基于K-P算法优化的手写汉字细化算法
2023-11-03范勇峰李成城
范勇峰,李成城,林 民
(内蒙古师范大学 计算机科学技术学院,内蒙古 呼和浩特 010022)
0 引 言
汉字骨架提取(汉字细化)作为汉字提取、汉字识别与汉字书写质量评价等工作的上游任务,使用骨架研究中国汉字可以较为灵活的存储汉字的字形信息,节省存储大量像素点所需的存储空间[1],同时在保证原有汉字重要结构特征的前提下减少了图像的冗余信息,与原始图像相比,更好突出了汉字的拓扑特征[2],且将模式简化为细线后可以更好进行形状分析与特征提取等[3]。因此,使用汉字骨架进行汉字研究具有较大的优势。
对于当前机器学习细化算法中存在的骨架断裂、毛刺与交叉点畸变等问题,本文提出了一种K-P算法用以优化现有的手写汉字细化算法。算法在现有汉字细化算法的基础上针对性地进行了如下优化:
(1)提出交叉点匹配模板,用于后续的骨架毛刺去除等任务;
(2)使用PCA(principal component analysis)算法对骨架走势进行判断,并结合端点距离信息,解决骨架断裂问题;
(3)使用PBOD(point to boundary orientation distance)算法提取畸变交叉点算法的交叉区域并扩张,对区域内的像素点进行Kmeans++聚类,将新的聚类中心作为初始合并交叉点,并用骨架与交叉区域相交的点对初始合并交叉点做出修正,使其更接近原有走势,最后进行B样线性插值对骨架进行重建,解决交叉点畸变问题。
通过上述方法解决了目前汉字细化中的重点问题,提取出的骨架光滑、无冗余像素与毛刺,且交叉点无畸变,可以有效提升后续汉字识别、汉字书写质量评价等任务的准确性。
1 相关研究
从1967年有研究者用中轴表示连续平面上的图形以来,许多图像细化算法相继应运而生。汉字细化算法从算法层面可分为基于深度学习的细化算法与基于传统机器学习的细化算法。
基于深度学习的细化算法为了从汉字图像中提取骨架,通常会借助卷积等操作对汉字图像进行分析,将图像级别的分类延伸到像素级别的分类,进而提取骨架。代表性算法有Gao等[4]在形态学细化算法的基础上使用卷积运算表示侵蚀与膨胀,并借助TNet(skeleton transformation network)对图像进行转换,成功提取了汉字骨架。Wang等[5]提出基于FCN(fully convolutional network)的手写汉字骨架提取法,此方法首先借助rDUC(regressive dense upsampling convolution)与HDC(hybrid dilated convolution)生成用于骨架提取的像素级预测,然后使用MDF(multi-rate dilated fusion)来融合不同粒度层数上的骨架信息,最后借助多损失函数对参数进行调优,成功提取出骨架信息。Wang.Z等[6]利用BP(back propagation)神经网络对优化的组合模板进行训练,得到优化的训练参数,将优化后的参数输入汉字细化系统进行快速细化。基于深度学习方法的缺点是需要大量的标注信息对网络进行训练,此外,模型的训练与加载成本较大,对于后续实时性的识别与评价任务有所影响。
基于传统机器学习的细化算法通常是对汉字图像的像素点或轮廓进行分析,从而得到代表汉字骨架的中轴点。根据对图像中的不同信息进行分析,基于传统机器学习的细化算法又可分为基于模板匹配的细化算法和基于距离变换的细化算法。
基于模板匹配的细化算法使用预先设定的像素点模板对图像中前景像素点类型进行判断,删除符合条件的前景像素点。常见的算法有Zhang-Suen算法[7,8]、EPTA(enhanced parallel thinning algorithm)算法[9]与Hilditch算法[10]等。此类细化算法由于其模板本身限制,忽略了对部分像素点的判定,因此通常存在非单像素、毛刺与交叉点畸变等问题。而基于距离变换的细化算法主要是借助图形的中轴与轮廓信息对图像抽取骨架。主流的算法有蚁群搜索法[11]、点云模型法[12,13]与Delaunay三角剖分法[14]等。基于距离变换的细化算法对于图像的质量与在细化过程中“经验值”要求较高,如果图像质量较低或者细化过程中的“经验值”选取不当就容易产生骨架断裂与毛刺等问题。
除了上述的几种方法与其对应的改进方法外,诸多研究者[15-23]均在传统机器学习细化算法的基础上提出了优化算法,并针对性的解决了上述的骨架断裂、交叉点畸变等问题,如周正扬等[15]将交叉区域全部移除后借助局部关联度对骨架进行重建;Sathesh等[23]检测轮廓像素并对噪声边缘进行丰富,然后使用形态学操作分离轮廓中不需要的像素,从而提取目标骨架信息。虽然研究者们有针对性地提出了汉字细化问题的解决方案,但是都没有完整解决现在汉字细化中的重点问题。
基于传统机器学习的细化算法可以在数据量较少时通过算法本身对图像的分解,从而提取骨架,速度较快且可以更为直观观察骨架点与非骨架点的区域,进而更好优化算法,使得算法可以提取出可观性更强的汉字骨架。因此目前对于手写汉字细化的研究方法仍然以传统机器学习算法为主。
2 基本定义
设图像Image为二值化图像,像素值为1的设为前景像素点,像素值为0的为背景像素点。
定义1 8-邻域,设P1为前景像素点,则其周围8个方向的像素点组成的集合S(P1)=[P2,P3,P4,P5,P6,P7,P8,P9] 即为其八邻域,如图1所示。
定义2 端点、节点、模糊点,汉字细化后其骨架中的点类型可分为3类,其分类依据前景像素点8-邻域中其它前景像素点的数量,设P1为前景像素点,则分类依据如图2所示。
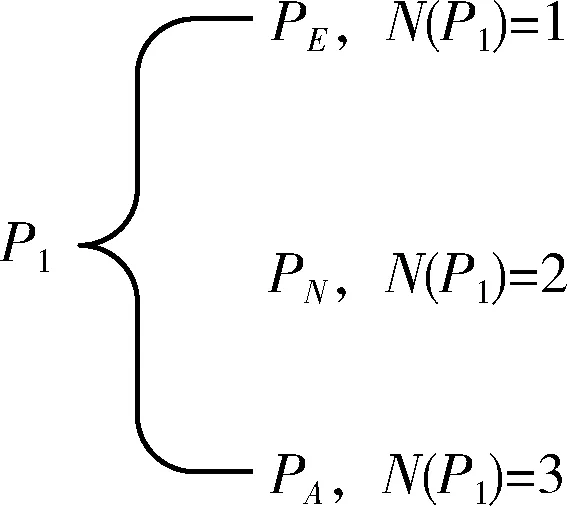
图2 前景像素点分类
PE、PN、PA分别代表端点、节点与模糊点,其中N(P1) 为P18-邻域中其它前景像素点的数量,定义如下
(1)
定义3 平均笔画宽度,设P为一骨架点,计算P点处原始笔画边到边的距离,最小的距离即是P点处的笔画宽度。对所有骨架点处的笔画宽度累加后求均值,即为平均笔画宽度。
其中P点处原始笔画边到边的距离设为BBOD(P),汉字图像img大小为H×W,P点处坐标为 (x,y), 则有
BBOD(P)=L1+L2
(2)
其中L1为一整数,满足
img(x+L1cos(θ),y+L1sin(θ))=0
(3)
并且对于任何整数l∈(0,L1), 均有
img(x+lcos(θ),y+lsin(θ))=1
(4)
L2为一整数,满足
img(x-L2cos(θ),y-L2sin(θ))=0
(5)
并且对于任何整数l∈(0,L2), 均有
img(x-lcos(θ),y-lsin(θ))=1
(6)
式(3)~式(6)中的θ=3K,K=0°,1°,2°,…,60°, BBOD(P)可存储60个P点处原始笔画边到边的距离。则P点处的笔画宽度为
L(P)=min(BBOD(P))
(7)
设汉字骨架像素点数量为n,则平均笔画宽度为
(8)
定义4 交叉点,对定义2中的模糊点进一步划分,可以划分为交叉点与非交叉点,交叉点为N(P)=3且起“分叉”作用的点,而非交叉点不起“分叉”作用。通过对模糊点的进一步划分,可以在骨架去毛刺与交叉点畸变修复任务中更快定位到毛刺起点与交叉区域,从而减少算法的计算量,提升效率。本文对骨架图像中的模糊点进行分析,从对称性的分叉与不对称的分叉出发,提出了如图3的交叉点匹配模板,可以在模糊点匹配的基础上进一步定位到交叉点。
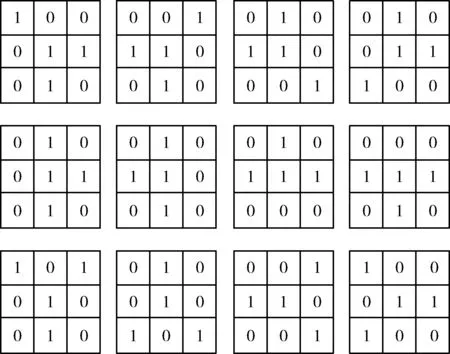
图3 交叉点匹配模板
3 算法研究
3.1 骨架去毛刺
由于书写力度的不同,笔画的宽度也随之不同,在笔画宽度变化较大的地方容易出现毛刺,而毛刺的出现影响后续的汉字识别或书写质量评价任务,因此,需要对毛刺进一步处理。本文首先对汉字图像进行预处理,然后提取骨架并进行非单像素处理,最后通过计算交叉点到端点的距离是否大于平均笔画宽度对毛刺进行判断。
骨架毛刺去除算法的具体步骤如下:
步骤1 图像预处理(包括图像二值化、噪声去除、中值滤波);
步骤2 汉字细化算法结合非单像素处理方法提取汉字骨架;
步骤3 遍历骨架图像,找到所有的交叉点与端点;
步骤4 遍历交叉点,沿着交叉点分叉的方向进行遍历,直至端点(或者遍历到的前景像素点数量大于平均笔画宽度),然后将遍历路径加入到历史像素点列表中;
步骤5 若历史像素点列表中像素点的数量小于平均笔画宽度,则将列表中的像素点添加到待删除像素列表中;
步骤6 重复步骤4、步骤5,直至所有交叉点全部遍历完;
步骤7 在图像中删除所有待删除像素列表中的像素,算法结束。
经过毛刺去除算法处理之后的图像如图4(图例骨架均采用Zhang-Suen细化算法)所示。
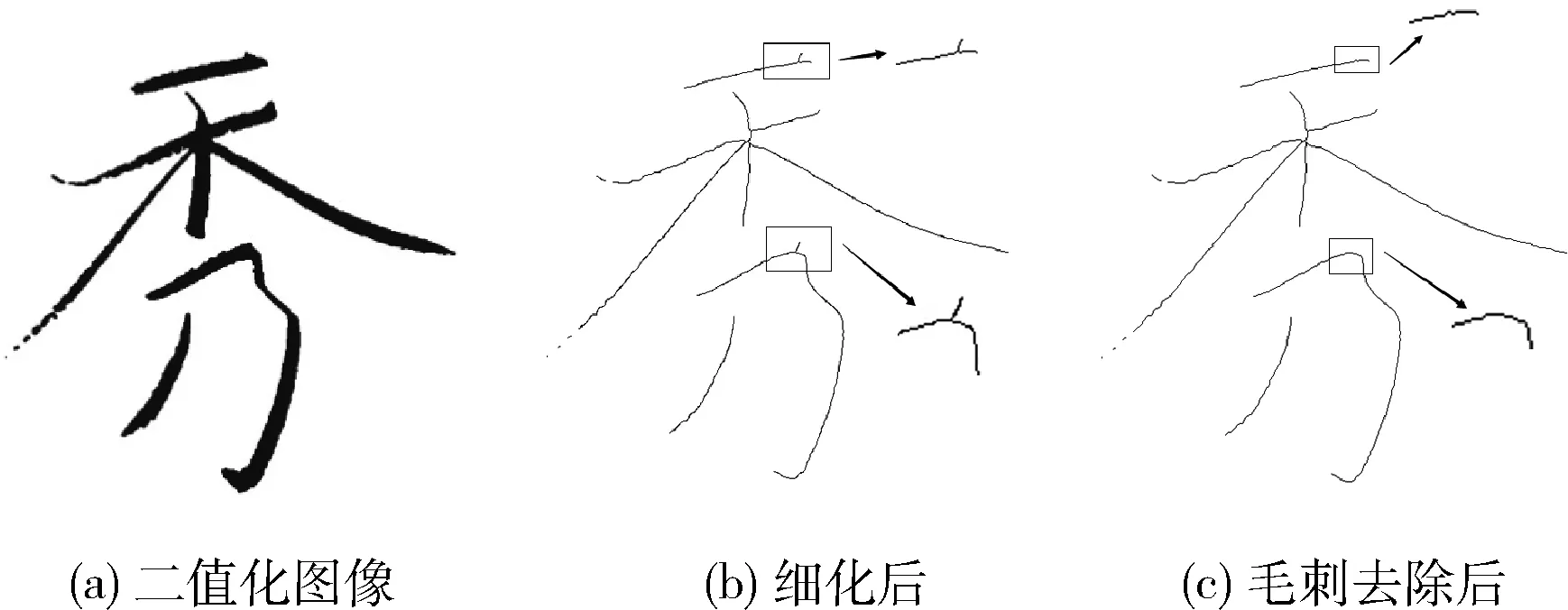
图4 骨架去毛刺前后对比
由图4可见,经过毛刺去除算法之后,骨架变为平滑且无冗余像素,此外借助定义4中的交叉点匹配模板对毛刺的起点进行定位,避免了因为非交叉点引起的遍历,通过交叉点匹配后再进行毛刺去除比之前直接进行毛刺删除节约了80%的时间。
3.2 骨架断裂连接
由于书写问题与图像质量问题,汉字提取出的骨架常常存在断裂,这些断裂影响了后续任务中笔画提取与汉字特征提取等任务,因此需要对断裂的骨架进行连接。在对断裂的骨架进行连接时,为了预测断点(或端点)处骨架的大致方向与其它骨架的对应关系,避免误连接,本文使用统计模式识别中一种著名的方法,即主成分分析算法(PCA)。主分量定义为协方差矩阵最大特征值对应的特征向量,因此,主成分捕捉最大方差的方向,即骨架走势,在数学中,将协方差矩阵写为
(9)
式中:X,Y为坐标,l为骨架段长度,当前断点处骨架的主成分记为Pcurrent,其余断点处的骨架主成分为iPcurrent(i为其它断点,不包括当前断点),计算两者的点积为
Dp=|Pcurrent·iPcurrent|
(10)
则对应的
(11)
式(11)中n为断点的数量,不包括当前断点。通过上述公式即可计算并得出最优的连接方案。
此外,骨架的断裂通常都在一个小的区域范围内,为了减少对不同断点主成分的分析,降低计算量与误连接率,可借助断点之间的距离作为辅助判断条件。先用断点之间的距离做一次筛选,再使用PCA算法进行判断,如果在设定的阈值范围内(通过实验测试结果,阈值为15时即可判断两者之间的关系),即将两个断点进行连接。为了使连接后的骨架更为平滑,优化算法使用了B样插值法对断裂的骨架进行修复,进而在不影响骨架原有拓扑性的基础上完成骨架断裂连接。图像通过骨架断裂修复算法前后对比如图5所示。
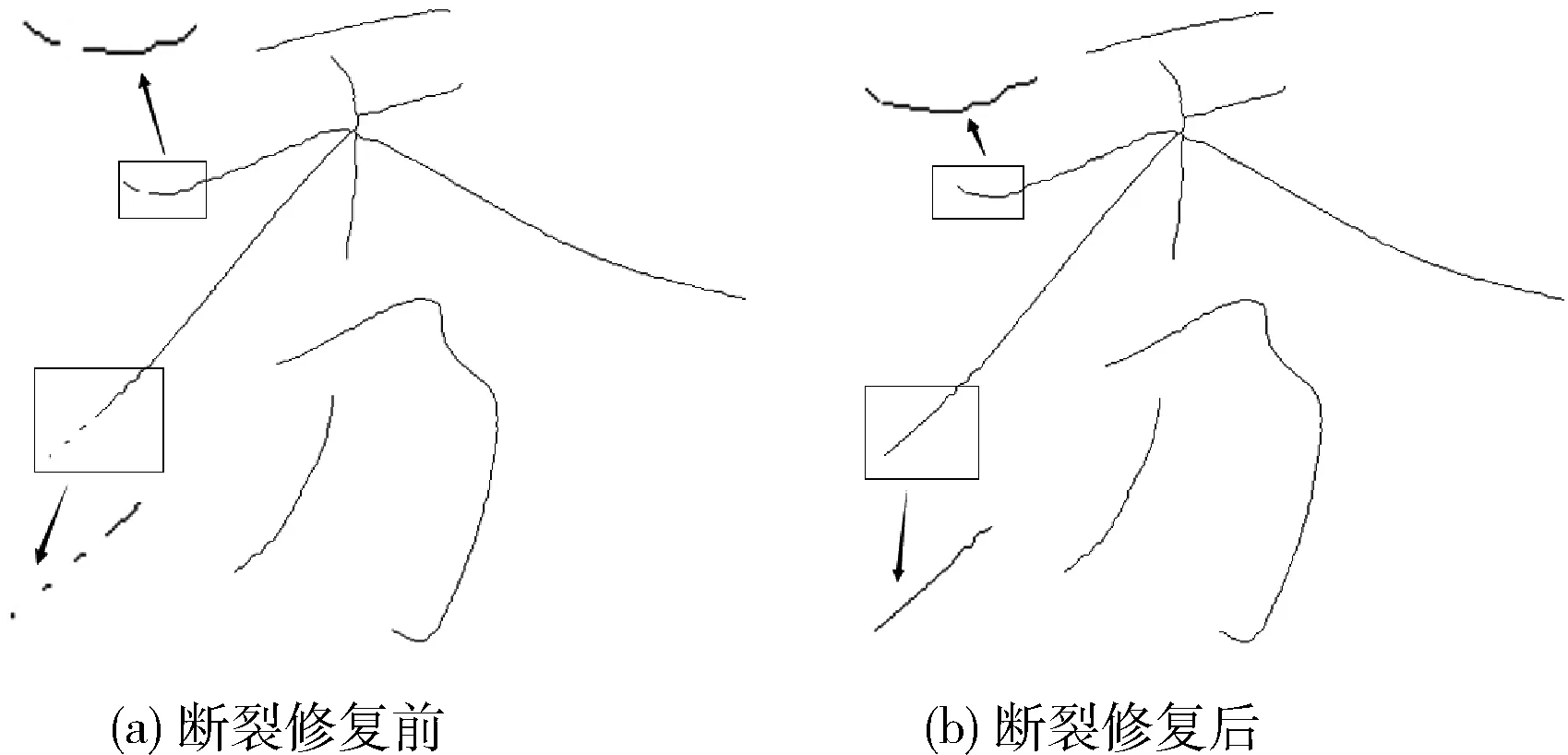
图5 骨架断裂修复前后对比
3.3 交叉点畸变修复
当前的细化算法在对图像交叉区域处进行细化时,由于像素的剥落速度不一与图像质量问题,使骨架在交叉区域产生了畸变,由一个交叉点分裂成两个或者更多交叉点,如图6所示。

图6 交叉点畸变
交叉点的畸变使后续的任务复杂度变高且准确率也会下降,因此需要对在交叉区域产生畸变的骨架进行修复。本文提出了一种汉字图像与骨架图像相结合的方法对畸变骨架进行修复,首先获取所有的交叉点,然后对所有获取到的交叉点按交叉点之间的距离进行分组,若某一组中存在两个及以上的交叉点,则验证该交叉点所在的交叉区域存在骨架畸变问题,最后对交叉区域分析,修复畸变的骨架。为了对产生畸变的交叉区域进行分析,本文使用PBOD算法[24]提取汉字图像中的交叉区域:算法沿着一个前景像素点360°遍历(每隔3°一个方向,初始方向竖直向下),获取每个方向上点到汉字笔画轮廓的距离,通过计算点到汉字轮廓的距离得到每个点的PBOD曲线,观察PBOD曲线的波谷信息,波谷数量在3个及以上的点即为交叉区域内的点。根据波谷获取交叉区域的角点,连接这些角点,即可提取交叉区域。设汉字图像img大小为H×W,P点处坐标为 (x,y), 像素点P的PBOD曲线定义如下
L=PBOD(θ)
(12)
式中:θ为曲线的横坐标,L为纵坐标,θ=3K,K=0°,1°,2°,…,120°。
其中L为一整数,满足
img(x+Lcos(θ),y+Lsin(θ))=0
(13)
并且对于任何整数l∈(0,L), 均有
img(x+lcos(θ),y+lsin(θ))=1
(14)
由于事先借助汉字骨架获取到了交叉区域对应的交叉点,因此只需要对交叉点处理后对处理后的交叉点做PBOD算法,而不需要对全部像素点进行PBOD,减少获取交叉区域所需时间,降低了计算量。其中交叉点处理方法如式(15)所示
(15)
式(15)中num为交叉点的数量,X,Y为处理后用来进行PBOD点的坐标。
对图6中交叉点使用式(15)处理后进行PBOD,得到了对应的PBOD曲线图(如图7所示)。
由图7可知,该交叉区域有6个波谷,通过波谷信息可以进一步获取交叉区域的角点坐标,连接这些角点所取得的多边形即为交叉区域。提取结果如图8所示。

图8 交叉区域提取
为了修复畸变的交叉点,需要对笔画在交叉区域处的走势进行分析,因此首先获取处于交叉区域内的笔画像素点,这些像素点大致包括了笔画在交叉区域处的密度与走势信息,而为了更好获取交叉区域处笔画的走势信息,选择将交叉区域向外围进行扩张,把部分非交叉区域的笔画像素点包括进来,这些笔画像素点所包含的走势信息更为丰富。
使用Kmeans++算法对这些像素点进行聚类分析,通过聚类可以发现像素点的分布规律,从而获取可以反映原始笔画走势的聚类中心点,将获取到的聚类中心点作为初始合并交叉点,结合骨架与交叉区域的交点作为辅助信息,借用式(15)对初始合并交叉点做出修正,使其可以更好保持原始笔画的拓扑性,以便得到最后的合并交叉点。
得到最终的合并交叉点后,将骨架图像中位于对应交叉区域内的骨架像素点全部清除后进行骨架修复。
为了使恢复的骨架不丧失原有的走势信息,使用B样插值法连接交叉点与骨架段,而由于使用B样插值法连接骨架时可能会存在像素溢出问题,因此需要对修复后的骨架图像再进行一次非单像素处理,处理后的图像即为最终的图像,可用于后续的汉字笔画提取与汉字书写质量评价任务等。交叉区域畸变修复前后图像如图9所示。

图9 交叉区域畸变修复前后对比
尽管优化算法需要借助骨架中的交叉点信息,但是由于有交叉点匹配模板和不需要遍历所有像素点等原因,优化算法提取交叉区域所需时间只有原始PBOD算法提取交叉区域的15%左右。使用优化算法后的细化算法提取出的骨架平滑、无非单像素问题且原始笔画的拓扑性也得到了保证。
手写汉字细化算法优化方法流程如图10所示。
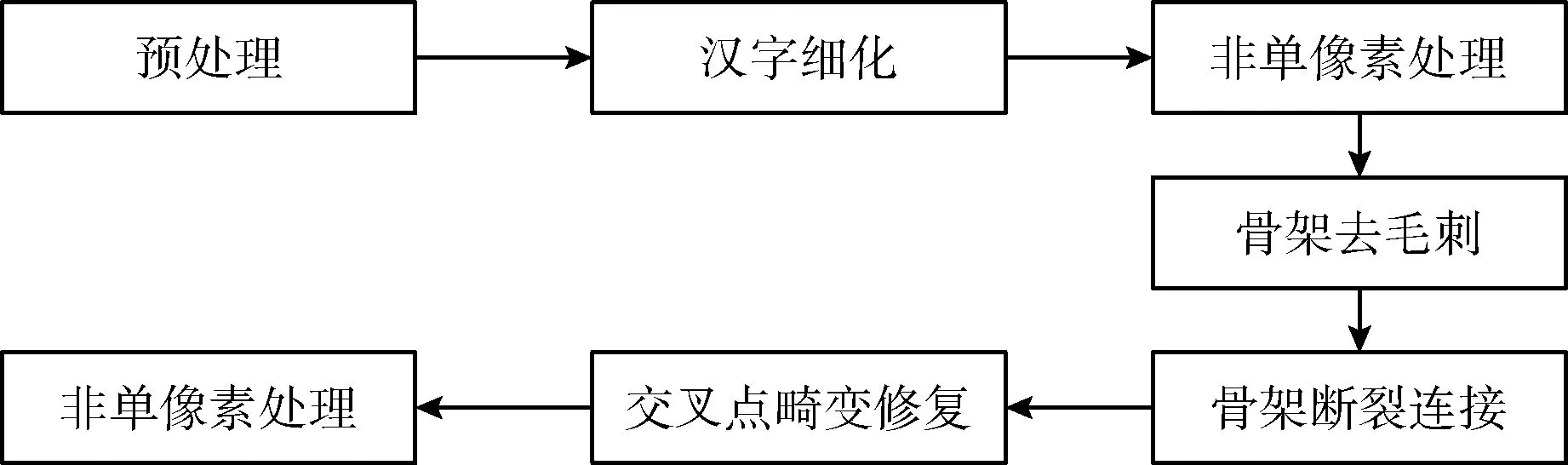
图10 优化算法流程
4 实验结果及分析
在验证K-P算法对于现有细化算法的优化效果时,选取了目前汉字细化方面使用较为广泛的Hilditch算法、LuWang算法、Stentiford算法与Zhang-Suen算法,使用K-P算法分别在4种细化算法上进行优化,通过对比算法优化前后的结果验证K-P算法的优化效果并分析当前优化算法不足。
实验所使用的数据集采集自师范生粉笔字自动训练系统中的手写汉字图像,为师范生参加三笔一画考试中粉笔字测试环节中手写汉字图像,是自然环境中的图像,具有较好的代表性。实验数据从采集到的数据集选取了部分,总计100首诗词,共875个字,均为楷体,包括了大多数的汉字笔画形态,实验图像大小设置为600*600。实验环境采用PyCharm作为开发平台,PC机处理器为I5-7300HQ。
在4种汉字细化算法上将优化后的算法与未优化的算法结果进行对比,部分结果如图11所示。

图11 细化算法优化前后对比
由图11可知,细化算法经过优化后,毛刺、断裂与交叉点畸变等问题基本得到了解决,提取出的汉字骨架更具有可观性,但如果细化算法本身原因导致笔画骨架部分偏离了笔画走势,如Hilditch算法细化的骨架存在着许多凹陷,特别在笔画“撇”中,则优化算法无法解决。
为了进一步评估骨架提取与优化结果,将优化算法处理之后的图像从优化耗时、细化率、端点数、交叉点数4个方面与优化前的细化算法进行对比。对比特征中的优化耗时与细化率反映了方法的计算复杂度与细化后骨架中非单像素存在情况,端点数的多少说明了骨架是否有较多的断裂与毛刺等,而交叉点数则是反应骨架毛刺的数量与骨架在交叉区域是否产生形变,产生交叉点分叉的现象。通过对4个细化算法进行优化并进行实验,结果见表1。
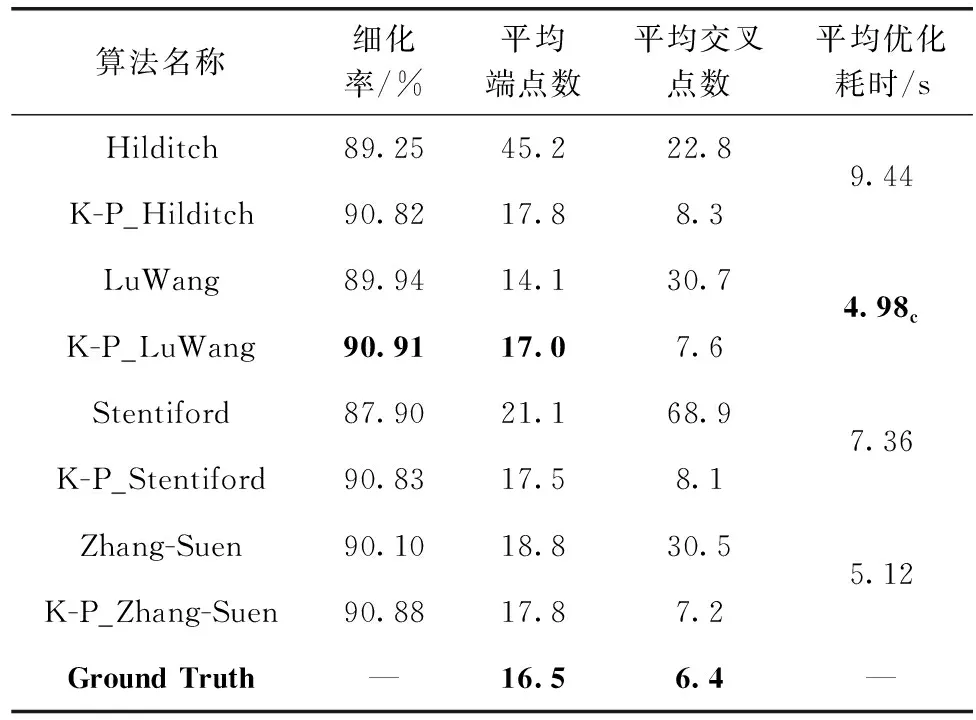
表1 细化算法优化前后对比
由此可知,优化算法在细化率、端点数、交叉点数这3个方面均表现较多的优势。
(1)细化率上Stentiford算法提升最大,因为此算法的像素点匹配模板较少而忽略了部分像素点的判定,存在大量的冗余像素,经过非单像素处理后,细化率从87.90%提升到90.83%,提升了2.93%,在4种细化算法上平均细化率也提升了1.59%,较好解决图像中的像素冗余问题。
(2)端点数量上,优化后的LuWang算法与真实值的差距降到了0.5,但是它是4个细化算法中唯一一个在经过优化后比优化前端点数量多的一个算法,通过对数据进行分析,发现此算法的细化结果在骨架端点处存在较多的非单像素问题,因此造成了在经过优化算法之后其端点数不降反升,而其余细化算法得益于优化算法中的骨架去毛刺与断裂连接处理后,端点数量都有所减少。
(3)交叉点数量上,优化后的Zhang-Suen算法与真实值差距只有0.8,最接近真实值,其原因是此算法在细化过程中产生的交叉点畸变与毛刺较少,因此优化后的结果最接近真实值,而优化后的Stentiford算法交叉点数量减少的最明显,由优化前的68.9减少到优化后的8.1,对数据进行观察后发现Stentiford算法对汉字的细化不够充分,骨架中存在着大量的细小毛刺,导致了其交叉点数量较多,在经过优化后,毛刺问题得到了有效改善。优化算法中的断裂连接与交叉点畸变修复较好改善了当前细化算法的缺陷,在端点与交叉点数量上与真实值的平均差距由优化前的9.5与31.8分别降低到1.025与1.4。
(4)优化耗时上,因为优化算法耗时部分主要在骨架断裂连接与交叉点畸变处理,而LuWang算法与Zhang-Suen算法的断裂和交叉点畸变问题较其它两个算法更少,因此在细化耗时上表现较为优秀。
综上所述,现有的细化算法在经过K-P算法优化后可以较好解决骨架图像中非单像素、毛刺、断裂与交叉点畸变等重点问题,从而较为完整、准确地提取手写汉字骨架,为汉字骨架在汉字研究任务上铺垫了良好的基础。
5 结束语
K-P算法通过分析汉字书写特征与笔画走势等信息解决了骨架中断裂连接、交叉点畸变问题,弥补了现有细化算法的缺陷,使细化算法提取出的骨架在保证原有汉字结构形体特征的前提下更具有可观性。但本文在处理交叉区域时,对于交叉点组的划分较为依靠距离因素,如果畸变的交叉点相距较远,则畸变问题可能无法优化。后续考虑在本文方法的基础上进行手写汉字笔画提取与汉字特征提取,用于汉字识别与汉字书写质量评价任务中,从而借助更精细化与更准确的汉字书写特征以提升汉字识别与汉字书写质量评价任务的准确率。
