结合特征融合和任务分组的人脸属性识别
2023-11-18刘英芳马亚彤
刘英芳,王 松,2,马亚彤
(1.兰州交通大学 电子与信息工程学院,兰州 730070;2.甘肃省人工智能与图形图像处理工程研究中心,兰州 730070)
0 概述
随着人脸识别技术在人机交互[1]、视频监控[2-3]、图像检索[4-5]等场景的广泛应用,人脸属性分类(Face Attribute Classification,FAC)成为了计算机视觉方向研究的热点问题之一,属性分类的准确性和实时性备受关注。然而,姿态、光照等因素的不确定性给人脸属性分类带来较大困难。传统人脸属性识别方法通过人工标注特征,容易受到环境影响且识别过程耗时长,识别准确性又依赖于特征标注的有效性,识别效果不理想。在这种情况下,现有方法多数利用深度学习技术的端到端识别特点,开展基于深度学习的人脸属性识别。
基于深度学习[6-8]的人脸属性识别方法避免了人工提取特征的不完备性,相较于传统方法表现更加出色,在当今研究中占据主导地位。RUDD 等[9]使用多任务方法同时学习多个属性标签,提出混合目标优化网络(MOON)以处理数据集中多标签不平衡问题,使用最小均方损失得到多个预测分数,减少回归误差。MAO 等[10]设计深度多任务多标签网络(DMM-CNN),通过多任务学习方法提升属性识别性能,从主观和客观角度将属性划分为两组,设计两种网络分别提取特征。ZHENG 等[11]提出双向阶梯注意力网络(BLAN)得到层次表示,设计残差双重注意力模块连接局部和全局属性的层次特征。姚树婧等[12]提出FD-SDGCN 网络结构,通过特征解耦模块,获得不同属性的对应特征,然后联合不同属性间关系的动态图和静态图以更好地识别人脸属性。HAND 等[13]认为属性之间存在联系,通过构建多任务网络(MCNN-AUX),达到属性之间的信息共享。HUANG 等[14]通过一种贪婪神经网络结构搜索(GNAS)方法自动生成有效的网络,克服了人工设计网络在应用中的不灵活问题。ZHUANG 等[15]提出一种新的级联卷积神经网络多任务学习方法(MCFA),用于同时预测多个人脸属性,利用3 个级联的子网络,对多个任务进行由粗到精的联合训练,实现端到端优化。SAVCHENKO[16]研究基于轻量级卷积神经网络的多任务学习框架,提出基于MobileNet、EfficientNet 和RexNet 架构的模型,用 于无裁剪情况下的面部属性分类和人脸识别。LIU等[17]提出一种自适应多层感知注意力网络(AMPNet),利用不同的细粒度特征提取面部全局、局部和显著特征,学习面部关键信息且对遮挡和姿态具有鲁棒性,提高了潜在面部多样性信息学习的有效性。
综上所述,现有的基于深度学习的人脸属性识别方法基本采用多任务学习框架,通过属性分组反映不同属性间的关系,但属性分组策略多数根据属性位置信息,人为地划分为不同的属性组而未深入考虑属性相关程度的强弱。此外,在提取特征的过程中,多数网络模型忽略了层间语义信息的作用,导致特征提取不充分,识别准确度不高。针对以上问题,本文提出结合多尺度特征融合和任务分组的人脸属性识别模型(Slim-FAC),实现对人脸属性的有效识别,主要工作包括:1)在Slim-CNN 网络的基础上,通过两个特征融合模块融合不同层之间的语义信息;2)通过中心核对齐和谱聚类(Centered Kernel Alignment-Spectral Clustering,CKA-SC)分组策略进行属性分组,将相关性强的属性划分在同一个分支,有利于在识别每种属性时能够利用相关属性的特征信息;3)引入ECA 注意力机制,提高特征利用率,加强对目标区域的关注;4)考虑任务权重对于模型性能的影响,通过不确定性加权(Uncertainty Weighting,UW)方法来平衡不同任务之间的损失值,自动调整任务的相对权重,达到优化模型的目的。
1 Slim-CNN 网络
Slim-CNN[18]是一个轻量级网络模型,通过轻量化模块(Slim Module)构造深度神经网络,在降低模型参数量的同时保证模型性能良好。Slim-CNN 网络结构如图1 所示(彩色效果见《计算机工程》官网HTML版),使用轻量化模块作为深度神经网络构建块,4 个轻量化模块堆叠在一起,构成网络特征提取部分。
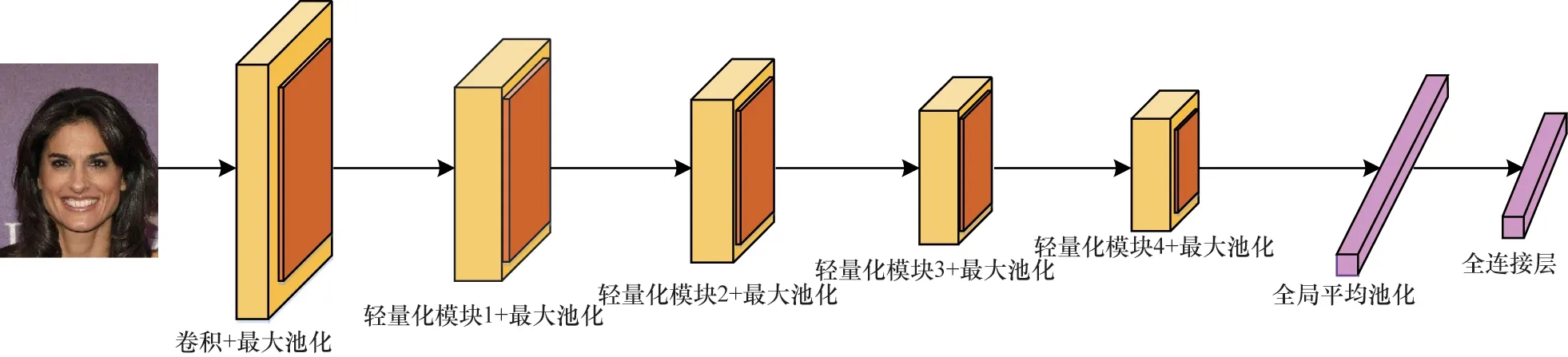
图1 Slim-CNN 网络结构Fig.1 Slim-CNN network structure
Slim Module 和可分离的压缩扩展(Separable Squeeze-Expand,SSE)模块(SSE Block)结构如图2所示(彩色效果见《计算机工程》官网HTML 版)。Slim Module 由2 个可分离的SSE Block 以及1 个深度可分离卷积构成,第1 个SSE Block 上存在跳跃连接,第2 个SSE Block 的输入为第1 个SSE Block 的输入和输出之和。SSE Block 由2 个1×1 逐点卷积和1 个3×3 深度可分离卷积组成多层排列结构。第1 层为挤压层,特征维度低于特征表示的前一层。第2 层为扩展层,由1×1 逐点卷积和3×3 深度可分离卷积形成串联结构,增加输出通道的数量。
2 结合特征融合和任务分组的人脸属性识别模型
2.1 整体框架
经典的神经网络对于设备性能要求高且计算量大,轻量化网络提高了计算效率,降低了对设备的要求。现有的一系列轻量化的神经网络在特征提取过程中通过卷积操作获得图像的单尺度特征,会出现图像特征提取能力弱的问题。多数人脸属性识别模型在需要识别多个人脸属性的情况下未充分考虑属性之间相关性的强弱。本文在Slim-CNN 的基础上,建立一种结合特征融合和任务分组的人脸属性识别模型,整体框架如图3 所示(彩色效果见《计算机工程》官网HTML 版)。该模型主要分为两个部分:
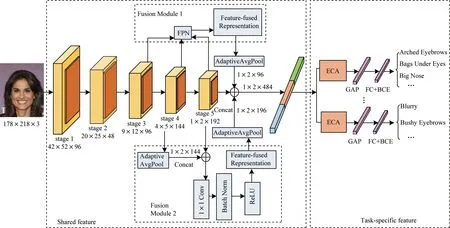
图3 结合特征融合和任务分组的人脸属性识别模型整体框架Fig.3 Overall framework of face attribute recognition model combining feature fusion and task grouping
1)参数共享部分。在Slim-CNN 的基础上,通过两个特征融合模块,克服原有网络特征提取不充分,识别准确度不高的问题。通过参数共享的形式达到信息共享的目的,提升属性识别准确率的同时减少了模型参数量。
2)分支部分。通过CKA-SC 分组策略将40 个属性划分为6 组,克服了依据位置信息划分属性组对属性相关性考虑不充分的问题。在分支部分,通过ECA 注意力机制增强有用信息的利用。使用二元交叉熵损失函数,每个分支部分得到一个损失值,通过不确定性加权方法自动调整每组任务损失之间的相对权重,以提高模型性能。
2.2 多尺度特征融合模块
在使用卷积神经网络提取特征过程中,浅层提取的特征分辨率高且包含更多细节信息,但是包含的噪声多且语义性不强;深层提取的特征噪声更少,但缺乏细节信息,分辨率低。将不同层的特征融合可以更好地表示特征。相关研究[19]表明,神经网络的中层特征在人脸属性识别中表现出极为重要的作用,受此启发,通过两个特征融合结构实现不同尺度特征的有效利用,以此提高人脸属性识别的性能。
1)融合模块1
当人脸图像目标特征不明显时,出现特征提取困难的问题,影响人脸属性识别的准确率,而且随着神经网络层数的加深,语义信息逐渐丰富,提取的特征图逐渐变小,分辨率逐渐降低,融合模块1 通过融合特征金字塔网络(Feature Pyramid Network,FPN)[20]连接浅层特征和深层特征,构建不同尺寸的特征金字塔结构,更充分地利用特征信息。
特征金字塔融合结构如图4 所示(彩色效果见《计算机工程》官网HTML 版),左侧为Slim-CNN,通过自下而上的方式提取语义信息。C1、C2、C3、C4、C5分别对应Slim-CNN 特征提取过程中5 个阶段的特征输出,选择C3、C4、C5这3 个阶段的信息进行特征融合。在提取人脸图像的高层语义特征后,通过自上而下的方式,将经过上采样后的深层语义特征和浅层的细节信息相融合。将C5通过1×1 卷积减少通道数得到特征图M5,通过上采样操作后与浅层特征元素相加得到融合特征。M4特征信息包括M5的特征信息和对应的横向连接信息。M3特征信息包括M4的特征信息和对应的横向连接信息。特征融合过程表示如下:

图4 特征金字塔融合结构Fig.4 Feature pyramid fusion structure
其中:f1×1(∙)为1×1 的卷积;fup(∙)为上采样操作;⊕为对应元素相加的融合操作。
最后通过3×3 卷积操作消除上采样的混叠效应[21],得到最终P3、P4、P5层的特征。
通过金字塔结构联合不同尺度的特征,将浅层和深层信息进行融合,获得更准确的特征图。
2)融合模块2
随着网络深度的增加,在特征提取过程中,网络中间层提取特征的信息逐渐减少,使得每个任务的特征表示能力降低。通过融合模块2 将Slim-CNN中stage 4 和stage 5 的特征再次融合。在融合模块中,将stage 4 的特征通过池化操作来匹配stage 5 特征图的长和宽。使用通道连接操作进行通道叠加。在串联后,采用1×1 卷积进行降维,减少融合特征图的通道数,最后得到stage 4 和stage 5 两个阶段的特征融合表示。
在原始的Slim-CNN 网络的基础上,通过两个特征融合模块,融合了不同感受野下的人脸属性的特征信息,联合浅层得到的高分辨率低级特征和深层得到的低分辨率高级语义特征,有效改善原始人脸图像中存在的人脸特征信息丢失问题,提升了对人脸特征信息的利用率,克服了现有人脸属性识别模型中存在的特征提取不充分问题。
2.3 ECA 注意力机制模块
在识别人脸属性时,识别效果受环境复杂度以及光照等因素的影响。为了提高复杂背景下的人脸属性的识别准确性,通过注意力机制减少无用信息,将识别的重点区域放在人脸部分,有助于从人脸图像的复杂背景中获取目标区域。
ECA[22]是一种轻量化的通道注意力模块,在增加少量计算量的情况下,提高模型的分类准确率,通过一维卷积实现不降维的局部跨信道交互策略,增强有效特征权重。ECA 结构如图5 所示(彩色效果见《计算机工程》官网HTML 版)。

图5 ECA 结构Fig.5 ECA structure
输入大小为F∊RC×H×W的特征图,首先通过全局平均池化操作得到1×1×C的全局描述特征,然后通过卷积核大小为k的一维卷积操作获得局部的跨通道交互信息,其次通过Sigmoid 函数得到通道权重占比,反映通道的重要性,最后输入的特征图与权重进行相乘,获得通道注意力特征。
ECA 根据输入特征通道数C自适应地选择卷积核尺度k,如式(2)所示,无需手动调优,提高了学习性能和效率。
其中:|*|odd为最近邻奇数;γ=2;b=1。
在ECA 中考虑相邻通道信息的交互,权重表示如下:
其中:σ为Sigmoid 激活函数;yi为第i个通道;wi为通道yi的权重;Ωki为yi的k个相邻通道集合。使用卷积核大小为k的一维卷积实现通道注意力模块,权重的计算公式表示如下:
其中:C1Dk为卷积核大小为k的一维卷积操作;y表示通道。
2.4 CKA-SC 分组策略
人脸的属性之间有不同程度的相关性,相关属性之间的特征相互辅助,以提高属性的识别准确度。多数现有研究基于位置对属性进行手动分组,属性的相关性考虑不充分,本文进一步考虑属性之间的相关性。属性之间相关性的强弱由CKA[23]计算得到并以矩阵形式表示。CKA 是一种核度量方法[24],基于核对齐的概念计算两个核矩阵(核函数)之间的相关性。
设需要比较的两层网络中的神经元的个数分别为p、p,样本个数为n,得到的表征矩阵,基于点积的相关性表示如下:
根据HSIC[25]的表达式,将X、Y中的列通过核函数对应 到K、L上,使 得Ki,j=k(xi,xj)、Li,j=l(yi,yj),得到HSIC 的经验估计值:
以单属性模型不同层的CKA 平均值作为两个任务的相关程度表示,得到矩阵A以表示单任务之间的相关性:
其中:m、n分别为第m个属性(任务)、第n个属性(任务);Tm,i、Tn,i分别表示m、n两个单属性模型中的第i层;s表示模型层数,以单属性模型中对应层相关性的平均值作为两个属性的相关性系数。使用CKA 计算不同模型层与层之间相关性的优点在于通过对核矩阵的中心化处理有效解决了因原点远离映射样本而导致的核信息表达能力降低问题。
由于以客观衡量单属性之间的相关性为基础,需要得到属性分组,因此本文提出CKA-SC 分组策略。CKA 用来衡量神经网络中层与层之间表示的相关性,以CKA 计算结果作为相关性指数,再利用谱聚类[26]得到属性分组结果。谱聚类以图论为基础,通过图的最优划分解决分组问题。利用CKA 度量CelebA 数据集中40 种属性之间的相关性,将每个需要识别的属性抽象为图的顶点,由CKA 计算得到的属性之间的相关程度的平均值作为不同顶点(属性)之间连接边的权重(相关性)。将图通过谱聚类算法划分得到若干子图。在划分之后的子图内部相关性要尽可能大,子图之间的相关性要尽可能小。根据划分结果,将同一子图内的属性识别任务放在模型的同一个分支中,共享相同的特征提取模块,提高模型性能。
通过分组策略将CelebA 数据集的40 种属性划分成6 组,组内属性信息互补,反映了属性识别受属性关系的影响,分组结果如表1 所示。

表1 属性分组结果Table 1 Results of the attribute grouping
2.5 损失函数
人脸属性识别是一个多标签分类问题。使用二分类交叉熵损失(Binary Cross Entropy Loss,BCELoss)作为每个任务中的损失函数。将每个组视为一个独立的任务,第i个任务Ltask,i定义如下:
其 中:yn,i、xn,i分别表示第i个任务的第n个属性的标签和预测结果。
使用不确定性加权[27]平衡6 组任务之间的损失函数的权重,不确定性加权使用同方差不确定性平衡任务损失,最终的损失函数表示如下:
其中:σi是噪声参数,可通过反向传播进行更新为每个任务损失函数的权重;logaσi是正则项,控制噪声参数不会增加太多。
3 实验结果与分析
3.1 实验平台
实验环境为:Windows 10 操作系 统,Intel®CoreTMi7-10875H CPU@2.3 GHz,显卡NVIDIA Geforce RTX 2060,采用PyCharm 2020.1 x64 作为开发环境。
3.2 实验数据集及参数设置
为了验证Slim-FAC 的有效性,在CelebA 数据集[28]上进行实验评估和分析。CelebA 数据集包括202 599 张人脸图像,用40 种人脸属性进行标注。数据分为训练集(162 770 张图像)、验证集(19 867 张图像)和测试集(19 962 张图像)。
实验以开源的深度学习框架PyTorch 为基础实现,学习率设置为0.001,批处理大小为128,训练总轮次为50。现有模型多数以人脸属性识别准确率作为评价指标,本文也采用相同的指标评价Slim-FAC,并取10 次实验结果的平均值作为最终结果。
3.3 属性组数选择实验
为了分析人脸属性划分组数对模型性能的影响,将属性分别划分为5、6、7、8 组进行实验,实验结果如表2 所示。由表2 可以看出,将属性划分为6 组时模型识别效果最好,最终将40 种属性划分成6 组。

表2 不同属性组数的实验结果Table 2 Experimental results of different number of attribute groups
3.4 分组策略比较
将文献[13]分组策略应用于Slim-FAC,结果如表3 所示,分析可得在模型相同的情况下,CKA-SC分组策略优于文献[13]分组策略,证实了CKA-SC分组策略的有效性。

表3 不同分组策略的实验结果Table 3 Experimental results of different grouping strategies %
3.5 消融实验
为了直观反映Slim-FAC 中的特征融合、CKA-SC分组策略、ECA 注意力机制与不确定性加权等对模型性能的影响,通过消融实验进行证明,在原Slim-CNN 上依次添加不同模块进行训练和测试,以人脸属性识别准确率作为评价指标,验证Slim-FAC的有效性,并给出了不同模型在CelebA 数据集上所需的训练时间,如表4 所示,其中√表示具有该模块。

表4 不同模型的训练时间对比Table 4 Comparison of training time for different models 单位:h
消融实验结果如图6 所示(彩色效果见《计算机工程》官网HTML 版),由图6 可以得出:

图6 CelebA 数据集上的消融实验结果对比Fig.6 Comparison of the results of ablation experiments on the CelebA dataset
1)在CelebA 数据集 上,Slim-FAC 及其变 体(Variant 1、Variant 2、Variant 3、Variant 4)对于人脸属性的识别效果总体优于Baseline,其中Slim-FAC 的准确率最高,说明了特征融合、ECA 注意力机制、CKA-SC 分组策略以及不确定性加权等都可使模型性能提升,Slim-FAC 更能有效学习人脸属性间的关系表示,提高相关属性的识别准确率。
2)分析Variant 1 及Variant 2 的实验结果可得,通过两个特征融合模块将不同尺度的特征联合用于人脸属性识别,模型性能有所提升,验证了不同尺度特征对于人脸属性识别的有效性;分析Variant 3 的实验结果可得,通过任务分组将相关性强的任务划分到同一个组,通过相关信息的共享进一步提高了属性识别的准确率;分析Variant 4 的实验结果可得,通过ECA 注意力机制减少了无用信息,从人脸图像的复杂背景能更准确地获取目标区域;分析Slim-FAC的实验结果可得,通过不确定性加权动态调整任务权重,能获得更高的平均分类准确率,说明了使用不确定性加权方案的有效性。
3.6 对比实验
为了评估Slim-FAC 的性能,分别比较不同模型的人脸属性识别准确率以及模型参数量,对比结果如表5 所示,最优指标值用加粗字体表示。由表5 可以得 出:Slim-FAC 以轻量 化Slim-CNN 为 基础网络,对整体框架进行改进,在尽可能获得较高的人脸属性识别准确率的前提下,使模型参数量减少。
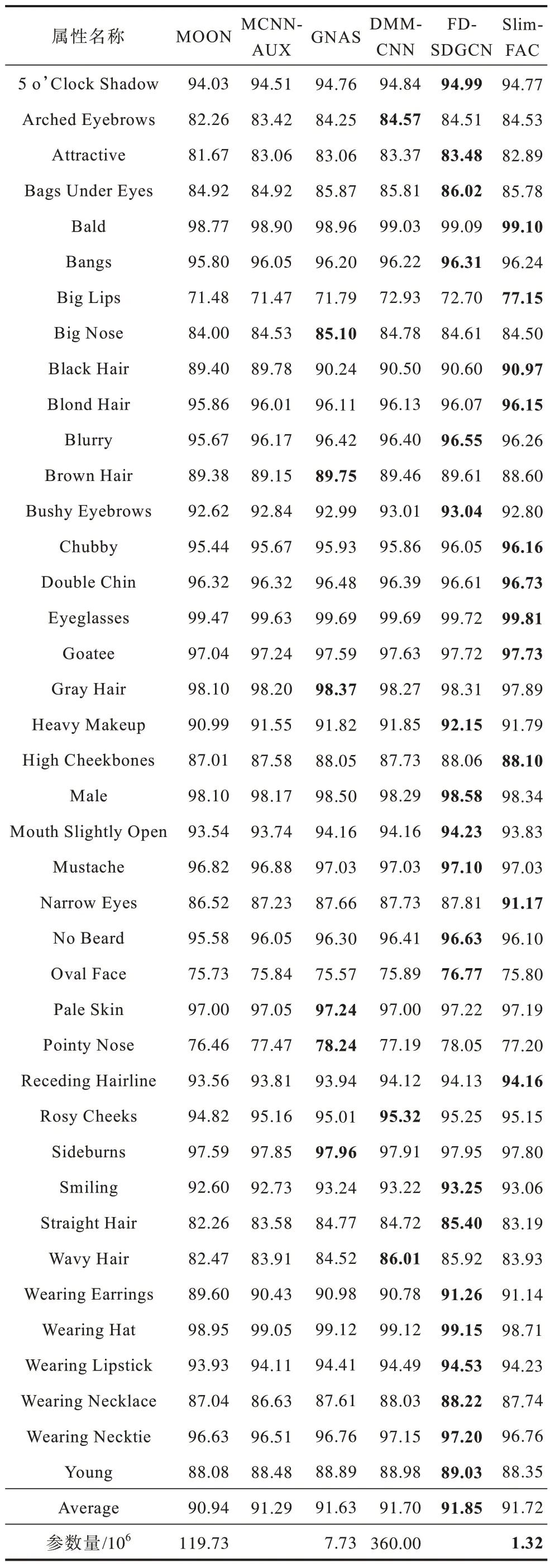
表5 不同模型在CelebA 数据集上的实验结果Table 5 Experimental results of different methods on the CelebA dataset %
1)人脸属性识别准确率。Slim-FAC 的平均准确率达到91.72%,分类误差为8.28%,相较于MOON[9]、MCNN-AUX[13]、GNAS[14]以 及DMM-CNN[10]平均识别准确率提高了0.78、0.43、0.09、0.02 个百分点,分类误差分别降低了8.61、4.94、1.08、0.24 个百分点。Slim-FAC 在CelebA 数据集 的Bald、Big Lips、Black Hair 等多种属性上取得了最高的识别准确率。
2)模型参数量。Slim-FAC 参数量 为1.32×106,分别为MOON、GNAS 以及DMM-CNN 参数量的1.10%、17.08%以及0.37%,参数量远小于上述3 个模型,可以部署在存储资源受限的硬件设备上。
可见,Slim-FAC 在参数量显著降低的情况下保证了对人脸不同属性的较高识别准确率,证明了Slim-FAC 的有效性。
3.7 算法泛化性实验
通过跨数据集的方法验证Slim-FAC 的泛化性,将在CelebA 数据上训练好的Slim-FAC 在LFWA 数据集[28]上进行实验,并与MCFA[15]、DMM-CNN[10]和LNets+ANet[28]模型进行对比,实验结果如表6 所示。由表6 可以看出,在未做任何微调的情况下通过跨数据集的方法,Slim-FAC 在LFWA 数据集上的平均识别准确率达到84.04%,相较其他模型,性能表现更好,验证了Slim-FAC 具备一定的泛化能力。

表6 LFWA 数据集上的实验结果Table 6 Experimental results on the LFWA dataset %
4 结束语
为了提高人脸属性识别性能,针对现有人脸属性识别模型中存在特征提取不足且未充分考虑不同属性之间相关性的问题,在Slim-CNN 的基础上,建立一种基于多尺度特征融合和任务分组的Slim-FAC 模型。通过两个特征模块融合了不同尺度的特征信息,有效改善了特征提取过程中存在的特征信息丢失问题,提高了人脸属性识别准确率。利用CKA-SC 分组策略,更加充分地度量了不同属性相关性的强弱。同时,引入ECA 注意力机制减少无用信息,使得人脸属性识别效果更好。采用不确定性加权方法动态调整每组任务损失之间的相对权重,提升了模型性能。在CelebA 数据集上的实验结果表明,Slim-FAC具有较高的人脸属性识别准确率,平均识别准确率达到91.72%,且模型参数量仅为1.32×106,满足实际应用需求。但由于当前数据集中标签存在噪声,因此下一步将对噪声标签进行预处理,构建噪声模型以及通过推理步骤对噪声标签进行校正,在训练过程中减少噪声标签对模型训练过程的影响,进一步提高人脸属性的识别准确率。
