基于SSA-SVR 模型的国内新能源汽车销量预测研究★
2023-11-10梁亚玲陈英伟刘思佳
梁亚玲, 陈英伟, 刘思佳
(河北经贸大学, 河北 石家庄 050061)
0 引言
新能源汽车是当前全球汽车行业的发展趋势,也是我国汽车产业转型升级的重要方向。随着人们环保理念和绿色出行意识的提升,新能源汽车越来越受到青睐。新能源汽车与传统燃油汽车相比,具有节能减排、低碳环保的优点。另外,我国要实现2030 年“碳达峰”、2060 年“碳中和”的目标,治理汽车碳排放问题成为当下聚焦的热点问题。新能源汽车在我国已经进入了快速发展的阶段。因此,预测新能源汽车市场未来发展趋势,对于行业的可持续发展和“双碳”目标的实现具有重要的现实意义。
目前,在对新能源汽车销量预测的研究中,学者们通常基于市场需求、技术进步和政策环境等的预测方法(如SWOT 分析、技术生命周期分析和政策环境分析等),而更多采用的是基于历史数据构建数学模型,对新能源汽车销量进行定量预测。主流的预测模型有多元回归模型、时间序列预测模型、灰色预测模型、BP 神经网络模型以及集成学习算法等。
2019 年,张双妮[1]在对新能源汽车销量预测中,通过多元回归模型拟合新车比(新能源汽车销量/汽车销量)的走势,进行短期预测。Tang 等通过三个线性回归模型来确定对新能源汽车销量有显著影响的因素,结果表明,可支配收入、充电站数量、补贴和素养水平正向影响新能源汽车销量。Chen 等研究油价对中国新能源汽车销量的影响,发现原油价格和汽油价格均对新能源汽车销量产生正影响,汽油价格影响大于原油价格。陈璐[2]利用ARIMA 季节模型对2018—2020 年新能源汽车销量进行预测,得出新能源汽车需求呈上升趋势,发展前景可观。王小璇[3]选择灰色关联分析法筛选出影响新能源汽车保有量的因素建立指标体系,并结合灰色系统理论建立GRA-GM(1,N)多元灰色预测模型,预测新能源汽车保有量。杨东红[4]提出一种基于改进BP 神经网络的新能源汽车销量模型,有效提高了预测精度。此外,为提高预测的准确性和可靠性,组合模型在新能源汽车销量预测中也常使用。苏越等[5]采用回归预测、灰色预测以及二者组合预测的方法,对新能源汽车销量进行预测。结果表明,预测精度显著提高。白一凡[6]对数据进行因素分解,生成非随机波动序列和随机波动序列,构建SARIMA 和BP 神经网络组合模型,对新能源汽车月度销量进行预测。
新能源汽车销量预测无论采用哪种方法,都需要进行充分的数据收集和分析,并根据实际情况选择合适的预测模型和方法。如,时间序列分析方法是基于历史销量数据对未来销量进行预测,但新能源汽车销量会受到除自身以外因素的影响。因此,时间序列模型精度不够高。机器学习方法比时间序列分析方法的精度高,但使用默认参数也会有较大的预测误差。因此,本文使用麻雀搜索算法,优化支持向量回归模型参数来提高新能源汽车预测精度,并与传统时间序列模型进行对比,结果表明,本算法具有更高的精度。
1 模型方法
1.1 SARIMA 模型
在某些时间序列中会存在明显的周期性变化。这种周期是由于季节性变化(如季节、月和周等)或其他因素引起的,这样的序列称为季节性序列[7]。描述季节性序列的模型之一是乘积季节模型,也叫季节时间序列模型(seasonal ARIMA model,SARIMA),模型简记为ARIMA(p,d,q)(P,D,Q)S。其中,P、p分别为季节与非季节自回归,Q、q分别为季节与非季节移动平均数,D、d分别为季节与非季节差分阶数。该模型结构式如下:
式中:S为周期步长;B为滞后算子;εt为残差项;Φ(B)=1-φ1B-…-φpBp;Θ(B)=1-θ1B-…-θqBq;ΦS(B)=1-φS1BS-…-φSP BPS;ΘS(B)=1-θS1BS-…-θSQBQS。
SARIMA 模型适用于具有季节性、趋势性和周期性的平稳数据序列,可有效应用于包含趋势和季节性的单变量数据,特别是那些具有周期性趋势的数据。
1.2 麻雀搜索算法优化支持向量回归(SSA-SVR)
SARIMA 模型真实值与拟合值对比,如图2 所示。
医院运营结果最终取决于所有员工的所有行为。要达到理想结果,不仅医院管理层须努力在各个层面上营造让每个员工都能看得到的理想行为,还要切实为每个员工个体赋能。
支持向量机回归(Support Vector Regression,SVR)是一种基于核函数的算法,通过最小化损失函数来选择最佳的超参数,使得模型能够最好地拟合训练数据。利用核函数将数据映射到高维空间,在其中找出最优超平面,并将其用于回归预测。SVR 旨在最小化预测值与实际值之间的误差和模型的复杂度,同时允许一定程度上的误差[8]。SVR 的优点是能够有效处理具有复杂非线性关系的数据,并且在处理大规模数据集时具有较高的效率。
广东港丰电器有限公司坐落于广东省佛山市顺德区龙江镇,是港丰集团旗下企业,专业致力于PE健康给水管道及配件系列,埋地双平壁钢塑复合缠绕排水管及配件系列,PP-R精装家装给水管及配件系列,HDPE双壁波纹管及配件系列,PVC-U排水管、电缆管及配件系列,难燃PVC电线管、槽及配件系列,PE安全燃气管配件系列等产品的生产、设计、研发。
本文使用麻雀搜索算法来优化支持向量回归模型的参数,通过模拟鸟类在搜索食物时的行为来寻找最优解。适应度函数是SVR 模型的预测误差和模型复杂度之和,目标是最小化这个函数的值。通过使用麻雀搜索算法对SVR 模型参数进行优化,可以提高模型的预测性能和泛化能力。实验结果表明,SSA-SVR比其他优化算法具有更高的效率和准确性。
所谓合作学习,就是指学生为了完成共同的任务,有明确责任分工的互助性学习。在中职学校物理课程的教学过程中,倡导学生之间的相互学习、相互合作、相互竞争。教师可以按照班级人数划分相应的学习小组,并且按照学习能力大小进行有效的“分配”,要求在学习小组内相互帮助、相互协作、相互交往,增强责任感荣誉感;在学习小组外培养竞争意识、平等意识、参与意识及友谊意识,形成良性竞争,激发学生对物理课程的学习兴趣。
2 实证分析
2.1 数据来源与指标说明
本文对我国新能源汽车销量展开精准预测研究,选取了2014 年1 月—2022 年12 月的新能源汽车月度销量数据,数据来源分别为中国汽车工业协会、乘用车市场信息联席会、国家统计局和中国充电联盟等网站。新能源汽车主要包括纯电动汽车、插电式混合动力汽车和燃料电池汽车三种类型。结合国内外学者的有关研究以及数据的可取性,选取了5 个关键性指标作为影响新能源汽车销量的因素,分别是消费者信心指数、消费者价格指数、95 汽油价格、居民人均可支配收入和公共充电桩数量。
2.2 SARIMA 模型预测
首先,绘制出我国新能源汽车的原始时间序列图。
从图1 可以看出,新能源汽车月度销量类似呈现周期性上升趋势。原始时间序列为非平稳序列,具有一定的趋势性和周期性,需对原始序列进行差分。
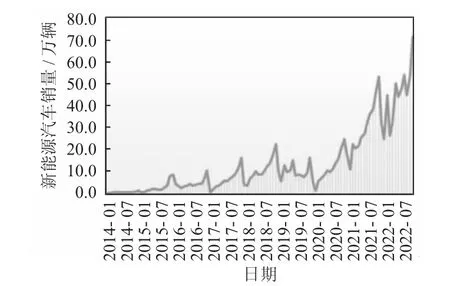
图1 新能源汽车销量时序图
经过一阶12 步差分后,序列基本平稳。对一阶12 步差分序列进行平稳性检验。ADF 单位根检验和白噪声检验中p值均小于0.05,表明一阶12 步差分后序列平稳且为非白噪声序列,可以利用SARIMA 模型进行建模。
下面进行模型定阶,本文选取准则函数(AIC 和BIC 准则)进行定阶。对于p、q、P、Q值的确定,通过不同组合计算各组合BIC 值,得到各组合的BIC 信息量,选取具有最小BIC 信息量的模型阶数。
对各参数进行t检验,得到的值均小于0.05,表明各参数均通过检验。最后进行残差检验,检验通过,表明模型是有效的。
将血浆引流管妥善固定于床旁,告知患者引流管的重要性,切勿自行拔出,避免引流管脱出或落入伤口内,若引流管不慎脱出,切勿自行安置,应立即通知主管医生处理[5,6]。

表1 各组合BIC 值比较
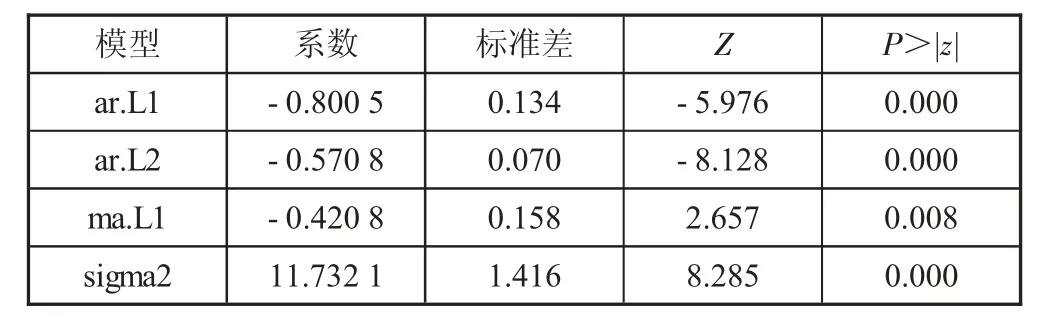
表2 模型参数
由表1 可知,BIC 值最小的组合为SARIMA(2,1,1)(0,1,0)12。通过计算,得到如表2 所示模型系数。
最终的模型如下:
麻雀搜索算法(Sparrow Search Algorithm,SSA)是一种启发式新型群智能优化算法,SSA 算法具有全局搜索能力和快速收敛性能,且计算复杂度较低,具有较高的实用价值。其灵感来源于麻雀的群体行为,利用麻雀飞行和寻找食物等行为特征。SSA 算法的基本原理是将问题转化为一个搜索空间,通过一群麻雀在搜索空间中的飞行和觅食来寻找最优解。该算法主要包括初始化、麻雀的飞行和觅食、适应度评价和更新等步骤
