基于改进优先经验回放的SAC算法路径规划
2023-11-13崔立志董文娟
崔立志, 钟 航*, 董文娟
1. 河南理工大学电气工程与自动化学院, 焦作 454003
2. 河南省智能装备直驱技术与控制国际联合实验室, 焦作 454003
3. 国网新疆电力有限公司电力科学研究院, 乌鲁木齐 830011
0 引 言
为智能体规划一条从起点到目标点的无碰撞路径是路径规划领域的一大核心问题.传统路径规划方法包括模型预测控制[1-2](model predictive control,MPC)、人工势场法[3]和A*算法[4]等,这些方法都是基于地图的路径规划方法,在局部路径规划中的效率较高,广泛应用于各种已知环境下的路径规划任务中.但是,这些方法都要依赖于一些先进的建图技术(如SLAM[5]等)对智能体所在环境建立高精度地图[6],并且在面对不同的环境时,需要重新建立高精度地图,这会大大降低路径规划效率.
近年来,在线异策略深度强化学习算法[7]在游戏AI、机器人路径规划和无人机导航等领域取得了巨大成功,引起了研究者的广泛关注.在线异策略深度强化学习算法是利用深度神经网络[8]强大的特征表示[9]能力对智能体的状态动作对的价值进行拟合,赋予智能体自监督学习能力,自主与环境交互,并通过环境反馈的奖励不断修正其策略.相比于传统的路径规划算法,在线异策略深度强化学习算法突出优势有:1)通过智能体与环境交互,不断学习动态根性模型参数,具有一定的鲁棒性;2)在短路径规划中,能够为智能体实时规划路径;3)无需人工参与调整参数,只需要根据距离等角度等信息提前设定奖励函数即可实现智能体路径规划.
BAYERLEIN[10]等引入一种基于双深度Q网络(double deep Q-network,DDQN) 的方法,在飞行时间和路径规划约束下优化UAV(unmanned aerial vehicle)路径,实现在物联网数据采集任务中控制无人机的作用.DING[11]等利用深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法模型作为无人机在3D环境下的轨迹运动规划算法,并以系统能量效率最大化及通信服务最优分配为目标来解决路径最优规划问题.LI[12]等将人工势场与视线相结合,提出一种改进的深度确定性策略梯度算法(deep deterministic policy gradient,DDPG),实现了UAV在障碍物环境下对地面目标的跟踪.沈凡凡[13]等针对目前矿井传感器所收集数据的传输效率差、实时性低和丢包率高等问题,将强化学习方法引入到无人机巡航路径规划领域,利用无人机来提高矿井中数据的接收效率.吴健发[14]等为解决多重约束条件下的航天器规避机动过程中初值敏感、计算耗时等问题,提出一种基于双延迟深度确定性策略梯度(twin delayed deep deterministic policy gradient,TD3)的动作规划方法.该方法利用TD3训练得到的策略网络在线生成满足多种约束条件的规避机动动作,提高航天器姿态指向变化较小时规避障碍物的时效性.
上述在线异策略深度强化学习算法框架均采用经验回放[15]的方式优化算法模型参数.经验回放方法能够较大程度提高模型学习效率和样本利用率,其思想是将不同行为策略产生的样本数据[16](s,a,s′,r)储存在经验池中,在模型开始学习时,从经验池中随机均匀采样一批样本用于模型学习优化策略.MNIH[17-18]等首次将经验回放的方法用于DQN(deep Q-leaning network)算法.SCHAUL[19]等为进一步提高模型学习效率,在经验回放的基础上,提出优先经验回放方法(prioritized experience replay,PER).在从经验池中选择经验样本时,先通过TD误差衡量经验池中每个样本的优先度,随后再从经验池中贪婪地批量抽取优先度较大的经验样本给模型学习优化.优先经验回放能够提高模型学习收敛速度,改善模型的收敛性能,实现模型快速学习优化目标.但该方法在连续控制复杂任务中的表现差强人意:1)在模型学习过程中,评估网络对部分经验样本的Q值存在高估,导致该部分样本优先度大于其实际值.采用优先经验回放方法将提高该部分经验样本在模型后续学习过程中的学习频率,并给后续模型参数优化带来噪音.2)策略网络参数是在评估网络指导下优化.评估网络利用TD误差较大的经验样本优化自身参数,TD误差的大小代表评估网络对样本的不确定性[20]程度,TD误差越大,评估网络对该样本的期望奖励不确定性越高,评估网络Q值波动也越大,这会降低策略网络参数优化效率.为此,FUJIMOTO[21]等提出损失调整优先化(loss adjusted prioritized,LAP) 经验回放方法,其思想是利用任何与非均匀概率相结合的损失函数都可以转换为具有相同预期梯度的新均匀采样损失函数对应物这一原理,校正PER方法中损失函数的等效统一采样损失函数,以提高模型的学习效率.基于损失调整优化的优先经验回放方法虽然能够提高模型的学习效率,但在部分连续控制任务中,该方法容易使得模型陷入局部极小情况,并且模型鲁棒性较差.
为提高优先经验回放在连续控制任务中的性能,本文提出一种改进优先经验回放方法:1)利用样本状态优先度与TD误差构建样本混合优先度,改进经验样本优先度的衡量标准,降低部分经验样本的优先度偏离其实际值的优先度,从而提高模型学习效率;2)采用样本混合优先度的离散度计算经验样本的采样概率,在保证高误差样本抽样概率的同时提高低误差样本的采样概率,从而解决由于评估网络过高估计导致策略网络参数优化过程中梯度偏离其实际梯度[22]的问题.实验结果表明,基于改进优先经验回放方法能够有效提高智能体的学习效率.
1 系统模型设计
为提高连续控制任务下在线异策略深度强化模型的路径规划效率,提出一种改进优先经验回放方法,并将该方法应用于柔性动作评价算法,该算法结构框图如图1所示.
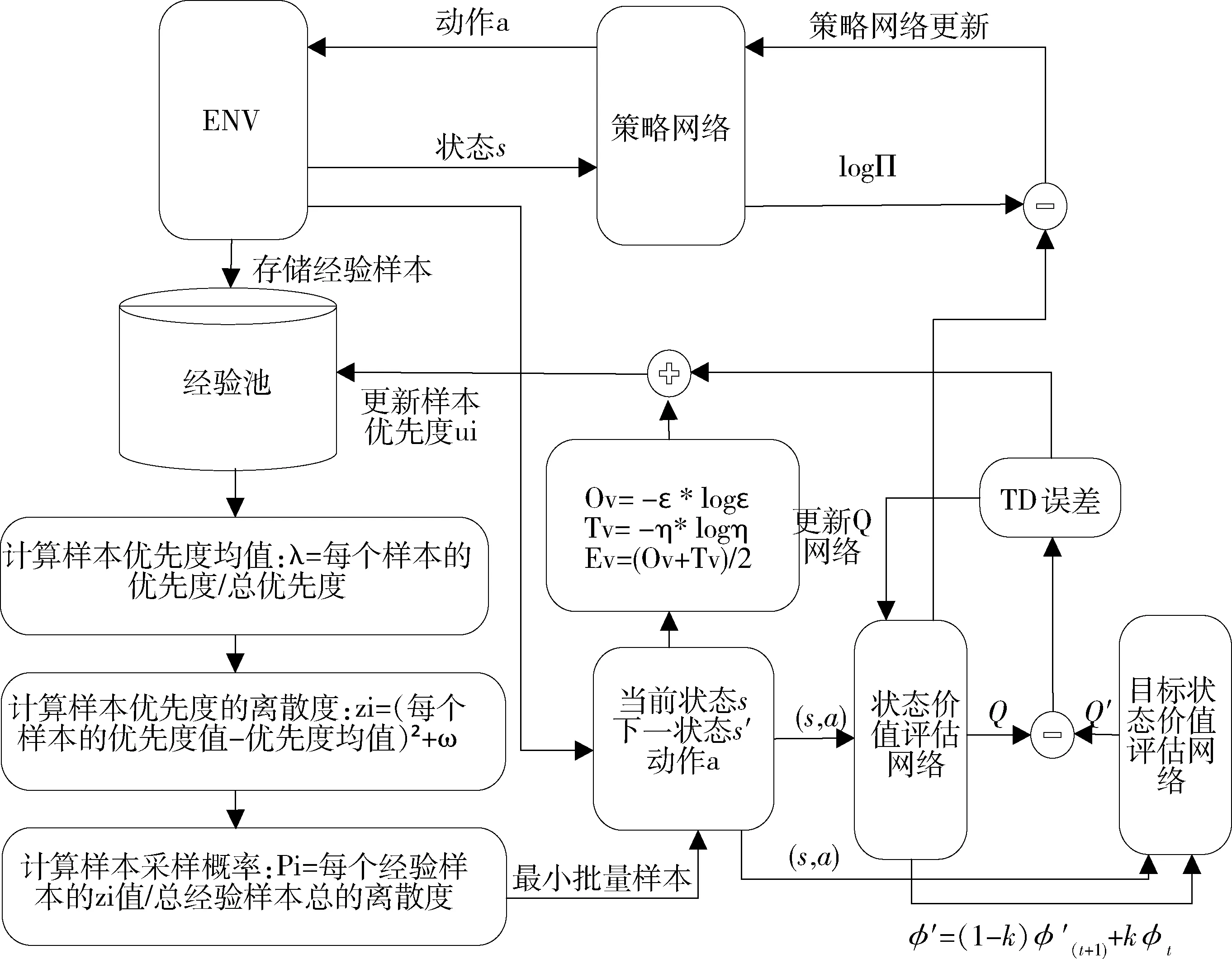
图1 改进优先经验回放SAC算法框架图
1.1 TD误差与贪婪优先经验回放
优先经验回放方法是当前深度强化学习算法性能提升的重要组成部分,其思想是利用TD误差衡量样本优先度,随后批量抽取优先度较大的经验样本.相比于均匀采样方法,优先经验回放方法能够提高模型快速学习优化的能力.
强化学习可以由一个五元组(S,A,R,P,γ)构成的马尔可夫决策过程表示.其中,S表示智能体的状态空间,A表示智能体的动作空间,确定性奖励函数R,状态转移函数P、折扣因子γ∈(0,1).策略π的性能是在动作价值函数(Qπ函数)下进行评估
(1)
式中,Qπ(s,a)表示在状态s中执行动作a后遵循策略π时预期折扣奖励总和.
动作价值函数由贝尔曼方程[23]确定
Qπ(s,a)=Er,s′~P,a′~π[r+γQπ(s′,a′)]
(2)
式中,a′表示在策略π观察到下一个状态s′时选取的下一个动作.
在深度强化学习中,动作价值函数由参数为θ的神经网络Qθ近似表示.对任意一个给定经验样本(s,a,r,s′),通过最小化从当前的状态动作对(s,a)到下一状态动作对(s′,a′)的价值估计时序误差δθ对评估网络进行优化
q(s,a,r,s′)=r+γQθ′(s′,a′)
(3)
δθ(s,a,r,s′)=q(s,a,r,s′)-Qθ(s,a,r,s′)
(4)
当优先经验回放方法与深度强化学习算法相结合时,TD误差(δθ)成为衡量样本优先度的标准[19],样本TD误差越大,样本优先度越高,该样本在后续学习过程中的抽样概率越大.
在模型学习过程中,评估网络可能会对部分经验样本的Q值评估出现过高估计,部分研究表明,评估网络估计的时序差分误差(TD误差)与在最优函数下计算的绝对估计误差在该样本或后续样本中是正相关[22].即评估网络的过高估计会造成部分经验样本TD误差的高估,从而导致经验样本优先度高于其实际值.优先经验回放方法是不断对高误差经验样本进行采样,模型不可避免地会利用过高估计的经验样本学习优化参数,会给模型参数优化带来噪音[24],降低模型的优化效率.
TD误差代表了评估网络Qθ估计损失,同时表明评估网络在自举预期未来奖励方面对经验池中样本的不确定性和知识.TD误差越大,表明评估网络对经验样本知识了解较少、不确定性高.研究表明,若评估网络利用不确定性较大的经验样本学习优化时,评估网络无法指导优化策略网络快速高效优化网络参数:在当前或后续学习优化过程中,在评估网络下计算的策略梯度可能会偏离在最优估计函数Qπ下计算的实际梯度.
1.2 样本混合优先度设计
改进优先经验回放方法原理首先是利用样本状态优先度和TD误差构建样本混合优先度,降低评估网络Q值高估对模型后续学习优化的影响,利用样本的状态优先度筛选出有利于模型快速学习优化的经验样本,从而提高模型的学习效率.
在在线异策略深度强化学习模型的经验池中,每个经验样本均对应一个TD误差,TD误差是由评估网络对该样本的状态动作以及后续状态进行评估得到.在模型优化过程中,评估网络对部分经验样本的状态动作价值可能存在过高估计,TD误差与在最优函数下计算的绝对估计误差是正相关的,这会导致部分经验样本的TD误差高于其实际值,进而导致样本优先度高于其实际值.而优先经验回放方法是贪婪地对高误差经验样本进行采样,这会提高TD误差高于其实际值的经验样本的采样次数,并对模型后续学习产生噪声影响,不利于模型学习优化.
本文通过融合样本状态优先度与TD误差的方式对样本优先度进行重塑,样本混合优先度越高,在模型后续学习过程中的抽样概率越大.该方法能筛选出有利于模型优化的样本并提高其在模型后续学习过程中的利用率:1)当样本Q值无高估并且TD误差接近时,状态优先度越大的样本,其混合优先度越高,提高接近目标点和障碍物的经验样本的利用率,从而加快模型学习效率;2)当样本Q值存在高估时,利用经验样本的状态优先度降低部分由于Q值高估导致的TD误差高于其实际误差的经验样本的优先度,从而降低其在后续学习过程中的采样概率,降低评估网络的过高估计对模型后续学习的影响.
样本的状态优先度是由样本中s、s′状态下的碰撞优先度和目标优先度构成.碰撞优先度和目标优先度分别表示智能体与障碍物、目标位置的接近程度.智能体与障碍物、目标位置越接近,样本状态优先度越大,越有利于模型学习优化,样本学习价值越高.
碰撞优先度是指在某一状态下,智能体与障碍物的最小距离与最大距离的比值与其对数的乘积的相反数.样本碰撞优先度是指智能体在s、s′状态下的碰撞优先度差值的绝对值
(5)
lv=-ε×lgε
(6)
(7)

目标优先度是指在某一状态下,智能体离目标点的距离与初始距离比值与其对数的乘积的相反数.样本目标优先度是指智能体在s、s'状态下的目标优先度差值的绝对值
(8)
(9)
dv=-η×lgη
(10)
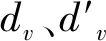
为避免样本状态优先度过大造成样本多样性丧失,利用clip函数对hv、gv进行截断处理.另外,为了平衡碰撞优先度与目标优先度,对2者归一化处理得到样本状态优先度
ev=(gv+hv)/2
(11)
由此,可得出样本混合优先度
u=(δ+ev)2
(12)
式中,u表示样本的混合优先度,δ表示TD误差.
1.3 离散抽样设计
本文设计一种利用样本混合优先度的离散度计算样本抽样概率的方法.优先经验回放中贪婪地对高误差样本进行抽样,导致评估网络Qθ不断利用高误差经验样本优化学习,研究表明评估网络无法通过学习高误差经验样本指导策略网络优化.因此,在从经验池中采样经验样本的过程中,应提高低误差经验样本的采样概率,以尽可能多地采样低误差样本训练评估网络和策略网络,利用低误差经验样本优化评估网络,降低评估网络的不确定性,进而提高引导策略网络优化的能力.
在模型训练学习过程中,经验池中的经验样本处于动态更新状态,经验池中经验样本总优先度跟随经验样本的更新而波动,从而导致经验样本优先度的离散度动态调整,利用经验样本优先度的离散度计算样本采样概率,有利于提高模型训练样本的多样性,并且在提高低误差经验样本采样概率的同时保证高误差优先度高的样本的采样概率.
利用样本混合优先度的离散度计算样本抽样概率
zi=(ui-λ)2+ω
(13)
(14)
式(13)中,zi表示第i个样本的离散度,λ表示经验池中所有样本混合优先度的均值,ω表示一个较小的正常数,以保证经验池中的每个样本的优先度不为0.式(14)中,pi表示第i个样本的采样概率,ζ表示优先度的调节因子.当ζ=0时,优先经验回放退化成随机均匀抽样;当0<ζ<1时,采用部分优先度抽样;当ζ=1时,采用全优先度抽样.本文采用全优先度抽样计算样本抽样概率.
2 仿真环境、奖励函数设计
本章基于ROS Gazebo平台设计了多障碍物类型、部分障碍物位置在学习过程开始时随机生成并且可相互叠加的仿真环境,以尽可能地模拟出狭窄、凹凸等各类型仿真环境.此外,利用智能体的动作空间给出障碍物陷阱的定义,并且为了激励智能体跳出障碍物陷阱,设计了动态步数奖励函数.
2.1 仿真环境设计
为提高模型泛化能力,本文设计了由固定位置的墙体、位置在学习过程开始时随机初始化且可以相互叠加的正方体以及圆柱体作为障碍物的仿真环境.
在线异策略深度强化学习算法为智能体规划路径时,仿真环境大多是以单一类型静态障碍物或者单一类型动态障碍物构成,这种环境下训练得到的模型往往会出现过拟合现象.为了提高模型复杂环境下的路径规划能力,本文设计了具有较强随机性的仿真环境(如表1所示),以提高模型训练环境的多样性和模型的泛化能力.
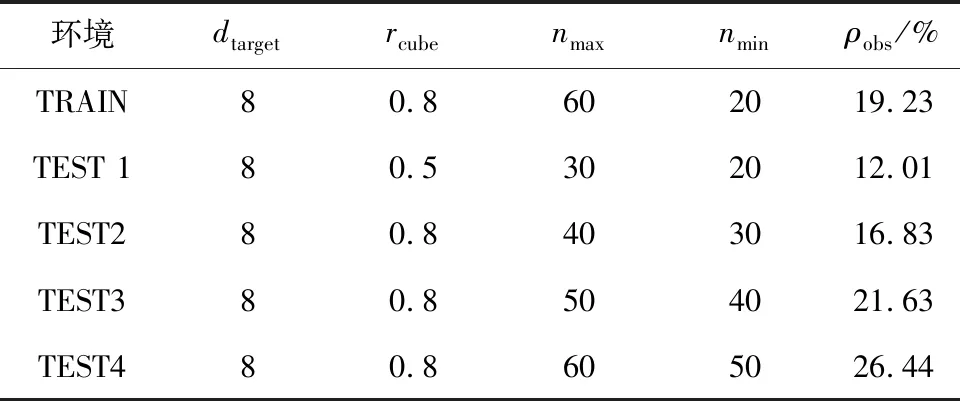
表1 仿真环境障碍物密度
表1中,dtarget表示智能体与目标点的初始距离;rcube表示每次学习(测试)正方体障碍物出现的概率;nmax、nmin分别表示环境中圆柱体障碍物出现的最大值与最小值;ρobs表示环境中的障碍物密度,它是圆柱体障碍物nmax、nmin的中位数与仿真环境面积的比值.
2.2 状态-动作空间设计
本文中,智能体的状态空间是由障碍物信息obst、智能体与目标点之间的距离goalt、智能体在世界坐标系中的前向速度vx与偏航率yrate构成的一个40维的向量.obst是由跟随智能体运动的LiDAR所探测到的36个智能体与障碍物的距离,其可以表示为obst=obs(l1,l2,…,li)(i=1,2,…,36), 其中,li表示第i个雷达激光探测到的障碍物与智能体的距离.goalt表示在极坐标中,智能体当前位置与目标点之间的距离和角度的矢量,表示为ο=(dtarget,ϑ).最终,模型策略网络输出智能体前向速度vx和偏航速度yrate的正态分布.
2.3 奖励函数设计
利用在线异策略深度强化学习进行移动智能体的路径规划,奖励函数的设计对模型的路径规划性能会产生较大影响.本文的奖励函数设置如下:
Reward=Rstep_p+Rcrash+Rarrive+Rangular
(15)
仿真环境中,由于仿真环境的随机性较强,智能体在学习过程中易陷入障碍物陷阱.在智能体运动到多障碍物叠加构成的凹型区域时,智能体前向速度vx=0、yrate≠0.另外,在面对墙壁等长方体障碍物时,智能体会突破危险区域与障碍物发生碰撞,智能体偏航速度yrate=0、vx≠0.因此,本文根据智能体运行过程中出现的上述2种运动情况,给出智能体陷入障碍物陷阱的定义:
1)当yrate≠0,并且vx=0时,智能体陷入障碍物陷阱;
2)当vx≠0,并且yrate=0时,智能体陷入障碍物陷阱.
以上2种智能体运动方式会大大增加模型训练时间成本,为鼓励智能体逃离障碍物陷阱,设计了如下角度奖励Rangular:
(16)
式中,abia表示s状态下智能体的偏航速度与s'状态下智能体偏航速度差值的绝对值,lmin表示s状态下雷达探测到的智能体与障碍物的最小距离.
为了弥补智能体逃离障碍物陷阱带来的步数奖励的损失,设置了动态步数惩罚奖励函数
Rstep_p=-β×step_count
(17)
(15)
式中,step_count表示s状态下,智能体从起点到当前状态所运动的总步数.
3 仿真实验设计与结果分析
为了验证基于样本混合优先度的改进优先经验回放方法在连续控制复杂任务下的性能,本文将该改进优先经验回放方法与当前2种先进的Actor-Critic算法:双延迟深度确定性策略梯度[25](twin delayed deep deterministic policy gradient,TD3)和柔性动作评价算法[17](soft actor-critic,SAC)相结合,利用PER、LAP为基准验证该方法的有效性.实验分为2个部分:第一部分从多个角度研究2种具有不同优先经验回放模块的算法模型在学习环境下的性能;第二部分利用测试环境对上述算法模型的泛化能力进行测试,并从路径规划成功率等角度对模型的泛化能力进行分析.
3.1 实验设计
本文采用Turtlebot3机器人作为仿真实验平台,该机器人的最大线速度与角速度分别为0.22 m/s、2.84 rad/s.在机器人顶部搭载有一部具有360°视野的LiDS_01激光雷达,每个雷达激光之间的夹角为10°,并且雷达的探测范围设置为0.14~3.5 m,可以给机器人提供36个机器人与其附近障碍物的距离信息.在仿真环境中,机器人的起始点固定于坐标原点,机器人方位随机生成.目标位置由固定于x轴正半轴距坐标原点8 m的球体构成.为了避免真实碰撞,设定每个障碍物的危险区域为0.2 m,以此建立障碍物碰撞缓冲区.另外,为了提高仿真环境的可行性,在机器人的起始位置和目标点区域设置了0.8m的安全范围.同时,为了避免机器人与目标发生碰撞,若机器人进入目标区域0.3 m的范围,视机器人到达目标点.
本文对所有模型超参数严格按照原始论文中论述的超参数和架构设置(如表2所示).网络学习率均设置为0.000 3,模型回合运动的最大步数设置为300步,回合迭代学习次数为4 800轮.SAC算法的温度参数α则由文献[18]所述方式实现α自动调节.此外,模型在每种测试环境下的测试轮数设置为200轮.
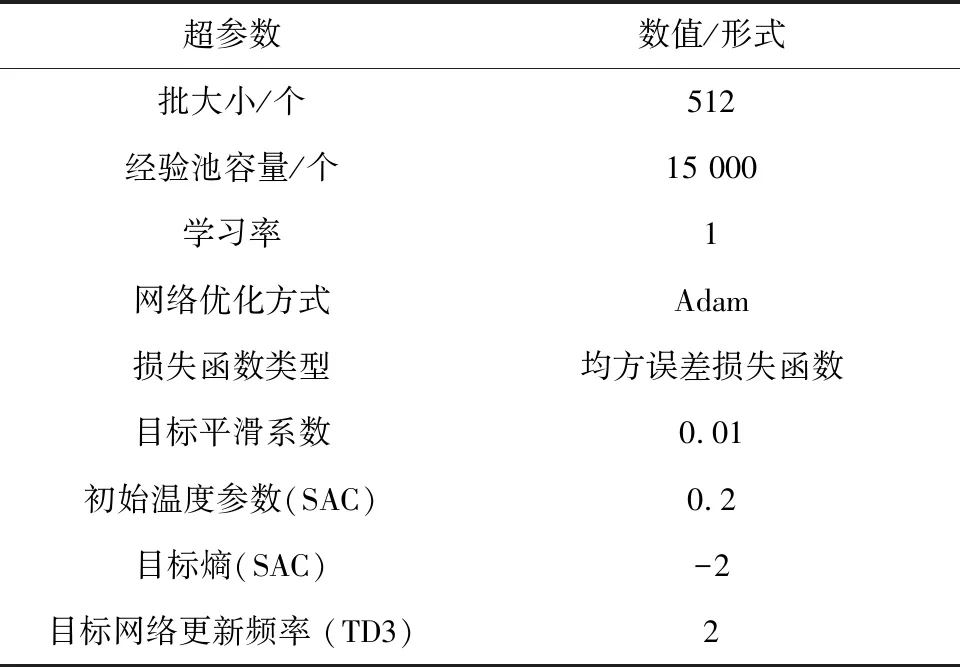
表2 模型超参数设置
3.2 实验结果分析
本文为分析模型的路径规划能力,从模型在学习环境中获得的回合奖励、步奖励、回合学习时间和陷阱率4个方面进行分析.此外,模型泛化能力是模型路径规划能力的一项重要指标,为分析模型的泛化能力,利用4种测试环境对学习后的模型进行测试,并从模型的陷阱率、成功率与碰撞率(如表3所示)3个方面进行分析.
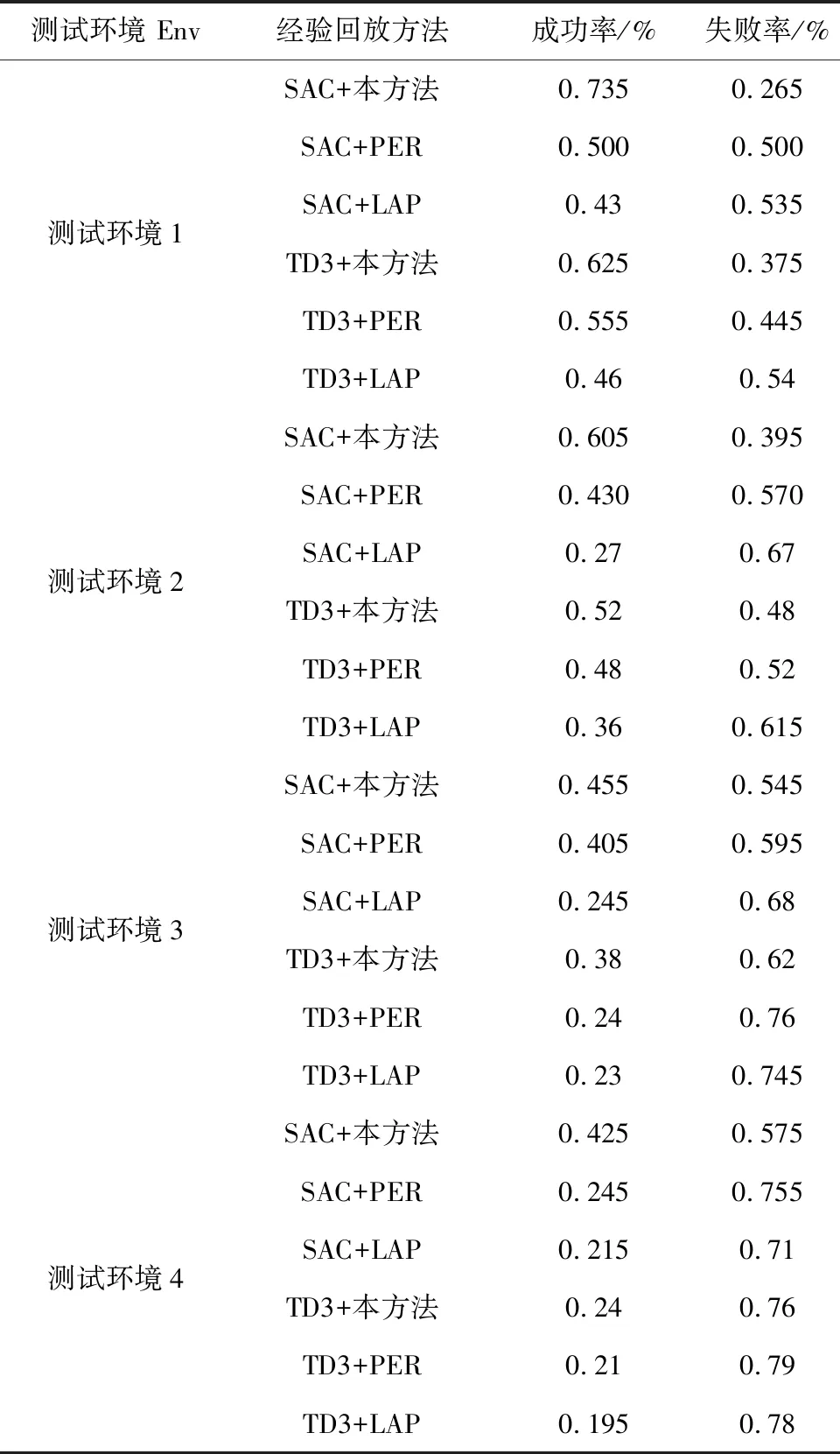
表3 测试环境下路径规划成功率与碰撞率
(1)模型回合奖励分析
在线异策略深度强化学习领域,模型学习目标的形式化体现在回合奖励.回合奖励是一个实数值信号,这个信号是模型在学习过程中的累计奖励.模型通过不断学习获得更高的回合奖励,回合奖励值越高,回合奖励收敛越快,说明模型学习能力越强.用回合奖励表征模型的学习能力的高低是在线异策略深度强化学习的一个最典型的特征.
模型在学习环境下的回合奖励如图2所示.基于改进优先经验回放的SAC算法回合奖励值在120轮迭代学习后明显高于其它对比算法,并且其回合奖励在300轮迭代学习后开始收敛于46附近,收敛性能均优于对比算法.此外,相比于基于PER、LAP的TD3算法,基于改进优先经验回放的TD3算法的回合奖励的收敛性能更高、更稳定,但其收敛速度相比于LAP的TD3算法略低.
在学习环境中,相比于PER、LAP的优先经验回放方法,基于改进优先经验回放的SAC算法的回合奖励的收敛速度最快,并且其回合奖励最高.虽然基于改进优先经验回放的TD算法的回合奖励的收敛速度略低于基于LAP方法的回合奖励,但是该算法的收敛性能更高、更稳定.这表明改进优先经验回放方法能够赋予模型较高的学习能力,能够有效利用低误差经验样本快速学习优化,策略模型的决策能力更强、更稳定.
(2)模型步奖励分析
回合奖励是步奖励累计结果,步奖励表征着机器人与环境交互过程中每一步的避障能力,步奖励越高,表明模型避障能力越强.
由图3可知,基于改进优先经验回放的SAC算法步奖励的收敛速度优于基于PER、LAP的SAC算法、TD3算法的步奖励.此外,在模型学习过程中,基于LAP的TD3算法、SAC算法的步奖励收敛性能不佳,算法的步奖励波动较大.
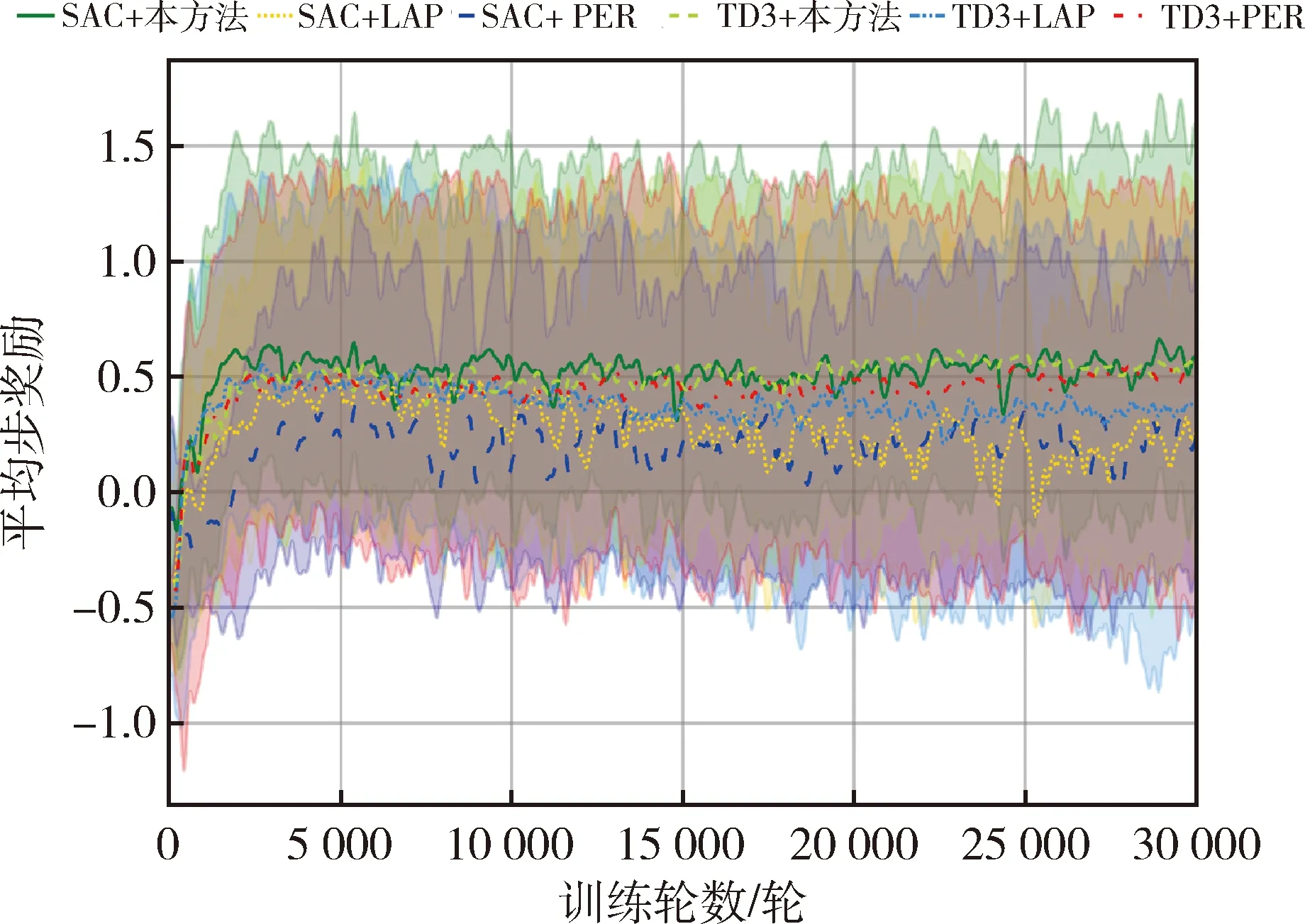
图3 步奖励
基于改进优先经验回放的SAC算法步奖励收敛速度更快,收敛性能更强.该算法模型通过学习低误差经验样本能够快速往目标方向探索环境,并且能够较好地躲避环境中的障碍物,其决策能力较强.
(3)模型回合时间分析
回合时间是指算法模型一个回合学习所需要的时间.回合时间越短,表明模型所用的步数越少,模型规划的从起点到目标点的路径越短.
从图4可知,相比于上述3种SAC算法模型框架的回合学习时间,基于改进优先经验回放、PER和LAP经验回放方法的TD3算法回合时间较少,并且波动范围较小.但是结合算法模型的回合奖励(如图2)、步奖励(如图3)和路径规划成功率与失败率(如表3)可知,基于改进优先经验回放、PER和LAP的TD3算法回合学习时间较短是由于机器人与障碍物发生碰撞而终止回合学习导致.另外,基于改进优先经验回放的SAC算法的有效回合时间在收敛速度以及收敛性能上均优于基于PER、LAP的SAC算法的回合学习时间.

图4 回合时间
基于改进优先经验回放的SAC算法回合有效学习时间最短,表明在学习环境下,改进优先经验回放方法能够提高模型参数的优化效率,并且该模型为智能体规划的从起点到目标点的路径长度较短.
(4)陷阱率分析
表3中,基于损失调整优先化经验回放(LAP)的SAC、TD3算法模型的路径规划成功率与碰撞率之和不等于1,本文将这部分差值称陷阱率,其表示机器人陷入障碍物陷阱并且无法逃离的概率.在上述6种算法模型中,基于LAP的SAC算法、TD3算法在TEXT1~4环境中的陷阱率在0.025~0.075之间,这表明在连续控制随机性较强的环境下,基于损失调整优先经验回放的算法模型在路径规划任务中可能陷入局部最优.在4种不同障碍物密度测试环境当中,基于改进优先经验回放的SAC、TD3算法陷阱率为0,表明改进优先经验回放方法能够提高训练模型所需经验样本的多样性,提高模型的鲁棒性能.
(5)模型泛化能力分析
为了进一步验证改进SAC算法的泛化能力,利用表1所示的TEXT1~4所示环境下对上述算法模型进行测试,记录每种模型在4种测试环境下的路径规划成功率、碰撞率(如图5和表3所示).
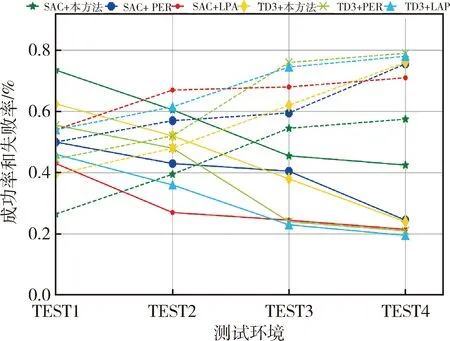
图5 成功率和碰撞率
从图5和表3可知,基于改进优先经验回放的SAC算法在4种测试环境中的路径规划成功率最高,并且基于改进优先经验回放的SAC算法、TD3算法的陷阱率为0,这表明利用改进优先经验回放方法训练的算法模型陷入障碍物陷阱的可能性较低,并且能够在较大障碍物密度环境下保持相对较好的路径规划性能.
综上,改进优先经验回放方法能够筛选出部分高学习价值经验样本,降低评估网络的不确定性对模型后续学习稳定性影响.此外,通过提高低误差经验样本在模型后续学习过程中的采样概率,可以有效提高模型的学习优化效率.在复杂、随机性较强的环境下,相比于TD3算法,结合改进优先经验回放的SAC算法具有较好的路径规划性能.
4 结 论
本文针对优先经验回放方法在连续控制任务中性能不佳问题,提出一种改进优先经验回放方法,并将该方法应用于SAC算法.实验结果表明,结合改进优先经验回放的SAC算法的收敛速度相较于PER、LAP方法提高10%以上,收敛性能提升15%以上,在4种测试环境下的路径规划成功率最高,改进优先经验回放方法能够提高模型的学习效率和重要性样本的复用率,降低模型的有效学习时间,提高模型在复杂环境下的路径规划能力.
虽然该方法能够有效提高模型的学习效率和样本的复用率,但是样本的混合优先度仍然要依赖于评估网络,并且无法完全筛选出部分Q值存在高估且状态优先度较大的经验样本并降低其采样概率,在未来可以通过参数共享的方式提高模型评估网络的评估能力,降低评估网络的过估计,进一步筛选出重要性样本,提高模型的学习速度.此外,仿真环境与现实的差距仍然是在线异策略深度强化学习的主要挑战,后续的工作应该聚焦在将训练好的策略模型转移到真实智能体当中.
