基于CNN CBAM-BiGRU Attention 的加密恶意流量识别
2023-11-18刘朝晖欧阳燕陈建华
邓 昕,刘朝晖,,欧阳燕,陈建华
(1.南华大学 计算机学院,湖南 衡阳 421001;2.南华大学 创新创业学院,湖南 衡阳 421001)
0 概述
近年来,随着对隐私保护和数据安全需求的提高,越来越多的网络应用对流量进行了加密处理。据《谷歌透明度报告》统计的数据,截至2022 年9 月,在chrome 浏览器的所有流量中,https 加密流量占到了99%[1]。流量加密技术也为恶意流量提供了可乘之机,恶意流量通过加密技术隐藏自己的恶意行为,从而躲避安全检测,导致传统的检测方法失效。对加密后的网络流量进行解密,不仅需要消耗大量的计算资源和时间,而且难度较大,同时还存在侵犯隐私等问题。如何在不解密的前提下识别加密流量中的恶意流量,成为工业界与学术界的研究热点与难点之一。
对流量进行加密后,IP 报文的明文变成密文,很多特征都发生了变化,使得基于深度包检测和基于深度流检测的方法失去效果[2]。研究人员通过对恶意加密流量的特征进行分析,发现正常加密流量与恶意加密流量的行为特征有明显差异,机器学习方法可以利用这些特征将恶意与正常的加密流量区分开来,但是如何选取特征则依赖专家经验,且深层特征难以直接发现。深度学习能够自动地从原始数据中提取和选择特征,避免了繁琐的特征工程,因此,在加密恶意流量识别问题研究中,大量学者开始使用深度学习方法。
本文提出一种加密恶意流量识别网络模型,其使用1DCNN+CBAM(Convolutional Block Attention Module)[3]提取空 间特征,利 用BiGRU+Attention 提取时序特征,以改善现有方法存在的对加密流量特征表征能力不足等缺点。通过在公开数据集CTU-13和ISCX VPN-nonVPN 上进行对比实验,以验证该模型的有效性。
1 相关工作
现有的加密恶意流量识别方法主要分为机器学习方法和深度学习方法两种。
机器学习方法需要先人工进行特征选取,再从原始流量中提取这些特征,然后利用这些特征进行分类。文献[4]首次提出在不解密的情况下利用机器学习技术从加密的网络流量中识别出具有恶意行为的网络流量。文献[5]通过分析加密正常流量与加密恶意流量的TLS 流、DNS 流和HTTP 流,选择加密恶意流量与正常流量有明显不同的地方作为特征,利用SVM 算法进行识别。文献[6]规避了流量的五元组信息,利用报文负载和流指纹来识别加密恶意流量。但是,基于机器学习的方法特征工程耗时耗力,不同的数据集中有效特征不同,在特征选取上非常依赖专家经验,特征选取的好坏直接影响结果。此外,恶意软件的更新迭代速度非常快,攻击者可以通过更新代码使部分特征失效,从而绕过检测。
近年来,为了避免特征工程,研究人员开始在加密流量分类和恶意流量识别任务中使用深度学习这种端到端的方法来自动提取特征。文献[7]将流量转换为灰度图,然后使用1D_CNN 模型与2D_CNN[8]进行恶意流量与正常流量的二分类以及流量应用类型的多分类,实验结果表明,1D_CNN 在加密流量分类中表现更好,这是在流量分类任务中首次尝试端到端的表征学习方法,给加密流量分类和恶意流量识别引入了新的思路。文献[9]使用CNN 和专家经验特征混合神经网络来识别恶意TLS 流量。文献[10]利用 Word2vec 对流量负载进行词嵌入,并通过多核一维卷积识别恶意软件加密C&C 流量。文献[11]利用堆栈式自动编码器(SAE)模型进行加密流量应用类型的多分类。
上述方法只关注了空间特征,缺少对流量上下文时序信息的表征,在面对复杂网络流量时识别效果可能会出现严重下降[12]。文献[13]使用LSTM 模型提取网络层的传输包序列和时间序列特征以识别流量行为,完成加密恶意流量识别的二分类任务。文献[14]利用BiGRU 和注意力机制进行HTTPS 流量分类。文献[15]提出BotCatcher检测框架,使用CNN和双向LSTM 组合来进行僵尸网络检测的二分类任务。文献[16]提出CNN-LSTM 检测模型,CNN 学习底层空间特征,LSTM 学习高阶时序特征。文献[17]使用CNN-SIndRNN 模型识别使用TLS 协议加密的恶意流量,在训练时间和检测时间上有大幅提升。文献[18]修改卷积神经网络的结构,用卷积层代替池化层提高对流量的表征能力。文献[19]使用TextCNN+BiLSTM 捕获时空特征,再利用多头注意力机制提取关键特征以进行恶意应用流量识别。文献[20]把Inception 与Vision Transformer 两个模型结合起来,在未知流量上进行实验。文献[21]提出一种ET-BERT 模型,在大规模无标记流量中使用多层注意力来学习流量上下文关系和流量间的传输关系,在特别场景下进行微调以完成加密流量分类任务。
现有方法虽然效果良好,但是仅依靠神经网络模型提取特征,并未充分利用加密流量的时序和空间特征,导致对流量的表征有限。在现有研究的基础上,本文提出一种同时考虑流量空间特征与时序特征的模型,并且在空间特征和时序特征提取中加入注意力机制来对重要特征进行加权,突出加密恶意流量与正常流量中差异性大的特征,从而提高识别的准确性。
2 方法设计
本文提出的加密恶意流量检测方法主要分为数据预处理、流量空间特征与时序特征提取、流量分类3 个步骤,模型结构如图1 所示。首先将原始流量数据预处理为灰度图,然后再转换为一维序列。特征提取层对输入的序列自动提取时空特征:在空间特征提取模块,选用不同大小的一维卷积核对输入流量进行特征提取,为了防止特征丢失,通过调整卷积层参数代替池化层进行特征压缩与去除冗余[22],再利用CBAM 注意力机制对提取到的不同尺度的空间特征进行加权以提高分类准确率;在时序特征提取模块,选用双层双向GRU 网络,再利用注意力机制突出不同数据包之间的差异。流量识别是依靠不同类型流量之间的特征差异来判定的,因此,最后要把提取到的混合特征向量进行融合,再利用Softmax 分类器进行二分类和多分类。

图1 加密恶意流量检测模型结构Fig.1 Structure of encrypted malicious traffic detection model
2.1 数据预处理
数据预处理的目的是尽可能保留原始流量数据中特征差异最大的数据,并把数据转化为神经网络模型输入所要求的向量类型。
在流量粒度的选择上,与单向流相比,通信双方的双向会话流含有更多的交互信息,选取流量所有层的信息能尽可能地保留原始流量[6]。预处理工作首先将原始pcap 文件按会话进行拆分。原始数据集的每一类流量对应一个pcap 文件,把原始数据按数据包进行拆分,将一定时间内具有相同五元组(传输协议,源端口号,源IP 地址,目的端口号,目的IP 地址)信息的数据包汇聚成流,再利用源IP 和目的IP将流组成会话,删除空会话生成的空文件,相同会话生成的文件只保留一个,同时删除MAC 地址、IP 地址等会对模型造成偏差的信息。
由于模型只能输入定长数据,因此所有会话必须统一长度。参考文献[7]的实验设计,本文将清洗后的会话长度统一修剪为784 Byte,长度不足的会话在末尾用零补齐。加密恶意流量和正常加密流量的主要差异存在于前面握手阶段,因此选取前784 Byte 主要包含握手阶段的协商信息,784 也方便转换为28×28 的灰度图。
在统一长度后,每一个会话被转化为灰度图,网络流量传输的字节在0~255 之间,把序列数据转换成二维,生成png 格式的灰度图,0 对应黑色,255 对应白色,通过灰度图可以直观感受到各类流量的不同,png 格式也方便读入数据。在读入数据后,为了提高模型的收敛速度,先将灰度图转换回一维序列,再利用Min-Max 标准化的方法对数据进行归一化。
在进行时序特征提取之前,需要对会话的字节进行向量化。文献[23]采用One-hot 编码,但这种编码方式会导致生成的二维矩阵过于稀疏,影响模型的拟合效果。本文采用Embedding 词嵌入,将原始流量的前784 Byte 编码成784×64 的稠密向量。
2.2 特征提取
特征提取模块分成空间特征提取模块和时序特征提取模块,2 个模块直接对原始数据进行特征提取。2 个模块并行,可以更好地表征流量,避免由串行带来的信息丢失,从而提高识别准确率。
2.2.1 空间特征提取
网络通信中客户端与服务器的会话类似于现实中2 个人的对话,会话的流量可以类比于对话的句子。一维卷积更适用于序列处理,如果采用高维卷积,则需要把序列变成高维向量,转换过程中有可能把原有流量的连续数据变成毫不相干的两部分[10],破坏了流量的原始信息。因此,本文采用一维卷积来提取流量的空间特征,不会破坏流量数据原来的相对位置,避免了信息丢失给模型识别准确性带来的影响。传统的CNN 结构由卷积层与池化层相互交替组成,池化层通过使用最大值或平均值代替池化核内的值进行特征压缩及去除冗余[22],从而简化网络复杂度。但是在流量数据中,相邻的字节之间关联性较弱,若使用最大池化或平均池化,容易导致特征的丢失。如图2 所示,在TCP 头部,SYN、FIN、ACK、PSH、RST、URG 的每种信息仅使用一个二进制位来表示,与前一位的信息并无联系。
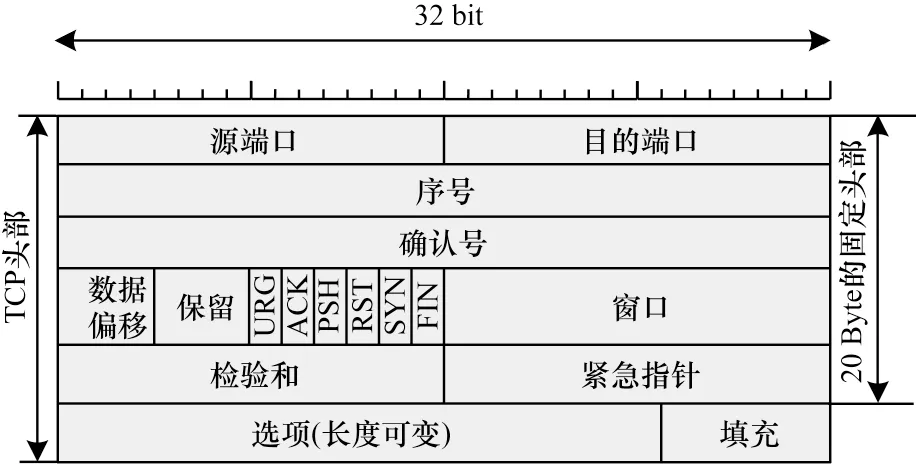
图2 TCP 头部结构Fig.2 Structure of the TCP header
加密流量的空间特征包含多种特征,如果只采用单一大小的卷积核,容易忽略某些空间特征,因此,本文选取多种大小不同的一维卷积核进行空间特征提取。为了尽可能地保留不同尺度的空间特征,将卷积层后的池化层使用卷积层代替,通过调整卷积层中卷积核尺寸、步长、填充等参数得到和池化层同样大小的输出,卷积层可以通过参数学习来防止特征丢失,同时也能达到压缩特征和去除冗余的目的。
识别恶意流量以及恶意流量种类需要依靠加密套件复杂程度、流量负载等特征,这些特征的差异度会有不同,差异度大的特征能帮助模型更好地识别出恶意流量。注意力机制能够对输入特征赋予不同的权重,从而突出重要特征,提高分类的准确性。CBAM 是一种轻量级的端到端注意力机制,由通道注意力模块和空间注意力模块串联组成,有效结合了2 个模块的优势。其中,通道注意力的作用是明确特征中什么是有意义的,空间注意力的作用是明确特征中重要的特征在哪里。CBAM 结构如图3所示。

图3 CBAM 结构Fig.3 CBAM structure
通道注意力结构如图4 所示。输入的特征矩阵先同时进行最大池化和平均池化,再经过多层感知机处理得到2 个通道注意力的映射,最后把2 个结果相加再与原输入相乘得到输出。
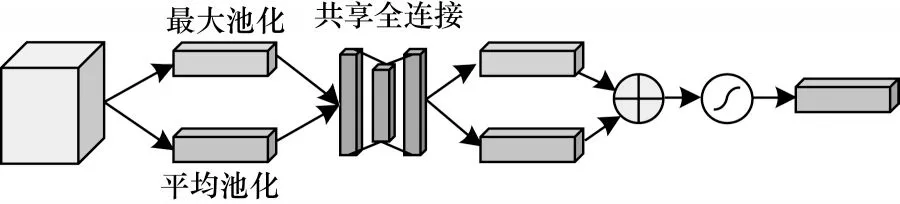
图4 通道注意力结构Fig.4 Channel attention structure
空间注意力结构如图5 所示。输入的特征矩阵先同时进行最大池化和平均池化,把得到的矩阵先聚合再进行一次激活函数为Sigmoid 的卷积,最后与原输入相乘得到输出。

图5 空间注意力结构Fig.5 Spatial attention structure
不同大小卷积核提取到的不同维度的空间向量,对于加密流量识别的重要性不同。为了能够突出重要特征的作用,在卷积层后添加CBAM 模块,通过对重要的特征赋予更高的权重,提高识别的准确性,最后再经过一层卷积层提取深层的空间特征。
2.2.2 时序特征提取
CNN 善于提取空间特征,但是难以捕捉流量的时序特征。网络流量的字节-数据包-流量结构可以类比于字-词语-句子的结构。字节、数据包、流量按时间顺序排列,因此,网络流量存在时间序列相关的特征。循环神经网络(RNN)是提取时序特征的常用方法,但是传统的RNN 中由于后面的神经元难以与前面输入建立联系,导致对长距离信息的学习能力较弱。LSTM 和GRU 能在一定程度上缓解传统RNN 存在的梯度爆炸和梯度消失问题。与LSTM 相比,GRU 的结构更简单,参数更少,因此,本文模块选取GRU 进行时序特征提取。
单向GRU 只能将当前输入与历史信息建立联系,无法捕捉到未来输入对当前输入的影响,然而流量数据会话中的某个数据包与前后数据包都存在时序联系,因此,本文选择使用双向GRU(BiGRU)模型来提取流量的时序特征。双向GRU 由正向GRU和反向GRU 连接而成,正反2 个方向互补能够建立当前输入与前后状态的联系,更好地表征流量时序特征。时序特征提取模块结构如图6 所示。

图6 时序特征提取模块结构Fig.6 Temporal feature extraction module structure
本文先对输入流量进行词嵌入,再使用双向GRU 模型进行时序特征提取,网络结构设计为串联的两层双向GRU,通过加深网络层次来提取深层时序特征。由于在会话中每个数据包对加密恶意流量识别的重要性不同,因此最后针对时序特征向量使用Attention 模块来突出重要时序特征。
2.3 流量识别
时序特征和空间特征是完全不同的特征,2 种特征在识别中起到的作用也不相同,因此,本文在进行特征融合时定义如下:
其中:F是特征融合后的向量;fs是空间特征向量;ft是时序特征向量;w是一个超参数,取值范围为(0,1),用来调节各部分特征对最终结果的影响程度。最后,把融合的特征F输入Softmax 分类器中。Softmax 分类器使用Softmax 激活函数得到识别为每种类别流量的概率,取最大值作为模型识别结果,其计算公式如式(2)所示:
其中:pi表示输入的一次会话被识别为第i种流量的概率;xi为对应流量类别的分数。
3 实验验证
3.1 实验环境与设置
本文实验在Windows 操作系统中完成。在数据预处理阶段,使用SplitCap 工具将原始数据以会话为单位进行分割,使用numpy、PIL 等库对会话进行处理,生成灰度图。在深度学习模型的搭建与训练阶段,使用TensorFlow 和Keras2.7.0 框架进行模型搭建与参数调优。CPU 使用Intel 酷睿i7-12700F,内存为32 GB,采用英伟达RTX3060 显卡加速。为了增强实验的有效性,防止偶然性,取10 次实验结果的平均值作为最终结果,细粒度划分实验进行十折交叉验证,训练集、验证集、测试集的比例设置为8∶1∶1。
在模型网络结构中,空间特征提取模块中2 个卷积层的卷积核分别设置为32 和64,代替池化作用的卷积层的卷积核与上一层卷积核个数相同,步长设置为5,使用ReLU 激活函数,经过CBAM 块后再经过一个Flatten 层与全连接层变成128 维向量。2 层时序特征提取部分的双向GRU 的unite 分别设置为32和64,神经网络的每一层设置Dropout 为0.5。选用交叉熵损失函数,Adam 算法优化,学习率设置为10-3,batch_size 设置为64。
3.2 数据集
文献[2]指出,可用于异常加密流量识别和加密攻击流量识别的公开数据集非常少,很难找到既包含加密恶意流量又有正常加密流量且以pcap 格式存储的公共数据集。因此,本文的恶意加密流量数据集选取CTU-13[24],正常加密流量数据集选用ISCX VPN-nonVPN[25]。
CTU-13 是由各种加密恶意流量组成的数据集,这些流量是由捷克理工大学开展的Malware Capture Facility 项目所收集的,本文从中选取10 种加密恶意流量,具体类型与数目如表1 所示。ISCX VPNnonVPN 是加密流量应用和服务类型分类任务中常用的数据集,该数据集由7 种常规加密和7 种VPN 加密的应用流量组成,本文从中选取10 种流量组成正常流量数据集,具体类型与数目如表2 所示。数据经过预处理后,生成的部分流量灰度图如图7 所示,从图7 可以直观地感受到各种类型流量之间的差异。

表1 加密恶意流量数据集Table 1 Encrypted malicious traffic dataset

表2 正常加密流量数据集Table 2 Normal encrypted traffic dataset
3.3 评估指标
实验使用准确率(Accuracy)、查准率(Precision)、查全率(Recall)、F1 值(F1)等常见指标对模型性能进行评估。各指标的计算公式如式(3)~式(6)所示:
其中:TTP,k表示正确识别的k类流量的数量;TTN,k表示正确识别的非k类流量的数量;FFN,k表示k类流量识别为非k类流量的数量;FFP,k表示非k类流量识别为k类流量的数量。
3.4 结果分析
在卷积核的选择上,本文选取4 种常用尺寸的卷积核组合,在二分类任务中进行实验,结果如表3所示。从表3 可以看出,选用3、5、7 这3 种大小尺寸组合时准确率和F1 值最高,因此,本文选用3、5、7 这3 种不同大小的卷积核组合。

表3 不同卷积核组合的实验对比Table 3 Experimental comparison of different convolution kernel combinations
图8 反映了训练过程中模型准确率与训练迭代次数的关系。由图8 可见,训练5 轮时验证集准确率达到99%,训练15 轮时模型基本收敛,准确率达到99.5%,说明本文模型收敛速度较快,能够提取出恶意加密流量的有效特征并识别出恶意流量。

图8 准确率与迭代次数的关系Fig.8 Relationship between accuracy and number of iterations
在融合层的超参数w设置上,选取从0.1~0.9 且间隔为0.1 的9 个数进行实验,结果如图9 所示。由图9 可知,将w取为0.6 时模型效果最佳,在本数据集中流量的空间特征差异略大于时序特征。

图9 不同参数w 下的F1 值Fig.9 F1 values under different parameters w
3.4.1 二分类消融实验
为了验证本文模型中各模块的作用,进行二分类消融实验。1DCNN 模型去除了时序特征提取模块与CBAM 模块,BiGRU 模型去除了空间特征提取模块与Attention 模块,1DCNN+BiGRU 模型是上述2 个模块的拼接,1DCNN-BiGRU 去除了空间特征提取模块中的CBAM 和时序特征提取模块中的注意力部分。
为了更真实地模拟现实网络场景,更好地验证模型的鲁棒性,在二分类实验中,训练集由加密恶意流量数据集中的前5 类各1 000 条和加密正常流量数据集中的前5 类各1 000 条会话组成,测试集由两部分数据集的剩下类别各选1 000 条会话组成,这样能够保证测试集中的流量类型在训练集中都没有出现过,可以检验模型识别未知类型加密恶意流量的性能。
由表4 可以看出,本文模型的准确率、召回率、F1 值均为5 种模型中最高的,说明本文模型在5 种模型中检测恶意流量的能力最强。5 种模型的准确率、召回率、F1 值都已达到94%以上,说明加密的恶意流量与正常流量在空间特征与时序特征上有较大差异,可以通过深度学习方法来进行识别。从1DCNN 和BiGRU 的实验结果与CNN+BiGRU 和CNN-BiGRU的实验结果对比可以看出,同时考虑时序特征和空间特征的模型比只考虑单一特征的模型表现更好。从CNN+BiGRU 与CNN-BiGRU 的实验结果对比可以看出,本文模型的2 个模块更适合并行,模块并行能在一定程度上避免串行导致的部分特征丢失问题。本文模型在3 个指标上都优于CNN-BiGRU,说明注意力机制能够提高模型对加密恶意流量的识别能力。

表4 二分类实验结果对比Table 4 Comparison of results of binary classification experiments %
3.4.2 十分类对比实验
在现实场景中,除了需要识别网络中的恶意流量,还需要对恶意流量的类别进行细粒度划分,将结果提供给网络维护人员以采取准确的防御措施。因此,本文选取10 类加密恶意流量进行实验,为了避免数据不平衡对实验的影响,从每一类加密恶意流量中随机选 取5 000 条会话 组成数据集,将1D_CNN[7]、CNN-BiGRU、BotCatcher[15]模型与本文模型进行对比,以检验模型识别加密恶意流量具体类别的性能。BotCatcher 由含有2 个卷积层并且每个卷积层后加入最大池化层的2 维CNN 与双层双向LSTM 组成。
图10 所示为4 种模型的查准率、召回率、F1 值以及整体准确率。从图10 可以看出:1D_CNN 由于缺乏对时序特征的表征,因此整体准确率最低;本文模型在整体准确率上比其他3 种模型分别高出4.20%、1.42%、0.12%,说明在此数据集中,本文模型对恶意加密流量的具体类型识别效果更好;与BotCatcher相比,本文模型对于提取到的特征经过注意力层与特征融合层,更加有效地利用了加密流量的特征,因此,整体准确率更好;CNN-BiGRU 由2 个模块串联组合而成,整体准确率比本文模型低0.12%,在Zbot类别中查准率比本文模型高2.5%,但是查全率和F1 值都低于本文模型,原因可能是串联连接中前一个模块的特征提取给后一个模块造成了部分特征丢失;在Zbot 类别中,本文模型的识别效果相比其他3 种模型有明显提升,在查准率上分别提升5.57%、4.54%、4.05%,在F1 值上分别提升16.93%、5.41%、0.9%;在10 个类别的F1 值对比中,本文模型在Dridex、Miuref、Zbot、Htbot、Wannacry、TrickBot 这6 个类别中都大于等于其他3 种模型,剩下的4 类中比其他3 种模型中的最大值低不超过0.2%,说明本文模型在大多数类别中都有较好的稳定性,能够有效识别加密恶意流量的具体类型。
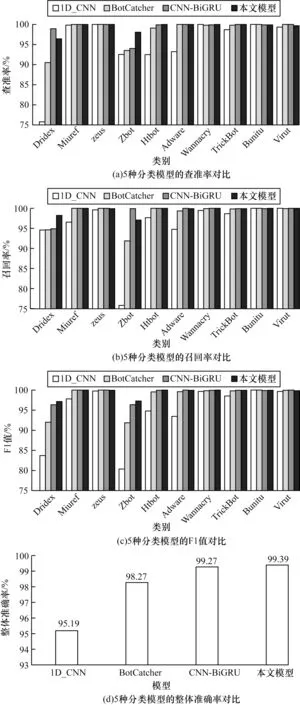
图10 5 种分类模型的实验结果对比Fig.10 Comparison of experimental results of five classification models
本文模型某次实验的混淆矩阵如图11 所示。结合图10 可知,本文模型的查准率在Dridex 类上低于CNN-BiGRU,在Zbot 类上高于其他3 种模型,查全率在Dridex 类上高于其他3 种模型,在Zbot 类上低于CNN-BiGRU,F1 值高于其他3 种模型。本文模型对Dridex 与Zbot 这两类的混淆程度较高,查准率和查全率比其他类别低,原因可能是这两种流量行为相似,使得空间特征和时序特征差异不够明显。

图11 测试集结果的混淆矩阵Fig.11 Confusion matrix of test set results
4 结束语
本文提出一种端到端的加密恶意流量识别方法,利用CNN 与双向GRU 模型分别提取流量的空间特征与时序特征,在每个模块中利用注意力机制突出特征的差异性。在空间特征提取中,采用更加适合序列的一维卷积,基于不同大小的卷积核提取多视野空间特征,为了防止池化操作带来的特征丢失,通过调整卷积的参数代替池化操作对特征进行压缩和去除冗余,从而加强对流量的表征,利用CBAM 注意力机制对提取到的多视野空间特征进行加权,以提高准确率。在时序特征提取中,使用双层双向GRU 神经网络来表征流量的上下文信息,利用注意力机制突出不同数据包的重要程度。实验结果表明,该方法能达到较高的识别精度。下一步工作将从3 个方面展开:本文模型参数较多,检测实时性不强,需要进一步提高模型在时间维度的检测效率;在实际的网络攻击中,攻击与攻击之间可能存在联系,本文模型只考虑了会话内部的特征,没有考虑会话与会话之间的关系,从而忽略了攻击之间的联系,后续可以通过图神经网络来建立会话与会话之间的关系;对特征聚合进行深入研究,探索一种更优的时序特征和空间特征融合方式,以更好地利用这2 种特征进行加密恶意流量识别。
