基于地基气辉图像的大气重力波目标识别
2023-11-18陈锦生马文臻方少峰邹自明
陈锦生,马文臻,方少峰,邹自明
(1.中国科学院国家空间科学中心 空间科学卫星运控部,北京 100190;2.中国科学院大学 计算机科学与技术学院,北京 100049)
0 概述
重力波是不可压缩流体受到扰动时以重力和浮力为恢复力而产生的波动,可分为重力外波和重力内波。重力外波出现在2 种不同流体的分界面上,通常发生在大气边界并沿着表面垂直方向传播衰减。重力内波即通常说的重力波,是指大气内部的空气团受到扰动后以重力和浮力为恢复力而产生的波动[1]。本文关注的是平流层及以上的中高层大气重力波,其传输、饱和、破碎和扩散问题是大气动力学研究的热门方向。中高层大气重力波在上传过程中会导致能量和动量的转移,对中高层大气结构以及层间耦合产生重要影响[2],除此之外,中高层大气重力波对平流层和电离层的扰动会影响地面通信系统以及飞行器的飞行[3],因此,开展大气重力波的智能识别具有重要的研究意义和应用价值。
大气重力波常见观测手段包括MF 雷达、MST雷达、高空卫星以及气辉光学成像等[4]。大气重力波本身无法通过肉眼识别,其在传播过程中会对中高层大气分布的若干气辉发光层产生扰动,通过追踪不同的发光波段,可以观测到相应高度的大气重力波。伴随着CCD 成像技术的不断发展,1983 年,PETERSON 等[5]通过全天空气辉成像仪获取了大气重力波的波动图像,在这之后全天空气辉成像仪被广泛用于追踪大气重力波。从2008 年开始,我国的子午工程建立了由分布在不同经纬度十几个观测台站组成的地基气辉观测网,积累了海量的气辉观测原始数据[6],为研究大气重力波提供了较好的数据基础。
目前基于地基气辉图像的大气重力波事件识别筛选主要依赖专家判断,因此,从海量的气辉数据中筛选出大气重力波事件十分耗时耗力,亟需发展快速有效的自动识别算法。近些年来,深度学习在计算机视觉和自然语言处理等领域都取得了巨大的成功[7-8],基于深度学习进行目标检测诞生出了诸如Faster R-CNN、RetinaNet、YOLO 等经典模型,使得发展大气重力波机器自动识别方法成为可能。2019 年,CHANG 等[9]使用深度学习模型Faster R-CNN 构建了基于全天空气辉观测图像的大气重力波识别算法,其识别效率大大超过专家经验判断。
使用深度学习进行目标检测的重要前提是获取足够多的标注数据,通过大量的标注数据使得神经网络能充分学习目标中的特征以此来提高模型的识别 率[10],例如从2015 年开始每年举办的COCO 和Mapillary 联合目标识别挑战赛[11]采用的COCO 数据集中共包含80 个目标类别、200 万个目标标注数据。但是在真实世界中获取专家标注的数据往往需要大量的成本,而训练的图像不足会导致模型出现过拟合。针对标注数据少的问题,一个常见的思路是对现有数据进行增强。使用传统的数据增强方式包括填充、噪声、裁剪、反转、差值等来增加数据的多样性[12],已经成为深度学习目标检测中的基本操作步骤。但这些方法并没有利用原始图像的深层次内在信息,导致最终训练的模型精度提升有限。
生成对抗网络(Generative Adversarial Network,GAN)[13]为人工合成数据提供了一种新的思路。GAN 是一个生成网络模型,可以通过神经网络的学习能力来模拟真实数据集的样本分布,从而达到扩充不完备数据的目的。在目标检测领域,GAN 已经被用于数据增强[14]。2020 年,洪硕[15]使用DCGAN生成遥感船舶图像,在提升船舶目标检测召回率的同时避免了虚警率明显升高。2021 年,黄攀等[16]基于GAN 扩充的红外飞机数据集训练目标检测模型,该模型相较几种常见的目标检测算法精度均有提升。2022 年,ZHANG 等[17]针对物体表面缺陷检测中样本数量不足的问题,提出一种基于MAS-GAN的工业缺陷图像生成模型,大幅降低了数据采集和数据清洗的成本,有效提高了缺陷检测训练的收敛速度和检测精度。
本文首先针对大气重力波标注样本稀缺的问题,提出基于改进Cycle GAN 模型扩充训练数据集的算法,通过重新设计Cycle GAN 中源域到目标域的Cycle 损失函数,增加Identity 损失函数和目标图像掩膜图,使得生成图像有效保留大气重力波的波纹结构;然后利用气辉观测图像识别目标与背景低信噪比的特点,提出改进YOLOv5s 的大气重力波识别算法,通过将YOLOv5s 骨干网络中的Neck 结构由原来的PAFPN 改进成双向加权融合的双向特征金字塔网络(Bidirectional Feature Pyramid Network,BiFPN)并增加加权边界框融合(Weighted Boxes Fusion,WBF)机制,实现高效的双向跨尺度链接和加权特征融合;最后基于改进后的数据集扩充算法以及YOLOv5s 算法,实现基于气辉观测的重力波事件的快速有效识别且仅需利用少量标注样本,大幅降低对人工的依赖。
1 数据来源及预处理
本文所使用的气辉图像数据来自子午工程中国临朐站(118.7°E,36.2°N)2013 年拍摄的原始图像。全天空气辉成像仪采用尼康16 mm f/2.8D 鱼眼透镜,追踪波段为715~930 nm,CCD 光敏器件像素尺寸为1 024×1 024 像素。仪器曝光时长为1 min,存储时间为4 s,天顶角度为180°。人工将拍摄的晴朗夜空数据进行星光噪声中值滤波[18]、相邻图像差分[19]并投影至512×512 像素矩阵,一个像素对应现实地理长度为1 km。经过人工筛选得到1 060 张图像,其中训练集530 张、验证集265 张、测试集265 张[9]。在现实世界中获取足够数量的大气重力波标注数据往往需要耗费大量的人力物力,使用少量标注图像并充分利用标注图像的内在信息进而提升模型检测的性能,具有非常重要的实际意义。但是想要提取原始标注图像的内在信息并应用于机器识别模型,需要相关领域的专家结合大量研究设计出合适的方法。本文采用一种低成本的风格迁移方法,借助神经网络迁移标注图像的内在信息至扩增数据集上,使得采用扩增数据集训练的深度模型取得良好的效果。
2 图像生成与目标识别模型
2.1 基于Cycle GAN 的大气重力波样本生成
2.1.1 Cycle GAN 网络结构
生成对抗网络自2014 年由GOODFELLOW 等提出以来,由于其优秀的性能和良好的转换效率被广泛应用于图像风格转换、图像超分辨率等领域[20],结合不同的业务诞生出了WGAN、DCGAN、Style GAN等模型。其中,ZHU 等[21]于2017 年提出的Cycle GAN 模型可以无需源域和目标域一一映射实现风格迁移,并可以保证生成图像具有源域的图像的特征。
本文使用Cycle GAN 的主要目的是使神经网络学习真实图像域的风格特征,进而达到扩充训练样本的目的。如图1 所示,为了基于Cycle GAN 扩充训练样本,需要直接生成扩充图像,具体做法是:首先截取训练集真实图像中具有重力波的区域,将截取的区域随机生成在无重力波背景图像的任何区域,得到直接扩充的图像;然后将所有直接扩充的图像组成Cycle GAN 网络训练所需要的源域数据集,目标域数据集则为原始训练集真实图像;最后将源域数据集和目标域数据集输入到Cycle GAN 中开展模型的训练。

图1 Cycle GAN 流程Fig.1 Procedure of Cycle GAN
如图1 所示,Cycle GAN 由2 个生成器以及2 个判别器共同组成环形网络结构GAN(G,F,DX,DY)。不妨用X域和Y域来代表源域数据集和目标域数据集,那么生成器G(x)是X到Y的映射,表示从直接扩充图像生成真实图像,其目标是通过G(x)使得X域的图像越来越靠近Y域风格的图像。判别器DY用于判定图像由G(x)生成还是原生Y域图像。同理,反向映射生成器F(y)是Y到X的映射,可以看作G(x)的逆向过程,判别器DX用于判定图像由F(y)生成还是原生X域图像。加入生成器F(y)与判别器DX是为了保证图像在由X域到Y域的风格迁移时,X域原图像中的原有特征不会被当成噪声而忽视。
为了对模型权重进行训练,Cycle GAN 的损失函数Loss(G,F,DX,DY)由X域GAN 损失LossGAN(F,DX,Y,X)、Y域GAN 损失LossGAN(F,DY,X,Y)以及循环损失Losscycl(eG,F)组成,总的优化目标如式(1)和式(2)所示:
其中:λ为权重系数,用来控制循环损失在整体损失中 的占比,一般取0.5;G和F为生成器,G将X域映射为Y域,F将Y域映射为X域;DX为X域判别器;DY为Y域判别器。
式(1)中损失LossGAN(F,DY,X,Y)表示生成器G和判别器DY的优化目标,具体流程是将X域直接扩充图像x输入生成器G中,生成具有Y域真实特征的图像x′,再经由判别器DY判断x′是否属于Y域。损失LossGAN(F,Dx,Y,X)表示生成器F和判别器DX的优化目标,具体流程是将Y域直接扩充图像y输入生成器F中,生成具有X域直接扩充图像特征的图像y′,再经由判别器DX判断y′是否属于X域。那么X域GAN 损失和Y域GAN 损失可表示为:
其中:log 用于计算极值方便,一般底取2 或e 均可;G(x)为由X域输入生成器G的假样本数据;Ey~Pdata(y)为Y域期望,Ex~Pdata(x)为X域期望,则判别器DY的目标是将式(3)最大化,生成器G的目标是将式(3)最小化,如式(5)所示;F(y)为由Y域输入生成器F的假样本数据;Ey~Pdata(y)为Y域期望,Ex~Pdata(x)为X域期望,则判别器DX的目标是将式(4)最大化,生成器F的目标是将式(4)最小化,如式(6)所示。
循环损失Losscycl(eG,F)是为了在由原域生成不同域图像时保留原域图像的特征,而不是将原域特征当作噪声忽视。在理想情况下,即满足G(F(y))≈y,F(G(x))≈x,则循环损失如式(7)所示:
在式(7)中,通过L1 范数来计算真实样本与生成样本之间的误差。
2.1.2 Cycle GAN 网络改进
由于原始图像中大气重力波的波纹结构相对于背景并不显著,导致原始Cycle GAN 生成的图像往往忽视了需要保留的波纹结构,因此本文依据大气重力波图像特性改进原始Cycle GAN 的结构,重新设计源域到目标域的Cycle 损失函数,增加Identity 损失函数和目标图像掩膜图结构。通过掩膜图取消背景部分生成图像的Cycle 损失和Identify 损失,使背景部分完全由生成器从目标域图像中学习生成,减少源域数据集背景相一致带来的干扰,使神经网络专注于截取的波纹结构特征。修改后的Cycle 损失和Identify 损失分别如式(8)和式(9)所示:
其中:X和Y为2 个图像域,X代表直接扩充图像,Y代表真实图像,生成器G学习X到Y的映射;同理,另一个生成器F学习从Y到X的映射;E 代表数据的期望;A(x)为0-1 掩膜图,其中有目标的区域像素值为1,没有目标的区域像素值为0;K(x)为图像总像素数量与有目标像素数量之比。
除此之外,基于原始Cycle GAN 损失函数进行网络训练时极易造成梯度消失问题,使得最终训练无法达到纳什均衡。为了增加训练的稳定性,本文参考LSGAN[22]将式(3)和式(4)中的对数似然损失函数替换成平方损失函数,具体如式(10)~式(13)所示:
式(10)~式(13)依据LSGAN 推导,LSGAN 中将生成样本和真实样本分别编码为a和b,生成器的目标是使得编码a靠近于编码c,一般a取0,b取1,c取1,则改进后的总优化目标如式(14)和式(15)所示:
其中:LossGAN(F,Y,X)为式(13);LossGAN(G,X,Y)为式(11);LossGAN(DY,X,Y)为式(10);LossGAN(DX,Y,X)为式(12);Losscycle′为式(8);Lossidentity为式(9);G和F为生成器;DX为X域判别器;DY为Y域判别器;λ和ζ为常数。
2.2 目标检测模型
2.2.1 YOLOv5s 算法
YOLO 目标检测算法最早由REDMON 等[23]于2016 年提出。之后数年内,YOLOv2、YOLOv3两个版本被相继推出。2020 年,Ultralytics 基于YOLOv4 改进发布了YOLOv5 目标检测算法[24]。YOLOv5 在网络的轻量化以及检测速度上进步明显,其由输入端(Input)、骨干网络(Backbone)、颈部网络(Neck)和头部网络(Head)4 个部分组成。Input 主要对输入图像进行预处理,包括在线数据增强和自适应锚框优化等操作。Backbone 通过不同层次的卷积操作从输入图像中提取出目标特征,生成特征图,主体部分沿用YOLOv4 的CSPDarknet53 深度模型,包括Focus、CBL、CSP、SPP 等模块。Neck 结合路径聚合网络(PAN)和特征金字塔(FPN)结构,可以提取多尺度的特征。Head 主要功能为检测,会产生不同尺寸的特征图,其末端生成目标的类别概率以及目标框的位置信息。
2.2.2 YOLOv5s 改进算法
针对大气重力波图像背景与目标信噪比低的特点,提出基于加权BiFPN 模块[25]和WBF 模块[26]的改进YOLOv5 网络模型。首先,在特征融合阶段,使用加权BiFPN 代替PANet 特征金字塔,加强网络特征融合的能力,在模型轻量化的同时实现对大气重力波目标的高速与高精度检测;其次,采用加权融合框WBF 代替NMS 非极大值抑制,提升检测框的定位精度和置信度。本文网络模型的总体结构如图2 所示,其中CBL、Focus、CSP、Bottleneck、SPP 模块结构如图3 所示。

图2 本文算法框架Fig.2 Framework of the proposed algorithm

图3 部分模块结构Fig.3 Structures of some modules
2.2.3 双向特征金字塔网络
BiFPN 结构利用高效的双向跨尺度连接融合不同尺度的特征,并依据不同的输入特征按照重要性赋予权重以加强特征融合,在检测速度略微降低的情况下实现检测精度的提升。BiFPN 网络结构如图4 所示。

图4 BiFPN 结构Fig.4 Structure of BiFPN
2.2.4 加权边框融合
YOLOv5 采 用NMS(Non-Maximum Suppression)算法对输出的候选框进行过滤。NMS 仅仅从交并比(Intersection-over-Union,IoU)这一角度考虑,可能导致预测有效的候选框被删除,造成漏检的现象。本文引入加权边框融合WBF 算法,如图5 所示,对生成的候选框进行线性融合,减少目标中重复检测的现象,使得预测的候选框更靠近真实标注。
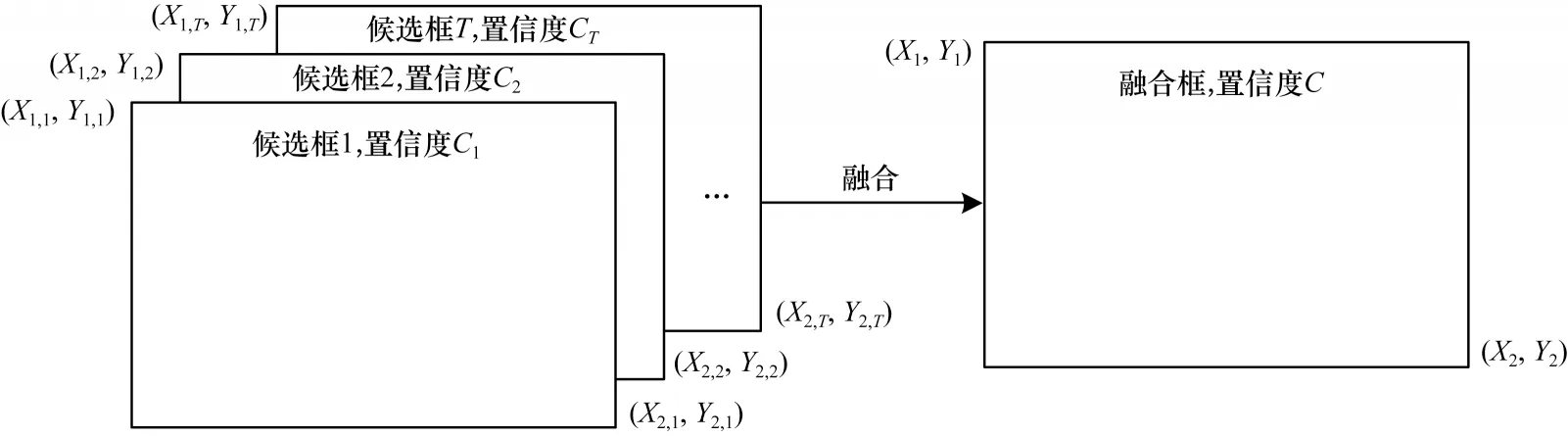
图5 WBF 示意图Fig.5 Schematic diagram of WBF
WBF 的具体过程如式(16)~式(18)所示:
其中:T为单个目标下的所有预测框个数;C为融合后候选框的置信度;Ci为每个候选框的置信度;X1,2、Y1,2为融合后候选框的具体坐标;X1i,2i、Y1i,2i为每个候选框的坐标。
3 实验结果与分析
3.1 实验流程
本文基本实验方法包括3 个部分:首先对原始标注数据进行数据增强,包含随机仿射变换(缩放、旋转、翻转)、随机亮度对比度变换和改进Cycle GAN 扩增3 种增强方法;其次利用增强后的数据训练深度检测模型,在训练过程中使用验证集评估模型精度以对模型进行微调;最后使用测试集评估模型平均识别精度,进行结果比较分析。具体流程如图6所示。

图6 实验流程Fig.6 Procedure of experiment
3.2 实验环境
本文实验中使用的处理器为Intel Xeon E5-2660 v3@2.60 GHz,显卡为NVIDIA Tesla K80,操作系统为Ubuntu 1604 LTS,CUDA 版本为10.2,Python版本为3.8.8,PyTorch 版本为1.8.2。
3.3 模型评价指标
3.3.1 样本生成模型评价指标
其中:μr代表真实图像特征的均值;μg代表生成图像特征的均值;∑r代表真实图像特征的协方差;∑g代表生成图像特征的协方差。
3.3.2 目标检测模型性能评价指标
采用平均识别精度(Average Precision,AP)作为衡量预测结果的指标。AP 需要通过模型训练样本的准确度P和召回率R计算,表达式分别为:
其中:TP为被正确识别的正样本数量;FP为被正确识别的负样本数量;FN为被错误识别的负样本数量。通过由准确度和召回率所组成的准确度-召回率曲线(P-R 曲线)的下方面积可以计算出目标类别的平均识别精度,如式(22)所示:
3.4 大气重力波样本生成评估
3.4.1 模型训练
Cycle GAN 模型改进后,Batch Size 设置为1,训练过程中采用Adam 优化器进行优化,Momentum 值为0.5,初始学习率为0.000 2,使用线性缩放动态调整学习率。生成器G以及对应的判别器DY的训练损失函数趋势如图7 所示,当迭代次数达到3 200 次后,判别器与生成器的损失逐渐收敛,上下围绕0.25进行小幅波动,说明模型网络已经达到纳什均衡,但仍然有少数个例损失波动过大,这属于正常现象。

图7 模型生成器G 和判别器DY损失函数趋势Fig.7 Loss function trend of model generator G and discriminator DY
3.4.2 生成样本质量评估
为了体现本文改进模型生成样本质量的好坏,选用未改进Cycle GAN 模型生成样本以及直接扩充样本进行FID 测量作为对比,检测结果对比如表1所示。
徐州市地处苏鲁豫皖四省交界处,素有“五省通衢”、“五通汇流”、“淮海商埠”之称。2000 年起,随着人居规模发展和城市规模的扩张以及古彭广场的改造、中心商圈的崛起,徐州市的商业格局开始发生改变。商圈从“集中与分散相结合”到“中心商圈—商业综合体”的布局不断演化。2010年以前的徐州商业的业态格局主要以大型综合商场、中型百货商店、零售超市为主。2013年云龙万达商业综合体运营,直到最近三胞广场开业,短短5年内商业空间发生了巨大的转变,商业综合体发展迅速。如云龙万达商业综合体成为徐州东部地区的城市副中心;三胞广场加速了南区商圈的形成;美的广场填补了新城区的商业空白等(如表1所示)。

表1 基于FID 的样本质量定量评估Table 1 Quantitative evaluation of sample quality based on FID
分析表1 数据可知,使用原生Cycle GAN 生成的样本相比于直接扩充样本数据FID 值下降36.31%,而本文方法所生成样本在原生Cycle GAN模型样本基础上FID 下降64.56%,说明一系列对模型的改进能提升样本图像的生成质量,生成的结果与原始图像最相似。
为了直观地对比所生成的数据,选取一些典型的生成图像进行对比,大气重力波使用黑框标出,如图8所示,其中,第1 列为截取原始图像重力波随机生成的背景图像,第2 列为未改进Cycle GAN 生成的图像样本,第3列为使用本文方法生成的图像样本。
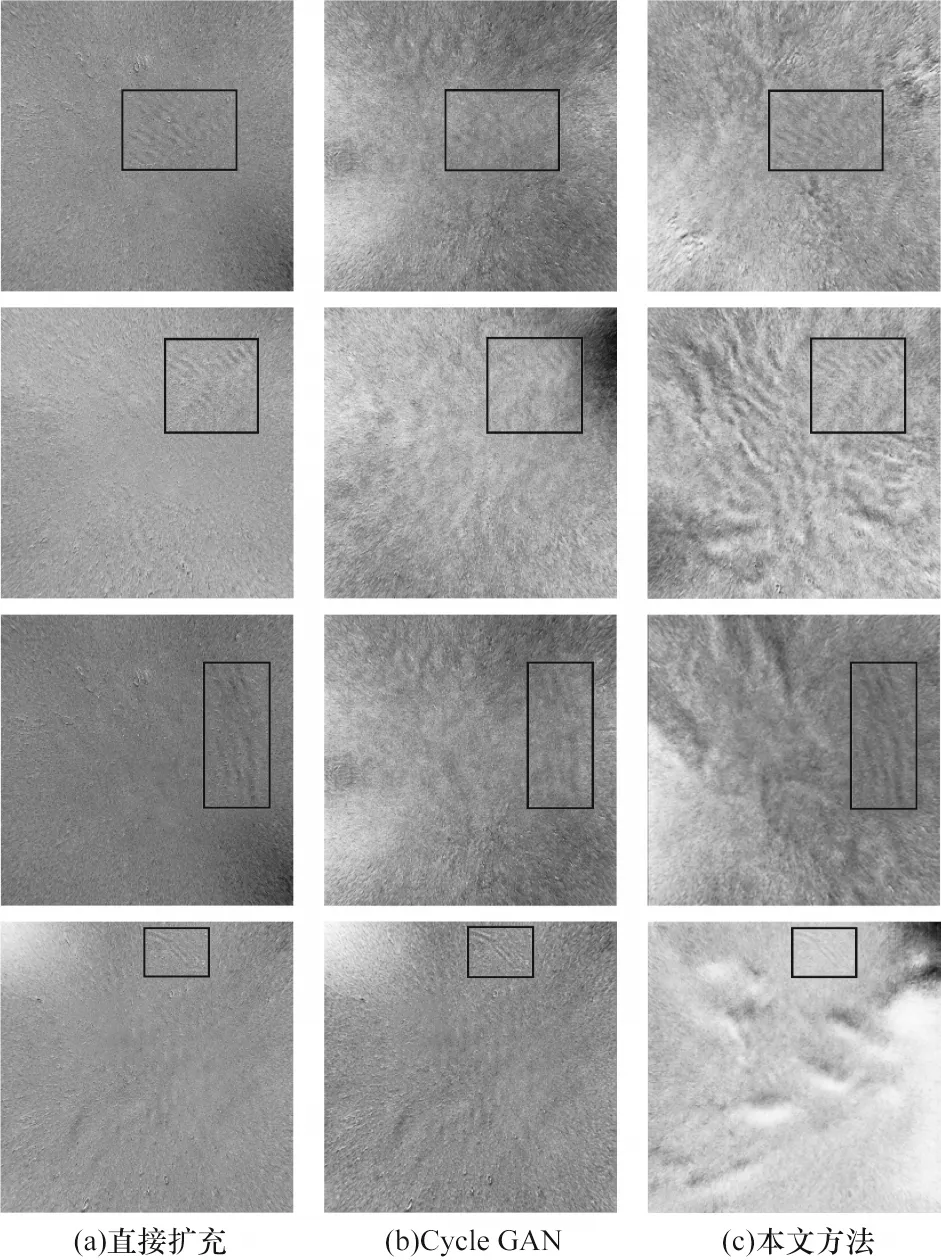
图8 不同方法生成的样本图Fig.8 Sample pictures generated by different methods
由于大气重力波的波纹结构相对于背景并不显著,导致原始Cycle GAN 生成的图像往往忽视了需要保留的波纹结构,如第1 行第2 列以及第2 行第2 列所示;而改进后生成的图像有效保留了大气重力波波纹纹理,背景更加丰富,更能反映真实图像,如第4 行第3 列中生成了云的结构。
3.4.3 大气重力波扩增样本对目标检测模型性能影响的分析
实验1为了评估生成样本的有效性,使用生成的大气重力波样本扩充原始训练集来训练目标检测模型,将未经扩容的原始训练集作为基准,来验证生成样本的扩充是否有效。
选取目前常见的目标检测模型YOLOv5s 和RetinaNet,分别给原始训练集增加生成样本,增加倍数为1、2、4、6、8、10 倍。对于YOLOv5s 目标检测模型,模型迭代次数为1 000 次,Batch Size 设置为16,训练过程中采用AdamW 优化器进行优化,Momentum 值为0.937,初始学习率为0.001,学习率衰减权重为0.000 5,使用余弦退火衰减动态调整学习率。对于RetinaNet 目标检测模型,骨干网络为ResNet50,模型迭代次数为1 000 次,Batch Size 设置为16,训练过程中采用SGD 优化器进行优化,Momentum 值为0.9,初始学习率为0.01,学习率衰减权重为0.000 1。2 种模型的检测结果如表2 所示,其中,N的值代表训练集图像数。
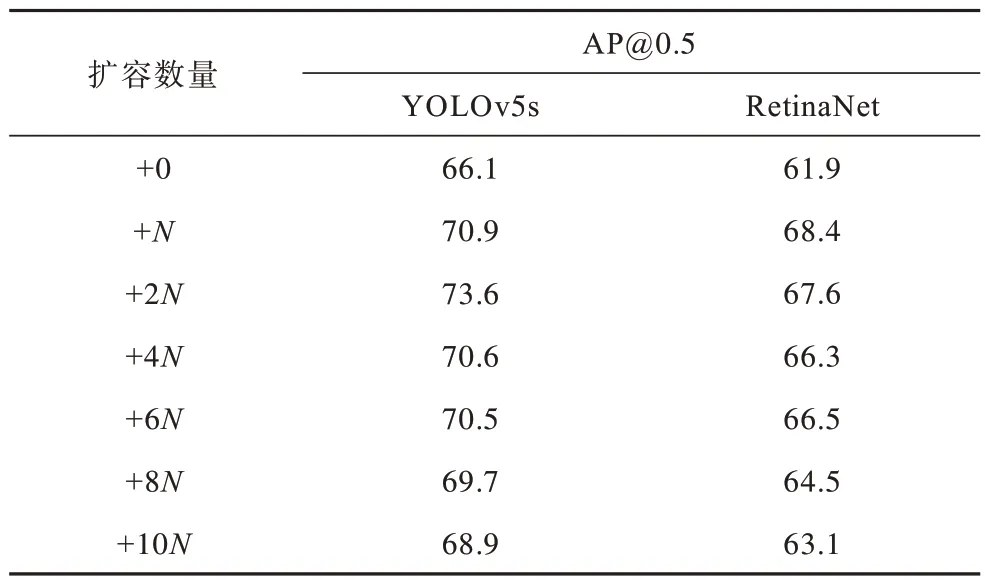
表2 扩容样本AP 结果Table 2 AP results of expanded sample %
如表2 所示,对于不同的检测模型,扩容数量对识别精确度的提升均不相同,其中:YOLOv5s 模型在增加2 倍数量的样本时,识别精确度最高提升7.5 个百分点;RetinaNet 模型在增加1 倍数量的样本时,识别精确度最高提升6.5 个百分点;之后随着生成样本数继续增加,检测精确度总体呈现下降趋势。由此可见,适量扩充训练样本的方法可以有效提升目标识别精确度,但增加过多的样本会增加较多的无用信息,增加模型的训练难度,导致模型最终识别精确度下降。
实验2使用直接扩充样本、未改进Cycle GAN模型生成样本、随机仿射变换生成样本、随机亮度对比度变换生成样本训练目标检测模型。YOLOv5s模型以及RetinaNet 模型使用参数同实验1,分别给原始训练集增加相应合成样本,增加倍数为1、2、4、6、8、10 倍,选取检测效果最好的识别精确度,结果如表3 所示。
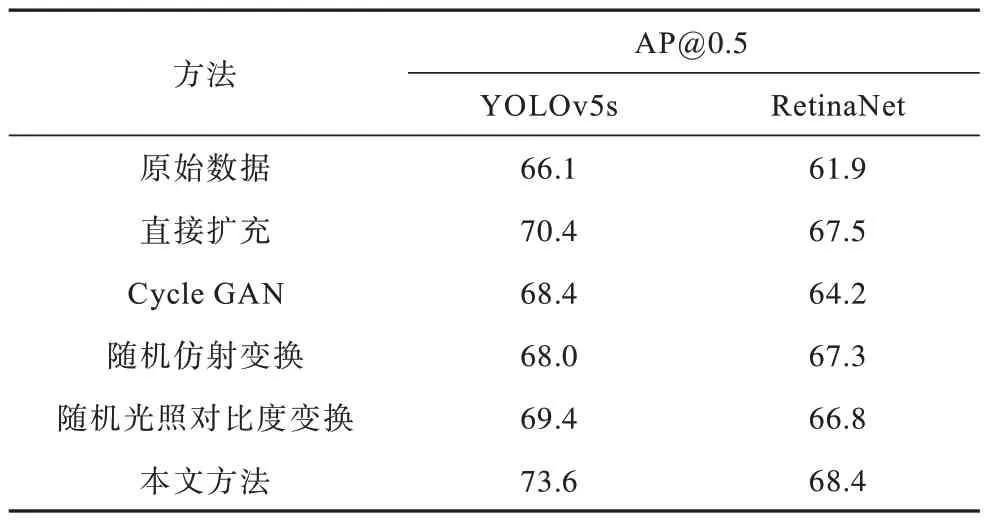
表3 不同数据集检测结果Table 3 Detection results by different datasets %
如表3 所示,相比于原始数据,使用扩充后的数据集训练均能有效提升检测模型性能,其中:YOLOv5s 直接扩充样本、Cycle GAN 扩充样本、随机仿射变换扩充样本、随机光照对比度变换扩充样本最佳精确度分别在扩容6、6、1、4 倍时取得;RetinaNet 直接扩充样本、Cycle GAN 扩充样本、随机仿射变换扩充样本、随机光照对比度变换扩充样本最佳精确度分别在扩容6、1、1、2 倍时取得。2 种目标检测模型使用本文方法生成样本训练结果相比其他对比方法识别精确度均有小幅度提升,表明使用本文改进模型生成样本扩充数据集可以更好地提高检测模型的性能。
3.5 大气重力波目标识别结果分析
3.5.1 模型训练
采用改进后的YOLOv5s 目标检测模型在扩增数据集上进行训练,Batch Size 设置为16,训练过程中采用AdamW 优化器进行优化,Momentum 值为0.937,初始学习率为0.001,学习率衰减权重为0.000 5,使用余弦退火衰减动态调整学习率,训练过程如图9所示,其中分别为预测框回归损失函数、目标检测损失函数、IoU 阈值为0.5 时的平均识别精度。可以看出:训练早期,2 种损失随迭代次数增加快速下降,与之对应的平均识别精度快速上升;当训练次数迭代到300 轮左右时,损失情况趋于稳定,平均识别精度也随之逐步提升并趋于稳定。

图9 预测框回归损失/目标检测损失/AP@0.5 随训练迭代次数的变化Fig.9 Prediction box regression loss/target detection loss/AP@0.5 variation with training iterations
3.5.2 消融实验
本文对YOLOv5s 的骨干网络进行改进,实现高效的双向跨尺度链接和加权特征融合。为了评估不同模块改动和不同模块组合对于算法性能优化的程度,本文进行消融实验,采用的策略及其说明如表4所示,对应的模型结果如表5 所示。
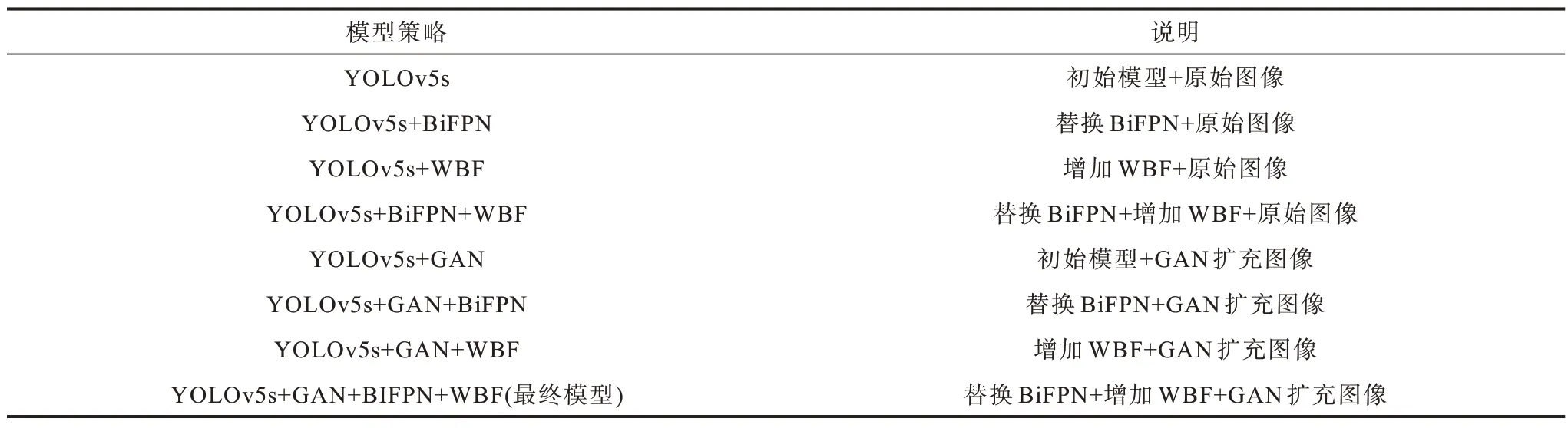
表4 模型策略及说明Table 4 Model strategies and descriptions
消融实验以YOLOv5s 为基线(第1 组)。分析表5 中数据可知:在未扩增的数据集上,通过修改特征融合网络为BiFPN(第2 组)或增加WBF 机制(第3 组),AP 分别提升3.0 及3.5 个百分点;单独采用不同策略在基线模型上提升AP 有限,若将策略叠加(第4 组),AP 相比基线提升5.3 个百分点;对于使用GAN 扩充的数据集进行目标检测(第5 组),相比基线模型,AP 提升7.5 个百分点,说明深度模型依靠大量数据驱动,增加相应训练数据,会使得检测精度有一定提升;在GAN 扩充的基础上,采用修改特征融合网络为BiFPN(第6 组)或增加WBF 机制(第7 组),AP 分别提升0.6 及0.9 个百分点;将所有策略叠加得到最终的检测模型(第8 组),AP 相比基线提升9.7 个百分点。结果表明,改进后的大气重力波最终识别模型相比于基线模型,平均识别精确度具有明显提升。
3.5.3 对比实验
为了更加直观地展示最终改进模型在大气重力波识别方面的卓越性能,本文选取目前主流的目标检测算法Faster R-CNN(ResNet101)、YOLOv3、YOLOv5进行实验比较,实验结果如表6 所示。

表6 4 种算法的性能对比Table 6 Performance comparison of four algorithms
通过表6 可知:在相同的测试集上,本文方法平均识别精度为75.8%,相比Faster R-CNN、YOLOv3、YOLOv5s 算法平均识别精度提高了9.4、6.3、9.7 个百分点,表明了本文方法具有更好的准确性;在模型体积上,本文方法相比YOLOv5s 模型体积增长微乎其微,远小于Faster R-CNN、YOLOv3;同时,从检测速度上而言,本文方法略低于YOLOv5s,比Faster R-CNN 快 了4.9 倍,比YOLOv3 快 了2.6 倍。由此可见,本文方法在保证了检测精度的前提下,模型体积以及检测速度都保证了高水准。选取一些测试集上检测的图片,分别展示Faster R-CNN、YOLOv3s、YOLOv5s 以及本文方法的结果对比,如图10 所示。

图10 4 种算法检测结果对比Fig.10 Comparison of detection results of four algorithms
从图10 分析可知:在第1 行检测结果中,4 种算法都能轻松识别出大气重力波,没有误识别云层;在第2 行检测结果中,Faster R-CNN 误将云层进行了识别,且未识别出大气重力波上半部分,YOLOv3s 未识别出大气重力波的上半部分,YOLOv5s 未识别出重力波,只有本文方法成功检测出完整的大气重力波,有效避免了云层的干扰;在第3 行检测结果中,由于目标与背景过于相似,只有本文方法准确检测;在第4 行检测结果中,Faster R-CNN 和YOLOv5s 均出现重复检测,YOLOv3 未完整检测出大气重力波,本文方法正常检测。通过对比图10 中不同算法的检测结果可见,本文方法具有更好的鲁棒性以及更强的检测准确率。
4 结束语
本文利用目前计算机视觉领域研究前沿的生成对抗网络和目标检测技术,提出一种基于地基气辉观测图像的大气重力波智能识别方法。鉴于现阶段基于气辉观测图像的大气重力波事件标注数据集稀缺,极度依赖专家判断,本文提出基于改进Cycle GAN生成对抗网络的气辉观测大气重力波数据集扩增方法。实验结果表明,在利用少量专家标注样本基础上,使用改进后的Cycle GAN 扩增样本训练集能明显提升主流目标检测模型对大气重力波的平均识别精度。针对地基气辉图像中大气重力波与背景低信噪比的特点,本文对YOLOv5s 检测模型的骨干网络进行改进,实现高效的双向跨尺度链接和加权特征融合,有效提升了检测模型对大气重力波的识别精度。最终改进检测模型对大气重力波的检测速度以及平均识别精度均优于对比的主流目标检测算法。
在后续的工作中,一方面计划扩充大气重力波的数据集,不断丰富大气重力波的种类和数量,以满足科学研究的实际应用;另一方面,考虑将已经在单台站实现的检测模型通过迁移学习方法扩展应用至多台站,使该方法更具鲁棒性。除此之外,随着子午工程气辉观测台站的不断扩增,通过少量标注样本,本文所述方案可以快速扩展应用于更多台站,后续还可应用此方案开展如电离层行进式扰动等类似事件的自动识别。
