基于手语表达内容与表达特征的手语识别技术综述
2023-11-18陶唐飞刘天宇
陶唐飞 刘天宇
①(现代设计及转子轴承系统教育部重点实验室 西安 710049)
②(西安交通大学机械工程学院 西安 710049)
1 引言
世界听障联盟[1]的数据显示,目前全球有超过7×107人使用超过300种手语沟通交流。据相关媒体数据,我国语言障碍、听力障碍人数超过3×107人[2,3]。听障与语障人士是主要的手语使用者。手语识别技术能够帮助手语使用者在社会生活中打破与普通人群的交流障碍。手语识别(Sign Language Recognition, SLR)可被定义为利用计算设备将手语转换成文本或语音信息[4]。手语识别技术的研究内容主要包括手语采集方法与手语识别方法:(1)在手语采集方面有数据手套[5,6]、颜色手套[7]、K inect[8,9]设备、体感控制系统(leap motion)[10]等丰富的信息采集设备。采集设备的多样性也使得手语数据集的数据形式多样化。(2)手语识别方法的研究从手语表达内容可分为孤立词的识别研究[11,12]及连续语句手语识别[13,14];从识别方法所用的特征种类可以分为仅依靠手部特征方法以及多特征融合方法,多特征融合方法能够有效提高模型准确率与鲁棒性[15]。在深度学习未得到大规模应用前,基于机器学习的手语识别方法[16,17]比较普遍。然而传统机器学习方法泛化能力弱,无法构造完整的语言识别体系;处理大规模数据的能力不足,无法构建高精度手语识别模型;特征学习能力不强,无法构建精细化、鲁棒性高的识别方法。深度学习方法能够解决传统机器学习的限制。
在手语识别方面已有一些综述性工作,张淑军等人[18]总结了基于深度学习方法手语识别技术,但对迁移学习、零样本学习等解决数据标注瓶颈的方法缺少阐述。米娜瓦尔·阿不拉等人[19]从静态手语、孤立词和连续语句识别3个分支出发总结手语识别方法,但未关注多特征融合的手语识别方法。郭丹等人[20]回顾了手语识别、翻译和生成任务的典型方法和前沿研究,并总结了常用数据集,但其在总结手语数据集时未给出数据集发展建议。基于此,本文系统梳理了手语识别的相关技术,包括手语数据集及其发展趋势、手语识别方法评价指标、手语识别方法及其发展趋势,总结了注意力机制以及多特征融合的手语识别方法。为缓解手语数据限制,强调了迁移学习以及零样本学习在手语识别中的应用。文章结构如下:第2节阐述手语数据集,并总结其发展方向;第3节介绍手语识别方法的评价指标;为便于对比评价手语识别方法,在总结了手语数据集及手语识别方法评价指标后,第4节总结手语识别方法;最后探讨手语识别技术现阶段存在问题及未来发展趋势。
2 手语数据集
手语识别技术的发展离不开大规模数据集的建立,现阶段很多国家已经开启了手语识别技术的研究。表1、表2分别总结了具有代表性的孤立词与连续语句手语数据集。在手语识别研究方面,中国、德国、美国以及伊朗等国家已建立起手语数据集[21,22]、手语识别的研究已初具规模。本节按照中国、德国、美国以及其他国家的先后顺序分别介绍孤立词与连续语句手语数据集并总结现阶段数据集的发展趋势。
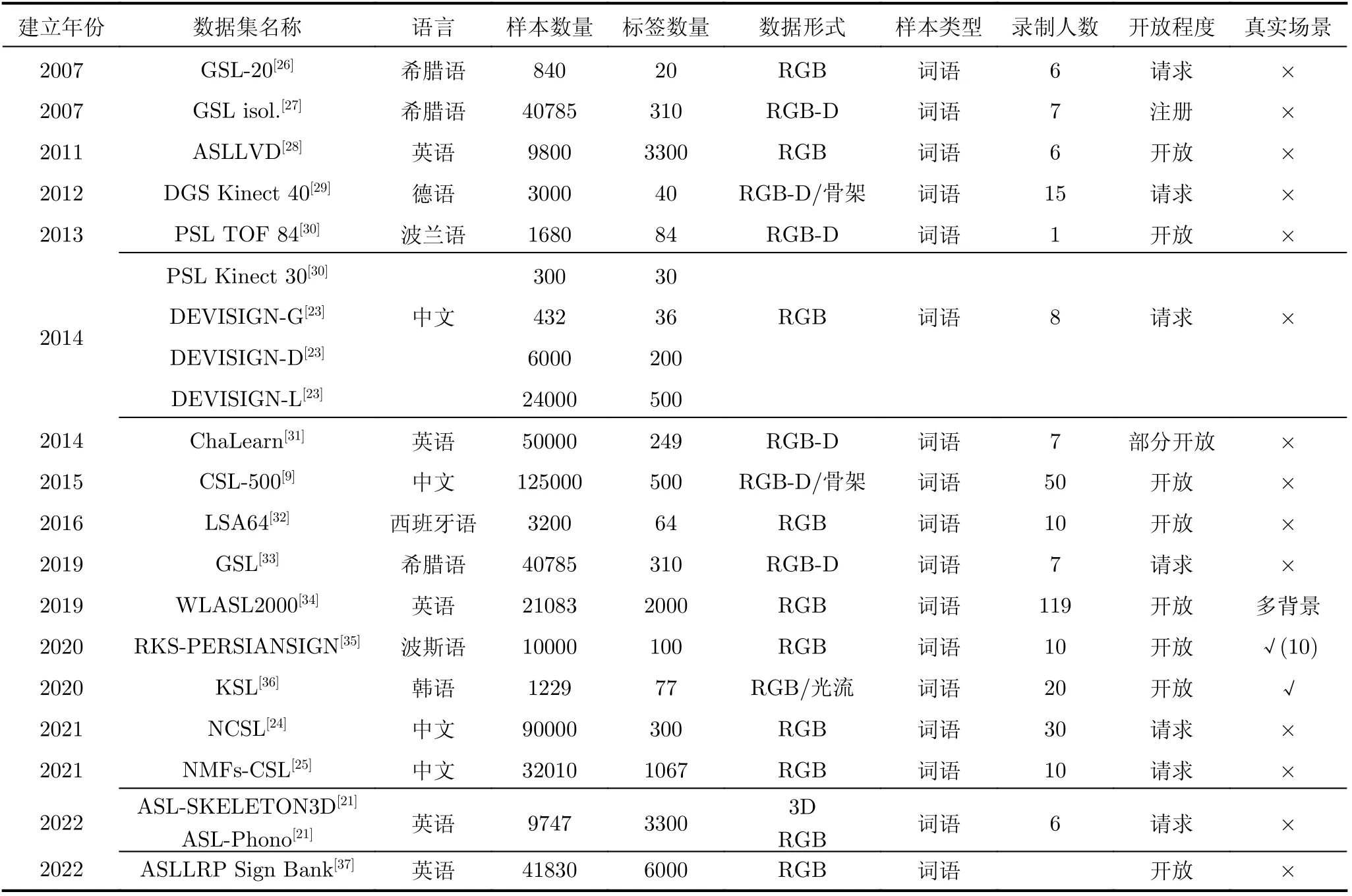
表1 孤立词手语数据集
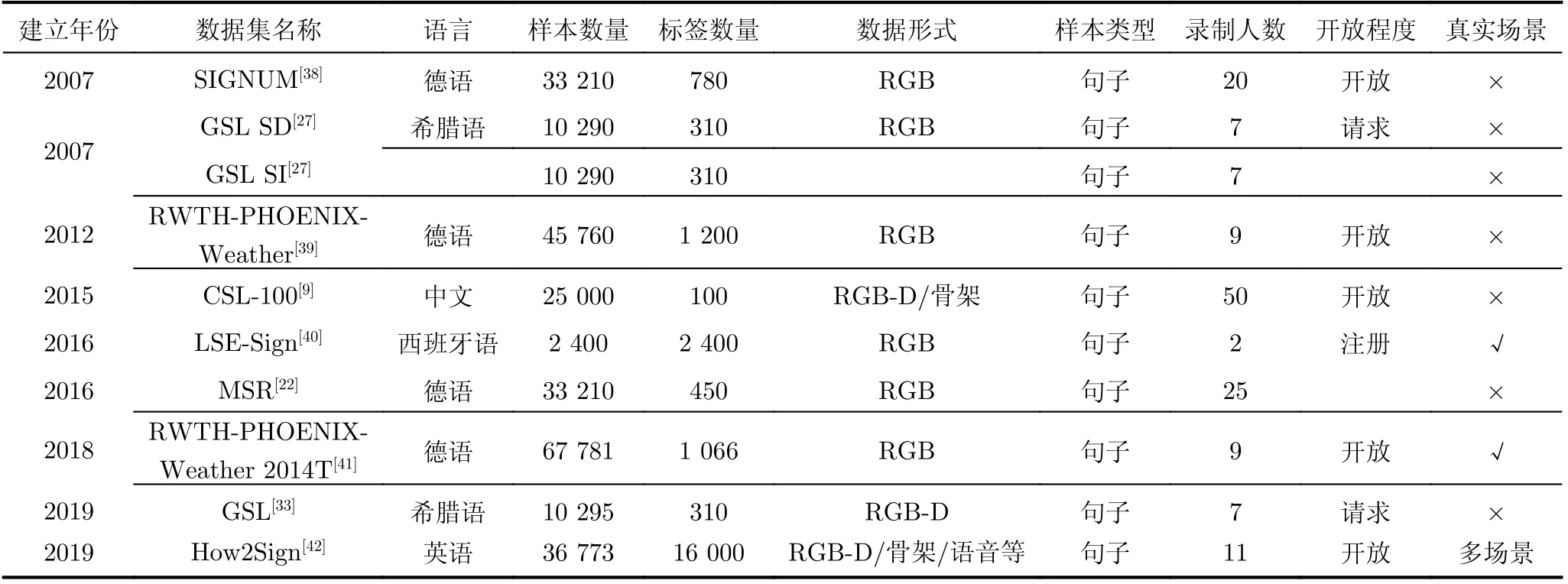
表2 连续语句手语数据集
2.1 孤立词数据集
表1总结了孤立词手语数据集的相关信息。在孤立词的数据集方面,3维手语识别评估数据集(Dataset and Eva luation for 3D SLR, DEV ISIGN)[23]是中国第1个样本数量达到万级的大型孤立词手语数据集。中国孤立词手语识别数据集(Chinese isolated SLR500 dataset, CSL-500)[9]拥有500个词语标签,数据形式多样,具有骨架信息、深度视频信息以及RGB视频信息,是中国手语孤立词识别领域颇具重量级的数据集。近年来手语领域研究队伍逐渐壮大。2021年,东北大学王斐团队[24]建立的NCSL数据集关注在手语演示过程中的个体差异以及演示差异问题。同年,中国科学技术大学团队提出了非手控特征中国孤立词手语数据集(Non-Manual-Feature-aware isolated Chinese Sign Language dataset, NMFs-CSL)[25],该数据集关注非手控特征,例如:面部表情、嘴型等。非手控特征对于模型的鲁棒性及准确率的提升具有关键作用。
德国是大型孤立词手语数据集发展最早的国家之一。最初的SIGNUM[38]数据集,由33 210个样本组成,该数据集开启了德国手语孤立词大规模数据的时代。随后有德国手语(German Sign Language,DGS) Kinect40[29]数据集,包括骨架信息、深度信息以及RGB视频信息。
英语手语数据集的发展也相对较早且影响广泛,美国手语词典视频数据集(Am erican Sign Language Lexicon Video Dataset, ASLLVD)[28]由6人录制完成,具有3 000多词汇、字母等。英语在国际交流中占有非常重要的位置,因此对ASLLVD的研究颇多。例如:美国3维骨架手语数据集(Am erican Sign Language SKELETON 3D,ASL-SKELETON 3D)[21]将ASLLVD多角度下的视频转换成3D数据,保留9 747条视频;美国手语研究项目手势库(American Sign Language Linguistic Research P ro ject Sign Bank, ASLLRP Sign Bank)[37]增强了语言的注释性,在网页端展示了手语的动作及相关含义,并且大幅提升了样本数量。除ASLLVD系列数据集外,英语手语另有影响力广泛的数据集:ChaLearn[31]数据集具有深度视频信息,由7人录制完成,具有50 000条视频;美国手语词汇数据集(W ord-Level Am erican Sign Language, W LASL2000)[34]在多种背景下录制,更注重数据集的真实场景,一定程度解决了词汇量少、录制人数少等问题,且数据集已在Github上开放。
其他数据集另有希腊手语孤立词(G reek isolated Sing Language, GSL isol.)[27]数据集,是最早的大型孤立词手语数据集之一。伊朗的RKS-PERSIANSIGN[35]数据集,录入时更换多场景,数据集开放。韩国手语数据集(Korean Sign Language,KSL)[36]由20位听障人士录制而成,能够表达出真实的手语细节特征及使用姿态,数据的真实性与应用性更强。
2.2 连续语句数据集
表2总结了连续语句手语数据集的相关信息。中国连续手语数据集(Chinese continuous SLR100 dataset, CSL-100)[9]是中国连续语句大型数据集,采用M icroso ft K inect录制,共有100条语句,25 000条视频。此数据集在国际上具有影响力,其数据庞大,填补了我国连续语句的大型手语数据集的空白。
影响广泛的RW TH-PHOENIX-W eather[39]德国手语天气数据集系列包括2014年发布的PHOENIXW eather 2014,以及2018年发布的PHOEN IXW eather 2014T[41]。此数据集来自德国电视台的天气播报场景,虽然背景单一,但更偏向于真实应用。德国的MSR[22]数据集属于连续语句大型数据集,样本数量达30 000。
美国的How2Sign[42]数据集具有RGB信息、深度信息、关节点信息以及语音信息等多输入模态,是拥有16 000个词汇量的大型手语数据集,录入时长达80 h。
其他代表性连续手语数据集有希腊手语数据集GSL[33], GSL SI[27]和西班牙手语数据集(a Lexical database for Spanish Sign language, LSE-Sign)[40]等。
2.3 数据集发展方向
手语数据集是手语识别技术的基础,手语识别方法本质上依靠数据驱动。本节指明手语数据的发展方向,使手语数据集的创建更符合手语识别技术的研发需求。
(1)更接近真实环境。真实应用环境包括:(a)手语录入者为真实的听障人士,更能表现出真实表情与手语姿态;(b)真实场景;实验室环境过于单一,训练后的模型应用到真实环境中识别表现不佳。
(2)多信息模态,多角度视频数据集。多信息模态结合能够增强手语识别方法在复杂环境下的鲁棒性,使用多角度视频训练的方法能够有效改善视角变化、手部遮挡等识别难题。多模态信息的手语采集与识别设备多样且复杂。开发多模态联合手语采集识别设备是多模态融合手语识别方法的应用推广前提。
(3)加强数据的注释性。部分数据集[37]在网页端展示手语的动作及释义,能够让实验人员深入理解动作、词汇的含义,应用到模型中可增强泛化能力,同时手语动作图解数据集是零样本学习方法的基础。
(4)多特征标注。手型固然是手语最重要的传递语义信息的特征,但脸部、肢体同样在手语表达中发挥关键性作用,因此手语数据集应录入标注唇形、面部表情等多特征。
(5)多语手语数据集。现阶段手语识别方法缺乏不同语言的比较研究,同时基于此类数据集的手语翻译方法能够有效促进手语使用者的国际化交流。
3 手语识别方法评价指标
手语识别方法评价指标用来衡量手语识别方法的识别效果。手语识别方法的评价指标包含自然语言处理领域使用的错词率、杰卡德系数等以及机器学习通用的准确率、精度等。手语识别方法常用评价指标包括:(1)错词率(W ord Error Rate, WER)[43]是目前使用较为广泛的评价指标,借鉴了自然语言处理中语音识别的指标。W ER是计算翻译语句转化为标签语句中的删除、插入和替换操作的最小数量,W ER越小,模型识别性能越好。除错词率外,外文手语识别中还有字符错误率(Character Error Rate, CER);(2)杰卡德系数(Jaccard index)[31]用于比较两个样本之间的相似性与差异性。指标数值越高,相似性越高,证明模型识别效果更好;(3)准确率(Accuracy, Acc)是指被正确划分的样本数占所有样本数的比例。模型的准确率越高,识别性能越好;(4)ROC曲线下方面积(A rea Under roc Curve, AUC)[44]是为了解决模型识别准确率与模型实际作用效果不匹配的问题。该指标通常用于手语识别中的手部跟踪以及手部姿态检测;(5)平均精度均值(mean Average Precision, m AP)[45]是在目标检测中常用的评价标准,即各类别的关节平均检测率的均值。通常情况下,m AP数值越高,识别效果越好。该指标常用于手部关节点信息检测;(6)另有一些工作采用运行时间[46]、精度[47]等作为评价指标。
在连续手语识别中错词率是使用最广泛的评价指标,其能够允许识别句子中词汇的位置变化,符合语言规则。在孤立词手语识别中,当准确率作为评价指标时简洁干脆,无论外文中的字母错误还是中文的汉字错误都会影响词汇含义,但准确率会产生与模型实际作用效果不匹配的问题。而AUC指标能够避免产生少数样本准确率高而被认为识别效果更好的问题。平均精度方法适用于手部检测、关节点检测等基于目标检测的手语识别方法。杰卡德系数描述两个样本间的相似程度,适用于高稀疏度的数据中,评判手语模型的容错性高。运行时间评判模型的训练效率,但评判内容单一,实际应用性不足。
4 手语识别方法
根据手语的表达内容,手语识别可分为孤立词手语识别和连续语句手语识别。孤立词手语识别可以看作视频的分类问题,而连续语句数据集中只给出了视频标签,所以属于不确切监督问题,但随着近年来数据集注释性的增强,有利于不确切监督问题的处理。手部特征与非手控特征结合的手语识别模型能够一定程度提升模型的准确性以及鲁棒性。本节基于手语表达内容(孤立词与连续语句识别)以及手语识别方法所采用的特征(仅依靠手部特征、多特征融合)分别介绍手语识别方法。
4.1 孤立词与连续手语识别方法
针对手语识别方法使用的数据集可以分为孤立词手语识别与连续语句手语识别方法,本节介绍孤立词与连续语句的手语识别方法。
4.1.1 孤立词手语识别方法
孤立词手语识别也称为离散手语识别,是指识别单个词或字节。孤立词的研究着重于模型准确率、轻量化与推理速度的提升。表3分类总结了孤立词的研究方法,涉及经典神经网络模型、基于注意力机制模型等。为解决手语数据标注瓶颈,又介绍了迁移学习方法以及零样本学习方法。
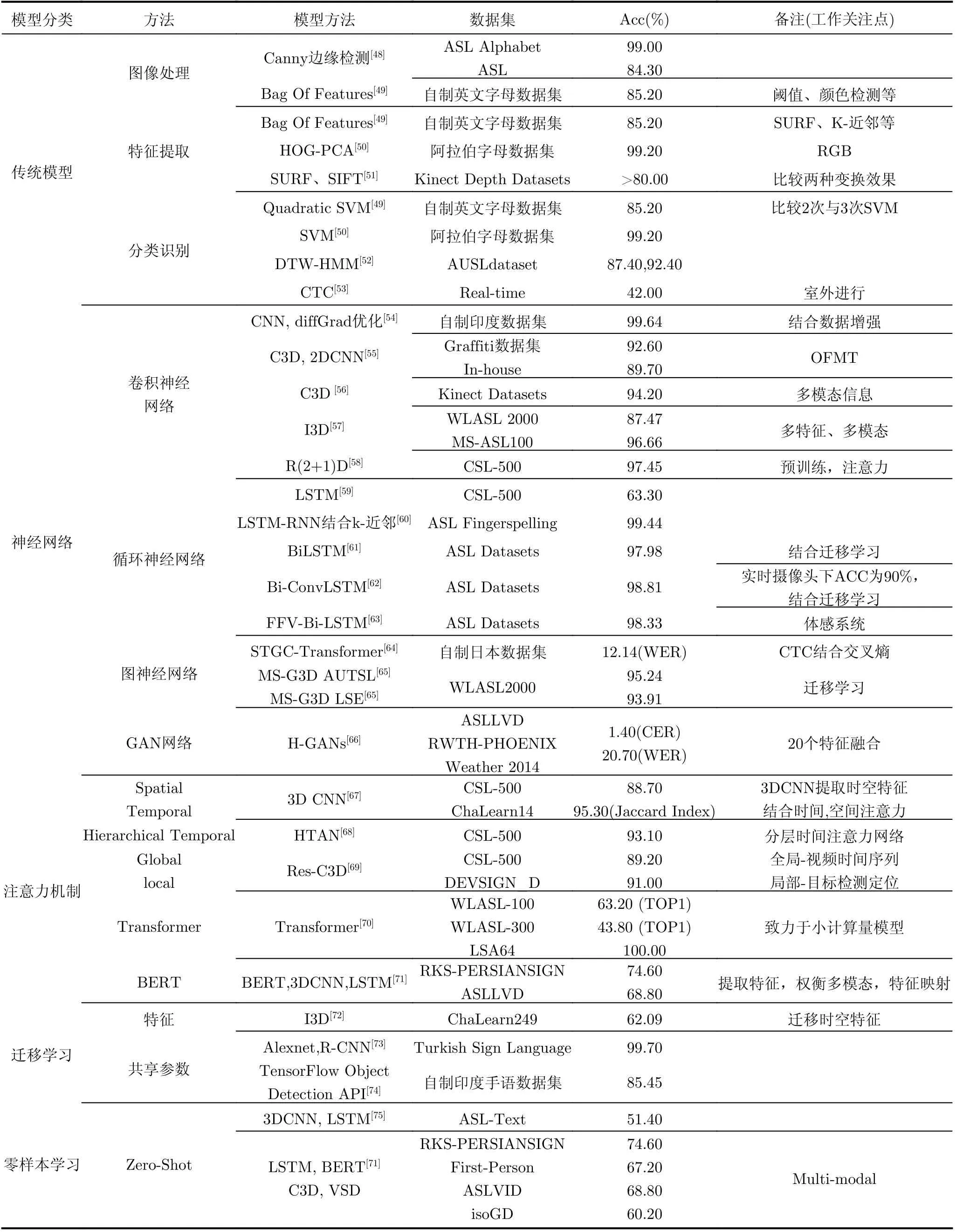
表3 孤立词手语识别方法
(1) 传统模型方法。传统模型可将整个手语识别方法流程划分为图像预处理、特征提取以及分类识别。图像预处理方法包括视频处理、减少噪声干扰、增强识别效果;特征提取方法用来提取图像特征,为识别建模做准备;最后在分类识别环节中对处理后的视频、图像分类识别。
(a)图像预处理方法。视频要转化成帧图像来搭建训练手语识别模型,对帧图像的处理效果影响着模型的识别性能。手语识别图像预处理方法可以分为两类:①去除噪声及背景干扰。直方图均衡化[50]、颜色检测[49]及肤色的背景减除[76]方法可以有效避免背景信息对手语表达的干扰;利用滤波器[77]去除图像噪声。②减少数据计算量。比如使用边缘检测[48]、灰度化方法[49]、分割阈值[78]等方法减轻模型训练的计算负担。
直方图均衡化可去除冗余干扰信息,颜色检测减少背景干扰,结合小波变换、傅里叶变换等方法构造滤波器去除噪声干扰,但上述方法处理后的图像计算量依然颇高。边缘检测、分割阈值方法能够减少数据量,但手语表达的关键信息也可能会被省略。灰度化方法将RGB图片转化为灰度图片,通道数量减少,无法去除图片中影响手语表达的干扰信息。手语识别工作结合两类预处理方法后处理效果更佳,例如文献[76]在预处理阶段运用背景减除方法排除接近肤色干扰,通过高斯模型检测肤色区域并转化为二值化图像。
(b)特征提取方法。主成分分析[50](Principal Com ponent Analysis, PCA)、K-近邻方法[49]对图像信息进行降维处理,精简并保留显著性特征,减轻计算负担,利于模型训练。尺度不变特征变换匹配(Scale Invariant Feature T ransform, SIFT)[51]具有尺度不变性,对光线、噪声等影响因素的容忍度高,但在手语识别特征提取方面表现效果不佳,且需要较多内存空间。加速鲁棒特征(Speeded Up Robust Features, SURF)[49,51]是以2D离散小波作为描述子,在图像变换中具有稳健性,比SIFT具有更快的特征提取速度,但对图片质量、环境要求高,实用性弱。
(c)分类识别方法。分类识别方法包括两部分:①规划分类方法。该类方法主要包括支持向量机[50](Support Vector M achine, SVM)。SVM通过改变核函数来完成不同的识别任务,比如2次支持向量机[49](Quadratic SVM)及3次支持向量机[49](Cubic SVM)在手语识别中均有使用。②时序分类方法。此类方法主要包含动态时间规整[52](Dynam ic Time W arping, DTW)、隐马尔可夫模型[52](Hidden M arkov M odel, HMM)以及连接时序分类[53](Connectionist Tem poral Classification, CTC)方法。
SVM算法简单,鲁棒性强,但训练速度慢,核函数选择敏感,易产生错分、不可分现象,无法处理序列关系,通常适用于静态手语识别方法。DTW基于动态规划思想,根据最小路径(即比较手语序列间相似性)匹配识别目标,此方法需要构建模板库,泛化能力弱,上下文关系处理能力差,限制手语数据集规模。HMM作为统计分析模型,训练学习到的是状态和观察序列的联合分布,但其依然无法利用手语表达过程的上下文信息。CTC方法扩展标签集合,无需数据对齐处理,通常与卷积神经网络等深度学习方法结合,表征时序关系,在手语识别任务中的识别效果较好。
(2) 经典神经网络方法。与传统机器学习方法相比,神经网络方法在大数据、大样本下处理效果强悍,泛化能力强,具有非线性映射能力,能够实现多任务集成,开发综合系统。其中主要的神经网络方法包括卷积神经网络方法[54]、循环神经网络方法[79,80]、图神经网络方法[64]等。
(a)卷积神经网络(Convolutional Neural Network, CNN)方法。卷积神经网络具有强大的局部特征提取能力。由于手语识别多涉及时序关系,在卷积网络中只依靠1维卷积难以达到要求,通常应用多流2维卷积以及3维卷积网络表征手语数据的模态信息、特征融合以及时序关系。文献[56,57,81]分别提出了结合多尺度空间信息,图像关节点位置、深度视频等模态信息,手部、面部表情等特征信息的多流卷积手语识别模型。识别模型通常随着网络深度增加而提升识别效果,但深层网络需要更多的手语数据。由此文献[54,81]将卷积网络与数据增强技术结合,避免出现过拟合问题。2维卷积网络适合单帧图像的特征提取,3维卷积网络(3D Convolutional neural network, C3D)[55,56,81]则可以处理视频上下文关系,提取手语视频时空特征。C3D的网络结构浅,难以实现高准确率,在大型数据集中尤甚,由此膨胀3维卷积网络(Inflated-3D, I3D)便应运而生。Maruyama等人[57]提出多流框架搭建I3D模型,结合手型、面部表情、骨架信息等,最终在W LASL 2000数据集中最高的识别准确率达到87.47%。此外,伪3维残差网络(Pseudol-3D residual network, P3D)[82]可以缓解参数数量以及运行内存的限制难题。手语冗余信息与时空关系复杂,因此将3D卷积核优化为R(2+1)D[58],减少训练时长,并提高分类精度。
多流卷积网络可以结合丰富的手语表达相关信息,提高模型的识别性能。2DCNNs网络即使配备了TConvs等时序建模模块,在表达短期时序关系方面仍然不如3DCNN的效果更佳。I3D网络具有更深的网络结构,在孤立词数据集中的识别准确率更高,同时在复杂背景(非实验室环境)下依然能够参数收敛。
(b)循环神经网络(Recurrent Neural Network,RNN)方法。循环神经网络具有强大的序列信息处理能力,通常用于时序建模。传统时序模型很难适应手势在不同的词汇中的巨大变化[59],循环神经网络通过隐藏层节点周期性连接来捕捉序列化数据中动态信息。RNN在模型训练时参数较多,网络结构复杂,训练困难,双向循环神经网络(B idirectional RNN, Bi-RNN)和长短期记忆网络(Long Short-Term M em ory networks, LSTM)的发展改善了循环神经网络所面临的问题。文献[60,61]利用Bi-RNN与LSTM模型缓解了由于长期依赖问题而导致的RNN梯度消失和梯度爆炸的问题,但其不能够并行计算,计算耗时长,在更长序列中梯度问题仍然棘手。由于RNN网络的复杂性,文献[60,62]以循环神经网络为基础,采用预训练数据的方式降低模型的训练难度。文献[61,62,83]利用循环神经网络提取手语表达的时空特征,解决输出与预测之间的依赖关系,在视频序列与动作标签间建立有效对齐关系。Abdu llahi等人[63]利用快速费舍尔向量,将生成模型用于判别式分类器中,表示高维特征,与双向长短时记忆网络结合,利用体感系统中3维手的骨骼运动、方向及角度信息,并将视频中的身体特征信息融合训练模型。
(c) 图神经网络(G raph Neu ra l Netw ork,GNN)方法。图神经网络方法将信息分布存储于网络内神经元中,大幅提高模型鲁棒性与容错性,文献[64]利用图神经网络模型增强了手语背景变化的鲁棒性。图神经网络能够适应复杂的结构性先验,比如定义多个概念之间关系,描述复杂的非线性结构。文献[84]利用图卷积模型定义相似领域或同一领域不同数据之间的关系,有效传递了先验知识。Yan等人[84]将动作识别的先验知识通过图卷积模型传递到手语识别领域中。Vázquez-Enríquez等人[65]提出了多级时空图卷积网络模型(Multi-scale Spatialtem poral G raph convolu tional netw orks, M SG 3D),并且探讨了基于图卷积网络的不同数据集间的迁移学习能力。MS-G3D模型在AUTSL dataset 进行预训练后,W LASL2000上的识别率准确为95.24%,在LSE_Lex40预训练后的W LASL2000上的识别准确率为93.91%。
(d)生成对抗神经网络(Generative Adversarial Networks, GAN)方法。手语识别视频信息与标签信息没有严格对应的关系,因此属于典型的弱监督问题。GAN网络能够完成半监督学习以及无监督学习任务,且文献[66,85]将GAN网络应用于语义分割与手语识别的弱监督问题中,证明其同样适用于弱监督问题。GAN网络可以跨模态组合、多特征融合训练,利用生成器与判别器组合的形式不断提高模型的判别性能。Elakkiya等人[66]提出的超参数生成对抗神经网络H-GANs模型将手型、手掌形状、头型、脸型、唇形、眼睛等20个特征融合,利用LSTM网络作为生成器,从真实帧序列中生成带有噪声的随机序列。L S T M 网络与3 D-C N N网络结合作为鉴别器,检测并分类符号手势的真实帧。该网络在ASLLVD数据集中的字符错误率为1.4%。
手语识别是弱监督、多分类、跨模态以及多特征融合问题。GAN网络不仅是无监督学习与半监督学习的典范,在弱监督学习中同样适用。其在分类领域也有一席之地,将判别器替换成分类器即可实现多分类任务,生成器仍然可以辅助分类器训练,适用于跨模态、多特征融合任务。但目前尚未发现GAN网络达到纳什平衡的快速有效方法,训练不稳定,且存在模式崩溃风险。
(3) 注意力机制方法。注意力机制是指对输入信息权重分配的关注,能够有效解决编码容量瓶颈以及长距离依赖问题。相比CNN,该方法计算手语输入信息之间关联性的操作次数不随距离而改变。手语识别是一个视觉与语言结合的计算机视觉任务。T ransform er更适合连接视觉与语言,其能够解决视觉与语言的网络结构不同时使得优化器不适配的问题,达到更好的建模效果。其中自注意力机制通过矩阵运算可以一步提取全局特征,卷积操作则适合提取局部特征,因此文献[67,69,71]将卷积神经网络搭配注意力机制形成互补,将全局特征与局部特征结合训练,利用3维卷积模型提取时空特征,注意力机制用于特征映射或关注重要特征。黄杰等人[67,68]提出基于注意力机制的3维卷积网络方法以及分层注意力网络,从结合空间与时间注意力到利用分层注意力关注关键片段的重要视频特征,在CSL-500数据集中不断提高准确率。Zhang等人[69]构建了全局-局部特征结合描述的手语识别框架,提出带有注意力层的3维残差全局网络模型和基于目标检测的局部网络模型。全局特征描述基于整个视频行为进行时间序列建模。在局部模块中,通过目标检测网络定位主导手,突出手部行为的关键作用,从而增强类别差异,并补偿全局网络。T ransformer模型可以并行计算,提高计算效率,可为手语识别在手持设备中推广提供更高可能性[70]。
T ransformer在处理手语识别序列问题中突破了RNN模型不能并行计算的限制,促进了手语数据的批量化处理。其使用的自注意力机制具有可解释性,多头注意力机制可以将注意头分散学习关注不同手语表达特征信息。但T ransform er需要更明确的表示序列中元素的相对或绝对位置关系,其提出的位置编码在手语信息特征空间中并不具备可变换性,因此无法高效地表征手语位置信息。
(4) 迁移学习方法。迁移学习是指将一个已在大规模数据集中训练好的模型特征迁移到另外一个模型中,特征提取不变,再次训练分类器,即只需训练图像分类的小规模数据就能达到相对满意的识别效果。迁移学习可分为同构迁移学习与异构迁移学习,在手语识别的研究中以同构迁移学习中的领域适配以及数据集偏移为主。手势识别与动作识别的工作[86—88]对手语识别技术发展具有重要的借鉴意义。Sarhan等人[72]搭建了膨胀3维卷积模型用于大规模手语训练,采用基于特征的迁移学习方式,将大规模动作识别模型的时空特征迁移到手语识别模型中,结合RGB和光流信息。文献[73,74]利用官方提供的大规模数据集预训练权重,将学习到的特征迁移至自制的小规模手语数据集中。Vázquez-Enríquez等人[65]则在多个不同语言的大型手语数据集中进行预训练,迁移手语表达特征,利用目标手语数据集进行训练,在W LASL等数据集识别性能显著。
在迁移学习方法应用于该领域前,手语识别方法受到硬件设备、数据集规模限制。手语识别领域的应用性、商业化随着迁移学习的发展大幅增强。迁移学习可将数据集从手语识别扩展到手势识别甚至动作识别,扩充模型知识储备,目前最有效的迁移方式是在手语同类数据集中迁移特征。但迁移方式的选择、迁移有效性目前缺乏可靠的理论支撑。
(5) 零样本(Zero-Shot)学习。零样本学习需要在未知类与已知类之间引入耦合关系,建立二者间的语义关系,从已知类中抽取相关信息预测未知类。如图1所示,手语零样本学习简单而言是指利用训练好的手语识别模型来识别未包含在训练集中的手语。零样本学习推广的重难点在于手语知识的理解,缺乏大型手语动作图解数据集。文献[71,75]建立了手语视频附带动作描述性文本信息的数据集,在其零样本学习模型框架下实现了非数据集手语的识别功能。目前的零样本学习框架以3DCNN网络结合注意力机制做特征提取,LSTM网络表征时序关系为主。Bilge 等人[75]利用手语词典中的描述作为知识转移的过渡语义表示,结合手语视频信息,在零样本学习框架内利用描述性文本以及时空特征,完成零样本识别。Rastgoo等人[71]利用深度特征与骨架特征融合互补,提出一种多模态零样本手语识别(ZS-SLR)模型。其将T ransform er模型和C3D模型分别用于手部检测和深度特征提取,LSTM表征时序关系,最后利用BERT将视觉特征映射到手语标签。

图1 手语零样本学习示意图
零样本学习能够克服手语数据的标注瓶颈,解决遮挡、光线变化等带来的识别难题。但其目前处于起步阶段,识别准确率不足以支撑其实际应用。该方法的研究重难点在于:(a)测试数据来自训练数据分布以外的未知类造成域偏移情况,即要识别的未知手语词语表达所需要的动作视频或动作的文本描述未在训练数据中出现;(b)手语识别模型在训练过程中出现的语义损失;(c)手语视觉信息特征与文本语义特征之间的映射关系的表达。(d)缺乏专业手语视频动作图解数据集,数据集需要精确描述视频动作,理解相关动作含义。手语识别零样本学习是机会与挑战并存的研究方向。
4.1.2 连续语句手语识别方法
连续手语识别是指利用计算设备对通过手语表达的连续性句子的视频等转化为文本、语音等信息,连续手语的训练数据只给出了粗粒度标签,属于弱监督问题中的不确切监督问题。连续手语识别的难点在于句子种类丰富多样,视频时长大大增加,帧序列特征提取以及上下文关系处理难度增加,表达词汇间的间隔难以捕捉,因此单一的网络模型较难实现高性能的连续手语识别任务,许多工作将多种网络结构结合,本节将总结连续语句手语识别领域中常见的方法及网络结合方法,各模型方法见表4。
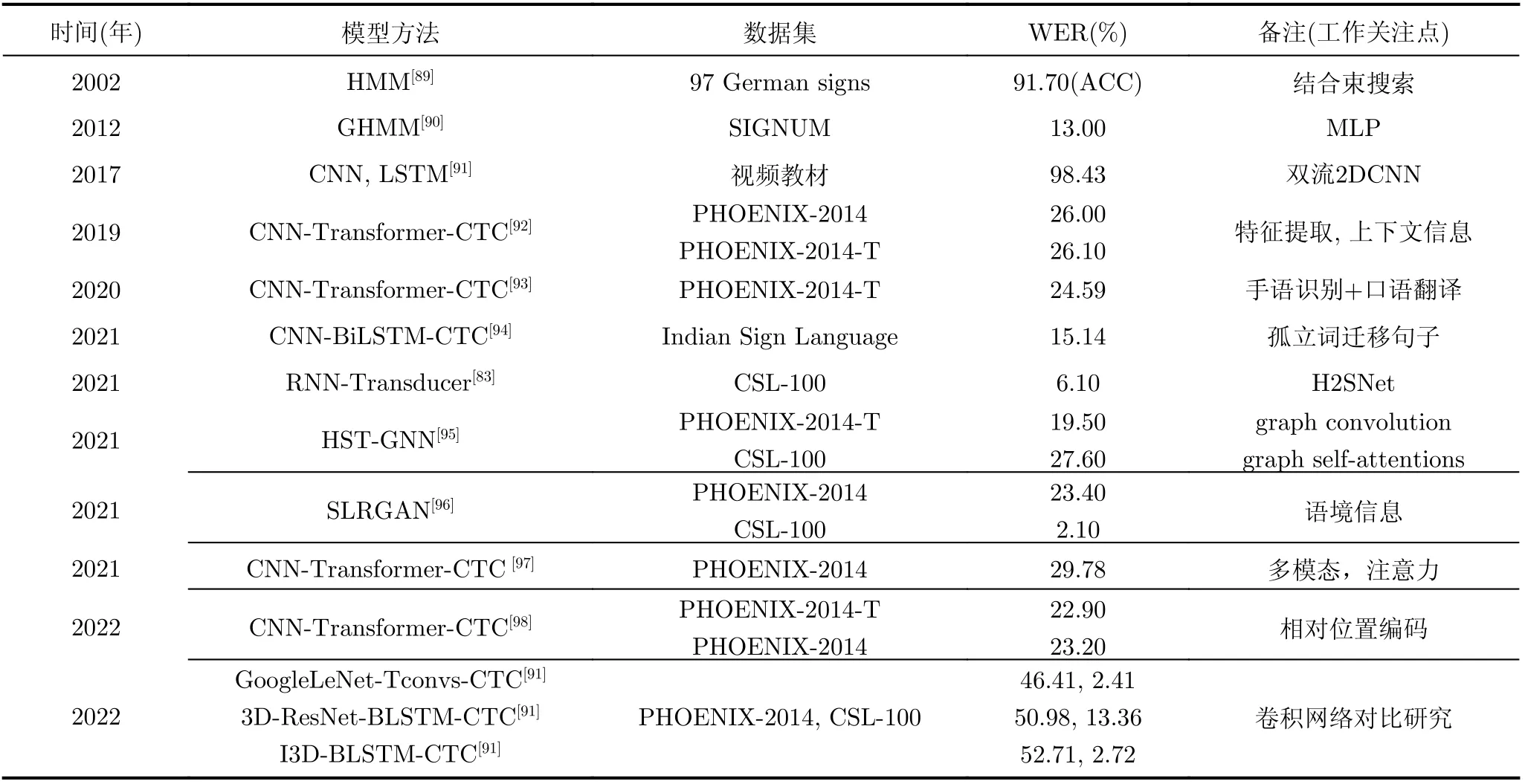
表4 连续语句手语识别方法
(1)传统模型方法。在神经网络模型盛行以前,隐马尔可夫模型(HMM)在手语识别领域表现最好,通过隐藏层刻画序列间的依赖关系。Bauer等人[89]利用隐马尔可夫模型结合束搜索降低识别任务中的计算复杂度。Gweth等人[90]在SIGNUM数据库上建立一个基于高斯隐马尔可夫模型(GHMM)结合神经网络的模型,将多层感知器(M u ltiLayer Perceptron, MLP)特征首次用于手语识别系统。HMM本质是统计分析模型,无法考虑长序列信息,时序表征能力与RNN网络相比逊色很多,且无法处理上下文信息。
(2)卷积神经网络与循环神经网络混合方法。文献[91,92,94—99]的工作表明,3维卷积网络与2维卷积网络相比,其优点在于其初始层具有将全连接层以及嵌入层中的连续手语多通道时空特征投影的能力,这使得网络具有更丰富的语义表达信息。然而3维卷积网络无法精确划分词汇边界,2维卷积网络不表征视频帧间的依赖关系,而其往往可以提供较为精确的词汇间隔,因此其在连续手语识别中的效果较好。卷积网络优势在于特征提取,需要结合长短时记忆网络表征词汇间的长时依赖关系,然而对词汇内的时序关系建模能力不足,此时通常需要结合连接时序分类(Connectionist Tem poral C lassification, CTC)完成连续手语识别任务,CTC在连续手语识别任务中能够使得词汇间隔更明确,表征词汇内的依赖关系。很多工作[91,92,94—99]结合上述3种模型优点完成连续手语识别任务。迁移学习在连续手语识别大规模数据模型中的作用至关重要,Sharm a等人[94]在孤立词数据集上预训练模型用于连续手语识别任务。Han等人[99]在K inetics数据集上预训练,使其模型为识别视频特征做准备。另有工作利用多级长短时记忆网络完成连续语句任务。Gao等人[83]利用多个BiLSTM s表征帧序列信息、词汇序列信息以及短语序列信息,利用预测网络表征语句上下文信息,最后利用RNN-T ransducer模型学习视频与语句间的最佳对齐策略。
在连续手语识别方法中,2维卷积网络提供较为精确的词汇间隔,建立词汇与视频动作间的对齐关系,因此其在连续手语识别中的效果相比3DCNN更好。CNN网络需要与LSTM网络结合表达长序依赖关系,最后通过结合CTC网络对齐帧序列与词汇信息,表征词汇内的序列关系。
(3)基于注意力机制的混合方法。RNN固有的顺序属性阻碍了训练样本间的并行化,对于长序列信息,计算设备的内存限制会阻碍训练样本的批量处理,而连续手语信息的序列长度对RNN模型并不友好。T ransform er在处理手语识别序列问题中突破了RNN模型不能并行计算的限制,且具有长时序信息的表征能力,与卷积网络互补,表征全局特征信息。常见的混合方法包括:(a)CNN+Transform er+CTC方法。卷积网络做特征提取,T ransformer表征时序关系,CTC对齐帧序列与词汇信息的结合方式[93,97,98]已成为一个主流研究方向。X ie等人[98]利用内容感知邻域聚合方法选择手语相关特征,将特征整合至位置感知的时间卷积层来增强手语的特征表达,利用T ransformer模型表征长时序关系,并引入相对位置编码的概念解决T ransformer中绝对位置编码方向与距离的未知性,通过卷积层的特征提取策略解决T ransform er采用视频帧聚合手语特征从而忽略手语的时间与语义的结构对齐问题,最后利用CTC完成连续手语识别。Cam goz等人[93]提出了利用CNN网络做特征提取,将T ransformer与CTC结合实现端到端的训练,其在RWTH-PHOENIX-W eather-2014T(PHOENIX14T)数据集上达到了24.59%的错词率,并且将手语识别和语句翻译任务集成到统一网络结构中进行联合优化。Ban Slim ane等人[97]利用2DCNN与T ransformer分别对空间与时间信息建模,联合多条独立数据流表征多模态信息,并共享同一时间序列结构。(b)图卷积网络+图T ransform er+CTC方法。Kan等人[95]利用图卷积网络以及图T ransform er作为编码器提取手语信息的局部与全局特征信息,图T ransformer表征手语序列中的上下文信息,最后利用CTC网络关联词汇与视频帧中的对齐关系,在PHOENIX-2014-T数据集上的错词率达到19.5%,在CSL-100的错词率达到27.6%。(c)GAN+T ransform er方法。Papastratis等人[96]利用GAN网络识别连续手语中的词汇信息,T ransform er将手语词汇转换为自然语言文本。生成器使用时序CNN网络与BLSTM网络提取时空特征识别手语词汇,判别器则通过对句子与词汇中的文本信息建模判别生成器的手语识别效果。该项工作还研究了手语对话中语境信息对听障人士与健听人群不同组合的重要性。
LSTM记忆网络不能够并行化,计算设备的限制阻碍训练样本的批量处理,连续手语的序列长度对其不友好。T ransform er既能够突破LSTM并行化限制,又能够与卷积互补,提取局部、全局特征,更好地连接视觉与语言,因此运用T ransform er表征连续手语的长时序依赖关系已成为主流方向之一。
4.2 仅依靠手部特征的手语识别方法与多特征融合的手语识别方法
手部动作是手语信息最主要的特征,如图2手部特征区域所示,仅依靠手部特征的手语识别方法涉及手部检测、手部追踪以及手部姿态估计等方面。面部特征及肢体特征同样是手语表达的重要部分。图2表明手部特征可以和面部、肢体等非手控特征融合训练。多特征结合能够提升模型准确率和鲁棒性,尤其是在遇到光线、形态变化等情况下。除训练多特征融合模型外,人体参数化建模也能有效融合手语多特征。本节分别介绍仅依靠手部特征手语识别方法与多特征融合手语识别方法,各方法总结如表5所示。
(1)仅依靠手部特征手语识别方法。手部特征是手语最关键的语义传达特征,仅依靠手部特征的识别方法主要包括手部姿态估计、手部追踪以及手部检测等。(a)在手部姿态估计中具有代表性的模型是MPH (MediaPipe Hands)方法。该模型已有训练基础,能够省去训练花费的大量精力。文献[100,101]均利用MPH模型检测手部关键点,并在其使用数据集中表现优异。MPH模型可与SVM,GBM方法结合[101]完成手部姿态估计。该方法所使用的采集识别设备精简,便于推广,能够有效解决手部被遮挡的识别难题。此外,文献[102]利用CNN结合奇异值分解实现低复杂度,高准确度的手部估计方法。(b)手部检测的代表性框架包括R-CNN系列以及YOLO系列,手语检测识别通常情况下有两个难点,一是要处理大量候选的手语表达位置框,二是需要表征弱监督问题中的细粒度特征以及精细化候选框位置。文献[73,103]分别采用R-CNN框架以及YOLOv5完成实时手语识别。R-CNN使用的VGG-16参数量大,耗费大量计算时间与空间,每个候选区域要执行卷积网络前向传播且需要多阶段训练。其改进版Fast R-CNN以及Faster R-CNN优化训练阶段并缩短检测框生成速度。YOLOv5对小目标的敏感度更高,而手语识别需要利用手指关节等部位的精细化特征。文献[73,74]将迁移学习应用到目标检测中,Srivastava等人[74]利用TensorFlow Object Detection API框架,利用迁移学习实现了手语实时检测识别。该框架部署讯速,预训练权重丰富。(c)在手部追踪方面,文献[44,104]均使用CNN网络实现手部追踪,将手部运动学3维模型与卷积神经网络结合实现手部追踪[44],增强模型鲁棒性以应对遇到遮挡及视角变化等问题。Roy[105]利用Cam shift T racker实现了手部跟踪,结合HMM模型实现了能够区分单双手的手语识别。
在仅依靠手部特征信息的手语识别方法中,多模态信息输入能够帮助识别模型提高鲁棒性与准确率。Rastgoo等人[106]分别在2018年与2021年实现了多模态手语识别,有效提升识别准确率。另有学者致力于模型参数的简化[107],期待利用图像处理[48]的方法提升模型的识别准确率等。
(2)多特征融合手语识别方法。手语的语义传达离不开面部表情以及肢体等非手控特征,以手部特征为基础融合面部、肢体等特征能有效提高模型的识别性能。融合方法可以大致分为神经网络融合方法及3维姿态恢复方法。(a)多特征神经网络融合方法。在手语识别任务中既需要细粒度特征,探索手语动作的关键信息,同时需要粗粒度手语动作特征把控序列进程。卷积神经网络的浅层网络能够提取图片的高分辨率低层特征,包含手语表达中的手部关节位置、面部表情、眼型等细节信息。深层网络提取的高层特征虽然分辨率低,细节感知能力弱,但能有效表征动作语义信息。因此,许多工作[25,48,111]采用CNN网络融合手语表达所采用的多特征信息。多特征融合根据方法结构可分为前端融合、中间融合以及后端融合。Elakkiya等人[66]运用前端融合方式,在输入层通过HMM模型提取手部特征及非手控特征,利用VAE融合手型、唇形及眼睛等20个特征降维后输入至GAN网络中。文献[48,111]采用后端融合按照特征权重等方式融合预测结果。文献[48]将CNN提取的面部、口型的不同特征输入至HMM模型融合预测。Gökçe等人[111]利用3DCNN将手、面部以及肢体按照相应权重融合特征,完成手语识别任务。Hu等人[25]利用3DCNN网络通过结合上下文关系与细粒度线索两条数据流表征了面部表情、眼睛等非手控信息。(b)3D身体姿态恢复方法。姿态恢复是将RGB图像转化为3维姿态,获取身体各部位的坐标、图像等细节信息以融合手语表达特征。SMPL是其中代表性模型,可以精准的刻画人肌肉伸缩等细节性特征。K ratimenos等人[112]提出了SMPL-X模型利用单个图像生成3D身体姿态模型,利用3D模型融合手语特征,完成手语识别任务。该方向有效地解决亮度、形态、视角变化等手语识别领域的难题,是多特征融合手语识别发展的重要方向之一。
目前多特征融合方法能够有效提高手语识别方法的鲁棒性与精细度,缓解手部遮挡、视角变化等问题带来的预测难题。但其仍然面临如下问题:(a)如何充分利用手语表达特征之间互异性、互补性与冗余度以提升模型的训练效率与效果。(b)不同手语特征融合时引入的噪声以及语义鸿沟可能对识别模型产生负影响。(c)在后端融合时缺少分配手语特征权重的标准。
4.3 模型总结
图3分别总结了在孤立词最具权威性的CSL-500数据集与ASLLVD数据集下模型准确率,以及在连续语句应用最广泛的CSL-100, PHOENIX-2014以及PHOENIX-2014T数据集下的模型错词率。其中文献[58,66,95,96,98]在以上数据集中识别效果最佳,总结以上模型可发现:(1)注意力机制有效解决长时序依赖关系[58,95,98],学习手语序列的上下文关系;(2)GAN网络在手语识别弱监督、多分类问题中表现强势[66,96];(3)多特征、多线索融合[66,96]有效提升手语识别方法的准确性与鲁棒性。图3表明手语识别研究重点并未局限于准确率的提升,遮挡、复杂环境、数据扩展等问题同样是当前研究重难点。
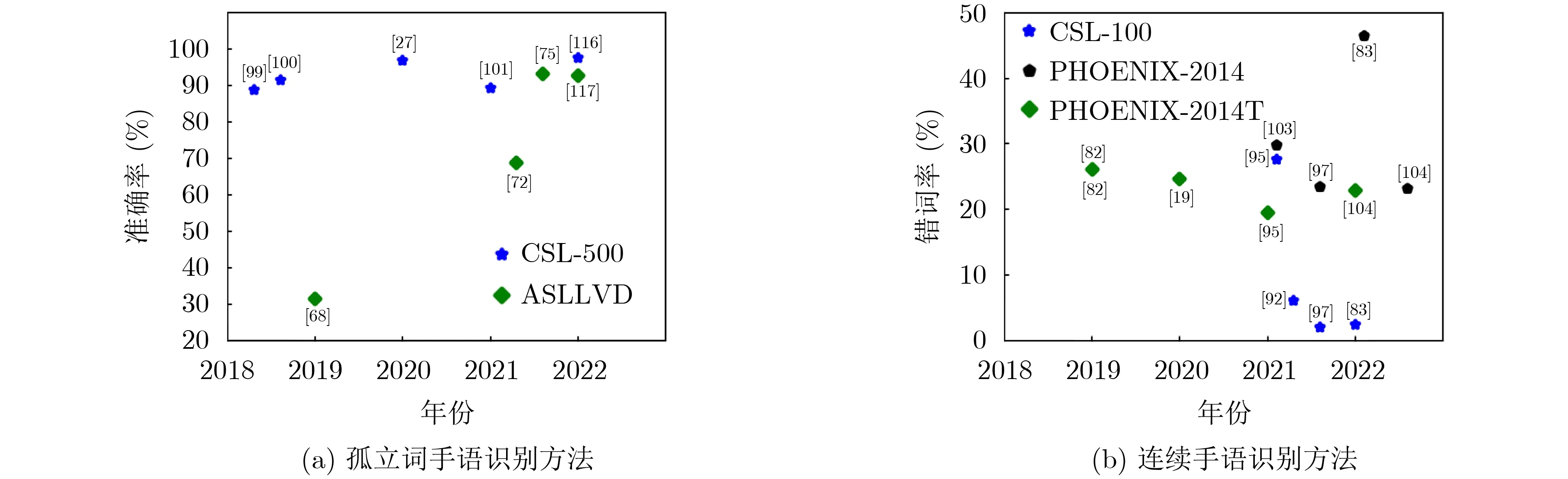
图3 本文所收录的手语识别模型在几种典型数据集下的识别表现
5 总结与展望
5.1 手语识别技术的问题与挑战
手语识别技术的研究要考虑使用人群的需求,在识别方法上寻求应用性、普及性以及可拓展性。该领域发展迅速,但在发展过程中仍存在很多挑战。本节总结了手语识别技术所面临的技术难题与挑战。
(1)手语精细化特征与粗粒度动作语义序列建模。手语除依靠手部动作外,非手控特征也影响语义传输。手部细节特征以及唇形、眼睛等非手控特征均需要精细化建模,同时要考虑表征手语动作序列与语义单元的关联衔接性。手语多特征精细化建模兼顾粗粒度动作序列建模以提升模型鲁棒性与准确率仍是一个挑战。
(2)不确切监督序列识别。目前的连续手语识别技术是典型的不确切监督问题,这是由于连续手语数据集大多只有句子级标签,无法构造动作与词汇的序列对齐关系,通常需要划分精确的词汇间隔,将帧序列信息与词汇语义信息关联对齐训练,对模型的上下文关联及时空特征聚合能力要求很高。
(3)手语数据匮乏与模型训练数据限制。多样化、真实性、大规模数据集十分稀缺,手语数据标注困难,且现实应用场景中数据量庞大,无法逐一训练。如何高效利用邻域与跨域数据特征,以及实际应用中如何拓展模型以准确识别未训练词汇仍是巨大挑战。
(4)复杂环境实时识别。现阶段很多手语识别技术研究停留在实验室背景下的视频理解。而真正能够将手语识别技术推广的研究要在实时的情况下解决光线、视角变化、手部遮挡等复杂环境的识别难题。
5.2 展望
手语识别技术的研发目标是实现实时精准识别方法落地,服务于大众。面对上述手语识别技术难题,该领域应从识别方法的简便性与拓展性、数据集的发展、识别系统应用性等取得突破性进展,推动人机交互。
(1)轻量化、高速推理与鲁棒性模型研发。大众更期待在手机等便携式设备上使用手语识别功能,因此开发兼顾轻量化、高速推理与多模态多特征融合的快速部署、实时识别、具有鲁棒性的实用模型迫在眉睫。
(2)大规模、真实性、多样化、注释性手语数据集需求。首先,手语识别技术落地必然离不开大规模的听障人士在真实环境下录制的数据集。其次,需要数据形式、录制人员、标注特征及场景多样化的手语数据以提升识别方法的鲁棒性。最后,亟需建立专业的手语动作注释性图解数据集用于语义理解与模型拓展。
(3)手语知识可扩充性模型研究。现实应用中的庞大手语数据无法在模型中逐一训练,这要求模型具有强大的拓展能力。在此方面有如下展望:(a)完善近域、跨域迁移学习方法拓展训练数据范围,缓解手语标注瓶颈。(b)强化零样本学习模型的识别准确率以达到应用性要求,在连续手语识别领域开展零样本学习研究。(c)探索手语识别终身学习机制,在模型部署应用的同时不断扩充模型知识储备。
(4)在线手语识别综合系统功能开发。实时识别是系统应用性前提,除此还可拓展如下功能:(a)多人手语识别,并要解决其余手部及特征干扰识别对象问题。(b)手语识别后的文本翻译。目前手语识别缺乏多语种比较研究。手语识别后的语言翻译能够有效促进使用者国际化交流。(c)多模态联合手语采集识别设备开发。多模态手语识别方法面临着采集与识别设备复杂的应用难题,开发轻便化采集识别设备迫在眉睫。
