基于Markov-BP神经网络的武汉市物流需求预测
2023-11-04廖倩茹艾学轶蒲秋梅
汪 勇,廖倩茹,艾学轶,蒲秋梅
(1.武汉科技大学 恒大管理学院,湖北 武汉 430065;2.中央民族大学 信息工程学院,北京 100081)
0 引言
区域物流需求是从区域经济发展状况中分化出来的概念,它与区域的社会消费水平、生产总值和居民可支配收入等经济指标关系紧密,因此,对区域物流需求进行预测[1]具有很大的现实意义,区域经济指标也可以作为需求预测指标。区域物流需求预测旨在预先估计区域未来可能发生的货物流通量,从而推测出区域物流需求的规模,方便专家学者们做出正确的区域物流规划。
目前常用的预测方法主要分为线性与非线性两种。线性方法[2]一般用于短期数据预测,其计算量较小,容易理解,具体包括指数平滑法、回归分析法和自回归滑动平均(ARMA)模型等。如:练金[3]实用指数平滑技术建立预测模型,经过一次指数平滑、二次指数平滑后拟合出船舶的流量;刘炯[4]构建多元回归模型对安徽省物流需求进行了预测;赵彦军,等[5]指出ARMA模型对中短期物流需求预测具有较好的效果,但预测时间越远,预测值与实际值的偏差就越大。
基于影响物流需求的因素复杂且样本数据多的特点,许多学者更倾向于采用非线性预测方法,主要包括单一智能预测方法[6]和组合预测方法等。如:潘珠[7]构建了BP神经网络模型对海南省农产品冷链物流需求进行预测;由于传统的灰色预测模型自身存在缺陷,李义华,等[8]在原有模型的基础上进行优化,首次提出了滑动无偏灰色模型。尽管神经网络凭借其较高的自学习能力而倍受广大学者喜爱,但其存在易陷入局部最优的弊端,因此有学者提出构造组合模型。现有对于组合预测模型的研究主要分为两种:其一是对不同的预测方法进行组合[9],如:马欢,等[10]利用遗传算法对SVR模型的函数进行寻优,使用优化后的参数建立了支持向量回归预测模型,增强了预测的真实程度;孙逊[11]将遗传算法带入SVM模型中优化参数,构建了GA-SVM物流需求预测模型,通过对比发现,将遗传算法得出的参数用于模型中,预测值更真实有效;Zhou,等[12]提出了一种基于非线性主成分分析方法和灰狼优化算法支持向量回归机的新型农产品物流需求预测模型,该模型的非线性主成分分析的性能明显优于常规主成分分析,同时灰狼优化算法提高了支持向量回归机的性能。其二是对单一预测结果进行误差修正。如:Chen,等[13]运用GM(1,1)灰色模型预测近20年的全国货运量,并使用马尔可夫链修正预测误差;Ding,等[14]选取BP神经网络作为预测方法,用支持向量机修正预测误差。目前关于预测结果误差修正方法的研究较少,本文选择构建Markov-BP神经网络模型,利用马尔可夫链修正误差值,实验结果表明预测精度更高,具有一定的可靠性。
1 区域物流需求预测模型构建
1.1 区域物流需求预测指标
由于物流需求与区域经济发展关系密切,本文主要从经济和社会两大方面分析区域物流需求的影响因素,并总结出五大预测指标。
(1)地区生产总值。该指标是常住人口在某一段时间内生产活动的产物,常被研究者用来衡量研究区域的经济发展水平。物流行业的发展离不开GDP的增长,因此,GDP上升意味着该城市的物流需求增大。
(2)社会商品零售总值。该指标描述了城乡居民和企业对实体产品的需求变化趋势,间接地反映了研究区域的社会整体消费水平,以及经济运行的景气程度,是政府进行宏观调控的依据。
(3)货物进出口总值。该指标反映了研究区域对外贸易的整体规模和发展状况,是研究当地对外贸易水平的重要依据。同时,国内外进出口贸易的发展促进了物流需求的增长,对水路、航线和高速公路的需求也有所增加。
(4)货物周转率。它反映了企业的库存流通能力,以及企业的生产和运营库存效率。若货物周转率快,则表面货物变现速度快,货物流通能力强,企业的存货风险小。该指标可以反映各大企业生产的总成果和产品在市场流通的综合能力。
(5)货物运输量。该指标表示一定时间内研究区域的水运、路运和航运等实际运输的货物数量总额,反映了研究区域运输业的发达程度,也能近似反映社会物流需求的规模。
由于物流需求的概念比较宏观,表示物流需求的指标无法完全收集,因此,根据各省市统计年鉴中数据的特点,将地区生产总值、社会商品零售总值、货物进出口总值和货物周转率作为预测模型的输入变量,将货物运输量作为预测模型的输出变量。
1.2 Markov-BP神经网络预测模型
1.2.1 BP神经网络。BP神经网络的结构包括输入层、隐含层和输出层,是一种基于训练误差反馈乘法的多层前馈网络。它的训练过程为:外部信息通过神经网络传递给输入层,输入层接收后发送给隐含层,隐含层根据输入层各层的特征和内部关系对接收到的信息进行处理并转换,最后将处理后的信息发送给输出层。若实际输出与理想值的误差大于给定值,则必须明确故障产生的全过程。即从输出层开始,根据所选用的隐含层函数改变每一次的权重,并不断调整修改,这个过程即为神经网络的学习和训练。当输出误差减小到预期水平或预定的学习迭代次数时,训练结束,BP神经网络完成学习。
本文构建一个BP神经网络,其输入层记为xi(i=1,2,…,n),层数为n;隐含层记为hk(k=1,2,…,m),层数为m,输出层记为y;(j=1,2,…,l),层数为l。输入层与隐含层的权值为wki,隐含层与输出层的权值为wjk。隐含层和输出层的阈值分别为bk和bj。
隐含层传递函数一般采用logsig函数或tansig函数,见式(1)、式(2)。
传递层输出函数为:
输出层输出函数为:
输出层误差函数为:
其中oj为样本实际值。
根据误差梯度下降法依次修正隐含层神经元权值Δwki和输出层神经元权值Δwjk,表达式见式(6)-式(8)。
其中η为学习率。
则网络总误差为:
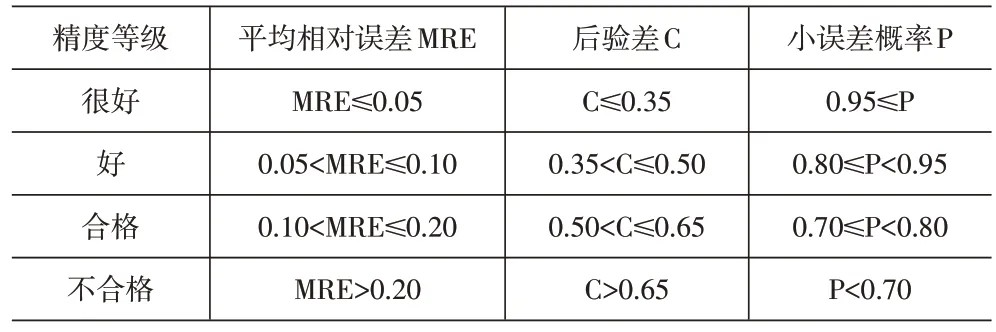
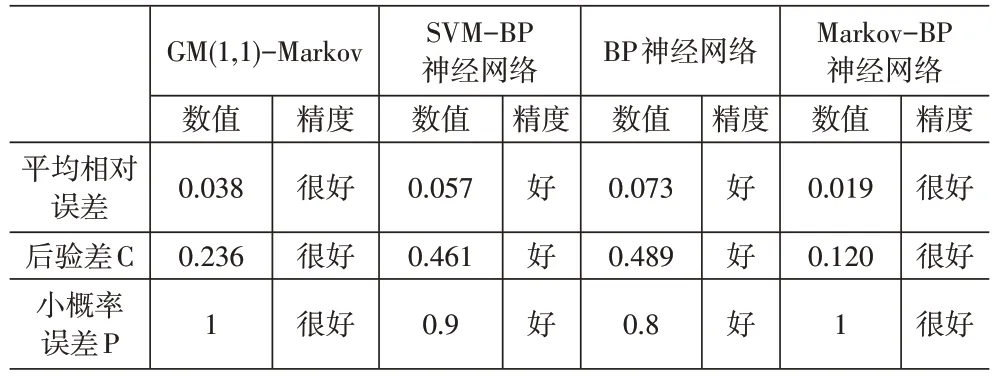
当E 1.2.2 马尔可夫链。马尔可夫链表明,事件的发展呈现出一种链的形式,它提供了一种基于马尔可夫过程理论来预测未来事件概率的方法,该理论只考虑事件的当前状态,认为状态的转变具有“无记忆性”。换句话说,如果t0时刻已知,则(t>t0)时刻的条件与t0时刻之前的条件无关,这意味着未来的过程将不依赖于过去的条件。 将时间看作一个集合,记为T1={0,1,2,…},马尔可夫链记为{Xn=X(n),n=0,1,2,…},其空间状态为I={a1,a2,…},ai∈R,则对任意的正整数n,r和0≤t1 1.2.3 预测误差分析。Markov-BP 神经网络模型建立后,需要进行模型精度检验,采用平均相对误差、后验差和小误差概率三个评价指标来反映。 (1)平均相对误差。该指标表示预测值和实际值之间相对误差的平均值,所有个体差异在平均值上的权重都相等。平均相对误差值越小,说明模型的精确度越高。 ε(k)为误差值。 (2)后验差C。该指标表示相对值数列和原始数列标准差之间的比值。后验差值越小,说明预测数据越优。 式(12)中,S1为原始数列的标准差,S2为相对值数列的标准差。 (3)小误差概率P。该指标计算出来的概率越大,说明误差分布越紧密,模型的精度越高。 (1)计算BP神经网络预测误差。首先,根据样本数量确定神经网络的输入层n和输出层l数量,依照n和l的值拟定隐含层m。设定初始权值wki、wjk和阈值bk、bj,通过现有连接权值将其正向传播,根据式(3)、式(4)分别计算隐含层输出y和输出层输出z;其次,根据式(5)计算输出层各神经元的误差e,这些误差逐层向输入层方向反向传播,利用式(6)-式(8)调整各连接权值和阈值的修正量。 当训练达到最大迭代次数或E (2)确定状态区间。计算BP神经网络预测值与实际值的误差相对值,并将相对值集合划分为n个区间状态,记为E1,E2,…,En。 其中ei1和ei2分别是状态区间的上限和下限。 (3)确定状态转移概率。将Pij记为状态Ei经过k步转移到Ej的转移概率,Pij的表达式见式(15)。 其中Mij为状态Ei转移到Ej的次数,Mj为状态Ej出现的总次数,则以Pij为元素构成的状态转移概率矩阵为: (4)确定Markov-BP神经网络的预测值。首先计算区间状态Ej的初始概率Sj,由Sj组成初始状态向量S(0)。 初始状态转移k步后得到向量S(k)。 其次,在S(k)中寻找最大值Sj(k),通过Sj(k)确定预测值在Ej区间的概率最大。ej1和ej2分别为Ej区间的上限和下限。Markov-BP神经网络的预测值为: 其中x(k)为使用BP神经网络模型的预测值。 模型精度可以划分为很好、好、合格和不合格四个等级,见表1。将Markov-BP神经网络模型计算出来的预测值带入式(11)-式(13),分别得到平均相对误差、后验差和小误差概率三个指标,并得到相应的精度等级。 表1 模型精度等级 本着研究的科学性、真实性和可靠性原则,选取的数据资料全部来源于《武汉统计年鉴—2021》,具体数据见表2。 表2 武汉市物流需求影响因素原始数据 通过上述对武汉市物流需求外部经济因素和内部社会因素的分析,选择货运量作为反映物流需求规模大小的指标。选取1998-2010年的数据作为训练样本,2011-2020年的数据作为测试样本,将测试样本的数据与实际值进行比较,计算并优化误差。 为了保证计量单位的统一性和预测结构的可靠性,使用MARTLAB2017a软件中的mapminmax函数对1998-2010年的数据进行归一化处理。 选择traingdx函数对构建的BP神经网络进行训练,训练速度快且学习效果好,神经网络的传递函数选用正切函数tansig。BP神经网络的参数根据所选用的函数和样本数量来确定,将最大训练次数设置为1 000 次,最小误差为0.000 01,即样本训练1 000 次自动停止或者误差值达到0.000 01自动停止。由于训练函数traindx学习率具有自适应性,学习速率一般为0.001,附加动量因子为0.9,同时函数每迭代50次显示结果,训练停止后得出最终预测值。 根据实际值和预测值计算误差相对值,并将相对值集合划分为五个区间状态,即E1[0.829 4,0.881 3]、E2[0.881 3,0.933 1]、E3[0.933 1,0.985 0]、E4[0.985 0,1.036 8]和E5[1.036 8,1.088 6],见表3。E1转移了3次,E2转移了1次,E3转移了1次,E4转移了3次,E5转移了2次,由式(18)可知,初始向量为S(0)=[0.3 0.1 0.1 0.3 0.2]。由式(15)-式(17)分别确定一步转移概率至五步转移概率,概率矩阵如下: 表3 预测值状态区间和误差修正 由式(20)计算得到S(1)=[0.200 0 0.150 0 0.100 0 0.300 0 0.250 0],S(2)=[0.300 0 0.066 7 0.066 7 0.400 0 0.166 7],S(3)=[0.500 0 0 0.100 0 0.166 7 0.233 3],S(4)=[0.166 7 0 0 0.400 0 0.333 3],S(5)=[0 0 0.400 0 0.055 6 0.111 1]。由此可以看出,2021、2022和2024 年武汉市物流需求量在状态E4区间的概率最大,2023年在状态E1区间的概率最大,2025年在状态E3区间的概率最大。 确定预测值的状态区间后,对预测误差进行修正,根据式(21)计算出马尔可夫链修正后的BP神经网络预测值,见表3。 将Markov-BP 神经网络的预测结果分别与GM(1,1)-Markov 模型[15]、SVM-BP 神经网络模型[16]和单一BP 神经网络模型的预测精度进行对比,结果见表4。 表4 精度对比 Markov-BP神经网络模型的平均相对误差值为0.019,后验差为0.120,小概率误差为1,每个指标的精度等级都为很好,表明该模型的预测效果显著,适合用于物流需求预测分析。与单一的BP神经网络预测值相比,Markov-BP神经网络预测值的平均相对误差降低了74%,后验差和小概率误差提高了一个精度等级,误差修复效果显著,弥补了BP神经网络拟合程度不确定的缺点;与GM(1,1)-Markov模型相比,两者精度等级虽然都为很好,但是Markov-BP神经网络模型的平均相对误差和后验差分别降低了50%和49%,由此可以看出预测复杂且无规律的样本数据时,选择BP神经网络模型效果更好;与SVM-BP神经网络模型相比,Markov-BP神经网络模型的精度整体提高了一个等级。而且使用SVM计算时,会占用大量的机器内存,也会耗费大量的运算时间。同时面对无规律且数量庞大的样本,SVM很难进行预测,而Markov模型具有“无记忆性”,过去的数据不影响未来数据的走向,因此更适合用于物流需求预测。 实验表明,本文建立的Markov-BP神经网络模型能够有效优化误差,提高预测精度,为地区物流需求的预测分析提供了一种新方法。由于单一的BP 神经网络训练能力和预测能力联系紧密,一般训练能力强则预测效果好,但若这种趋势达到极限,训练能力提高时预测效果反而会下降。因此,运用马尔可夫链对预测误差进行状态区间转移,经过有限次数序列的转换修正误差,使预测值趋于稳定。通过Markov-BP神经网络模型预测得到2021-2025年的武汉市货运量分别为64 835万t、64 069万t、60 359万t、72 391万t和74 282万t,模型预测精度很好,能够把握武汉市未来货物运输的发展趋势,为武汉市物流需求的预测工作提供有效的数据支持。1.3 区域物流需求预测算法步骤
1.4 模型评估
2 实例分析
2.1 数据来源
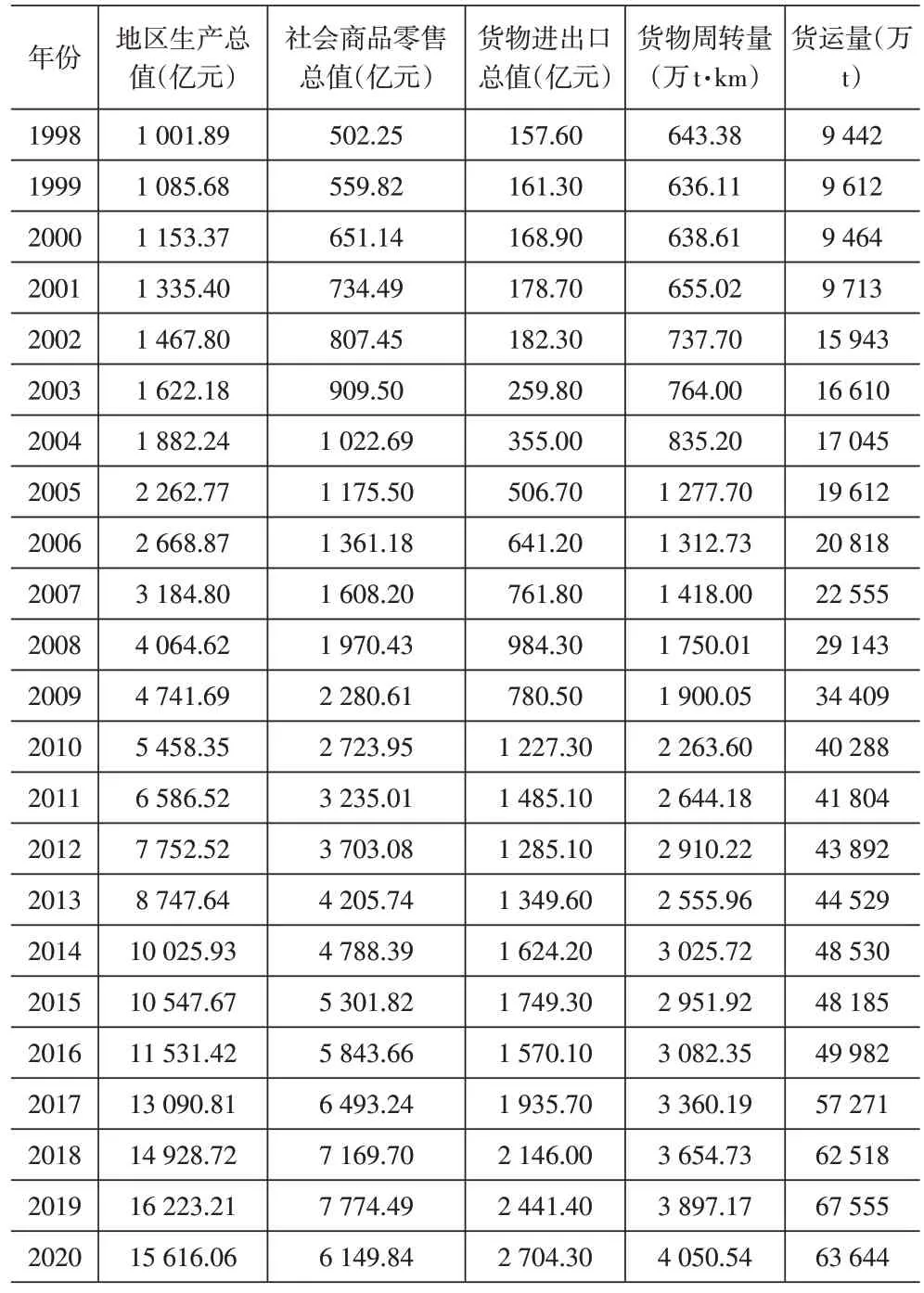
2.2 武汉市物流需求预测

2.3 模型对比分析
3 结语
