采用随机块附加策略的云数据安全去重方法
2023-11-17林耿豪周子集周艺腾钟宇琪齐天旸
林耿豪,周子集,唐 鑫,周艺腾,钟宇琪,齐天旸
(国际关系学院 网络空间安全学院,北京 100091)
1 引 言
云存储提供以数据存储和管理为核心的云计算服务。随着互联网数据的激增,越来越多的用户选择将数据外包给云服务提供商(Cloud Service Provider,CSP)来减轻本地压力。由于云存储具有数据量大、受众范围广等特点,云服务商面临着冗余存储的问题。有研究表明,近75%的云端存储数据至少存在一份副本。此外,大量数据的重复上传也给资源有限的用户引入了沉重的通信开销。鉴于此,Dropbox、Mozy、Mega、Bitcasa[1]、百度云、阿里云等云服务提供商都开始采用去重技术来解决数据冗余问题。根据发生位置的不同,可将去重技术分为目标端去重(又称云端去重)和源端去重[2](又称客户端去重)。在目标端去重[3]中,客户端不必与云服务器进行去重响应的交互,可以有效防范侧信道攻击,但是用户必须先上传完整的文件,再由云端判断是否执行重复数据删除。由此带来的是通信开销与存储开销的增加。源端去重[4]在上传数据之前,首先将其哈希指纹上传到服务器,如果服务器索引中存在数据指纹,则不会上传相应的文件。该技术能在文件级、块级和字节级检测数据流中的相同数据对象,只传输和存储惟一的数据对象,并使用指向惟一数据对象的指针替换其他重复副本,从而实现快速缩减海量数据的目的。具体来说,用户在外包数据之前先计算目标文件的哈希值作为查询标签发送给云服务商,后者在本地查找确认是否已经存储相同文件,如果是,则返回响应阻止用户的进一步上传。尽管这一方案提高了存储效率和带宽利用率,云服务商返回的确定性响应却为攻击者创建了一个侧信道[5],一旦不需要后续上传,目标文件的存在性隐私立即泄露。尤其对于包括电子邮件、企业合同、病历、电子工资单、标底书等在内的含低最小熵敏感信息的文件,攻击者完全可以猜测文件内容并发动文件确认、学习剩余信息[6]和附加块攻击[7]等侧信道攻击,窃取合法用户的身份、职业、敏感文件等隐私信息,严重危害用户数据安全[8]。
为抵抗侧信道攻击,已有研究主要分为以下几类:①添加可信网关[9]。在客户端和云服务器之间设置一个第三方可信存储网关,由客户端将数据先上传至网关进行存储,再由网关执行去重后上传至云服务器中。然而可信网关在现实场景中的部署开销严重阻碍了实际应用。②设置触发阈值[10]。只有请求文件的云端副本数量超过设定的阈值后,才会触发去重机制,使隐私程度较高的非流行文件得到更好的保护。然而云端需要存储相同文件的多个副本,不可避免地引入大量开销。并且一旦文件副本数量超过阈值,去重机制便失去了对文件存在性隐私的保护作用。③混淆响应值。即引入响应模糊化策略,使得无论请求文件中的目标敏感块是否存在于云端,返回的去重响应对于攻击者都是难以区分的。这在一定程度上提高了去重方案的安全性。然而考虑到随机块生成攻击[11]这一更为复杂的侧信道攻击,现有方案的隐私泄露概率将急剧增加。具体来看,攻击者可以将随机生成的块和含有敏感信息的目标块混合在一起生成去重请求发送给云服务提供商,由于随机生成的块在云端存在的概率极低,将其视为未命中块。一旦响应返回下边界值,即要求用户上传的块或线性组合的数量等于随机生成块的数量,目标敏感块的云端存在性将泄露给攻击者。此外,现有方案并未重视请求块的位置与响应间的内在联系。对于低熵文件,攻击者可以构造特定排列的去重请求,结合学习剩余信息攻击[12]和随机块生成攻击提高成功窃取隐私的概率。
在此背景下,为实现抵抗侧信道攻击的安全性,笔者提出了一种新的基于随机块附加策略的云数据跨用户安全去重技术(Random Chunks Attachment Strategy,RCAS)。RCAS是一个能够很好地抵抗随机块生成攻击的去重协议,尤其针对安全风险更高的可预测模板文件。具体来说,云服务商接收到用户上传的去重请求后,在请求末端附加一定数量且状态未知的块来模糊原有请求块的存在状态,并通过乱序处理改变原有请求块间的位置关系,在新提的响应表的帮助下扩大响应值的取值区间,从而降低下边界值返回的概率。文中的工作主要概括如下:
(1) 提出了基于随机块附加策略的跨用户去重架构,这是一种简单而有效的防御侧信道攻击的架构。在用户不清楚具体块的存在状态的前提下,支持通过上传少量冗余数据块(数量可调节)来实现抗随机块生成攻击、学习剩余信息攻击等侧信道攻击的安全性。
(2) 提出了RCAS响应表、基于添加随机块的存在状态模糊化以及上传块乱序处理方法,在去重架构的帮助下生成混淆响应。有效改善已有工作在安全与效率关系上失衡的问题,实现了低熵文件的隐私保护。
(3) 在安全性分析基础上,通过真实数据集将RCAS与当前流行的ZEUS、ZEUS+、RARE、CIDER等方法对比,证实文中方法以增加少量开销为代价提高了安全性。
2 相关工作
本节将介绍已有抗侧信道攻击方案,并分析存在的缺陷。HARNIK等[1]首先提出基于随机阈值的方法(Randomized Threshold Solution,RTS)和脏块列表来降低去重响应与文件存在性之间的相关性,并降低攻击者利用侧信道重复攻击的能力。服务器为每个文件分配一个在范围[2,d]内随机均匀选择的阈值,其中d是一个公共的参数。当文件为流行文件,即上传次数超过阈值时,才会启用去重。然而,为保证安全性应选取较大的参数d,这导致去重启动开销较大。LEE等[13]在RTS基础上提出了一种动态随机化确定去重阈值的方法,服务器将上传文件的实际数量减去集合中的随机数确定为去重阈值,使去重的发生具有一定的随机性。WANG等[14]基于博弈论提出混合策略纳什均衡(Mixed-Strategy Nash Equilibrium,MSNE)方法来确定去重阈值,将重复数据消除建模为攻击者和云之间的动态非合作博弈。但是,以上设置去重触发阈值的方案需要用户多次上传文件副本,增加了去重的启动开销。类似地,TANG等[15]设计了一种通过基于拉格朗日插值的聚合策略来支持标签去重和完整性审计的方案。该方案可以抵抗对文件所有权隐私的侧信道攻击。ZHANG等[16]提出一种基于k匿名策略的安全阈值去重方案,支持机密性保护和所有权验证。然而,类似于RTS,上述两种方案均无法保证流行文件的存在性隐私。
对此,ZUO等[7]基于隐私信息仅存在于一个数据块的假设,提出了一种随机冗余块方法(Randomized Redundant Chunk Scheme,RRCS)。RRCS与RTS类似,设置一个取值范围在[d1,d2]中的随机数w。RRCS的随机冗余块策略指云端在命中块中随机选取w个块,将它们标记为未命中块,需要额外上传。若敏感块存在,则云端要求用户上传w个块;若敏感块不存在,则需要上传敏感块,以及其他随机选取的w-1个块,从而保证每次都需上传w个块,云端通过观察目标敏感块是否存在调整随机选取块的数目,实现无差别响应。在此基础上,ZUO等提出了一种新的威胁模型“附加块攻击”(Appending Chunks Attack,ACA),攻击者可以生成任意数量的未命中块附加在上传请求中,由于敏感块未命中时与附加块均为未命中块,云端将无法通过判断敏感块的存在状态返回无差别响应。在新模型下,RRCS的响应值区间为可区分区间,隐私泄露的风险从零提升至1/(d2-d1+1)。基于响应值开展侧信道攻击的成功率较低,但从块的位置信息推测敏感块是否命中的成功概率极高。RRCS的响应值并非未命中块个数,而是各个块的序列号。一旦敏感块命中且没有包含在随机选择的块中,攻击者立即得知它的云端存在性,这种情况的泄露概率高达w/(n-1),其中n为块总数。为此,TANG等[12]提出请求合并方案(Request Merging based Deduplication Scheme,RMDS),用户上传所有块的内容异或值。若敏感块未命中,则云端可由其余存在块和该异或值求出敏感块内容;若敏感块命中,则用户也需上传异或值,以实现无差别混淆。对于附加块攻击,RMDS需要不同用户对同一目标文件请求去重至少两次,云端可以根据两次请求判断附加块的数量N,生成N+XOR作为响应值(N为附加随机块块数),对附加块与其余块采取不同上传策略,从而抵抗附加块攻击。但是,RRCS与RMDS均假设敏感信息仅存在于一个块,这显然不符合现实去重情况。
YU等[17]扩展了单敏感块的应用场景,提出隐私感知重复数据消除方案(ZEro knowledge dedUplication reSponse,ZEUS)和ZEUS+方案。ZEUS根据相邻两块的存在状态生成去重响应,当两个块中至少有一个块命中时,响应值为1,要求用户上传这两个块的异或值;否则响应值为2,用户需要上传两个完整块。同时,ZEUS引入了撤销请求攻击——攻击者获得响应值后拒绝上传或者上传不合规的块以期望执行重复请求窃取隐私,以及“Sybil”攻击——攻击者可以操纵多个傀儡账户发起攻击,增加泄露概率。为此,ZEUS设计脏块列表抵御它们。当任何块不合规请求去重时,该次请求去重的两个块均会被列入脏块列表,标记为脏块。若在后续上传中任意一个块为脏块,则云端不论这两个块是否存在,都要求上传两块的内容而不是两块的异或值。由此,脏块列表使得同一敏感块仅在第1次请求去重时存在泄露隐私的风险。在此基础上,ZEUS+方案还额外引入随机阈值的思想,进一步保护数据块的不存在性隐私。随后,POORANIAN等[18]提出随机响应方案(RAndom REsponse,RARE),即在ZEUS基础上采用了混淆性更强的响应方案,当两个块至少有一块存在时,云端要求用户上传异或值或者两块的内容,两种选择的概率各为50%。然而,这些方案无法抵抗随机块生成攻击[11],攻击者可以构造敏感块+随机块的上传请求,由于随机块未命中,一旦敏感块命中,两种方案的隐私泄露概率分别高达100%和50%。文献[19]提出基于编码的客户端重复数据消除响应方案(Coded clIent-side DEduplication Response,CIDER),将RARE的原理推广到了两个以上同时请求去重的数据块。但是攻击者仍可以构造一个敏感块多个随机块的组合,在第1次攻击中以50%概率得知敏感块的存在状态。随后,HA等[20]提出了一种基于分组异或的抗侧信道攻击去重方案。具体来说,云服务商根据存在状态将请求块划分为命中和非命中两个集合,根据两集合中块数的比值,采用不同的方法将集合中元素两两配对,要求用户上传不同块对的异或值。此方案在一定程度上扩大了响应的取值范围。然而,一旦返回响应区间的下边界值,则存在性隐私立即暴露。
3 系统模型
本节介绍采用随机块附加策略的云数据安全去重机制网络模型,并通过定义威胁模型来展现潜在的攻击手段与安全威胁。
3.1 网络模型
文中的网络模型包含两个实体:云服务提供商以及用户。一个云服务提供商具有强大的计算能力,可以同时为多个用户提供云存储、跨用户去重以及下载服务。具体来说,接收到去重请求后,云服务商在本地存储进行比较,并根据去重协议生成响应返回给用户,阻止相同文件的后需上传。而用户则通过外包文件来减轻本地存储压力。用户将要上传的文件f以固定长度φ划分为多个块Ci,i∈{1,2,…,n}。计算它们的哈希值Hi=Hash(Ci)作为查询标签发送给云端,其中Hash(·)是哈希摘要函数(例如SHA-256)。根据云端返回响应值R计算并上传相应数目的线性组合,以供云端解码得到未命中块。
3.2 威胁模型
侧信道攻击是跨用户源端去重的主要威胁。攻击者伪装成普通用户,通过分析敏感块Ci的云端响应值窃取该块的存在状态,即试图得知云存储中是否已经存在Ci的副本。在流量混淆策略下,响应值的最小值根据敏感块是否存在而变化,因此攻击者可通过观察去重响应值是否等于已知未命中块的块数来判断该敏感块的存在状态。如果云端响应值R等于已知未命中块的块数,则攻击者得知敏感块Ci已经存储在云端。
文中方案主要考虑两种复杂的侧信道攻击、随机块生成攻击[11]和学习剩余信息攻击[6]。
3.2.1 随机块生成攻击
攻击者构造一个内容为随机比特流、长度为块长度φ的随机块。由于一个随机块被云端检索到的概率极小可以忽略不计,故认为该块为未命中块。攻击者可以构造上传请求,其包括一个含隐私信息状态未知的块、t个随机块和s个命中块。除敏感块以外所有块的存在状态已知。当敏感块存在于云端时,云端响应值的最小值为t;而敏感块不存在时,云端响应值的最小值为t+1。故一旦攻击者接收到的响应值为t,则可判断敏感块命中。
3.2.2 学习剩余信息攻击
对于低熵模板文件[21],攻击者可以生成并请求上传隐私信息的所有可能版本,以获得它们各自的响应值。结合随机块生成攻击,一旦生成的敏感块命中且返回响应下边界值,则该隐私信息的内容立即泄露。
文中方案不考虑撤销请求攻击、Sybil攻击与所有权认证(Proof of OWnership,POW)问题。由于文中方案沿用ZEUS的脏块列表机制,设计针对文件块的黑名单机制,其可以在用户抵赖、上传内容无法通过完整性检验时将非法文件块记录为脏块,阻止攻击者通过撤销请求攻击、Sybil攻击构造去重请求获取更多信息[17]。此外,在文中模型下,攻击者可以构造去重请求,则该请求的所有块均为攻击者所有,必然会通过所有权认证。因此不考虑模糊去重、密文去重[22]等涉及的所有权验证威胁。
4 采用随机块附加策略的云数据跨用户安全去重方法
本节介绍基于上述系统模型构建的采用随机块附加策略的云数据安全去重方法(RCAS),从设计动机、去重模型框架和去重方法阐述该模型的设计与实现。
4.1 RCAS去重模型设计动机
现有响应模糊化去重策略无法抵御侧信道攻击的原因主要有如下4个方面。
4.1.1 响应表的设计
现有流量混淆策略的去重模型将安全性仅依赖于响应表的模糊化。随着随机块生成攻击[11]的出现,攻击者可以构造仅含有敏感块与随机块的上传请求,ZEUS、RARE、CIDER的响应表在这种攻击中存在可区分响应,泄露隐私的概率分别为100%、50%和50%。并且,响应表的设计需要平衡安全性与性能,被要求上传的命中块数越多,模糊性越强,但额外通信开销也越大。例如,若命中块有50%概率被要求上传,则侧信道泄露隐私的概率降低至50%,但需要额外上传50%的命中块。因此,为实现安全级别较高的去重方案,仅凭借响应表模糊化会带来大量额外传输开销。
4.1.2 多敏感块的缺陷
现有方案将安全性依赖于多敏感块的上传请求。根据CIDER[19],当多个敏感块分散在l个分组中,当且仅当各分组响应值均等于分组内未命中块数时泄露隐私,每个分组泄露隐私概率为50%,因此含l个敏感块的上传请求泄露所有敏感块隐私的概率为2-l。但攻击者可以构造多个独立的上传请求,每次请求仅包含单一敏感块,每次请求泄露单个敏感块隐私的概率为50%。攻击者虽然窃取所有隐私的概率较低,但能够以较大概率窃取半数敏感块。
4.1.3 响应值区间大小的局限
现有方案通过扩大响应值区间大小以提高安全性,需要付出高昂传输开销代价。在RTS方案中,门限最大值d的增大可以扩大门限取值区间;在RRCS中,随机选取w个命中块标记为未命中块,w∈[d1,d2],该区间的扩大也可以提升安全性。可区分响应泄露隐私的概率取决于响应值等于其取值下界的概率,而以上策略为了降低该概率需要提高d和d2两个参数,它们与隐私泄露概率的关系为d-1和(d2-d1+1)-1,与开销的关系为d和(d2-d1)。因此,随着参数变大,安全性提升速度减缓,开销提高速度不变。文中方案考虑一种新型的随机块附加策略,以较小开销为代价实现安全性大幅提升。将随机块定义为云端生成的存在状态未知的块,结合范德蒙德编码方案模糊响应值和块位置间的关系[19],可以在降低额外通信开销的同时为去重方案带来更高的安全性。以该机制结合CIDER为例,假设一个分组内有k个状态随机的附加块,原有t个未命中块和1个敏感块,附加块为命中块概率α,则响应值区间由[t,t+1]扩大至[t,t+k+1],响应值为下边界t时泄露隐私,隐私泄露概率p降低至αkp。
4.1.4 位置关系的泄露
现有方案未对块与块位置关系模糊化处理。现有方案中敏感块在上传请求的位置固定,因此攻击者可以构造含有敏感块的单一分组,该分组响应值由组内命中块与非命中块数目决定,响应值区间较小,模糊性较差。当采用位置关系模糊化处理时,敏感块以等可能概率分布在任意分组,攻击者仅能通过检查整个上传请求的响应值窃取隐私,响应值区间扩大。以概率计算为例,出现隐私泄露的排列为事件A,响应表泄露隐私为事件B,则现有方案泄露隐私的概率为P(B),在特定排列下且泄露隐私为事件A∩B,概率为P(AB),小于等于P(B)。因此,未进行位置模糊化处理是现有方案泄露隐私概率高的原因之一。
文中方案分别对以上4种因素采取措施:设计RCAS响应表,平衡模糊性与去重性能;所有实验考虑一次上传请求中仅含一个敏感块的情形,在此基础上开展安全性实验;设计存在状态模糊化机制,云端在每个上传请求末尾附加k个状态未知的块,从而将特殊情况下泄露隐私的概率降低至原本的αk,其中α是每个附加块为命中块的概率;云端收到上传请求后进行乱序处理,对请求中各块位置模糊处理。
另外,文中方案沿用了3个现有方案的去重机制:①参考ZEUS在一定程度上改进脏块列表,阻止攻击者通过抵赖或上传不符合完整性校验的块获取额外信息并降低传输开销。②参考CIDER响应表设计响应值新下边界值,考虑攻击者构造的1个敏感块加n-1命中块的上传请求,其中n为该次上传的总块数,当敏感块命中时,该上传将消除乱序带来的混淆性,将响应值下限从0提升至1,以阻止敏感块命中带来的可区分响应。③参考CIDER采用范德蒙德编码解码机制,云端只需发送未命中块的数量信息以保护未命中块的位置信息,阻止攻击者通过判断位置已知的敏感块是否需要上传来窃取信息。
4.2 采用随机块附加策略的云数据跨用户安全去重模型
基于随机块附加策略的明文去重方法,去重的流程通常由用户发送去重请求开始。如图1去重模型概念图所示,首先用户将文件分块,并分别计算每个块的哈希值作为查询标签发送给云端。接下来,通过图1中响应值处理模块的6个子模块得到响应值:①云端从数据库查询用户上传的指纹,检查各请求去重的块的哈希值是否存在,获取拟上传块的存在状态数组;查询脏块列表,检查每个块是否被标记为脏块,如果是,则在存在状态数组中修改对应数据块的脏块状态标识;②附加块生成器向存在状态数组附加k个状态随机的标签;③执行乱序处理;④根据响应表生成针对该次上传请求的响应值;⑤根据响应值的下边界值修改响应值,令其最小为1;⑥返回响应值。用户根据云服务提供商返回的响应值上传指定数目的线性组合,非正常上传的块将被加入脏块列表。云端对用户上传的线性组合解码还原出相应的未命中块,并在本地数据库保存。此外,云服务提供商维护已存储文件的块列表,块列表存储文件所含块在数据库的实际地址。

图1 采用随机块附加策略的云数据安全去重模型概念图
以用户A和用户B的去重为例,在图2所示基于随机块附加策略的云数据跨用户安全去重模型框架图中,用户A将请求上传的文件fA分割成n个长度相等的块C1,C2,…,Cn,生成每个块的标签H1,H2,…,Hn,并以标签集tagA的形式发送给云服务提供商作为去重请求。 接收到请求以后,云端首先查询本地数据库,分别比对tagA中H1,H2,…,Hn的存在状态,生成存在状态数组D。 接着,云端逐个检查Hi,i∈[1,n]对应的数据块是否为脏块。 在图中的例子里,经检查,云服务提供商发现脏块列表为空,所有请求去重的数据块都不是脏块。再下来,云端使用附加块生成器生成k个状态随机的块附加在存在状态数组D末尾,然后将存在状态数组重新排列,形成乱序数组Dshuffle。 云将该数组的元素按照相邻顺序排列,两两分为一组,根据RCAS响应表计算每小组的响应值rai。最后,执行求和算法计算总响应值RA,并将RA的最小值限定为1。云服务提供商将RA发送给用户A。 用户A通过范德蒙德矩阵编码,计算并上传包含C1,C2,…,Cn信息的RA个线性组合。
对用户B,其准备上传的文件fB与用户A上传的文件fA是相似文件。fB被用户B分割成n个长度相等的块C1,C2,C′3,…,C′n,其中C1和C2两块已由用户A上传,属于命中块,存在状态为1。 在用户B发送此去重请求之前,由于某用户C未按要求上传,导致C2被标记为脏块。 因此通过查询脏块列表,云服务提供商将用户B的去重请求标签集tagB中的H2值更新为0。 接下来,云端生成k个状态随机的附加块,再经过乱序、响应生成等流程,最终生成响应值RB。 用户B计算并上传RB个线性组合。 接收到用户发来的线性组合后,云服务提供商解码并恢复出fB。 由于fB所有块最终都正常上传,没有块被记录为脏块。
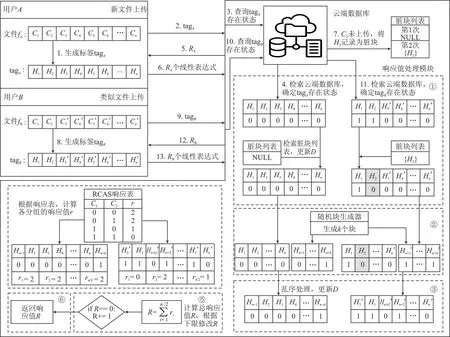
图2 采用随机块附加策略的云数据安全去重模型框架
去重模型的基本流程大致可以划分为4个步骤:用户请求上传、云端响应、数据存储和数据还原。采用随机块附加策略的云数据安全去重模型(RCAS)伪代码描述如下。
算法1RCAS。
输出:filefwith chunk sizeφ,and user partitionsfinto chunksC1,C2,…,Cn
① if bit length |Cn|≠φ
② user performs padding toCnwith 0 最后一块用比特0将长度补齐至块长
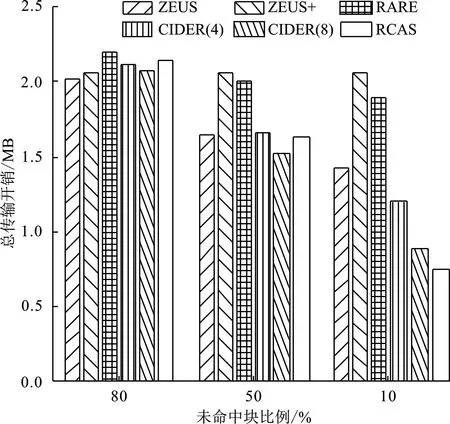
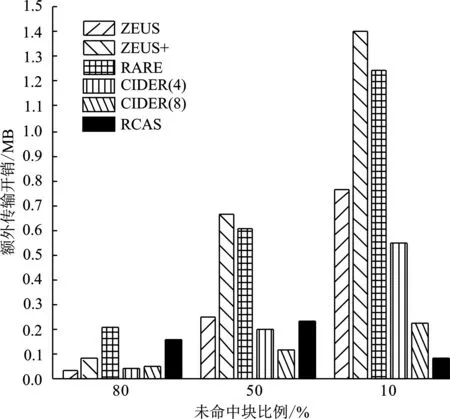
③ if 0 ④ user addsT-nchunks to the end of filef ⑤ user setsn=T ⑥ user obtainsHi=Hash(Ci)(1≤i≤n) and uploads tag={H1,H2,…,Hn} 计算上传请求标签tag ⑦ CSP obtains listD=IsExist(tag) 云端检查用户上传块的存在状态D并检查脏块列表 ⑧D′=RandRsp(D,α,k) 执行RandRsp函数,附加k个块 ⑨Dshuffle=Shuffle(D′,w) 执行Shuffle函数,对D′乱序,w是置乱密钥 ⑩R=GenRsp(Dshuffle) 执行GenRsp函数,获取响应值R 4.2.1 用户请求上传阶段 用户对文件执行4个操作:分块(Input行)、块内补齐(步骤①~②行)、块数补齐(步骤③~⑤)、计算上传请求标签(步骤⑥)。首先用户按照给定的数据划分策略——固定块长φ(字节)将文件f分割成n个小的数据对象块C1,C2,…,Cn。若最后一个块长度不足φ,则补齐至φ。若块数n不足阈值T,则用T-n个数据块将文件补齐至T块,这T-n个块的内容为全0比特。特别地,全0比特块由于存在于云端,无需额外传输开销,但可以扩大响应值取值范围从而保护敏感信息。用户在本地基于每个数据块的内容计算其哈希值作为指纹。块指纹是数据库存的惟一标识,一般选择SHA-1和MD5等抗冲突加密哈希值作为其指纹。将块指纹作为上传请求标签发送至云端。 4.2.2 云端响应阶段 云服务提供商接收用户发来的哈希值之后执行4个元算法:IsExist、RandRsp、Shuffle和GenRsp。他们分别对应块存在性状态查询(步骤⑦)、添加附加块(步骤⑧)、文件块打乱(步骤⑨)和响应值生成(步骤⑩)。在IsExist算法的执行过程中,云服务提供商从本地数据库中对用户上传的块指纹进行查询,获取上传块的存在状态数组D。接下来,云端创建用户ID和文件指纹,文件内建立块列表,将命中块在数据库的实际地址保存至块列表。在RandRsp算法的执行过程中,云服务提供商在用户拟上传块的存在状态数组D尾部添加k个随机块。然后,云端执行Shuffle算法打乱存在状态数组的排序,执行GenRsp算法获取响应值R,并限制R的最小值为1(步骤~行)。最后,将响应值R发送给用户(步骤)。 4.2.3 数据存储阶段 用户执行VandEnc算法,云服务提供商执行VandDec算法。在接收到云端的响应值R后(步骤),用户端执行VandEnc算法(步骤),以R作为输入,输出R个线性表达式并将它们上传至云端(步骤)。云端执行VandDec算法对用户上传的R个线性表达式进行解码(步骤),从而恢复出用户发送的请求中未命中块的内容。云服务提供商将未命中块的实际地址保存到块列表中,便于后续开展去重检测和文件还原时使用(步骤)。 4.2.4 数据还原阶段 云服务提供商首先对用户开展身份认证,检查用户对文件的所有权。云根据用户标识符ID以及文件指纹在云端查询目标文件。若找到目标文件,根据目标文件的块列表提供的各块实际地址,将各块内容按序拼接,还原文件。 本小节介绍实现文中方法所使用的核心算法,如存在状态模糊化、上传块乱序、RCAS响应生成、范德蒙德矩阵编解码和脏块处理等内容。 4.3.1 存在状态模糊化 存在状态模糊化是一种通过对用户请求去重的文件对应的数据块标签中,附加一定数量状态随机的块,以实现混淆命中块块数的方法。 云服务提供商在接收到用户发送的查询标签Hi之后,先分别检查每一个标签在云端的存在状态,并将存在状态存储在一个数组D中。 数组中元素di,可表示为 (1) 由式(1)可知,D= {0,1}n,其中n为用户本轮请求去重的文件中数据块标签的总数。接着,云服务提供商在D的末尾附加k个元素,每个元素以概率α取1,以概率1-α取0。 存在状态模糊化通过对存在状态数组D做出一定改变,可在响应值得出过程中实现有效混淆。 从实现上看,获取存在状态以及存在状态模糊化可以用原算法形式表示如下: (1)D←IsExist(tag),其中输入为集合tag,表示用户上传的请求去重的数据块标签的集合;输出为数组D,表示云服务提供商返回的用户拟上传数据块在云端的存在性状态。 函数IsExist()用来判断tag中的每个数据块标签是否存在于云端,并将结果记入D中。 (2)D′←RandRsp(D,α,k),其中输入为数组D,附加元素取值概率α以及附加元素个数k,输出为数组D′。 函数RandRsp()表示响应模糊化函数,向数组D中添加k个元素,其中每个元素以概率α取1,以概率1-α取0。 4.3.2 上传块乱序 乱序是将敏感块等可能地分散至任一分组,从而扩大响应值的取值区间,以实现对攻击者的混淆。 为了实现乱序,通常采用专门实现置乱的库函数,输入有序序列,得到等长乱序序列。 从实现上看,乱序可以用元算法形式表示如下: Dshuffle←Shuffle(D′,w),其中w为置乱密钥,由CSP随机生成。 该算法以经过云端模糊化处理的文件块存在状态数组D′为输入,将乱序后的数组Dshuffle作为输出。 4.3.3RCAS响应生成 R←GenRsp(Dshuffle),其中输入是乱序后的存在状态数组Dshuffle,输出是该数组的响应值R。 该函数表示由存在状态数组生成响应值的函数。 表1 RCAS响应表 4.3.4 范德蒙德矩阵编解码 范德蒙德矩阵编解码[19]由客户端范德蒙德编码与云端范德蒙德解码组成。 假设待上传的文件含有n个块,其中t个为未命中块,文件块矩阵C=[C1,C2,…,Cn]T,云端返回的响应值为r。 客户端线性表达式计算如下:用户与云端约定了一个r×n的范德蒙德矩阵Vr,矩阵的秩R(Vr)=r。 用户计算mr=VrCr,并将矩阵mr上传至云端。 云端得到mr后,取其前t行,记为mt,云端由参数t计算矩阵Vt,计算(n-t)×n的In-t,In-t的内容为(E(n-t)×(n-t)⋮0(n-t)×t),E为单位矩阵,0为零矩阵;由于云端已经拥有n-t个块,云端由这些块得出矩阵Cn-t=[C1,C2,…,Cn-t]T;接着将In-t和Vt拼接,形成n×n的矩阵;将Cn-t与mt拼接,形成n×φ的矩阵。 由式(4),可得出C=[C1,C2,…,Cn]T。Vr、mr、Cn表达式为 (2) mr=VrCr, (3) (4) 从实现上看,范德蒙德编码与解码可以用元算法形式表示如下: (1)m←VandEnc(V,C),其中输入为矩阵V和C,输出为矩阵m,该函数表示范德蒙德编码。 (2)C←VandDec(m,V),其中输入为矩阵V和m,输出为矩阵C,该函数表示范德蒙德解码。 4.3.5 脏块处理 云端设置脏块列表,将所有未上传的或上传后未通过完整性校验的块定义为脏块,记录在脏块列表中[17]。在请求去重阶段,云服务提供商收到用户发来的文件块标签后首先检索它们是否在脏块列表中。有别于ZEUS、CIDER的脏块处理机制,若块Ci为脏块,则云端仅将该块的存在性状态设置为不存在,即0。无需将本组所有块状态设置为不存在,此改进可以有效减少传输开销。 本节从理论上分析RCAS去重策略面对随机块生成攻击的安全性。 定理1面对随机块生成攻击时,当上传块数n远大于附加块k时,RCAS的响应值泄露隐私的概率小于目标敏感块在云端存在概率的1%。 证明:假设攻击者构造包含n个块的去重请求,其中含1个状态未知的目标敏感块,目标敏感块在云端存在概率为p,包含s个命中块和t个未命中块,n=s+t+1。 云端附加的随机块数为k,n>>k。令泄露隐私为事件A,云端响应值为响应值下边界是事件B,敏感块为命中块是事件C,事件B|C为事件X,云端k个附加块中有i个块为命中块是事件Zi。P(C)=p。 对于随机块生成攻击,当敏感块存在于云端且云端响应值为响应值下边界时泄露隐私,此时有 P(A)=P(BC)=P(C)P(B|C)=pP(B|C) 。 (5) 计算全概率公式: P(B|C)=P(X)=P(Z0)P(X|Z0)+P(Z1)P(X|Z1)+…+P(Zk)P(X|Zk) 。 (6) 由于单个附加块命中概率α,未命中概率1-α,且各个附加块是否命中相互独立,可得 (7) 因此,求P(X|Zi)可得P(A)。 事件X出现情景如下:当n+k个块,所有命中块靠左侧排列,而所有非命中块靠右排列时,根据RCAS响应表,响应值即为下边界值,等于未命中块块数,泄露敏感块存在性隐私,此时有 (8) 将式(7)、(8)代入式(5),可得 (9) 展开式(9),可得 (10) (11) (12) (13) (14) 定理2当上传数据中含有脏块,且上传块数n远大于附加块k时,泄露隐私的概率小于敏感块在云端存在概率的1%。 证明:考虑以下场景,攻击者可能无法从一次攻击得知敏感块状态,因此考虑对同一敏感块的多次攻击。比如攻击目标的薪资收入是40美元,攻击者需要反复上传验证该具体数值。 一旦该敏感块存储至云端,窃取该块存在性隐私的攻击将没有效果。 为保证后续验证时目标块未存储于云端,攻击者在得到第1次请求的响应后会选择中断上传。 根据脏块机制,中断上传将导致后续请求中包含脏块。 假设后续请求总块数为n,其中含1个敏感块,目标敏感块在云端存在概率为p,请求还包含s个命中块和t个未命中块,n=s+t+1。 若敏感块为脏块,且此外含若干脏块。因为脏块的存在状态为0,即为非命中块,故响应值下界大于等于t+1,大于t。 又因为当且仅当敏感块为命中块且响应值为t时泄露隐私,故敏感块为脏块时不会泄露隐私。 泄露隐私概率为0,小于0.01p。 通过实验来测试文中方案抵抗侧信道攻击的安全性以及去重性能。比较对象为DEDUP、ZEUS[17]、ZEUS+[17]、RARE[18]、CIDER4[19]、CIDER8[19],其中DEDUP为未设置任何模糊化处理的跨用户源端去重,CIDER4为每次上传4个块为一个分组的CIDER去重模型。实验采用Python实现采用随机块附加策略的云数据安全去重方法。在该去重系统中,哈希摘要函数采用SHA-256算法。选取亚马逊EC2来部署云端程序,选取一组配置为 Intel(R) Core(TM) i7-8565U CPU @ 1.80 GHz、8 GB RAM内存和512 GB容量 7 200 转硬盘的服务器部署用户端程序。在安全性验证实验部分采用UCI机器学习知识库的薪资数据集Census Income[23],其包含48 842条薪资数据。在去重性能实验部分采用Enron电子邮件数据集[24],其大小为1.5 GB。 模型中,块大小φ为实验变量,φ∈{64,128,256,512},单位为字节(B)。附加块为公开块的概率α,设置为0.5。附加块块数k为实验变量,k∈{2,4,6},单位为块。文件所含块数阈值T默认为30,随着块数增加,安全性逐渐增强,当块数大于等于30块时,安全性趋于定值,因此选取T=30。 使用UCI机器学习知识库的薪资数据集Census Income测试比较各个方法面对随机块生成攻击结合学习剩余信息的混合攻击时,泄露目标敏感块存在性隐私的概率。场景如下:数据机构A将某公司员工工资信息表存放于云端,该文件只含部分敏感数据,其余部分均为公开数据。具体地,工资信息表包含年龄、阶层、婚姻状况等公开信息以及学位、每小时薪资、资本收入敏感信息。攻击者在未经许可的情况下想要获知其他员工的学位、薪资、资本收入,只需按照模板格式生成目标员工的公开信息,同时附加上猜测的敏感信息生成工资信息表,并生成去重请求,发送给云服务提供商观察响应。一旦云服务提供商在本地发现相同的工资信息条目,则会阻断当次上传。此时该攻击者就可确认猜测的学位、薪资、资本收入即为目标对象的真实信息。 该数据集含有3类低最小熵的可预测敏感信息,每条敏感信息存在于单一数据块之中。在攻击策略上,攻击者采用学习剩余信息,即暴力字典攻击,例如,攻击者可以枚举学位的所有可能选项,学士学位、硕士学位、博士学位,逐一构造含有以上选项的上传请求,观察各上传请求是否被云端阻止。一旦某次上传请求的敏感信息等于目标敏感信息,且上传请求被阻断,则泄露隐私。以上构造的多次上传请求被视作一次学习剩余信息攻击。由于目标敏感信息必然在上述可能选项之中,因此目标敏感块在云端存在的概率p的值固定为1。对于学习剩余信息攻击的每次上传请求,攻击者采用随机块生成攻击策略,构造内容为1个敏感块加s个命中块加t个未命中块的上传请求。若目标敏感块在云端存在,且响应值等于未命中块数t,则泄露隐私。本实验假设攻击者试图窃取所有可预测敏感信息,对每个目标敏感信息构造一次学习剩余信息攻击,期望在所有可预测敏感信息中猜对尽可能多的信息。 实验设置上,云端数据方面,将数据集所有薪资数据共48 842条上传至云端数据库。待去重的用户端数据方面,薪资数据含有三类敏感信息,共146 526个敏感数据。随机选取其中100 000个敏感数据作为敏感数据,攻击者采用学习剩余信息策略构建含有敏感数据的上传请求。若单次学习剩余信息攻击构造的所有上传请求中任意一次响应值为t,则此次攻击成功窃取目标敏感信息,记录100 000次攻击中成功窃取隐私的次数。 接下来分别测试了所提方案与现有工作在上述场景中隐私泄露的概率。 6.2.1 响应值下限机制下RCAS的安全性 为了检测设置响应值下限对隐私保护的作用,实验首先测试了未设置该机制时模型的安全性。如图3所示,在未命中块数量t=0的场景下,隐私泄露率并没有随块数增加而提升,而是固定在25%、6.25%和1.56%,此时有极大概率泄露隐私。原因如下:当未命中块数t=0,且附加的k个块全为命中块时,该情况概率为αk,攻击者构造的上传请求全部为命中块,响应值以100%概率等于0,即等于未命中块块数,从而泄露隐私。而当k个块不全为命中块时,此时t≥1,响应值等于未命中块数的概率降低。因此泄露隐私的概率P(A)约等于附加的k个块全为命中块的概率αk。具体如图3所示,当k=2时,P(A)=25%;当k=4时,P(A)=6.25%;当k=6时,P(A)=1.56%,与上述理论值相符。因此,未设置响应值下限时,方案有较高概率泄露敏感信息存在性隐私。 图3 未设置响应值最小值时RCAS泄露隐 私次数图(其中未命中块数t=0) 图4、5、6展示了设置响应值下限时模型的安全性。由于未命中块数t=0时,响应值最小值为1而不为0,此时隐私泄露概率为0。方案仅在t≥1时泄露隐私。当附加块数k=2时,模型泄露隐私概率均小于7%,而当k≥2时,模型泄露隐私概率降低至1%以下,体现了所提方法在侧信道攻击下的安全性。k和t的值越高,所提方法的安全性越强。随着n的值增加,方法的安全性趋于稳定。用户可以设置k的值,动态调整安全性。 图4 RCAS泄露隐私次数图(其中未命 中块数t=1,已设置响应值下限) 图5 RCAS泄露隐私次数图(其中未命 中块数t=2,已设置响应值下限) 图6 RCAS泄露隐私次数图(其中未命 中块数t=4,已设置响应值下限) 6.2.2 RCAS与现有工作安全性性能对比 RCAS与比较对象在相同输入参数下的隐私泄露次数如表2所示。在100 000次攻击中,对照组方案DEDUP以及ZEUS隐私泄露的次数是100 000次,RARE、CIDER(4)、CIDER(8)方案隐私泄露的次数分别是50 054、50 090、49 986次。RCAS在不同的参数设置下,隐私泄露的次数分别为25 016、6 256、1 561、475和66次,显著低于对比方案,并且用户可以根据自己的需求设置不同附加块块数k以实现安全性的动态调整。因此,RCAS在面对随机块生成攻击结合学习剩余信息攻击的混合攻击时,具有较高的安全性。产生这种现象的原因在于,在对照组DEDUP方案中,云服务提供商未对响应值做任何模糊化处理,响应值等于未命中块块数,因此暴露隐私的概率是100%;在ZEUS方案中,请求去重的块被成对检查,攻击者构造目标敏感块和未命中块的配对,当目标块命中时,响应值固定为1,要求用户上传这两个块的异或值,否则响应值固定为2,要求用户上传两个块本身。因此,攻击者可以根据响应值为1确定目标块的存在;而RARE对ZEUS方案的这两种情况做了进一步混淆,具体为当敏感块命中时,响应值等概率分布为U(1,2)。只要攻击者接收到响应值等于下边界值1,即未命中块数,便能推测出敏感块命中,因此隐私泄露概率为50%。对于CIDER,尽管将场景从两个块扩展到多个块,本质上与RARE原理相同,当敏感块命中,一旦响应返回下边界,即未命中块数,隐私立即泄露。 表2 安全性性能表 通过在Enron电子邮件数据集上开展去重实验,比较各方案的去重效率。开展传输开销与块长关系实验,探究保证效率下的最佳块长;开展传输开销与附加块块数关系实验,探究方案参数附加块块数对去重效率的影响;开展上传开销与未命中块比例关系实验,比较各方案在不同未命中块比例下的去重效率。 6.3.1 用户端上传开销与文件块长度的关系 实验通过比较各模型在不同块长下的传输开销探究最佳块长。块长越小,去重的强度越高。然而,块长越小,元数据量也会相应增加,客户端指纹数目增加,指纹的传输开销更高。为此,设计实验以研究块长对传输开销的影响。 实验设置如下:待去重的客户端数据测试集为Enron电子邮件数据集中may-l文件夹,含1 600个总共大小为5.84 MB的文本数据文件。云端数据为该数据集除去测试集的所有文件夹内数据,包含51万个文件共约1.5 GB的文本数据。场景如下:某公司的大多员工已经将各自的电子邮件数据存储在云端,员工May最后一个上传她的邮件。由于不同电子邮件间形式上极为相似,对于May,使用源端去重相比于目标端去重能够节省更多传输开销。除了ZEUS等方案,还比较了DEDUP和RAW两个对照组模型的去重开销。DEDUP为不经任何模糊化处理的源端去重方案,所有命中块无需上传。而RAW为目标端去重方案,所有块无论命中与否都需要上传。选取块长φ为自变量,φ∈{64,128,256,512},单位字节(B)。参数选取k=2,α=0.5。 块长与总传输开销的关系如图7所示。当块长为128 B时,所有方案均有最佳的去重表现,所需总传输开销维持在最低水平。而当块长为64 B或256 B时,各方案去重传输开销均有所上升,而块长达到512 B时,需要额外传输大量数据。因此,128 B为各方案最佳块长度。 图7 各方案传输开销与分块长度的关系图 6.3.2 用户端上传开销与附加块数量的关系 附加块数量作为方案的可变参数,其与传输开销的关系值得进一步研究。实验沿用以上实验的设置,调整附加块数量k,观察不同块长下的传输开销。如图8所示,当附加块数增加时,传输开销没有显著变化。原因如下:①对每个上传请求仅执行一次随机块附加算法,附加次数少,因此总附加块数远少于总块数。②每个附加块有α概率为命中块,根据响应值表,命中块仅有在特殊位置才会增加传输开销,这进一步减少了附加块数量对传输开销的影响。③由于采用真实数据集开展实验,被测数据含有一定数量的命中块与未命中块,多次测试中在乱序后由响应表带来的额外传输开销各不相同,存在一定的随机性。在此随机性因素下观察附加块数带来的影响比较困难。 图8 RCAS方案传输开销与附加块数量的关系图 6.3.3 用户端上传开销与未命中块比例的关系 将文中模型RCAS在不同命中块比例下传输开销与ZEUS、RARE和CIDER进行比较。采用10%、50%和80%作为未命中块比例的取值。这3个取值能够较为全面地体现不同模型在低、中、高未命中块比例下的传输开销。具体实现上,每个文件将按照最佳块长128 B进行分块。以数据集所有文件作为云端数据选取范围,随机选取90%、50%、20%的文件预先存放在云端作为云端数据,因此未上传的文件为未命中块,比例分别为10%、50%和80%。选取may-l文件夹中所有文件作为待去重的用户端数据,上传用户端所有数据,记录总传输开销。传输开销由哈希传输开销、未命中块传输开销组成。分别测试以上4种方案,各方案总传输开销如图9所示,额外传输开销如图10所示。在未命中块比例较小时,RCAS需要10%的额外传输开销,低于其他方案。当未命中块占比达到50%时,根据图10可知,RARE与ZEUS+的开销过大,远远高于RCAS,而CIDER的性能则比RCAS要好。当未命中块比例达到80%时,RCAS总传输开销稍高于RARE以外的方案。总的来说,未命中块比例较小时,文中方案在开销上稍优于其他模型,而随着自变量增大,传输开销与比较对象持平。产生这种现象的原因如下: 图9 各方案总传输开销与未命中块比例的关系图 图10 各方案额外传输开销与未命中块比例的关系图 (1) ZEUS。根据ZEUS的响应表,当且仅当一个分组的两个块均为命中块时,ZEUS会额外产生一个块长的开销。当未命中块比例较低时,一个分组的两个块大概率均为命中块,此时ZEUS会产生更多的额外开销。而未命中块比例较高时,两块均为命中块的概率大大降低,ZEUS的额外开销降低。 (2) ZEUS+。当云端存储的文件块副本数较少时,文件块的存在状态被调整为不存在,响应表与ZEUS保持一致,因此ZEUS+会由于阈值带来比ZEUS更高传输开销。 (3) RARE。根据RARE响应表,RARE在未命中块比例较低时,分组内均为命中块概率较高,额外开销大。当未命中块比例较高时,分组内均为未命中块概率较高,额外开销小。但额外开销仍会高于同类型的ZEUS。 (4) CIDER。选取组内块数分别为4和8的CIDER4和CIDER8作为RCAS比较的对象。在未命中块数小于组内总块数时,响应值为未命中块数和未命中块数+1的概率相等,因此额外传输开销约等于一个块的大小;否则,不存在额外开销。因此,随着未命中块比例的增加,组内未命中块块数等于组内总块数的概率增大,带来的额外传输开销减小。由于CIDER每4或8个块产生一个块长的额外传输开销,因此传输开销低于ZEUS。 (5) RCAS。根据RCAS响应表,当未命中块比例较低时,组内未命中块+命中块比例由未命中块块数决定,该组合比例较低,带来的额外传输开销较少。当未命中块块数中等水平时,该组合概率达到最大值。当未命中块比例较高时,该组合比例由命中块块数决定,比例同样较低。但是此时未命中块+命中块组合比命中块+命中块组合比例更高,而前者增加RCAS额外传输开销,不增加ZEUS的开销,因此RCAS传输开销比ZEUS高。 文中提出一种采用随机块附加策略的云数据安全去重方法RCAS,实现了抗随机块生成攻击以及学习剩余信息攻击等侧信道攻击的安全性。具体来说,该策略采用附加随机块、文件块乱序、构造响应表等技术隐藏文件块的存储状态和位置信息,扩大响应值的取值区间,在增加少量开销的情况下,使响应值出现下边界值的概率极大降低,从而将安全风险降低到概率可接受范围。安全性分析和实验结果表明,与当前流行技术相比,该方法以增加少量开销为代价提高了抗侧信道攻击的安全性,在包括电子邮件、电子工资单、企业合同、病历、标底书等在内的低熵文件去重领域拥有广泛的应用前景。 但是,文中方法仍有进一步优化的空间。在接下来的研究中,针对附加块为命中块的概率α,可探究α的不同取值对去重方案抗侧信道攻击的安全性与通信开销的影响;针对响应表的设计,可探究只有一个块命中时响应值取非整数对通信开销的优化效果。4.3 采用随机块附加策略的云数据安全去重方法
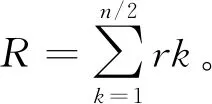

5 安全性分析




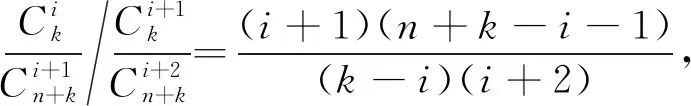
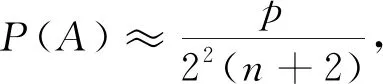
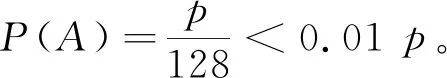
6 实验验证及结果分析
6.1 模型参数设置
6.2 安全性测试





6.3 去重效率


7 结束语
