一种相机和激光雷达数据融合的目标检测算法
2023-11-15申彩英朱思瑶黄兴驰
申彩英,朱思瑶,黄兴驰
(辽宁工业大学 汽车与交通工程学院,辽宁 锦州 121001)
0 引言
无人驾驶汽车主要由3大系统构成:环境感知系统、路径规划系统和运动控制系统。环境感知是路径规划和运动控制的前提,也是无人驾驶汽车最亟待解决和优化的关键技术难题,正确识别车辆周身环境是无人驾驶汽车运行的基础。
相机和雷达是环境感知的重要传感器,由此衍生出3类基本检测算法。基于纯图像算法、基于纯点云算法、基于两者融合算法。三者各有优劣:基于图像视觉常见的算法有:一阶段算法其典型代表有SSD[1]、YOLOv3[2]系列;二阶段算法其典型代表有R-CNN[3]、Faster R-CNN[4],此类算法由于可见光相机信息密度高,提供了细致的纹理和颜色信息,可提取更多特征,从而提高检测精度。但夜间工作能力差且无法提供深度信息。
基于激光雷达的算法有:基于点云的PointNet[5]算法和基于体素的VoxelNet算法[6],以及相关的改进算法SECOND算法[7],PointRCNN算法[8]。此类算法可在夜间工作并提供了非常准确的深度信息,但存在远处点云数据稀疏,对小目标检测效果差的问题。
基于两者融合的算法,能够很好地利用两者优点,典型的融合算法有:MV3D算法[9],其算法融合RGB图像和雷达点云作为模型输入的一种三维目标检测,用多视图对3D点云进行编码。AVOD算法[10],引入FPN结构以适应不同尺寸的图片数据,增加了三维检测框的参数。AVOD相较于MV3D,提高了小目标的召回率。Qi等提出F-PointNets检测算法[11],使用了串联的方式先融合图像与深度信息,减小了需处理的数据量,提高了算法运行效率,但此算法较为依赖RGB图像数据,对光线变化敏感,算法鲁棒性不佳。Xu等提PointFusion算法[12],结合了AVOD和F-PointNets的优势,由残差模块提取物体颜色和几何特征,由PointNets提取点云空间分布特征,算法的泛性和鲁棒性较好。类似的还有MVX-Net[13]等算法。但此类框架都比较复杂,且运行缓慢和繁琐。
本文中算法基于PointPainting[14]算法框架:每个激光雷达点被投影到经过图像语义分割网络的输出图像中,这样就将语义信息增添到点云上了。绘制好的激光雷达点就能够用在任何激光雷达检测算法上,通用性极强。利用条形池化运算模块改进语义分割DeepLab算法[15],提出DeepLabvs算法,使之对长条形目标更加敏感,从而绘制出更好的点云。再采用PointPillars[16]基线算法进行目标检测,形成PointPainting+算法。融合后的算法在远距离小目标检测精度上有较大提高。
1 检测网络框架
1.1 总体框架
本算法参考文献[14]将图像经DeepLabvs语义算法得到的语义信息投影到点云上以增强点云,再使用PointPillars算法提取点云特征,从而达到提高目标检测准确率的目的,其总体结构如图1所示。
融合算法使用点云和图像信息作为输入,检测目标并生成对应3D检测框,它包括以下3个阶段:① 基于图像的语义分割,计算逐像素分割分数;② 用语义分割分数绘制激光雷达点云;③ 利用绘制好的点云数据通过卷积神经网络进行3D目标检测。
1.2 训练数据来源及处理
数据直接使用kitti数据集,作为训练样本,利用KITTI数据集训练。KITTI Object Detection Evaluation 2012数据集包含7 481张道路交通采集图像和7 481份对应的点云文件,将数据集划分为训练集70%,测试集30%。
1.3 改进的语义分割方法
DeepLab语义分割方法是经典的语义分割算法,它在捕获高层语义信息方面已经取得了一些成效,但是这个方法仍有一些缺陷,此方法主要是堆砌了一些局部的卷积和池化操作,因此,感受野是有局限性的,对于复杂场景的解析仍有不足。
为了增大感受野,现在主要有以下几种方法:一是利用自注意力机制来建立长距离的依赖关系,但是这种改进方法需要耗费较大的内存来进行复杂的矩阵运算;二是利用全局池化或是金字塔池化来增加全局线索。但这些方法的局限在于,运用在轮廓较为方正的目标上效果较好,但对于很多长条形的目标(如行人,骑行者)效果并不佳,为改善此问题,将条形池化引入语义分割,提出改进算法DeepLabvs。
标准空间平均池化能应用于收集远程上下文信息。然而,当处理的对象不是规则的形状时,它会带有很多无关的区域,条形池化可以缓解上述问题,条形池化使用带状窗口沿水平或垂直维度执行池化。在数学上,给定二维张量x∈RH×W,在条形池化中,池化的空间范围(H,1)或(1,W)是必需的。相比于二维平均池化,条形池化对一行或一列中的所有特征值进行平均运算,所以可得水平条形池化后的输出yh∈RH为:

(1)

(2)
条形池化模块如图2所示。
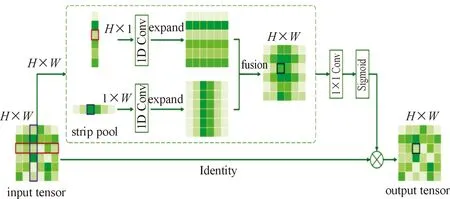
图2 条形池化模块示意图
令x∈RC×H×W为输入张量,其中C表示通道数。首先将x送入2个平行路径,每个路径包含一个水平或垂直条形池化层,然后是一个内核大小为3的一维卷积层,用于调制当前位置与其相邻像素特征。再令yh∈RC×H、yv∈RC×W,为了获得包含更有用的全局先验的输出z∈RC×H×W,首先将yh和yv组合到一起产生y∈RC×H×W,然后有:
(3)
输出z可用如下公式计算:
z=Scale(x,σ(f(y)))
(4)
式中:Scale( )指逐元素乘法;σ是Sigmoid函数;f是1×1卷积。
改进后的DeepLabvs算法结构如图3所示,整个网络模型分为编码器和解码器2个部分,编码器部分通过多次卷积生成感受野大小不同的特征图,再对特征图进行空洞卷积和条形池化操作;金字塔结构的特征图会分别输入解码器部分进行张量拼接和上采样。损失函数采用交叉熵损失,最终输出语义分割结果。

图3 DeepLabvs算法结构框图
DeepLabvs算法能够有效地在道路交通的复杂环境中分割人、车等要素,其效果如图4所示。

图4 语义分割效果图
1.4 利用语义分割分数重绘激光雷达点云
图像语义分割网络将输入图像按像素进行分类,输出对应的像素的类别分数。用语义分割有个优点,语义分割是一项比3D目标检测更简单的任务,分割只需要按像素进行局部分类,而3D目标检测需要对目标进行定位和分类,执行语义分割的算法网络更容易训练并且执行速度上也更具优势[17]。
本算法的关键之处在于如何让语义分割结果与激光雷达点云产生关联,在进行融合之前,有必要定义几个关键参数。输入参数有:激光雷达点云L∈RN,D,N为点数,D为维度数;语义分割像素分数S∈RW,H,E,W、H为特征图的宽和高,E为类别数;齐次变换矩阵T∈R4,4;相机矩阵M∈R3,4。输出参数有:重绘后的激光雷达点云P∈RN,D+E。激光雷达点云中的每个点的维度信息分别是(x,y,z,r)或(x,y,z,r,t),这里(x,y,z)是每个激光雷达点的空间坐标位置,r是反射率,t是激光雷达点的相对时间戳。激光雷达点通过齐次变换进行转换,然后投影到图像中,转换过程是:
T=T(camera←ego)T(egotc←egot1)T(ego←lidar)
(5)
首先将激光雷达坐标变换到自车坐标;其次将t1时刻激光雷达捕获数据时的自车坐标变换到tc时刻可见光相机捕获数据时的自车坐标;最后将自车坐标再变换到相机坐标,相机矩阵将点投影到图像中。语义分割网络的输出是每个像素点的E类分数,对于本算法来说E=4(汽车、行人、骑行者、背景)。一旦将图像投影到激光雷达点云中,相关像素的分割分数也将附加到激光雷达点云上。这样使数据有更多维度的信息,将有利于网络提高检测的精度。
1.5 3D目标检测
在上节得到处理后的带有分割分数的点云数据后,再基于点云进行目标检测。PointPillars算法在文献[7]基础上,将体素方块改为长方体柱,使得点云可以运用于二维卷积,大大提高了模型运行速度,基于点云的卷积神经网络算法有了实时检测的可能。经编码处理后的点云数据可以被卷积神经网络处理,从而将深度学习方法用于点云目标检测之中,其总体结构如图5所示。
图5 基于点云的目标检测总体结构框图
1.5.1点云编码框架
点云编码框架如图6所示。
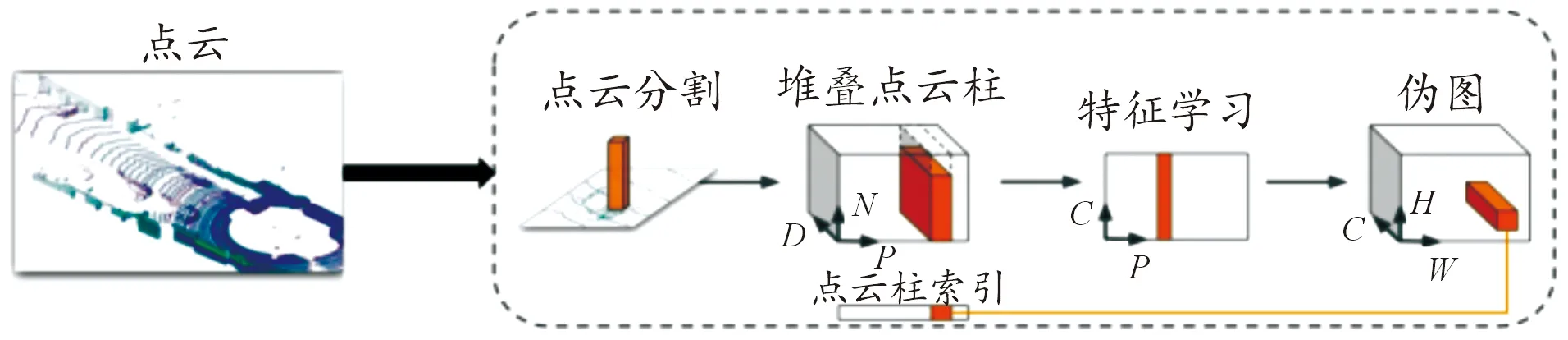
图6 点云编码框架示意图
实验采用Velodyne VLP-16激光雷达的最远感应距离100 m,编码点云的取值范围是:横向X轴正、负半轴各39.68 m,纵向Y轴正半轴69.12 m,竖向以雷达中心为Z轴原点,向上取1 m,向下取2 m。要对点云进行编码,首先在点云X-Y平面中划分一个个固定大小的格子(如图7所示),每个格子的边长是0.16 m,格子沿Z轴纵向延伸就成了点云柱,每个点云柱中包含若干个点。
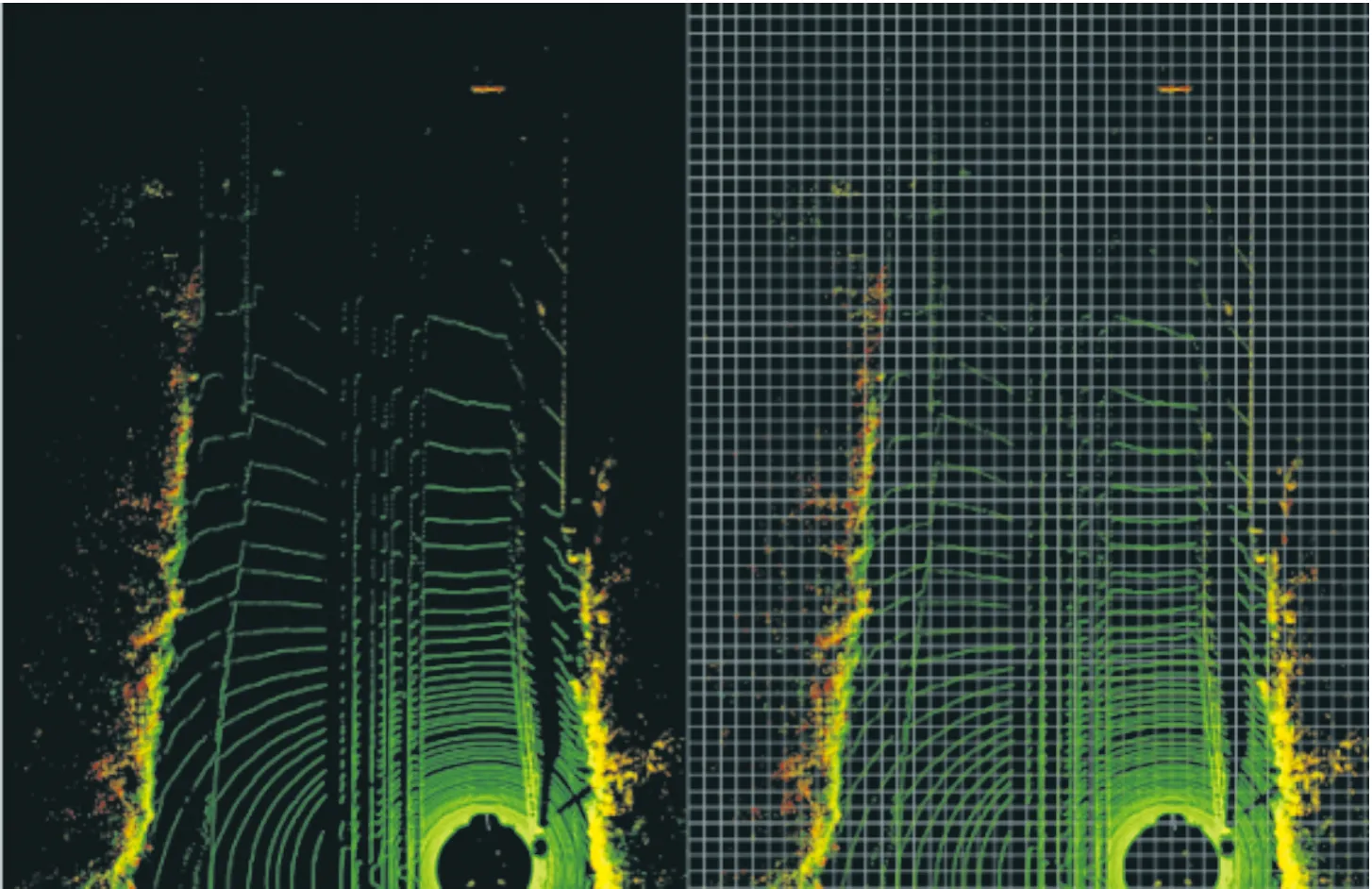
图7 点云柱格子划分示意图
点云中每个激光点有8个维度(D)的信息:(x,y,z,r,s0,s1,s2,s3),(x,y,z)表示点的3维坐标,r表示激光点照射到物体表面的反射强度。s0,s1,s2,s3分别表示为4个类别(汽车、行人、骑行者、背景)的语义分数。再将点云的信息维度扩充至13维:(x,y,z,r,xc,yc,zc,xp,yp,s0,s1,s2,s3),(xc,yc,zc)表示当前点相对于点云柱内所有点平均值的偏差,(xp,yp)表示当前点相对于点云柱中心的距离,有关偏差可由以下公式计算。
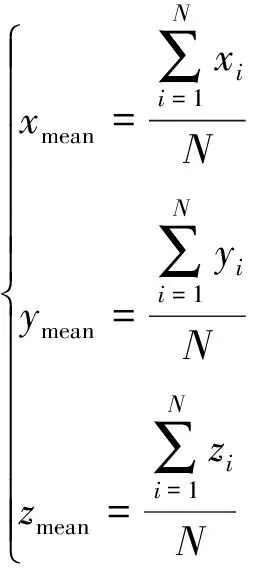
(6)
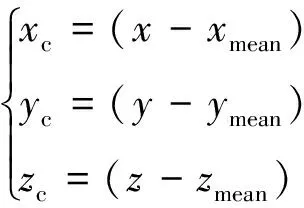
(7)
式中:N表示点云柱内点的数量,最大值设为100,不足100的点云柱补0,超过100的点云柱随机采样100个点。再设P为当前帧点云X-Y平面所能划分的点云柱数,即将点云信息从(x,y,z,r,s0,s1,s2,s3)变为了(D,P,N)形式的张量,此时D=13;然后通过全连接运算将D升至64维,再经过最大池化,将每个点云柱内的点数压缩成1,最大池化只取具有代表性的点,点云数据变为(C,P)形式的张量,C为通道数。之后将所有点云柱尺寸相加得到当前帧点云数据的总尺寸(H,W),经上述变换之后,每个H×W大小的空间内存放着一帧内所有点云柱的某一个特征维度的数据,总共有64个特征维度,因此点云数据形式变为(C,H,W),至此,点云数据被编码为可直接输入卷积神经网络的张量。
1.5.2主干网络
主干网络采用与文献[5]类似的结构,如图8所示。
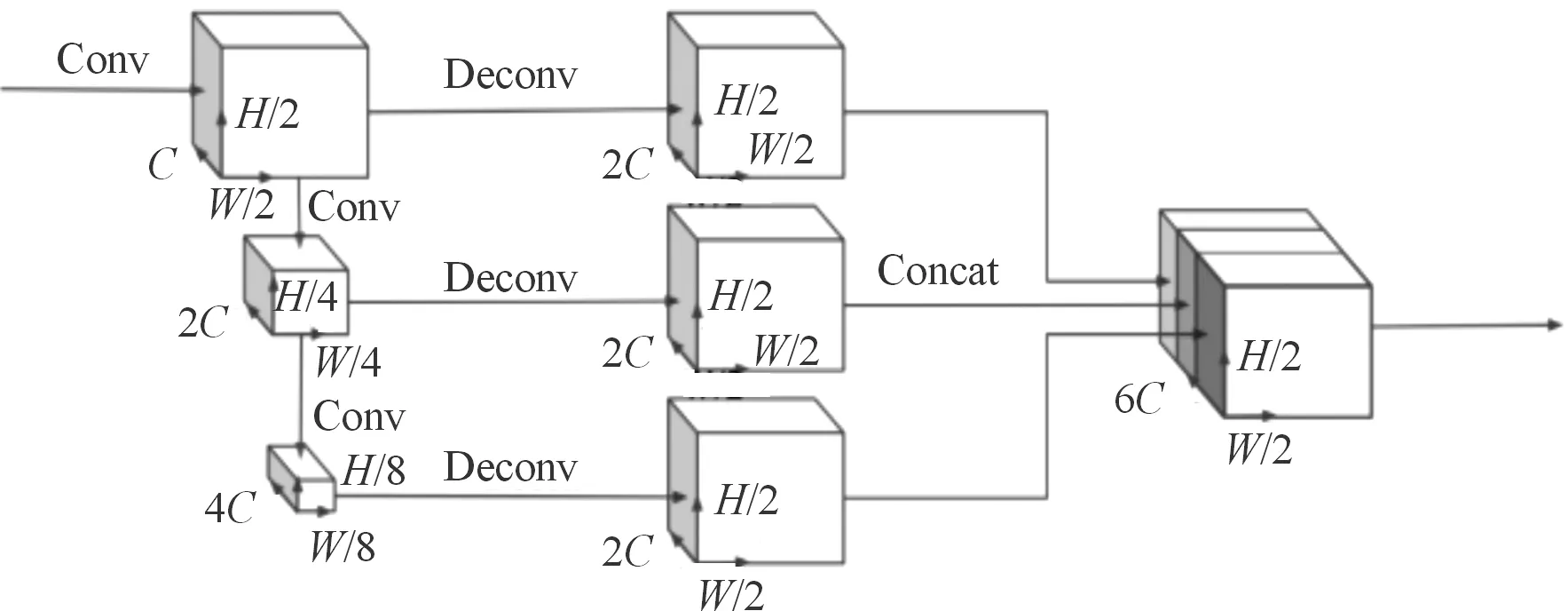
图8 主干网络结构示意图
1.5.3检测头
使用SSD网络作为整个算法模型的检测头,检测头共输出3种数据:分类检测、检测框回归、方向预测。分类检测每个区域有6个anchors,每个anchor的类别概率是一个3维度的数据,共有18维;检测框回归的每个检测框都具有7个维度的值,分别为(x,y,z,w,l,h,θ),(x,y,z)为检测框中心坐标,(w,l,h)为检测框宽、长、高,θ为检测框朝向角;方向预测使用Softmax函数预测离散的旋转角(朝向)类别。ground truth和 anchor之间的定位回归残差定义为

(8)
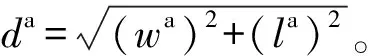
损失函数参考文献[7],检测框定位回归损失函数采用SmoothL1函数,其可以有效防止梯度爆炸。
(9)
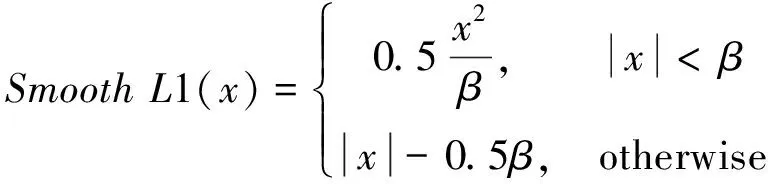
(10)
式中:Δb为定位回归残差。式(10)中:β为系数,通常取1。分类损失采用在交叉熵损失函数基础上改进的focal损失函数,能够降低负样本的权重。
Lcls=-αa(1-pa)γlogpa
(11)
式中:pa为anchor的类别概率;α和γ为常系数,分别取0.25和2。因为定位损失无法区分检测框完全正向和完全逆向,因此使用交叉熵损失Ldir预测检测框的方向,总损失函数为
(12)
式中:Npos为真阳性anchor的数量;β为系数,βloc取2,βcls取1,βdir取0.2。
为了优化损失函数,使用初始学习率为2×10-4的Adam优化器,每15个epochs将学习率衰减0.8倍,并训练30个epochs。
2 平台搭建与试验
2.1 激光雷达和摄像头联合标定
由于激光雷达和可见光相机安装位置不同,所采集数据的中心坐标也不同,为使二者能够统一融合处理,需要对激光雷达和可见光相机进行联合标定。实验使用Autoware软件中的标定工具Calibration Toolkit进行联合标定。
在ROS中分别启动激光雷达和可见光相机,将棋盘格标定板置于传感器前方,并变换方位与角度,采集好雷达和相机标定用数据。打开Calibration Toolkit标定工具,界面如图9所示,选定与棋盘格靶标对应的点云,选定若干组后进行标定计算得到相机内参,畸变参数,相机到雷达外参。

图9 Calibration Toolkit联合标定界面
2.2 实验平台搭建
以一辆中华V3轿车进行改装作为实验平台,如图10所示。采用Velodyne VLP-16作为激光雷达传感器,视觉传感器采用维视无人驾驶MV-EM130C工业相机。

图10 实验汽车实物图
计算机硬件配置为:CPU Intel Xeon E5-2678 v3,GPU NVIDIA GeForce RTX 2080 Ti,RAM 62 GB。模型部署计算机硬件配置为:CPU Intel i5 8300H,GPU NVIDIA GeForce GTX 1060,RAM 16 GB。计算机需要搭载的软件及其版本如表1所示。
表1 计算机软件版本
3 实验结果分析
3.1 评价指标
机器对目标的预测判断有表2所示4种情况:
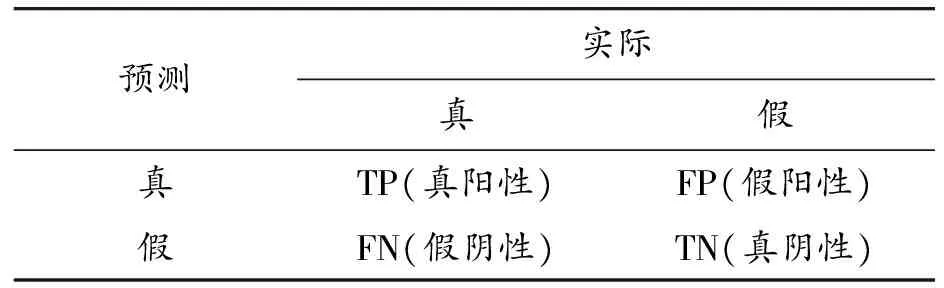
表2 预测结果分类
精确率(Precision)是衡量机器识别真阳性样本准确程度的指标,其计算公式为:
(13)
召回率(Recall)衡量机器对目标检测的全面程度,反应样本中有效目标被检测出来的概率,其计算公式为:
(14)
单一的精确率无法反映漏检的情况,单一查全率无法反映误检的情况。综合考虑模型的准确性和全面性,故本算法以AP(Average Precision)值(平均精度)来综合衡量算法性能,具体为:以Recall为横轴,Precision为纵轴绘出曲线,对曲线积分即得到AP值。其值越大,代表算法性能越好。
3.2 定性分析
用上节所示实验平台在学校内采集道路数据样本对算法进行验证,效果如图所示。由图11、12可见,本算法能够在同一帧数据中识别汽车、行人等多个目标,并在点云中用3D检测框标识出目标的位置和基本朝向。

图12 实验测试结果
3.3 定量分析
在KITTI数据集对本融合算法进训练,并对结果进行评估,AP(平均精度)为评价指标,值越大越好。其结果对比如表3所示。
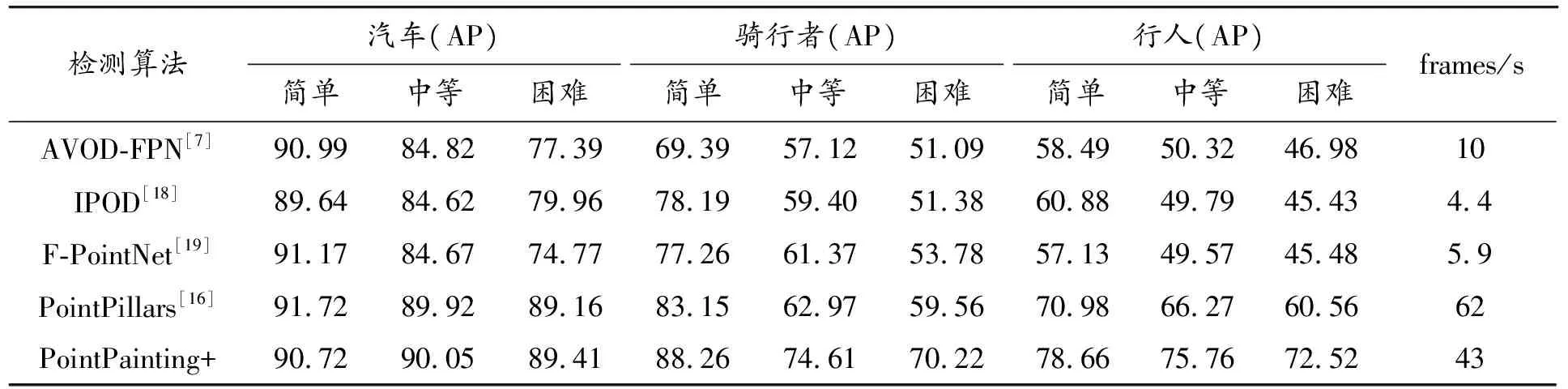
表3 各算法在KITTI测试数据集AP的性能对比 %
相比于仅依赖点云信息的PointPillars基线算法,本融合算法在简单汽车样本检测方面并无优势,但在小目标样本如(骑行者、行人)检测时优势较大。骑行者检测平均性能提高了9.14%,尤其在困难骑行者样本中领先幅度高达10.66%。行人检测方面,平均性能提高了9.71%。相对AVOD-FPN经典融合算法,本算法在速度上也有较好的表现,检测速度达到43 fps,能满足实时性要求。而相对于依赖图像的算法对光线十分敏感,融合算法的环境适应性和鲁棒性更强。
4 结论
1) 在原语义分割算法中加入条形池化模块,提高了算法对行人等细长型目标的敏感度。
2) 对比使用纯点云的检测方法,本算法对行人、骑行者等远距离小目标有更好的检测精度。
3) 交通参与者这类目标检测研究,对于无人驾驶汽车而言有重要意义。
4) 本文中的实验环境均为良好光照条件,如何提升恶劣天气下的准确检测率是进一步研究的方向。
