基于视觉Transformer 的多级特征聚合图像语义分割方法
2023-10-31孔玲君郑斌军
孔玲君, 郑斌军
(1 上海出版印刷高等专科学校, 上海 200093; 2 上海理工大学 出版印刷与艺术设计学院, 上海 200093)
0 引 言
语义分割是计算机视觉领域的一个重要的研究任务,具有广泛的应用,如自动驾驶、视频监控、增强现实、机器人技术等等。 语义分割通过给图像的每个像素分配语义标签,进而为目标任务提供高级图像表示, 如在自动驾驶场景中识别行人和车辆以进行规避。 Long 等人[1]开创性地使用完全卷积网络(Full Convolutional Network,FCN)进行图像语义分割任务,并取得良好的效果,这激发了许多后续的工作,并成为语义分割的主要范式。
图像分类与语义分割有着密切的联系,许多先进的语义分割框架是在ImageNet 上流行的图像分类体系结构的变种。 因此,主干框架设计一直是语义分割的重要活跃领域。 从早期的VGG[2]到具有更深层、更强大的主干方法,主干网络的进步极大地推动了语义分割性能的提升。 通过可学习的堆叠卷积,可以捕获语义丰富的信息。 然而,卷积滤波器的局部性质限制了对图像中的全局信息的分享,但这些信息对图像分割十分重要。 为了避免这个问题,Fisher 等人[3]引入了扩张卷积,通过在内核上“膨胀”空洞来增加感受野;Chen 等人[4]更进一步地使用具有空洞卷积和空洞空间金字塔池化进行特征聚合,扩大卷积网络的感受野并获得多尺度的特征。
自Transformer 网络在自然语言领域取得巨大成功后,研究人员开始尝试将Transformer 网络引入视觉任务中,Dosovitskiy 等人[5]提出了用于图像分类的视觉Transformer(Vision Transformer,VIT),按照NLP中的转换器设计,把原始图像分割成多个切片,展平成序列,输入到标准的Transformer 网络中,最后使用全连接层对图片进行分类,在ImageNet 上获得了令人印象深刻的性能表现。 VIT 虽然拥有良好的性能,但是也存在一些不足,如:需要庞大的训练数据集;对于高分辨率图像,计算成本高等。 为了突破上述局限,Hugo 等人[6]提出了一种基于蒸馏的训练策略Deit,仅使用120 万张图像就可实现高效训练,并取得良好的表现。 Wang 等人[7]提出一种用于密集预测的金字塔视觉Transformer(Pyramid Vision Transformer,PVT),可以显著减少计算量,并且在语义分割方面有很大的改进。 然而,包括Cswin[8]、Swin Transformer[9]等新的方法均着重考虑编码器设计部分,却忽略了解码器部分对进一步提升性能的贡献。
基于此,本文提出了一种基于视觉Transformer的多级特征聚合图像语义分割方法(Multilevel Feature Aggregation with Vision Transformer,MFAVT),将原始图像分割成切片后,使用线性切片嵌入作为Transformer 网络编码器的输入序列;解码器将编码器生成的上下文词符序列上采样到逐像素类分数。 关键思想是利用Transformer 网络的感应特性,即较低层注意力倾向停留在局部,而高层的注意则高度非局部。 通过聚合来自不同层的信息,解码器结合了来自局部和全局的注意,从而有效地提升分割精度,实现分割目标。
1 MFAVT
MFAVT 主要由编码器和解码器模块组成,模型结构如图1 所示。 在编码器部分,是将图像分块并投影到一系列嵌入位置,并使用Transformer 网络进行编码;解码器部分,是将编码器的输出作为输入进行多层聚合,来预测分割掩膜。
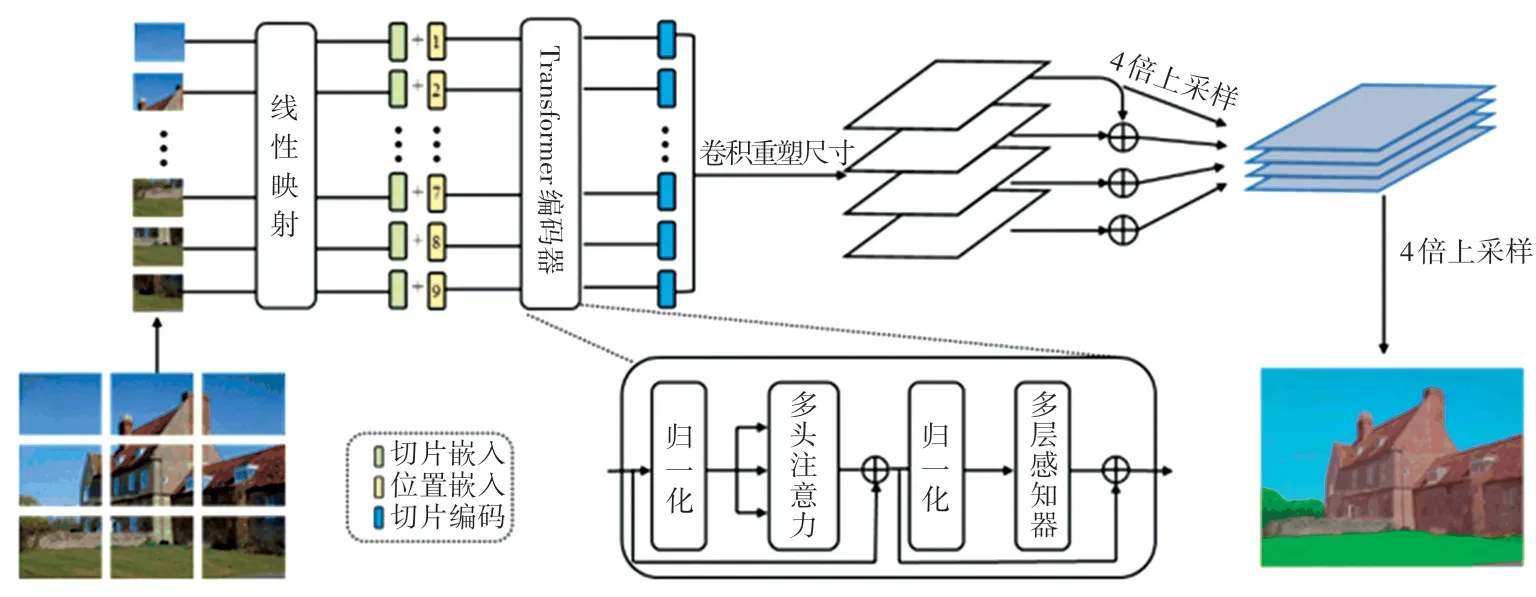
图1 MFAVT 结构示意图Fig.1 The illustration of MFAVT
1.1 编码器
标准的Transformer 网络编码器接收一维的序列词符作为输入,但二维图像和一维序列之间存在不匹配的问题,因此需要将二维图像重塑为一维序列。 具体而言,将输入图像x∈ℝH×W×C分割成一系列切片x =[x1,…,xN] ∈ℝN×P2×C。 其中,(H,W)是原始图像的分辨率,C是图像的通道数,(P,P) 是每个图像切片的分辨率,N =HW/P2是生成的切片数量,且是transformer 有效序列输入长度。 将每个切片展平为一个序列,使用线性投影函数将其映射到切片嵌入, 得到图像X的一维切片嵌入序列x0=[Ex1,…,ExN] ∈ℝN×D,其中E∈ℝD×(P2C)。 为了对切片的空间信息进行编码,添加一个可学习的位置嵌入p =[p1,…,pN] ∈ℝN×D到序列切片中,以形成最终的输入序列g0=x0+p。
以一维嵌入序列g0作为输入,采用基于纯transformer[10]网 络 的 编 码 器 学 习 特 征 表 示。Transformer 网络层由多头自注意力(Multi-head Self-attention, MSA)块和多层感知器(Multilayer Perception,MLP)块组成。 在每个块之前使用层归一化(Layer Normalization, LN),在每个块之后添加残差链接,计算过程如式(1)所示。
其中,i∈{1,…,L}。
MSA 由多个独立的SA 操作组成,并投射其级联输出。 自注意力层通过查询(Query)与键(Key)-值(Value)对之间的交互,实现信息的动态聚合。 对输入序列, 通过线性映射矩阵将其映射到Q、K、V(Q,K,V∈ℝN×D)3 个向量,计算Q和K间的相似度,并对V进行加权处理。 自注意力计算公式如式(2)所示:
Transformer 网络编码器将带位置信息的切片嵌入连续序列g0=[g0,1, …,g0,N],编码成一个供解码器使用的、带有丰富语义信息的序列gL =[gL,1, …,gL,N]。
1.2 解码器
解码器的目标是将切片编码序列gL∈ℝN×D解码成分割图Seg∈ℝH×W×K。 其中,K是类别数量。解码器来自编码器的切片级编码映射到切片级别类分数,通过双线性插值将这些切片级别的类分数向上采样到像素级别的分数。 下面将描述一个线性解码器作为基线对比,以及介绍MFAVT 解码器。
(1)线性解码器:首先使用了一个逐点线性层(1× 1 卷积+同步批归一化(ReLU) +1 × 1 卷积)将Transformer 网络特征gL∈ℝN×D投影到切片类维度gbas∈ℝN×K(例如对Pascal Context 数据集是59),然后将序列重整为二维特征图Segbas∈ℝH/P×W/P×K并双线性上采样到原始图像大小Seg∈ℝH×W×K,最后在类维度上应用一个像素级交叉熵损失的分类层。 当使用这种解码器时,称其为Seg-Basic。
(2)MFAVT 解码器:采用多级特征融合的方式设计编码器,核心思想类似于特征金字塔网络。 具体地说,将Transformer 网络编码器的特征表示均匀分布在4 层中,到达解码器;然后部署4 个流,每个流聚焦于一个特定的选定层;在每个流中,将特征编码从2D 特征转换为3D 特征采用3 层(卷积核大小为1×1、3×3 和3×3)网络,第一层和第三层分别将特征通道减半,第三层之后通过双线性运算将空间分辨率提升4 倍,通过元素添加引入自上而下的聚合设计,来增强不同流之间的交互;按元素添加后,再使用一个3×3 卷积;最后使用通道级联获得所有流的融合特征,通过4 倍双线性上采样操作恢复图像到原始分辨率,形成最终的分割图。 当使用这种解码器时,称其为Seg-MFAVT。
2 实验结果与分析
2.1 数据集
实验在3 个公开数据集上进行。 其中,ADE20K[11]是最具挑战性的语义分割数据集之一,该训练集包含20 210 幅图像,150 个语义类。 验证集和测试集分别包含2 000 和3 352 幅图像。 Pascal Context[12]数据集为整个场景提供像素级语义标签,包含4 998(最常见的59 个类和背景类)和5 105 张用于训练和验证的图像。 Cityscapes[13]数据集侧重于从汽车角度对城市街道场景进行语义理解。 该数据集分为训练集、验证集和测试集,分别有2 975、500 和1 525张图像;注释包括30 个类,其中19 类用于语义分割任务;数据集的图像具有2 048×1 024 的高分辨率,本文实验采用其中的精细标注图像数据集。
2.2 实验设置
2.2.1 实验环境
实验运行环境为Win10 专业版操作系统,处理器为Intel Core i9-9900k,内存32 GB,图形处理卡为一张Nvidia GeForce GTX1080 Ti(11 GB),Cuda版 本 为 10.2, 数 据 处 理 使 用 Python3.6 和Matlab2020a。
2.2.2 数据增强
训练期间,遵循语义分割库MMSegmentation[14]中的标准流程,使用比例因子(0.5、0.75、1.0、1.25、1.5、1.75)对图像执行多比例缩放以及随机的水平翻转。 随机裁剪大图像,并将小图像填充到固定尺寸大小:ADE20K 为512×512,Pascal Context 为480×480,Cityscapes 为768×768。 辅助分割损失有助于模型训练,每个辅助损失头遵循2 层网络,辅助损失和主损失头共同使用,此外在解码器和辅助损失头使用同步批归一化操作。
2.2.3 优化
使用标准的像素级交叉熵损失对语义分割任务的预训练模型进行微调,而无需重新平衡权重。 使用随机梯度下降(SGD)[15]作为优化器,基本学习率β0,并将权重衰减设置为0。 采用“poly”学习率衰减其中Niter和Ntotal表示当前迭代次数和总迭代次数。 对于ADE20K,其基本学习率β0设置为10-4,并以16 个批量进行160 K 次迭代;Pascal Context,将β0设置为10-4,并训练160 K迭代,批量大小为16;Cityscapes,将β0设置为10-3,并以8 的批量进行160 K 迭代。
2.2.4 预训练
使用VIT[5]和Deit[6](一种VIT 的变体)提供的预训练权重,初始化模型中的所有Transformer 网络层和输入线性投影层。 将Seg-MFAVT-Deit 表示为利用Deit 中预训练模型的同时,使用MFAVT 作为解码器。 所有未经预训练的层均随机初始化。
2.2.5 推理
使用平均交并比(mean Intersection over Union,mIoU)作为语义分割性能的评估指标。 实验报告了单尺度(Single Scale,SS)和多尺度(Multi Scale,MS)推理。 对于多尺度推理,使用比例因子(0.5、0.75、1.0、1.25、1.5、1.75)对图像执行多比例缩放和随机水平翻转。 测试采用滑动窗口(例如,Pascal 上下文为480×480)。 如果图像尺寸的短边长度小于滑动窗口,则在保持纵横比的同时,将短边长度调整为滑动窗口的大小(例如480)。
2.3 消融实验
本节将在Cityscapes 验证集上进行消融实验,评估了Transformer 网络层大小、补丁大小、预训练集数据大小、模型性能、与FCN 卷积网络的比较,并验证了不同的解码器。 除非另有说明,否则使用8批次处理,80 K 迭代次数,并使用单尺度推断报告结果。 表1 中“R”代表随机初始化权重。
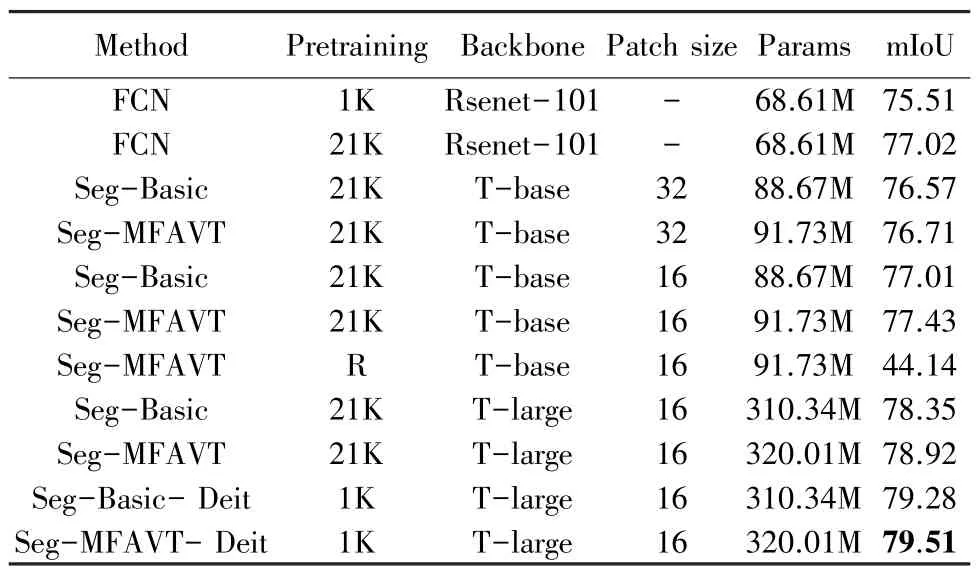
表1 不同分割模型变体的性能比较Tab.1 Performance of different segmentation variants
观察表1 中数据,可以得出如下结论:
(1)Seg-MFAVT-Deit 在所有的变体中取得了最佳的性能表现。
(2)使用T-large 的变体优于T-base 的对照物,这与实验预期一样,即Transformer 网络层数加深会相对应的增强模型性能。 如:Seg-MFAVT 使用的主干网络(Backbone)从T-base 转换到T-large,获得了1.92%的提升。
(3)切片尺寸(patch size)是语义分割性能的关键因素,切片尺寸从32 到16,Seg-MFAVT 提高了0.72%。可见,当图像用切片表示时,较大的切片尺寸会使模型获得有意义的全局分割,但是会产生较差的边界;而使用较小的切片尺寸会使图像边界更清晰。这一结果表明,减少切片尺寸是一个能够获得强大性能的改进来源,其不会引入任何参数,但是需要在更长的序列中计算注意力,从而增加计算时间和成本。
(4)预训练模型对于模型性能的表现至关重要。随机初始化权重的Seg-MFAVT 只达到了44.14%MIoU,显著低于其它变体。 在Imagenet-1K 上用Deit预先训练好的模型略优于在Imagenet-21K 上用VIT预先训练出的模型。
(5)为了与FCN 基线进行公平比较,使用分类任务,在Imagenet-21K 和1K 上对Resnet101 进行预训练,然后在Cityscapes 上采用预训练权重进行FCN 训练。 与在Imagenet-1K 上的预训练变体相比,在Imagenet-21K 上预训练的FCN 基线得到了明显地改善。 但是,本文方法在很大程度上优于FCN 方法,体现了所提出的多层聚合策略方法的有效性,而不是更大的预训练数据。
2.4 对比分析
为了验证MFAVT 的有效性与先进性,将MFAVT 与一些对比方法在Cityscapes、ADE20K 和Pascal Context 数据集上进行性能比较。 测试结果在表2~表4 中进行展示。 在数据可视化中,为方便直观地展现分割效果,将分割结果图与原图像进行叠加并采用一定的透明化处理,以DeeplabV3+分割结果代表其他方法作为锚定参照对象,与MFAVT分割结果进行突出化对比,结果如图2~图4 所示。

表2 在ADE20K 验证集上的性能表现Tab.2 Performance comparison on ADE20K validation set

图2 在ADE20K 上定性的可视化结果Fig.2 Qualitative visualization results on ADE20K
表2 展示了在最具挑战性的ADE20K 数据集上的结果,Seg-MFAVT 在单尺度推理下(SS),取得了48.01%的mIoU 分数,在多尺度推理(MS)下取得了最佳的49.97%的mIoU 分数,优于所有的卷积网络方法,比DeeplabV3+的mIoU 分数高出3.58%。 图2展示了在ADE20K 上定性的可视化结果。
表3 比较了在Pascal Context 上的分割结果。在单尺度推理时,Seg-MFAVT 得到了54.16%的mIoU 分数,而在多尺度推理时获得了最佳的55.43%mIoU 分数,超过了所有FCN 方法。 与最有竞争力的APCNet 相比,mIoU 分数提高了0.73%。 图3 展示了在Pascal Context 上定性的可视化结果。
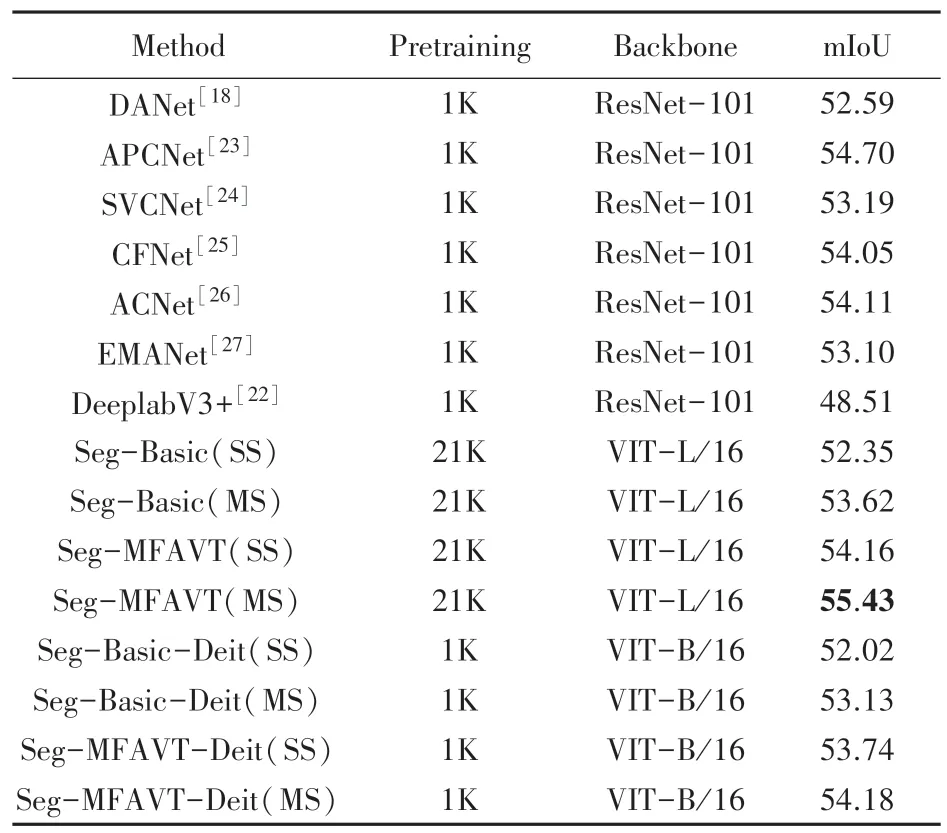
表3 在Pascal Context 验证集上的性能表现Tab.3 Performance comparison on Pascal Context validation set

图3 在Pascal Context 上定性的可视化结果Fig.3 Qualitative visualization results on Pascal Context
在Cityscapes 验证集上的比较结果见表4。 Seg-MFAVT 在单尺度推理下取得了79.42%的mIoU 分数,而在多尺度推理下取得了令人印象深刻的82.03%mIoU 分数。 需要注意的是相比于一些方法在训练中采用全尺寸图像分辨率(2 048×1 024)输入,MFAVT 的图像输入尺寸为768×768,训练过程有一定劣势,但最终的性能表现超过了其他有竞争力的方法。 与DeeplabV3+相比提高了2.71%mIoU,与最有竞争力的DNL 相比提高了1.53%mIoU。 图4展示了在Cityscapes 上定性的可视化结果。
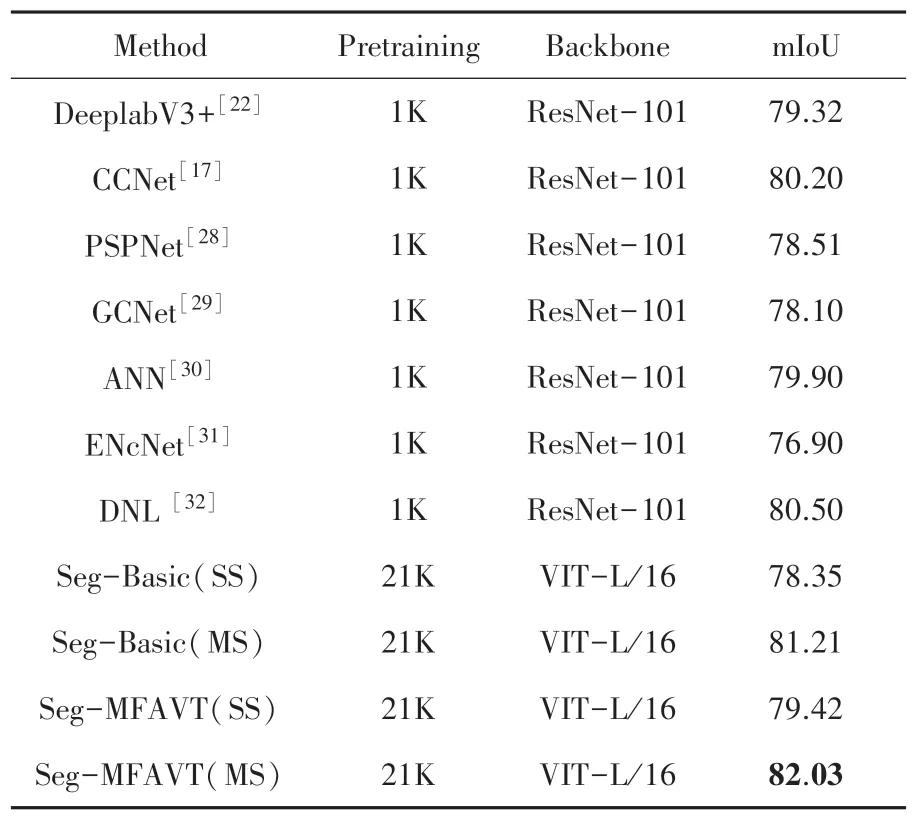
表4 在Cityscapes 验证集上的性能表现Tab.4 Performance comparison on Cityscapes validation set
3 结束语
本文介绍了一种基于视觉Transformer 的序列到序列的分割方法,为语义分割任务提供了一种新的视角。 现有的基于FCN 的方法通常使用扩张卷积和注意力模块来扩大感受野,与之相比,本文的编码器部分采用当下流行的视觉Transformer 主干网络,对图像切片进行编码。 基于视觉Transformer 的编码器很好地建模了全局上下文信息,随着一组不同的复杂性的解码器设计,建立了强大的分割模型。简单的线性解码器就取得了非常好的效果,使用MFAVT 进行解码进一步提高了性能。 大量的实验表 明, 本 文 方 法 在 ADE20K、 Pascal Context 和Cityscapes 数据集测试上展示了最佳的性能表现。
