通常通过注意力机制以及辅助信息嵌入等方式,直接或间接地增强单模态图像特征或多模态图像融合特征。这类方法在挖掘单模态图像特征或多模态图像融合特征中高鉴别力信息的同时降低干扰信息的影响,进而提升语义分割精度。
Shivakumar等人(2020)提出了一种PSTNet(PENN subterranean thermal network),其核心思想是首先利用RGB 图像的语义分割置信图作为一种辅助信息,通过将其与输入的RGB 图像和热红外图像组合,以增强输入数据中所包含的有效信息。随后,再通过预训练分类网络对增强后的输入数据进行特征提取。本质上,该方法是通过增强输入图像间接地实现融合特征增强。如图1 所示,该方法共包含两个阶段。在第1阶段,RGB 图像被输入到一个“编码器—解码器”结构中,以获取基于RGB 图像的语义分割置信图。紧接着,在第2 阶段,将第1 阶段获得的RGB 图像语义分割置信图、RGB 图像和热红外图像级联后作为输入,通过一个预训练的高效残差分解卷积网络(efficient residual factorized ConvNet,ERFNet)实现最终的多模态图像语义分割结果预测。该方法具有较快的推理速度,但其语义分割精度较低,这是因为这种对输入数据进行增强的方式无法对单模态图像特征或多模态图像融合特征直接增强,难以确保具有高鉴别力的信息能够被完整、有效地挖掘。

图1 PSTNet网络结构图Fig.1 Structure of PSTNet
不同于PSTNet 将辅助信息嵌入到输入数据中间接实现特征增强的思路,一些工作选择直接对单模态图像特征或多模态图像融合特征进行增强。例如,Deng 等人(2021)提出了一种特征增强注意力网络(feature-enhanced attention network,FEANet),通过联合利用基于空间维度和通道维度的注意力机制,直接实现对多层级RGB 图像特征和热红外图像特征的增强。具体来说,该工作提出了一种特征增强注意力模块(feature-enhanced attention module,FEAM)。首先,该模块通过全局最大池化计算获得通道注意力向量,以选择单模态图像特征中包含高鉴别力信息的通道,随后,经通道注意力操作增强后的单模态图像特征通过沿通道维度的全局最大池化计算获得空间注意力图,进一步在全局区域挖掘有效的信息线索。通道注意力操作能够有效地挖掘前景线索,与之相辅相成的是,空间注意力操作集中在全局区域挖掘场景信息,寻找其中可能的小目标物体。通过融合经FEAM 增强后的单模态图像特征,能够有效保留空间信息,并将更多的注意力转移到高分辨率特征上,进而促进语义分割效果的提升。
Zhou 等人(2021a)提出了一种边缘引导融合网络(edge-aware guidance fusion network,EGFNet),利用边缘信息作为辅助信息直接实现多模态图像融合特征的增强。该方法的结构如图2 所示。该方法首先通过一个多模态融合模块(multi-modal fusion module,MFM)实现对多模态图像特征的充分融合。随后,对于融合后的多模态图像融合特征,该方法引入一个由RGB 图像和热红外图像生成的先验边缘图来捕获场景中的细节、纹理信息,通过将先验边缘信息与多层级的多模态图像融合特征相乘,进而实现边缘辅助信息的嵌入。该方法通过利用先验边缘信息,能够缓解语义分割任务中物体边界判别性较弱的问题,有效校正了语义分割预测结果中模糊的目标边界,因此能够获得目标边缘更加精细的高质量语义分割结果。但是,该方法的效果比较依赖于先验边缘图的质量,边缘图是否完整、准确将直接影响最终的语义分割结果。

图2 EGFNet网络结构图Fig.2 Structure of EGFNet
1.2 基于多模态图像特征融合的方法
基于多模态图像特征融合的方法主要关注如何有效利用RGB 图像特征与热红外图像特征之间的互补特性,进而充分发挥多模态图像的优势。与单模态图像语义分割任务相比,特征融合是多模态图像语义分割任务所特有的。因此,现有的大多数RGB-T图像语义分割方法主要针对多模态图像特征融合策略展开研究。
以多光谱融合网络(multi-spectral fusion networks,MFNet)(Ha等,2017)、RGB-T融合网络(RGBthermal fusion network,RTFNet)(Sun 等,2019)和FuseSeg(Sun等,2021)为代表,早期基于多模态图像特征融合的工作主要通过求和或级联等简单融合方式获取多模态图像融合特征。
MFNet 是第1 个基于深度学习的RGB-T 图像语义分割工作,其结构如图3 所示。首先,该工作通过两个简单的编码器结构分别提取RGB 图像特征和热红外图像特征,之后通过级联的方式实现对两种模态特征的融合,最后利用一个解码器结构逐级恢复融合特征分辨率并进行语义分割结果预测。由于该方法自行设计了轻量级编码器结构,未使用预训练的分类网络提取图像特征,导致分割精度较差,难以满足实际应用的要求。

图3 MFNet网络结构图Fig.3 Structure of MFNet
随着深度学习技术的发展,大量高效的分类网络相继提出。RTFNet 和FuseSeg 分别利用预训练的ResNet 和DenseNet(dense convolutional network)(Huang 等,2017)作为编码器,以便更好地提取RGB图像特征和热红外图像特征,随后采用逐元素求和的方式实现多模态图像特征融合。最后,在解码器部分,为了减少解码过程中细节、语义信息的丢失,RTFNet 提出一种基于残差结构设计的Upception 模块以恢复特征图分辨率,而FuseSeg 则采用类似于U-Net(Ronneberger 等,2015)的结构,通过跳连接的方式实现编码器特征对解码器特征的补充。然而,这些通过简单策略融合多模态图像特征的方法,难以充分利用多模态图像特征间的互补特性,导致其性能差强人意。
为了更好地融合多模态图像特征,Xu 等人(2021)提出了一种注意力融合网络(attention fusion network,AFNet)。具体来说,该方法首先使用两个经洞卷积操作改进的ResNet-50作为编码器(其结构类似于DeepLab v3(Chen等,2017)中的编码器结构)分别提取RGB 图像特征和热红外图像特征。通过该编码器能够获得分辨率更高、信息更详细的特征图,同时有助于提升对场景中较小目标的感知效果。随后,对于编码器最深层提取到的RGB 图像特征和热红外图像特征,该方法提出了一种基于交互注意力机制的注意力融合模块(attention fusion module,AFM),以实现多模态图像特征融合。该模块首先通过计算RGB 图像特征和热红外图像特征之间的余弦相似度来构建空间相关性矩阵,具体为
式中,Cx→y表示x模态与y模态间的相关性矩阵,Fx和Fy表示x模态特征和y模态特征,x代表RGB模态或热红外模态中的一种,y代表与x不同的另一模态。Cx→y值的大小反映了RGB 图像特征和热红外图像特征不同空间位置间信息的相关程度。随后,通过空间相关性矩阵与多模态图像特征间的矩阵乘法运算,以指导不同模态图像特征的融合。
Lan 等人(2022)提出了一种多模态多层级网络(multi-modal multi-stage network,MMNet)。通过缓解编码器和解码器之间的语义差异(semantic gap)实现单模态图像特征增强。该方法由两个不同的阶段组成,第1 阶段包含两个相互独立的“编码器—解码器”结构,分别用来提取不同模态的图像特征,同时,为了缓解编码器特征和解码器特征之间存在的语义差异,本文利用一种基于残差结构的高效特征增强模 块(efficient feature enhancement module,EFEM)来连接编码器和解码器。在第2 阶段,该方法通过简单的求和方式融合了第1 阶段获得的RGB 图像信息和热红外图像信息,并通过设计一个轻量级的迷你精细化块(mini refinement block,MRB)逐渐精细化细节信息,以获得最终的语义分割结果。
Zhou 等人(2021b)提出了一种特征分级和多标签学习网络(graded-feature multilabel-learning network,GMNet),其结构如图4 所示。不同于其他方法,该方法对编码器提取的多层级图像特征进行分级,其中浅层特征属于低级特征,主要提供细节信息(如空间、纹理和边缘信息);深层特征属于高级特征,主要提供具有高鉴别力的语义信息,用于指导每个像素的类别标记。考虑到RGB 图像浅层特征可能携带误导和不完整的信息,针对低级特征,该方法提出了一个浅层特征融合模块(shallow feature fusion module,SFFM),利用浅层热红外图像特征对浅层RGB 图像特征进行校正,之后再通过通道注意力机制进一步增强校正后的RGB 图像特征。对于高级特征,该方法提出了一个深层特征融合模块(deep feature fusion module,DFFM),首先通过逐元素相乘以及求和的方式融合多模态图像高级特征,随后使用多个串行且膨胀率不同的洞卷积挖掘其中丰富的上下文语义信息。最后,除网络结构和模块设计外,该方法还利用多种标签监督网络训练:对浅层特征施加边缘图监督以精细化边缘细节信息;对浅层特征与深层特征间的过渡层特征施加二值化标签监督以准确区分前景和背景信息;对深层特征施加语义分割标签监督以获取丰富的语义信息。相较于其他使用单一融合策略获取多模态图像融合特征的思路,该方法根据不同层级特征的特点进行针对性设计,能够更好地利用多模态图像特征间的互补特性,进而取得了很好的分割效果。

图4 GMNet网络结构图Fig.4 Structure of GMNet
Zhang等人(2021b)提出了一种自适应加权双向模态差异缩减网络(adaptive-weighted bi-directional modality difference reduction network,ABMDRNet)。该方法充分考虑了由于成像机制不同而导致的模态信息差异,提出了一种“先缩减再融合”的策略,首先通过设计一个基于跨模态图像转换方式的双向模态差异缩减网络以缩减不同模态特征分布间的差异,得到更具鉴别力的单模态图像特征;随后,设计了一个通道自适应加权融合模块,利用卷积块自适应学习不同模态各通道特征的重要程度,并对其进行选择。此外,该方法还提出了多尺度空间∕通道上下文模块,挖掘更为丰富的上下文信息,以提升模型对场景中不同尺度目标的分割精度。该方法探索性地指出了多模态图像特征难以被直接融合的可能原因,分析了忽视模态差异可能导致的结果,为基于多模态图像特征融合的RGB-T 图像语义分割方法提供了一种新的研究思路。
1.3 基于多层级图像特征交互的方法
不同尺度的感受野能够提取场景中不同尺寸目标的信息,因此,多层级图像特征的交互有助于捕获丰富的多尺度上下文信息,进而显著提升语义分割模型在目标尺度多样场景下的性能。基于多层级图像特征交互的方法在单模态图像语义分割领域已经得到广泛应用,在RGB-T图像语义分割任务中,也有一些工作利用此类方法,取得了良好的语义分割结果。
Guo等人(2021)提出了一种MLFNet(multilevel fusion network)方法,通过建立多层级图像特征的交互,以获取丰富的多尺度上下文信息。首先,该方法利 用ESANet(efficient scene analysis network)(Seichter 等,2021)中提出的融合模块实现多模态图像特征融合。对于多层级的多模态图像融合特征,该方法提出了一种提取层(extraction layer),用于在每一层级整合所有层级的多模态图像融合特征,其结构类似于ResNet 中的残差块。最后,包含丰富多尺度上下文信息的特征通过一个辅助解码模块(auxiliary decoding module,ADM),通过上采样与级联的方式进一步整合,用于最终的语义分割结果预测。得益于对多层级图像特征的整合,该方法在目标尺度多样的场景中具有更好的有效性和鲁棒性。
Zhou 等人(2022)提出了一种多尺度特征融合和增强网络(multiscale feature fusion and enhancement network,MFFENet),其结构如图5 所示。与RTFNet 以及FuseSeg 类似,MFFENet 同样通过求和的方式获得多层级的多模态图像融合特征。之后,最深层特征被送入到一个简化的洞卷积金字塔(compact version of ASPP,CASPP)结构中,通过级联操作并结合3 个卷积核尺寸相同但膨胀率不同的洞卷积,以进一步挖掘上下文信息。紧接着,多层级图像特征通过双线性插值的方式上采样到相同的分辨率,再利用级联操作实现多层级图像特征的交互。最后,多层级聚合特征被送入到一个经典的空间注意力模块中,实现最终的语义分割结果预测。此外,为了提升语义分割精度,同时提升目标边界的区分效果,该方法同样采用了与GMNet 类似的多标签训练策略,利用边缘图、二值化标签图以及语义分割标签图作为监督信息联合训练模型。

图5 MFFENet网络结构图Fig.5 Structure of MFFENet
1.4 其他方法
部分方法的侧重点难以被归纳到前文提及的类别中。例如,考虑到夜间RGB 图像与热红外图像对标注困难的问题,Vertens 等人(2020)通过引入知识蒸馏技术,有效避免了昂贵且烦琐的夜间图像注释过程。
知识蒸馏是深度神经网络模型压缩技术中的代表性方法之一,其将一个复杂深度神经网络模型学习到的知识迁移至另一个轻量级模型中,在保证性能的情况下实现模型轻量化。其中,复杂深度神经网络模型称为教师模型,而轻量级模型称为学生模型。一个完整的知识蒸馏系统包含知识、蒸馏算法以及师生架构3个关键部分。
具体来说,该方法首先通过一个在白天场景预训练的RGB 图像语义分割教师模型进行监督,再由一个经过夜间场景预训练的热红外图像语义分割教师模型进行可选的监督。最后,引入对抗学习策略,通过最小化域鉴别器的域混淆损失,以减小白天和夜间图像之间的域差异,进而实现白天场景到黑夜场景的知识迁移。
2 深度学习RGB-D图像语义分割模型
相较于热红外图像和RGB 图像,深度图像能够提供丰富的场景三维空间信息,对于前、背景混淆程度高的场景具有很好的适应能力,但其往往存在较多的噪声和干扰信息。本文将基于深度学习的RGB-D 图像语义分割方法按照其对深度图像信息的利用方式划分为两大类。第1 大类类似于基于深度学习的RGB-T 图像语义分割方法,该类方法将深度图像与RGB 图像当做两种独立的输入数据,通过“单模态图像特征提取+多模态图像特征融合”的方式,利用RGB 图像与深度图像的互补特性,以获取更具鉴别力的多模态图像融合特征,进而提升算法对场景的感知能力,本文将这类方法归纳为基于深度信息提取的方法。根据其侧重点不同,这类方法又可以细分为基于多模态图像特征融合的方法和基于上下文信息挖掘的方法。其次,第2 大类方法则是将深度图像看做一种监督或先验信息,这类方法通常不需要提取深度图像的特征,而是显式或隐式地将深度信息嵌入到RGB 图像特征提取过程中。这类方法是基于深度学习的RGB-T 图像语义分割方法中所没有考虑的,本文中将这类方法归纳为基于深度信息引导的方法。
2.1 基于深度信息提取的方法
2.1.1 基于多模态图像特征融合的方法
早在FCN 中,就已经进行了将深度图像和RGB图像级联以实现RGB-D 图像语义分割的尝试。紧接着,Hazirbas 等人(2017)提出了一个基于多模态图像特征融合的RGB-D 图像语义分割网络FuseNet,其结构如图6 所示。该方法通过直接求和的方式逐层级融合RGB 图像特征与深度图像特征。

图6 FuseNet网络结构图Fig.6 Structure of FuseNet
在FuseNet的基础上,为了进一步增强深度图像所包含的信息,Hung 等人(2019)提出了一种LDFNet(luminance and depth information by a fusionbased network)。该方法采用与FuseNet 类似的结构,利用两个编码器分别提取RGB 图像特征和深度图像特征。不同的是,该方法将RGB 图像中的亮度信息嵌入到深度图像中,进一步提升深度图像特征的有效性。
Wang 等人(2016)提出了一种RGB-D 图像语义分割方法,与FuseNet和LDFNet不同,该方法对于每个模态图像都采用一个完整的“编码器—解码器”结构。该方法的主要实现步骤是:首先利用4 个相互独立的全连接层实现两种模态图像共有特征和特有特征的解耦,得到RGB 图像特有信息Frs、RGB 图像共有信息Frc、深度图像特有信息Fds以及深度图像共有信息Fdc。随后利用某一模态的模态共有信息与另一模态的所有信息进行融合,即Fdc、Frs和Frc进行融合,Frc、Fds和Fdc进行融合。最后将融合后的特征分别送入到两个独立的解码器中进行语义分割结果预测。该方法的核心思路是增强多模态图像共有特征的表示,尤其是当一个模态图像中的共有信息没有被很好地捕获时,能够较为显著地提升语义分割效果。
虽然浅层的RGB 图像特征和深度图像特征都很好地保留了空间线索,但是由于缺乏对RGB 图像中视觉信息与深度图像中几何信息间的校准,导致两者在融合过程中难以充分获取具有鉴别力的信息。考虑到包含语义信息的深层RGB 图像特征与深度图像特征具有更强的兼容性,Li 等人(2017)提出利用一种深层语义信息指导浅层细节信息的融合策略。具体来说,该方法首先利用两个独立的FCN分别提取RGB 图像特征和深度图像特征。随后,将包含兼容性更高的语义信息的最深层RGB 图像特征与深度图像特征通过求和的方式融合,用以指导浅层RGB 图像特征和深度图像特征融合。在浅层图像特征融合过程中,融合后的深层图像特征首先经过上采样操作得到与相应浅层图像特征分辨率一致的特征图,再通过求和的方式嵌入到浅层RGB 图像特征和深度图像特征融合过程中。该方法通过引入深层语义信息作为引导,在融合过程中缓解了浅层深度图像特征和RGB 图像特征间存在的模态差异,取得了比直接融合浅层RGB 图像特征和深度图像特征更好的语义分割效果。
Lee 等人(2017)提出了一种RGB-D 融合网络(RGB-D fusion network,RDFNet),其核心思想是将ResNet 中提出的残差学习思想扩展到RGB-D 图像语义分割任务中。该方法首先利用两个独立的ResNet 作为编码器,以提取RGB 图像特征和深度图像特征。随后,提出了一种多模态特征融合模块(multi-modal feature fusion,MMF),通过残差学习的方式处理RGB 图像特征和深度图像特征及其组合,以充分利用RGB 图像和深度图像间的互补特性。在该模块中,RGB 图像特征和深度图像特征首先被输入到一个卷积层中进行降维,以减少参数量过大的问题。随后,经降维处理后的RGB 图像特征和深度图像特征均被送入两个串行的残差卷积单元(residual convolution unit,RCU)中,通过执行一些非线性转换以帮助后续的多模态图像特征融合。其中RCU 是RefineNet(Lin 等,2017b)中提出的模块,其结构与ResNet 中的残差块类似。最后,RGB 图像特征和深度图像特征通过求和的方式融合,并通过一种残差池化操作(residual pooling operation)为融合特征添加上下文信息。此外,在得到多模态图像融合特征之后,该方法还引入了RefineNet 中的特征精细块(feature refinement block),该模块由RCU、多分辨率融合(multi-resolution fusion)和链式残差池化(chained residual pooling)组成,通过联合多层级的多模态图像融合特征,实现精细的语义分割结果预测。
为了利用RGB 图像与深度图像之间的互补特性,上述几种方法均使用直接求和的方式实现RGB图像特征和深度图像特征的融合,然而,在不同场景中,RGB 图像和深度图像所包含的信息量并不是完全等价的。考虑到这一问题,Hu 等人(2019)和Sun等人(2020)分别提出注意力互补网络(attention complementary network,ACNet)和实时 融合网 络(real-time fusion network,RFNet),根据RGB 图像特征和深度图像特征所包含的信息量,利用通道注意力机制选择高质量的信息。两种方法采用相同的思路,首先通过两个独立的编码器分别提取RGB 图像特征和深度图像特征。紧接着,利用通道注意力机制分别从RGB 图像特征和深度图像特征中选择高质量的信息,并对这些高质量信息进行求和融合,具体为
式中,Frgb表示RGB 图像特征,Fd表示深度图像特征,Ffused表示融合特征,G表示全局平均池化操作,C表示卷积操作,⊗表示外积计算,σ表示sigmoid 函数。最后,多模态图像融合特征被送入到一个解码器中实现语义分割结果的预测。这两种方法均利用注意力机制选择每个模态图像特征中有用的信息,同时抑制干扰信息,从而有效提升多模态图像融合特征的鉴别力。类似地,Liu等人(2018)则利用加权求和的策略替代直接求和的多模态图像特征融合方式,以解决RGB 图像和深度图像在不同场景中信息量不等价的问题。具体来说,该方法通过设置一个可学习的权重矩阵实现多模态特征加权融合。在训练过程中,权重矩阵能够学习到对RGB 图像特征和深度图像特征选择的能力,进而提升融合特征的鉴别力。
考虑到编码器网络越深,其边缘、轮廓等细节信息丢失越严重的问题,为了充分利用深度图像中丰富的边缘、轮廓信息,Zhou 等人(2021c)提出了一种三分支自注意力网络(three-stream self-attention network,TSNet)。与其他已有方法不同的是,该方法采用一种非对称的方式,即利用两种不同的编码器结构分别提取RGB 图像特征和深度图像特征。具体来说,为了充分利用深度图像所提供的边缘、轮廓信息以及RGB 图像所提供的细节和语义信息,该方法采用层数较少的VGG 结构提取深度图像特征,同时采用层数较多的ResNet 结构提取RGB 图像特征。此外,该方法也使用通道注意力机制,进一步对深层的RGB 图像特征进行选择,通过优化多模态图像语义信息融合过程,进而获取更多具有鉴别力的信息。
大多数基于多模态图像特征融合的方法均假设深度图像是足够精确的,且与RGB 图像是逐像素对齐的。然而,由于实际测量得到的深度图像不可避免地存在大量噪声,将会显著影响多模态图像融合特征的有效性,进而影响最终的语义分割精度。基于此,Chen 等人(2020)提出了一种分离和聚合门控(separation-and-aggregation gate,SA Gate)操作,在多模态图像特征融合之前过滤和重新校准两种特征,如图7 所示。首先,该方法利用两个独立的编码器分别提取RGB 图像特征和深度图像特征。随后,RGB 图像特征和深度图像特征级联后输入到两个全连接层中得到跨模态注意力向量,并通过加权融合的方式过滤噪声以及干扰信息。紧接着,为了充分利用RGB 图像特征和深度图像特征间的互补特性,该方法利用一种空间门控策略,采用注意力机制控制每个模态特征的信息流,最后采用加权求和的方式进行多模态图像特征融合。经过“先校正再聚合”的方式获取的多模态图像融合特征包含更具鉴别力的信息,且有效抑制了噪声以及误导信息,进而提升语义分割精度。
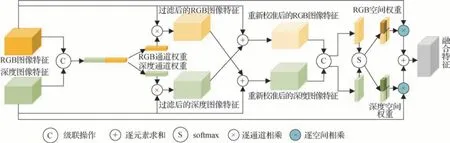
图7 SA Gate模块结构图Fig.7 Structure of SA Gate module
Yue 等人(2021)提出一种两阶段串行解码器网络(two-stage cascaded decoder network,TCDNet),为了从包含大量噪声和冗余信息的低质量深度图像中提取有用的信息,该方法提出了一种深度筛选和融合模块(depth filter and fusion module,DFFM)。该模块通过一种“丢弃—接受—聚合”(discard-acceptintegrate)机制实现RGB 图像特征和深度图像特征融合,以保留RGB 图像特征中的有用信息并丢弃深度图像特征中的冗余信息,同时提高RGB 图像特征和深度图像特征的兼容性。此外,对于浅层的多模态图像融合特征,该方法还提出了一种细节修正模块(detail polishing module,DPM)以实现浅层细节信息去噪。对于深层的多模态图像融合特征,则提出了一种改良金字塔膨胀模块(modified pyramid dilated module,MPDM)来扩大感受野,利用多个串行且膨胀率不同的洞卷积层获取丰富的上下文信息。
2.1.2 基于上下文信息挖掘的方法
上下文信息是提升单模态图像语义分割方法以及多模态图像语义分割方法性能的关键,有助于实现场景中不同尺寸目标的感知。受到Non-local(Wang 等,2018)的启发,Zhou 等人(2020)提出了一种交互注意力网络(co-attention network,CANet)。该方法提出一种位置交互注意力模块(position coattention fusion module,PCFM)和一种通道交互注意力模块(channel co-attention fusion module,CCFM),在不同维度上充分发挥跨模态长距离依赖(longrange dependency)的优势。在PCFM 中,深度图像特征和RGB 图像特征通过1 × 1 卷积层映射到同一特征空间中,再通过维度变换、矩阵转置以及矩阵乘法运算得到空间交互注意力亲和矩阵S,该矩阵中值的大小用来表示RGB 图像特征各个位置与深度图像特征各个位置间的相关程度。随后空间交互注意力亲和矩阵S与深度图像特征进行矩阵乘法运算后与RGB 图像特征求和得到多模态图像融合特征。该模块根据多模态图像特征在空间维度上的长距离依赖对深度图像特征进行选择,有效融合了深度图像特征的空间上下文信息。对于CCFM,该模块利用类似的方法获得通道交互注意力亲和矩阵C,进而在通道维度上建立RGB 图像特征和深度图像特征的长距离依赖。最后,包含丰富空间上下文信息的多模态图像融合特征和包含丰富通道上下文信息的多模态图像融合特征进一步聚合,以实现最终的语义分割结果预测。
考虑到CANet仅在编码器最深层挖掘上下文信息,忽略了多层级图像特征上下文信息的利用,Zhang 等人(2021c)提出了一种非局部聚合网络(non-local aggregation network,NANet),致力于捕捉多层级上下文信息,其结构如图8 所示。该方法首先通过两个独立的编码器获得RGB 图像特征和深度图像特征,随后,利用一个空间融合模块(spatial fusion module,SFM)在空间维度对RGB 图像特征和深度图像特征的长距离依赖进行建模。紧接着,经过SFM 得到的结果被输入到一个通道融合模块(channel fusion module,CFM)中,通过学习多模态图像特征通道间的非线性交互,利用一种加权融合的方式实现沿通道维度的长距离依赖关系建模。
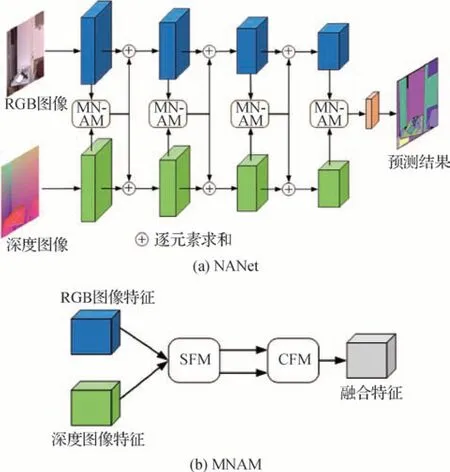
图8 NANet网络和MNAM模块结构图Fig.8 Structures of NANet and MNAM((a)NANet;(b)MNAM)
Chen 等人(2021)提出了一种全局—局部传播网络(global-local propagation network,GLPNet)。首先,该方法引入一种局部上下文融合模块(local context fusion module,L-CFM),在RGB 图像特征和深度图像特征融合前动态地对齐这两种特征。随后,引入一种全局上下文融合模块(global context fusion module,G-CFM),通过联合建模多模态图像特征的全局上下文信息,以实现深度信息到RGB 信息的传播。该方法利用上下文信息实现了多模态图像特征间的传播,进而提升了模型对多模态图像互补信息的利用能力,实现了较为准确的语义分割预测。
2.2 基于深度信息引导的方法
基于多模态图像特征融合的方法和基于上下文信息挖掘的方法充分利用了RGB 图像和深度图像间的互补特性,有效提升了语义分割精度。然而,这些方法需要通过单独的编码器提取深度图像特征,不可避免地增加了模型复杂度,进而导致其在实际场景中的应用受限。考虑到上述问题,基于深度信息引导的方法选择将深度信息嵌入到RGB 图像特征的提取过程中,在利用深度图像提供的三维信息的同时,在一定程度上实现了模型轻量化。
Wang 和Neumann(2018)提出了一种深度感知卷积神经网络(depth-aware convolutional neural networks,D-CNN),利用卷积神经网络处理空间信息的本质,将深度图像中的三维场景信息无缝地集成到RGB 图像特征提取过程中。该方法提出了一种深度感知卷积层和一种深度感知平均池化层,以替代RGB 图像编码器中的普通卷积层和平均池化层,能够在不引入任何参数和计算复杂度的情况下利用深度信息指导RGB 图像特征提取过程。在深度感知卷积层中,考虑到深度值接近的空间位置彼此之间应具有更大的影响,该方法在普通卷积操作中添加深度相似性项,利用像素之间的深度相关性引导RGB图像特征提取,具体计算为
式中,p0和pn分别表示RGB 图像特征图中一个局部网格的中心点坐标及其周围的非中心点坐标,L表示该局部网格中非中心点坐标的集合,x表示该局部网格中各位置的像素值,w表示卷积核权重,FD表示深度相似性项,具体计算为
式中,α为常数,D表示各位置的深度值。类似地,深度感知平均池化层同样利用深度相似性项,提升模型对目标边界的敏感性,与普通的平均池化操作不同的是,深度感知平均池化操作对池化窗口内的每个空间位置并不是“一视同仁”的,而是根据它们之间的深度相似性赋予不同空间位置权重后再进行计算。该方法灵活地将深度信息作为引导嵌入到RGB 图像特征提取过程中,仅需要一个“编码器—解码器”结构就能实现RGB-D 图像语义分割,在取得与基于多模态图像特征融合的方法和基于上下文信息挖掘的方法接近的分割精度的同时,大大降低了模型计算量和参数量,在一定程度上缓解了模型推理精度与推理速度间的矛盾,为基于深度学习的RGB-D图像语义分割提供了全新的思路。
受D-CNN 启发,Zheng 等人(2020)提出了一种深度相似卷积层(depth-similar convolution),其实现方式与D-CNN 中提出的深度感知卷积层基本一致,两者的差异在于深度相似性项的计算方式有所区别。
场景分辨率(scene-resolution)表示物体和场景的总体分辨率,在绝大多数场景中,深度信息与场景分辨率存在着相关性。一般来说,深度值较高的区域往往具有较低的场景分辨率,反之,场景分辨率较高的区域往往伴随着较低的深度值。在场景分辨率较低的区域,物体和场景密集共存,相对于场景分辨率较高的区域,物体与场景之间的相关性将更加复杂。基于此,Lin 等人(2017a)与Lin 和Huang(2020)提出利用深度图像来划分场景层次的方法,对场景分辨率较高的区域和场景分辨率较低的区域分别进行处理。该方法首先通过设定不同的深度阈值区间实现场景划分,随后,引入了一种上下文感知感受野(context-aware receptive field,CaRF),利用不同大小的超像素块学习不同场景的相关上下文信息。通过CaRF,网络能够对具有相似场景分辨率的场景进行单独学习,进而减少不同场景间的相互影响。该方法将深度图像作为RGB 图像场景的划分依据,通过一种类似于图像预处理的方式,高效地将深度信息嵌入到RGB 图像特征学习过程中。该方法丢弃了常规的深度图像特征提取以及多模态图像特征融合的操作,大大降低了模型参数量和计算量,同时也取得了很好的分割效果。
Lin 等人(2020)则考虑了目标共存(object coexistence)与深度信息之间的相关性。目标共存表示类别一致的目标。在距离深度相机较远(即深度值较高)的区域,物体通常密集共存,而距离深度相机较近(即深度值较低)的区域往往包含较少的目标和变化。该方法提出了一种可切换上下文网络(switchable context network,SCN),通过自顶向下(top-down)的方式将上下文信息从低分辨率特征传播到高分辨率特征。在上下文信息传播过程中,该方法提出了一种基于深度信息的可切换特征聚合方案,对于具有对象密集共存的区域,采用带有压缩结构的分支,在保留关键上下文信息的同时减少干扰信息。对于目标和变化较少的区域,采用带有扩展结构的分支进一步挖掘上下文信息。SCN 根据深度图像与场景中目标共存情况的相关性,利用深度信息引导不同场景上下文信息的提取,为RGB-D 图像语义分割方法提供了轻量化的思路。
2.3 其他方法
部分方法由于其特殊的创新性难以归纳到前文提及的类别中。例如,考虑到深度图像特征包含局部区域的几何形状(shape)属性以及它的位置(base)属性,其中形状属性与目标语义的联系更强,能够显著影响语义分割精度,Cao 等人(2021)提出了一种形状感知卷积层(shape-aware convolutional layer,ShapeConv)来处理深度特征。该方法首先将深度图像特征分解为形状分量和位置分量,然后引入两个可学习的权值分别作用于这两个分量,最后对这两个分量的加权组合进行卷积。该方法能够更为高效地利用深度图像特征中与目标语义相关的信息,进而提升语义分割精度,此外,这种形状感知卷积层还具有即插即用的能力,能够直接集成到任意卷积神经网络中。
⑤蒋介石自己也承认,“国府成立以来,各种设施,百分之九十九悉依汉民之主张”(《国府纪念周蒋主席报告胡辞职经过》,《大公报》1931年3月6日,第1张第3版)。
3 客观评测指标和数据集
3.1 常用客观评测指标
为了分析基于深度学习的多模态图像语义分割算法,同时实现各算法性能间的直观比较,客观评测指标是必不可少的。与基于深度学习的RGB 图像语义分割算法所采用的客观评测指标类似,准确率、实时性以及复杂度通常用于综合评估基于深度学习的RGB-D∕RGB-T 图像语义分割模型。考虑到模型推理精度与速度之间的矛盾,参考以上3 种客观评测指标,研究人员可以在语义分割精度满足实际需求的情况下,根据硬件要求选择合适的模型进行部署。
1)准确率。对于多模态图像语义分割任务,用来衡量模型精度的客观评测指标主要包括:类平均精度(mean accuracy per class,mAcc)和类平均交并比(mean intersection-over-union per class,mIoU)。其中,类平均精度也称为类平均召回率(mean recall per class),用来反映语义分割预测结果与真值标签对应像素位置的分类准确率,而类平均交并比则用来反映场景中目标的捕获程度(即语义分割预测结果与真值标签的重合程度)。由于现有的多模态图像语义分割数据集大多存在较为严重的类别不平衡问题,导致类平均精度可能难以准确反映模型性能,因此,类平均交并比是目前衡量模型分割精度最为关键的客观评测指标。
为了方便读者理解,本文通过混淆矩阵中真阳性(true positive,TP)样本、假阳性(false positive,FP)样本、真阴性(true negative,TN)样本和假阴性(false negative,FN)样本的角度来描述这些常用评测指标的计算方式。假设某个语义分割数据集中共包含n种类别的标注,对于第i个类别来说,真阳性样本表示真值标签(ground truth)为i且被模型正确预测为i的像素个数,假阳性样本表示真值标签不为i但被模型错误预测为i的像素个数,真阴性样本表示真值标签不为i且被模型正确预测其类别的像素个数,假阴性样本表示真值标签为i但被模型错误预测为其他类别的像素个数。
类平均精度首先在每个类内计算像素类别预测精度,再取所有类的平均值作为评测指标,具体为
类平均交并比则是在每个类内计算真实值与预测值的交集与两者并集的比值,具体为
2)实时性。除准确率外,语义分割模型的推理速度也是同样重要的,尤其是在工业级应用中,例如自动驾驶、地质监测等领域。对于模型本身来说,其推理速度往往取决于其计算量和参数量的大小,此外,模型推理速度还取决于硬件设备的计算能力。每秒传输帧数(frames per second,FPS)反映了模型每秒能够分割的图像数量,往往用来作为评估模型实时性的重要评测指标。
3)复杂度。模型复杂度与其实时性是密不可分的,若模型复杂度较高,其实时性往往较差。模型复杂度通常包含模型时间复杂度和模型空间复杂度。其中,时间复杂度能够通过模型浮点运算数量(floating point operations,FLOPs)反映,即模型的运算次数;而空间复杂度则通过模型的参数数量(parameters)反映。如果模型的复杂度较高,在实际应用中,往往需要更多的训练数据以及较高的硬件设备要求,才能满足模型训练和推理效率。
3.2 常用数据集
近年来,随着深度相机和热成像仪的普及以及图像配准技术的发展,获取与RGB 图像配准的深度图像和热红外图像已不再困难。
3.2.1 RGB-D图像语义分割数据集

图9 NYUD v2数据集示例图Fig.9 Examples of NYUD v2 dataset
2)SUN-RGBD(scene understanding-RGB-D)。SUN-RGBD 数据集是普林斯顿大学提出的一个有关室内场景理解的RGB-D 图像数据集。该数据集共包含10 335 组不同场景的室内RGB-D 图像,其中训练集、验证集和测试集分别包含2 666、2 619 和5 050 组配准的RGB-D 图像,平均每幅图像中包含14.2个目标。这些图像涵盖47个不同的室内场景,包含800 种像素级目标类别标注,如床、椅子、镜子、沙发、冰箱、窗户、人等,在RGB-D 图像语义分割任务中,现有方法均采用其中的38 类标注目标进行模型训练和测试。其规模远大于NYUD v2 数据集。SUN-RGBD 数据集和NYUD v2 数据集均是目前RGB-D 图像语义分割领域最为常用的数据集,该数据集样例如图10所示。
3.2.2 RGB-T图像语义分割数据集
1)MFNet(multi-spectral fusion network)数据集。在早期,热成像仪主要用于军事相关领域。Ha 等人(2017)提出了第1 个公开的大规模RGB-T 图像语义分割数据集MFNet用于城市场景理解。该数据集包含1 569 组配准的RGB-T 图像,其分辨率均为640 ×480 像素,其中,白天图像为820 组,夜间图像为749 组。同时,该数据集还提供了城市街道场景中常见的9 类目标标注,分别为背景、三角锥、人、挡车器、路缘石、自行车、汽车、凸起和护栏,能够应用于自动驾驶领域的模型训练。MFNet 数据集是目前RGB-T 图像语义分割领域最常用的数据集,该数据集样例如图11所示。

图11 MFNet数据集示例图Fig.11 Examples of MFNet dataset
2)PST900(PENN subterranean thermal 900)。该数据集来自美国国防部高级研究计划局(Defense Advanced Research Projects Agency,DARPA)地下挑战赛,主要包含洞穴和矿井下的真实场景。该数据集包含894 组配准的RGB-T 图像,同时还包括5 类像素级目标类别标注,分别为背景、手摇钻、背包、灭火器和幸存者,该数据集样例如图12所示。
3.3 算法性能分析与比较
1)根据已有文献公开结果,基于深度学习的RGB-T图像语义分割算法在MFNet数据集上的性能比较如表1 所示。可以看出,在基于图像特征增强的方法中,FEANet(Deng 等,2021)的语义分割准确率最高,在MFNet 数据集上mAcc 和mIoU 分别达到了73.2%和55.3%。这类方法通过设计一系列的图像特征增强策略,能够从包含大量噪声以及干扰信息的图像特征中挖掘并增强具有更高鉴别力的特征,进而为语义分割预测提供更为明确且精细的场景信息。此外,PSTNet(Shivakumar 等,2020)的性能远低于其他两种方法,这意味着通过增强输入图像间接实现图像特征增强的方式不如直接对图像特征进行增强有效,但是,其优点在于网络结构更为简单,模型复杂度较低,对某些实际应用场景具有一定的参考价值。在基于多模态图像特征融合的方法中,GMNet(Zhou等,2021b)的语义分割准确率最高,在MFNet 数据集上mAcc 和mIoU 分别达到了74.1%和57.3%。这类方法往往能够取得较高的语义分割精度,通过利用RGB 图像特征和热红外图像特征间的互补特性,能够有效弥补单一模态图像存在的缺陷,在不良光照及天气条件下显著提升语义分割精度。在基于多层级图像特征交互的方法中,MFFENet(Zhou等,2022)的语义分割准确率最高,在MFNet 数据集上mAcc 和mIoU 分别达到了74.3%和57.1%。这类方法通过多层级图像特征的交互挖掘丰富的上下文信息,对于场景中不同尺度的目标都有良好的分割表现,进而显著提升模型语义分割精度。从表1 可以看出,在MFNet 数据集上,目前性能最优的算法是GMNet 和MFFENet。此外,部分方法还存在mIoU 较高但mAcc 较低的现象,如AFNet(Xu等,2021)和MMNet(Lan 等,2022)。由于MFNet 数据集中存在严重的类别不平衡问题,例如,标签类别为护栏的像素数目仅占总像素的0.095%,这使得护栏这一类的Acc 很难得到准确评估,进而导致mAcc难以准确反映模型的性能。相比之下,mIoU 的结果则更具参考性。

表1 不同RGB-T图像语义分割模型在MFNet数据集上的性能比较Table 1 Performance comparisons of different RGB-T semantic segmentation methods on the MFNet dataset
2)基于深度学习的RGB-T 图像语义分割算法在PST900 数据集上的性能比较如表2 所示。在基于图像特征增强的方法中,EGFNet(Zhou 等,2021a)性能最优,在PST900 数据集上能够达到mAcc 94.02%和mIoU 78.51%的准确率。在基于多模态图像特征融合的方法中,GMNet(Zhou 等,2021b)性能最优,在PST900 数据集上达到了mAcc 89.61%和mIoU84.12%的准确率。在基于多层级图像特征交互的方法中,MFFENet(Zhou 等,2022)性能最优,在PST900 数据集上达到了mAcc 75.60%和mIoU 78.98%的准确率。从表2 结果可以看出,EGFNet 的mAcc最优,而GMNet 的mIoU最优。

表2 不同RGB-T图像语义分割模型在PST900数据集上性能比较Table 2 Performance comparisons of different RGB-T semantic segmentation methods on the PST900 dataset
3)基于深度学习的RGB-D 图像语义分割算法在NYUD v2数据集上的性能比较如表3所示。在基于多模态图像特征融合的方法中,直观来看,RDFNet(Lee 等,2017)的mAcc 最优,达到了62.8%,而TCDNet(Yue 等,2021)的mIoU 最优,达到了53.1%。对比来看,通过设计更为有效的多模态图像特征融合模块,基于多模态图像特征融合的方法性能逐年提升。相对于早期利用求和或级联等简单融合方式的模型,针对RGB-D 图像互补特性精心设计的融合策略能够挖掘两种模态图像中的有效信息,进而显著提升语义分割准确率。特别地,以抑制深度图像噪声及干扰信息为侧重点的SA Gate(Chen 等,2020)和TCDNet(Yue 等,2021)均取得了很好的性能,这得益于两者对深度图像成像特性的分析,进而更全面地发挥深度图像的优势。在基于上下文信息挖掘的方法中,GLPNet(Chen 等,2021)的mAcc 和mIoU 分别达到了66.6%和54.6%,不仅是该类方法中性能最优的,也是所有方法中性能最优的。已经证明的是,上下文信息无论是在单模态图像语义分割任务还是多模态图像语义分割任务都能够显著提升模型性能,通过挖掘上下文信息,模型能够更好地感知场景中不同尺度的目标,因此,这类方法在目标尺度及种类繁杂的复杂场景下往往有较好的表现。在基于深度信息引导的方法中,Zig-Zag(Lin 和Huang,2020)的mAcc 和mIoU 分别达到了64.0%和51.2%,是该类方法中最优的。这类方法将深度图像作为引导信息,不需要提取深度图像特征,大大降低了模型复杂度,使其在实际应用中更加灵活。但是,这类方法由于缺乏对深度信息的充分利用,其性能往往不如其他类方法。此外,该类方法往往还需要比其他类方法更复杂的预处理流程,这也是实际应用过程中所要面临的挑战。例如,Zig-Zag 需要统计数据集中深度值的范围,再人工设定相应的阈值区间以划分不同的场景。

表3 不同RGB-D图像语义分割模型在NYUD v2数据集上性能比较Table 3 Performance comparisons of different RGB-D semantic segmentation methods on the NYUD v2 dataset
4)部分基于深度学习的RGB-D 图像语义分割算法在SUN-RGBD 数据集上的性能比较如表4 所示。在基于多模态图像特征融合的方法中,以mAcc为参考指标,RDFNet(Lee等,2017)达到了60.1%的最优性能,以mIoU 为参考标准,TCDNet(Yue 等,2021)达到了49.5%的最优性能。在基于上下文信息挖掘的方法中,GLPNet(Chen 等,2021)性能最优,其mAcc和mIoU分别达到了63.3%和51.2%。在基于深度信息引导的方法中,Zig-Zag 的性能达到了mAcc62.9%和mIoU51.8%。从表4 结果可以看出,在所列举的方法中,GLPNet的mAcc最优,而Zig-Zag的mIoU最优。
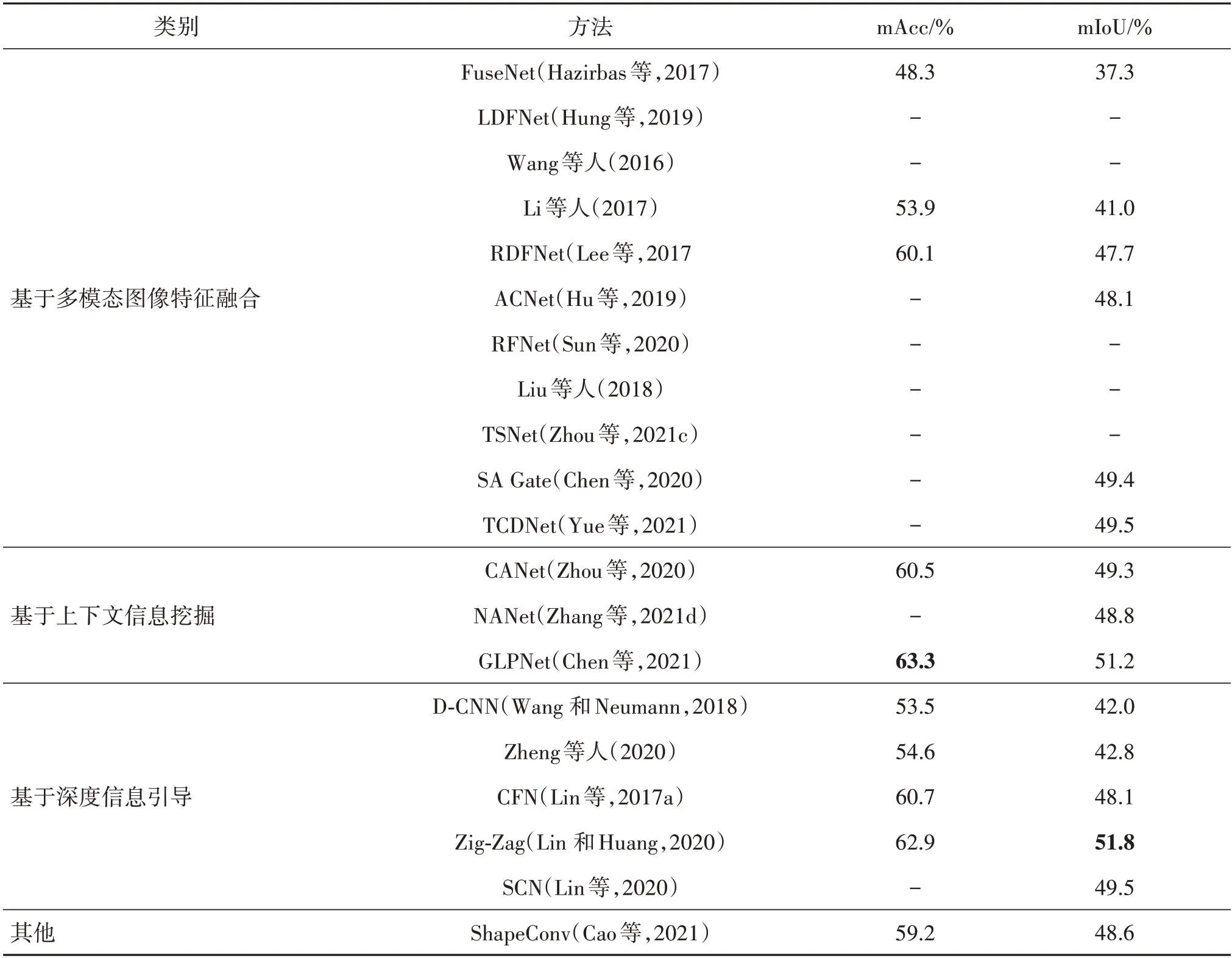
表4 不同RGB-D图像语义分割模型在SUN-RGBD数据集上性能比较Table 4 Performance comparisons of different RGB-D semantic segmentation methods on the SUN-RGBD dataset
4 研究展望
本文从目前已有算法的核心思想出发,详细介绍了基于深度学习的RGB-D 图像语义分割算法和RGB-T图像语义分割算法的研究现状。随着传感器技术与深度学习技术的不断发展,未来的研究方向包含但不局限于以下几个方面。
1)可见光—点云(RGB-point cloud)语义分割。相较于深度图像,点云数据包含更多三维场景信息。然而,点云数据与RGB 图像存在着巨大差异,如何将三维的点云数据中所包含的信息与二维的RGB图像信息结合,以利用两者的互补特性,是未来的研究方向之一。
2)可见光—深度—热红外(RGB-D-T)图像语义分割。由于成像机理不同,RGB 图像、深度图像以及热红外图像都有着各自独特的优势,如何利用三者之间的互补特性联合实现场景信息感知,进而在多样化场景下获取精确的语义分割结果,是未来的研究热点之一。
3)多模态图像实时语义分割。现有方法在语义分割准确率方面已经取得了显著提升,然而,在自动驾驶、视频监控等实际应用领域,不仅对算法的准确率有着较高的要求,还对算法参数量以及推理速度有着严格的限制。因此,如何平衡模型性能和推理速度之间的矛盾,在保证语义分割准确率的情况下,利用轻量化等技术简化模型,提升模型推理速度,是未来实际生产生活中所必须考虑的问题之一。
4)多模态视频语义分割。视频中所包含的时序信息是图像所没有的,在智能交通、智能监控等实际应用中,帧与帧之间的关系往往能够帮助模型更好地实现场景理解。目前还鲜有RGB-D∕RGB-T 视频语义分割的工作,未来仍需对该领域进一步探索。
5)其他多模态图像语义分割。除RGB-D∕RGBT 图像语义分割两种主流的多模态图像语义分割任务外,多模态图像语义分割还包括可见光—偏振(RGB-polarization,RGB-P)图像语义分割、可见光—事件(RGB-event,RGB-E)图像语义分割等。偏振光图像和事件图像等同样能够为RGB 图像补充不同类型的场景信息,具有提升模型场景理解能力的潜力。
6)弱监督∕半监督∕无监督学习。由于多模态图像间的互补特性,其标注工作需要耗费比单模态图像更高的人力及时间成本。考虑到目前基于RGBD∕RGB-T 图像的语义分割数据集仍面临数据量较少、标注困难以及场景较单一等问题,基于弱监督∕半监督∕无监督学习的多模态图像语义分割研究是未来主要的发展趋势之一。
5 结语
随着传感器技术以及图像配准技术的不断发展,以RGB-D 图像语义分割和RGB-T 图像语义分割为代表的多模态图像语义分割逐渐成为计算机视觉领域的研究热点之一。首先,本文详细论述了目前基于深度学习的RGB-D 图像语义分割算法和RGBT 图像语义分割算法,并对它们进行全面分类和比较。其次,本文介绍了多模态图像语义分割领域常用的客观评测指标以及数据集,并对现有方法在各个数据集上的性能进行了整理以及对比分析。最后,本文还对多模态图像语义分割未来的研究方向进行思考与展望,以期为广大研究者提供一些参考和帮助。
