基于OpenMP的并行Fortran程序数据竞争静态检测方法
2023-11-10金大海宫云战
葛 优,金大海,宫云战
(北京邮电大学 网络与交换技术国家重点实验室,北京 100876)
1 引 言
1.1 研究背景
随着信息技术的跨越式发展,并行计算以及并行处理技术因为高性能、低成本的优点,在当今各行各业的软件和系统中起到了举足轻重的作用[1].在2021年的ISC21超算大会上,中国在TOP500的计算机数量位居首位,且系统峰值性能达到了125425.9TFlop/s.然而随着并行计算机大规模的发展,故障和错误层出不穷,系统的可靠性问题亟待解决.
Fortran迄今为止仍是并行计算领域最流行的语言之一,但受限于其发明年代,最初的 Fortran 语言并不支持并行计算.而OpenMP作为可调用的并行库和应用程序编程接口,将Fortran语言扩展为并行语言,它以其良好的灵活性和可移植性成为了共享存储并行程序设计的工业标准.然而,由于编写并行程序的复杂性以及运行结果存在着难以重现和随机性[2],都会造成程序中的数据竞争故障,故障问题很难通过运行几次程序发现并定位出来.因此,如何准确的检测并行程序中数据竞争故障,提高程序的稳定性和可靠性,是本文研究的主要内容.
1.2 研究意义
1.2.1 国内外研究现状
Atzeni等人提出的Archer[3]使用动静结合的数据竞争检测方法来进行OpenMP数据竞争检测,它强制程序多次运行来查找其中的数据竞争问题.Archer通过仅检测程序中的并行部分,减少了基于pthread的TSAN-LLVM工具[4]的分析空间.由于Archer使用影子内存来跟踪每次内存访问,存在检测的内存需求和程序直接绑定的问题.此外由于Archer使用Polly获取函数的依赖和加载,在没有依赖的情况下将一段代码列入黑名单.对于循环嵌套等问题,由于黑名单的存在,对缺陷检测的准确度大大降低.
Gu等人提出的ROMP[5]维护每次内存访问的访问历史,为隐式和显式OpenMP任务构建任务图并分析并发事件.ROMP具有较高的准确率和召回率,但它没有对程序使用的所有动态加载的共享库进行检查.ThreadSanitizer[6]工具是基于Valgrid来检测数据竞争问题,它采用的happens-before的混合方法,并为共享内存上的读写操作维护锁集.由于它需要维护影子内存来存储元数据,而每次访问都需要影子内存,因此其内存需求会随着线程之间的共享内存量线性增长,检测的运行时间甚至会指数增长.
Basupalli 等人提出的OMPVerify[7]是一种基于多面体模型的静态数据竞争检测工具,其工作在抽象语法树层面上.OMPVerify检测的核心是通过计算多面体减少依赖关系图(PRDG),来推断OpenMP并行区域中可能存在的真实依赖关系、读写冲突以及过时的读取问题.但OMPVerify只能处理OMP并行的结构,并且对存在的数据竞争问题没有显著的分类,因此检测结果中存在的误报问题明显较多.
LLOV[8]作为一种基于LLVM独立中间表示的静态数据竞争检测工具.它使用多面体框架Polly,基于其中间表示在LLVM框架中实现快速、静态的数据竞争检查.LLOV可以处理参数数组大小和循环边界,并且其不依赖于运行时的线程数;但LLOV不支持OpenMP中用于同步和任务处理的制导指令,此外受多面体框架的影响,具有动态控制流和不规则访问的程序不在LLOV分析范围内.
现有的缺陷检测工具对OpenMP并行程序的语言和语法特性进行分析的不多,一些研究人员是通过多面体模型来检测指定的OMP并行构造进行静态检测分析,与他们工作不同的是,本文是针对OpenMP并行程序的指令特性来对数据竞争故障进行分析,从而建立数据竞争模型.因此本文方法对OpenMP制导指令的支持更健全和更准确.
1.2.2 本文工作
本文的工作应用数据流分析以及模型检测理论,将数据竞争抽象为一种故障模型,并根据基于OpenMP的Fortran并行程序的语言特性,对控制流图进行扩展引入并行控制流图,以及对并行区域的数据域进行活跃变量及数据流计算,根据程序控制流节点上进行状态转化来实现数据竞争的检测.此法不对源程序运行即可检测出程序中的数据竞争故障,并且能够全面、有效、准确的报告故障.
2 数据竞争故障分析
2.1 数据竞争故障
定义1.在程序内的某段代码区域产生并行区域P,假定P中存在着n(n>=2)个线程,若多个线程对P中的同一变量x进行访问,且有m(m>=1)个线程对x进行写操作,则可能会发生数据竞争问题.数据竞争不会立即使程序崩溃,但这可能会导致程序在并行模式下产生不确定的结果.
在基于OpenMP的Fortran并行程序中,串行区域由主线程执行,并行区域则是由线程组执行[9].对于线程组中的线程来说执行的只是并行区域中的代码部分,其操作的变量信息有一部分是与线程组中的其他线程共享的,另一部分则是其私有访问的,并且在这两部分中由于存在着变量的使用从而产生潜在的定值引用关系,从而产生其并行程序中的数据竞争问题.
2.2 数据竞争缺陷分类
2.2.1 循环携带数据依赖
循环携带数据依赖是指在并行区域P中,存在一个变量x,在线程t1的循环迭代中被读取,在线程t2的循环迭代中被写入,而t1!=t2.循环携带数据依赖故障主要是在指令需要稍后更新的值时会发生.结合图1分析,在程序中,循环嵌套应该在第1行中是并行的,但标记为并行的是第3行的内部循环,此处产生循环携带依赖问题.因为在程序的第4行,a(i,j-1)的读取取决于在前一次迭代中对a(i,j)的写入.当在串行执行时毫无问题,但在并行计算时,不能获取到a(i,j)处的未修改值,因此造成第4行产生一个数据竞争故障.
2.2.2 未指定行为
OpenMP是建立在共享存储结构的计算机之上,线程间的全局变量和静态变量是共享的,而局部变量是私有的[10].对于写入并行区域中的共享变量,变量的最终值是取决于最后一次迭代的写入,在串行情况下,这总是最后一次迭代,而在并行模式下,不能够保证,因此会导致数据竞争产生不确定的结果.
1)临时变量私有故障
临时变量私有故障是指并行区域内的各个线程未对数据进行私有备份,导致在并行区域多个线程可同时访问该数据,产生不确定的结果.如图2,在程序的第5行各个线程对变量x的值进行更新,而循环的最后一次迭代没能设置线程的私有备份x,导致最终的值不确定,在第5行产生一个数据竞争故障.
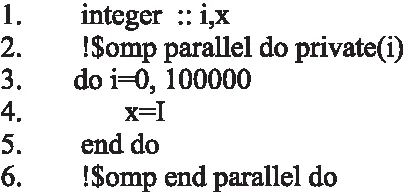
图2 具有临时变量私有故障的示例Fig.2 Example with temporary variable private
2)全局变量专有故障
全局变量专有故障是指并行区域内的线程未对全局数据进行专有拷贝,使其在多个并行区域之间保持连续性,导致多个线程同时访问该数据,产生未知结果.如图3,在程序的第2行和第3行声明了全局变量counter、pcounter;在第5行只对变量pcounter进行线程专有设置;第9行在并行区域多个线程对counter值进行读写操作,导致counter值的不确定性,因此第9行产生一个数据竞争故障.

图3 具有全局变量专有故障的示例Fig.3 Example with global variable exclusive
3)未定义的变量故障
未定义的变量故障是指该变量无有效的值,依赖于未定义变量值的使用导致未知结果产生.结合图4分析,在程序的第1行变量b是private()指定的,此时变量未定义;在第5行时,变量b被并行区域内使用但b未被定义,导致变量i值的不确定,因此造成第5行产生一个数据竞争故障.

图4 具有未定义故障的示例Fig.4 Example with undefined
3 数据竞争故障检测框架
本文描述的是在课题组自主研发的缺陷检测工具DTS[11]上的基于OpenMP的Fortran并行程序数据竞争的故障检测,检测框架如图5所示.本文根据数据竞争故障的分类,将数据竞争问题抽象为一种故障模式状态机,建立数据竞争故障模型;之后根据并行程序的语法和语义特性,进行并行程序建模; 最后将故障检测问题转化为一个计算故障模式状态机实例可能状态集合的正向数据流问题,沿着控制流节点通过判断变量的读写定值关系,迭代状态机实例的状态集合进行数据竞争故障的检测.故障检测流程的关键技术如下所示:

图5 数据竞争故障检测框架Fig.5 Data race detection framework
1)对源代码进行扫描,根据Fortran并行程序的语法和语义特性,构建对应的抽象语法树和并行控制流图,进行并行程序建模;
2)通过多次遍历抽象语法树,建立待分析程序的符号表.在符号表中存储着标记符的作用域信息、声明使用信息等;
3)进行并行数据流分析,计算并行区域内特殊数据作用域涉及到的变量隐式引用和隐式定值关系,来确定并行区域中变量的读写关系;
4)将数据竞争故障抽象为一种模型,并建立这种模型的缺陷模式状态机,将模型描述文件载入到检测引擎中;
5)在程序函数内部为每个相关的句柄建立一个状态机实例,通过在控制流图上迭代状态机,利用相关算法计算状态的转变,完成对数据竞争故障的检测.
4 Fortran并行程序建模
4.1 并行程序抽象语法树构建
由于Fortran程序实现并行是在串行程序中添加OpenMP API来构建的,而OpenMP作为并行语言,在语法上与Fortran是独立的.并行程序中的编译指导指令如OMP PARALLEL在构建Fortran抽象语法树时不会被解析生成抽象语法树节点[12],仅仅对Fortran源程序构建语法树的方法是不能识别出并行区域的.因此,本小节提出了一种Fortran并行程序抽象语法树的构建方法.
4.1.1 抽象语法树节点处理
对于Fortran程序的并行区域是根据OMP DO等编译制导指令将指令包围起来的串行区域并行化,制导指令只会将计算分散到不同线程中来加快执行速度,不会影响Fortran程序的计算结果.因此对于Fortran代码块来说,若代码块的外侧存在着一对制导指令,就可以确定这段代码需要并行执行.因此在抽象语法树生成的节点中,确定Fortran代码段与OMP制导指令的绑定关系,即可对并行程序的抽象语法树进行构建和访问.
1)基于ANTLR词法语法解析器[13],对Fortran和OpenMP生成对应的抽象语法树节点信息,在当前节点中存储其父结点及孩子节点信息.
2)对节点信息进行拆分和读取;根据节点关系特征,按照树高从上到下逐层读取语法树节点,每次都开辟一个新的空间来存储下一层节点的信息.
3)对节点信息进行标记;首先在抽象语法树节点存储对应行号信息,然后按照行号确定Fortran与OpenMP节点间的关系,确定并行入口节点、并行出口节点以及并行区域Fortran起始和结束节点.
4.1.2 基于邻接表的节点访问算法构建
根据上文的节点生成、节点存储以及节点标记,本文使用邻接表作为重建抽象语法树的存储结构,通过邻接表存储串行和并行出入口节点来实现对Fortran并行程序的节点访问算法.
此算法基本思想为:首先利用邻接表存储并行抽象语法树节点关联信息,将并行区域起始节点的父节点作为邻接表的邻接数组,将对应的OpenMP并行入口节点作为其邻接表内的邻接关系.之后对语法树节点访问时,先遍历邻接数组,判断访问的该节点是否在邻接表中存在,如果存在即当前节点为并行入口节点,则访问其邻接表内对应邻接关系节点为其并行抽象语法树的孩子节点;否则根据深度优先搜索直接访问其孩子节点信息.
4.2 并行控制流图构建
Fortran并行程序是由串行代码块和并行代码块交替组成的代码区域,对于串行控制流图来说,并不能表示因为OpenMP指导指令产生的并行区域,因此本小节提出了Fortran并行控制流图来解决这一问题.
算法.基于邻接表的节点访问算法
输入:邻接表、抽象语法树节点
输出:抽象语法树节点访问信息
1. begin:
2. createAdjacencyList(root);//邻接表存储节点关联信息
3. ASTprogram_unit ast !=null
4. for all num in nunMap do //遍历邻接数组
5. if node==num.key then
6. root.astNodeAddChild(createTree(root,node),root.child);//节点信息添加到语法树中
7. for all n in num.nodeList do //遍历访问邻接节点的邻接链表
8. visitNodeInfo(n);
9. else if node is not in numMap.key then //邻接数组中不存在当前节点
10. root.astNodeAddChild(createTree(root,node),root.child);
11. for all i in node.getChildNum()do //遍历访问该节点的孩子节点
12. visitNodeInfo(node.getChild(i))
13. end for
14. return ast //返回语法树节点访问信息
15. end
4.2.1 Fortran并行控制流图定义
定义2.设一个Fortran并行程序中存在N个并行代码块,那么该程序的并行控制流图(PCFG),可表示为三元组{Gs,Gp,Ep}:
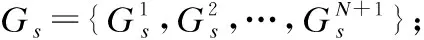

Ep定义为串行区域与并行区域控制流的边集,是从串行区域进入并行区域以及从并行区域离开串行区域的特殊控制流.
4.2.2 Fortran并行控制流图生成算法
在Fortran并行区中,一般包含任务共享结构,根据Fortran并行语法特征,主要将其分为两类:一类是如OMP DO结构,每个线程对应的串行控制流子图相同,只是遍历的循环的迭代空间不同;另一类则如OMP SECTIONS结构,对于任意两个线程所对应的串行控制流子图不相同[14].
针对这两种不同的任务共享结构,本文的并行控制流图(PCFG)的生成算法基本思想为:首先根据语法树节点确定并行标志位和串行标志位,通过访问标志位来判断当前语句节点为串行或者并行控制流,之后根据语句结构设计相应的控制流子图,最后将生成的控制流子图写入并行控制流图数据结构中.对于并行区域,则需要根据任务共享结构确定其相应类型,来生成控制流子图.
算法:并行控制流图生成算法
输入:控制流辅助结构、抽象语法树节点
输出:并行控制流图信息
1. begin:
2. gsFlag <-getFlagByParseTree(ast)//通过当前语法树节点确定是否访问串行标志位
3. gpFlag <-getFlagByParseTree(ast)
4. if gsFlag==true then //语句节点为串行控制流
5. node <-createPcfgNode(ast)//创建控制流节点
6. gsi <-new CFG(ast,node.addEdge())//根据语句结
构生成控制流子图
7. gs.add(gsi);
8. visitNextStatement(ast)//访问下一条语句
9. else if gpFlag==true then //语句节点为并行控制流
10. shareFlag<-getShareStructFlag(ast)//确定节点的任务
共享结构
11. if shareFlag==true then//并行区任务共享结构相
同时
12. node <-createPcfgNode(ast)
13. gp.add(new CFG(ast,node.addEdge()));
14. else if shareFlag==false then
15. for all i in node.getThreadNum()do//遍历并行区
域内的线程数
16. ni <-createPcfgNode(ast)
17. gp[i] <-new CFG(ast,ni.addEdge())//为不
同线程创建串行控制流子图
18. gp.add(gp[i]);
19. end for
20. visitNextStatement(ast)//访问下一条语句
21. end if
22. end
5 数据竞争故障模式状态机的设计
定义3.缺陷模式状态机是描述存在有限个缺陷模式状态以及在这些状态之间的转移和动作等行为的数学计算模型,包括非空有限状态集合S、输入字母表Σ及转移函数集合δ,S0是初始状态,为S的子集,其中δ:S×Σ→S.
在2.2节中讨论的两类数据竞争缺陷,可以用图6所示的缺陷模式状态机来描述.它以被分析的函数为单元,针对并行区域内调用的全局/局部变量创建状态机实例,并通过对变量的读写操作进行跟踪进行缺陷报告.
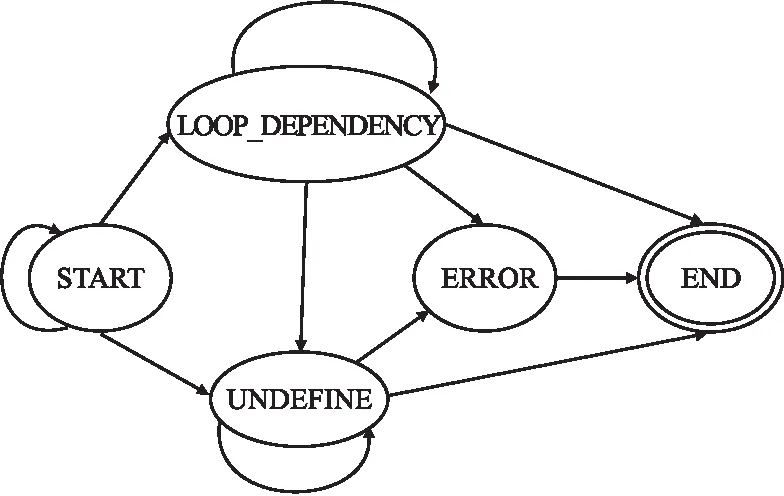
图6 数据竞争缺陷模式状态机Fig.6 Data race defect mode state machine
数据竞争状态机的状态集合S设计为:{START,LOOP_DEPENDENCY,UNDEFINE,ERROR,END}.其中START状态代表状态机的唯一入口;END状态代表结束状态;LOOP_DEPENDENCY状态代表着当前节点进入到循环执行的任务分担域,其中的各个线程各自分担其中一部分工作;UNDEFINE状态代表着当前节点内的数据变量被设置为对并行部分的线程可见/私有;ERROR状态代表当前分析的节点产生数据竞争缺陷.
表1标识了数据竞争状态转换过程.

表1 数据竞争的状态转换Table 1 State transition of data race
6 数据竞争故障检测算法
根据2.1节谈到的两种情况,可以看到这两种情况主要是分为循环携带依赖和未指定行为.因此,下面将对数据竞争检测算法分为循环携带依赖故障的检测算法和未指定行为的检测算法两个部分来描述:
数据竞争检测算法所用到的定义如下:
N:控制流图中所有节点的集合;
getEvaluationResults(node,xpath):通过Xpath检索当前程序中是否存在并行区域;
createSMInstance(var):变量var创建状态机实例;
getState(var,n):获得var在节点n上的状态,有START、LOOP_DEPENDENCY、UNDEFINE、ERROR、END;
addGen(state):添加新的状态至gen[n];
in[n]:到达节点n之前的所有状态;
out[n]:到达节点n之后的所有状态;
gen[n]:到达节点n之后创建或迭代的所有状态.
6.1 循环携带依赖故障的检测算法
以下是循环携带依赖故障检测算法涉及到的几个定义:
checkDependency(n):判断当前节点是否依靠并行区域的循环迭代次序,若为true,则说明依靠,反之不依靠.
compareDependency(leftVar,rightVar):比较赋值操作的左右两边的变量操作是否存在着读后写或者写后读问题.
此算法思想为:为程序中每个并行循环迭代变量创建故障状态机实例,在并行控制流图上根据状态转换条件进行状态的迭代,当节点中的状态为ERROR或END时,则整个算法结束.
算法.循环携带依赖故障检测算法
输入:并行控制流图、故障模式状态机
输出:报告数据竞争
1. begin:
2. for node in getEvaluationResults(node,xpath)
3. do createDBStateInstance(n)
4. for each n in N do
5. do in[n]=out[n] !=null
6. visited=true
7. if visited then
8. for each n in N do
9. if n==entry then //当前节点为控制流图的入口节点
10. in[n]=state.getValue(START)
11. elseif checkLoop(n)
12. n.addGen(LOOP_DEPENDENCY);
13. detectLoopRace(n)//判断节点是否存在数据依赖问题
14. elseif checkUnDefined(n)&& IsAssignmentStmt(node)then
15. n.addGen(UNDEFINE);
16. end for
17. end
18. detectLoopRace:
19. begin:
20. if getState(node,n)=LOOP_DEPENDENCY &&checkDependency(n)then
21. if compareDependency(leftVar,rightVar)//判断并行循环区域变量迭代的读写依赖情况
22. n.addGen(ERROR);
23. report find Data Race //报告数据竞争问题
24. elseif !checkDependency(n)then
25. n.addGen(END);
26. end
27. end
6.2 未指定行为的检测算法
对于Fortran并行程序来说,由于某些变量在进入并行区后具有特殊的数据作用域属性[15],如OMP PARALLEL PRIVATE(a),变量a被指定为并行区域中的私有属性,即会在每个线程里定义新的同类型对象,取代原始变量.则对于a来说,在并行区域中产生的每个线程,都将拥有其值未定义的私有副本.因此本文使用基本数据流分析方式,求解并行程序的结果可能不正确.
6.2.1 并行数据流分析
定义4.隐式引用和隐式定值定义为并行区域中由OpenMP指令导致的潜在赋值操作引发的定值和引用关系.即对于一个共享变量,如果在并行区域中被声明作为线程某种类型的私有变量,那么变量的共享版本值有可能会传递给线程中某一个私有副本,某一个私有副本的值也可能会传递给变量的共享版本.
并行数据流分析就是要在基本数据流分析的基础上对隐式引用和隐式定值进行分析和处理,使并行区域中存在隐式引用和隐式定值的代码块显示地存储在对应变量的定义出现(DEF)集合和使用出现(USE)集合中[16],来确定并行区域中变量的读写关系.
6.2.2 未指定行为的检测算法
getSameParallel(node,samePath):判断当前控制流节点对应的抽象语法树中并行区域是否为相同任务共享结构;
isLocalScope(n):判断当前节点的符号表作用域;
此算法思想为:与循环携带依赖故障检测算法一致,也是控制流图迭代状态,但未指定行为中任务共享结构分为两种,要对串行控制流子图相同与否进行分类分析,此外在迭代过程中对于各个线程的变量进行并行数据流分析,最终当前控制流节点的读写情况来确定是否含有数据竞争问题.
算法.未指定行为检测算法
输入:并行控制流图、故障模式状态机
输出:报告数据竞争
1. begin:
2. for node in getEvaluationResults(node,xpath)
3. do createDBStateInstance(n)
4. for each n in N do
5. do in[n]=out[n] !=null
6. visited=true
7. if visited then //当前节点位于控制流图
8. isSame=getSameParallel(node,samePath)
9. if isSame←true &&isLocalScope(n)then
10. if checkUnDefined(n)then //并行区域串行控制流子图相同时的情况
11. n.addGen(UNDEFINED)
12. goto detectUndefine
13. elseif checkSectionUndefined(n)then //并行区域串行控制流子图不相同时的情况
14. n.addGen(UNDEFINED)
15. goto detectUndefine
16. end for
17. detectUndefine:
18. begin:
19. in[n]=∪p∈pred[n]out[p]//进行数据流分析
20. old[n]=out[n]
21. out[n]=gen[n]∪(in[n]-kil([n]))
22. liveIn[n]=getParallelUseDef(out[n])//对并行线程副本的定义-使用关系进行分析
23. if liveIn[n]={var:ERROR} then
24. report find Data Race
25. end
26. end
7 实验结果与分析
为了进行实验评估,本文选择了DataRaceBench Fortran 1.3.2 基准测试集[17],可以系统和定量评估数据竞争检测工具的有效性.DataRaceBench Fortran是由166个微基准内核组成的,其中83个具有已知的数据竞争问题,剩余83个不存在任何数据竞争问题.
以运用本文所提出的方法参与开发的缺陷检测系统(DTS)为工具进行实验,对DataRaceBench Fortran进行检测,并与其他检测工具进行比较,表2为测试结果.
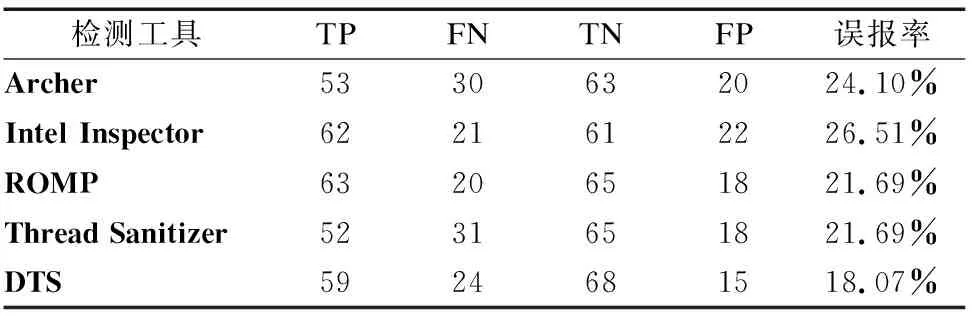
表2 不同工具检测的最大竞争数Table 2 Maximum number of races reported by different tools
表2中的TP表示能检测到已存在的缺陷,FN表示未能检测到已存在的缺陷,TN表示能检测到不存在缺陷问题,FP表示误报,不存在缺陷却检测到;误报率表示本工具中检测到的误报缺陷数占所有不存在缺陷问题总数的百分比.
根据表2中的实验对比数据,可以看出运用本方法的DTS与国际一流工具相比在数据竞争检测的准确性上基本持平,尤其是DTS的平均误报率仅为18.07%,比效果最好的ROMP 21.69%的误报率低了3.62%,这说明DTS能正确报出故障的效果是最好的,具有更好的检测性能.
为了验证DTS检测的稳定性和精确性,对UP2D、NDYN、ParallelForest[18]等3个大型开源项目进行检测,表3为测试的结果.
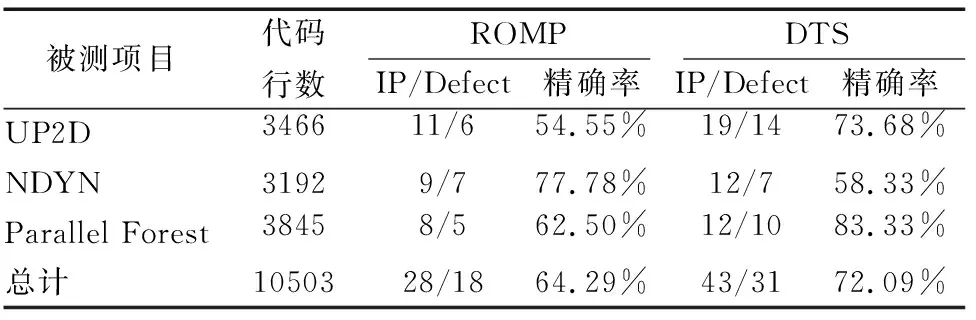
表3 开源项目测试结果Table 3 Open source project test results
IP表示检测工具检测到的数据竞争故障,Defect表示IP中经人工确认后真实存在的数据竞争故障,精确率是对预测结果的接近程度进行度量,其表示为Defect个数占IP个数的百分比,较高的精确率表示该检测工具通常会在存在数据竞争时识别出数据竞争问题.运用本方法的DTS检测工具与ROMP检测工具的测试结果进行对比,图3为对应的结果.在所测的3个项目中,DTS经人工确认后的真实故障数为31个,平均精确率为72.09%,而ROMP检测出来的真实故障数为18个,平均精确率为64.29%.从表3可以看出运用本方法的DTS能够检测出更多的故障并且精确率更高,说明本文提出的检测方法是有效的,具有更好的精确性.
8 结 论
本文采用静态分析方法检测 OpenMP并行Fortran程序中的数据竞争问题,并通过所研发的测试工具来证明了本方法的可行性,同时实验数据也证明了本方法在数据竞争检测上的有效性.但通过实验数据也显示了本方法并不能完全排除漏报和误报问题.通过分析,本文发现漏报问题主要是由于有些数据竞争故障没有被归类以及函数调用关系划分不准确造成的,而误报问题是由于并行数据流的分析不准确造成的.今后的研究方向将在以下3个方面改进:首先是进一步总结数据竞争问题出现的情况,将其进行更细致全面的抽象归类;其次是对并行数据流进行优化以及变量进行区间计算,尽量减少误报和漏报;最后是将此方法应用于更多的故障检测中去.
