基于YOLOv8的卫星遥感图像快速目标检测方法
2023-11-13刘瑞锦何章鸣
刘瑞锦, 何章鸣
国防科技大学, 长沙 410072
0 引 言
在现代军事战争中,战场环境日益复杂,通过军事卫星准确侦察陆地战场的情报,对于夺取并保持战场信息优势具有重要意义.在具体操作中,如果能从军用卫星收集到的图像中快速获取敌军的军事设施或者部队数量,就能在战场上及时安排新的战略布置来有效打击敌军.在技术层面上,该任务的实质是目标检测[1-2],即识别图像中的目标,并对它们进行定位.伴随着人工智能和机器学习的快速发展,基于深度学习的目标检测方法已在诸多领域中被广泛应用,该方法主要分为多阶段方法[3]和单阶段[4]方法.其中多阶段目标检测算法如Fast RCNN[5]和Cascade RCNN[6]等,它们往往需要一个单独的网络来先提取物体区域再使用另一个网络对物体区域进行分类识别,虽然有较高的精度,但往往运行速度较慢,无法满足军事上快速目标检测的目的.
与多阶段目标检测方法相比,单阶段目标检测方法则是直接对获取到的整幅图像进行预测,只需一次提取特征即可实现目标检测,其精度虽然相比多阶段的算法低一些,但是检测速度较快.代表算法就是YOLO(you only look once)[7]系列,其思想是通过直接回归的方式获取目标检测的具体位置和类别分类信息,该算法极大降低了计算量,显著提升了检测速度.自2016年以来,该方法备受关注,经过多次改进,版本升级型号包括YOLOv2[8]、YOLO9000[9]和YOLOv5[10]等. 目前,YOLOv5在不同数据集上的泛化性能最好,在机械、航天、军事等许多领域也得到了充分的应用[11-14].本文则研究了最新的、综合效果最好的、模型轻量化的YOLOv8[15]目标检测算法,该算法于2023年1月提出,目前仍在开源修改状态,其快速准确实现目标检测的能力在部分大型数据集上已经得到证实.然而在空天战争中,当面临小规模遭遇战时,由于携带设备的限制,部队往往需要迅速标注他们获取的为数不多的战场信息,但目前该算法针对小样本数据的泛化性能尚未得到验证.
鉴于此,本文在YOLOv8的基础上,针对小规模飞行器数据集,开展了多种图像数据增强方法、优化函数及参数调整和参数预设等研究工作,借以改进模型的性能,最终获取了一种能快速准确地进行目标检测的模型.若能成功地将该模型部署到战略部队中,就可迅速判断敌军的力量分布,从而掌握情报上的主动权.
1 YOLOv8神经网络模型
1.1 总体结构
YOLOv8目标检测算法继承了YOLOv1系列的思考,是一种新型端到端的目标检测算法,尽管现在原始检测算法已经开源,但是鲜有发表的相关论文.YOLOv8的网络结构如图1[15]所示,主要可分为Input输入端、Backbone骨干神经网络、Neck混合特征网络层和Head预测层网络共4个部分.

图1 YOLOv8网络结构
1.2 各部分结构
输入端(input)方法包含的功能模块有:马赛克(mosaic)数据增强、自适应锚框(anchor)计算、自适应图片缩放和Mixup数据增强[16].马赛克数据增强包括3种方式:缩放,色彩空间调整和马赛克增强.该方法通过将4张图像进行随机的缩放、裁剪和打乱分布方式等操作来重新拼接图像,可丰富检测的数据集,具体步骤可见图2.随机缩放增加的许多小目标,非常适于解决卫星数据往往因距离目标过远从而导致图像中几乎都是小目标这一问题.在自适应锚框计算中,YOLO算法在每次训练数据之前,都会根据标注信息自动计算该数据集最合适的锚框尺寸,然后自动匹配最佳锚框.而自适应图片缩放只在检测时使用,由于不同场景需求不同,因而基于缩放系数YOLOv8提供了多尺度的不同大小模型.Mixup数据增强鼓励模型对训练样本有一个线性的理解,具体做法是在目标检测中将两幅图像的像素值按照图像透明度的通道信息(alpha值)进行线性融合,对于标签box的处理直接采用拼接(concat)的方法拼接到一起.

图2 马赛克数据增强方法
Backbone骨干网络指用来提取图像特征的网络,整体结构包括注意力机制(focus)模块、跨阶段局部网络[17](cross stage partial network,CSP)和空间金字塔池化结构(spatial pyramid pooling,SPP).其中,Focus模块的作用是在图片进入Backbone骨干网络前,对图片进行切片操作,即在一张图片中每隔一个像素取一个值,获得4张互补的图片,最后将新生成的图片经过卷积操作,得到没有信息丢失的2倍下采样特征图.YOLOv8使用了CSPNet中的C2f网络,网络见图3,其中CBS就是卷积层,而瓶颈层(bottleneck layer)使用的是1*1的卷积神经网络.C2f网络在保证轻量化的同时获得更加丰富的梯度流信息.而SPP结构是空间金字塔池化,能将任意大小的特征图转换成固定大小的特征向量,即把输入的特征地图划分为多个尺度,然后对每个图进行最大池化,再将提取的特征值拼接起来成为一维向量,输入SPP层获取分类.
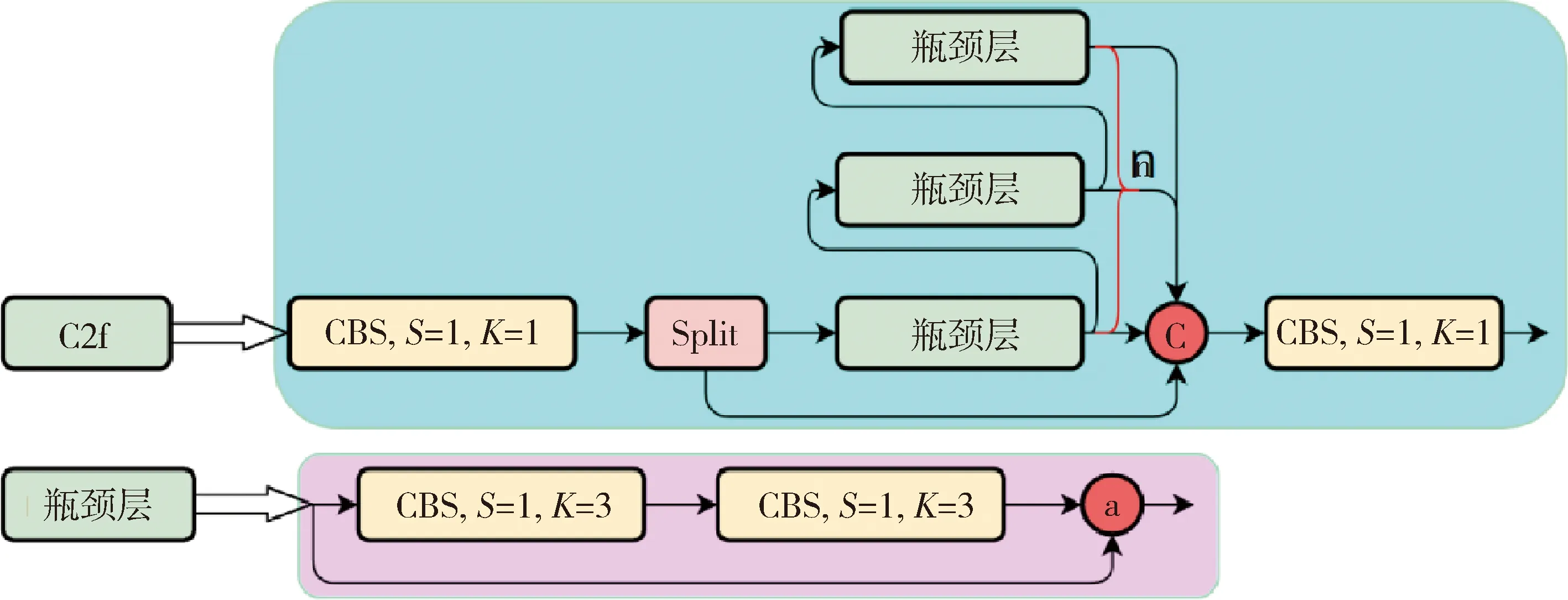
图3 CSP网络C2f模块
Neck结构如图4所示,它是由卷积层和C2f模块组成的的网络层,采用了路径聚合网络(path aggregation network,PAN)和特征金字塔网络(feature pyramid networks,FPN)的结构对特征进行多尺度融合,目标是将图像特征传递到预测层.其中PAN结构指图4左半边,它自底向上进行下采样,使顶层特征包含图像位置信息,两个特征最后进行融合,使不同尺寸的特征图都包含图像语义信息和图像特征信息,保证了网络对不同尺寸的图片的准确预测.而FPN结构指图4右半边,指通过自顶向下进行上采样,将高层特征与底层特征进行融合,从而同时利用低层特征的高分辨率和高层特征的丰富语义信息,并进行了多尺度特征的独立预测,对小物体的检测效果有明显的提升.从FPN模块的基础上看,它增加了自底向上的特征金字塔结构,保留了更多的浅层位置特征,将整体特征提取能力进一步提升.

图4 Neck结构:PAN-FPN
Head的结构如图5所示,在该结构中YOLOv8采用了解耦检测头(decoupled-head)[18],因为分类和定位的关注点不同,分类更关注目标的纹理内容而定位更关注目标的边缘信息.因而解耦头结构考虑到分类和定位所关注的内容的不同,采用不同的分支来进行运算,提升了检测效果,相对应的回归头的通道数也改变了.

图5 Head结构:解耦头
2 方法改进
2.1 评价指标
记目标的结果为正例(true)和错例(false),而预测的结果为正例(positive)和错例(negative).则准确率(查准率,precision)是真实目标占网络预测目标总数的比例,表示该网络的分类准确率,而召回率(查全率,recall) 是网络成功预测的真目标数与实际真目标数的比值,相对应的公式为
(1)
(2)
此外,目标的交集/并集比IoU (intersection over union)常用来衡量物体检测结果与真实值(真实的物体边界)匹配的好坏.一般当IoU大于0.5时可作为真目标,若记真实区域为A,预测区域为B,则IoU可表示为:
(3)
在IoU的基础上增加中心点距离,而CIoU Loss则又向其中添加了相对比例,用于对预测框和真实框不一致的结果进行惩罚.公式如下:
(4)
式中:b和bgt分别是预测框和真实框的中心点,p表示两个矩形框的欧式距离,c表示两个矩形框的闭包区域的对角线的距离;而v用来衡量预测框和真实框两个矩形框相对比例的一致性,α是权重系数.这样处理后,不仅考虑了两个框之间的距离,还考虑了矩形框的相对比例,更是解决了梯度为0和梯度爆炸的情况.
目标检测中衡量识别精度的指标一般是mAP,其中AP是计算某一类别的精确率和召回率(P-R)曲线下的面积,而mAP则是计算所有类别的P-R曲线下面积的平均值.在本实验中,我们只研究飞行器,故mAP与AP二者是相等的.FPS是指画面每秒传输帧数,即1 s能检测的图片数量,即图像的刷新频率.
2.2 损失函数改进
由于正负样本有不平衡问题[19],这可能会导致评价指标的误判,如几乎全是正例的模型中采用查准率(accuracy)作为评价指标会导致生成的模型无法预测反例.解决这个问题常用的想法就是调整类别权重:即算法实现过程中,对于分类中不同样本数量的类别分别赋予不同的权重.
因而YOLOv8使用变焦损失函数(varifocal loss function,VFL Loss)[20]作为分类损失函数,方程式如下:
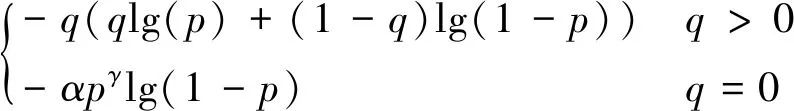
(5)
主要改进是提出了非对称的加权操作,其中p表示前景的预测概率,q是标签,正样本时q为预测结果(bounding box)和真实标注框(ground truth)的IoU(intersection over union),而负样本时候q值为0.该损失函数其他符号中由于p表示前景的预测概率,故1-p和p的系数次方分别是前景类和背景类可以减少简单样例的损失贡献,即相对增加误分类样例的重要性.
回归损失为CIoU损失函数+分布焦点损失(distribution focal loss,DFL)[21],记y是真实标签,靠近真实标签y的两个标签分别是第i次和i+1次的预测.则有
(6)
故DFL损失函数表示如下:
DFL(Si,Si+1)=-((yi+1-y)lg(Si)+(y-yi)lg(Si+1))
(7)
2.3 应用改进
YOLOv8目前只在部分大规模数据集如Coco(microsoft common objects in context),即一个大型的、丰富的物体检测分割和字幕数据集上进行了实验,针对小样本数据集的研究尚未得到验证.在局部作战中,由于部队无法携带大量电子设备,往往图片留存量较小且存在误检测和检测框重复的问题.为了获得目标的实时检测查准率和查全率都比较好的算法模型,以YOLOv8作为基础网络模型,本文以要检测的小规模航天器数据集为例进行如下改进:
(1)提高模型泛化能力
由于有效图像数量较少,对训练集的图像进行翻转水平和翻转垂直操作,使得新的数据集是原来的3倍,并且相应地对标签也进行修改.此外,对每一个轮次(epoch)中的图像数据,采用马赛克(mosaic)数据增强、自适应锚框(anchor)计算、自适应图片缩放和mixup数据增强等方式,以此来提高模型的泛化能力.
(2)提高模型平均精度
1)优化函数的选取:针对训练的是小样本数据集且需要快速训练的特性,故而初始时使用SGD作为优化函数来提高算法效果.因为随机梯度函数(SGD)相比于非随机算法能更加有效地利用信息,相比于其他优化算法,它一次仅用一个样本点来更新回归系数,这样做大大减小了计算复杂度,从而提高了函数的收敛速度.之后针对SGD训练的模型容易收敛到局部最优点这一情况,在此基础上重新调整优化函数为Adam优化算法(adam optimization algorithm).它能够对每个不同的参数调整不同的学习率,对频繁变化的参数以更小的步长进行更新,而稀疏的参数以更大的步长进行更新.
在两种优化算法中都使用了余弦退火(cosine annealing),即使用余弦函数控制学习率的取值范围,具体是随着x的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降,从而来降低学习率.
2)像素类别损失:由于卫星图像本身就是复杂背景,往往会影响检测效果,因而我们调整像素的分类的类别损失(classifies loss,cls)增益并降低掩模比,其中分类损失函数使用变焦损失函数(varifocal loss function,VFL)对分类中不同样本数量的类别分别赋予不同的权重,而回归损失函数出于相对增加误分类样例的重要性这一目的修改为CIoU损失函数+分布焦点损失(distribution focal loss,DFL).这些改进对于小样本小目标的数据集训练的效果也有增幅.
3)降低模型运行时间:由于深度学习神经网络参数过多,选取其他的已经预训练好的样本数据集的模型中加载部分参数,并加载不同优化函数训练过的参数,从而可以使得本模型训练时间大幅下降.
3 实验结果及分析
3.1 数据及平台简介
实验使用GDIT航空机场数据集[22],它是由停放飞机实例的航空图像组成.该数据集包括338张图片,其中所有的飞机类型都被归类到一个名为“飞机”的分类中.将数据集划分为训练集、验证集和测试集,其比例为7∶2∶1,其中训练集已经进行翻转水平和翻转垂直操作.由于是小样本数据集,采用常见的笔记本机器,在Windows 11系统下,显卡RTX 3060,16 G内存,python3.7和torch 1.13.1环境下,针对性地改进.
3.2 评价指标对比
使用目前广泛应用于工程实际中的YOLOv5s以及未改进的YOLOv8作为比较,使用查准率-查全率作为评价指标之一,结果如图6所示,查准率和查全率分别在左边和右边.
为贯彻中央领导同志重要批示精神,2018年9月23日,农业农村部副部长于康震一行赴河北省开展非洲猪瘟防控工作督查。于康震强调,要坚持疫病防控和生产供应两手抓,全面落实非洲猪瘟各项防控措施,严防疫情扩散蔓延,确保北京猪肉产品有效供给和市场稳定。

图6 P-R曲线图对比
在本问题中,首先采用查准率和查全率的原因如下:查准率高表示模型检测出的物体中大部分确实是物体,只有少量不是物体的对象被当成物体;而查全率高代表着模型可以找出图片中更多的物体.
可以看出,相比于原网络以及YOLOv5s,经过改进之后的YOLOv8n的查全率和查准率均远高于另外两个网络模型.
直观上说,用查准率-查全率来衡量目标检测的好坏似乎已经够了.然而,目标检测问题中每个图像都可能具有不同类别的不同目标,这使得模型的分类和定位都需要不同的指标进行评估.
而由于目标检测中常用mAP作为衡量识别精度的指标,即精确率-召回率(P-R)曲线下的面积作为参考指标.本文只涉及一类研究目标-飞行器,故mAP也即AP.
故仍然以上述两个网络作为参考,它们的mAP曲线见图7所示,其中mAP50指代将IoU设置为0.5时每一类的mAP值,而mAP50-95指代不同IoU阈值(从0.5到0.95)上的mAP.

图7 mAP曲线图对比
从图7可以看出,改进后的YOLOv8神经网络在经过图像翻转、数据增强、改进优化函数、降低掩模下采样比、降低像素的类别损失增益等改进之后,模型的平均精度(mAP)相比于原模型以及YOLOv5有明显提升,mAP值逼近0.9.

表1 算法性能对比
从表1看出,改进的YOLOv8查准率-查全率和mAP均高于YOLOv8和YOLOv5,FPS值也高于另外两种方法.故改进的YOLOv8可以快速准确地检测出目标,能满足军事上的需求.
3.3 目标识别图像
调用改进的YOLOv8网络模型的预测函数,对测试集进行测试输出,显示结果如图8所示.
在前面所述的运行环境下,改进的网络模型处理每张图像的形状具有如下运行时间:0.8 ms的预处理,92.7 ms的推理,0.7 ms的后处理.从显示图像结合预测时间,可发现改进的YOLOv8网络能准确快速地判别卫星图像的飞行器.
4 结 论
YOLOv8神经网络是一种最新的一阶段轻量化的目标检测算法,在公开的部分大数据集上该方法的综合效果最好,但是尚未在小样本数据集上得到大规模应用.在小样本数据集上,本文开展了提高YOLOv8神经网络检测性能的相关研究:通过图像增强手段来提高模型的泛化能力,通过调用不同优化函数来避免局部最优点,并通过改进优化函数、调整类别损失增益以及降低掩模比等策略来提高模型对背景的判断能力,最后通过加载初始参数和训练过的模型参数来降低运行时间. 在小样本卫星数据集上的实验结果表明,改进的YOLOv8网络处理能够快速、准确地识别飞行器目标.实验性能的统计数据证实了该方法的有效性,该研究为未来局部战争的实时侦察任务提供了一种技术参考.
