一种基于长短期兴趣的推荐算法设计
2023-11-06时慧琨
时慧琨
(淮南师范学院,安徽淮南 232038)
0 引言
随着计算机、通信技术的发展,人类社会已经进入信息化时代,数字化、智能化已经成为社会发展趋势,人们已经能够从各种途径获取大量数据,如何从海量数据中得到用户需要的数据或知识成为用户面临的新难题,推荐系统应运而生。推荐系统对数据进行处理,根据用户的需求或兴趣筛选出用户需要的信息并推送给客户,为用户节省了时间,提高了信息获取的效率。如何根据用户需求提高推荐系统效率及用户满意度是各种推荐技术和推荐系统研究的重点。本文研究如何从用户历史会话信息中学习用户长期及短期兴趣,并利用其提高推荐的效果。
1 概述
1.1 推荐系统概述
推荐系统是从海量数据中帮助用户以较小成本获得感兴趣的物品或信息的系统,其基本原理是根据用户的特征或历史记录,再结合物品或信息的特征,对用户的需求目标进行预测,并推送给用户[1]。在推荐系统帮助下,用户对海量数据的处理转变为对推荐结果的处理,方便了用户,提高了数据处理的效率。推荐系统自从出现以来,已经在购物、新闻、视频等领域得到了广泛的应用。
推荐系统的核心是推荐算法,提高推荐算法的性能和推荐效果,可以从三个方面着手:1) 增加数据。数据量的多少决定了推荐算法性能的上限,大量学习数据是推荐模型尤其是大规模推荐模型性能的直接保证,而大规模的学习模型目前越来越流行。2)在数据尤其是有效数据无法增加的情况下,从推荐场景中挖掘利用更多的信息。推荐算法中常常考虑了物品、用户、场景上下文、过程等多方面的信息,除此之外,还可以利用知识图谱对信息进行扩展。3)采用不同的算法从数据中学习更多的知识。为此,推荐系统中常应用了多种算法,常见的包括基于协同过滤的算法、基于机器学习的算法、基于深度学习的算法、基于图的推荐算法等。
1.2 基于会话及用户兴趣的推荐
在推荐系统的研究中,如何对用户特征进行更加丰富、准确的刻画是研究的重点之一,这要求推荐系统不但要描述用户的静态特征还要考虑其动态特性,会话信息为此提供了有用的线索。会话是指用户与系统的一次连续完整的交互过程。会话为用户的行为增加了时间信息,由此产生了基于会话的推荐及基于序列的推荐。一次会话期间用户的行为隐含表示了用户的需求或意图,构成了用户的短期兴趣。在较长的时间段内,用户经常出现的短期兴趣则构成了用户的长期兴趣。兴趣的出现丰富了用户的特征表示,兴趣的变化则构成了用户的动态特征。因此,从会话序列中提取出用户的短期或长期兴趣,能够为推荐提供更多的信息,并有助于提高推荐的效果。
定义长期兴趣是指用户在跨越多个会话的较长时间内表现出的兴趣,短期兴趣则时间较短,通常用一个会话内的兴趣来表示。无论是长期还是短期兴趣,都具有多样性、变化性的特点。多样性,是指不同用户的兴趣千变万化,即使是同一个用户,也可能存在多种不同的兴趣。变化性是指用户兴趣通常都会随着时间的迁移而发生变化,只是长期兴趣保持的时间较长而已。如何对长期兴趣和短期兴趣进行表示,并在此基础上产生推荐是基于会话和兴趣的推荐系统研究的重点。
在基于序列和兴趣的推荐系统研究方面,目前已经有了一些研究的成果。DIN模型[2]对输入序列中的样本按照其与目标项的相关性进行加权计算,并作为每个样本的权重用于后期的处理;DIEN[3]模型使用一个GRU层提取用户的兴趣,并使用一个带有注意力机制的GRU层来获得兴趣的进化特征,在此基础上产生推荐信息。DSIN 模型[4]在DIEN 的基础上,对行为序列建模部分进行了改进,根据设定的时间间隔,将行为序列划分为不同的会话,分别对会话内和会话间的兴趣进行建模,利用自注意力机制提取会话内的兴趣,在此基础上,对会话间兴趣的演化利用Bi-LSTM进行建模,两者拼接得到用户最终的兴趣表征。MIMN模型[5]则重新设计了序列建模的结构,借鉴神经图灵机利用额外存储模块来解决长序列数据问题。模型中定义了行为细化层和多兴趣提取层,使用多头自注意力实现对用户多兴趣的提取。王鸿伟等提出的RMN 模型[6]则在循环神经网络中增加了兴趣记忆模块,增强了兴趣的表达能力。
DIEN模型中的兴趣是通过将用户的行为序列划分为长度较短的子序列,对子序列进行学习得出的,因此学习获得的是短期兴趣表示。本文的研究是在DIEN 模型的基础上,综合考虑了长期和短期兴趣的影响。通过对用户行为序列的学习获得用户短期兴趣,并通过短期兴趣的学习获得长期兴趣。综合利用长期兴趣和短期兴趣构造推荐模型,希望在更多信息的帮助下获得更好的推荐效果。
2 基于长短期兴趣的推荐系统设计
2.1 系统结构
本文提出的推荐模型结构如图1 所示,由以下几个部分组成:
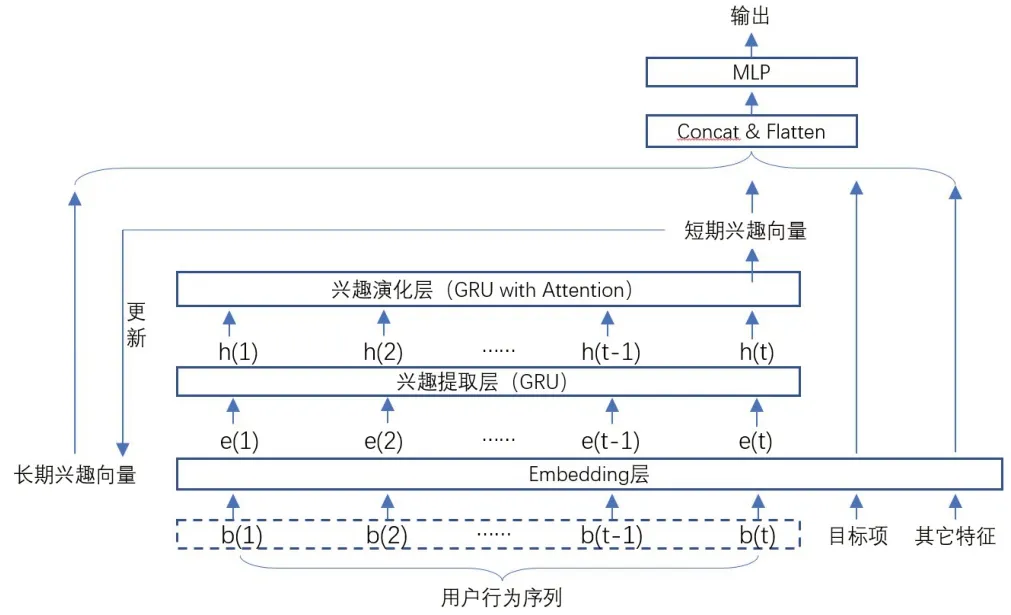
图1 基于长短期兴趣的推荐模型1
1)长期兴趣向量。由于用户兴趣的多样性特点,每个用户使用一个独立的向量表示用户的长期兴趣;
2)嵌入层。用于将one-hot等形式表示的用户交互记录、目标项及用户其他特征转换为稠密表示的嵌入向量。
3)兴趣提取层。以用户的行为序列作为输入,采用GRU(Gate Recurrent Unit) 模型从用户的点击记录中提取用户兴趣,为了增加兴趣表示的准确程度,利用正负样本构建辅助损失函数,提高兴趣学习的准确性。
4)兴趣演化层。为进一步提高模型对用户兴趣动态变化特征的学习效果,本层以兴趣提取层的输出作为输入,利用GRU 对其进一步学习,利用注意力机制计算各个阶段输出同目标项的相关程度作为更新权重,对输出结果进行加权后用于GRU 的更新,使得更新结果对用户感兴趣目标更加侧重,进一步提高了兴趣表示学习的效果。
5)MLP(多层感知机)。用于预测用户对目标项的行为。该层将用户长期向量、短期兴趣向量、目标项嵌入向量以及其他特征的嵌入向量拼接在一起作为输入,经MLP处理后得到最终输出。
在上述模型中,用户行为序列中的元素、目标项以及其他特征经过嵌入层处理后转换为嵌入向量,其中行为序列对应的嵌入向量经过兴趣提取层处理后转换为兴趣隐向量,再经过兴趣演化层的学习进一步获得兴趣的动态变化特征,经过注意力加权后得到用户的短期兴趣向量,将用户长期兴趣向量、短期兴趣向量、目标向量及其他特征进行拼接后送到最终的多层感知机处理得到最终的输出。同时,短期兴趣向量用于长期兴趣向量的更新以反应长期兴趣的变化特性。
除了以上结构外,本文还提出了另外一种模型,如图2所示。其中长期兴趣向量并不作为独立向量拼接送到MLP中,而是用于对兴趣提取层的隐向量进行初始化,这样对训练样本学习后得到的是综合了用户长期和短期兴趣的综合兴趣向量。除此之外与模型1相同。
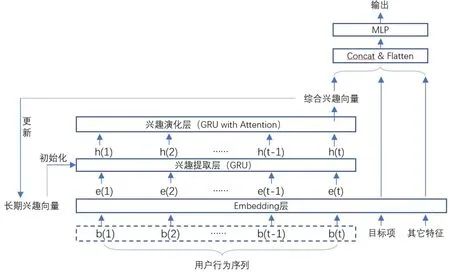
图2 基于长短期兴趣的推荐模型2
2.2 训练及测试过程
1)长短期兴趣的表示
本文用两个相同长度的向量来分别表示用户的长期和短期兴趣,长度值dim为一个超参数。长期兴趣向量用li(u)(u为用户ID)表示,短期兴趣向量由下文介绍的h(t)’表示,用于表示通过训练样本的学习而获得的短期兴趣,每次学习获得的短期兴趣是独立的,并且用于更新长期兴趣向量。
2)训练过程
①b(1),b(2),…,b(t)及目标项均为物品的ID,经过嵌入层处理后得到各自的嵌入表示e(1),e(2),…,e(t),e(target),其中e(i)(i=1,2,…,t,target)∈Rdim。
②兴趣提取层基于GRU对输入e(1),e(2),…,e(t)进行处理,得到输出h(1),h(2),…,h(t),这个输出一方面送给兴趣演化层作为输入,另一方面则用于构造一个辅助损失函数以提供学习更准确地兴趣表示。辅助损失函数构造的方法为:根据b(i),b(i+1)(i=1,2,…,t-1)的标注值是否相同构造训练目标,如果两者不相同则目标为0,否则目标为1。以e(i)和e(i+1)为输入,使用二分类交叉熵损失函数(BCELoss)拟合该目标,假设系统总的损失函数为L,辅助损失函数为Laux,最终预测目标项的损失函数为Ltarget,则L=Ltarget+α·Laux,其中α是一个超参数。
③兴趣演化层以h(1),h(2),…,h(t)为输入,经过该层的GRU 处理后得到更新门输出u(t)和重置门输出r(t),利用当前物品i(t)和目标项e(target)计算注意力值at=softmax(i(t)·wa·e(target)),实际更新权值为u(t)’=at×u(t),利用u(t)’对隐层输出ht进行更新。
④兴趣演化层的GRU 模型最终输出h(t)’,将其与长期兴趣向量li(u)、目标项e(target)及其他特征拼接后送给MLP 进行最终处理。该MLP 由若干全连接层组成,输出一个softmax(2)对目标项用户是否喜欢做出预测,最终计算得到总损失函数L,利用反向传播更新各模型的参数。
⑤长期兴趣向量li(u)的更新。利用公式li(u)=li(u)+γ·h(t)’得到更新后的li(u),其中γ 为一个超参数,表示更新的权重。
3)模型评估及预测过程
模型评估及对新数据的预测过程和训练过程基本相同,区别在于此时兴趣提取层不计算辅助损失,也不利用损失函数反向传播更新模型的权值,但是长期兴趣向量仍然更新以实现用户兴趣的迁移演化。
3 实验及结果
3.1 测试数据
使用ml-1m数据集作为系统的训练和测试数据,该数据集为GroupLens 研究组根据MovieLens 网站提供的用户对电影的评分记录创建,其中包含了6 040位用户对3 952 部电影的1 000 209 条评分,评分值为1~5,将其中评分值>=4 转换成1 表示用户喜欢,否则转换为0。对每个用户的评分记录按照时间排序得到评分序列,并按照窗口值=6对其截取子序列从而得到用户的行为序列,其中前5项作为历史点击记录,最后一项作为学习目标。随机选取其中10%的数据作为测试集,其余为训练集。在随机选取时不进行乱序操作,从而保留用户的兴趣进化历史。
3.2 与其它系统的分析比较
以ml-1m作为数据集,系统中的超参数选择dim=128,α=γ=0.05,不使用其他特征,选择DeepFM、DIN、DIEN作为比较对象,以准确率作为评价指标,测试结果如下:
从表1 可以看出,在考虑了用户长期及短期兴趣特征后,推荐系统的性能相比其它模型有了很大的提升。和DIEN模型仅考虑用户短期交互系列提取的短期兴趣相比,模型中综合考虑了用户的长期与短期兴趣,对用户的兴趣表达更加丰富,推荐结果综合考虑了用户长期和短期兴趣的变化,在推荐结果上利用了更多的用户特征,从而获得了更好的系统性能。
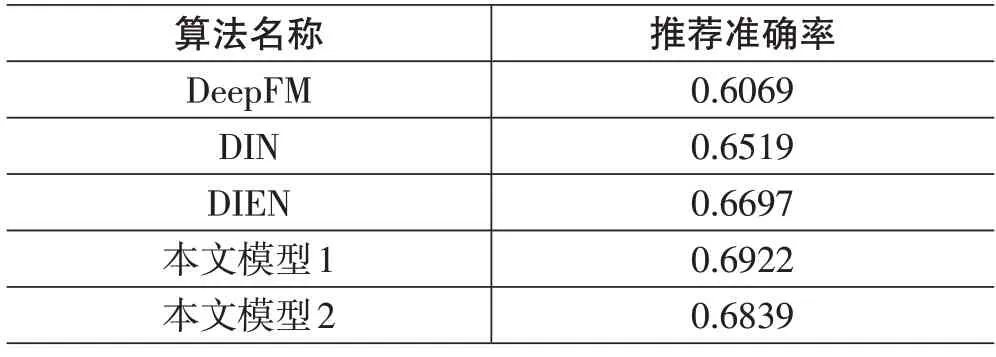
表1 算法性能测试结果
对本文提出的两种不同模型来说,一种构建了长期兴趣和短期兴趣各自独立的表示,拼接后送给最终的MLP 进行学习。另一种是将长期兴趣和短期兴趣综合后得到综合兴趣向量作为输入进行学习。实验结果表明,第一种采用长短期各自独立的兴趣表示其特征表达能力更强,系统的性能更好。
4 总结
本文提出了一种结合用户长期和短期兴趣的推荐算法。利用用户的交互记录建立短期兴趣表示,基于GRU模型建模用户的兴趣和兴趣进化过程,并在短期兴趣的基础上学习获得用户的长期兴趣,结合长期、短期兴趣及物品特征产生推荐结果。与其他模型相比,结合用户兴趣的推荐系统能够获得更加丰富的用户特征表示,帮助系统提升推荐效果。在下一步研究中,如何对用户长期兴趣的多样性进行建模是模型进一步改进的方向。
