基于决策树模型的风化玻璃制品成分分析与鉴别
2023-11-06许思琦谢健林瀚滕越
许思琦,谢健,林瀚,滕越
(广东东软学院,广东佛山 528225)
0 引言
在早期贸易来往的过程中,玻璃是其中最重要的流通物证之一。早期的玻璃常使用铅矿石与草木灰等多项助熔剂进行研制,在炼制时使用的助熔剂不同将导致其烧制的玻璃化学成分不同,主要可以分为铅钡玻璃与钾玻璃两种,而铅钡玻璃通常认为是我国自主发明的玻璃品种[1]。
此外,由于古代炼制技术不够发达,所以在埋藏地点极易受到环境的影响而导致风化,其内部元素将和环境元素进行大量的交换,使得对古代玻璃制品类型的鉴别工作难以进行。
1 需求及假设
①对这些玻璃文物的表面风化与其玻璃类型、纹饰和颜色的关系进行分析,结合玻璃的类型,分析文物样品表面有无风化化学成分含量的统计规律,并根据风化点检测数据,预测其风化前的化学成分含量。②对数据中未知类别玻璃文物的化学成分进行分析,鉴别其所属类型,并对其分类结果的敏感性进行分析。
综上,于是提出基本假设如下:①假设各玻璃文物在制造时相同特征的玻璃加工参数相同。②假设各玻璃文物各部位随机采样时的采样面质地均匀。③假设各玻璃文物中检测空白处的值趋近于0。④假设各玻璃文物颜色仅由有无风化及化学成分决定。
2 模型建立与求解
2.1 对玻璃文物属性的分析及预测
在本节中,需要研究各玻璃文物中各项属性之间的关联程度,利用附件表单1中的各项数据进行可视化处理。其中,由于数据项多为文本数据,于是考虑先对其进行文本向量化处理。在明确了玻璃文物之间的关联程度后,依照两种玻璃类型讨论样品表面有无风化对应的化学含量的变化,并设计预测模型研究风化文物风化前的化学成分含量。
1)利用独热编码思想的文本向量化
①独热编码规则
独热编码(One-Hot)其根本思想为将各类文本数据进行划分,以n维向量集对n个不同状态进行编码,而对应每一种状态下的第n维向量应只有一位数据有效。以本题为例,对于58 个文物编号即有58 种组合关系,以文物编号01-03 为代表,于是利用独热编码规则有:
对各类文物编号进行组合编码如上所示,但考虑到各文物其对应的各项属性应均不相同,所以对其中各项属性进行分类,以纹饰、类型、颜色和表面风化为主属性,将其中属性项依照文物编号进行独热编码。
②统计文本特征
考虑到数据表格中的各文物属性对应的属性项不同,所以需要对其中的属性特征进行分类,将其不同的数据项进行提取。对应各属性有如下属性项:

表1 各文物属性特征
对应上表,可以发现类型和表面风化可以分为两类,纹饰分为三类。对应颜色特征,其中可能存在部分文物风化程度较高的原因从而使得玻璃颜色无法辨认,所以有颜色未知的情况,加上未知项,共有九类颜色特征。
③文本特征编码规则
由上可以得知,对各文物的属性项进行拆分后,有16 种不同属性特征。此外,由于存在有58 种特征组合,所以对文本特征进行向量化后得到一个58×16的特征编码矩阵。58 种组合中的一个行向量中包含的各数据名称依次为纹饰属性、类型属性、颜色属性和有无风化。于是,对任意的向量应有如下所示:
其中,对应各编码含义如下表所示:
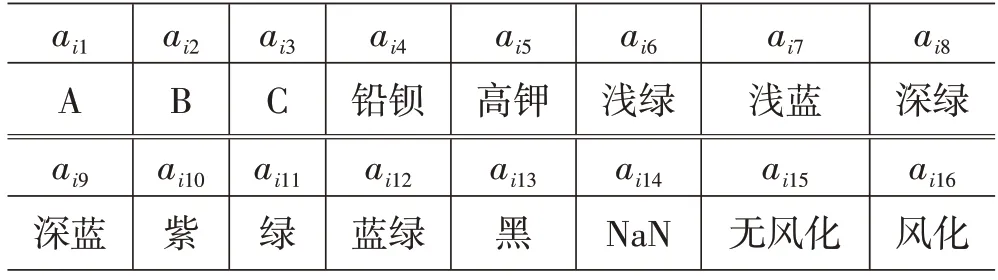
表2 各文物属性特征编码含义
如上,(ai1,…,ai3)为纹饰属性,(ai4,ai5)为类型属性,(ai5,…,ai14)为颜色属性,(ai15,ai16)为表面风化属性。其中,对任意的ain,其值为1 时,意味着在第i个文物编号下具有第n个属性特征,反之则代表不具有对应特征。
2)编码结果
综上所述,对附件表单1中的文本数据进行编码,考虑颜色类型可能由于风化程度的原因导致有部分数据为空,于是对应有其一个特征编码。对所有的特征进行编码后,矩阵onehot有如下所示:
3)对编码结果的卡方检验
为保证各数据的有效性,需要对上述编码结果进行卡方检验。研究上述各特征之间的相关关系,卡方值越小,即代表各特征之间的偏差程度较低,各编码对风化的影响程度较高。于是,利用SPSS 对上述各编码与风化之间进行卡方检验,对应有如下表格:
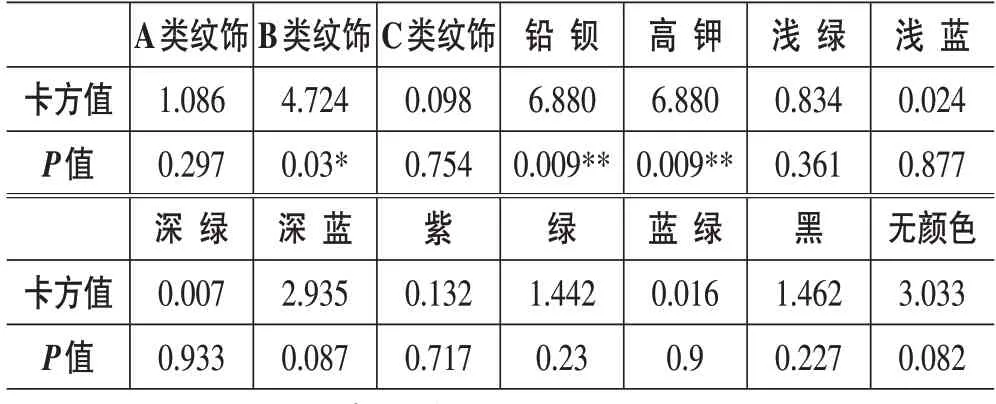
表3 各文物属性特征卡方检验
4)logistic回归分析
依据上述向量化的数据与卡方检验结果,需要考虑部分变量对于回归可能无意义,且在相同类别的中国古代玻璃制品化学成分在风化前后可能发生改变,于是为研究各玻璃文物表面有无风化与其各项属性的关系,可以设有无风化为一个“0-1”变量wi,即将玻璃文物之间的各项属性与风化之间的关系转化为一个二分类问题。
①分析过程
首先将上述经过编码的文本数据导入Matlab 进行处理,为对其进行多元线性回归分析,需要在首列插入一个全1列。随后利用Matlab中的regress函数求得其对应的各项系数,并得到其残差值。于是,可以得到如下多元线性回归函数:
其中,β0为常数项,βl和xl分别为变量系数和解释变量,ε则为误差项。于是,考虑到logistics回归模型的特性,设pi为第i组文物编号风化的可能性,结合上述函数有:
于是变换后对应有:
综上,依据其文物编号风化的可能性表达,分别对整体数据,高钾类型和铅钡类型进行logistics回归分析。同时选择其可能性的阈值为0.5,即pi在不同阈值对应的文物有无风化,所以设wi为第i组文物编号有无风化,于是有对应结果如下所述:
此外,对于高钾类型和铅钡类型做logistics回归分析时的向量集应提前剔除全0列。于是对上述得到的编码矩阵进行数据清洗,其中保留各类类型对应编码做对照实验,若回归结果对其不产生依赖,则代表回归模型具有一定合理性。
②分析结果
将上述各项数据带入分析过程中,可以得到其对应的相关系数及残差项,其中对各项残差做残差分析有如下所述:
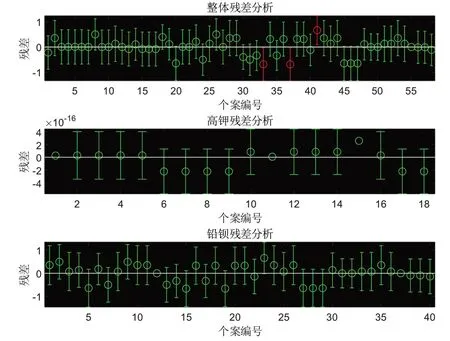
图1 残差分析图
从上可以看出,在整体残差分析中存在有3 个离群点,而对应高钾及铅钡的残差分析当中残差状态均较良好。其中对于整体残差分析得离群点,其分别为文物编号33、37和41项。对附件表单1进行分析不难发现,其离群的原因为与33、37 属性相同的34、35、38、39号数据均为风化,而其则为无风化;41号数据则对应有32 号,35 号数据与之对应有属性相同但风化属性不同。所以可以认为上述三点为离群点但不必剔除。综上,有三组不同logistics回归模型如下:
如上,对应整体的logistics回归函数ponehot中,ε为随机误差项,βi依次为:0,1.0055,0.224,0.7923,0,0.3333,0.8705,0.6846,0.6202,0.5,0,1.0109,1.224,1.112。其中对应纹饰_A,类型_高钾和颜色_绿属性特征在回归中没有贡献,即上述值不影响有无风化,可以选择将其剔除。
上述为对应高钾的logistics回归函数pk。其βi依次为:-1.82×10-18,1,0,0,1.71×10-16,2.48×10-16,0,2.29×10-16。其中对应纹饰_C,类型_高钾和颜色_深蓝属性特征在函数中不影响有无风化,在回归时可以相应剔除。
此外,有对应铅钡的logistics回归函数pPbBa如上。其βi值依次有:-0.2769,0,0,0.0564,0.6462,0.3897,0,0.2231,-0.2769,0.8154,1,0.8615。其中对应纹饰_C,类型_铅钡和颜色_深蓝属性特征不影响回归函数的结果,故可以考虑剔除。
综上可以发现,对各类型的回归效果及无关因素均不相同,所以考虑对其实际效果进行验证,其中ε为文物编号对应的残差项。
③logistics回归逆向验证
对应上述三类回归函数,为验证表面风化与其相关因素关系的有效性,尝试利用上述向量化后的特征矩阵onehot,对“高钾”和“铅钡”属性进行带入,研究其结果是否对应表面风化情况,于是以pK为例,其中高钾测试结果如下:
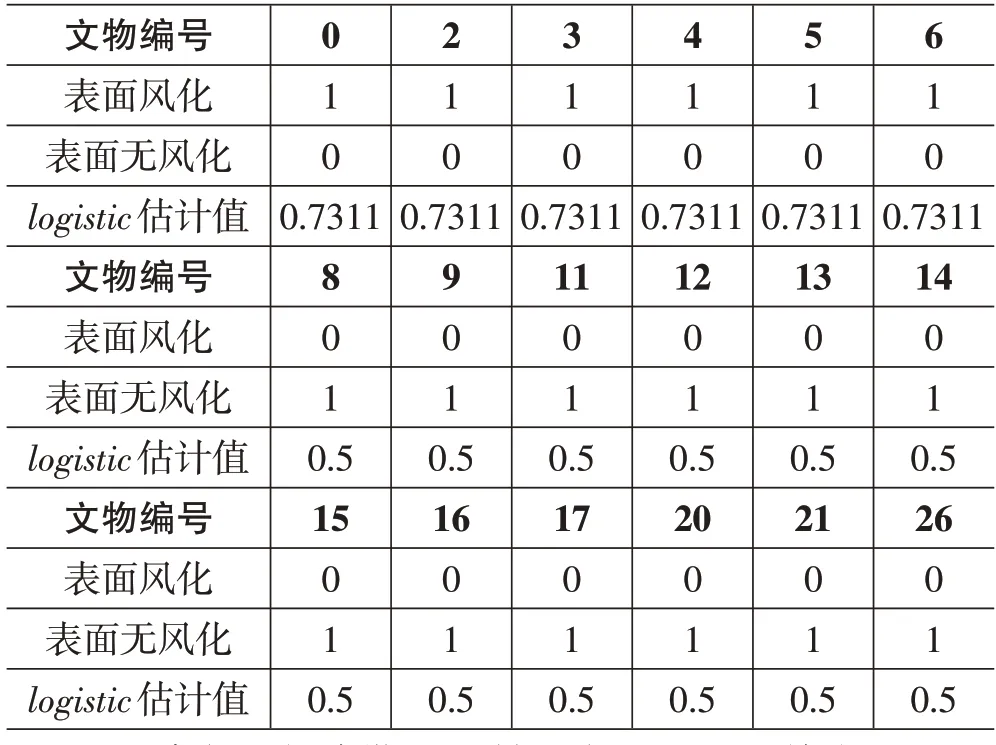
表4 高钾测试结果
用“高钾”表单带入后结果如上所述,其中已按照logistic估计值大小进行排序。此外,以表面风化为原假设,对应原假设的logistic估计值大于0.5 的部分视为假设成立。可以看到,其中上述表格的结果中满足预设阈值要求,以阈值为0.5 和0.7311 对测试结果进行区分,由于其为一个二分类的回归模型,在其中logistic估计值较大的一方视为1,较小的一方则是为0,经由上述结果测试可知,该回归函数拟合较好,测试集的准确率为100%。
5)预测风化前化学成分含量
对各风化文物的化学成分含量进行研究,依照上述得到的logistic回归对文物表面采样点进行测试,将采样点未知风化的进行确定,并依照对应风化前后成分变化数据,求得该文物的风化化学成分含量转化率,并基于此预测其在风化前的化学成分含量,其中由于数据量较大,所以此处以54号文物的化学成分预测为例,如下:
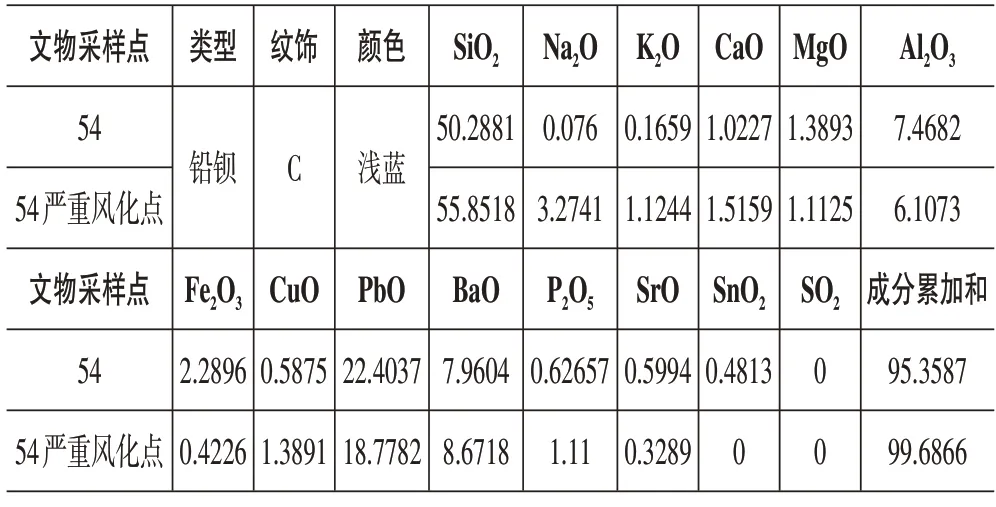
表5 54号文物风化前成分预测
此外,考虑到不同颜色对应的化学含量关系不同[2],对其附件的四个未知颜色的化学含量进行判别,经过判定后可知:文物编号19为深绿、文物编号40为紫色、文物编号48和58为浅绿。
2.2 对玻璃文物类型的分类方法
在本节中,需要依附附件数据研究两类玻璃的分类规律,并以各不同的化学成分对其进行亚类划分,建立相应的划分模型,设计相应算法求解划分结果,并研究模型的灵敏度和合理性。
1)分类准备
为考虑研究不同玻璃对应的分类规律,需要分析高钾与铅钡中分类特征。于是对高钾玻璃及铅钡玻璃中钾含量和铅、钡含量进行对照[3],基于此对其进行类别划分,所以对附件表单2中的相关数据进行可视化,建立三维散点图对其进行相关分析,具体图像如下:
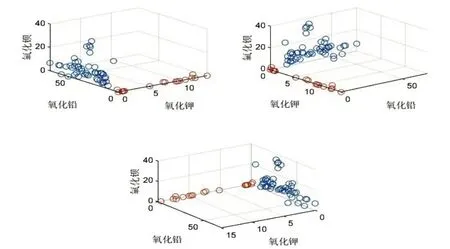
图2 高钾与铅钡的化学含量比较散点图
上图中,浅灰色“o”为铅钡类型对应的相关含量,深灰色“o”为高钾类型对应的相关含量。可以看出,其中以原点为分割,其中相对含量较为明显。此外,对于各类类型对应的化学含量可能存在缺失值,于是考虑建立决策树分类模型对各玻璃类型进行明确划分。
2)决策树分类模型
由于玻璃的各项化学成分中,有部分数据为缺失值,若使用logistics回归模型将无法较好的进行类型划分。而对于机器学习的决策树模型,由于其基于树结构来进行决策,所以针对此类问题通常会进行一系列的判断或子决策,最后综合得出最终决策,即判断玻璃的类别。最终结果应当对应的正确的判定结果。由于最终的结果为二分类,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点;叶结点对应于决策结果,其他每个结点则对应于一个属性测试。由于数据属性为不同化学成分的含量,决策结果对应玻璃类别。综上,基于python的构建决策树模型如图3所示。

图3 决策树分类模型
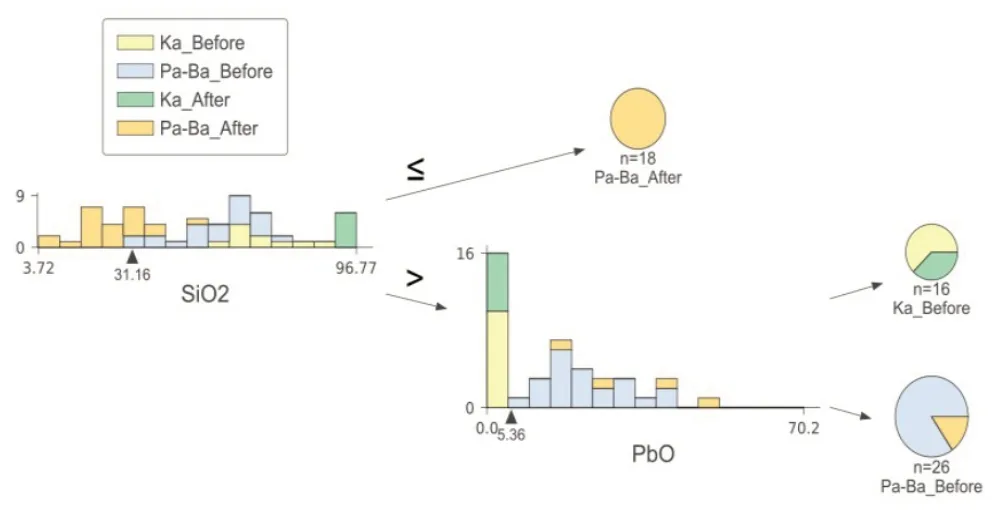
图4 深度2时决策树分类结果占比示意
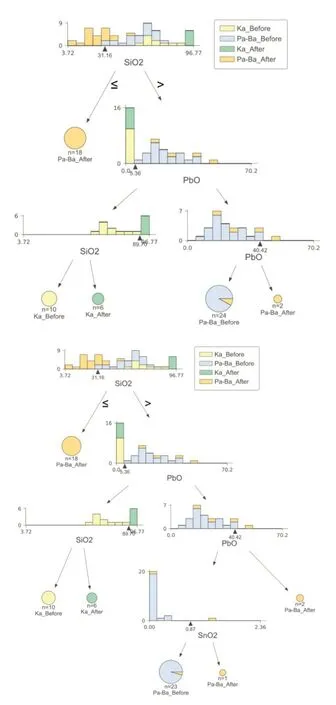
图5 深度3(上),4(下)时决策树分类结果占比示意
其中,Ka_Before和Pa-Ba_before分别为高钾类与铅钡类风化前对应的类别,Ka_After和Pa-Ba_After则对应高钾类与铅钡类风化后对应的类别。中间靠上的化学式则为当前需要判断的决策变量,其与决策值进行判断,若小于则通向左子树,反之通向右子树。
3)分类结果
其中,结合上述计算步骤,利用决策树中得到的答案对于上述表6中的A1-A8玻璃文物进行分类,其依次均分别为高钾类、铅钡类、铅钡类、铅钡类、铅钡类、高钾类、高钾类、铅钡类。
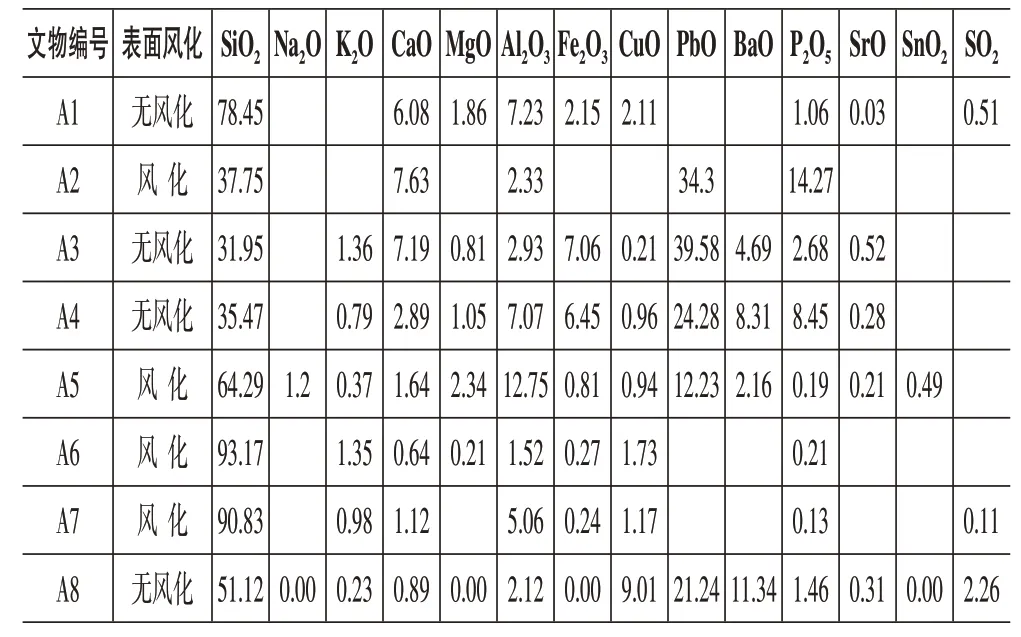
表6 分类测试集
4)敏感性分析
决策树中的重要参数为树的深度,在训练时不断更改树的高度,并对比不同树的深度时的分类情况。由于所选决策树模型的分叉为二叉树,因此,当树的深度小于二时,无法将四个分类完全区分开。故敏感性分析从树的深度为2开始讨论。可以看到当深度为二时,预测未能将所有的类都分开,预测的准确度只有83.33%,其中具体图像如下:
其中,当深度为3 时,其分类的出错率为0.033,当深度为4时出错率0.015,具体图像如下:
依据上述不同深度对应的分类出错率,最终经多次试验后可以确定,当深度为5即以上时错误率维持在0%,其准确率随深度的变化趋势如图6:
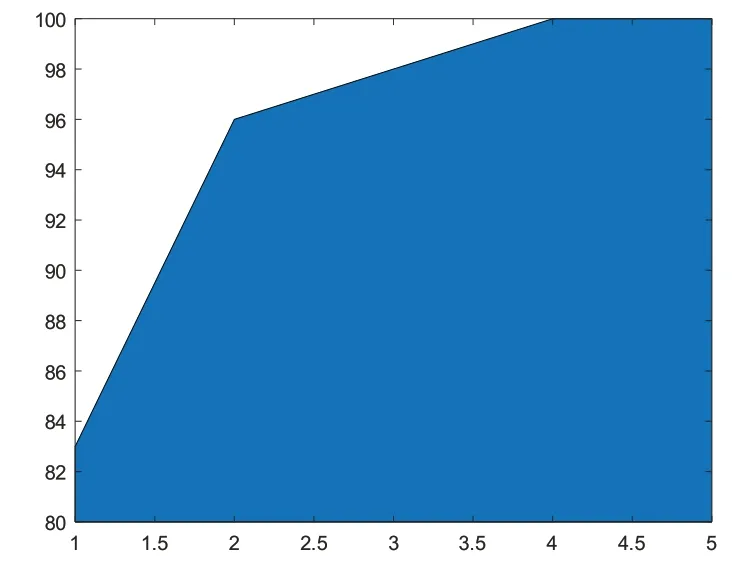
图6 分类准确率随树深度变化示意图
3 结论
为了更好地对中国古代玻璃制品的风化前后成分进行分析,考虑研究各玻璃文物的化学成分含量的统计规律,并基于此预测风化前化学成分含量。随后在上述成分分析的前提下,同时考虑到决策树可能存在的过拟合情况,对决策树在保证其准确率的前提下尽可能避免生成决策树复杂。最终在实际判断中国古代玻璃制品的类型时可以较高效率地完成区分。
