基于后缀向量拼接的军事装备命名实体识别
2023-11-20谢德鹏邹华懿刘进才
谢德鹏,王 佳,邹华懿,刘进才
(北京计算机技术及应用研究所,北京 100854)
0 引言
命名实体识别(named entity recognition,NER)是自然语言处理(nature language processing,NLP)中的一项基本研究工作[1]。最早是在MUC-6(message understanding conference)上引入这一评测任务,作为信息抽取技术的子课题供广大学者讨论研究。实体识别旨在识别出自然语言文本中的专用名词和有意义的数量短语,并加以分类,是信息提取、知识图谱构建、信息检索、智能问答、句法分析、机器翻译等众多NLP 任务的重要基础工作。
随着军事领域对智能决策和大数据赋能的重视,对情报、文书等军事文本的自动化分析和整合速度及准确度提出了更高要求[2],军事实体识别作为文本分析的基础工作,也在这一过程中显得愈发关键。常见的军事实体识别内容主要包括军事装备、物资、设施,机构(包括部队番号)以及军事地点、军衔等[3]。基础的基于字典和规则的实体识别方法虽然稳定可靠,但是迁移性和自动学习能力较差,并且需要耗费大量人力和时间,已经无法满足目前文本处理分析自动化和智能化的需要。为解决以上问题,研究者引入了神经网络算法进行装备实体识别,并且充分利用军事文本语义信息和结构信息实现实体识别。通过分析发现,军事实体虽然种类较多,但军事实体语义结构组成之间具有很大规律性。本文以军事装备实体的识别为主要研究内容,通过BERT 预训练模型生成字向量、词向量与装备实体后缀特征向量进行拼接,实现文本语义信息和后缀特征的应用,进而提升军事装备实体识别的准确率。本文方法对其他种类军事实体识别具有很大借鉴和参考意义。
1 相关工作概述
1.1 命名实体识别
目前命名实体识别的研究主要集中在互联网和金融、医疗等领域,在军事领域的研究起步较晚,特别是军事装备更新换代的频率较快、新式装备层出不穷,且部分装备的别名和简称较多,容易造成识别错误。装备实体识别作为军事文本分析和装备知识图谱构建的基础性工作,装备识别的高准确率和召回率对军事文本智能分析、军事装备知识问答和文电态势分析具有重要作用。
装备实体识别从早期基于词典和规则的方法,到传统机器学习的方法,再到后来基于深度学习的方法,包括LSTM、Bi-LSTM-CRF、BERT 等研究方法,装备实体识别技术路线随着时间在不断发展。
在实际应用中,基于词典的方法和基于规则的方法,通过前期构建实体字典和标识规则与文本进行匹配,从而实现实体的识别,其识别结果在一定程度上依旧较为可靠和有效,但是前期需要投入大量人员和时间,整体可移植性较差,面对新的装备实体和未收录的装备名称、别称时,单纯依靠此种方法效果较差。
机器学习方法主要通过人工标注语料进行有监督的学习,利用人工设计和挑选的特征信息训练后机器学习模型进行实体的预测,通过将命名实体识别转化为序列标注进行实现。其常用算法和模型包括:隐马尔可夫模型(hidden markov models,HMM)、最大熵模型(maximum entropy models,MEM)、决策树(decision trees)、支持向量机(support vector machines,SVM) 和条件随机场(conditional random fields,CRF)等[4-8]。彭春艳等借助条件随机场集合生物单词构成特性完成生物命名实体的识别,识别效果良好[9];ZHOU 等利用基于HMM 的机器学习方法进行命名实体识别并分类名称、时间与数量,分别在MUC-6、MUC-7 测试识别任务中F1 达到96.6%和94.1%[4];QIN 等借助决策树算法进行汉语的未登录实体识别,并且利用成词概率、自由度、共现概率和互信息等知识进行训练,最终开放测试召回率69.42%,正确率40.41%[6]。然而机器学习方法仍需要大量人为工作,而后深度学习方法的出现改变了现状。
基于深度学习方法的实体识别利用端到端方式自动学习句子语义特征[10],人工介入工作量更少,特征工程量更小,目前已经成为实体识别的主流方法,但深度学习的方法依旧存在领域迁移性和可解释性差等问题。主要利用的方式包括基于卷积神经网络的方式(convolutional neural networks,CNN)[11]、基于循环神经网络的方式(recurrent neural network,RNN)及相关变种的方式。MA 等利用CNN 进行文本字符及表征,然后将向量输入RNN 中进行命名实体识别,取得效果的提升[12]。 HAMMERTON 等借助长短时记忆网络LSTM 实现命名实体识别,LSTM 是RNN 的变种模型,实现了更好的特征提取效果[13]。GUILLAUME 等在单向LSTM 基础上实现双向拼接,更好地利用上下文序列信息,并且结合CRF 模型实现实体识别,在CoNLL-2003 测试语料上效果优秀,实现F1 值90.94%[14]。但是此类方法更多关注文本中的词语特征、字符特征和词语间特征,对于文本的上下文语境和语义特征等信息的利用率较低,DEVLIN 等提出了BERT(bidirectional encoder representation from transformers)语言预处理模型生成词向量信息,通过词向量泛化能力的提升,实现实体识别效果的提升[15]。SOUZA 等通过结合BERT 模型和CRF 模型,实现3.2%的效果提升[16]。谢腾等进一步提出BERT-BiLSTM-CRF 模型进行命名实体识别,通过BERT 预训练模型生成词向量,输入BiLSTM-CRF 模型进行识别,在MSRA语料和《人民日报》语料上的F1 值94.65%、95.67%[17]。
本文在上述研究基础上,根据军事实体装备名称的结构特点,为充分利用文本语义信息和装备实体后缀特征信息,提出了实体向量拼接方式实现实体识别的方法。通过实体后缀向量拼接字向量和词向量(BERT 向量)的融合网络模型,实现军事装备实体结构信息的高效利用,将隐含的字词特征、后缀特征融合到基于字符的Bi-LSTM-CRF 模型中。
在军事新闻和装备百科数据中进行装备相关样本集标注,进而进行实验验证,结果表明该方法对其他几种较为常见方法有一定效果提升,模型整体流程如图1 所示。

图1 模型整体示意图Fig.1 Schematic diagram of the model
1.2 BERT 模型
在基于神经网络的自然语言识别工作中,预训练模型一直发挥着重要作用。以Mikolov 提出的Word2vec 为代表的词向量表征方法一直较为流行[18],但是这种通过训练生成的表征向量为静态向量,对文本上下文信息利用率不高,并且对学习窗口的大小较为敏感,对后续任务效果提升不大。后面PETERS 等提出Embeddings from Language Models(Elmo)模型[20],形成上下文相关的特征向量表示方法,在多项自然语言处理任务中效果出色[19]。之后Radford 等提出GPT 预训练模型,利用Transformer 的编码器作为语言模型,但其使用的Transformer 为单向结构。 DEVLIN 等提出BERT 模型,利用微调的多层双向Transformer 结构构建模型进行编码[20],充分挖掘上下文信息,实现动态向量生成,模型结构示意如图2 所示,在后续的自然语言处理任务中表现效果较好,极大地推动了预训练模型在自然语言处理中的发展。
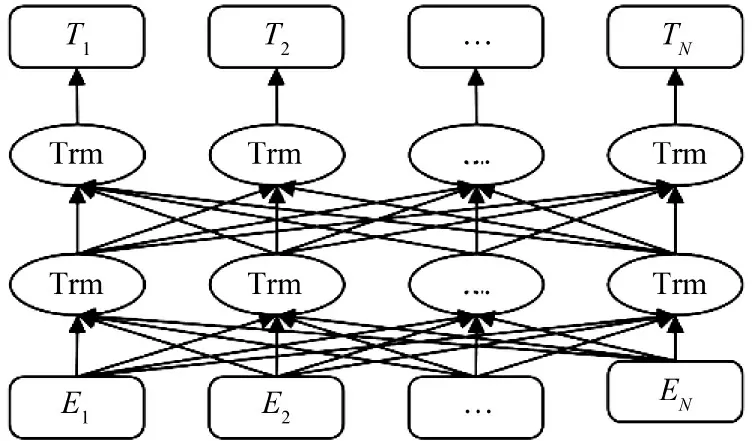
图2 BERT 模型结构示意图Fig.2 Structural diagram of BERT model
BERT 预训练任务主要包括两个,分别是masked language model(MLM)和下一句预测。MLM通过随机掩盖部分输入词,进而借助上下文信息预测被掩盖词语。通过BERT 预训练模型生成字向量和词向量,BERT 预训练模型直接输出字向量,词向量可以通过截取累加方式生成。
1.3 Bi-LSTM 模型
LSTM(long short term)由HOCHREITER 等人提出,是RNN 的一种特殊类型。RNN 可以动态获取序列状态信息,但容易产生梯度消失和爆炸问题。LSTM 通过sigmoid 激活函数和pointwise 乘法操作实现门控机构来控制数据传递过程,实现长距离信息的有效利用,并且对梯度爆炸问题实现控制。LSTM 的门控机制由输入门、遗忘门、输出门组成,分别负责特征信息的记忆、遗忘和输出,并且增加了隐藏状态(cell state)。通过双向信息学习和拼接实现语义信息的高效利用,其示意图如图3 所示。

图3 Bi-LSTM 模型结构示意图Fig.3 Structural diagram of Bi-LSTM model
循环神经网络输入n 维向量X=[x1,x2,…,xn],从而得到一列向量化表示序列H=[h1,h2,…,hn]。主要包括式(1)~式(6)。
其中,ftc是t 时刻的遗忘门信息,otc为t 时刻的输出门状态,itc为t 时刻的输入信息,hct-1为t-1 时刻的隐层状态;Wfct、W0ct、Wict、Wcct分别表示t 时刻遗忘门、输入门、输出门和特征提取过程记忆单元中t 时刻的权重系数;bf、b0、bi、bc分别表示t 时刻遗忘门、输入门、输出门和特征提取过程记忆单元在t 时刻的偏置向量,tanh 表示两种不同的神经元激活函数。通过门控机制进行记忆单元信息的选择性记忆和丢弃,从而解决RNN 梯度消失或者爆炸的问题。
1.4 CRF 模型
最初的预测阶段一般采用softmax 分类器进行解决,通过分类器对文本中的不同文本进行标签预测,但是因为其在预测过程中相对独立地预测每个标签没有利用实体上下文间的语义依存信息,容易产生不符合常规的诸如实体头连接的问题。借助CRF 模型的全局标签信息理解,通过参考上下文标签信息,在军事装备命名实体识别中可以较好地避免装备实体尾部后缀直接连接的情况判别出现。
条件随机场重要参数为标签转移矩阵,在进行序列标注时,主要借助条件概率模型P(y|x)预测标签类型,其中,Y=(Y1,Y2,…,Yn)为输出变量,X=(X1,X2,…,Xn)为输入变量,通过观察X 输入序列,生成Y 结果序列。
条件概率模型P(y|x)可以通过该公式进行表示:

2 实体后缀向量的生成和拼接
军事文本中的各类军事实体也有一定的规律性,比如武器装备名通常以“号”“艇”“舰”“航母”“机”“坦克”“自行火炮”“枪”“弹”“雷”等这类词结尾。因此,如果文本中出现以此类特征词进行结尾,在此出现军事武器装备实体的可能性较大。
通过手工梳理和整合细分武器装备类别,形成海陆空多军种的武器后缀库,并且在后期实体识别中动态更新和丰富,其中,部分常见装备实体后缀特征词如表1 所示。通过该装备实体后缀库,生成文本中实体后缀向量。

表1 装备常见后缀特征词Table 1 Common suffix characteristic words of equipment

表2 实验结果对比(单位:%)Table 2 Comparison of Experimental results(%)
军事文本输入字符切分后,获取对应的后缀特征,并通过匹配后缀特征库生成对应后缀向量,进一步通过Word2Vec 模型进行训练获取文本中字符的上下文特征,生成符合维度要求的实体后缀向量。
将经过预处理的军事文本输入到BERT 预训练模型生成BERT 向量,将BERT 向量和后缀向量进行拼接,得到包含语义和后缀信息的拼接向量。
将BERT 预训练字向量与实体后缀特征向量形成的拼接向量输入BiLSTM-CRF 模型。通过BERT模型生成字向量和词向量,对于输入的文本S=(s1,s2,s3,…,sn),通过特征向量的拼接生成总体表征向量。其中,包括字符向量、词向量和后缀向量,分别用xc(x1c,x2c,x3c,…,xnc),xw(x1w,x2w,x3w,…,xnw),xe(x1e,x2e,x3e,…,xne)进行表示。
其中,双向BiLSTM-CRF 实现方式:
其中,拼接向量通过字向量、词向量和后缀特征向量的拼接形成:xi表示右向的向量表示,xic表示字向量,xiw表示右向的词向量,xiw表示左向的词向量,xie表示装备实体的后缀特征向量。在xi生成中融入基于字开头的词汇信息。hi为经过模型生成的左右向量拼接形成。
3 试验和结果分析
3.1 实验数据
因为目前尚没有专门针对军事装备实体的正式训练语料,因此,主要通过人工标注方式进行训练语料库的构建。本文使用三元标记集{B,I,O},B-EQU 表示装备实体的第1 个词,I-EQU 表示装备实体的其余词,O 表示不属于装备实体名称部分。实验数据总共获取到包含军事新闻、装备百科知识在内的8 500 条数据,划分其中70%为训练数据集,20%为验证数据集,10%为测试数据集。
3.2 评价方法
抽取效果的评估指标包括识别精确率P(Precision)、召回率R(Recall)和F1 值(F1-Score)综合指标。精确率P 表示被正确识别的装备实体和全部识别出的装备实体的占比,召回率R 表示识别出的装备实体数据和全部转装备实体数量的占比,F1 则是为了更好地衡量识别的效果,避免出现识别正确率和准确率因影响出现的极端现象而无法正确度量结果。其计算方法如下:
精确率:

以上参数中:
True Positive(TP)指被正确地识别出的武器装备标签数量。
False Positive(FP)指被错误地识别为武器装备领域标签个数。
False Negative(FN)指未被识别出的武器装备领域标签个数。
3.3 实验设置
实验通过Python 语言进行模型构建、训练和测试的代码实现,实验中的字向量、词向量和后缀向量均采用300 维度向量表示。借助Adam 优化器,训练后特征矩阵通过CRF 计算全局最优标签序列,学习率(learning_rate)设置为0.001,批处理参数(batch_size)为64,最大句子长度(max_sequence_length)为128,通过设置Dropout 函数值为0.5,通过随机丢弃训练中的一部分神经元信息,防止出现过拟合现象。
3.4 结果分析
共进行了4 组对照试验,分别为BERT-BiLSTMCRF,BiLSTM-CRF,BERT-Word-Character-BiLSTMCRF,BERT-Word-Character-Suffix-BiLSTM-CRF。
各模型实验结果如下:
基于上述实验可以得出,通过BERT 预训练模型加持的BiLSTM-CRF 相比较原始BiLSTM-CRF模型精确率和召回率分别提升5.9%和7.76%。BERT-Word-Character-BiLSTM-CRF 通过添加词汇信息和字符信息以增强语义信息的应用,实现模型识别精确率和召回率分别提升0.25%和2.73%。BERT-Word-Character-Suffix-BiLSTM-CRF 模型在上一步基础上继续添加实体后缀向量特征信息,整备实体的识别精确率和召回率分别提升3.65%和1.21%。通过上述实验结果比对,BERT 预训练模型具有显著效果,通过添加词汇信息进行语义增强,可以进一步提升实体识别效果;通过添加实体后缀特征向量信息,对实体的识别精确率和召回率有明显提升效果。
4 结论
军事命名实体识别在军事文本智能分析处理,军事知识图谱构建中具有重要作用。传统的规则和词典的方法对于已经获取的实体识别效果较好,但是人工特征工程量较大,基于神经网络的识别方法自主学习实体特征,但缺乏针对性,因此,本文提出了实体后缀特征向量拼接方式的军事实体抽取,并且以武器装备实体为语料进行了实验验证,表现效果良好。但是在实体口语化称呼抽取及军事装备的嵌套实体等方面仍需要提升,如055、大驱、大护、出云等类型实体的识别。且本方法后缀特征提取和后缀向量生成过程仍需要一定的人工干预,这些也将是进一步提升和改进的重点。
