基于双重注意力机制的云计算负载预测模型
2023-11-18王恩旭王晓红张冬雯
王恩旭,王晓红,张 坤,张冬雯
(河北科技大学 信息科学与工程学院,石家庄 050018)
0 概述
近年来,随着云计算的兴起和信息技术的快速发展,云计算[1]的应用逐渐进入人们的视野。但随着用户量的不断增加,越来越多的云计算数据中心存在能源消耗过高的问题,因此降低服务器集群的能耗成为云计算技术发展的重要研究方向[2]。CPU和内存等资源的消耗是服务器的主要能耗来源,分析CPU 和内存等资源的负载模式和特点对于提高资源利用率和降低能耗具有重要意义[3]。服务器资源分配不均匀,会造成数据中心服务器资源的浪费,是服务器集群能耗过大的主要因素之一。目前解决数据中心资源利用率不平横问题已经成为云计算发展的挑战[4]。提高服务器资源的利用率和合理的资源分配可以有效地缓解资源浪费和能耗高的问题。如果可以对数据中心资源使用量做出预测,就可提前对资源进行分配和管理,即可有效地提高服务器资源的利用率和降低数据中心能耗[5]。
负载预测[6]是关于集群资源管理的关键技术,在服务器正常运行的前提下,每隔一定时间对各台服务器进行CPU 和内存等资源信息的数据采集,通过对云数据中心所采集的历史数据进行分析,掌握负载数据的走势和变化规律,从而进行下一个周期负载值的预测。通过负载预测可以合理地分配云数据中心的资源,达到提高资源利用率和降低能耗的效果[7]。因此,针对于降低数据中心的能耗和提高服务器的资源利用率,负载预测技术具有很高的研究价值。
云计算资源的负载预测是一个典型的时间序列预测问题,建立准确的时序预测模型是负载预测研究工作的重点。基于深度学习的长短期记忆(Long Short-Term Memory,LSTM)网络是当前比较流行的时序预测模型,但对于云计算服务器各个特征的时序数据,每个特征和每个时间节点信息对于预测结果的影响可能各不相同。LSTM 网络将所有信息以相同的重视程度进行预测,并无法区分每个特征和时间节点的重要程度。而且,当前很多对负载预测的研究大多只针对服务器某个特征的时序情况进行预测,单一特征无法全面地反映当前服务器的负载情况。
针对于以上问题,本文基于负载预测模型引入双重注意力机制的思想,搭建双重注意力机制网络模型,自适应地提高网络对各阶段时序信息的注意程度,动态挖掘服务器各特征之间的潜在相关性,并且使用CRITIC 客观赋权法对CPU 利用率和内存利用率等特征进行加权求和,以确定服务器获得负载值的时序数据。通过对服务器负载值进行预测,以更加全面准确地体现服务器下一时刻的负载状态。
1 相关工作
云计算资源的负载预测是一个典型的时序预测问题,利用历史负载数据建立时序预测模型,对未来的趋势与走向进行分析和预测。本文将目前流行的负载预测研究分为基于机器学习的预测方法和基于神经网络的预测方法两大类。
基于机器学习的负载预测方法可变参数较少更容易把握最优参数,在训练数据集较少时更具有优势。由于云计算环境的动态性和复杂性,文献[8]提出一种基于支持向量回归的多步提前CPU 负载预测方法,并且结合卡尔曼平滑技术进一步减小预测误差。为捕捉到复杂的非线性特征,文献[9]提出一种改进的线性回归方法来预测主机的CPU 使用率,但前提是主机负载变化趋势在短期内必须为线性的。文献[10]提出一种将小波分解和ARIMA 相结合的混合方法进行时序预测,通过SavitzkyGolay 滤波进行平滑,再根据小波分解将平滑的时间序列分解为多个分量,分别针对趋势和分量的统计特征建立ARIMA 模型,但这种方法对数据的稳定性有更高的要求。文献[11]提出一种基于二次指数平滑的Stacking 集成预测模型对弹性云服务器进行预测,但是该模型需要进行多次构造,并且实现复杂。为了提高模型精度,文献[12]提出将负载信息分解为线性部分和非线性部分的思想,并将ARIMA 模型和CART 模型相结合进行预测,使得模型的最终预测值比传统模型预测值更加精确。
基于神经网络的负载预测方法对预测非线性和噪声水平高的数据更具有优势,更适用于数据集较为庞大的数据。针对云资源时间序列的负载预测问题,文献[13]使用循环神经网络(Recurrent Neural Network,RNN)预测云主机CPU 利用率,证明了RNN 优于传统方法,但是使用结果表面随着预测的步长增加,网络预测的准确性会逐渐下降。文献[14]尝试使用LSTM 对云服务器的负载进行预测,并使用RMSE、MSE 和MAE 3 个指标对预测精度进行衡量,获得了较好的效果,确定了LSTM 模型用于负载预测的可行性。文献[15]提出基于概率预测和改进的多层LSTM 的云资源预测模型,为了减少模型的过拟合现象,通过改进似然函数随机丢弃中间输出,取得了不错的效果。文献[16]提出一种基于遗传算法的神经网络负载预测方法,有效提高了网络模型的收敛速度和预测精度。文献[17]提出一种基于ARIMA 和LSTM 的组合预测模型对云平台资源进行预测,并利用CRITIC 将两个模型的预测结果进行加权组合。实验结果表明,该方法优于单一的预测模型,但存在梯度消失的问题。文献[18]针对主机负载中复杂的噪声变化,提出一种由一维卷积神经网络和LSTM 组成的混合预测方法,用于在多个连续时间步预测云服务器上的CPU 利用率,有效缓解了噪声对负载预测影响。文献[19]提出一种基于深度循环神经网络编码器-解码器的多步在线预测模型,该模型可以对主机的负载进行多步预测,且具有一定的稳定性,但其只考虑了服务器CPU 利用率这一个维度的信息,并没有考虑如内存或网络等其他维度信息。文献[20]将残差连接与LSTM 网络相结合,提出一种新的CPU 负载预测模型,并且使用阿里巴巴Cluster-trace-v2018 数据集进行实验,说明了残差连接和注意力机制网络相结合的有效性。文献[21]通过综合考虑预测精度和预测时间两方面因素,提出一种基于GRU 与LSTM 的组合预测模型,结合LSTM 预测精度高与门控循环单元(Gate Recurrent Unit,GRU)预测时间短的优点,对云计算资源负载进行高效预测,但在多个特征维度和时间序列内在关联性的捕获上并不敏感。文献[22]提出一种基于iForest-BiLSTM-Attention 的负载预测方法,该方法结合注意力机制与双向长短期记忆网络,计算隐层状态和注意力权值,对负载数据进行预测,但未考虑到特征维度信息对预测的影响,只是单一维度对注意力权重进行加权。文献[23]设计并实现一个基于注意力的GRU 负载预测模型,并与没有注意力机制的GRU 进行对比实验,验证了注意力机制可以有效提高预测的准确度,但该模型只考虑了时序注意力,对特征注意力权重的捕获并不敏感。
针对大多研究对特征维度和时间序列内在关联性的捕获不敏感问题,本文在负载预测中引入了双重注意力机制的思路,加强了各阶段时序信息和各特征之间的潜在相关性,评估出各时序信息和特征信息的重要程度。双重注意力机制网络模型可以动态地捕获时序信息和特征信息的权重关系,不仅提高了单步和多步预测的精确度,同时也提高了预测结果的稳定性。
2 负载预测模型
2.1 负载值计算
本文提出使用客观赋权法求得服务器CPU 使用率、内存使用率和磁盘I/O 等特征的权重,进而计算出服务器负载值的时序数据。受CRITIC 方法的启发[24],针对对比度的考量,标准差可以反映各项特征的变异程度;相关系数可以体现出各项特征的冲突性,如果两个特征之间具有较强的正相关,说明两个特征冲突性较低;如果具有较强的负相关,则说明两个特征冲突性较高。通过负载值的数据可以有效了解当前各个云计算数据中心服务器的负载情况,进而预测出下一个时间单位的负载情况,并提前进行相应的操作和处理,达到合理分配数据中心资源的效果,同时可以有效提高资源利用率和降低能耗。
假设数据中心中n个主机收集到的特征数据分别为X={X1,X2,…,Xi,…,Xn},其中,Xi为第i台服务器特征向量集合Xi={C1,C2,…,Cj,…,Cm},Xi定期从服务器收集特征信息,如CPU 使用率、内存使用率、磁盘I/O 使用率等信息。其中每个Cj均具有T个历史数据,用于预测T+1 时刻的数据,即Cj={cj,1,cj,2,…,cj,t,…,cj,T}。求取负载值权重方法如下:
其中:Ij为信息量,表示第j个特征对服务器的负载影响程度;σj表示第j个特征的标准差;rkj表示第k个特征与第j个特征之间的相关系数。Ij值越大,第j个特征对服务器负载的影响程度就越大,该特征重要性也就越大。因此,第j个特征的客观权重ωj的计算公式如下:
通过ωj数据即可求取数据中心每台服务器负载值的时序数据。负载值时序数据计算公式如下:
其中:L为数据中心某台服务器负载值时间序列数据。每个L具有T个历史数据,即L={l1,l2,…,lt,…,lT},lt为服务器某一时刻的负载值,通过负载值的时序数据即可预测T+1 时刻的负载值。
2.2 双重注意力机制网络模型
注意力机制的本质是对数据加入相应的权重,提高某些数据信息在训练过程中的重要性,LSTM神经网络在训练过程中忽略了时序数据每个时间节点的重要性和每个特征的重要性,只是对信息进行了无差别的压缩。注意力机制可以自适应地给数据分配注意力权重,突出重要信息对预测结果的影响。本文将双重注意力机制的思想运用于负载预测中,使数据在训练过程中自适应地对重要信息增加权重,提高了负载预测网络单步预测和多步预测的准确性。双重注意力机制网络模型如图1所示。
模型训练集数据首先进入特征注意力机制模块,自适应地计算出每个特征对应的权值,并将特征权值与原始数据融合。再将加权后的数据传入LSTM 中进行学习,随后传入到时序注意力机制模块,以自适应的方式获取LSTM 网络层输出数据的时间权重,数据在时间维度上进行加权,提高了网络对每个时间步的关注程度。最后将时序注意力机制的输出使用Flatten 函数进行数据降维,得到[d1,d2,…,dk×T]输入到全连接层。y1、y2和y3分别为多步预测数据结果。
2.2.1 特征注意力机制
特征注意力机制的目的是输入数据在进入LSTM 神经网络之前,将模型的输入特征自适应地动态分配注意力权重,挖掘某些特征对预测结果的重要性。通过特征注意力机制的方式使模型增大重要特征的训练权重,从而减小甚至忽略对预测结果影响小的特征重视程度。传统的相关性分析法会导致特征关联信息丢失,而特征注意力机制可以有效缓解特征关联信息丢失问题。特征注意力机制网络模型如图2 所示。

图2 特征注意力机制网络模型Fig.2 Network model of characteristic attention mechanism
如图2 特征注意力机制部分所示,以第T个时间步为例,将单时间步的m个特征CT={c1,T,c2,T,…,cm,T}输入到由m个神经元组成的单层神经网络计算得出特征注意力机制的权重向量αT:
本文通过自适应的方式获取时序数据的特征属性,将各项特征的权重系数与输入数据相融合,以提升重要特征对训练模型的影响,提高了预测模型的准确性。
2.2.2 时序注意力机制
时序注意力机制将接收到的LSTM 隐藏层时序历史数据信息自适应地分配权重,以区分不同时刻对预测结果的影响。同时,时序注意力机制提取各历史数据时刻的信息,提高了网络对于多步预测的准确性。时序注意力机制网络模型如图3所示。

图3 时序注意力机制网络模型Fig.3 Network model of temporal attention mechanism
以第k个神经元的输出为例,时序注意力机制的输入为LSTM 网络隐藏层状态再由k个神经元组成的单层神经网络计算得出时序注意力机制的权重向量βT:
在获取到数据矩阵h′=[h′1,h′2,…,h′k]后,输入到全连接层中。
2.3 模型评价指标
为了量化负载值预测的准确性,本文提出的负载预测模型在进行测试时使用以下评价指标:MAE、平均绝对值百分比误差(Mean Absolute Percentage Error,MAPE)、MSE、均方根误差(Root Mean Square Error,RMSE)和决定系数(R2)。其中,MAPE 的值越高说明预测准确度越精确,其他指标反之。
其中:n为测试集的总个数为测试集的预测值;yi为测试集的实际值;yˉ为测试集的平均值。
3 实验结果与分析
3.1 实验数据集
为了验证本文提出的双重注意力机制负载预测网络的效果,使用阿里巴巴2018 年公开的数据集Cluster-trace-v2018[25]对网络行实验。Clustertrace-v2018 记录了8 天4 000 多台服务器各个特征的历史数据,其中包括CPU 使用率、内存使用率、网络带宽的输入输出和磁盘使用率,采集频率约为每次10 s。本文使用其中一台服务器8 天的历史数据,为保证时序数据的连续性,对不连续的时间数据进行裁剪,最后网络的实验数据裁剪为42 000 条。其中,取前60%作为实验的训练集,取20%的作为实验的验证集,取后20%作为实验的测试集。数据集时序数据如图4 所示。
3.2 数据标准化处理
将数据进行标准化处理可以提高网络的拟合速度,同时能够提高网络预测的准确性和稳定性。本文采用z-score(zero-mean normalization)标准化方法对服务器各项特征进行处理,如式(12)所示:
其中:xt为各项特征在t时刻的值为t时刻的数据标准化结果;μ为实验数据所有时刻的均值;σ为数据所有时刻的标准差。
3.3 负载值计算与分析
将数据集的历史数据使用CRITIC 客观求权法求取服务器各项特征的权重,获得服务器各个时刻负载值的历史数据。求得各项特征的信息量如表1所示。

表1 各项特征的信息量Table 1 Information amount of each characteristics
特征变异性为标准差,标准差越大则体现出该特征的变异性越高,权重就会越大。特征冲突性为相关系数,特征之间相关性越强则冲突性较低,权重越小。通过求得标准差和相关系数,确定特征的信息量,进而确定各项特征的权重。各项特征权重如图5 所示。
相比于其他特征,CPU 使用率的权重更大,同时说明CPU 使用率的波动对服务器的负载有着更大的影响。网络的输入输出只占有5%和4.9%,相比其他特征对服务器负载影响较小。通过求得的特征权重计算出服务器的负载值,输入到网络中进行预测。
3.4 负载预测实验过程与分析
3.4.1 实验过程
本文使用双重注意力机制网络对服务器未来时刻进行预测。首先获取数据集总服务器每个时刻的特征历史数据,之后对数据集数据进行裁剪,裁剪的目的是保证时序数据的连续性。将裁剪好的数据进行标准化处理后,通过各个特征加权计算出服务器的负载值,然后将各个特征连同负载值输入到网络中进行训练。当网络训练完成后,使用测试集数据对网络进行评价,评估网络负载预测的准确性。最后通过一段时间的历史数据来预测下一时刻或多个时刻的服务器负载值。
3.4.2 实验环境
本文使用Python3.7 版本进行实验,软硬件实验环境如表2 所示。

表2 实验环境Table 2 Experimental environment
3.4.3 网络预测结果
本文提出的双重注意力机制网络预测模型为多步预测网络,本文截取测试集数据5 000 个时间单位的多步预测结果和真实值的比较。由于选择预测的时间节点过长会与真实值偏差过大,本文分别选取未来第1 个、第4 个和第10 个时间节点的预测结果进行对比,如图6 所示。其中,图6(a)~图6(c)分别表示预测未来第1 个、第4 个和第10 个时间节点的真实值与预测值对比,可以看出本文的网络模型对于单步或多步预测的真实值与预测值吻合度较高。

图6 真实值和预测值对比Fig.6 Comparison of real value and predicted value
在网络训练结束后,获取自适应训练得到的特征注意力机制权重和时序注意力机制权重,如图7所示。图7(a)为特征注意力机制各个特征自适应得出的训练权重,可以看出CPU 使用率、网络的输入和磁盘I/O 对预测结果影响相对较小,网络输出和服务器负载值对预测结果影响较大。说明特征注意力机制在训练过程中自适应地降低了网络输入和磁盘I/O 这两个特征的重要程度,有效地提高了网络预测的准确性。图7(b)为时序注意力机制各个步长的权重,通过网络自适应获取到时间步长权重可以看出,距离预测结果越近的时间步对于预测结果的准确性影响越大,反之相对较远的时间步对结果的影响偏小。时序注意力机制通过加大后几步时间步的权重,从而提高预测结果的准确性。
3.4.4 对比实验
为了验证本文所提出的双重注意力机制负载预测模型(DA-LSTM)单步预测和多步预测的精确度,使用双重注意力机制网络与LSTM 网络、RNN 网络、GRU 网络以及单一的加入时序注意力机制(TALSTM)或特征注意力机制(CA-LSTM)网络分别进行对比,以MAE、MSE、R2和MAPE 评价指标作为衡量标准,结果如表3 所示。

表3 模型评价标准Table 3 Model evaluation criteria
从表3 可以看出,针对服务器的负载预测问题,引入了注意力机制后的TA-LSTM 和CA-LSTM 模型,均具有比传统预测模型RNN、LSTM 和GRU 较好的预测效果。进而说明,通过时序注意力机制的时间权重提取和特征注意力机制对各项特征的权重提取可以有效地对数据的时序信息和特征信息进行挖掘,提升负载预测的准确性。本文提出的双重注意力机制网络在单步预测中相较于LSTM 网络,MAE 和MES 分别下降了9.2%和16.8%。对于多步预测,其相较于LSTM 网络在预测第4 步和预测第10 步的MSE 分别下降了13.3%和9.8%,提升效果明显。综上所述,针对服务器的负载预测问题,加入特征注意力机制和时序注意力机制可以有效提升网络单步预测和多步预测的准确性。
本文将双重注意力机制网络与其他网络的预测结果进行对比,通过对比模型预测负载值与真实值的偏离程度,可以得到各个网络预测的准确性,如图8 所示。由图8 可以看出,本文提出的双重注意力机制网络模型相较于LSTM、GRU 和RNN 等单一的预测模型,双重注意力机制网络预测结果更接近于真实值。与单一加入时序注意力机制或特征注意力机制相比,双重注意力机制在预测结果与真实值的偏差范围更加稳定。

图8 各模型的预测结果Fig.8 Prediction results of each models
同时本文还分别与文献[21]提出的GRU-LSTM组合模型、文献[22]提出的BiLSTM-Attention 注意力机制模型和文献[23]提出的GRU-Attention 注意力机制模型进行了对比实验,预测结果与真实值的对比如图9 所示,模型预测的评价指标如表4 所示。
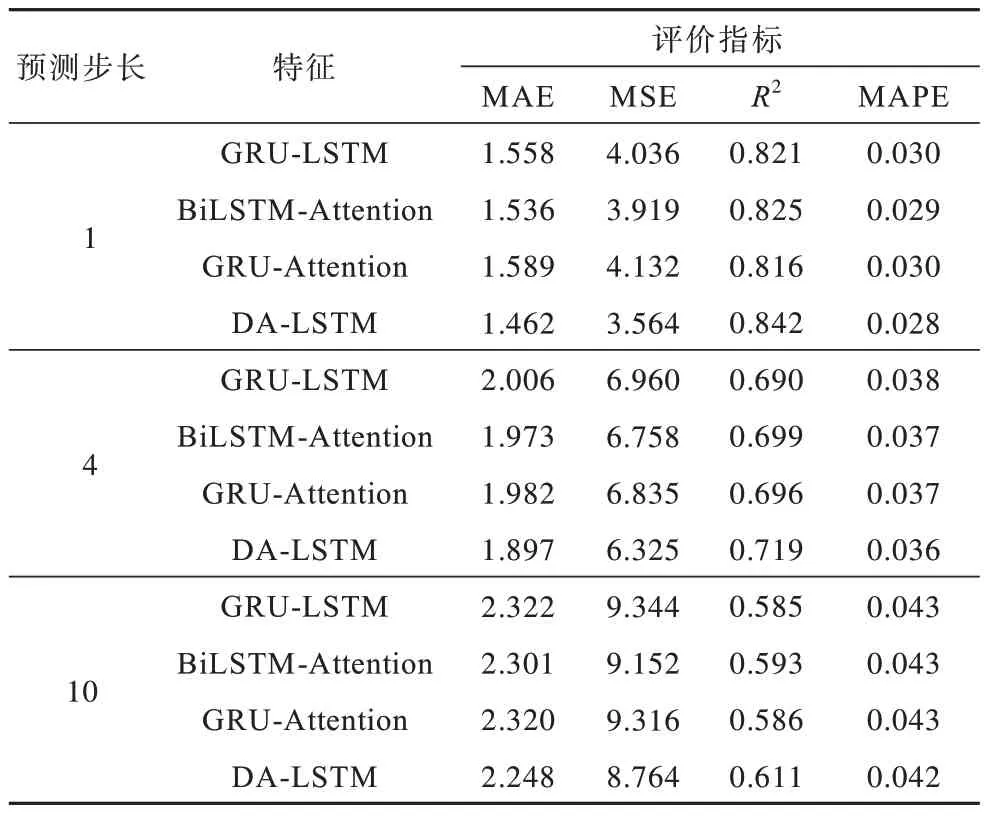
表4 各模型评价标准对比Table 4 Comparison evaluation criteria of each models

图9 各模型预测结果对比Fig.9 Comparison of prediction results of each models
从 图9 和 表4 可以看出,GRU-LSTM 组合模型为提高模型的训练速度,在LSTM 的基础上与GRU 进行组合,BiLSTM-Attention 将注意力机制融合到BiLSTM 中,增强了时序数据的训练权重,GRU-Attention 组合模型将GRU 与注意力机制融合,得到了较好的效果。但以上模型均没有考虑特征权重对模型预测的影响,本文提出的双重注意力机制模型在训练时自适应地对时序信息和特征信息进行捕获,预测结果更接近于真实值。与其他3 个组合模型相比,本文模型MEA 分别降低了6.5%、5.0%和8.6%,MSE 分别降低了13.2%、9.9%和15.9%,充分说明本文模型具有更好的准确性。
4 结束语
针对服务器单一特征无法准确体现服务器的负载情况,本文提出使用客观赋权法对CPU 利用率和内存利用率等特征进行加权求和计算出服务器当前的负载值。通过对负载值的预测可以更加有效地了解服务器下一时刻的负载情况,通过引入特征注意力机制和时序注意力机制,提高网络对负载信息的时序信息和特征信息的重视程度。实验结果表明,本文所提出的双重注意力机制网络能够有效地提高网络单步预测和多步预测的准确性。但由于本文模型引入了注意力机制,增加了网络的训练时间,减缓了模型的拟合速度,下一步将对模型的结构进行优化,以达到减少训练时间、提高网络模型训练速度的目的。另外,可以寻找模型的最优参数,提高网络预测的准确性。
