基于自适应动态加权图的会话推荐系统
2023-10-30姜宜鑫吴杰
姜宜鑫 吴杰
辽宁科技大学计算机与软件工程学院 辽宁 鞍山 114051
引言
对话推荐系统(CRS)的目标是通过互动对话的方式了解用户的喜好并推荐。作为推荐系统重要的研究方向,具有明确获取用户偏好和揭示推荐原因的天然优势,CRS已经成为推荐系统的研究热点之一,并受到越来越多的关注。传统的推荐系统和交互式推荐系统(IRS)主要解决推荐哪些项目问题,而CRS一般存在两个核心问题,分别是问题提问的时间和内容,通过问题的提问方式,引导用户提供推荐信息。研究表明,询问问题对CRS的推荐性能影响巨大。
1 相关研究
根据问题设置的不同,可以将CRS相关研究分为四种。第一种使用强规则[1-3],解决用户推荐中的冷启动问题;第二种为问题驱动的方法[4-6],旨在向用户提问,以获取关于他们偏好的更多信息;第三种方法为对话理解与生成,这种方法旨在理解用户的喜好,从他们的话语中传递有效的推荐信息。
神经网络中基于图的推荐研究主要包括两种方法。一是通过图表示学习提高推荐性能,包括利用结构信息进行协同过滤;采用图嵌入作为丰富的上下文信息。另一种将推荐建模问题转化为路径推理问题,以构建可解释的推荐系统。神经网络中基于图的推荐研究主要包括两种方法。一种是通过图表示学习提高推荐性能,包括利用结构信息进行协同过滤;采用图嵌入作为丰富的上下文信息。另一种将推荐建模问题转化为路径推理问题,以构建可解释的推荐系统。本文研究了基于动态加权图的会话推荐系统,综合了上述模型的优点,实验结果性能更好。
2 模型结构
本文提出的方法主要包括:基于图的MDP环境、图表示学习、行动选择策略和深度Q-Learning网络。MDP环境负责通知代理当前状态和可能采取的操作,然后根据当前策略观察用户交互奖励代理。在形式上,MDP环境可以定义为一个元组其中表示状态空间,为动作空间,表示状态转移函数,表示奖励函数。状态空间主要为会话推荐的所有信息,包括会话历史和所有用户、项目和属性的全图。给定一个用户u,主要考虑两个元素:
2.1 基于图的MDP环境
MDP环境负责通知代理当前状态和可能采取的操作,然后根据当前策略观察用户交互奖励代理。在形式上,MDP环境可以定义为一个元组其中表示状态空间,为动作空间,表示状态转移函数,表示奖励函数。
结合目前的MCR研究,我们的环境包含五种奖励:当用户接受推荐项时会获得一个强奖励;当用户获得推荐项时,获得一个负奖励;当用户接受询问属性时,获得一个次级正奖励;当用户拒绝请求属性时,获得一个负奖励;当达到最大回合数时,获得一个强消极奖励。
2.2 图表示学习
基于图的MDP环境中,将会话推荐作为统一的策略学习问题,因此需要将会话和图结构信息编码到潜在的分布式表示中。为了利用用户、项目和属性之间的相互关系,采用基于图神经网络的预训练方法,对全图G中的所有结点进行节点嵌入。
将基于图的MDP环境的当前状态表示为一个动态加权图。定义一个无向加权图其中为图的节点集合,表示边的集合,表示节点集合中的每个元素,间的边。
除了涉及的用户、项目和属性之间的相互关系,CRS还期望在当前状态下对会话历史建模。与启发式特征进行会话历史的研究不同,使用Transformer编码器捕获会话历史记录的顺序信息,并参与决定下一个动作的重要信息。
2.3 行为选择策略
行为搜索空间将在很大的程度上影响策略学习的性能。处理巨大的操作空间特征非常重要。本文提出两种简单的策略提高候选行动选择的样本效率。
对于推荐的候选项目,只考虑从少数最符合用户偏好的候选项目中推荐,因为用户不太可能对所有项目感兴趣。而对于要求的候选属性,期望属性不仅能够很好地消除选项的不确定性,而且还能编码用户偏好,采用加权熵作为筛选候选属性的标准。
2.4 深度Q-Learning网络
获取图表示和动作空间后,使用深度Q-Learning网络完成统一的对话推荐策略。根据延迟奖励的标准假设,每一个时间步都要计算对应的奖励,定义表示为状态行动的预期奖励。Q-network利用两个深度神经网络计算价值函数和优势函数
模型学习后,给定一个用户和他的对话历史,遵循同样的过程来获得候选动作空间和当前状态表示,然后根据最大间隔值Q决定下一个动作。如果选择的操作指向一个属性,系统将询问用户对该属性的偏好程度,如果选择操作指向项目,则将这个项目推荐给用户。
3 实验过程与结果分析
表1显示了本文提出的方法和UNICORN方法对比,同时比较了在这些数据集上的基线模型。总体来说,UNICORN的成功率明显更高,平均回合数更少。对于真实的电子商务数据集,SCPR优于EAR和CRM,它们的性能在很大程度上受到了电子商务数据集中较大的操作空间的影响。具体分析如下:
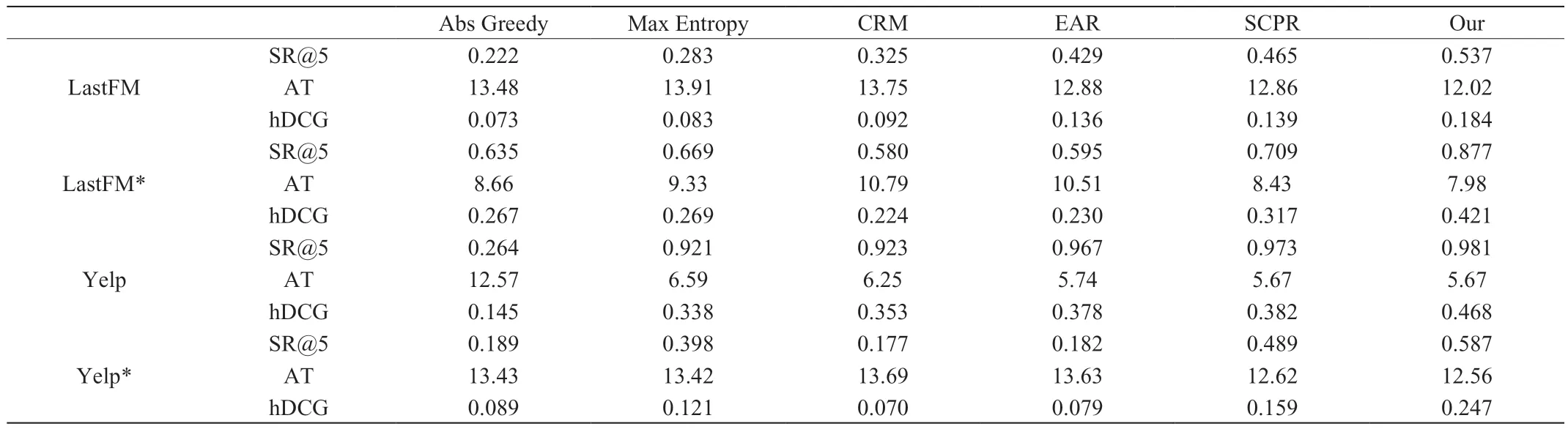
表1 不同数据集的结果
由表中的数据可以清晰的看到,本文提出的模型训练更加稳定,需要更少的交互回合数,就能获得更好的性能。在这些基线模型中,SCPR曲线是最活跃的,因为它只考虑什么时候询问和建议决策,而询问和建议决策是两个独立的组成部分。对于EAR和CRM模型,由于前3个数据集的动作空间较大,在模型的训练过程中,并没有明显的性能提升,甚至模型性能更差。这些结果证明了所提出的统一策略学习方法的有效性。为了更好地观察不同方法的差异,表中展示了最先进的基线SCPR的推荐成功率。值得注意的是:在所有数据集和几乎每一次对话中,本文提出的模型性能都大大超过了这些基线模型;由于贪婪匹配推荐的方法,对会话的早期阶段成功击中目标,导致在前几个回合中表现较强,但是,随着回合的增加,这个性能会迅速下降;本文提出的方法在会话的中间阶段表现突出,此时仍然有大量的候选项目和属性需要删除。这种现象表明,本文提出的方法在不同的情况下有效处理大型候选空间的强大可扩展性;SCPR在对话后期的性能越来越接近本文提出的方法,因为候选项和属性集越来越小,任务变得越来越容易;EAR和CRM在具有大型候选属性集和数据集中具有与AbsGreedy相似的性能,这表明他们的政策学习只是在遇到大的行动空间时才会起作用。
本文提出的模型和最先进的CRS模型相比,从电子商务数据集随机抽样的真实世界交互之间差异明显。面对巨大的候选操作空间,CRM倾向于只触发推荐组件进行推荐,而EAR则不断地询问用户不喜欢的问题。尽管SCPR在预测用户偏好属性方面取得了成功,但是SCPR中的策略学习只是根据候选条目数量决定何时提问或推荐,这导致了一些不必要或冗余的问题循环。本文提出的模型通过对下一步行动做出全面的评估,系统的解决了这些问题。
4 结束语
本研究将3种独立的CRS决策过程,包括何时询问或建议、问什么和推荐什么,作为一个统一规则学习问题。为了解决统一会话推荐策略学习问题,提出一种基于动态加权图的自适应RL框架。此外,本文进一步设计了2个简单而有效的行动选择策略处理样本效率问题,实验结果证明,该模型的性能明显优于4个基准数据集,并具有显著的可扩展性和稳定性。
