面向ASPE的抗合谋攻击图像检索隐私保护方案
2023-11-17范艳芳
蔡 英,张 猛,李 新,张 宇,范艳芳
(北京信息科技大学 计算机学院,北京 100101)
1 引 言
随着图像数据的指数级增长,云计算因其丰富的计算和存储资源使图像数据的存储、多用户检索和分享更加高效[1]。因此,越来越多的用户将图像外包至云服务器,因上传的数据对于云服务器来说是完全可见的[2],而在检索过程中,云服务提供商和检索用户不可信以及外部敌手的存在,可能导致包含敏感信息的图像数据泄露[3],这会对用户的财产安全以及人身安全等造成威胁[4-6]。因此,云计算下的图像检索中的隐私保护是至关重要的[7-8]。
现有的实现隐私保护的图像检索技术大致分为非对称内积标量保留加密(Asymmetric Scalar-Product-preserving Encryption,ASPE)[9-10],流密码[11],保序加密[12]和同态加密[13]。ASPE因其密文内积值和明文内积值一致的特点,可以实现云计算下在密文域的相似图像检索。相对于流密码中密文异或与明文一致以及保序加密中密文顺序与明文一致的特点,ASPE不会泄露上述的数据关系。相对于同态加密可能出现的密文膨胀和密钥过大的问题[14],基于ASPE的图像检索效率较高,是由于其通过随机矩阵对特征向量进行加密,安全性与向量长度正相关,因此可以在安全性和效率之间动态调整。2009年,WONG等[15]基于对K近邻计算的研究提出了ASPE算法,经其加密的数据向量和查询向量可以保证密文内积值和明文内积值一致。YUAN等[16]将ASPE转变为错误学习(Learning With Errors,LWE)困难问题,解决了使用相同密文查询导致的安全问题。SONG等[17]为了防止查询用户拥有全部的密钥,将ASPE算法的密钥分解为两部分,一部分用于本地加密,另一部分交给云服务器进行重加密。LI等[18]为了进一步提高向量的机密性,将加密数据向量和查询向量进行分裂,并分别进行加密。上述大部分方案默认检索用户是完全可信的,但在实际的多用户场景下,可能存在恶意用户泄露密钥从而导致其他查询用户的明文泄露。文献[17]虽然通过将一部分密钥上传至云服务器来解决用户不可信问题,但同时会产生新的问题,即云服务器和检索用户因合谋导致的密钥泄露。
针对上述问题,笔者提出一种面向ASPE中抗合谋攻击的图像检索隐私保护方案。该方案在实际的多用户场景下,不会泄露图像及其特征的明文信息,且可以抵抗不可信用户和云服务器之间的合谋攻击。同时通过在大规模数据中可以快速进行相似性检索的局部敏感哈希来构建索引。实验表明,在保证检索效率的前提下,密文域下的检索精度可以接近明文域下的检索精度。
2 准备知识
2.1 ASPE算法
(1)GKey:密钥生成。 数据拥有者随机生成一个(d+1)×(d+1)维可逆矩阵M(d为正整数),将M-1(M的逆矩阵)发送给检索用户。

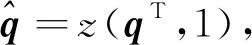
(4)Sim:相似度比较。 分别用p′i和p′j表示数据库中两个加密向量。 当p′iq′-p′jq′>0,说明q与pi距离更近;否则反之,由此计算前K个相似图像并返回给用户。
2.2 局部敏感哈希
给定一簇哈希函数H,H={h:D→U}。d表示两点之间的距离。 给定阈值r1和r2,概率值p1和p2,其中r1
(1)若d(x,y)≤r1,则PH[h(x)=h(y)]≥p1。
(2)若d(x,y)≤r2,则PH[h(x)=h(y)]≤p2。
3 系统模型与威胁模型及设计目标
3.1 系统模型
文中系统模型如图1所示,由4类实体组成:可信机构(Trust Authority,TA),图像拥有者(Image Owner,IO),查询用户(Search User,SU)和云服务器(Cloud Server,CS)。
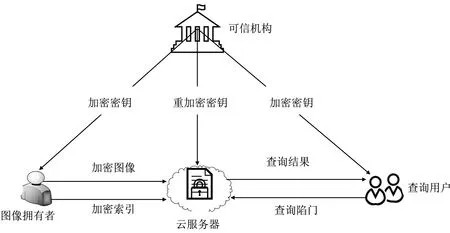
图1 系统模型
(1) 可信机构:负责初始化系统安全参数,生成所需密钥,并分发给图像拥有者、查询用户和云服务器。
(2) 图像拥有者:首先提取图像的特征向量,使用可信机构通过可信信道发送的密钥对图像数据集进行加密,并由特征向量构造加密索引。最后,将加密索引及加密图像上传到云服务器。
(3) 查询用户:首先提取查询图像的特征,使用可信机构通过可信信道发送的密钥对其进行加密,将其作为查询陷门上传到云服务器进行检索。最后,将云服务器返回的前K个结果进行解密。
(4) 云服务器:存储图像拥有者上传的加密索引和图像,并根据查询用户上传的陷门在索引中计算相似性,将相似的前K个图像重加密后返回给查询用户。
3.2 威胁模型
文中案定义如下威胁模型:图像拥有者和可信机构完全可信,查询用户不可信,云服务器半可信(会按照设计的协议来执行相应的图像检索服务但可能会基于利益关系窃取存储的图像数据和查询用户的查询请求)。由此得出以下4种攻击模型:
(1) 合谋攻击:不可信查询用户和半可信云服务器存在合谋,例如查询用户向云服务器泄露加密密钥。
(2) 唯密文攻击:由于云服务器可以获取加密图像,索引和查询陷门,因此云服务器可以对密文进行穷举攻击。
(3) 已知背景攻击:外部敌手获取一些与图像用户相关的背景信息,并根据大量的查询请求和相应的检索结果推断出明文和密文对。
(4) 已知明文攻击:云服务器通过已得知的与待解密文用同一个密钥加密的一个或多个明密文对推断出密钥。
3.3 设计目标
针对上述的威胁模型和系统模型,设计目标如下:
(1) 隐私需求。
① 密钥泄露:云服务器和查询用户不能获得全部密钥,且需要考虑两者的合谋问题。
② 索引隐私:索引由特征向量构造,特征向量包含图像的敏感信息。因此云服务器存储的应为加密索引。
③ 图像隐私:对图像进行可靠加密处理,防止云服务器了解图像明文信息。
(2) 检索效率:在不会降低检索精度的前提下,为了适应大规模的图像检索场景,方案的检索时间复杂度应尽可能低。
(3) 检索精度:为了满足检索用户的相似性需求,所提方案在密文域的检索精度应无限接近明文域下的检索精度。
4 多用户场景下的图像检索隐私保护方案
文中方案适用于多用户场景下大规模数据的图像检索。在客户端采用对角矩阵加密解决云服务提供商和检索用户之间的合谋攻击,云服务器端通过代理重加密技术解决图像的密钥泄露问题,采用线性判别分析来解决局部敏感哈希构建索引时因降维导致的精度下降。方案包括7个步骤,具体如图2所示。方案中的参数说明如表1所示。
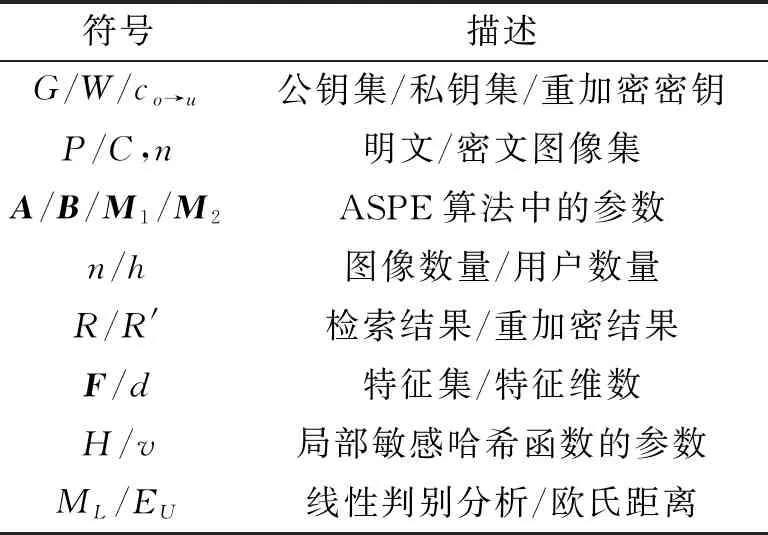
表1 符号描述

图2 多用户场景下的图像检索方案过程图
方案步骤具体说明如下:
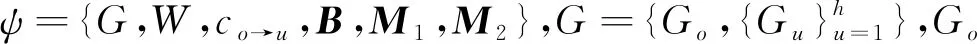
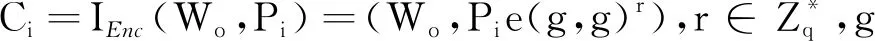
(3) 图像拥有者上传加密索引。 根据图像特征构建的安全索引详见算法1。 其中,步骤②~⑧是对角矩阵的构造过程,步骤④中前d+1项的值设为1,原因是在步骤对特征加密时,前d+1项是原始特征,后d-1项是混淆特征,因此为防止矩阵相乘时破坏原始特征,前d+1项设为1。 步骤⑨~是构建局部敏感哈希索引的过程,其中步骤引入线性判别分析是为了减小局部敏感哈希因降维映射导致的精度丢失问题。 步骤~是对特征向量加密的过程,其中步骤是将特征扩展到2d维。 步骤~是将特征分解成两个2d维向量并由{A,M1,M2}加密。
算法1基于线性判别分析的抗合谋攻击索引构造算法。
输入:P,V
① 初始化:哈希桶T={T[i]={φ},i∈N};矩阵A2d×2d={A[i][j]|A[i][j]=0,i,j∈(1,…,2d)}向量∂={∂i|∂i∈{0,1},i∈(1,…,d-1)}
② fori←1 to 2ddo
③ ifi≤d+1 then
④A[i][i]=1
⑤ else:
⑥A[i][i] =R(·)∥产生随机数
⑦ end if
⑧ end for
⑩F.append(Pn)∥提取图像特征并存入F中
张兰花用一颗赤诚的心,连续五年参与了师团“5000致富带动工程”,与女职工郭艳英结成帮扶对子,使其成为团场“脱贫致富标兵”。在她的带动下,连队25名职工成为团场科技致富的“领头雁”。她通过自学获得了第二师颁发的“高级农艺工”证书。

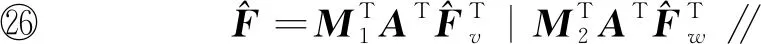
(4) 查询用户上传陷门。 首先查询用户提取查询图像MQ的特征向量Q=(q1,q2,…,qd),并根据特征向量计算哈希桶值TQ=H(Q)=(v1(Q),v2(Q),…,vg(Q))。查询用户将Q扩展为2d维向量,如式(1)所示:
Q′=(q1,q2,…,qd,1,β1,β2,…,βd-1) ,
(1)
其中,βi,i∈(1,2,…,d-1),是随机生成的二进制向量。然后,使用{B,M1,M2}来加密向量Q′。加密分两步进行。
① 根据B[j](j=1,2,…,2d)的值将向量Q′分为两个2d维随机向量{Q′v,Q′w}。若B[j]≥0,则Qv[j]+Qw[j]=Q[j];否则,Qv[j]=Qw[j]=Q[j]。
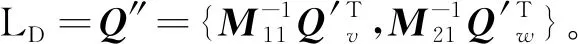

(2)
(3)
式(2)和式(3)做差得到式(4):
(4)

(6) 云服务器发送重加密图像。 云服务器根据查询用户所对应的重加密密钥co→u=gGo/Gu对结果R进行重加密,得到结果R′,并将R′返回给查询用户。
(7) 查询用户解密图像。 查询用户收到重加密结果R′之后,使用自己的私钥Gr解密得到结果集合,如式(5)所示:
Im=IDec(Gr,R)=(Ime(g,g)a)/(e(g,g)aGr)1/Gr。
(5)
5 安全性分析
针对密钥安全性、图像安全性、索引和查询陷门的机密性进行分析。

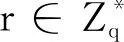
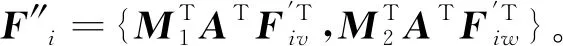
6 方案性能分析
6.1 理论分析
所提方案分别与CSM方案[5]和文献[10]从计算和通信开销进行对比。其中,|λ|为安全参数λ的长度,n为图像数量,K为检索结果的数量,d为特征向量的维数,h为用户的数量,m为映射到哈希桶内的图像数量,s为随机正整数。
6.1.1 计算开销
如表2所示,索引构建和陷门生成的计算开销主要来自矩阵与向量的乘积,其中矩阵是密钥矩阵,图像特征构成向量。文献[10]和CSM方案通过扩展向量维数判定用户的合法性,其中文献[10]将原来的d维向量扩展为d+3+h维,CSM方案扩展为2d+2+h维,文中方案扩展为2d维,因此当h增大时,CSM方案和文献[10]的计算开销大于文中方案的计算开销。为了增强特征的机密性,CSM和文中方案将维数扩展后又将其分裂为两部分,导致开销是文献[10]的2倍,但当h增大(实验数据h=384)时,文献[10]的计算开销就仍大于文中方案。图像检索的计算开销也是来自矩阵的乘积,由于文中方案在算法1的步骤使用了线性判别分析,使桶内的数据更加精准,桶内数量比CSM和文献[10]少s个,因此提高了检索的效率和精度。

表2 计算开销对比
6.1.2 通信开销
如表3所示,图像拥有者主要的通信开销来自向云服务器上传n个加密的图像及特征,其中n个加密图像的长度为n|λ|,加密特征的长度由扩展的特征向量决定,因文献[10]和CSM方案通过扩展特征向量维数判定用户的合法性,其中文献[10]将原来的d维向量扩展为d+3+h维,CSM方案扩展为2d+2+h维,文中方案扩展为2d维。因此当h增大时,CSM方案和文献[10]的通信开销就大于文中方案的通信开销。查询用户的通信开销是将陷门上传至云服务器,陷门的长度同样由扩展的特征向量决定,因此当h持续增大时,CSM方案和文献[10]的通信开销就仍大于文中方案的通信开销。云服务器的通信开销来自于返回给用户的检索结果,因此返回的检索结果个数K越大,云服务器的通信开销就越大。

表3 通信开销对比
6.2 实验分析
实验的开发平台为PyCharm,开发语言为Python。测试环境:Intel(R)Core(TM) i7-8565U CPU @ 2.00 GHz的处理器,8 GB内存,Windows 10操作系统。实验采用了GPU服务器(12核、60 GB内存、2×P100、Ubuntu18+NV440+CUDA10.2)模拟云服务器的计算能力。仿真实验数据集采用加利福尼亚理工学院的Caltech 256数据集,其中包含256类图像(共10 800张)。CNN模型提取特征向量的维度为4 096。分别从检索准确率和效率两个方面进行实验对比。
6.2.1 检索准确率
由于文中方案返回的是前K项结果,而P@K[19]是一种可以度量前K项检索准确率的指标,因此文中方案使用P@K来作为准确率的衡量标准,如式(6)所示:
(6)
其中,K表示返回的图像数量,npositive表示返回图像中的正类图像的数量。文中采用开源机器学习库Scikit-learn中Decomposition模块里的PCA函数,即主成分分析,对特征进行降维。
方案测试了不同K值在不同维度下的检索精度。从表4可以看出,特征向量在d=128且K=5时检索精度达94.17%。由方案设计可知,top-K(选择相似度排名前K个元素)是由桶内特征和查询特征之间的欧氏距离决定的,因ASPE本身不会破坏特征向量,因此影响检索精度的关键因素是使用局部敏感哈希构建索引时因降维导致的精度丢失问题。图3是在d=128,n=10 000情况下,通过线性判别分析优化局部敏感哈希,文中方案在密文域下的检索精度与明文域的检索精度仅相差约2%,其中CSM方案和文献[10]因未考虑局部敏感哈希因降维导致的精度丢失问题,单个哈希桶内和查询类相似类的个数比文中方案少,造成检索准确率比文中方案低。

表4 不同向量维度下的准确率 %
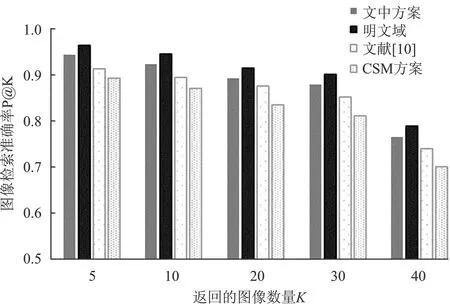
图3 不同返回图像数量下P@K精度
6.2.2 检索效率
从索引构建、陷门生成和检索计算开销三方面来与CSM方案[5]和文献[10]进行检索效率对比分析。
(1) 索引构建计算开销。
图4表明当向量维度d=128和图像数量n=10 000时,随着用户数量的增加,文献[10]和CSM方案的构造索引的时间开销也随之增加。文中因在算法1步骤~中将特征扩充后再加密,所以开始时的构建索引开销比文献[10]的大,又文献[10]和CSM方案对向量的扩展和用户的数量相关,所以当用户数量不断扩大时,文中方案索引构建开销就会远小于其他两个方案。因此文中方案在用户规模庞大时,效果明显优于其他两个方案。
图5表明在向量维度d=128和用户的数量h=384时,随着图像数量的增加,构建索引的时间开销也随之增加。这是因为图像增加导致特征增加,构建索引的时间也随之增加。选取h=384是因为在图4中当用户数量大致在384时文中方案的性能优势开始产生。

图4 用户规模变化下的索引构建时间开销
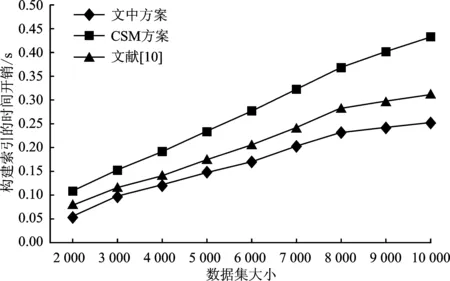
图5 数据规模变化下的索引构建时间开销

图6 特征维度变化下的陷门生成时间开销
(2) 陷门生成计算开销。
图6表明在图像数量n=10 000时,随着特征向量维度的增加,陷门生成的时间开销也随之增加。这是因为生成陷门的时间开销主要来自于矩阵乘积,因此当维度增大时,矩阵乘积的时间开销也增大。文中方案因引入的变量相对CSM方案和文献[10]要少,所以陷门生成的时间开销比其他方案要小。
(3) 图像检索计算开销。
图7表明在图像数量n=10 000和返回数量K=5时,随着向量维度的增加,检索时间也随之增加。这是因为维度增加导致矩阵相乘的计算开销增大。图8表明在特征维度d=128和返回数量K=5下,随着数据集的增大,检索时间也随之增加。这是因为数据集增大导致映射到每个哈希桶的数量也随之增加。文中方案因使用线性判别分析来扩大类间距离和缩小类内距离,因此映射到每个桶内的数目更精准,在降低检索开销上比CSM方案和文献[10]更具优势。
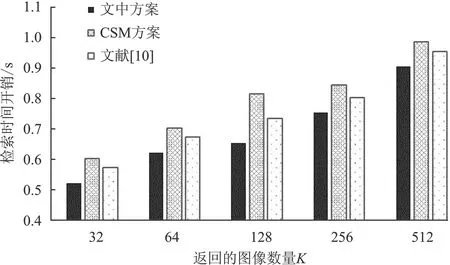
图7 特征维度变化下的检索时间开销
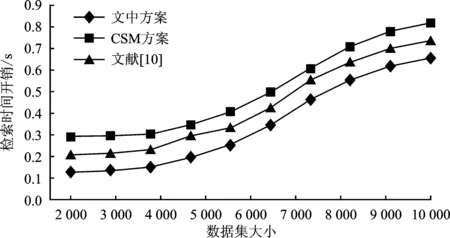
图8 数据集规模变化下的检索时间开销
7 结束语
针对云计算多用户场景下图像检索的隐私保护问题,笔者提出了一种面向ASPE的抗合谋攻击图像检索隐私保护方案。安全性分析证明了所提方案能够达到已知明文攻击、唯密文攻击、已知背景攻击和合谋攻击下的安全。通过与其他方案的比较,证明了文中方案在大规模图像数据中,依然可以在较小的计算开销以及较高的检索效率下,拥有接近明文域的检索精度。
