基于视觉的工业机器人装配演示示教研究
2023-11-09张浩陈成军潘勇
张浩,陈成军,潘勇
(青岛理工大学机械与汽车工程学院,山东青岛 266520)
0 前言
工业机器人在自动化生产中具有广泛的应用前景,然而机器人编程效率已经成为影响其生产效率的关键因素之一,因此提高机器人编程效率已成为工业机器人应用的关键。演示示教编程是指机器人理解人类演示行为,并将人类行为映射成机器人控制命令的过程[1]。
演示示教编程的关键是人类(演示者)如何向机器人(学习者)传递相关的行为信息,即演示方法。按照演示方法,目前演示示教编程主要包括动觉教学[2]、动作捕捉[3]和视觉演示编程[4]。视觉演示编程目前主要有基于物体位置变化的演示学习[5]、基于动作任务的演示学习[6]和基于规则约束的演示学习[7]。
基于动作任务的演示学习编程中,如何理解人类行为是国内外研究的热点,目前主要方法有视频字幕任务[8]。视频字幕任务输出自然语句以描述视频中发生的内容,同时可以将输出的自然语言句子转换为机器人动作指令。NGUYEN等[9]将视频字幕任务研究应用于机器人演示示教,设计了一个将人类演示视频转换为机器人动作命令的框架,该框架由CNN(Convolutional Neural Network)和RNN(Recurrent Neural Network)组成,首先利用CNN提取人类演示视频中的视觉特征,然后利用RNN输出机器人动作指令,并在一台仿人机器人上进行了各种操作实验,验证了该系统的有效性。然而该方法只关注RGB视频中的全局特征(全帧),忽略了局部特征(目标物体);其次通过视频字幕方法将人类演示视频转换为机器人连续控制指令,会存在部分动作视频帧分类错误导致控制指令异常的问题。
为实现全局特征(全帧)和局部特征(目标物体)的融合并解决机器人控制指令异常的问题,本文作者提出基于视觉的工业机器人装配演示示教系统,用于机器人轴孔装配演示示教。首先,使用MaskRCNN网络模型[10]从RGB视频帧中检测和分割目标物体,输出物体类别信息和目标物体的像素掩码,并利用均值化方法处理目标物体像素掩码,确定目标物体的中心点像素坐标;通过RGB-D相机的三维定位原理将中心点像素坐标转化为相机坐标系下的三维坐标。然后,建立动作分类识别模型提取出演示视频中的视觉特征并输出动作分类标签(机器人控制指令);为了消除异常的动作分类标签,提出数据清洗滤波算法,对动作分类标签清洗和整理,得到期望的标签数据,提高动作分类的精度。最后,机器人根据动作分类标签、中心点坐标和物体类别等信息执行轴孔装配演示动作。
1 系统架构
图1所示为文中提出的基于视觉的工业机器人装配演示示教系统,包括目标识别与中心点定位模块、装配动作分类识别模块、机器人动作执行模块。

图1 装配演示示教系统结构示意
目标识别与中心点定位模块包括实例分割功能单元、目标中心点定位功能单元;装配动作分类识别模块包括动作识别单元、动作标签清洗单元;动作执行模块接收目标物体的中心点坐标及其物体类别、动作分类标签等,规划UR5机器人的路径动作,控制机器人运动。文中使用ROS平台[11]搭建机器人动作执行模块。
1.1 目标识别与中心点定位模块
目标识别与中心点定位模块的功能是从演示视频帧中识别定位圆轴、圆孔和机器人夹爪,为机器人执行轴孔装配演示任务提供输入信息。此研究选用MaskRCNN网络模型对RGB视频帧进行实例分割。MaskRCNN网络是基于卷积神经网络的实例分割算法,包括目标检测和语义分割2个模块。目标检测模块判断物体类别,并用检测框框选出目标物体;语义分割模块分割检测框中的背景和物体类别,并输出像素掩码。随后对输出的像素掩码进行均值化处理,定位出圆轴、圆孔和机器人夹爪的中心点像素坐标,并通过matplotlib函数库[12]标记出像素中心点,同时根据圆轴像素中心点对应的深度值z和RGB-D相机的内参计算圆轴、圆孔和机器人夹爪在相机坐标系下的实际中心点坐标。
1.1.1 实例分割功能单元
准确识别定位圆轴、圆孔和机器人夹爪是机器人演示示教的前提和关键。考虑到实例分割的精度和实时性需求,MaskRCNN网络的输入为RGB-D相机获取的RGB视频帧,图2(a)为RGB视频帧中的圆轴、圆孔和机器人夹爪。图2(b)为MaskRCNN的输出结果,包括每个预测的名称、置信度得分、像素掩码。

图2 圆轴、圆孔和机器人夹爪展示
1.1.2 目标中心点定位功能单元
目标中心点定位功能单元对输出的掩码进行均值化处理,计算出圆轴、圆孔和机器人夹爪的中心点像素坐标。机器人执行装配模仿动作旨在找到一种稳定实现轴孔装配的方法,文中将轴孔装配的解决方法定义如下:
g={x,y,o}
(1)
其中:(x,y)为掩码的中心坐标;o表示物体类别标签。确定圆轴、圆孔和机器人夹爪的像素中心点后,通过matplotlib函数库标记出其中心点,并输出圆轴、圆孔和机器人夹爪的中心点像素坐标Oi(ui,vi)。图3表示了目标物体像素掩码与中心点定位的表示方法。

图3 目标物体像素掩码与中心点定位
为了将圆轴、圆孔和机器人夹爪的中心点像素坐标转换为相机坐标系下的三维坐标,首先需要将目标物体的深度图像和RGB图像的坐标系原点对齐,然后利用RGB-D相机提供的SDK获取相机的内参和相机的光心距离圆轴像素中心点O1(u1,v1)所对应的实际深度值z。根据RGB-D相机的三维定位原理,计算圆轴、圆孔和机器人夹爪在相机坐标系下的三维坐标Pi(xi,yi,zi)。三维定位原理如公式(2)、(3)和图4所示:
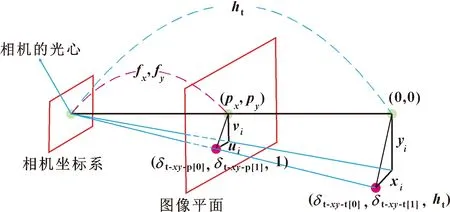
图4 RGB-D相机的三维定位原理
(2)
(3)
其中:px和py为相机视野中心的像素坐标;fx、fy为相机的焦距;(0,0)表示相机坐标系x轴和y轴方向的原点坐标;δt_xy_p[0]、δt_xy_p[1]分别表示检测物体在图像中的像素x、y坐标值;δt_xy_t[0]、δt_xy_t[1]分别表示检测物体在相机坐标系下的x、y坐标值;ht为实际深度值。
1.2 装配动作分类识别模块
确定目标物体的类别和中心点坐标后,需要识别出人体装配演示视频中的动作行为信息,进行机器人的装配演示示教。装配动作分类识别模块包括动作识别功能单元和动作标签清洗功能单元。动作识别单元提取出装配演示视频中视觉特征,结合视觉特征的时间序列,识别并输出动作行为信息。动作标签清洗单元检测并清理动作行为信息,得到期望的动作行为信息。
1.2.1 动作识别单元
动作识别单元建立了基于深度学习网络的动作分类识别模型,识别人体的装配动作,随后输出动作分类标签命令。与视频字幕任务输出的自然语言形式有所不同,文中使用自制的词汇语言描述输出的命令。基于深度学习网络的人体动作识别流程具体步骤如图5所示。
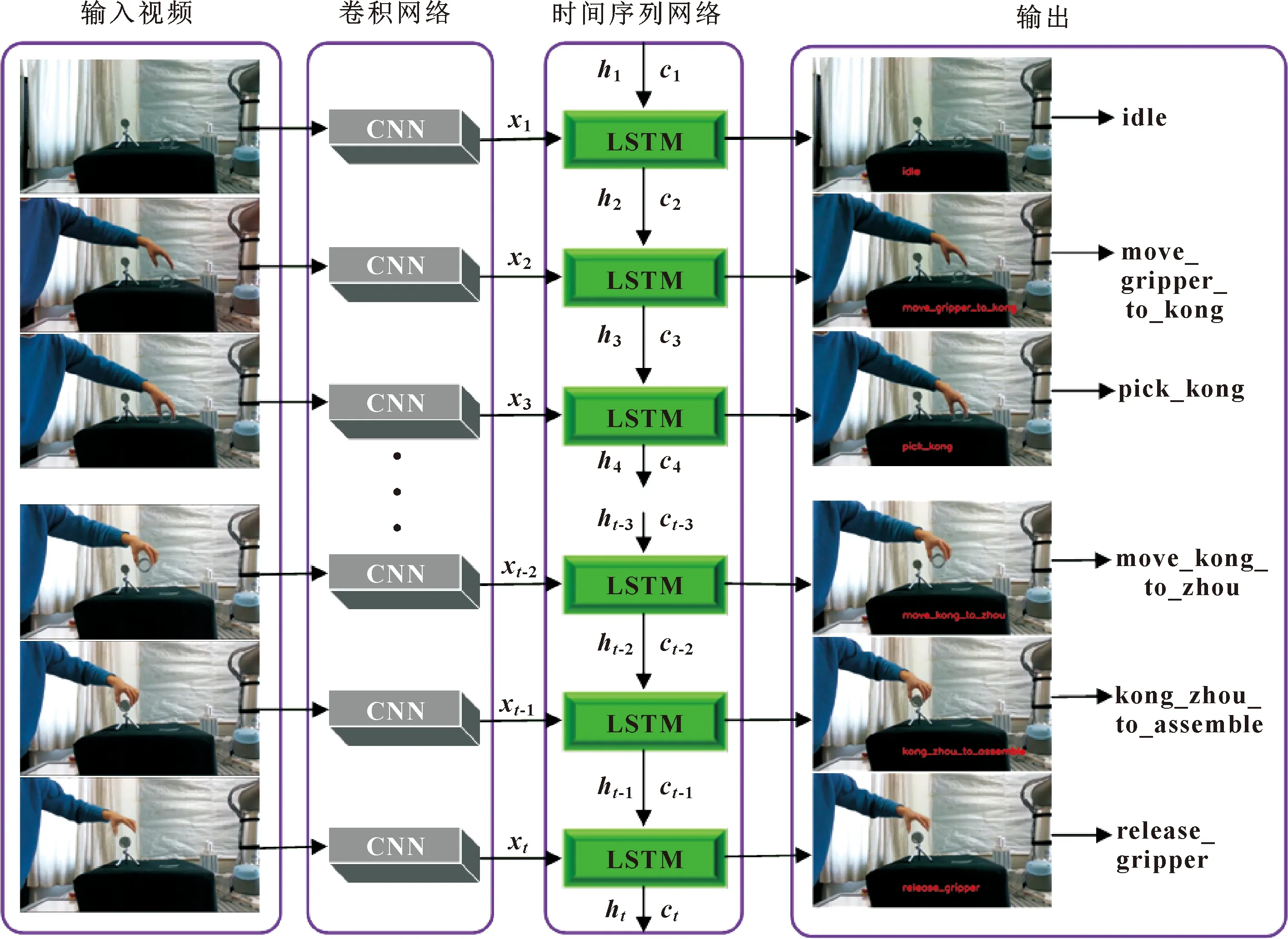
图5 基于深度学习网络的人体动作识别流程
此研究的人体动作分类识别模型由卷积神经网络(CNN)和长短期记忆网络(Long Short-Term Memory,LSTM)[13]组成。其中CNN网络能够有效提取视频帧的图像特征,LSTM网络可以编码视频帧的图像特征并依次按照视频帧的顺序解码。此研究选用ResNet50[14]作为主干网络,用于提取装配演示视频帧的图像特征,将CNN网络提取到的图像特征输入到LSTM网络,LSTM网络会在每个时间步长t获取输入的图像特征xt,并计算隐藏状态ht和记忆细胞状态ct,如公式(4)所示:
(4)
其中:⊙表示逐元素乘法;函数σ是sigmod非线性,而φ是双曲正切非线性;权重矩阵Wij和偏差bj是训练参数。
文中首先使用预训练的CNN网络对装配演示视频中的每一帧提取出图像特征xt,连同前一个时间步长的隐藏状态ht-1和记忆细胞状态ct-1,一起输送到LSTM网络中进行编码,并计算出此次时间步长的隐藏状态ht和记忆细胞状态ct,最后解码视觉特征,以生成相关的单词列表,用于输出命令。即给定输入的视觉特征序列X={x1,x2,...,xt},计算隐藏状态序列H={h1,h2,...,ht}和记忆细胞状态序列C={c1,c2,...,ct},输出字序列Z={z1,z2,...,zt}。
动作分类识别模型对装配演示视频中人体的动作分类识别,视频中的每帧将生成相关的动作分类标签,并将动作分类标签保存至csv文件中,将输出的动作分类标签发送至动作标签清洗单元。
1.2.2 动作标签清洗单元
数据清洗可以剔除数据中的干扰项,将原始数据处理为有价值的数据。此研究动作识别单元生成了n个动作分类样本(其中n是视频帧数),由于LSTM网络输出的动作分类标签会存在部分异常,因此查找、剔除并替换异常的动作分类标签至关重要,其直接决定了机器人执行装配模仿动作的准确性。因此,此研究提出了一种数据清洗滤波算法,对装配动作分类标签按照视频帧的顺序清洗和整理,利用统计分析识别产生的错误值或异常值。图6所示为数据清洗滤波算法的原理。

图6 数据清洗滤波算法的原理
标签值按照视频帧顺序排列,此研究选用单位长度为5的清洗滤波窗口,从初始标签值开始依次向下滑动,每滑动一次,分析所框选的清洗滤波窗口内部的数据,清洗滤波窗口内部的中间数据分别与上方的2个数据和下方的2个数据比较,在这个区间内,利用公式(5)对清洗滤波窗口内的5个标签分析,得到相关动作分类标签数量的最大值C,ci表示清洗滤波窗口内对应的动作分类标签。
C=max{ci,ci+1,ci+2,ci+3,ci+4}
(5)
图7所示为数据清洗滤波算法的流程,文中仅考虑每个清洗滤波窗口内出现的3种动作分类标签(如果产生3种以上的标签,证明网络初始生成的动作分类标签出现错误)。(1)如果清洗滤波窗口内都是相同的动作分类标签,该动作的标签数量则为最大值5,直接提取出相关的动作分类标签;(2)如果清洗滤波窗口内产生2个不同的动作分类标签x1、x2,则取对应的数量为最大值的动作分类标签;(3)如果清洗滤波窗口内产生3种不同的动作分类标签x1、x2、x3,如果有1类标签数量大于另2类标签数量,即x1>x2>x3,则取对应的数量为最大值的动作分类标签x1;如果有2种标签值数量都达到同等最大值,即x1=x2>x3,则此次标签值选择与上方清洗滤波窗口生成的标签值结果。同时每个清洗滤波窗口产生的动作分类标签如果连续相同,则视为相同的动作分类,如果不同,则依次按照动作分类排序。

图7 数据清洗滤波算法流程
1.3 机器人动作执行模块
此研究ROS的通信机制选用话题通信机制和服务通信机制,通过通信机制机器人动作执行模块与目标识别与中心点定位模块、装配动作分类识别模块实现信息融合。
在示教系统开始工作时,首先初始化系统,RGB-D相机与目标识别与中心点定位模块、装配动作分类识别模块分别建立联系,同时ROS与UR5机器人通过TCP/IP协议建立通信连接,随后执行装配演示示教动作。
如图8所示,此研究设计了3个功能单元:(1)人体运动和物体运动状态观察单元;(2)人体动作行为规划单元;(3)机器人动作执行单元。人体运动和物体运动状态观察单元为感知数据(见图8),通过装配动作分类识别模块,将人体动作状态分割为空闲状态和人体手臂运动;从物理场景中存在的对象及其属性获取2种主要类型的信息:物体静止状态和物体运动状态。人体动作行为规划单元按照动作状态(空闲状态和人体手臂运动)和对象属性(物体静止状态和物体运动状态)定义了4类动作行为库,动作行为库用编程语言编写了此研究所提到的轴孔装配操作任务以及一系列常见的机器人操作任务(例如抓取物体、推拉物体、旋转物体等)。动作行为库的设定是后续如果进行更多的人类活动任务,只需要将相关的动作分类标签对应于动作行为库,因为此研究所提到的人类动作行为(例如抓取孔、将孔移向轴)都是特定且单一的。

图8 装配动作执行框架
动作分类标签按照动作状态和对象属性进行分类(见图8),然后根据目标识别与中心点定位模块输出的中心点坐标和物体类别,结合动作分类标签信息执行动作行为库中所对应的机器人操作任务。随后MoveIt!进行动作规划,人为设定规划次数为10,如果规划未成功,则重新规划。规划成功后利用ROS提供的3D可视化工具rviz,通过导入UR5机器人的URDF树形结构模型,可以观察到机器人3D模型的运动状态。机器人的动作执行单元为机器人的动作执行(见图8),功能模块MoveIt!把计算的结果通过ROS Action的方式发送给Driver,Driver调用通信模块Modbus/TCP的Modbus_write Server节点发送各个控制指令到UR5机器人控制器,机器人执行与人体装配动作相关的模仿运动。
2 实验
为了验证上述演示示教系统结构的可行性,文中设计了图9所示的演示示教原型系统。该系统包括:配备MHZ2-40D平行气爪的UR5机器人、RealSense D435i相机[15]、相机支架、计算机(CPU:i7-9700、RAM:16 GB、graphics card:RTX2060)、工作台、圆轴、圆孔。RealSense相机固定于工作台正前方处,机器人的整个工作空间在相机视野内。

图9 实验系统
2.1 实验系统设置
为了获取目标识别与中心点定位模块的数据集,文中利用RealSense相机拍摄了300张圆轴、圆孔和机器人夹爪的RGB图像,图像的分辨率为1 280像素×720像素。利用LabelMe软件标注RGB图像,数据集由训练集和验证集两部分组成。此研究使用TensorFlow1.3开发框架搭建MaskRCNN网络模型,在配备Intel Xeon E5-2630 CPU处理器、以及4个NVIDIA TITAN Xp GPU的服务器上进行了训练。
图10所示为训练过程中产生的总损失曲线,MaskRCNN的多任务损失函数由分类损失Lclass、回归框损失Lbbox和mask损失Lmask组成:

图10 训练过程中的损失变化
L=Lclass+Lbbox+Lmask
(6)
模型共经过30个epoch,在15 个epoch训练后损失趋于稳定。
为了获取装配动作分类识别模块的数据集,文中进行了数据采集:选用RGB-D相机,将相机固定于圆轴、圆孔正前方70 cm处,录制100段人体轴孔装配的动作视频,分辨率为960像素× 544像素。针对轴孔装配动作任务,此研究将人体的动作划分为6种类别,每段动作视频都用人体的6种动作类别进行注释,文中使用数据集的80%进行训练,剩余数据集的20%用于测试。动作分类识别模型基于Tensorflow1.15开发框架,在配备Intel Xeon E5-2630 CPU处理器以及4个NVIDIA TITAN Xp GPU的服务器上进行了训练,训练时长为12 h。
2.2 实验验证
为了验证提出的示教系统的可行性,文中开展了实验研究。操作员通过轴孔装配动作演示视频对机器人进行示教,验证机器人动作模仿的可行性。
操作者执行的轴孔装配动作任务的视频图片如图11所示,由人类演示一次相关的轴孔装配动作,然后机器人执行20次模仿轴孔装配动作的实验,实验的总体成功率达到了80%,图12显示了机器人执行模仿实验的示例视频图片。

图11 人体执行轴孔装配动作任务的视频画面

图12 机器人执行模仿实验的示例视频画面
3 结论
文中提出了基于视觉的工业机器人装配演示示教系统,利用该系统,机器人通过视觉观察从人体装配演示视频中学习机器人装配控制指令。该系统包含了3大模块:目标识别与中心点定位模块通过MaskRCNN网络识别物体类别和输出目标物体的像素掩码,利用均值化方法处理目标物体像素掩码,确定目标物体的中心点像素坐标,并通过RGB-D相机的三维定位原理将中心点像素坐标转化为相机坐标系下的三维坐标;装配动作分类识别模块基于CNN和LSTM的动作分类识别模型,识别人体装配动作视频中的动作行为,输出描述动作行为信息的动作分类标签,并通过数据清洗滤波算法对动作分类标签清洗和整理,获得期望的动作分类标签;机器人动作执行模块根据物体类别、中心点坐标和相关的动作分类标签等信息,规划机器人运动,控制机器人执行装配任务。此研究建立实验系统,通过实验验证了基于视觉的工业机器人装配演示示教系统可以完成轴孔装配任务实现演示示教。
