基于Altmetrics的睡美人文献识别方法研究
2023-11-21陈华芳
向 菲,陈华芳,沈 桐,2,曹 广,刘 艳
(1. 华中科技大学同济医学院医药卫生管理学院,武汉 430030;2. 华中科技大学同济医学院附属同济医院,武汉 430030;3. 浙江省人民医院,杭州 310014)
互联网和社交媒体平台的发展,使学术成果的传播渠道得到进一步拓展,除传统的期刊、图书形式外,社交软件、学术博客、视频、论坛等成为学术成果传播的新渠道。传播渠道的拓展将学术成果的受众范围从同行业的学者扩大到社会大众,学术成果影响力的体现形式也不仅局限于传统的文献被引频次,还包括社交媒体平台上的转发、收藏、评论、反馈等[1]。Altmetrics 正是对社交媒体平台上学术成果使用情况的测量。从本质上看,Altmetrics 和被引频次均是对学术成果影响力的计量,那么,由于论文内容早熟、超前、颠覆等原因导致在引文中出现的“睡美人”现象,在Altmetrics 中也同样存在。因此,仅从引文、学术影响力的角度定义“睡美人文献”是不全面的,睡美人文献的概念、识别方法需要从Altmetrics 的角度进行补充。
睡美人文献通常是富有价值的文献,但一开始并不为人所知,导致知识浪费。社交媒体平台具有用户体量大、覆盖范围广、传播速度快等特点,实现Altmetrics 睡美人文献的早期识别,有利于充分挖掘文献价值,提高文献利用率;有助于知识在社交媒体上的快速传播,缩短公众科学认知时滞,提升公众智慧;可以反映公众对于科学的关注,激发学者研究兴趣。识别现有的睡美人文献,是实现睡美人文献早期识别的第一步。只有准确地识别出睡美人文献,才能进一步分析睡美人文献的沉睡原因以及检验睡美人预测模型的效果。
1 研究背景
1.1 睡美人文献
睡美人文献最早被称为“阻滞发现”(resisted discovery)。1961 年,Barber[2]发现,因为一些文化和社会原因,科学家们会对一些科学发现产生抵制。后来,Stent[3]认为这类科学发现远超当时背景下科学家们的认知水平,与公认的知识不一致或无法在技术上被证实,属于早熟的、超前的,于是将这类发现称为“早熟发现”(premature discovery)。1980 年,Garfield[4]在总结这两类发现的基础上,提出了“迟滞承认”这一概念,是指这些论文在发表之后被闲置或不受重视,直至多年后被“重新发现”(承认),重新发现的过程可能是渐进的,也可能是突然的。2004 年,van Raan[5]引用经典童话故事“睡美人”,定义发表后长时间没有受到关注(“沉睡”)而后突然收获大量引用(“被王子唤醒”)的出版物为睡美人文献。
1.2 识别方法研究现状
目前,关于引文的睡美人文献识别方法已有较多研究,根据方法特性可将其大致分为4 类:人为参数类、客观指标类、曲线拟合类和数据变换类[6]。
Garfield[7]以平均数为基础,提出总被引频次高、前5 年及以上(最好10 年以上)的被引频次接近每年1 次的为睡美人文献。van Raan[5]制定了睡眠时间、睡眠深度和唤醒强度3 个指标用于识别睡美人文献。①睡眠时间:连续处于睡眠状态的时间为5~10 年;②睡眠深度:在睡眠期间,每年被引频次不超过1 时为深度睡眠,大于1 且不超过2 时为深度睡眠不足;③唤醒强度:被唤醒后连续4 年总被引频次大于20 则为苏醒,总被引频次越高,唤醒强度越大。
Costas 等[8]参考四分位数定义提出3 个指标:Year50%、P25、P75,将文献划分为普通论文、昙花一现、睡美人文献3 类,发现不同类型论文的引用过程不同。Wang[9]根据论文自发表后被引频次的积累过程提出“被引速率”。基于此,杜建等[10]结合年度累计被引频次的标准差概念,提出延迟承认指数(delayed recognition index,DRI)。Li 等[11]参考基尼系数提出了Gs 指数,计算睡眠文献觉醒的概率。Sun 等[12]对Gs 进行改进,提出文献老化向量,对睡美人文献的检测结果更加精准。Ke 等[13]提出了无参数指标“美丽系数”(beauty coefficient,B),用于量化一篇论文在多大程度上可以被视为睡美人文献。杜建等[14]对被引速率和美丽系数两种指标的识别结果进行对比分析发现,美丽系数只考虑了论文发表年至最高被引频次年的过程,而不是全部的引文窗口;被引速率反映了全部的引文窗口,但不能直接筛选出睡美人文献。因此,2018 年杜建等在美丽系数的基础上提出了一个新的无参数指标Bcp[15]。Teixeira 等[16]参考标准差概念提出了K 指数。同样考虑引用分布的离散程度,唐洁等[17]引入变异系数设计了PCV 指数(product of CVyearlyand CVaccumulative,PCV)。
宋呈玉等[18]为了能够更简便、快速地识别睡美人文献,将引用曲线均拟合为二次函数,根据函数对称轴与坐标轴的距离来识别睡美人文献。侯剑华等[19]则借助Logistic 曲线拟合引文累积曲线,设计累积引文睡美人指数(cumulative citation sleeping beauty index,Cc Index)。从曲线拟合类的识别方法中可以看出,指标的计算结果会受到曲线拟合效果的影响,对于给定的曲线模型,拟合效果差时计算结果会出现严重偏差,若在应用时加入拟合优度约束,则识别率下降。
1.3 小 结
目前基于引文的睡美人文献研究已经有了一定进展,而基于社交媒体角度的睡美人文献研究才刚刚起步[20-21]。Altmetrics 指标与被引频次并不完全相关[22-28],两类指标的累积情况也不完全相同[29],因此基于Altmetrics 的睡美人文献不能直接照搬基于引文的睡美人文献相关结论,两类睡美人文献的对比研究可能反映指标的差异,因此,研究基于Altmetrics 的睡美人文献是有必要的。
2 研究数据
2.1 数据来源
Altmetric.com 可以追踪文章在多个社交媒体平台上的关注,指标丰富,覆盖面广,共有15 个指标带有时间标签:News、Blog、Policy document、Patent、Twitter、Peer review、Facebook、Wikipedia、Google+ 、 LinkedIn、 Reddit、 Pinterest、 F1000、Q&A、YouTube。通过其提供的Altmetric Explorer获取文章,学科主题限定为“Medical and Health Sciences”,文献类型限定为“articles”,为保证文章至少有3 年的累积时间,限定发表日期在“2018-11-30”之前的文章。检索时间为2021 年12 月21日,检索到685 万余篇文章,其中475 万余篇文章拥有关注分值(Altmetrics attention score,AAS)。根据睡美人文献定义,睡美人文献一定具有高关注度,参考高被引论文的界定方法[30],选取关注度排名前1%的文章共47533 篇为高关注度文献(相同分值文献一并纳入)。由于Altmetric Explorer 每个指标只提供最新的1 万条关注信息,因此,舍去部分指标数据缺失的文章,研究实验集共47510 篇文献,数据获取时间为2021 年12 月21—25 日。
各指标值表示文章在不同来源平台上的关注计数。Altmetric.com 根据指标来源平台的影响覆盖范围赋予不同权重[31],AAS 的计算方法为
2.2 文献的关注累积特征
统计实验集中文章的关注累积过程所需时间,结果如表1 所示。有接近50%的文章的首次关注发生在发表前后一周内,约39%的文章在正式发表之前被提及,其中有接近3%的文章提前一年在社交媒体平台上被提及,可见社交媒体平台的发展使得文章可以更早获得关注,甚至可以在正式发表前得到关注。与引文相比,Altmetrics 对文献的关注反应非常迅速。全部文章中有14%的文章在发表后一年内才获得首次关注,主要是因为“Altmetrics”概念于2010 年才被提出,2010 年以前发表的文章约占总文章数的12.14%,彼时社交媒体平台还未发展普及,鲜有人在平台上交流学术论文。2010 年前发表的文章在发表一年后才得到首次关注的文章占比约80%,2010 年后(包括2010 年)每年发表的文章中一年后才获得首次关注的文章占比逐年下降(图1)。在2010 年后随着社交媒体平台的推广和使用用户的增长,文章在发表后一周内获得首次关注的比例呈上升趋势(图1),文章更及时地在平台上进行传播,受到关注的学术论文占比逐渐增加。从文章关注累积各阶段的平均时间也可以证明,虽然所有文章获得首次关注的平均时间为341.04 天,但2010 年后(包括2010 年)发表的文章平均时间约为-0.63 天。由此可见Altmetrics 对于文献关注的反应速度。
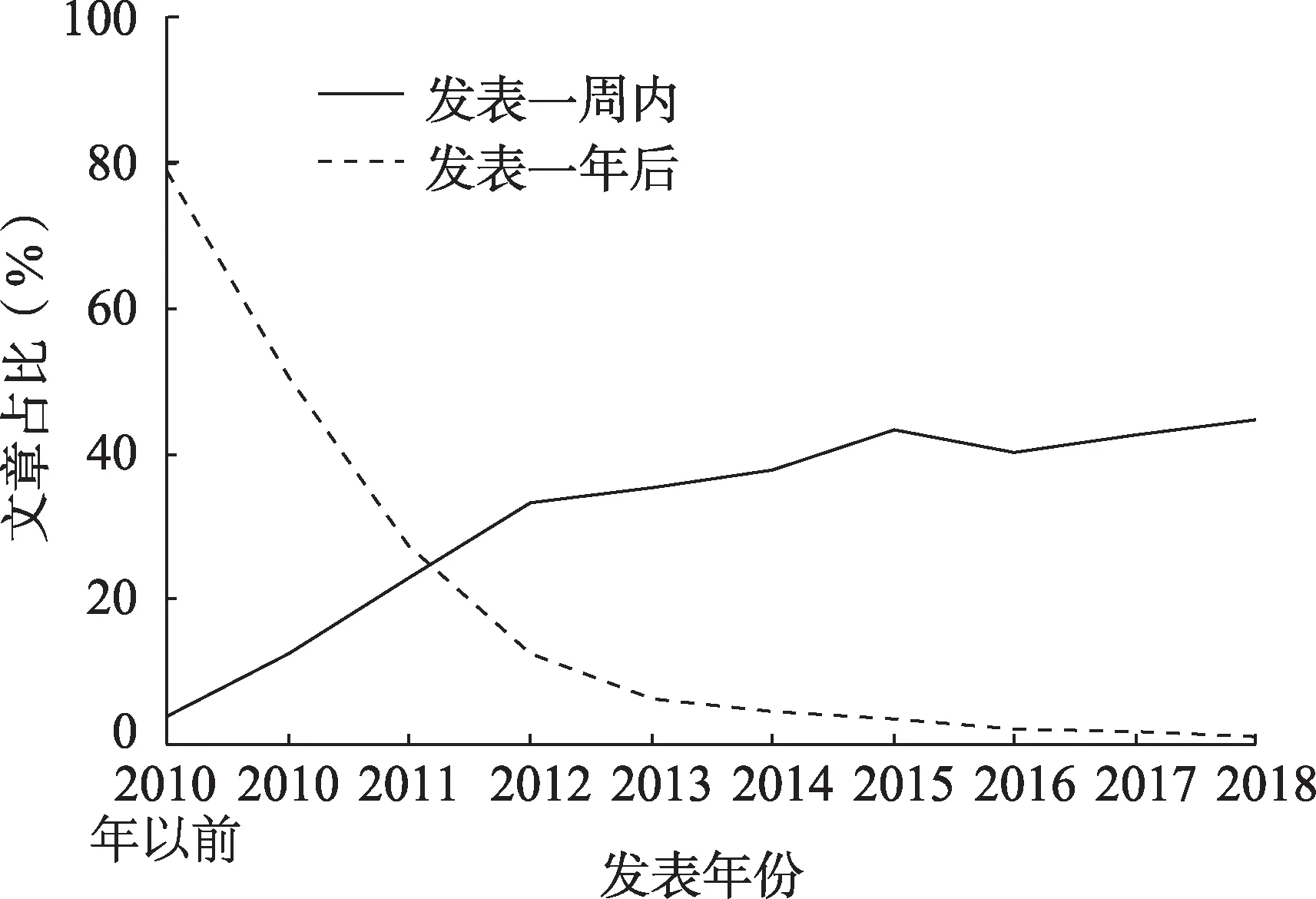
图1 不同年份文章正式发表后一段时间获得首次关注的比例
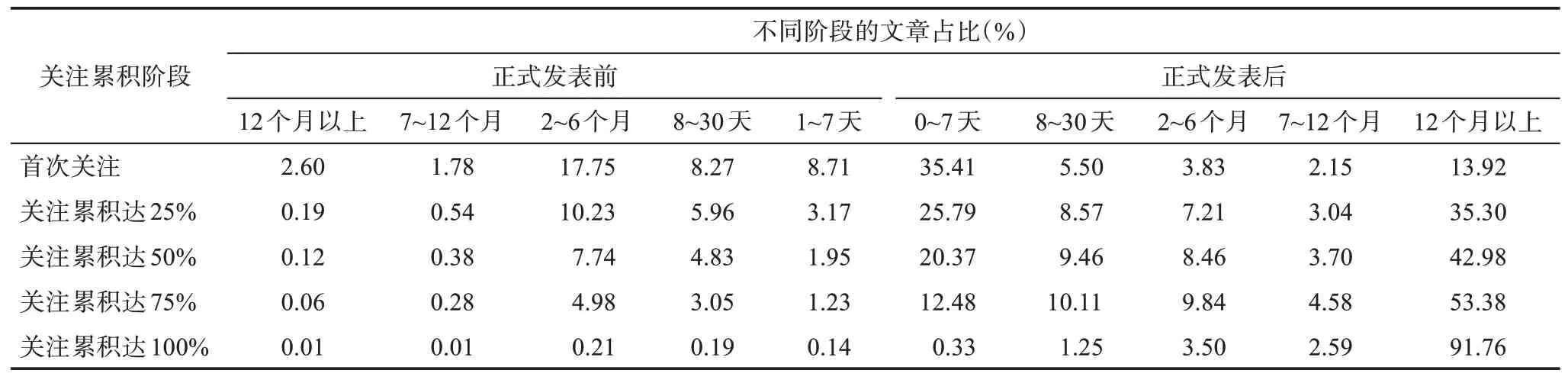
表1 关注累积达不同阶段所需时间的文章统计
文章从获得首次关注到关注累积达25%所需时间平均值为675.86 天,从25%到50%所需时间平均值为186.32 天,从50%到75%需227.91 天,从75%到100%需889.49 天。关注累积过程平均时间如图2所示,文章前期的关注积累比较缓慢,在有了一定关注基础后,关注累积速度会加快,达到关注高峰后慢慢减少至零,类似Logistic 曲线。
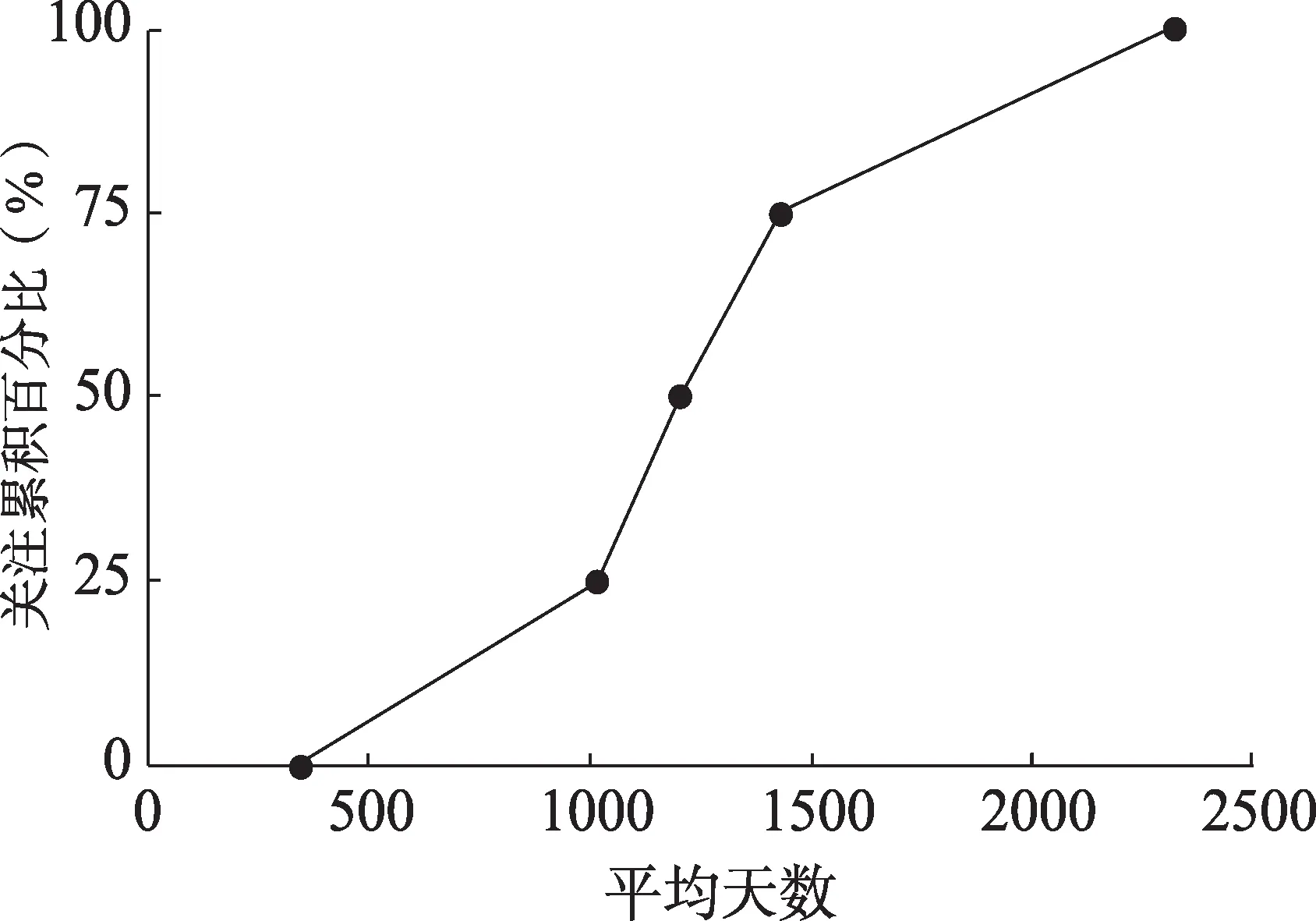
图2 文章累积关注的平均时间
在发表后一周之内累积25%、50%关注的文章约占25%、20%,由此可见,Altmetrics 能够及时反映文章的关注情况。若以周、月或年为单位观察关注变化,则无法反映关注的迅速累积和文章间的差异性,91%的文章在发表后一年以上才失去关注,若以小时为单位分析全部关注累积曲线则过于繁杂,故研究关注的累积变化过程以天为单位更合适。
3 基于Altmetrics 的睡美人文献识别方法设计
睡美人文献是指发表后长期没有受到关注,后突然被唤醒获得大量关注的文献。Altmetrics 主要体现的是文献在社交媒体平台上的受关注情况,因此,Altmetrics 睡美人文献是指在社交媒体平台上,获得关注的时间比普通论文更晚,唤醒后迅速累积大量关注的文献。参考基于引用的睡美人文献分析结果,Altmetrics 睡美人文献应具有以下特征:①具有较高关注度;②比普通论文更长的睡眠时间;③关注增长过程具有明显的“突增”特征。
在对于目前引文睡美人文献识别方法的学习基础上,本文以Altmetrics 睡美人文献的特征为核心,用无参数指标体现,设计了基于Altmetrics 的睡美人文献识别方法:Altmetrics 睡美人指数(Altmetrics sleeping beauty index,ASB 指数)。
3.1 四分位法与Bcp指数识别效果评价
目前有许多基于引文的睡美人文献识别方法研究,其中,四分位法和Bcp 指数避免了主观因素的影响,在识别时不会受到被引频次大小的限制,可以在不同的学科中推广使用,但分析识别结果发现其仍存在一些不足。
3.1.1 四分位法
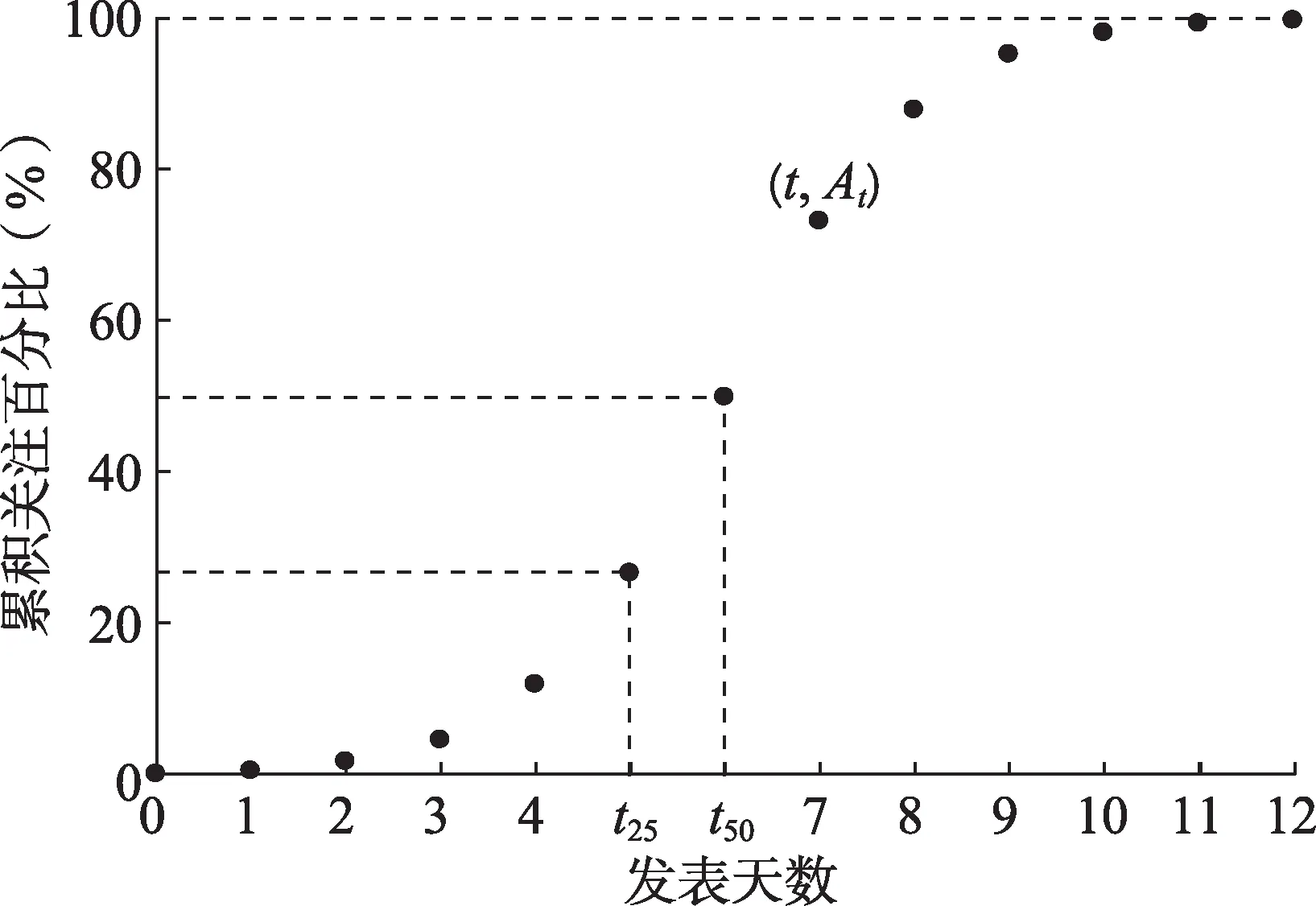
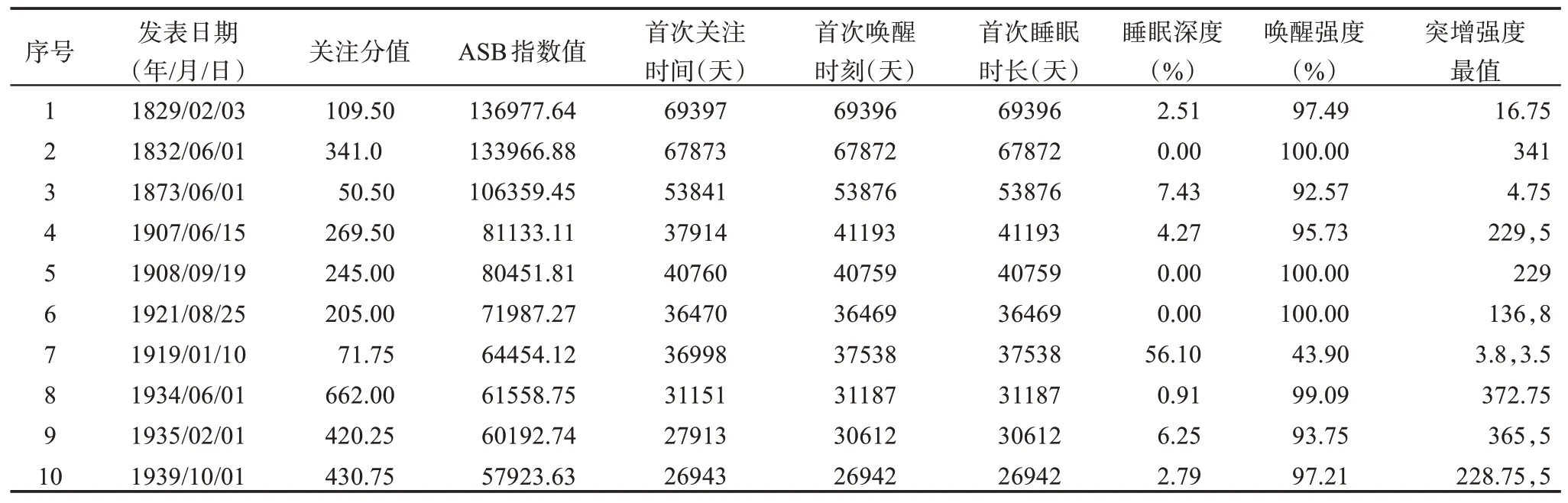
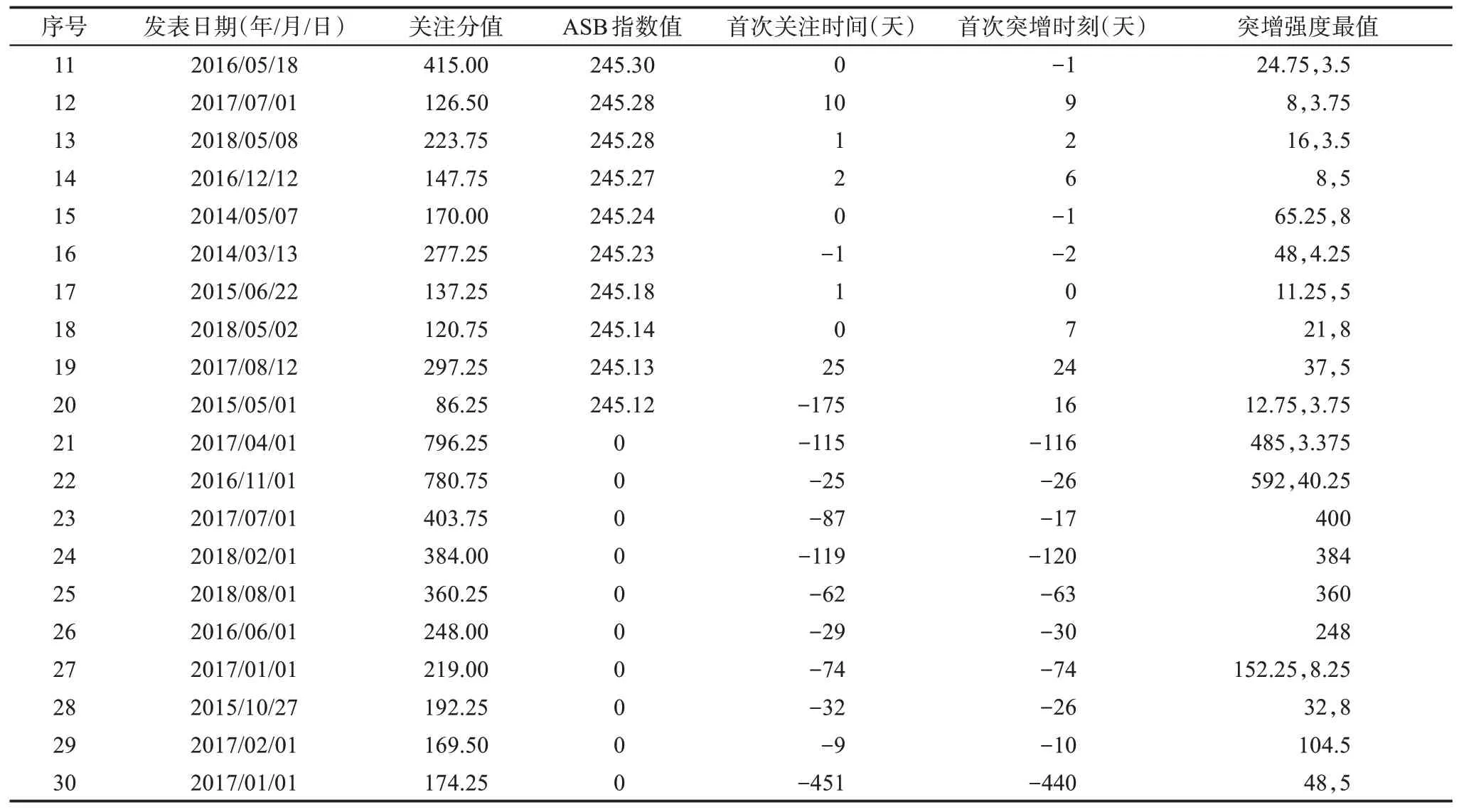
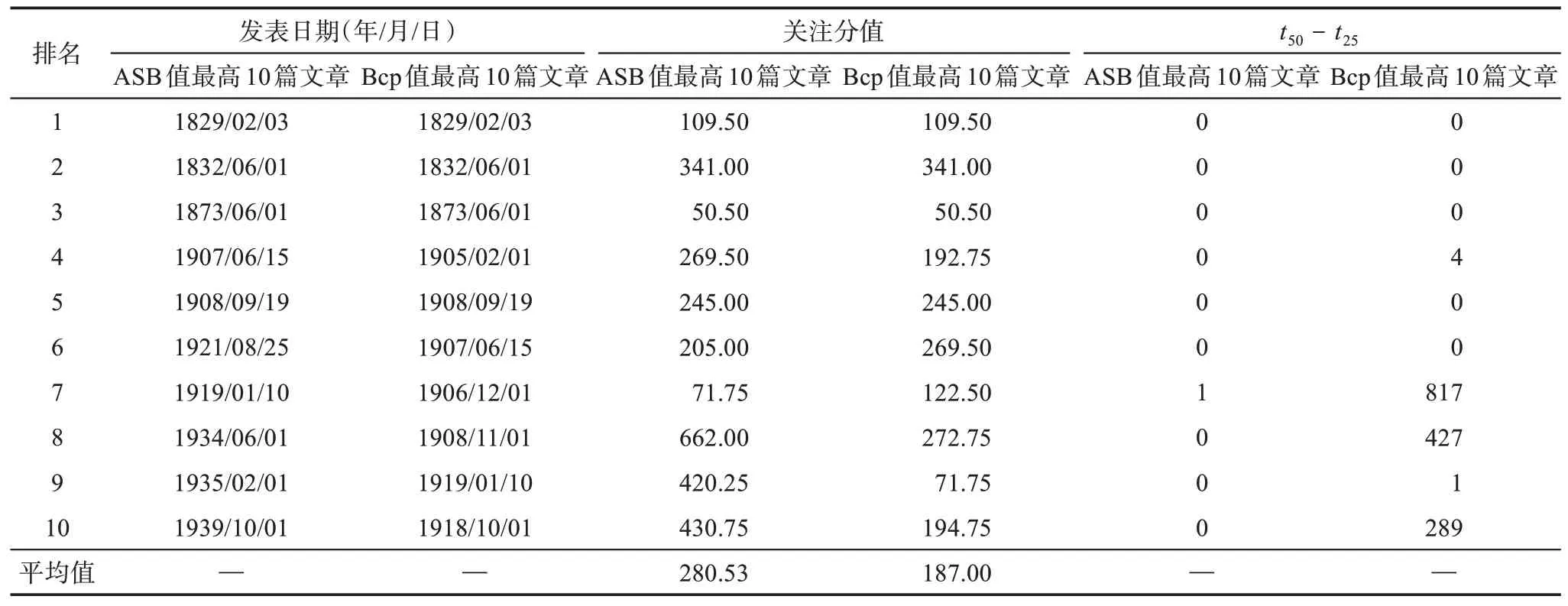
考虑到不同的年份、学科和文档类型的适用性,Costas 等[8]参考四分位数的定义提出了3 个指标:Year50%、P25、P75。其中,Year50%是指论文出版后累积引用首次达到50%的年份;P25、P75 是Year50%值的分布函数的四分位数,即同年同领域内累积引用达到50%较快的25%、75%论文所需的时间[8]。根据这3 个指标将文献划分为3 类:①普通文献,P25≤Year50%≤P75;②昙花一现文献:Year50% 虽然睡美人文献在不同学科中的存在比例有差异,但均应低于10%[32],更有学者认为睡美人文献的比例约为1%甚至更低[33]。然而,根据四分位法识别得到的睡美人文献约占25%,远大于10%,识别不够精确。 3.1.2 Bcp指数 杜建等学者认为,B 指数存在没有考虑全部引文窗口、忽视发表之初的被引情况、依赖总被引频次等问题,对其进行改进,并提出Bcp 指数[15]。 图3 为论文的年累积被引频次百分比曲线,ct是指论文年龄为t时的累积被引百分比,tm是指累积百分比为100%的时间,直线连接累积曲线的起点(0,c0)和终点(tm,1)两点做参考线l。计算直线l与曲线之间差值的总和,即lt-ct的总和,得Bcp 值,计算公式为 图3 Bcp指数示意图 Bcp 指数的计算依赖于图形的相对形状。如图3 所示,Bcp 指数默认文献的累积引文曲线为J 形,但侯剑华等[19]认为累积引文曲线呈逻辑曲线形增长。从实际情况来看,文献的累积引文曲线是复杂多样的,Bcp 指数在计算其他形式的引文曲线时,指数值可能会存在偏差。例如,在计算累积曲线为S 形曲线的文章的Bcp 指数时,曲线高于参考线的部分lt-ct的值为负,会削弱Bcp 指数值,对于已经完成唤醒再次陷入睡眠的睡美人文献识别效果不好。 通过实证检验发现,通过Bcp 指数识别得到的睡美人文献平均年龄较大[34]。在李贺等[35]的Bcp 应用研究中可以看出,Bcp 指数高的文献发表时间较早。例如,M 和N 两篇论文的累积引文曲线与参考线如图4 所示,可以看出,N 更符合睡美人文献的“突增”特点,但由于年龄较短,N 的Bcp 值为2.21,而M 的Bcp 值为11.86。Bcp 指数的计算结果会受到引文窗口长度的影响,在年龄相同或相近的文章中影响不明显,但是累积时间相差较多的文章进行比较时这种影响就会放大。对于Altmetrics 来说,论文的关注变化以天为单位,文章之间的时间差异大,这种误差不能忽略。 图4 论文M和N的Bcp指数示意图 基于上述对于四分位数和Bcp 指数的分析,以Altmetrics 睡美人文献的特征为核心,全面考虑累积曲线的可能形状,降低论文年龄的影响,本文设计了一种基于Altmetrics 的睡美人文献识别方法,称为Altmetrics 睡美人指数,简称ASB 指数。 3.2.1 ASB指数设计 睡美人文献最重要的两个特点是较长的睡眠时间和关注的突增,Altmetrics 睡美人文献也是如此[36]。Bcp 指数所用的差值总和可以体现睡美人文献的睡眠状况,考虑到关注累积曲线的多样,采用直线l:lt=1 作为参考线,如图5 所示。论文年龄为t时的累积关注百分比记为At,论文睡眠时1 -At值较大,随着关注的累积1 -At逐渐变小。对于Altmetrics 睡美人文献的识别来说,睡眠时间越长、睡眠深度越深,1 -At的差值总和越大。由于预印本等因素的存在,部分文献在正式发表之前,就已经在社交媒体平台上得到关注,为惩罚早期关注,只计算自发表之日(t=0) 起至关注累积百分比为100%时(tm)的差值总和,发表日期之前的差值不纳入计算。 图5 论文关注累积过程示意图 如果论文在关注累积百分比达到90%以后,在很长一段里偶尔获得少量关注,那么累积曲线会有很长一段“尾巴”接近于参考线,这可能会使1 -At的总和偏大,影响对Altmetrics 睡美人文献的识别效果。为了降低这种影响,使用指数函数对参考线与曲线间的差值进行转换,即e1-At- 1,扩大1 -At值的差距,使“尾巴”部分的值更接近于0,以降低影响。 选取论文关注累积首次达25%和50%的时间t25、t50,如图5 所示。t50-t25的值表示关注的突增情况,t50-t25的值越小,论文的关注累积越集中,突增越明显,且不会受到论文年龄的影响。 根据睡美人文献的特征,论文前期关注越少,睡眠时间越长,后期关注增加越突然,ASB 指数值越大,越有可能是睡美人文献。因此,计算∑(e1-At- 1)与t50-t25的比值,通过预实验结果对公式进行改进,得ASB 指数值计算方法为 对于t25、t50是同一天的文章,t50-t25的值取0.5。 3.2.2 唤醒时刻识别 睡美人文献在睡眠时遇到“王子”之后,受到的关注开始大量增加,即唤醒。Altmetrics 睡美人文献的唤醒时刻,也是关注的突增时刻,唤醒前关注少,唤醒前后关注的增长量大、增长速度快,还可能出现连续增长[36]。张靖雯等[37]对比多种引文“起飞”时刻识别方法的正确率发现,人为参数法对于睡美人文献唤醒时刻的识别正确率最高,年度引文增长率指标次之,还可以识别多次唤醒时刻。在此基础上,结合睡美人文献的唤醒特征,对Altmetrics睡美人文献唤醒时刻的识别方法进行设定。 以图6 睡美人文献的关注分布为例,at表示文章第t天获得的关注,当at为唤醒时刻时,唤醒前关注为0 或接近于0,at值小,唤醒后呈现大量增长,at+1应该远大于at。将唤醒时刻(t,at)分别与前后两点(t- 1,at-1)、(t+ 1,at+1)连线,两条连线的斜率差距应该较大。Eom 等[38]识别引文爆发时认为年引文增长率大于3 则为爆发增长,参考年引文增长率指标设定关注增长率指标r,在利用r识别突增时也以3 为标准。Altmetrics 睡美人文献的唤醒时刻t的具体计算方法为 图6 睡美人文献的关注示意图 考虑到at作为分母时可能等于0,对于小于1 的分母,at取1。 人为参数法的正确率高,但识别率低[37],对于采用公式(4)没有识别出唤醒时刻的文章,可以考虑删去条件at-1< 3、at< 3 后重新进行识别。 通过实证检验结果验证ASB 指数对Altmetrics睡美人文献的识别效果。首先,计算实验数据中所有文章的ASB 指数值;其次,根据ASB 指数值大小排序后选取不同排名位置的文章;最后,从关注累积曲线、指标特征两个方面进行比较,分析ASB指数的有效性。 将实验数据的指数值从大到小排列,ASB 指数值的分布情况如图7 所示,约80%的数据分布在[0,1500],头部数据分散,符合睡美人文献数量少的特征,ASB 指数值最高的10 篇文章值均大于57000。 图7 ASB指数分布 按照排序结果分别取ASB 值最高、中位、末位各10 篇文章,其关注累积曲线如图8 所示。 图8 30篇文章的关注累积曲线 从累积曲线可以看出,ASB 值最高10 篇文章的累积曲线均呈凹形,自正式发表之后超过25000 天才获得首次关注,有很长的睡眠时间,唤醒后在短时间内迅速累积关注,几乎呈直线上升,关注增长速度快,增长量大。中位10 篇的首次关注发生在发表日期附近,早期就有一定的关注累积。由于ASB 指数为0 的文章有275 篇,采用随机数方法从中随机抽取10 篇代表排名末位文章,末位10 篇文章的关注均发生在正式发表之前,其中有6 篇的首次关注发生在发表日期的一个月以前,另外4 篇发生在发表前一周内。通过对比排名先后文章的关注累积曲线可以发现,最高10 篇文章的曲线睡美人特征最明显,中位10 篇次之,末位10 篇最差,ASB 指数识别睡美人文献的效果良好。 参考基于引文的睡美人文献特征指标拟定下列指标,用于衡量ASB 指数的识别效果。 (1) 睡眠时长:有多次唤醒的文章有多次睡眠。第一次睡眠时长是指自文章正式发表之日起至唤醒时刻的时间间隔。文章唤醒后关注量先上升后下降,若关注度持续1 天以上(不包括1 天)低于3,则认为文章再次进入睡眠。第二次睡眠时长是从第一次唤醒结束、再次进入睡眠时开始直至下一次唤醒时刻止计算睡眠时长,以此类推。 (2)睡眠深度:文章处于睡眠状态时所有关注量之和(包括唤醒时刻)占总关注的比值。 (3)唤醒强度:文章被唤醒后处于苏醒状态时关注量之和(不包括唤醒时刻)占总关注的比值。 (4)突增强度:即关注增长率,文章的每一次唤醒都有一个突增强度值。 计算ASB 值最高的10 篇文章的唤醒时刻,其中有5 篇文章存在多次唤醒,利用人为参数法可以识别出唤醒强度较低的时刻,识别准确率更高。ASB 值最高10 篇文章的睡美人文献特征指标结果如表2 所示。对于有多次唤醒的文章,仅保留第一次唤醒时刻和睡眠时长,突增强度保留最值。由于大多数中位10 篇和末位10 篇中文章的关注发生时间早于正式发表时间,因此,不计算睡眠时长、睡眠深度、唤醒强度。根据唤醒时刻的计算方法计算突增时刻,中位10 篇和末位10 篇文章的关注累积特征如表3 所示。表2 和表3 中突增强度的最大值为592,最小值为3.375,文章的突增强度差距大,文章关注的累积形式不同,正如Garfield[4]所述,重新发现的过程可能是渐进的,也可能是突然的。 表2 ASB值最高的10篇文章的睡美人文献特征指标结果 表3 中位10篇和末位10篇文章的关注累积特征 由表2 可知,指标最高10 篇文章中,除第7 篇外,其余文章的睡眠深度均小于10%,符合睡美人文献睡眠时关注度低的特征;唤醒强度均大于90%,符合睡美人文献唤醒后关注大量增长的特征;唤醒强度与睡眠深度差距不大,首次睡眠时长从上到下呈递减状态,表明ASB 指数可以有效根据睡眠时长排序文献可能成为睡美人文献的概率。与第6 篇相比,虽然第7 篇睡眠时长更长,但由于睡眠深度、唤醒强度、突增强度比较低,所以,第7篇的ASB 指数比第6 篇低。 由表3 可以看出,中位10 篇文章的首次突增时刻在发表日期前后,均小于30,即在发表后的一个月内就在社交媒体平台上受到关注;末位10 篇文章的首次突增时刻均为负数,即在文章正式发表之前,就已经得到大量关注;表2 中最高10 篇文章的唤醒时刻为发表后70~190 年,远超另外两组文章,满足睡美人文献睡眠时间长的特征。从最高10 篇文章的排序结果和睡美人文献指标特征来看,ASB指数识别效果良好。 计算实验集中所有文章的Bcp 值,分别选出ASB 值、Bcp 值最高的10 篇文章,其特征如表4所示。 表4 ASB值、Bcp值最高的10篇文章特征 由表4 可以看出,相较于Bcp 值最高的10 篇文章,ASB 值最高10 篇文章的发表时间较晚,t50-t25较小,符合3.1.2 节的论述,Bcp 指数的计算结果会受到引文窗口长度的影响。ASB 值最高10 篇文章的关注分值平均值高于Bcp 值,更符合睡美人文献具有重要价值的特征。ASB 值最高10 篇文章的t50-t25为0 或1,与Bcp 值最高10 篇文章相比,ASB 值的关注突增更明显。与Bcp 指数相比,ASB指数考虑了Altmetrics 指标及时性强、反应快的特点,更适用于识别基于Altmetrics 的睡美人文献。 最高10 篇文章的睡眠深度平均值为8.03%,唤醒强度平均值为91.97%,杜建等通过Bcp 指数识别出的引文睡美人样本集的睡眠深度平均值为28%[15],从侧面反映了Altmetrics 指标的关注分布更为集中,基于引文的睡美人文献识别方法不能直接应用于Altmetrics。 本文选取累积时间足够长的实验数据用于分析Altmetrics 指标的累积特征,根据观察结果选取合适的时间单位用于睡美人文献的识别方法设计。根据基于Altmetrics 的睡美人文献的特征,本文选取论文年龄为t时的累积关注百分比At,论文关注累积首次达25%和50%的时间t25、t50,用于设计基于Altmetrics 的睡美人文献识别方法ASB 指数。以高关注度文献作为实验数据,比较ASB 值最高、中位、末位各10 篇文章的关注累积曲线和指标特征,研究结果表明,ASB 指数对基于Altmetrics 的睡美人文献识别效果良好。 本文存在一些不足:①很多文献会提前在线上发布,并不是等到发表之日才公开,但由于无法获取文献的具体上线时间,本文在计算过程中采用文献的正式发表日期作为发布时间。后续研究可以考虑跟踪一段时间内的文献发布情况,以获取准确的文献发布时间。②目前,文献在社交媒体平台上的传播还没有完全普及,仍然有大量的文献没有关注分值,即使是排名前1%的文章关注分值也比较低。随着社交媒体平台的发展和用户知识水平的提升,当公众逐渐认识并主动关注学术成果时,可能会有越来越多的论文在社交媒体平台上得到关注,学者们也更愿意在平台上分享科研成果。在后续研究中可以尝试加入引文数据,将基于Altmetrics 的睡美人文献分析结果与引文分析结果相互引证。未来需要进一步验证ASB 指数在不同学科、不同平台以及中文环境下的有效性。睡美人文献具有重要价值,后续需要对睡美人文献进行唤醒过程与文献特征分析,发现更多的早期识别线索,实现睡美人文献的早期识别。

3.2 ASB指数设计与唤醒时刻识别
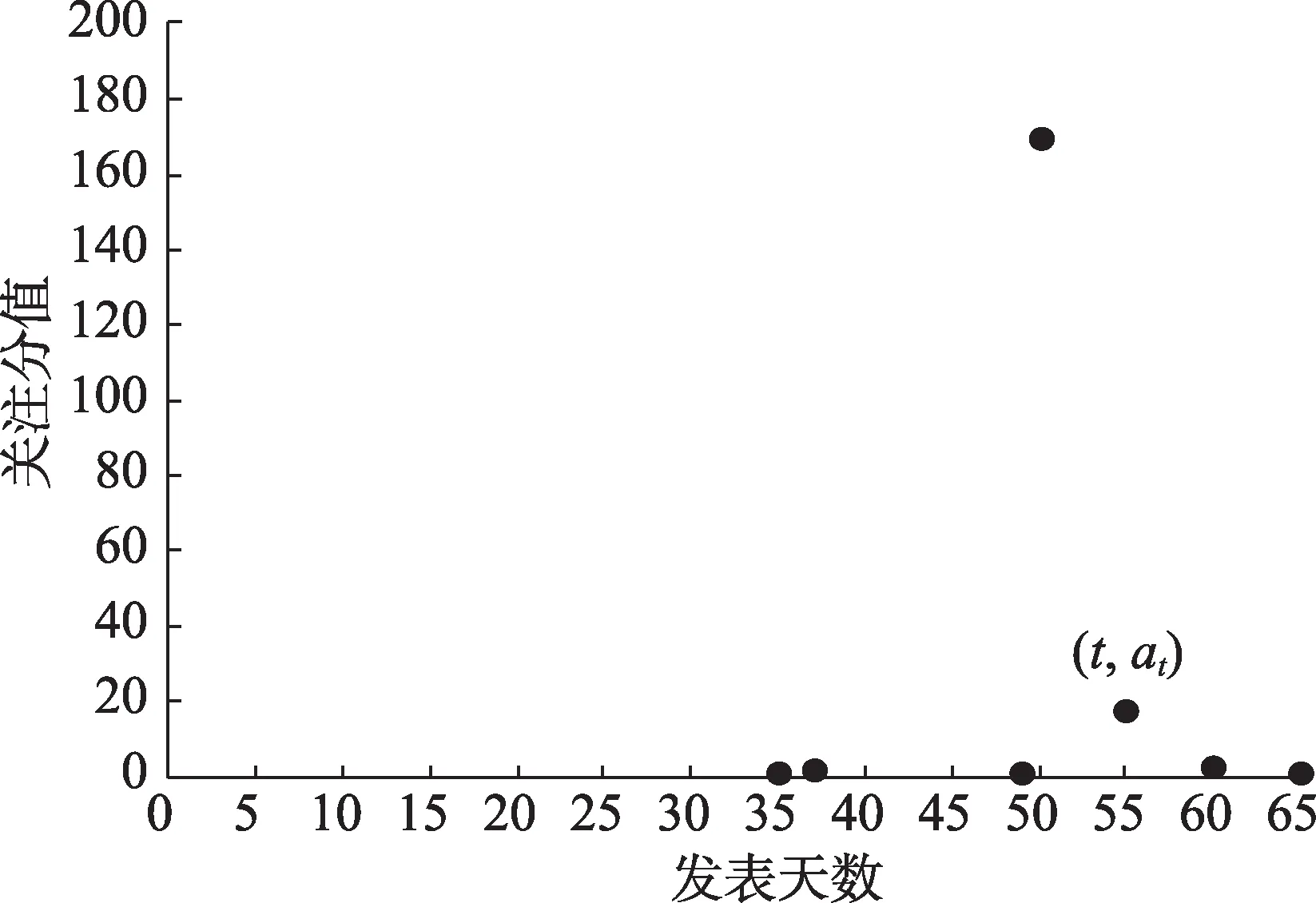
4 ASB指数识别效果检验

4.1 关注累积曲线
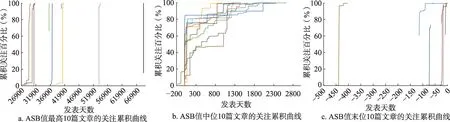
4.2 指标特征
4.3 与Bcp指数识别结果对比
5 结 论
