基于数字孪生和深度强化学习的无人仓储调度优化
2023-11-04叶旭乾刘一阳韩宪征
叶旭乾,王 丹,刘一阳,韩宪征
(1.中兴通讯股份有限公司,广东 深圳 518055;2.帝国理工学院,英国 伦敦 SW72AZ)
0 引言
根据中国物流与采购联合会的数据,2021年我国社会物流总费用16.7万亿元,同比增长12.5%。社会物流总费用与GDP 的比率为14.6%,其中仓储保管费用达到5.6 万亿元,占GDP的比重为4.9%,随着我国电商、新零售和高端制造的发展,对高标准仓储的需求进一步加大。无人仓储作为一种新型的存储方式,其相比传统仓储具有人力成本低、人员安全隐患少、货物破损风险低等优势。通讯制造企业利用无人仓储可实现货物存储流程的无人化,对企业向自动化、数字化、智能化转型具有重要意义。
针对精准调度和资源优化的问题,传统的解决方案主要是启发式算法,将复杂的多目标优化问题转化为单目标优化问题[1]或将运输设备与立体货架、检测设备同时视为资源,使用基于精英策略的遗传算法求解[2]。但这些算法的求解能力有限并且灵活程度不够,不能很好地解决多频次不确定数量货物到达的调度,以及货架、AGV、叉车等资源的配置问题,制约了仓储的服务能力和效率。而数字孪生[3-4]作为一种智能制造和仓储领域的前沿和热点[5-8],在本文中被引入无人仓储领域。目前针对数字孪生在无人仓储领域应用的研究很少,以陶飞,等[9]提出的数字孪生五维模型及其在仓储领域的应用规划为代表。但该技术在制造业相关领域应用较多,可以作为借鉴。Tong,等[10]应用数字孪生技术,针对生产加工数据难以实时交互的问题,提出了基于智能多模式终端的解决方案。Zheng,等[11]基于数字孪生三维模型提出了一种产品级数字孪生开发方法。Liu,等[12]结合赛博系统和数字孪生技术提出了一种基于网络的数字孪生建模和远程控制的网络物理系统。
借鉴数字孪生在制造领域的应用,可将数字孪生技术与无人仓储结合,对多类资源调度和效率优化问题,利用网络技术和可视化技术动态监控设备的运行状态,及时处理现场出现的问题,从而提高设备的运行效率和精准调度能力,而参数的设置来源于现场的传感器,故能很好地解决仓库及时精准调度难、资源效率低下的问题。为此本文从以下三个方面开展研究:
(1)针对无人仓储的流程特点搭建了多层级特征的数字孪生无人仓储系统架构;
(2)利用本体建模技术和数据服务系统搭建实时映射的数字孪生无人仓储模型;
(3)结合数据分析和深度强化学习方法对数字孪生无人仓储资源调度进行优化。
1 数字孪生无人仓储系统架构
借鉴陶飞[9]提出的数字孪生系统五维概念模型,构建如图1所示的数字孪生无人仓储系统框架,包含一个可感知的物理实体层,两个技术平台(多网融合的网络平台与数据服务系统平台),三层架构(感知层、数据层、服务层),三个数据库(本地数据库、系统数据库、实时数据库),六大逻辑流程映射(出入库、理货、拣货、订单接收、储存、送到线边),六类实体的实时映射(机器人、AGV、货物、托盘、叉车、立体仓库)。
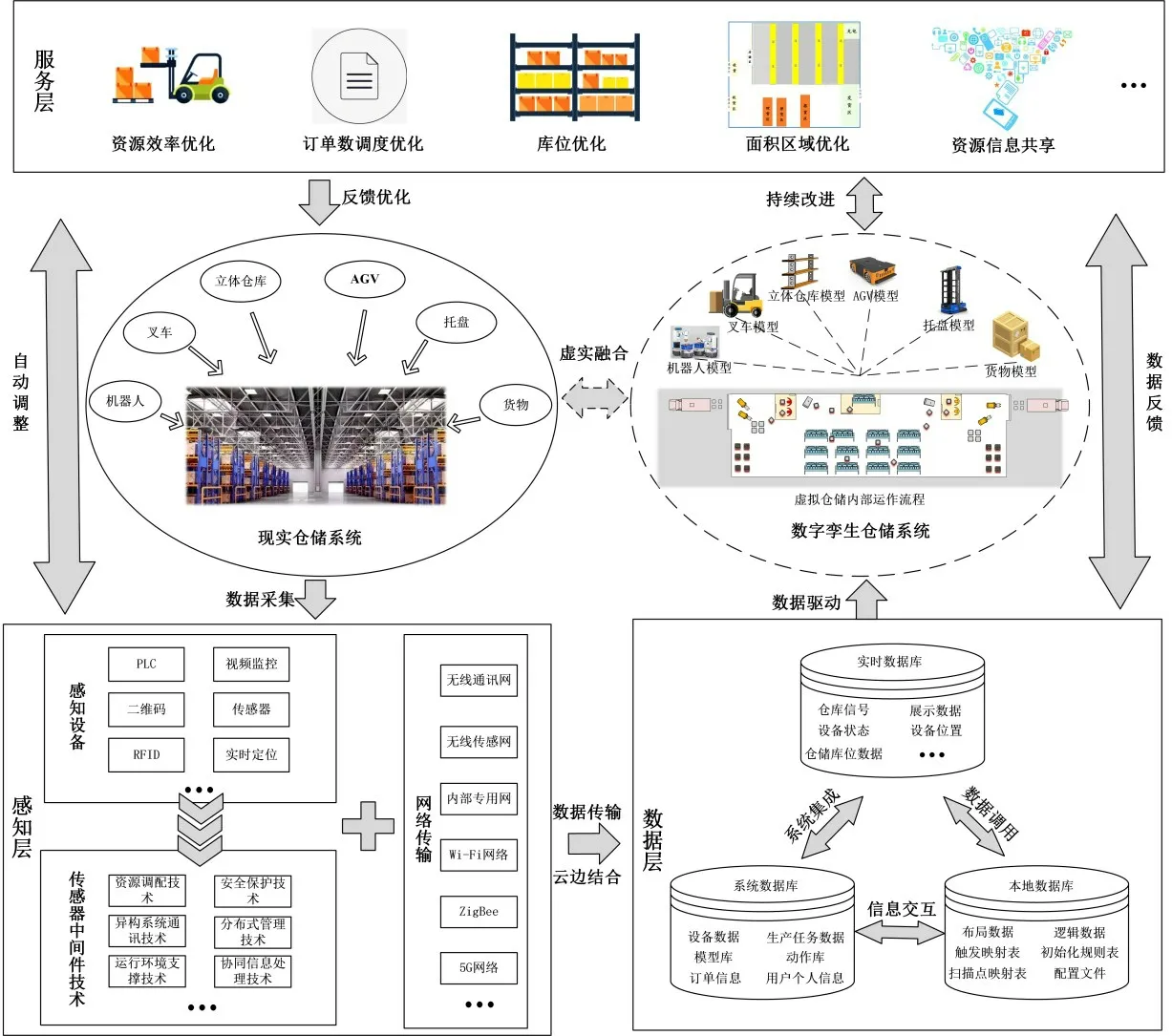
图1 数字孪生无人仓储系统架构
感知层用于识别物体、采集信息。该层利用感知设备读取安装在货架、叉车、AGV、货物、托盘、机器人、仓库的相关数据之后,利用传感器中间件技术进行数据处理,并利用相关网络工具对数据进行传输,完成底层信息的采集。
数据层中包含用户权限管理、数字孪生无人仓储系统与对象模型库的模型交互接口、实时数据库和本地数据库的数据交互接口。其中:实时数据库包含仓库信号、设备状态、设备位置、展示数据、仓储库位数据;本地数据库包含布局数据、逻辑数据、触发映射表、初始化规则表、扫描点映射表、配置文件;系统数据库包含设备数据、生产任务数据、模型库、动作库、订单信息、用户个人信息表。
服务层利用孪生数据和预测数据驱动模型运行并对数据层的数据进行迭代,实现仓储系统的智能应用,从而实现资源效率优化、订单数调度优化、库位优化、面积区域优化、资源信息共享等功能,并将优化信息反馈到感知层的数据中心进行虚拟监控。
2 数字孪生无人仓储作业流程要素
数字孪生无人仓储作业流程要素包含孪生实体建模、数据系统搭建、映射逻辑梳理。
2.1 孪生实体建模
孪生实体构建首先采用本体建模的方法,本体的构建重点是类和属性,类是对实体的定义,属性是对类特定功能的描述,所以数字孪生模型的建立需要预先进行对象和其属性的编辑,导出保存在对象库中,并记录到对象表。属性作为每一种对象建模的特征,可对其进行编辑,之后利用建模软件建立物理实体的多维模型,将模型导入到仿真平台,并选择性地对模型进行轻量化处理,以减少运行时的显示压力。对于多维模型中可运动的组成部件,设置其为可动画对象,进而编辑可动画组件的动作路径,并关联组件动画形成一个完整的动作。无人仓储本体模型的属性以及相互之间的联系,构成了一个复杂的网状概念结构,包含16类对象,21种联系,91种属性,具体如图2所示。
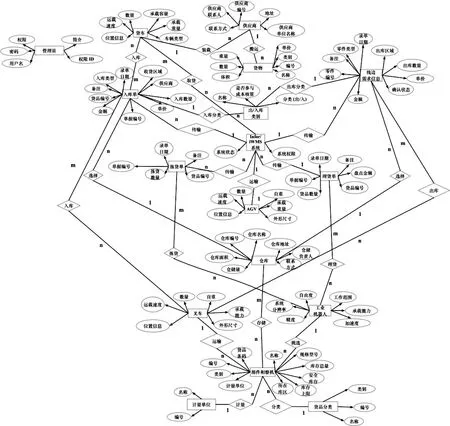
图2 无人仓储本体模型的网状结构
2.2 数据系统搭建
数据服务系统可以实现实时数据库与本地数据库和系统数据库三者之间的连接和数据调用,利用实时数据库驱动模型运行。模型首先通过XML接口模块访问XML配置文件,读取本地数据库和实时数据库地址信息,然后利用ODBC 接口模块连接本地维护的静态建模数据,并通过OWL-S技术调用以OWL方式建置的本体模型的知识本体,自动快速建立数字孪生模型,之后可选择性地通过数据库接口模块周期性地按照时间戳访问实时数据库规则数据,并对本地数据库和系统数据库数据进行解析,以数字孪生模型为载体快速还原无人仓储状态。
2.3 映射逻辑梳理
通过本体建模技术使孪生模型与物理实体在空间位置、几何尺寸、运动特性等方面具有相同的属性和功能。之后利用数据服务系统建立模型内部与外部的控制接口,实现模型与三类数据库的数据交互。最后根据实时映射规则使数字孪生模型能够实现实体要素之间的有效组合,从而完成出入库流程、理货流程、存储过程、拣货流程、订单接收流程和送到线边流程的有效运转,实现无人仓储整体的业务流程。实时映射逻辑流程如图3所示。
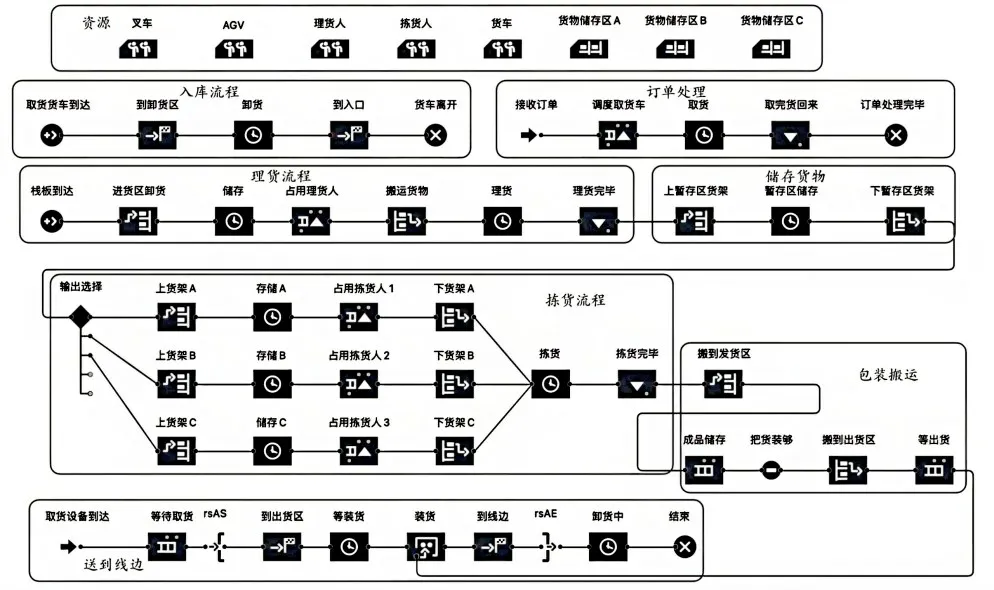
图3 数字孪生无人仓储实时映射流程逻辑图
3 数字孪生无人仓储调度优化逻辑
采用数字孪生技术对仓储资源效率进行优化时,其流程包括:基于出入库数据、库存数据、设备运行状态历史和实时数据进行预测分析;利用聚类分析方法对资源效率进行分析并运用深度强化学习方法进行优化;将资源效率优化后的分配方案与优化前对比,并将优化后的数据反馈至数据服务系统,进行矢量迭代输出优化结果。具体内容如图4所示。

图4 资源效率优化分析流程
3.1 数据分析预测
利用神经网络算法进行计算。其输入为根据数字孪生数据中心搜集的出入库货物数据,包含订单数、订单行、收货量、发货量、库存量、拆零量、SKU和设备状态的历史和实时数据,选择隐含层数目等相关参数,神经网络的数据主要分为三个部分:训练数据、验证数据、测试数据,其比例大约为7:1.5:1.5。数据训练的主要目的是通过训练,不断调整并最终确定神经网络的相关参数。训练效果用AUC值去判断,一般是介于0.5到1之间的,其值越接近1说明随机判断预测结果越好。利用预测数据与底层收集的实时数据去驱动数字孪生模型运行,反馈无人仓储可能存在的资源效率问题。
3.2 设备资源自动优化
系统自动优化流程包括对设备资源效率使用聚类分析,并基于分析结果设置自动优化算法优化相关参数。
利用聚类分析方法将各类设备资源效率分为3大类,以使类内具有较高的相似度,而且类间的相似度较低。运行数字孪生无人仓储模型,得到AGV、拣货机器人、理货机器人以及叉车等资源效率数据,利用聚类分析找出待优化的资源效率值以及优化方向。本文在无人仓储资源优化应用场景下使用A2C算法,需要结合实际场景设定状态(State)、动作a(Action)和回报r(Reward)。表1 介绍了A2C 算法中状态矩阵可选择的参数,包括:暂存区、储存区、进货区和出货区货架的存储情况;理货机器人、拣货机器人、AGV和叉车资源利用率;当前时刻理货机器人、拣货机器人、AGV和叉车资源的激活数量;下一批次到达货物的数量、预计卸货时间和种类;下一批次离开货物的数量、预计装货时间和种类。这些参数的数据类型都是整数和浮点数,可以整合成矩阵来帮助深度强化学习模型[13]判断并给出资源的调整方向。表2介绍了A2C算法中动作矩阵可选择的参数,根据状态矩阵传入的参数,A2C算法给予各个资源在下一阶段运行期间的资源池大小。以一种以AGV、进货区叉车和出货区叉车为资源优化目标的奖励函数计算方法为例,函数计算时会从模型中获取以下参数:AGV,进货区叉车和出货区叉车的使用效率以及进货区货架,理货区货架,暂存区和各个储存区货架的当前存量,以及上次执行动作函数到当前时刻货物的平均进货、出货和存储时长。当货架存量超过最大存量时,给予一个极大的惩罚值,同时通过惩罚值推荐智能体,将资源利用效率限定在一个较好的区间,最后计算周转时间并给予奖励值。表3给出了各函数和参数的定义与说明。

表1 A2C算法状态(State)矩阵可选择的参数

表2 A2C算法动作(Action)矩阵可选择的参数

表3 各函数定义与描述
在训练前,需要将导出的数字孪生无人仓储模型封装成可以与基于Python编写的深度强化学习模型交互的强化学习环境。之后无人仓储模型从云端抓取需要的表单数据,并运行返回当前状态函数矩阵。深度强化学习模型接收状态矩阵后做出决策,反馈给无人仓储模型执行动作,运行到下一判断时刻位置后无人仓储模型返回奖励值和下一时刻的状态矩阵给深度强化模型。模型直接不断交互迭代运行,最终得到训练好的无人仓储资源优化的深度强化学习模型,具体的部署流程如图5所示。

图5 深度强化学习部署框架
3.3 优化结果反馈
将经过验证的深度强化学习模型,结合Html 框架以Http server的形式部署到Linux系统服务器上。并将无人仓储模型以jar包形式部署到云端,并提供以API形式访问的功能。在实际应用时,现场数据库的数据经过获取和处理整合成模型需要的状态和任务数据并上传到云端数据库中。云端的深度强化学习模型抓取数据并返回动作策略结果,通过API调用无人仓储模型进行验证。最后将验证后的数据结果传输反馈到服务层的终端。用户可以根据可视化的显示界面查看优化后的模型和相关参数,更加科学合理地分配无人仓储资源。
4 数字孪生无人仓储系统应用
本文提出的数字孪生无人仓储系统在Z公司进行了应用。对公司2021年第一季度到2022年第二季度的10 920条订单数据进行分析,以每隔一个星期的订单数进行分类汇总。通过神经网络对订单数据进行训练预测,其AUC值为0.924 5,说明训练效果较好,并将数据上传至数据服务系统数据表格中,利用这些数据驱动数字孪生模型运行。利用深度强化学习A2C算法优化,学习率参数设定为1×10^(-6),仿真时间步长设定为5min,每次模型训练步数1 000步,训练总步长5×10^6步。
使用库存数据运行测试对比,结果如图6-图8 所示。将训练好的模型与实际无人仓储常使用的资源配置方式进行对比,从图6看出优化后的资源配置方案可以获得更高的奖励值。图7展示了优化前后的资源数量配置动态效果,可以看出为了获得更高的奖励值,深度强化学习模型对于无人仓储AGV、进货区叉车和出货区叉车进行了动态配置。图8分析了优化前后货物的入库、出库和在库内停留的时间对比,应用深度强化学习动态配置资源后,入库平均时间从26min降低到了25.8min,出库的平均时间由3.7min降低到了3.4min,货物在库内的平均停留时间从43.8min降低到了42.7min,在优化资源效率的同时,入库时间也随着动态的资源调整有了一定的改善。
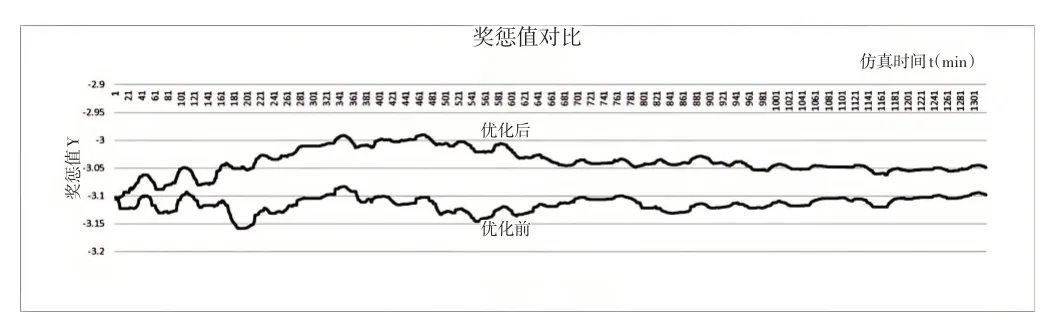
图6 奖励值优化前后对比

图7 资源配置优化前后对比
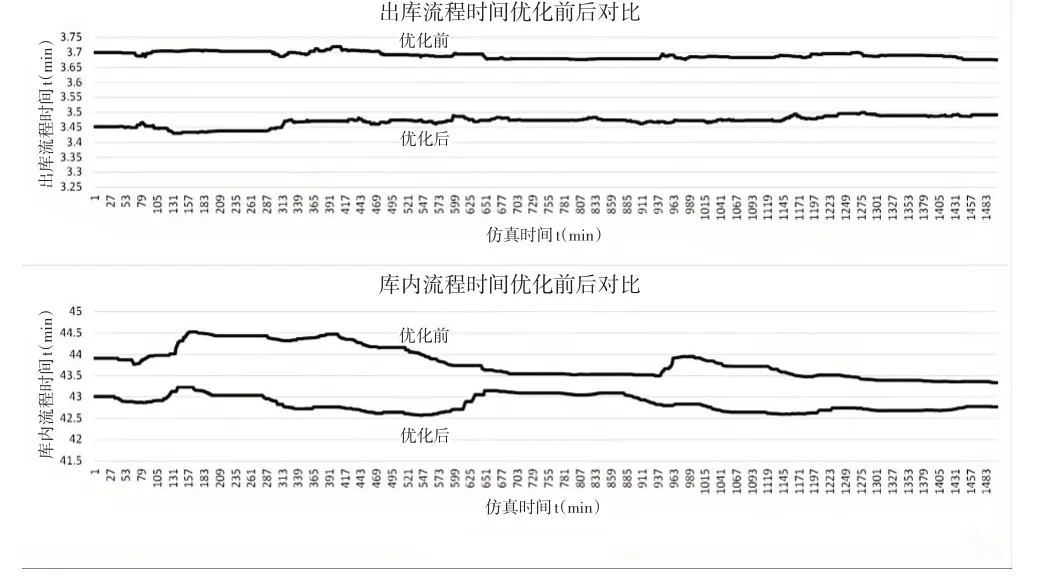
图8 流程时间优化前后对比
将优化后的数据信息反馈至数据服务系统,进行迭代优化,方便后续对模型的进一步优化,并将数据反馈至服务端的数据共享中心,决策人根据可视化界面的模型和参数,科学合理的做出相关资源的调配决策。
5 结语
本文针对基于数字孪生和深度强化学习的无人仓储调度问题进行了研究,主要包括以下内容和成果:
(1)设计了基于深度强化学习的无人仓储资源优化技术。由于现实环境中无法通过无人仓储的实际现场来训练深度强化学习模型,因此本文设计了一种使用仿真软件搭建深度强化学习模型训练环境的方法,训练时使用数字孪生无人仓储模型作为深度强化学习模型探索的环境,测试过的模型可以直接与生产执行系统对接,从而指导实际的仓储作业。
(2)开发了可交互优化的数字孪生无人仓储系统。该系统支持交互式优化求解,可以将云端数据库、深度强化学习、数据分析技术相结合,对数字孪生无人仓储进行优化。将此系统应用于Z公司后,提高了其规划质量,验证了本文中相关模型、算法及原型系统的有效性和便捷性。
考虑到数字孪生的实施成本和复杂性,本文设计的系统离高水平集成的数字孪生仍存在较大的差距,后续将在此基础上获取更多不同对象的孪生数据,并对不同粒度的数据进行进一步研究,更好的实现“以虚控实”的目标。
