结合向量化方法与掩码机制的术语干预翻译模型
2023-11-18张金鹏段湘煜
张金鹏,段湘煜
(苏州大学 计算机科学与技术学院,江苏 苏州 215000)
0 概述
神经机器翻译(Neural Machine Translation,NMT)是自然语言处理领域的一项重要且具有挑战性的任务[1]。随着信息技术的不断发展,电商、医药、新能源等领域涌现出大量行业术语[2-4],错误的术语翻译可能会严重影响用户体验,这便要求机器翻译系统具备更高的准确性与可控性。在统计翻译年代,基于短语的机器翻译系统[5]可以对系统输出进行良好的控制,实现对指定单词的强制翻译[6],然而这种强制干预不适用于神经机器翻译。
2022 年,WANG 等[7]借助向量化方法将词典知识显式地融入模型控制术语翻译。虽然向量化方法为术语干预提供了新的范式,但其只考虑了如何将术语信息与句子信息融合,并没有强调模型对术语信息的关注。在向量化方法中,目标术语的翻译主要依据两部分信息:一是源端句子信息,包含源端术语及其上下文;二是人为给定的术语约束,包含正确的术语翻译。本文建立一种结合向量化方法与掩码机制的术语干预机器翻译模型,在训练阶段借助掩码机制对源端术语加以屏蔽,以增强编码器与解码器对约束信息的关注,同时在推理阶段借助掩码机制优化术语干预输出层的概率分布,最终达到提升术语翻译准确率的目的。
1 相关工作
目前,主流的术语干预方法可以分为两类:一类是对传统的束搜索加以改进,引入强制解码策略;另一类是使用数据增强方法调整模型输入。
1.1 基于强制解码的术语干预方法
网格束搜索(GBS)[8]是典型的基于强制解码的术语干预方法,相较于传统束搜索,网格束搜索为术语额外增加一个维度,用于标记已经生成的术语单词数量,从而将束搜索拓展为网格的形式。假设术语单词数为C,GBS 将维护C+1 组用于存储满足不同术语单词数的候选译文,最后从第C+1 组(术语全部生成)的候选译文中选取得分最高的句子作为解码输出。由于网格束搜索增加了额外的维度,解码复杂度随术语单词数量线性增长。为了克服上述问题,POST 等[9]提出使用动态束分配(DBA)的策略改进GBS。不同于GBS,DBA 控制解码过程中波束的总量不变,并采用动态分配的策略将波束分配给C+1 组,保证解码复杂度与术语单词数无关。HU 等[10]进一步提出借助向量数组优化的动态束分配策略(VDBA),使DBA 能够以批处理方式运行,优化了解码效率。虽然此类方法通过对束搜索加以改进,确保指定术语出现在译文中,但其愈发繁琐的解码过程使其明显慢于传统束搜索解码。
1.2 基于数据增强的术语干预方法
目前,工业界采用的术语干预方法主要基于数据增强技术,原因在于采用数据增强技术无需修改模型结构,只需使用标准的束搜索即可达到一定程度的术语干预效果,且解码速度快。SONG 等[11]提出使用字符替换的方法(Code-Switching)进行术语干预,具体做法是借助先验的术语词典,将源句中的源端术语替换为目标端术语,用于翻译模型训练。在推理阶段,人们需要提前将源句中的术语替换为指定的翻译再进行解码。DINU 等[12]提出保留源端术语并在其右侧拼接目标术语的方式进行数据增强。在WMT2021 英中术语翻译任务中,WANG 等[13]对此类方法做进一步拓展,将源端术语使用特殊标记替换,并在该标记的右侧指明源端术语及其翻译(TermMind)。目前,数据增强方法最主要的缺点在于术语干预的成功率有限,说明只改变训练数据而不调整模型结构难以到达理想的干预效果。
2 融合向量化方法与掩码机制的术语干预机器翻译模型
采用Transformer[14]作为机器翻译模型的基础结构(Vanilla),模型由编码器、解码器以及输出层构成,Transformer 借助编码器与解码器将具体的单词或者子词转化为向量化表示,并借助输出层将解码器的输出向量转化为词表概率。
2.1 基于向量化方法的术语干预机制
基于向量化方法的术语干预机器翻译模型如图1 所示。对比传统的Transformer 模型,基于向量化方法的术语干预模型存在以下改动:1)借助词嵌入层以及多头注意力机制将源端术语以及目标端术语向量化(图1 虚线区域);2)将这些携带术语信息的特征向量融入翻译模型的编码器与解码器(分别对应图1 中编码器融合术语信息以及解码器融合术语信息);3)引入额外的输出概率分布提高术语生成的准确率(对应图1 中术语干预输出层)。

图1 基于向量化方法的术语干预机器翻译模型Fig.1 Terminology intervention machine translation model based on vectorization method
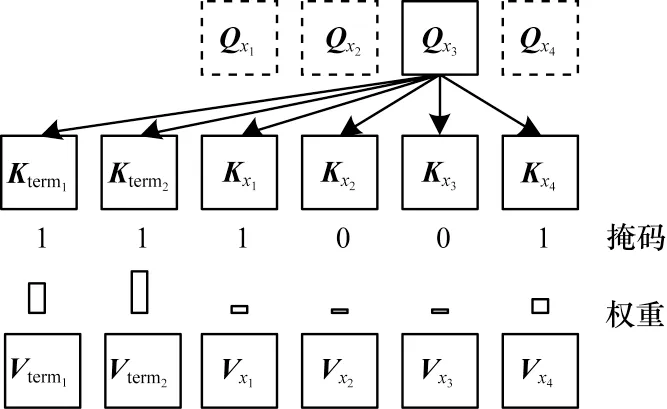
图2 结合掩码机制与编码器的自注意力机制Fig.2 Self-attention mechanism combining mask mechanism and encoder
2.1.1 术语向量化
向量化干预方法首先将源端术语与目标端术语分别转化为额外的键Kterm与值Vterm,以便将术语信息融入编码器的自注意力机制以及解码器的编码器-解码器注意力机制。使用(S,T)表示一组术语对在经过词向量层与位置编码层后得到的向量表示。在通常情况下,源端术语与目标端术语的长度不一致,在形态上不对齐[15]。在这种情况下,将S与T分别作为键与值是不可行的,需要额外增加一层多头注意力使得T与S形态一致,如式(1)所示:
其中:Kterm与Vterm分别表示一组术语的键与值,且Kterm与Vterm∊Rd×|s|,d与|s|分别表示模型的词嵌入维度以及该组术语中源端术语所包含的单词数量,Vterm可以被看作是向量T在源端长度上的重新分配。事实上,由于一组平行句对中包含不止一组术语,因此Kterm与Vterm由N组术语键值拼接得到,如式(2)所示:
2.1.2 编码器融合术语信息的过程
在Transformer 中,编码器由词嵌入层以及6 层编码层构成,编码层的自注意力机制由多头注意力网络构成,用于学习文本的上下文表示。每层的自注意力机制如式(3)所示:
其中:Hout表示自注意力机制的输出,Hout∊Rd×|x|;Henc表示编码层的输入,Henc∊Rd×|x|,|x|表示编码层输入的序列长度。
由于编码器的每一层都包含不同级别的语义信息[16],因此应确保术语信息融入编码器的每一层。在编码端,向量化方法借助自注意力机制融合Kterm与Vterm。在每一层执行自注意力过程前,使用两层适应网络将包含术语信息的键值与原始输入Henc拼接,确保编码器在自注意力过程中可以显式地融合术语信息,如式(4)所示,以此达到术语干预的目的。
其中:adapt 表示包含两层线性变换以及ReLU 激活函数的适应网络,该适应网络对所有编码层是通用的;Kunion与Vunion分别表示引入术语干预的键与值,Kunion和Vunion∊Rd×(|x|+|s|),|s|表示所有源端术语的长度之和。
在编码层中,融合术语信息的自注意力机制如式(5)所示:
2.1.3 解码器融合术语信息的过程
将术语信息融入解码器的方式与编码器类似,区别为选取编码器-解码器注意力机制融合术语信息。在Transformer 中,解码器由词嵌入层以及6 层解码层组成,解码层由自注意力组件、编码器-解码器注意力组件以及前向网络构成。每一层的编码器-解码器注意力机制如式(6)所示:
其中:Henc表示编码端提供的输入;Hdec表示解码端自注意力组件提供的输入,Hdec∊Rd×|y|,|y|表示解码器输入的长度。
对于每一层的编码器-解码器注意力机制,融合术语信息的键值如式(7)所示:
其中:Kunion和Vunion∊Rd×(|y|+|s|),与编码器融合术语信息类似,解码器借助adapt 将术语特征向量与该注意力机制的原始输入Henc进行拼接,得到新的键Kunion与值Vunion。在融合术语信息后,编码器-解码器注意力机制如式(8)所示:
2.1.4 术语干预输出层
如图1 所示,向量化方法借助术语干预输出层进一步提升术语翻译准确率。在Transformer 中,输出层用来将解码器最后一层的输出转化为子词级别的概率。使用hk∊Rd×1表示解码器在k时刻的输出,使用s与t表示人为给定的术语对,则Transformer 模型的输出如式(9)所示:
其 中:W∊Rd×|υ|表示输 出嵌入矩阵,|υ|表示词 表大小。
为了进一步借助术语信息干预文本生成,受控制文本生成[17]的启发,在输出层引入额外的概率分布对输出分布进行调整,如式(10)所示:
其中:wy表示子词y的词向量;t表示所有目标术语子词集合。
在得到Pplug后,使用门控单元控制Pplug的干预力度,门控单元如式(11)所示:
其中:W1和W2∊Rd×d;W3∊R2d×1。
模型借助3 个可训练的线性变换生成干预权重g,最终的输出概率如式(12)所示:
2.2 掩码机制
掩码机制被广泛应用于各项任务中,用于屏蔽无关信息或者对原数据加噪,例如自回归生成模型在解码器中借助掩码操作屏蔽后续文本,在各项任务中对填充符进行处理,以及在掩码语言模型中直接使用掩码符号对一定比例的原文本进行替换。此外,ReLU 激活函数以及丢弃机制(Dropout)都被认为是一种掩码操作。本文在训练阶段借助掩码机制屏蔽源端术语,增强模型编码器与解码器对约束信息的关注;在解码阶段引入掩码机制,改善输出层的概率分布,进一步提升术语翻译准确率。
2.2.1 结合掩码机制的编码器
向量化干预方法将术语信息直接拼接到编码器自注意力机制的键值中,当自注意力机制进行查询操作时,可以显式地看到两部分信息,分别是人为给定的术语信息以及源端句子信息,源端句子又可以分为源端术语和源端术语上下文两部分。
2.2.2 结合掩码机制的解码器
掩码机制融入解码器的方式与编码器类似。向量化干预方法将术语信息直接拼接到编码器-解码器注意力机制的键值中,然后根据解码端提供的查询信息对编码器的键值进行注意力操作。为了增强模型解码器对人为给定的约束信息的关注,如图3所示,在编码器-解码器注意力机制中利用掩码机制屏蔽源端术语对应的键值。
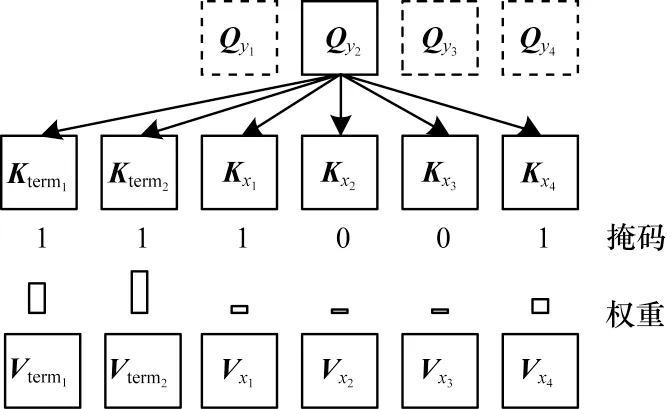
图3 结合掩码机制的编码器-解码器注意力机制Fig.3 Attention mechanism of encoder-decoder combining mask mechanism
2.2.3 结合掩码机制的输出层
在解码阶段,基于向量化方法的干预机制在输出层中引入额外的概率分布Pplug,然而Pplug是面向所有术语子词计算的,忽视了每个术语的实际翻译情况。例如“传染源”这个术语,经过子词切分后为“传染@@源”,术语干预输出层会额外增大“传染@@”以及“源”两个子词的输出概率。这一做法并没有考虑该术语的实际翻译情况,假设模型在推理阶段未解码出“传染@@”,此时模型无须增大“源”的输出概率,否则可能导致模型提前生成“源”。
简而言之,当术语的第i个子词未被译出时,Pplug不应该包括第i+1 个子词及其之后的子词。针对该问题,对Pplug进行改进,使用tnext替换式(10)中的t,如式(13)所示,tnext表示每个术语下一个待生成子词的集合,并非所有未生成的子词的集合。借助掩码数组进行维护,将每个术语下一个待生成子词的掩码置为1,其余置为0,并根据术语的解码情况进行更新。
3 实验与结果分析
3.1 数据集
选择德英与英中语项进行实验。对于德英任务,使用WMT2014 德英语料作为训练集,共包含447 万句平 行语料,并借助fast-align[18]对 齐,使 用文献[19]中的500 句包含人工对齐标注的平行语料作为测试集。对于德英训练集和测试集,也采用文献[19]中的术语抽取脚本依据对齐标注抽取术语。此外,由于德英测试集与训练集存在部分重叠,因此将这部分重叠句子从测试集中移除。对于英中翻译任务,使用语料随机抽取脚本,从WMT2021 英中数据集中抽取450 万句平行语料用于训练,训练集的术语抽取方法与WMT2014 德英数据集一致。采用WMT2021 英中术语翻译任务提供的2 000 句包含术语标注的平行语料作为测试集。德英与英中实验均采用子词切分方法[20]构建源端与目标端共享的词表,构建时迭代操作数设置为40 000。
3.2 实验环境与模型参数
所提翻译模型的执行根据Fairseq 工具库[21],所有模型的训练均在8 张显存为16 GB 的英伟达P100-PCIe 显卡上进行。选取编码器与解码器的层数均为6,将隐状态维度为512 的Transformer 模型作为基础架构,每个多头注意力机制包含8 个独立的注意力头。在训练阶段,德英与英中任务均迭代10 万步,采用Warm-up 学习策略,学习率的初始值为0.000 7,最大值为0.001,并采用Adam 更新策略,Dropout 的概率设置为0.1。在训练阶段,参考掩码语言模型的设计[22],借助掩码机制随机屏蔽15%的源端术语。
3.3 对比模型选取
对比的术语干预方法主要分为两类:一是基于强制解码策略的方法;二是基于数据增强的方法。此外,也与未采用掩码机制的基于原始向量化方法的Code-Switching 翻译模型进行比较。为了保证对比公平,所有基线均采用与本文术语干预方法一致的Transformer 结构,并保持一致的学习策略进行训练,直至收敛。在测试环节,为所有术语干预方法提供相同的术语约束。对比的机器翻译模型具体描述如下:
1)Vanilla。未采用任何术语干预方法的基线Transformer 翻译模型。
2)VDBA。在推理阶段采用向量化的动态束分配策略,并使用前缀树对DBA 进行优化,能以批处理方式执行解码并具有强大的术语干预能力。
3)Code-Switching。将源句中的术语直接替换为目标端术语作为输入,同时使用指针网络进一步优化。
4)TermMind。将源句中的术语替换为指定的特殊标记,并将目标端术语与源端术语拼接在特殊标记的右侧,在WMT2021 英中术语翻译任务中排名第一。
5)VecConstNMT。基于向量化方法的术语干预翻译模型,未引入掩码机制。
3.4 评价指标
评价指标主要包括:1)BLEU 得分,使用sacreBLEU[23]计算;2)复制成功率(CSR),从单词级别上计算术语翻译准确率;3)术语评估矩阵[24],包括正确匹配率(EM)、窗口重叠度量(Window2和Window3)以及偏向术语的翻译编辑率(TERm)[25-26]。EM 用来衡量在译文中成功匹配的源端术语占总源端术语的比例,不同于CSR,EM 从短语级别上计算术语生成的比例,是本文最重要的评价指标。窗口重叠度量用来衡量目标术语在译文中的位置准确率。TERm 计算术语单词部分的编辑损失。
3.5 模型性能
各模型在WMT2014 德英与WMT2021 英中数据集上的实验结果如表1 所示。对于术语翻译准确率,VDBA 具有最高的单词级别准确率(CSR)和短语级别准确率(EM),但该模型并不能更深层次地融合术语信息,且VDBA 在BLEU 得分以及窗口级别的准确率等指标上表现并不理想。基于术语数据增强的Code-Switching 以及TermMind 具有较高的BLEU 得分,但是术语干预能力较弱,CSR 与EM 低于其他模型。本文提出的结合向量化方法与掩码机制的干预机器翻译模型在提升术语翻译准确率的同时,进一步提升了译文的整体翻译质量,与Code-Switching 相比,在WMT2014 德英数据集上EM 指标提升了9.27 个百分点,在WMT2021 英中数据集上EM 指标提升了2.95 个百分点,且sacreBLEU提升了0.8 和0.4 个百分点,Window2、Window3 以及TERm 等指标也有所提升。

表1 各模型在WMT2014 德英与WMT2021 英中数据集上的实验结果Table 1 Experimental result of various models on the WMT2014 German-English and WMT2021 English-Chinese datasets %
3.6 消融实验
消融实验结果如表2 所示,分别移除编码器、解码器以及输出层的掩码机制以测试其对模型性能的影响。由表2 可以看出:移除编码器的掩码机制会显著降低模型的sacreBLEU;输出层的掩码机制减少了Pplug的候选,因此移除后会使sacreBLEU 略有提升,但EM 下降明显;解码器掩码机制对模型性能的影响介于编码器与输出层之间。

表2 消融实验结果Table 2 Results of ablation experiments %
3.7 短语级别干预
掩码机制的引入能大幅度提升模型对于短语级别术语的翻译能力。按照术语长度将测试集分为4 个子集,表3 对比了VecConstNMT 与所提模型的4 个子集的术语翻译结果。由表3 可以看出,CSR 与EM 之间存在较大的差距,这一差距随术语长度的增加而增加。这说明了向量化干预方法虽然可以将术语在单词级别翻译出来,但无法保证这些单词以正确的顺序连续译出,保证术语的完整翻译。引入掩码机制可显著提高长术语的EM 指标值,缩小CSR与EM 之间的差距。

表3 不同长度的术语翻译结果Table 3 Results of terms with different lengths
3.8 解码速度
各模型的解码速度如表4 所示。由表4 可以看出:Vanilla 未使用任何术语干预方法,解码速度最快;VDBA 在推理阶段加以约束,虽然具备最高的术语翻译准确率,但解码速度极慢,尤其是批处理解码,在大部分实际场景中不适用;所提模型只需在输出层跟踪每个术语的翻译进度,因此相比于Vec ConstNMT 模型,解码速度几乎不受影响。

表4 各模型的解码速度对比Table 4 Comparison of decoding speed of various models 单位:(句∙s-1)
4 结束语
目前,基于数据增强与强制解码的术语干预方法存在目标术语翻译准确率低以及解码速度慢的问题,限制了这些方法在实际场景中的应用。受向量化方法的启发,本文构建基于向量化方法与掩码机制的术语干预机器翻译模型,借助掩码机制增强模型对向量化信息的关注及优化输出层的概率分布。实验结果表明,所提模型在保证解码速度的同时显著提升了术语翻译的准确率,并且提高了译文的整体翻译质量。术语翻译任务建立在人为给定的术语翻译完全正确这一基础上,但在实际场景中术语对往往存在一对多的情况,并且对于每句句子中的每个术语,通过人工注释得到最合适的目标翻译显然是费时费力的。后续将针对上述问题做进一步研究,根据特定上下文,使模型从候选术语中自动识别并翻译出正确的目标术语。
