基于掩蔽自监督语音特征提取的帕金森病检测方法
2023-11-18杨茗淇郑慧芬
季 薇 杨茗淇 李 云 郑慧芬
①(南京邮电大学通信与信息工程学院 南京 210003)
②(南京邮电大学计算机学院 南京 210023)
③(南京医科大学附属老年医院 南京 210024)
1 引言
帕金森病(Parkinson's Disease,PD)是一种常见的慢性神经系统疾病[1]。研究表明,帕金森病与语言障碍[2–4]之间存在一定的病理关系。超过90%的帕金森病患者报告了至少一种最常见的声学相关症状,包括声音衰减、发音不准确等[5]。
近年来,一些学者基于语音进行了帕金森病诊断方面的研究,并取得了一些进展。其中,帕金森病患者的语音特征学习是帕金森病诊断方案的重要组成部分,主要包括特征选择和特征提取。Little等人[6]从采集的持续元音语音/a/中提取了包括频率微扰(Jitter)和振幅微扰(Shimmer)在内的17种声学特征,分析了利用机器学习技术进行帕金森病诊断的可行性。Tsanas等人[7]在此基础上使用了多种语音信号处理算法得到了相关病理特征,用于区分帕金森病患者和健康人。M oro-Velazquez等人[8]介绍了利用小波变换等方法提取帕金森病语音特征并用于帕金森病诊断和评估的方法。在语音特征提取方面,近年来出现了深度特征学习方法,通过对原始特征进行多层非线性变换,可获得具有更好判别能力的新特征。国内外学者尝试在语音数据中应用有监督的深度学习实现帕金森病的诊断,并取得了积极的成果[9–13]。
与有监督的方法相比,自监督方法可以从未标注数据中学习到数据的底层结构表示,从而有助于提高下游任务的性能和收敛速度[14]。目前,自监督的特征提取方法已经在语音信号处理领域取得了很好的效果。对比预测编码(Contrastive Predictive Coding,CPC)使用多层卷积神经网络编码过去的语音表示序列,可在对比二进制分类任务下预测潜在的语音表示序列[15]。自回归预测编码(Autoregressive Predictive Coding,APC)则使用自回归模型对过去语音表示序列的时间信息进行编码[16]。CPC和APC都属于未来预测编码,这类方法的一个显著不足在于它们只能按照语音的前向顺序进行单向分解。然而,对模型架构的单向性约束将使模型无法很好地预测潜在的语音表示序列,限制了语音表示学习的潜力。与前两种方法不同的是,掩蔽预测编码(M asked Predictive Coding,MPC)从原始语音序列中提取部分语音表示进行掩蔽,根据剩余的语音表示重构出被掩蔽的语音表示;MPC模型使用了同自然语言处理中BERT算法的掩蔽语言模型(M asked Language M odel,M LM)相类似的结构,本质是对基于T ransform er的模型进行预测编码[17]。通过T ransformer编码器的使用,MPC可以对语音序列从前后两个方向进行表示学习,从而克服了CPC和APC方法的单向性约束,实现了语音的深度双向预测编码[18]。此外,掩蔽自监督模型还拥有更快的训练速度,能够更好地利用相关语音序列信息[17]。在许多语音识别基准测试中,掩蔽自监督模型的性能明显优于单向自监督学习模型[19,20]。
本文将掩蔽自监督模型用于帕金森病患者语音特征的提取,来实现基于语音的帕金森病检测。首先,从帕金森病患者的原始语音中提取出富含病理信息的M el语谱图特征,对患者语音进行全局时序化表示;然后,利用掩蔽自监督模型来掩蔽部分Mel语谱图特征并对其进行重构,从而学习到帕金森病患者语音的更高级特征表示,并利用后续的帕金森病检测结果来评估所提的掩蔽自监督模型的性能。其中,为解决帕金森病语音数据稀缺的问题,先在LibriSpeech公开数据集上对掩蔽自监督模型进行预训练,然后基于迁移学习的思想,利用帕金森病语音数据对预训练好的掩蔽自监督模型进行微调和加权求和,以提升该模型特征表示学习的性能。结果表明,与传统的M el语谱图特征检测方法相比,所提方法在准确率、敏感度、特异度性能上分别提高了3.8%,14.5%,3%以上;与其他经典自监督特征提取方法相比,所提方法的检测准确率、敏感度、特异度性能分别提高了4.3%,4%,4.4%以上。
2 相关工作
2.1 语音的时频化表示
时域分析和频域分析是语音信号的常规分析方法。然而,单一的时域波形和频域频谱都有局限性,无法综合展现语音信号的时频域变化关系。因此,人们常使用短时傅里叶变换,将语音的时域信息和频域信息同时转化到时频域,实现语音的时频化表示[21]。
持续元音可以评估发音困难的程度,与其他持续元音相比,元音/a/发音更简单,且携带更多的临床有用信息,因而使用持续元音/a/进行帕金森病诊断可以取得更好的效果[6]。健康人(Healthy Controls,HC)和帕金森病患者的语音信号在时域波形和频域频谱图上均存在明显的差异。在时域上,二者语音信号振幅的相对变化不同,帕金森病患者的波形常伴有异常的波动;在频域上,二者的频谱能量在高频和低频处的分布也存在差异,帕金森病患者的高频能量明显增加;在时频域的语谱图上,健康人语音信号的能量分布的范围更加集中,在低频处分布更加均匀,在高频处能量更低[22]。
2.2 语谱图特征[21]
语音特征的选取对基于语音的帕金森病检测有重要影响。语谱图能够综合展现语音信号的时频域变化关系,因此常被用作语音分析的有效工具。本文中使用了常见的3种与语谱图相关的特征,分别为M el语谱图、Fbank和MFCC。其中,M el语谱图可通过对原始语音信号进行预加重、分帧、加窗、短时傅里叶变换、M el滤波等步骤获得。对M el语谱图特征取对数即可获得Fbank特征,对Fbank特征做离散余弦变换可以得到MFCC特征。
需要指出的是,离散余弦变换可以消除与音素判别关系不大的谐波,保留包络信息。但是,作为一种线性变换,离散余弦变换会丢失语音信号中的一些非线性信息。为最大限度地保留帕金森病语音中的信息,本文后续将以M el语谱图作为特征提取模块的输入。
2.3 CPC模型[15]和APC模型[16]
对比预测编码(CPC)由Van den Oord等人[15]提出,该方法通过在对比二进制分类任务下对未来语音帧进行预测,实现了从高维语音信号中学习潜在语音表示的目的。CPC模型的主要结构包括非线性编码器ge和自回归模型ga。首先,ge将输入语音序列xt(t=1, 2, ···, n)映射为隐藏语音表示r t=ge(x t),然后将r t馈送到ga以产生潜在表示w t=ga(r≤t)。为了预测语音序列的未来值x t+k,构造概率密度函数f k(x t+k,w t),用于保留x t+k和w t之间的互信息。为了优化编码器ge和自回归模型ga,将对比损失最小化
其中,N表示X={x1,x2,···,x N}中样本个数,其中一个来自分布p(x t+k|w t)的正样本,其余为来自分布p(x t+k)的负样本。
和对比预测编码一样,自回归预测编码(APC)[16]也属于预测编码模型。但与前者不同的是,自回归预测编码使用自回归模型对未来语音帧进行预测,并且直接优化输入语音序列和输出语音序列之间的L 1损失。在输入序列x t(t=1,2,···,n)和输出序列y t(t=1,2,···,n)的情况下,L 1损失定义为
3 基于掩蔽自监督语音特征提取的帕金森病检测方法
为更好地提取帕金森病患者语音中的病理信息,提升评估和检测的准确率,本文提出一种基于掩蔽自监督表示学习的帕金森病检测方法。图1展示了所提的基于掩蔽自监督语音特征提取的帕金森病检测模型及其训练过程。其中,掩蔽自监督语音特征提取模型的训练包括源域预训练和目标域微调两个部分。首先,对LibriSpeech公开语音数据集[23]进行预处理和语谱图特征提取,将结果输入掩蔽自监督模型进行预训练;然后,基于迁移学习的思想将预训练好的掩蔽自监督模型参数迁移至目标域,利用帕金森病数据集对模型进行微调,在目标域对模型进行微调和加权求和,并更新模型参数;最终,得到用于帕金森病检测的语音特征表示。后续,可将提取出的语音特征表示送入分类器,完成下游的帕金森病检测任务。
3.1 掩蔽自监督语音特征提取模型结构
本文将文献[18]的掩蔽预测编码思想引入帕金森病语音特征的表示学习,提出基于掩蔽自监督的语音特征提取模型,该模型使用T ransform er编码器[17]实现了双向编码[24],具体结构如图2所示。
将从原始语音信号中提取出的M el语谱图特征x t(t=1,2,···,n)作为掩蔽自监督语音特征提取模型的输入。根据文献[17]附录C.2节中的实验结果选取最优掩蔽策略,即选择每个输入序列中15%的帧进行掩蔽,被选择的帧在80%的时间内将被零向量替换,10%的时间内替换为随机位置的其他帧,剩余10%的时间内保持不变,掩蔽规则如图3所示。

图3 以M el语谱图为例的随机掩蔽规则
原始语音信号的语音帧数据量大,需要降低输入序列维度。在本文所提的掩蔽自监督语音特征模型中,对掩蔽后的输入序列进行3倍下采样,将长度为n的输入序列变为长度为n/3的序列。由于T ransform er编码器不包含递归和卷积,所以使用位置编码来使模型了解输入序列的顺序[25]。由于声学特征可以为任意长度且具有高方差[26],因此在模型中引入正余弦位置编码
其中,pos表示语音序列中的位置,i表示语音帧的位置,dmodel表示语音帧的维度。在位置编码中引入正余弦函数,使得对于任意间距长度k的语音帧,其位置编码PE(pos+k)可以由PE(pos)经过线性函数计算得到。
将经过3倍下采样后的输入序列与位置编码相加,作为T ransform er编码层的输入。通过3层的T ransformer编码器提取到帕金森病患者的语音表示c t(t=1,2,···,n/3),其中,每个编码器层有两个子层,分别为多头自注意力层和前馈神经网络层,模型中的所有编码器层以及其子层输出维度均为n/3。
最后,经过全连接层得到重构后的M el语谱图z t(t=1,2,···,n/3),并通过上采样重新映射成长度为n的序列。在输入的M el语谱图特征与重构后的Mel语谱图特征之间计算L1损失,其计算可参考式(2)。
3.2 基于迁移学习的掩蔽自监督模型训练过程
深度学习模型的性能很大程度上依赖于训练数据集的规模。由于帕金森病语音数据的稀缺性,直接将帕金森病语音数据用于掩蔽自监督模型的预训练,将难以得到很好的模型性能,且容易过拟合。
本文采用迁移学习,将说话人识别领域中的LibriSpeech语音数据集中100 h子集的语音作为源域数据集,通过学习不同的语音来进行说话人分类检测任务,训练过程如图1橘色虚线框所示。将帕金森病语音检测为目标域检测任务,帕金森病语音数据集作为目标域的训练样本,训练过程如图1绿色虚线框所示。将上述预训练模型中的参数作为目标域模型的初始化参数。
基于迁移学习的掩蔽自监督模型训练过程通过在源域数据集上进行预训练,再将模型迁移到目标域数据集上进行微调,从而大幅提升掩蔽自监督模型的泛化性能。
3.3 结合帕金森病检测任务的微调
利用掩蔽自监督模型提取语音特征本质上是提取T ransformer编码器的输出。本文采用了3种提取编码器输出的方法:直接从T ransform er编码器的最后一层提取、微调后提取、经过加权求和后提取。
微调后提取的方法是将预训练后的掩蔽自监督模型在帕金森病语音数据集上微调2个epoch,更新了掩蔽自监督模型的参数后,再从T ransform er编码器的最后一层提取输出。
经过加权求和后提取的方法则是采用来自3层T ransform er编码器输出的混合表示,通过softmax函数进行权重计算,其公式可以表示为
其中,以第j层编码器输出为例,h j为第j层编码器输出值,L为编码层总层数,S(h j)则为第j层编码器输出的权重。将3个编码层的输出进行权重分配并求和来整合所有层的输出,其计算公式为
其中,f为经过加权求和后的输出特征,l为当前计算层数,L为编码层总层数,s l为第l层的归一化权重,h l为第l层编码器输出值。
4 实验
4.1 数据集
本文使用了3个语音数据集,包括LibriSpeech公开语音数据集[23]、M ax Little帕金森病语音数据集[27]和本课题组自采的帕金森病中文语音数据集。
LibriSpeech数据集是由Vassil Panayotov发布的一个包含约1000 h英语语音的大型数据集[23]。本文从中选取总计100 h的语音数据子集(train-clean-100)作为自监督模型的预训练数据集,预训练数据集包含251名说话人的音频数据。经剪辑整理成每条10 s左右的音频文件,形成采样率为16 kHz的WAV格式音频文件集合。
M axLittle数据集是由牛津大学的Max Little与科罗拉多州丹佛的国家语音中心合作创建的帕金森病检测数据集[27],数据采集均在安静的室内环境进行,采集内容为持续元音/a/,受试者包括23名帕金森病患者和8名健康人,每人重复发声6次。经剪辑整理后,生成41条健康人语音数据和46条帕金森病患者语音数据,共计87条语音实验数据。
自采帕金森病语音数据集是由本课题组与南京医科大学附属老年医院的帕金森病诊疗中心合作采集的。受试者包含56位帕金森病患者(PD)和22位健康人(HC)。数据采集均在安静的室内环境进行。采集内容为持续元音/a/,每人重复发声2~3次。经剪辑整理后,生成59条健康人语音数据和56条帕金森病患者语音数据,共计115条语音实验数据。该数据集的统计信息见表1,其中,HY(Hoeh & Yahr)分期对帕金森病变程度的评估,3期以前属于轻中度,3期以后症状越来越严重。括号内为数据标准差。
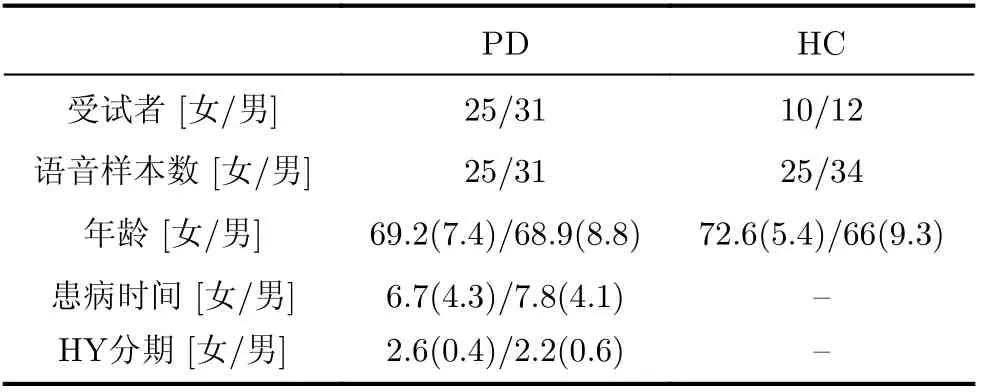
表1 自采帕金森病语音数据集信息统计
4.2 实验条件及过程
实验基于PyTorch深度学习框架实现所有算法。对所有的语音数据集提取[361,140]维的M el特征,采用帧长为25ms和帧移为10ms的滑动窗口对语音信号进行分帧,同时使用Librosa音频处理库去除语音首尾的静音帧。
自监督模型在LibriSpeech数据集的train-clean-100子集上进行了预训练,并使用帕金森病患者语音数据集对模型进行微调。具体地,预训练在4个GPU上进行,总批大小为256,步数为500k。使用Adam优化器[28]改变学习率,其中学习率在500k总训练步骤的前7%上升至峰值4e–4,然后线性衰减。
对所提取的语音特征,使用不同的分类器进行分类,通过10折交叉验证完成下游的帕金森病检测任务。为验证算法的有效性,本文使用准确率(Accuracy,ACC)、敏感度(T rue Positive Rate,TPR)、特异度(T rue Negative Rate,TNR)作为实验结果的评估准则。准确率表示准确区分帕金森病患者和健康人的概率,敏感度代表正确检测出帕金森病患者的概率,而特异度表示正确识别健康人的概率。其计算公式为
其中,TP表示分类正确的帕金森病样本,TN表示分类正确的健康人样本,FP表示将健康人样本误分类成帕金森病样本,FN表示将帕金森病样本误分类成健康人样本。
4.3 实验结果
4.3.1输入特征比较
为验证M el特征在帕金森病检测中的有效性,本文在自采数据集上进行了对比实验,实验结果如表2和表3所示。其中,M el,Fbank,MFCC所对应的方案表示直接将Mel,Fbank,MFCC特征作为后续分类器的输入。Mel-unsupervised,Fbank-unsu-pervised,M FCC-unsupervised所对应的方案则是分别将M el,Fbank,MFCC特征作为本文所提掩蔽自监督模型的输入,将自监督特征提取后得到的用于帕金森病检测的语音特征表示作为后续分类器的输入。表2是使用支持向量机作为分类器时的帕金森病检测实验结果,表3则是使用随机森林作为分类器时的帕金森病检测实验结果。为了进行更细致的分析,表2和表3还针对男性测试数据(Male)以及女性测试数据(Female)进行了进一步的细分。
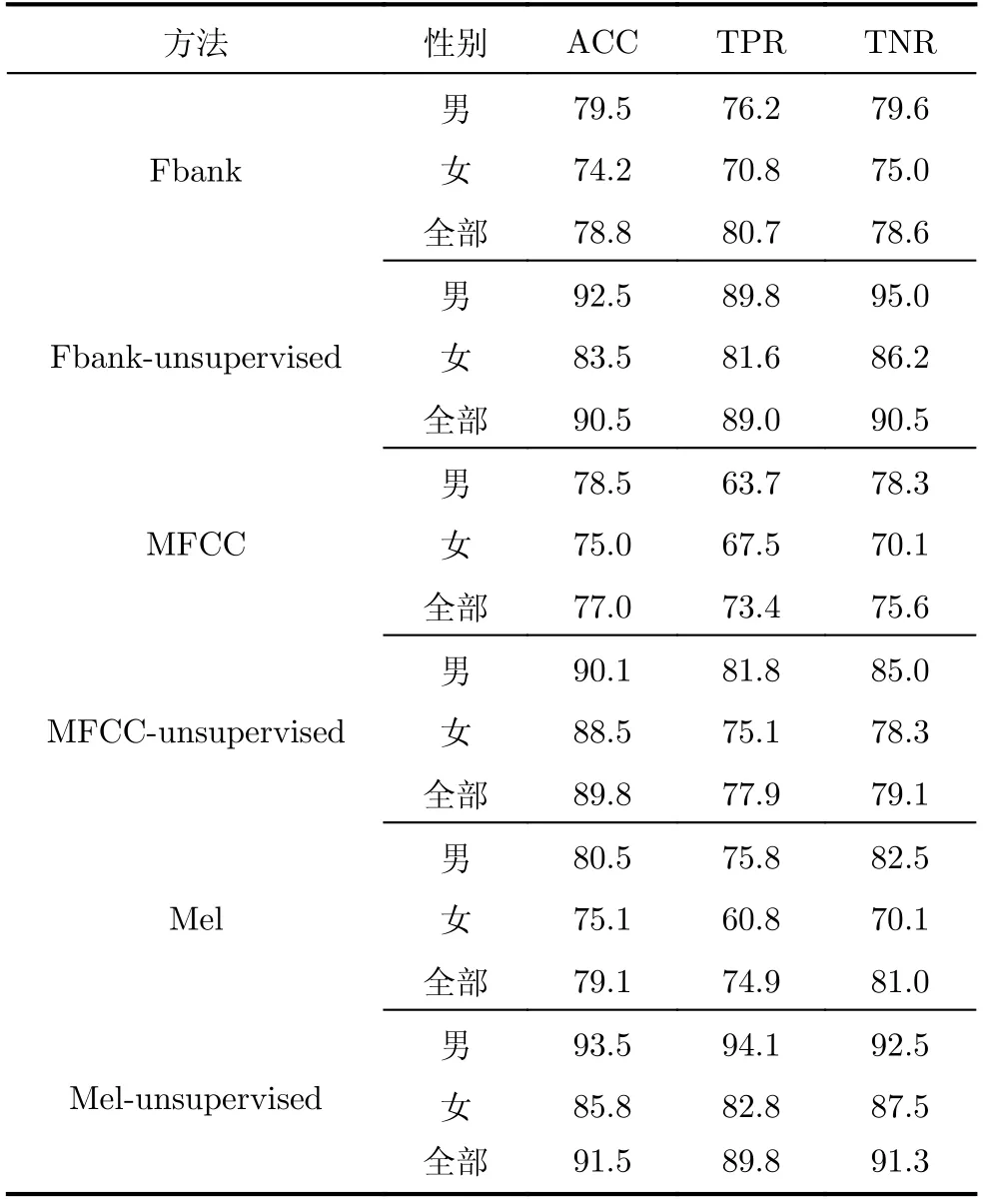
表2 结合支持向量机分类器进行帕金森病检测的实验结果(%)

表3 结合随机森林分类器进行帕金森病检测的实验结果(%)
比较表2和表3的结果可以发现,使用支持向量机作为分类器能获得更好的帕金森病检测性能;在不同性别以及全体数据上,基于M el语谱图特征的帕金森病检测性能要高于基于Fbank特征和基于MFCC特征的情况,基于M el-unsupervised的帕金森病检测性能通常要高于基于Fbank-unsupervised和基于MFCC-unsupervised的情况。
4.3.2自监督模型间比较
为检验本文提出的掩蔽自监督语音特征提取模型的性能,本文首次将在说话人识别领域有良好表现的CPC模型[15]和APC模型[16]引入基于语音的帕金森病检测领域,对不同自监督模型在帕金森病检测领域的表现进行比较。根据4.3.1节实验结果,本实验使用支持向量机作为分类器,以获得更好的帕金森病检测性能。
为证明自监督模型在不同语言的数据集上均具有良好的可迁移性,将自监督模型分别在MaxLittle数据集和自采数据集上进行了实验对比,实验结果如表4和表5所示。其中,M el+SVM对应的是直接将M el特征作为后续SVM分类器的输入进行帕金森病的检测的方案;本文-ft2和本文-w s分别为微调两个epoch的模型和经过加权求和后的模型。从表中可以观察到,在不同数据集上,基于自监督语音特征提取的帕金森病检测方法性能总体上要优于M el+SVM方案的情况;而基于掩蔽自监督语音特征提取的帕金森病检测方法性能要优于基于APC模型和基于CPC模型的情况,对掩蔽自监督模型进行微调和加权求和可以提高模型的帕金森病检测性能。
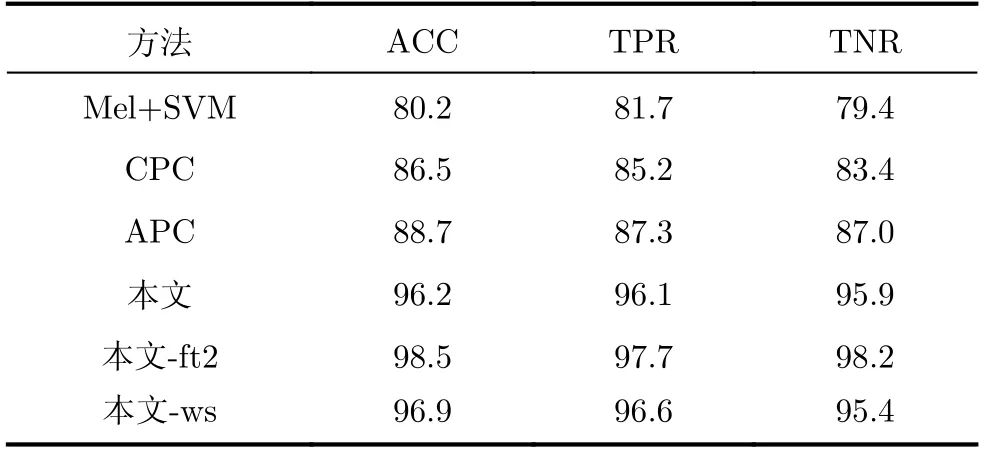
表4 MaxLittle数据集上的对比实验结果(%)
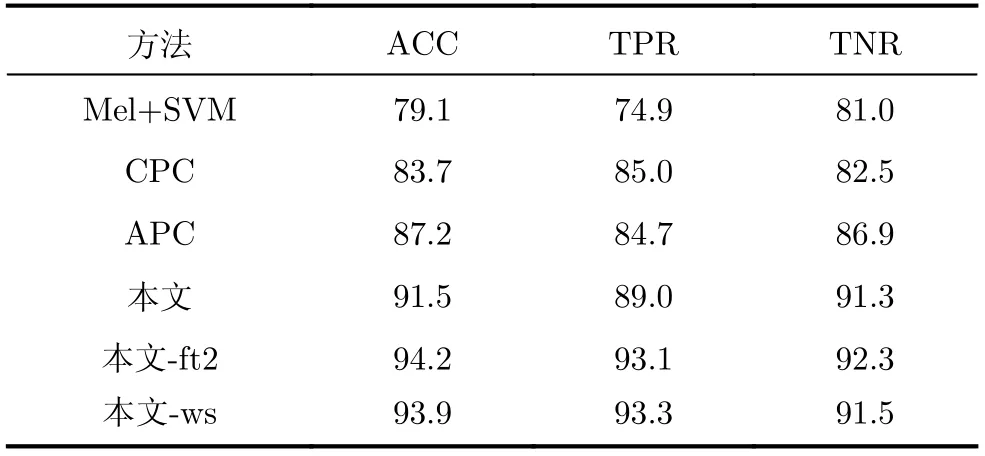
表5 自采数据集上的对比实验结果(%)
为了验证帕金森病检测结果的有效性,在自采数据集中将基于M el语谱图特征和基于掩蔽自监督语音特征的帕金森病检测结果的混淆矩阵进行了对比。其中,真正例为将样本正确识别为帕金森病患者的次数,真反例为将样本正确识别为健康人的次数,假正例为将样本错误识别为帕金森病患者的次数,假反例为将样本错误识别为健康人的次数。基于M el语谱图特征的帕金森病检测结果的混淆矩阵中有45个真正例、47个真反例、12个假正例、11个假反例。而基于掩蔽自监督语音特征的帕金森病检测结果的混淆矩阵中则有51个真正例、54个真反例、5个假正例、5个假反例。从结果可以看出,基于自监督语音特征提取的帕金森病检测方法不仅对受试者的患病情况实现了较好的预测,而且对健康人也有较少的误判。
5 结束语
本文提出了一种基于掩蔽自监督语音特征提取的帕金森病检测方法,该方法利用掩蔽自监督模型来掩蔽部分M el语谱图特征并对其进行重构,从而学习到帕金森病患者语音的更高级特征表示。本文采用迁移学习解决帕金森病语音数据稀缺的问题,并且在帕金森病检测任务上通过对掩蔽自监督模型进行微调和加权求和来提升模型的帕金森病检测性能。自采数据集和M axLittle数据集上的实验结果验证了该方法的有效性。未来的研究工作将集中在利用掩蔽自监督模型对帕金森病患者进行不同病情严重程度的分类。
