基于人工智能的中医经验传承辅助诊疗
2023-11-15唐广发卢子忱许金森
李 颖,唐广发,陈 立,卢子忱,许金森
[1.东莞中科云计算研究院,广东 东莞 523000;2.脸萌技术(深圳)有限公司,广东 深圳 518000;3.福建省中医药科学院,福建 福州 350000]
0 引言
中医学是我国历代传承并创新发展的原创性医学理论体系。中医的诊疗过程主要包括四诊、辨证分析、制定和调整治疗方案、巩固疗效4 个步骤。医生先根据望诊、闻诊、问诊、切诊所得的信息,结合患者的具体情况进行辨证分析,确定疾病的病因、病机、病位等。医生根据辨证分析的结果,制定针对性的治疗方案,包括药物治疗、针灸治疗、推拿治疗、拔火罐治疗、正骨治疗等。辨证论治这种模糊的、经验型的思辨模式,造成中医学的传承难以批量、标准化地进行。因此,需要将传统的中医理论和方法与现代科学技术相结合。
人工智能是一种研究、开发用于模拟、延伸和扩展人的智能的一门新的技术科学。人工智能包括自然语言处理、图像识别与计算机视觉等多种技术,应用范围非常广泛。人工智能技术在医学影像诊断、疾病监测和药物研发取得了较大进展,提高了医疗水平和效率[1-2]。在中医药领域[3],人工智能的应用主要体现在数据挖掘与分析、智能诊疗和医学影像智能识别等方面。表示学习作为一种新兴的人工智能方法,其目的是从原始数据中学习数据的表示方式,以便于后续的分类、聚类、回归等任务的完成[4]。表示学习在从海量数据中提取有用信息、促进中医证候的量化与标准化方面具有巨大潜力。
中医证候学是中医学的重要组成部分,它涉及对疾病症状的观察、分析和诊断。为了使中医的诊断和治疗更加科学、客观、准确,证候的量化是重要内容。郑淑美等[5]提出条件概率指数转化法,通过统计已知某病(或证)存在,某症状出现的条件概率,计算该症状的量化值。梁茂新等[6]提出主观离散赋分法,通过各症状按显著程度记分的总和,计算该病症的总体症状水平积分值。余江维等[7]通过TFIDF 相对熵函数进行症状信息的量化。
中医证候的表示学习涉及利用无监督学习或监督学习等技术,将中医证候的描述性语言转化为计算机可理解的向量表示。将表示学习应用于中医证候学,可以帮助我们从大量的中医证候数据中学习到更准确、更有效的表示方式,提高中医证候的分类和诊断精度。
本文利用人工智能技术,将中医证候的描述性语言转化为计算机可理解的向量表示,以便于进行机器学习和数据分析,提高研究的准确性和效率。
1 中医经验传承辅助诊疗系统
本文的中医经验传承辅助诊疗系统(图1)主要包括在线症状输入、症状表示、症状推荐和辅助论治4 个模块。
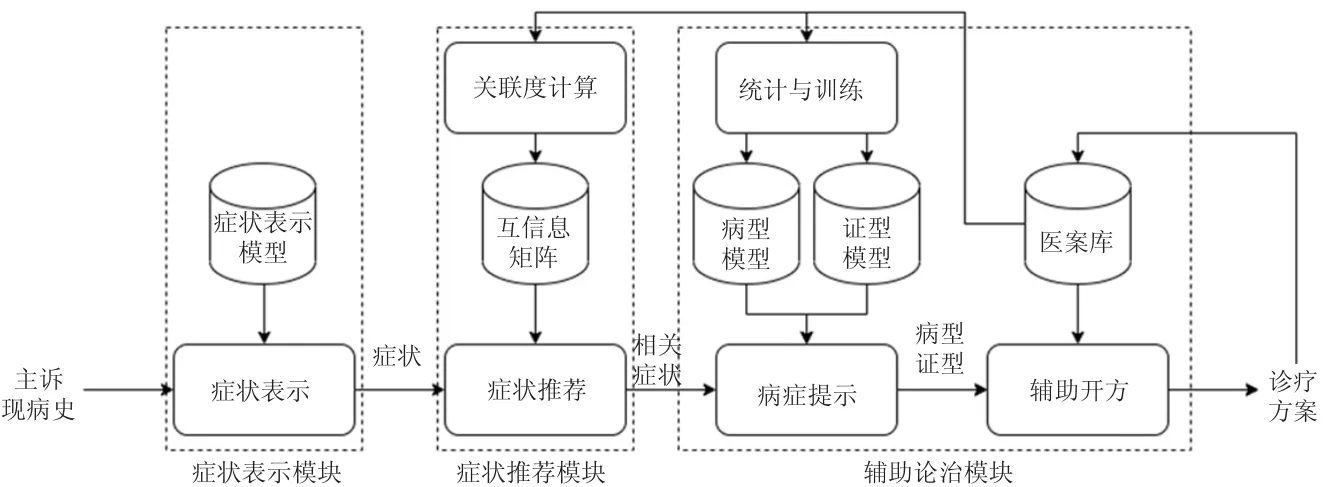
图1 基于人工智能的中医经验传承辅助诊疗系统
在线症状输入模块输入用户的当前症状;症状提取与表示模块构建症状病例数据集;问诊提示模块计算与输入症状相关联的前k 个症状;辅助论治模块输出根据推荐的病型和治疗方案。
1.1 症状表示
原始病例数据是描述患者信息的自然语言文本,而基于人工智能的中医经验传承辅助诊疗系统的数据处理需使用症状向量,因此,需要对病例数据进行症状提取与表示操作。
本文提出了一种使用高维向量表示症状作为辅助论治的输入,预测病型和治疗方案的模型。该模型将主诉、现病史中的症状文本转换为高维向量,并将这些向量作为输入,用于预测病型和治疗方案,连续词袋模型架构如图2 所示。
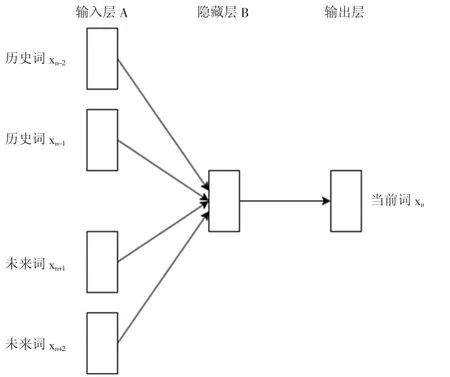
图2 连续词袋模型架构
连续词袋模型的架构包括输入层、隐藏层和输出层。在输入层A,对于给定一个词的上下文(即窗口内的其他词),连续词袋模型会接收这些上下文词作为输入,并将它们映射到神经网络的隐藏层。在隐藏层B,上下文词会被处理成一个固定长度的向量,这个向量的长度和训练样本的数量有关。在输出层,连续词袋模型会计算出目标词的概率分布。
连续词袋模型的训练过程是基于重构语言的词袋模型假设进行的,它假设词的顺序是不重要的。在训练过程中,神经网络需要重新构造输入的上下文词,以便学习上下文词和目标词之间的关系。具体来说,连续词袋模型首先会将每个词映射到一个固定长度的向量,然后将这些向量输入神经网络中。神经网络会根据这些向量的值来预测目标词的概率分布。本文建立了将4个未来词和4 个历史词的向量作为输入的分类器,训练标准是正确预测当前词。
在训练好连续词袋模型后,可以使用该模型获取每个症状词语的向量表示,即词向量。这些词向量构成了高维向量空间中的一组向量。对于主诉、现病史中的症状文本,可以将其中的每个症状词语替换为其对应的词向量,从而将该文本转换为高维向量的症状文本表示。
1.2 症状推荐
通过症状关联度计算得到症状病例数据集的互信息矩阵后,新的在线输入症状可利用该互信息矩阵计算当前症状与数据集中其他症状的互信息值,最后选取前k 个互信息值高的症状作为当前症状的推荐症状。
1.3 辅助论治
根据症状提取和表示的结果,从诊疗模型中得到初步的诊断结果和建议,供医生参考。同时,模块还可以根据医案库的历史病例数据,为医生提供更加全面和客观的诊断依据和治疗方案。
2 实验
2.1 实验数据
本文采用的病例数据来自某医院临床门诊病例数据共2383 条,训练集数据1906 条,测试集数据477 条。
2.2 实验结果与分析
首先,使用预处理过的主诉、现病史中的症状文本训练词向量模型。其次,训练好词向量模型后,用它来将主诉、现病史中的症状文本转换为向量。最后,将转换后的症状文本向量用于后续分类任务,对主诉、现病史进行分类,预测病型。其中,在计算距离时采用了余弦相似度,准确率如表1 所示。

表1 症状提取病型预测准确率
由表1 可知,随着向量维度的增加,症状表示病型预测的准确率呈现出一种波动上升的趋势。当向量维度为150 时,准确率最高,达到了87%。然而,当向量维度增加到200 时,准确率下降到了85%。这表明在症状表示病型预测任务中,过高的向量维度并不一定能带来准确率的持续提升。症状表示病型预测的准确率均优于或与症状提取病型预测相同,这表明使用症状表示的方法进行分类,预测病型更为有效。
使用症状表示的方法按疾病分类病型预测准确率如表2 所示。

表2 疾病分类病型预测准确率
以上实验结果反映的是模型在预测给定疾病类型的病例时的准确性。在测试病例数较多的疾病中,郁证、癌、咳嗽、消渴、痹症的准确率为80%以上,表现出良好的性能。相比之下,一些疾病的准确率较低,如不寐、心悸、眩晕、少阳病、瘿瘤,需要在未来的研究中进一步改进和优化。胸痹、乳癖、头痛、口疮、月经病、心悸的测试病例数较少(少于10 例),可能存在数据偏倚或统计误差,需要更多的数据来验证其准确率。
3 结论
本文主要研究了从临床病例数据的症状提取和表示到辅助论治的病型预测,实验结果表明本文方法可有效的对当前症状进行提取和表示,可在医生论治过程中给予辅助,减轻年轻医生辩证论治或学生在学习过程中经验不足导致的困难。后续工作中可不断补充完善病例数据库资源,进一步提高算法的稳定性和可靠性。
