基于物理信息约束的页岩油储层可压性评价新方法
2023-11-06李玉伟李子健邵力飞田福春汤继周
李玉伟,李子健,邵力飞,田福春,汤继周
(1.东北石油大学 石油工程学院,黑龙江 大庆 163318;2.辽宁大学 环境学院,辽宁 沈阳 110036;3.中钢集团马鞍山矿山研究总院股份有限公司,安徽 马鞍山 243000;4.中国石油大港油田分公司石油工程研究院,天津 300280;5.同济大学 海洋与地球科学学院,上海 200092)
页岩油作为一种重要的非常规油气资源,但页岩油储层属于低孔、低渗的致密储层,需要通过大规模压裂改造才能实现商业化开发[1]。准确进行页岩油储层可压性评价是开展压裂改造设计的重要前提,对于预测储层压裂改造效果、合理选择压裂井层和预测压后产能都有着十分重要的意义[2-3]。目前,采用各种岩石力学参数建立的多种可压性评价模型已被证明是非常有效的方法[4],但各种评价方法对参数的可靠性要求均较高,故准确获取页岩油储层岩石力学参数对于准确开展可压性评价至关重要[5]。
储层岩石力学参数通常采用岩心实验获取或通过现有经验公式进行估算[6]。实验方法通常工作量较大,且需对整个井段进行取心,对岩心质量要求很高,耗费大量时间和经济成本[7]。经验公式估算相较于实验方法降低了成本,但仍需要大量准确的岩石矿物组分、孔隙率和孔隙结构等参数作为支撑,这导致现有各类经验公式难以保证岩石力学参数估算的准确率。相比之下,机器学习方法只需通过少量取心实验结果,就可以实现对地层连续剖面的参数预测,在准确获取岩石力学参数的同时大大降低了时间和经济成本[8]。
用机器学习方法解决岩石力学问题最早可以追溯到20 世纪,1998 年P.E.Nikracesh[9]利用模糊逻辑模型在测井数据中发现了数据集之间结构关系,预测了沿地层深度变化的岩石力学参数,证明了机器学习方法相较于实验方法更加快捷高效。B.N.Alajmi 等[10]使用模糊逻辑系统推理和支持向量机方法,根据测井资料和实验数据来估计岩石力学参数,结果表明,机器学习方法预测准确率高于经验公式。为了提高岩石力学参数的预测精度,越来越多的优化算法被开发应用。C.M.Ruse 等[11]采用优化的梯度boosting(自适应)算法预测页岩的岩石力学参数,利用充足的地质测井数据集进行训练,将预测结果与实验数据进行对比,准确率可达90%,说明优化算法boosting 的实用性。研究人员不断对boosting 算法进行改进,Zhou Jian 等[12]使用boosting 算法的进化模型XGBoost 对岩石力学参数进行预测,并与随机森林、支持向量机和多层感知机等模型进行比较,结果表明,XGBoost 模型在预测岩石力学参数时具有较好的预测精度,但当数据量不足时,XGBoost 模型极易发生过拟合现象,无法被广泛应用。为了解决这一问题,Cao Jing 等[13]在XGBoost 模型的基础上提出XGBoost-firefly(萤火虫)优化算法间接估算岩石力学参数,使用支持向量机和XGBoost 算法来比较其模型性能,结果表明XGBoost-firefly 算法可以克服过拟合现象,但准确率并没有得到较大提升。随着现场工程技术发展,采集数据量不断增多,大部分机器学习模型无法应对庞大的数据集,为解决这一问题,神经网络作为机器学习的一个分支被提出。S.Dehghan 等[14]采用逻辑回归和神经网络预测岩石力学参数,研究发现神经网络模型在处理大批量数据时显示了比逻辑回归模型更高的性能。Z.Tariq 等[15]开发了包括神经网络、模糊逻辑和支持向量机3 种机器学习模型来估计石灰岩地层的岩石力学参数,采用162 口井的常规测井数据建立了弹性模量、泊松比和无侧限抗压强度的预测模型,研究结果证实了神经网络模型在数据量庞大的情况下完成既定任务时的优越性。机器学习方法在解决岩石力学问题方面已经取得了一些成果,但普遍建立在数据量充足的基础上,一旦出现数据量不足的情况,将会出现预测准确率低和泛化性差等问题,导致无法对岩石力学参数进行精准预测[16]。
数据的约束已经极大地限制了机器学习方法在岩石力学问题中的应用,为了解决这一问题,建立一种基于物理信息约束的神经网络模型,通过嵌入已有物理规律和经验模型的信息可以使神经网络模型在少量的训练数据集下整合基本物理定律和领域知识,达到规范和约束预测过程的作用[17]。首先构建物理信息约束的神经网络、随机森林、XGBoost 和人工神经网络4种学习模型,然后采用多种评价标准对4 种机器学习模型性能进行比较。优选性能最佳的模型对渤海湾盆地沧东凹陷K2 段不同井深的岩石力学参数进行预测,得到弹性模量、泊松比、抗拉强度和断裂韧性等参数,最后结合现有的储层可压性评价方法,实现对沧东凹陷K2 段不同储层的可压性评价。
1 研究方法
研究目标储层位于渤海湾盆地沧东凹陷K2 段地层,以往开展了连续取心工作,取心长495.71 m,岩心采取率99.14%,通过岩心矿物组成分析可以将储层划分成4 种页岩组构,分别为厚层状灰云质页岩、纹层状长英质页岩、纹层状混合质页岩和薄层状灰云质页岩(图1)[18-19]。本文研究方法可分为3 个步骤(图2),第一步数据工作,对测井数据和矿物组分数据进行特征选择和数据预处理;第二步模型选择,使用物理信息神经网络、XGBoost、随机森林和神经网络4 种机器学习方法对特征值与岩石力学参数之间的非线性关系进行拟合,采用多种评价标准对4 种机器学习模型性能进行对比评价,优选机器学习模型;第三步采用优选的机器学习模型对实际研究储层进行预测,使用预测得到的不同储层的岩石力学参数完成目标储层的可压性评价分析。

图1 渤海湾盆地沧东凹陷K2 段4 种页岩组构荧光薄片[18-19]Fig.1 Fluorescent thin sections of four shale fabrics in the K2 member of the Cangdong sag,Bohai Bay Basin[18-19]
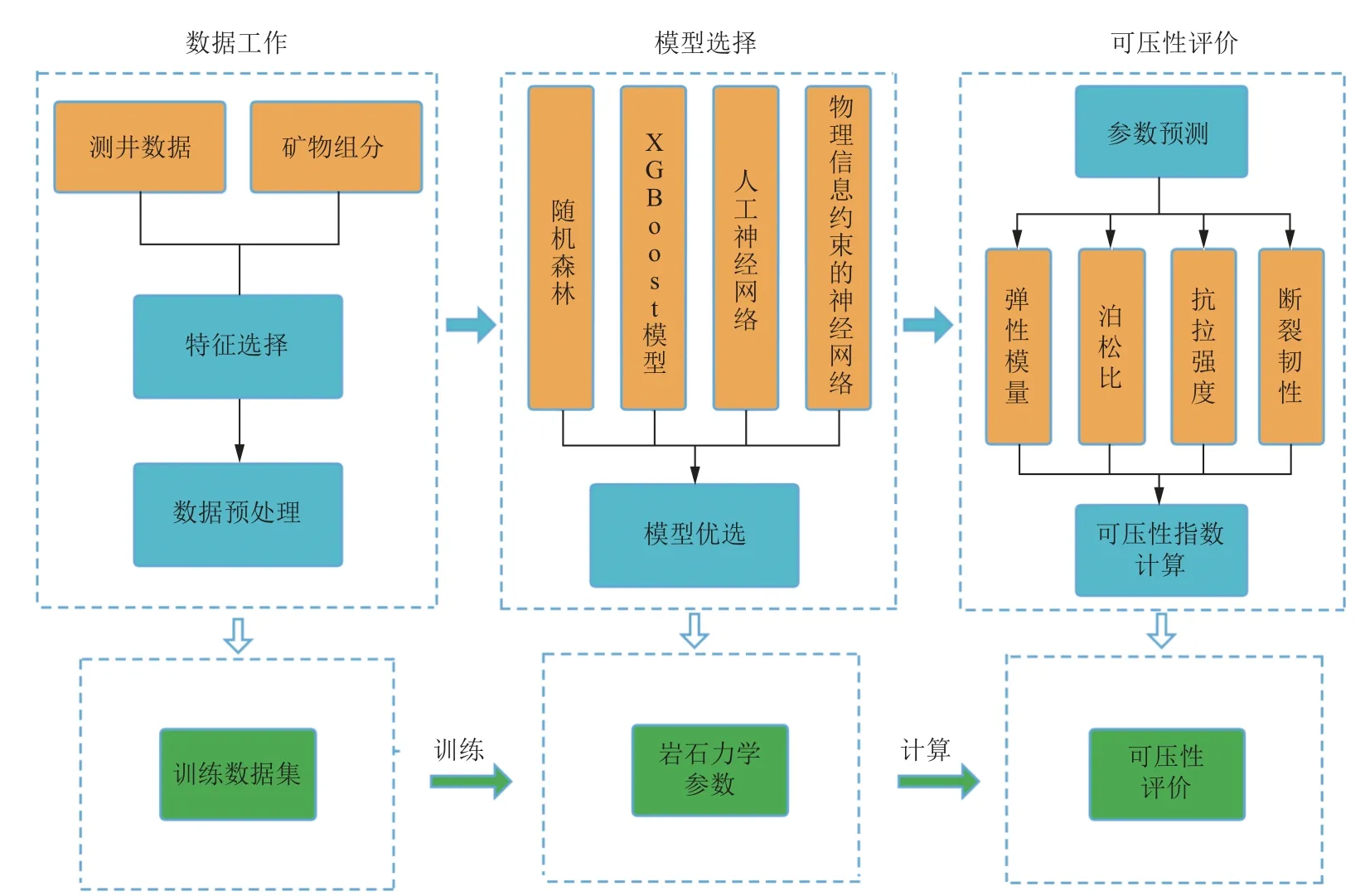
图2 渤海湾沧东凹陷K2 段储层可压性评价工作流程Fig.2 Workflow for the fracability evaluation of reservoirs in the K2 member of the Cangdong sag,Bohai Bay Basin
1.1 数据预处理
本文数据选自渤海湾沧东凹陷K2 段A 井页岩储层相关数据,A 井井位如图3 所示。研究使用的测井数据包括井深、横波时差和纵波时差,岩石矿物组分包含长石、石英、钙质、白云石、方解石、方沸石和黏土的含量,共计210 组数据。渤海湾沧东凹陷A 井3 009~3 214 m 单井柱状如图4 所示。

图3 渤海湾沧东凹陷A 井井位Fig.3 Map showing the location of well A in Cangdong sag,Bohai Bay Basin

图4 渤海湾沧东凹陷A 井3 009~3 214 m 单井柱状图Fig.4 Single-well stratigraphic column of well A at a depth of 3 009–3 214 m in the Cangdong sag,Bohai Bay Basin
采用Pearson 相关系数计算得到测井数据、岩石矿物组分数据与岩石力学参数之间的相关性。Pearson 相关系数是按积差方法计算,以2 个变量与各自平均值的离差为基础,通过2 个离差相乘来反映两变量之间的相关程度。Pearson 相关系数计算方法如下:别为对Yi样本的标准分数、样本平均值和样本标准差。Pearson 相关系数计算结果如图5 所示。
图5 中井深与弹性模量呈负相关性,相关系数为-0.83,井深在相关性排序中位于第一位,井深和岩石弹性模量之间存在一定的相关性,但并不是一种简单的线性关系。当沉积物、岩石等地层材料受到地质作用的影响,如挤压、折叠、断层等,它们的物理性质会发生变化。因此,井深可以作为一个间接指示因素,用于反映可能导致岩石力学参数变化的其他因素[20]。方沸石、石英与弹性模量的相关系数分别为0.71 和-0.38,其中石英和方沸石在相关性排序分别位于第二位和第六位。通常情况下,石英与弹性模量呈正相关性,然而岩石中石英含量和弹性模量之间的关系是复杂的,需要结合多种因素进行分析。当岩石中存在其他矿物质,这些矿物质的硬度和弹性模量也会对弹性模量产生影响,如钙质。在石英含量较低的情况下,其他矿物质的含量和硬度较高,可能会导致弹性模量升高,从而与石英含量呈现负相关性。王斌等[21]指出,方沸石与弹性模量呈高度正相关;石英却情况复杂,石英含量大于37%时,弹性模量随石英含量的增加而增大,在石英含量低于37%时,弹性模量随石英含量的增加而逐渐减小。与本文研究结论一致。图5 中黏土与弹性模量的相关系数为-0.6,在相关性排序中位于第三位,当岩石中含有大量的黏土矿物时,这些矿物会分散在岩石中,将岩石中的大颗粒分隔开来,形成微观孔隙。这些微观孔隙的存在会使得岩石的弹性模量降低,验证了本文相关性分析的正确性[22]。纵波、横波时差与弹性模量的相关系数分别为-0.53 和-0.4,在相关性排序中分别位于第四位和第五位,在岩石中,纵波时差和横波时差可以用于测量岩石的物理性质,如弹性模量和剪切模量。对图5 分析可以发现,井深、横波时差、纵波时差、黏土、方沸石和石英含量与弹性模量的相关性最高,用于弹性模量预测输入参数,其他参数与弹性模量的相关系数均不超过0.35。
图5 中黏土与泊松比的相关系数为0.59,黏土在相关性排序中位于第一位,岩石中的黏土含量越高,其孔隙结构越复杂,孔隙连通性越好,岩石的泊松比也会相应地增加[23]。横波、纵波时差与泊松比的相关系数分别为0.54 和0.59,纵波时差在与泊松比的相关性排序中并列第一位,横波时差位于第四位,波在弹性介质中传播的方式与介质的力学性质密切相关。泊松比越小,说明介质在受力作用下的体积收缩能力越小,而横波和纵波在介质中传播时,都会引起介质的体积变化[24],验证了本文相关性分析的正确性。井深与泊松比的相关系数为0.58,井深在相关性排序中位于第三位,井深依然是影响岩石力学参数的间接因素。方沸石与泊松比呈现最大负相关性,相关系数为-0.38,在相关性排序中位于第五位。方沸石的存在会导致岩石中的孔隙形态和大小发生改变,使得岩石的体积变化程度较小,从而使得岩石的泊松比较小[25]。由图5 可知,井深、横波时差、纵波时差、方沸石和黏土含量与泊松比相关性最高,其他参数与泊松比的相关系数均不超过0.35。
由图5 可知,抗拉强度、断裂韧性与参数之间的相关性均处在-0.31~0.45,不同参数与抗拉强度和断裂韧性的相关性没有明显差距,因此在预测抗拉强度和断裂韧性这两种参数时选择所有的数据作为输入参数。各岩石力学参数所对应的输入参数见表1。

表1 4 种岩石力学参数预测时输入参数的选取Table 1 Input parameters for the prediction of four rock mechanical parameters
为了解决数据量纲不一和数据异常而产生拟合效果差等问题,采用E-score 标准化(式(2))和K 近邻插补法(式(3))对数据集进行数据预处理。
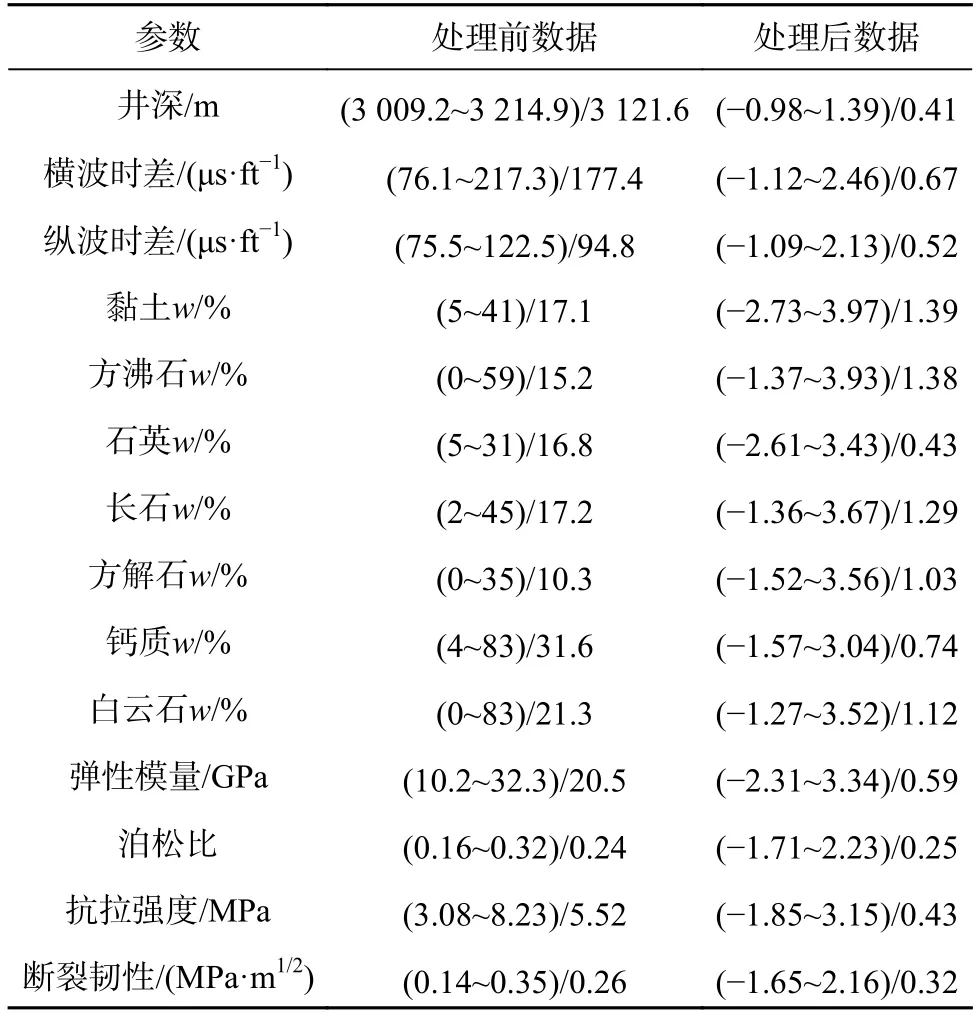
表2 数据处理前与数据处理后对比Table 2 Data pre and post processing
1.2 模型选择
1.2.1随机森林模型
随机森林[26]作为集成学习bagging(装袋法)的优化学习算法,利用集成学习的思想将多棵CART 决策树(Classification and Regression Tree)进行集成的一种算法。随机森林需要通过大量的基础树模型找到最可靠的结果,最终的预测结果由所有树模型共同决定。为了解决单一决策树的误差和过拟合问题,通过不同的决策树应用随机处理的方法建立算法,森林中各个决策树彼此互不关联,为单一的个体。随机森林基本原理如图6 所示。
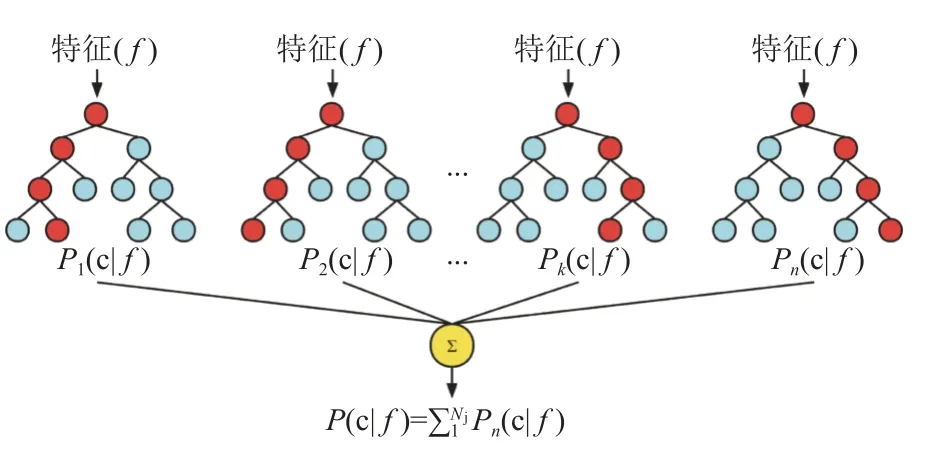
图6 随机森林算法工作流程Fig.6 Workflow of the random forest algorithm
1.2.2XGBoost 回归模型
XGBoost[27]模型作为一种集成学习方法,其对应的基学习器就是一堆决策树,将每棵树的预测值加到一起作为最终的预测值。XGBoost 将损失函数的二阶泰勒公式作为其替代函数,求解其最小化来决定回归树的最优切分点和叶子节点输出值,同时,XGBoost 在损失函数中引入子树叶节点数值和子树数量等,充分考虑到了正则化问题,能够有效避免过拟合。在效率上,XGBoost 通过利用独特的近似回归树分叉点估计和子节点并行化等方式,加上二阶收敛的特性,建模效率较一般的GBDT(Gradient Boosting Decision Tree)有了大幅提升。
1.2.3人工神经网络
神经网络作为一种计算模型,由大量的神经元(节点)相互连接构成,每个神经元代表一种特定的输出函数,称为激活函数,每两个神经元间的连接都代表着一个通过该连接信号的加权值,称之为权重。网络的输出则取决于网络的架构、连接方式、激活函数和权重。而网络自身通常是对某种算法或者函数的逼近,也可能是对一种逻辑策略的表达[28]。本文构建的人工神经网络架构的主要思想如图7 所示。
1.2.4物理信息约束的神经网络
1) 物理信息
由纳维·柯西方程变形得到弹性模量的经验公式,该公式利用声波测井的横纵波时差数据和体积密度资料得到弹性模量,公式适用于硬脆性地层[24],公式如下:
式中:E为弹性模量,GPa;ρ为体积密度,g/cm3;Δts为横波时差,μs/ft;Δtp为 纵波时差,μ s/ft 。当ρ=0时,式(4)—式(5)转化为:
式(4)和式(5)为弹性模量的经验公式,式(6)和式(7)为边界条件,两者共同构成弹性模量的经验模型,该经验模型作为物理信息嵌入神经网络中,对弹性模量的预测过程进行物理约束。
纳维·柯西方程变形依旧可以得到泊松比的经验公式[25],公式也适用于硬脆性地层。利用横波和纵波的时差得到泊松比的经验公式及其偏导形式:
式中:μ为泊松比。由式(8)可知,当Δts=0,泊松比为1,当Δtp=0,泊松比为1/2,可以得到式(11)和式(12)。
通过偏导公式(9)和式(10)可以看出,当Δtp=Δts=0,可以得到关系式(13)和式(14)。
式(8)-式(10)作为泊松比的经验公式,式(11)-式(14)作为边界条件,两者共同构成泊松比的经验模型,该模型将作为物理信息嵌入神经网络中,对泊松比的预测过程构成物理约束。
金衍等[29]在研究深部页岩储层岩石力学参数时,利用弹性模量作为中间变量计算岩石抗拉强度,得到经验公式:
式中:σc为抗压强度,MPa;Vcl为泥质含量,%;σt为抗拉强度,MPa;K为岩石抗压强度比例系数。由式(6)和式(15)可知,当ρ=0 时,E=0,即 σc=0,最终得到σt=0,因此可以得到:
式(15)和式(16)作为抗拉强度的经验公式,式(17)作为边界条件,两者共同构成抗拉强度的经验模型,该模型将作为物理信息嵌入神经网络中,对抗拉强度的预测过程进行物理约束。
满轲等[30]在研究渤海湾沧东凹陷板块深部页岩储层岩石力学参数时,利用横纵波时差相关数据计算岩石断裂韧性,得到经验公式如下:
式中:KIC为断裂韧性,MPa·m1/2。由式(18)和式(19)可知,当 Δtp=0 时,KIC=0.387,当 Δts=0时,KIC=0.349,关系式如下:
式(18)和式(19)作为断裂韧性的经验公式,式(20)和式(21)作为边界条件,两者共同构成断裂韧性的经验模型,该模型将作为物理信息嵌入神经网络中,对断裂韧性的预测过程进行物理约束。
2) 网络架构
物理信息约束的神经网络模型可以分为两个部分,第一部分通过构建全连接神经网络计算得到目标值,这里产生的损失函数用于衡量神经网络模型得到的预测值与真实值之间的误差;第二部分通过自动微分将经验模型嵌入神经网络模型中,这里产生的损失函数用于衡量预测值不满足物理信息约束所产生的误差。图8 展示了预测泊松比的物理信息约束的神经网络,其他3 种岩石力学参数预测过程与之类似。
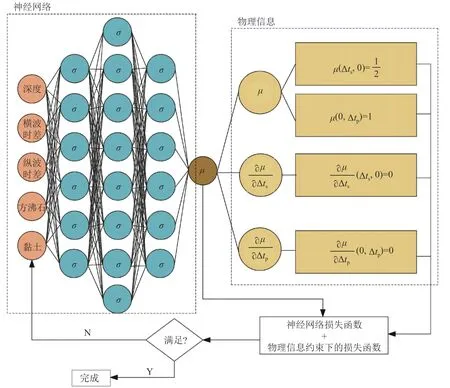
图8 物理信息约束的神经网络Fig.8 Physics-informed neural network
如图8 所示,采用物理信息约束的神经网络预测泊松比的过程如下:
(1)除现有的数据集外,需要另外定义两组数据,每组数据量都为210 个,第一组数据假设横波为0,其他输入特征在现有数据集的范围内随机取值,该组数据用于满足边界条件式(11)和式(14)。第二组数据假设纵波为0,其他输入特征在现有数据集的范围内随机取值,该组数据用于满足边界条件式(12)和式(13)。
(2)构造一个神经网络,其中输入层为深度、横波、纵波、方沸石和黏土,输出层的目标参数为岩石泊松比。
(3)构造损失函数量化在物理信息约束下预测泊松比与真实泊松比之间的残差。
(4)训练神经网络,通过损失函数梯度调整神经网络的权重和偏置项来确定泊松比,使预测泊松比和真实泊松比之间的误差最小化。
在第(2)步中,构建了一个具有3 层隐藏层的全连接神经网络,隐藏层中的神经元数量必须随输入和输出的数量缩放。在隐藏层中采用了6、8 和6 个神经元,在复杂场景中则需要更多的神经元。所有隐藏层均采用ReLU 激活函数:
式中:x为神经元的输入;ReLU(x)为神经元的输出。
在第(3)步中,构造2 种损失函数,第一种损失函数为数据驱动下神经网络在预测过程中产生的误差,第二种损失函数为物理约束下预测结果不满足物理条件产生的误差,物理信息神经网络总的损失函数为两种损失函数的加权求和,由于在(1)中定义了两组数据用于满足物理信息中的边界条件,这两组数据的数量均与现有数据集相等,为了保证神经网络自身计算产生的误差与物理信息约束下产生的误差重要性一致,此处定义第一种损失函数的惩罚系数为2,第二种损失函数的惩罚系数为1,物理信息约束的神经网络损失函数表示如下:
式中:θ为神经网络权重;Fh为物理约束条件(经验模型);Lh(μ)为不满足物理信息的约束条件产生的误差;NNLoss(θ)为 神经网络的计算误差;α、β为惩罚系数;Loss为总体误差。
在第(4)步中采用目前非常有效的随机梯度下降算法(SGD),从样本中随机抽取一组,训练后按梯度更新一次,重复这样的过程,在样本量较大的情况下,不用训练完所有的样本就可以获得一个在可接受范围内的损失值。
1.3 评价标准
R2通常被称为决定系数,它量化了一个自变量与其他自变量之间的方差。R2是Pearson 相关系数r的平方,它衡量2 个变量X和y之间的线性相关性。R2的表达式如下:
式中:yi为 每个数据点的值;为平均值;yreg为回归模型预测的值。
本文还使用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE)对结果进行量化,表达式分别如下:
1.4 泛化性验证
机器学习模型的泛化能力是评价模型性能的一项非常重要的指标。在机器学习中使用训练集去训练一个模型,通常做法是定义一个损失函数,通过最小化损失函数的过程提高模型的性能。然而学习模型的目的是解决实际问题,单纯的将训练数据集损失函数最小化,并不能保证在解决一般问题时模型依然保持优秀的性能,甚至不能保证模型是可用的。
k折交叉验证方法很好地解决了这一问题,k折交叉验证是一种用于验证机器学习模型泛化能力的常见方法。其基本思想是将数据集分成k个互不重叠的子集,然后使用其中一个子集作为验证集,其余k-1 个子集作为训练集,重复k次这个过程,每次选择不同的子集作为验证集。最终,将k次的验证结果平均值作为模型的性能评估指标,以此评估模型在未知数据上的泛化能力。过程如图9 所示。

图9 k 折交叉验证流程Fig.9 The k-fold cross-validation process
这种方法可以很好地解决模型在单个数据集上过拟合或欠拟合的问题。当模型在训练集上表现很好,但在测试集上表现很差时,就会出现过拟合的问题。而当模型在训练集和测试集上表现都很差时,则出现欠拟合的问题。通过使用k折交叉验证,可以使模型在不同的训练集和验证集上进行多次验证,从而有效地评估模型的泛化能力。
1.5 可压裂性指数
本文采用页岩油储层岩石的脆性指数和力学参数对渤海湾盆地沧东凹陷K2 段储层可压裂性进行评价。根据国内外对页岩储层可压裂性评价的研究成果,脆性指数不仅能够衡量压裂改造的难易程度,还可以表示压裂后储层形成复杂裂缝网络的难易程度。页岩脆性指数高的地方一般对压裂改造的反映敏感,极易形成复杂的网状裂缝,页岩脆性指数低的地方则容易形成简单的双翼型裂缝。本文采用弹性模量和泊松比计算脆性指数,由于预测得到的弹性模量和泊松比均为动态参数,需要通过动静态转换公式对其进行转换,M.Slota-Valim[31]在研究页岩弹性特性时提出了动静态转换关系如下:
式中:Ej为 静态弹性模量;μj为静态泊松比。
研究区域目标储层页岩静态弹性模量为17~33 GPa,平均26 GPa,静态泊松比为0.14~0.27,平均0.19,采用R.Rickman 等[32]对脆性指数的研究成果,得到脆性指数计算公式:
式中:EBrit为 归一化的弹性模量;μBrit为归一化的泊松比;Brit为脆性指数。
袁俊亮等[33]采用脆性指数与力学参数对页岩油储层可压性进行评价,通过计算可压裂指数来表征储层压裂的难易程度(下式)。其在研究中指出页岩油储层的可压裂性与脆性指数呈正相关,与断裂韧性和抗拉强度呈负相关,评价效果理想,与本文的研究路线基本一致,因此采用该方法对渤海湾沧东凹陷研究区进行可压性分析。
式中:σt为抗拉强度,MPa;Frac为可压裂指数。
2 结果
2.1 岩石力学参数预测
本文通过4 种机器学习模型预测弹性模量、泊松比、抗拉强度和断裂韧性这四种岩石力学参数。模型选用了210 组数据,按8∶2 的比例分为训练集和测试集,训练集为168 组,测试集为42 组。使用4 种机器学习方法对数据集进行训练,对每种方法进行10 折交叉验证。表3 展示了4 种岩石力学参数在机器学习模型训练中的最佳、平均和最差性能,平均值显示了这些模型在测试数据集上的平均性能,这些指标对判断机器学习模型是否优异具有重要意义。此外,图10 显示了仅在测试阶段预测四种岩石力学参数时模型的性能,为了更直观地观察四种机器学习算法的性能,图11显示了沿井深变化所提出的模型对测试集数据的拟合能力,需要注意的是,由于划分测试集时的随机性,所以在预测四种岩石力学参数时,每个测试集中的数据点都各不相同。

表3 4 种机器学习模型预测岩石力学参数时的评价结果Table 3 Evaluation results of four machine learning models for predicting rock mechanical parameters

图11 机器学习模型对测试集数据的拟合能力沿井深变化Fig.11 Well depth-varying fitting ability of machine learning models for data in the test set
从表3、图10 和图11 可以看出,PINN 对岩石力学参数的预测相比于其他3 种机器学习模型更准确,预ERM测S和弹性R2模的平量均的值实分验别中为,P1I.N5 7 N、在1.6测4 和试阶96%段,的相比EM于A、XGBoost 模型、随机森林和神经网络的准确率分别高出5%、9%和10%。在泊松比的预测中,PINN的EMA、ERMS和R2的平均值分别为0.012、0.021 和95%,同样表现为最优异的模型,相比于XGBoost 模型、随机森林和神经网络的准确率分别高出5%、8%和9%。在抗拉强度的预测中,PINN 的平均准确率为95%,相比于XGBoost 模型、随机森林和神经网络准确率高出5%、10%和11%,性能均优于其他模型。在断裂韧性的预测中,PINN 的平均准确率为97%,相比于XGBoost 模型、随机森林和神经网络准确率高出5%、8%和11%。该结果说明了PINN相比较于随机森林、XGBoost 和人工神经网络在性能上具有优越性。
此外,PINN 在经过10 折交叉验证后,其在预测弹性模量时EMA、ERMS和R2的最值差距分别为0.26、0.34 和6%,在预测泊松比时EMA、ERMS和R2的最值差距分别0.016、0.019 和9%,最值差距始终为4 种机器学习模型中最小的,在抗拉强度和断裂韧性的实验中亦然。准确率最值差距较小的模型,其k折交叉验证的各次验证准确率都比较稳定,说明模型对数据的泛化能力较强。也就是说,该模型在训练数据和验证数据中的表现差异较小,能够很好地应对新的数据集。因此,在选择模型时,通常会选择准确率最值差距较小的模型,因为这样的模型更具有可靠性和稳定性。因此,可以发现PINN 自身具有较强的泛化能力,并可以推广到解决其他岩石力学问题中。
XGBoost 在4 种岩石力学参数的预测实验中,平均准确率分别为91%、90%、90%和92%,虽然预测精度不及物理信息约束的神经网络,但依靠其强大的集成学习计算方法,在4 种机器学习模型中表现也较为可观。随机森林的表现次之,在4 种岩石力学参数预测中平均准确率分别为86%、87%、85%和89%,在10 折交叉验证的过程中,随机森林算法中EMA和ERMS的最值差距相比于其他模型明显较大,在弹性模量实验中,EMA、ERMS和R2的最值差距分别为1.65、3.62和21%,在泊松比的实验中,EMA、ERMS和R2的最值差距分别为0.068、0.071 和23%,这相较于其他模型最值差距已经非常大,究其原因,当进行回归时,随机森林不能够做出超越训练集数据范围的预测,这导致对某些特定噪声的数据进行建模时出现过度拟合,此次研究中,随机森林模型前期展示出较高拟合能力,但在交叉验证过程中拟合效果下降明显,说明存在过拟合现象,这也是进行交叉验证的目的。若在训练模型后不加以验证,一旦出现过拟合现象,模型可能在现有的数据集上表现优异,但其不具有泛化性,无法应用到更广泛的场景中,那么该模型是失败的。人工神经网络的拟合效果与随机森林方法相近,在四种岩石力学参数预测中其准确率分别为87%、86%、84%和86%,人工神经网络在这里没有获得更好的表现能力,主要因为其优势就是为了进行大规模数据分析,处理庞大的数据集并且寻找数据间的非线性复杂关系。因此,PINN 优势突出,它在少量的数据下依然可以最大程度地发挥出神经网络模型的潜力。
2.2 可压性评价
使用PINN 预测得到岩石力学参数,采用式(33)可压性评价方法确定目标储层可压裂指数,该可压裂指数反映沧东凹陷K2 段不同储层页岩可压性的相对大小,如图12 所示,颜色越红,可压裂指数越高,即可压裂性越好,形成复杂裂缝网络的可能性更大,裂缝更容易延伸;颜色越绿,可压裂指数越低,代表可压裂性越差,形成的裂缝形态单一,裂缝不易延伸。
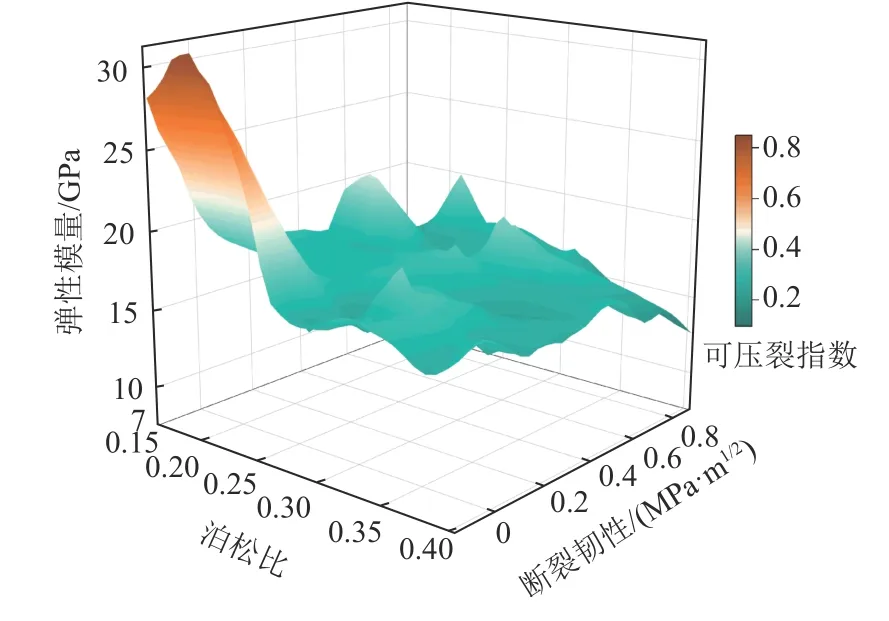
图12 可压裂指数三维分布Fig.12 3D distribution of fracability index
通过计算得到可压裂指数并结合现场实际生产状况,将可压性分为3 个级别:可压裂指数高于0.7,页岩可压性良好,属于优质页岩储层,容易形成复杂的裂缝网络;可压裂指数位于0.4~0.7,页岩可压性中等,可能形成复杂的裂缝网络;可压裂性指数低于0.4,页岩可压性较差,较难形成复杂的裂缝网络。图13 展示了不同井深的可压裂指数,由图中可知,沧东凹陷K2 段不同储层可压性整体上较好,其中,纹层状混合质页岩(2 951~2 961 m)可压裂指数高于0.7,可压性良好;纹层状长英质页岩(2 926~2 942 m)、厚层状灰云质页岩(2 919~2 925 m)和薄层灰云质页岩(2 974~2 984 m)可压裂指数均在0.4~0.7,可压性中等。
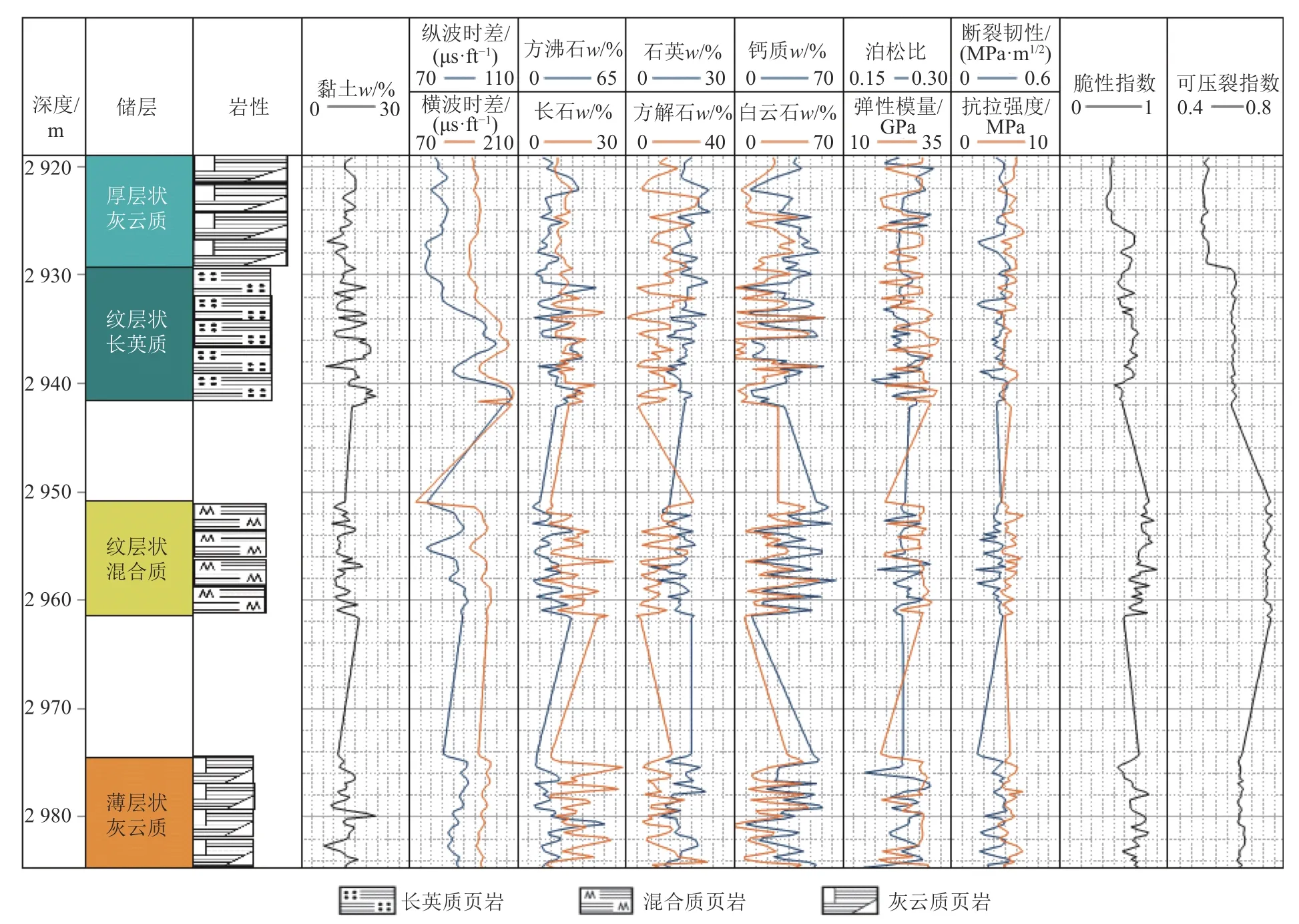
图13 渤海湾沧东凹陷K2 段不同井深可压性变化Fig.13 Fracability index at different well depths in the K2 member of the Cangdong sag,Bohai Bay Basin
韩文中等[34]对沧东凹陷K2 段进行了甜点层定量评价,经过研究发现纹层状混合质页岩甜点指数最高为0.94,甜点指数最低的储层为厚层状灰云质页岩,甜点指数0.62。其研究提到目前渤海湾沧东凹陷K2 段已经开采长达600 多天,其中纹层状混合质页岩储层平均日产油量可以达到16.6 t,是4 种页岩储层中产量最高的。可以发现文献[34]对沧东凹陷K2 段的研究结果以及目前该地区的产能情况与本次研究得到的可压性规律一致(图14),在此证明了本文研究结果的正确性。

图14 不同储层可压性评价结果验证Fig.14 Verification of the fracability evaluation results of different reservoirs
3 讨论
本文采用渤海湾沧东凹陷K2 段的测井数据和岩石矿物组分数据,通过物理信息约束的神经网络、人工神经网络、随机森林和XGBoost 这4 种机器学习模型对不同储层的岩石力学参数进行预测,采用多种评价标准横向对比4 种机器学习模型的性能,研究结果表明物理信息约束的神经网络预测精度最高,预测4 种岩石力学参数的平均准确率均在95%以上,性能远优于其他3 种模型。使用物理信息约束的神经网络预测得到的储层岩石力学参数结合现有的可压性评价方法,完成对渤海湾沧东凹陷K2 段4 种页岩油储层的可压性评价。本文建立物理信息约束的神经网络预测岩石力学参数,不仅极大地节约了人力物力,而且克服了经典机器学习模型由于数据量较少无法准确预测岩石力学参数的局限性,为储层可压性评价方法提供了可靠的岩石力学参数。本文建立的模型相比于过去的研究方法虽然取得了一定的进步,但也存在一些不足。该模型未考虑嵌入物理信息的种类和物理信息的数量对模型性能的影响,物理信息约束的神经网络最佳性能仍然有待挖掘。后续将针对嵌入物理信息的种类和物理信息的数量做深入研究,使物理信息约束的神经网络模型可以发挥更大的作用。
4 结论
a.提出一种基于物理信息约束的神经网络模型(PINN),采用PINN 预测弹性模量、泊松比、抗拉强度和断裂韧性的平均准确率分别为96%、95%、95%和97%,其准确率明显高于人工神经网络、随机森林和XGBoost 模型,在少量的数据下,通过对神经网络结构添加物理信息约束可以有效提高预测的精度。
b.XGBoost 预测岩石力学参数的平均准确率在90%以上,随机森林和人工神经网络预测的平均准确率均在85%以上,这3 种机器学习模型在岩石力学参数的预测中虽然效果不及物理信息约束的神经网络优异,但相较于传统的室内实验方法和经验公式方法表现出经济高效的特点。
c.将PINN 应用于沧东凹陷K2 段储层可压性评价,得出研究区整体可压性较好,纹层状混合质页岩可压性良好,纹层状长英质页岩、厚层状灰云质页岩和薄层灰云质页岩可压性中等。
d.提出的PINN 经过k折交叉验证后具有良好的泛化能力,选取的可压性评价方法经过前人的多次验证具有较高的可靠性,证实本文研究方法具有一定的普适性,可以推广到解决其他岩石力学和储层可压性问题中。
