融合知识图谱的矩阵分解推荐算法
2023-11-06周巧扣倪红军
周巧扣,倪红军
(南京师范大学泰州学院信息工程学院,江苏泰州 225300)
0 引言
随着互联网技术的蓬勃发展,产生了海量的数据信息,为了帮助人们快速有效地筛选信息,个性化推荐系统应运而生[1]。推荐系统从用户的历史行为和数据出发,建立相关的模型挖掘用户的需求和兴趣,并以此为依据从海量信息中为用户筛选出用户可能感兴趣的信息。然而,传统的推荐算法通常存在数据稀疏以及冷启动等问题,影响推荐算法的性能,需要借助一些辅助信息来提升推荐算法的性能,例如,用户的社交网络,项目的文本信息以及图片信息等[2-4]。知识图谱(Knowledge Graph,KG)是由知识组成的有向异构信息网络,其中包含了大量的实体和关系,蕴藏了丰富的实体之间的结构信息和语义信息,将知识图谱融入推荐算法中,能够更加精确地建模用户偏好与项目特征,从而可以较大程度上提升推荐效果[5]。
本文在矩阵分解算法[6]的基础上,提出一种融合知识图谱的矩阵分解推荐算法(Matrix Factorization Based Knowledge Graph,MFBKG)。
1 问题定义及相关算法
1.1 数据定义
用户集合、项目集合以及知识图谱可以使用一个四元组表示S=
1.2 矩阵分解算法
矩阵分解算法通过将用户评分矩阵X 使用机器学习的方法分解为一个代表用户偏好的用户矩阵P和一个代表被推荐项目特征的项目矩阵Q,用户矩阵中的行向量和项目矩阵中的列向量的点积即为行向量用户对列项目的评分。定义如公式(1)所示:
μ为所有项目的总平均分,bu为用户偏置项,bi为项目的偏置项。
1.3 融合知识图谱的矩阵分解推荐算法
TransH 算法[7]是一种知识图谱表示学习算法,通过训练可以得到知识图谱中实体和关系的低维向量,然后计算实体之间的相似度,本文中计算相似度的方法采用余弦相似度公式,设Bi和Bj分别为项目oi和oj在知识图谱中对应的向量表示,则项目oi和oj的相似度计算方法如公式(3)所示:
计算出项目之间的相似度后,在MF 算法优化函数中,增加项目隐因子向量qi与其近邻集合中所有项目隐因子向量的均值差的二阶Frobenius 范数这个限制条件,这样算法中参数的学习将受到两个方面的限制:1)学习评分值应该尽可能接近实际的评分值。2)项目的隐因子向量应该与知识图谱中与其语义相近的项目的隐因子向量尽可能接近。改进的算法优化函数如下所示:
通过增加语义限制条件,使得即使在评分数据比较稀疏的场景中,算法中的参数也能得到很好的优化,从而训练得到的用户隐因子和项目隐因子也更加精确。与MF 算法一样,文中也采用随机梯度下降的方法学习算法中的参数。
算法1 MFBKG算法
输入:用户评分矩阵X、知识图谱G、隐因子向量维度d、正则项参数λ、平衡因子α、学习率η、最大迭代次数Z
输出:用户隐因子矩阵P和项目隐因子矩阵Q
1.使用TransH 算法计算G 中实体及关系的低维向量
2 实验结果及分析
2.1 实验数据集
文中采用文献[5]中的电影数据集,该数据集在MovieLens-1M数据集的基础上采用Microsoft Satori构建数据集的知识图谱。数据集中包含:2 347个实体、20 782组关系、1 000 209条用户对电影的评分。实验采用5-fold交叉验证,训练集所占比例为80%,测试集所占比例为20%。
2.2 评价标准
本文针对所提算法采用的评价指标是平均绝对误差(MAE)和均方根误差(RMSE)。MAE 和RMSE 的值可以通过计算项目的预测评分与实际评分之间的偏差得到,值越小证明算法的推荐精度越高。
2.3 参数设置
MFBKG算法中包含多个超参数,如:迭代次数Z、学习率η、正则项参数λ、平衡因子α、隐因子向量维度d。实验中参数值设置为:Z=50、η=0.001、λ=0.01,TransH算法中实体和关系向量的维度为100。
2.4 实验对比
将本文提出的MFBKG算法与概率矩阵分解算法(PMF)[1]以及SVD++[6]算法进行对比实验。
2.4.1 算法性能分析
实验中设定隐因子向量维度d分别为:10、20、30、60、80、100、120,三种算法在MAE 性能指标的对比如图1 所示。PMF 算法在d为30 时达到最优为0.691,SVD++算法在k为80 时达到最优为0.683,MFBKG 算法在d为60时达到最优为0.678。三种算法达到最优后随着d的增加,性能不同程度的降低。
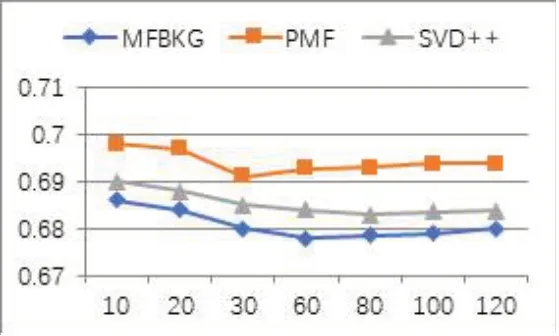
图1 三种算法MAE性能对比
相同的设置下,三种算法在RMSE 性能指标上的对比如图2 所示。PMF 算法在d为30 时达到最优为0.877,SVD++算法在d为80 时达到最优为0.870,MFBKG算法在d为60时达到最优为0.864。
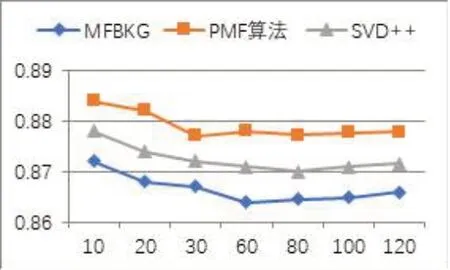
图2 三种算法RMSE性能对比
从MAE和RMSE两种性能指标的对比分析看来,SVD++算法和MFBKG 算法要明显优于PMF 算法,这是因为PMF算法只考虑了评分矩阵的分解,没有考虑其他辅助信息,SVD++算法在评分矩阵的基础上考虑了用户的隐式反馈,对算法的性能有所提升,MFBKG算法在三种算法中最优,表明知识图谱所包含的语义关系对推荐算法的性能提升最大。
2.4.2 α值对算法性能的影响
参数α控制MFBKG 算法中项目之间语义关系对算法整体性能的影响力度。其值越大表明矩阵P和Q受项目之间语义关系的影响就越大。如图3所示,当α为0 时,MFBKG 算法退化为SVD 算法,当α为0.4时,MFBKG算法性能达到最佳,之后随着α值的增加,性能逐渐下降。
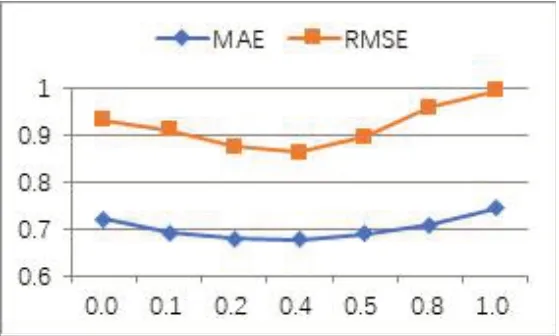
图3 α值对MFBKG算法性能的影响
2.4.3 近邻集合的数目N对算法的性能的影响
N 的值也会对MFBKG 算法的优化过程产生影响。图4 显示了随着N 值的增大,算法在MAE 和RMSE上的表现越好,当N达到60时,性能达到最优,此后算法性能趋于稳定,因为随着项目邻域集合的增加,它们与项目之间的语义关联越弱,因而对推荐算法性能的提升越小。
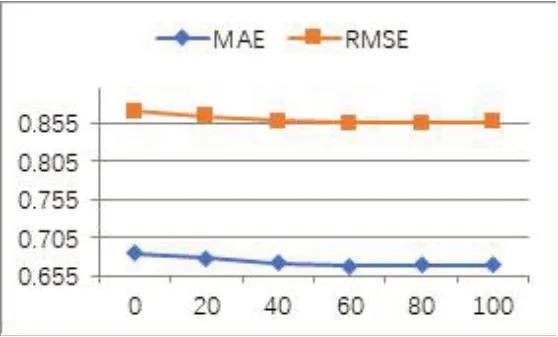
图4 近邻集合的数目N对MFBKG算法性能的影响
3 结束语
本文主要研究了将知识图谱表达的语义关系融入矩阵分解推荐算法中,以提高推荐算法性能的方法。首先利用TransH 算法将知识图谱中的实体和关系转为包含语义关系的图谱向量,接着计算实体之间的语义相似度,然后在矩阵分解推荐算法的优化函数中增加语义相关性对项目隐因子向量优化的限制,使得语义相似的项目隐因子向量应该更接近。最后在真实的数据集中,对提出的算法进行了性能测试并与其他相关算法进行了对比,实验表明本文提出的算法在MAE 和RMSE 性能指标上具有更好的表现。知识图谱所蕴藏的项目之间语义关系非常丰富,如何更有效地利用知识图谱提升推荐算法的性能是本文下一步研究的目标。
