浅谈机器学习中的回归问题
2023-11-16牟安胡艳茹张庆
牟安,胡艳茹,张庆
宁夏师范学院,宁夏固原,756000
0 引言
在现代科技的背景下,机器学习已经成为重要的研究领域,并且在诸多实践中展现出了巨大的价值和潜力。机器学习是一种数据分析的方法,它自动构造分析模型,以理解数据模式并提供数据驱动的预测。回归问题作为机器学习中的基础问题之一,对于预测连续值或离散值具有重要的作用。本文将深入讨论机器学习中的回归问题,包括线性回归、多项式回归以及逻辑回归。
1 连续值域上的回归问题
1.1 线性回归的概念与应用
线性回归是一种用于预测连续值的强大工具,它在机器学习和统计学中有着广泛的应用。其核心思想是基于输入变量与输出变量间的线性关系进行预测。例如,根据房屋面积预测房价、根据广告投入预测销售收入等。线性回归的优点在于其模型简单、易于理解、计算效率高。
线性回归的核心组成部分包括问题的抽象与方向、假设函数、代价函数以及梯度下降等。首先,线性回归问题的抽象与方向一般为找出输入变量和输出变量之间的线性关系。这种线性关系可以通过线性方程来表示,这就是所谓的假设函数。例如,在单变量线性回归中,假设函数可以表示为,其中,和是待求解的参数。然而,仅有假设函数并不能解决问题,还需要衡量假设函数的好坏,这就引入了代价函数的概念。代价函数也被称为损失函数或成本函数,它用于衡量预测值与真实值之间的误差。梯度下降法的基本思想是,沿着梯度(即函数在某一点处的斜率)的反方向,不断调整参数值,使得代价函数的值逐渐减小,最终达到最小值。这样就得到了线性回归问题的解[1]。总结来说,线性回归问题的特点是简单、易于理解,并且在许多实际问题中具有良好的预测效果。其解决方法主要是通过梯度下降算法优化代价函数,找到最佳的线性关系。
1.2 线性回归的代价函数
线性回归的核心在于通过构建数学模型进行预测。例如,收集房价样本y与其特征x(如房屋面积)的数据,并构造一个假设函数h(x)=ax+b,该函数可以使预测值h(x)与真实房价y非常接近。这种情况下,使用这个模型来预测未知的房价,这就是一元线性回归。如果房价数据涉及更多的特征,如房屋面积和卧室数量,可以构造一个二元线性回归模型在这里,假设函数h(x)也可以写成向量形式,其中=1。
接着,引入代价函数J(θ),其中θ是假设函数h(x)中所有参数的向量,包括θ0、θ1、θ2等。代价函数J(θ)度量了预测值h(x)与样本y值之间的差距。为了使预测更准确,目标是最小化J(θ),即最小化预测值与真实值之间的差距。线性回归的代价函数通常定义为预测值和实际值之间的均方误差:。
由于J(θ)是一个凸函数,它的局部最小值就是全局最小值[2]。这一特性可以通过梯度下降算法找到最优解。此外,方向在函数中也有其重要的含义,方向需要包含定义域的所有维度。例如,对于二元函数来说,其图像是三维空间,而定义域是二维的,所以函数上某点处在定义域上可能的运动方向是二维的向量,此时,方向的数量应该是无穷多个。由这种观点来看,一元线性回归样本x的一维空间上,运动方向只有两个,即正向和负向。在梯度下降算法中,需要明确理解方向的概念。
1.3 梯度下降法在求解线性回归中的应用
梯度是由函数对定义域内各个维度求偏导数得到的向量。在函数的某一点,沿着该点的梯度方向,函数值下降的速度最快。对于求解线性回归中的代价函数J(θ),可以应用梯度下降法寻找其全局最小值。具体来说,通过迭代更新参数向量θ,直到其变化非常小,即达到预设的停止条件。
2 多项式回归问题的特点及代价函数正则化
在多项式回归问题中,特征x可能具有高次方,相较于线性回归中的一次方特征,多项式回归能更好地拟合复杂的数据模式。然而,过度复杂的模型可能会导致过拟合,即模型过度适应训练数据,却在新的未知数据上表现不佳。为解决这个问题,引入了正则化的概念。
正则化是一种用于防止模型过拟合的技术,它通过在代价函数中添加一个惩罚项来抑制模型复杂度。在多项式回归中,通常会使用L2正则化,即在代价函数中添加参数的平方项。这样做的目的是鼓励模型生成更小、更稳定的参数,从而使得模型更接近线性,提升其泛化性能。具体地,L2正则化的代价函数如下所示:。其中,i从0到m,表示样本数量;j从1到n,表示特征维度的数量;λ是正则化参数,控制正则化的程度,即惩罚项的权重。注意,在这个公式中,通常不对进行正则化,因此求和项从j=1开始。正则化提供了一种权衡模型复杂度和泛化能力的方法,更好地解决过拟合问题,提升模型的预测性能[3]。
3 离散值域上的逻辑回归问题
3.1 逻辑回归问题的特点及其机器学习解法
线性回归和多项式回归通常用来做连续值域上的预测,而对于有些离散值域上的预测,会使用一些特别的假设函数g(z)。比如对于值域只有0和1的预测问题,会使用sigmoid函数作为假设函数。sigmoid函数如图1所示。
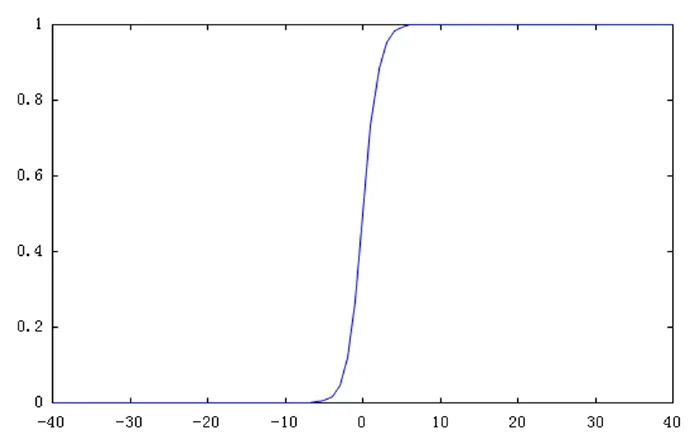
图1 sigmoid 函数
sigmoid函数为增函数,定义域为(-∞,+∞),值域为(0,1),且有g(0)=1/2,当时,;当时,,g(z)的特点可用来映射为一个按概率分类的二类分类问题,即有两类结果A和B分别对应于离散值0和1,当样本特征z>0时,就认为该样本有g(z)的概率分类为B类,有1-g(z)的概率分类为A类。同样的,对于多分类问题也可以在同一个空间内构建多个二类分类的sigmoid函数,把样本带入不同的sigmoid函数中得到不同的概率值,将其分类为概率值最大的sigmoid函数对应的分类中,这种解决分类问题的方法被称为逻辑回归[4]。通常使用线性回归和多项式回归的假设函数h(x)来定义z,即令z=h(x)。
对于逻辑回归的代价函数,一般不再使用线性回归和多项式回归的差的平方的定义方式,因为逻辑回归的样本特征y值是离散的0或1,按照差的平方算法得到的代价函数可能不是凸函数,那么对其应用梯度下降算法不容易得到全局最小值。一般的做法是采用y=0和y=1时以log函数为基础分别定义代价函数,设计思路是:对于正样本y=1,如果预测值h(x)越接近负样本,即x轴越接近0时,就认为代价值很大;对于负样本y=0,如果预测值h(x)越接近正样本,即x轴越接近1时,就认为代价值很大。进行y=0和1的汇总之后得到:
其中的h(x)是多项式回归的假设函数,所以对于逻辑回归来说,也需要进行正则化,大多数资料上,都是直接采用了线性回归和多项式回归的正则项,即直接在代价函数中增加θ2项所占的权重,得到下面经过正则化的逻辑回归的代价函数:
3.2 逻辑回归代价函数的正则化改进
逻辑回归是一种广泛使用的分类算法,其代价函数通常采用L2正则化项,与线性回归和多项式回归的处理方式相同。这样做的优点在于,求偏导数的计算和代码实现相对简单[5]。然而,通过对多项式回归正则化项的分析,可以发现,引入正则化项的目的是增加一次方项的权重,但在逻辑回归的代价函数中,如果仍然使用项,由于逻辑回归的代价函数并非基于线性回归的均方误差,而是基于对数损失函数,无法通过倒推的方式得到假设函数的一次方项。因此,提出对逻辑回归的代价函数正则化项进行改进,从项改为项。虽然这样的修改会增大计算代价函数偏导数的复杂度,但它可能会更准确地满足正则化项的本意,即增加假设函数中一次方项的权重。改进后的逻辑回归代价函数为:
然而,这个改进可能并不总是适用。因为log函数的特性,当时,是负的,这将导致整体的代价函数可能变为负数,需要调整为,因此,在实践中,需要根据具体情况和需求来选择合适的正则化方法。
4 线性回归与逻辑回归的区别与联系
对于逻辑回归来说,z=h(x)是线性、非线性对于求解过程来说并不重要,z按sigmoid函数的定义域来看,都是正负无穷区间。z的线性和非线性,区别只是表现在逻辑回归的二类分类时,展示分类效果图上分类的边界线是直线还是曲线,对于求解过程来说差别不大。逻辑回归的sigmoid函数,只是把定义域和值域做了简单的映射。sigmoid的定义域与值域之间的映射关系如表1所示。

表1 sigmoid 的定义域与值域之间的映射关系
sigmoid函数作为假设函数,只是让线性回归的假设函数z=h(x)相比较线性回归和多项式回归的假设函数h(x)换了一种看法,样本之间的相对大小并没有改变,因为sigmoid是递增的,只是让线性回归和多项式回归的假设函数的函数值,平移到了值域空间[0,1]上,使得值域成了概率值的空间。至于在做假设函数时,如果z=h(x)是基于多项式做的假设函数,同样会比较容易产生过拟合的问题,所以需要加入上文中提到的正则项。那么使用sigmoid的条件,就是其定义域z=h(x)的范围为(-∞,+∞)。对线性回归、多项式回归、逻辑回归的区别与联系归纳如表2所示。

表2 线性回归、多项式回归、逻辑回归的区别与联系表
由表2可见,线性回归、多项式回归和逻辑回归都是预测模型,各自适用于连续值预测和二分类问题。线性回归和多项式回归预测连续值,逻辑回归则处理二分类问题[6]。线性回归假设线性关系,多项式回归处理非线性关系,而逻辑回归通过sigmoid函数将结果映射到[0,1],作为概率解释。正则化技术用于防止过拟合,常在高阶项存在时使用。
5 总结
本文叙述了线性回归、多项式回归、逻辑回归的产生背景及适用场景,对求解代价函数所用到的梯度下降中的方向的概念做了着重强调和解释说明,它是理解梯度下降算法的关键所在,并对多项式回归中正则化项的由来以及倒推演算的观点做了解释说明,并由此种观点来改进逻辑回归中的正则化项,从而提高了逻辑回归中代价函数的精确性,并使其更符合正则化项的本意。
