融合双阶段解码的实体关系联合抽取方法
2023-10-30常思杰林浩田
常思杰,林浩田,江 静
北京联合大学 智慧城市学院 物联网与机器人实验室,北京 100101
构建知识图谱需要大量的三元组,三元组的获取除了可以通过IS-A 的上下位获取,再就是关系抽取。关系抽取可以把文本中的实体对抽取出来,并识别出实体对之间的语义关系,形成(主体实体,关系,客体实体)的形式,这种包含了语义关键信息的形式,称为实体-关系(entity-relation)三元组(triplets)。因此,关系抽取可以在知识图谱、信息检索、问答系统、情感分析、文本挖掘中广泛应用。
现有的关系抽取主要包括有监督方法、无监督方法、半监督方法和开放式实体关系抽取方法。基于深度学习阶段的监督实体关系抽取方法主要有流水线(Pipline)方法[1]和联合(Joint)方法[2]两种。在Pipline 中将实体抽取与关系抽取分为两个独立的过程,可以先做实体识别再做关系抽取,也可以先做关系抽取再做实体识别,这种方法在精度上可以达到很好的效果,但是容易造成误差累积和实体冗余,同时也忽略了两个任务之间的内在联系和依赖关系。在Joint中把实体抽取与关系抽取两个任务同时进行,通常用模型参数共享的方法来实现,相比于Pipline的方式可以有效利用两个任务之间的潜在信息,从而缓解错误传播的缺点,但是如何加强实体抽取和关系抽取的交互、如何解决实体重叠问题是联合抽取的难点。
早期Zeng等人[3]提出基于卷积神经网络(convolutional neural networks,CNN)、Socher 等人[4]提出基于循环神经网络(recurrent neural network,RNN)进行关系抽取,都有效提取出了单词和句子级别的特征,但是由于网络本身的特点,不能很好地将上下文的语义联系有效提取出来。Miwa 等人[5]提出了一种基于RNN 的端到端神经模型,该方法将单词embedding 之后,在解码时分别用了双向长短期记忆模型(bi-directional long-short term memory,Bi-LSTM)和Bi-TreeLSTM 建模对序列数据进行实体检测和关系分类。但是,并不是每个实体对之间都存在关系,这种方法[5]将两两配对的实体作为关系分类的输入,会造成实体冗余。为解决这个问题,Zheng等人[6]提出了一种新的标签方案,该方法将联合抽取问题转换成了标注问题,这种端到端的模型展现出较好的性能,但是基于标签生成的实体关系对三元组采用了就近组合的方式,因此会存在很多的问题,同时也无法解决实体关系重叠问题[7]。为解决关系重叠问题,Wei 等人[8]提出了一种新的级联二进制标记框架(CasRel),CasRel框架首先抽取出主体实体,然后在特定的关系下抽取客体实体,这种方法直接在三元组级别上进行优化,在关系的两端抽取出唯一实体对,减少了重叠问题。
为解决端到端关系抽取中的自回归解码的限制,Sui 等人[9]提出了一种无需固定关系顺序的集合预测网络SPN 模型,模型先使用Bert 和字节对编码(byte pair encode,BPE),然后用N个包含关系之间的self-attention、关系与句子之间的inter-attention(cross-attention)的transformer层解码关系三元组,解决了自回归解码器中需要固定关系三元组顺序的问题。但是,由于主体实体、客体实体和关系同时被解码出来,可能存在主客实体之间联系性不强、实体与关系之间交互不理想的问题。
鉴于上述条件,本文提出了一种融合双阶段解码的实体关系联合抽取模型。模型遵循了端到端的工作方法,解决实体关系联合抽取的问题。在级联解码实体的基础上,采用集合预测的方法抽取关系三元组,可以加强实体与实体之间、实体与关系之间的交互。模型由三部分组成:句子编码器、实体解码器和关系集合预测网络。首先采用Bert[10]作为句子编码器,然后基于多头注意力机制识别实体,最后在生成关系时采用基于注意力机制的关系集合预测网络解码出嵌入主客实体信息的关系三元组。
本文的贡献在于:
(1)提出一个新的端到端的网络模型,基于级联解码的思想,识别主体实体和客体实体,抽取出的实体不受关系的限制,缓解了实体识别的不平衡性。
(2)提出一种新的集合预测方法,将抽取出的实体融合到全文信息后嵌入到集合预测网络,抽取出关系。通过同一编码器实现共享参数,加强实体与关系之间的联系和交互,同时进一步加强实体与实体之间的联系。
(3)本文提出的方法在NYT 和WebNLG 两个公开数据集上的实验证明,该方法在准确率和F1 值上表现较优,并且在复杂情况下的抽取结果具有一定优势;在ACE2005 数据集上证明,该方法在准确率上表现较优,在解决关系抽取问题中具有可靠性。证明了模型的有效性。
1 关系抽取的研究现状
1.1 基于流水线的方法
现有的基于深度学习的监督方法可以将关系抽取任务分为基于流水线的方法和基于联合的方法。基于流水线的方法将关系抽取任务划分为命名实体识别[11]和关系抽取[12]两个任务,例如Wang等人[13]和Cai等人[14]的工作。Zhong 和Chen[15]提出了一种优于大部分联合模型的流水线方法,该方法基于两个独立的编码器,将实体模型作为关系模型的输入,验证了在关系模型中融合实体信息以及合并全局上下文的重要性。由于两个任务串联进行,因此,实体识别任务和关系抽取任务不能很好地交互;同时,前一个任务的错误会累积到下一个任务中,从而产生误差传递的问题;最后,实体对是两两组合产生的,但是并不是每个实体对都存在关系,这样就会产生冗余实体,也会产生误差传播,从而降低整个模型的性能。
1.2 基于联合抽取的方法
为解决流水线模型的弊端,越来越多的学者尝试用联合模型来解决关系抽取问题。联合学习模型可以同时识别实体和关系,直接得到实体-关系三元组。按照建模对象的不同,又将联合模型分为共享参数的方法和序列标注的方法。其中,共享参数的方法有效解决了错误传播的问题。Li 等人[16]在Miwa 等人[5]提出的模型上进行了两点改进:(1)在关系分类任务中引入了一种新的关系,以区分有效实体和无效实体;(2)为了避免单向逐步预测实体标签产生的错误传播问题,将解码方式由贪婪搜索换为波束搜索。Katiyar 等人[17]还提出了一种无需访问依赖树的基于注意力的递归神经网络,模型由多层双向递归网络组成,并使用顶层的隐藏表示进行联合实体和关系提取。不同于在单个编码器内捕获两个任务信息的设计,Wang 等人[18]构造了表编码器和序列编码器分别捕获两种不同任务的信息,并且在表示过程中相互学习,将联合任务转化成表格填充问题。序列标注的方法除了可以解决错误传播的问题,同时还解决了实体冗余的问题。Li 等人[19]将实体关系抽取问题转化为多轮问答问题,模型首先查询要识别的实体类或者关系类编码的重要信息,然后联合建模实体和关系,利用机器阅读理解模型抽取实体或者关系。
1.3 联合抽中的重叠问题
目前,按照实体的重叠程度,可以将重叠问题划分为三种类型[8]:正常类(Normal),单实体重叠(single entity overlap,SEO)和实体对重叠(entity pair overlap,EPO),示例如表1所示。

表1 关系重叠示例Table 1 Examples of overlapping relationships
解决关系重叠问题又分为基于序列到序列(sequence to sequence,Seq2Seq)、基于图(graph-based)和基于预训练语言模型(pre-trained language model,PTM)三种方法。在这些方法之下又按照解决问题建模方式的不同分为级联解码(cascade decoding)的方法和编码器-解码器(encoder-decoder)方法。
Ma 等人[20]提出了一种级联双解码抽取模型,不同于先检测实体的模型,该方法首先检测句子中的关系,然后在特定的关系下依次抽取主体实体和客体实体,使得该模型在解决重叠问题上也达到了很好的效果。Dixit 等人[21]为解决span-level 特征的重叠实体建模问题,并缓解顺序解码存在的级联错误,提出了一种可以直接建模所有可能span 的模型。田佳来等人[22]提出了一种基于BIO标注方案的分层序列标注方法,在抽取出主体实体的前提下,按照预先定义的关系类别抽取出客体实体,从而抽取出实体-关系三元组,该方法同时引入了GLU Dilated CNN 对句子进行编码,采用自注意力机制提高模型抽取能力,在WebNLG 公开数据集上F1值达到86.4%,并成功将模型运用到军事领域,F1 值达到80.84%。这些级联解码的方法,在一定程度上都受到了特定条件的限制,使解码的实体和关系之间的重要程度不平衡。
Zeng 等人[23]提出一种采用自回归解码器且具有复制机制的CopyRE模型,该模型在解决重叠问题上取得一定的效果,但是复制机制导致识别实体不全,且顺序解码三元组限制了无序关系的抽取。后来,Zeng等人[24]虽然在原有的模型上进行改进,但是并未打破自回归解码器本身的限制,得到的三元组依然存在交互不平衡的问题。
以解决关系抽取的重叠问题为方向,解决三元组内部及三元组之间的交互问题和不平衡问题为目标。本文提出一种新的实体关系联合抽取模型。模型首先采用Bert进行编码,然后采用级联解码的思想先解码主体实体和客体实体,最后将初步所得的结果嵌入到非自回归解码器中,解码出关系,从而得到实体-关系三元组。
2 融合双阶段解码的联合抽取方法
把关系预测问题转换为三元组建模问题。关系抽取的目标为抽取句子中的(s,r,o),其中,s为主体实体,o为客体实体,r为主客实体之间的关系。Seq2Seq模型的解码方法如式(1)所示:
其中,x为先验句子,为解码出的词语,给定一个句子x,在所有y上建模,使生成的概率最大似然。由此,可以得出三元组的抽取方法如式(2)所示:
其中,x是输入的句子。首先抽取出主语s和客体o,然后将句子x和实体解码出关系r。最终从输入的句子中,得到n个实体si(i=1,2,…,n)和m个客体实体oj(j=1,2,…,m)以及它们之间的关系
本章将详细介绍模型的三个组成部分:句子编码器、实体解码器和非自回归解码器。本文模型框架如图1 所示。其中Te表示BERT 编码的句子向量;Sstart和Send分别表示主体实体的开始位置和结束位置,Ostart和Oend分别表示客体实体的开始位置和结束位置。

图1 模型框架Fig.1 Model framework
2.1 任务定义
实体关系联合抽取是将给定句子中所有的实体以及所有实体之间的关系三元组抽取出来。给定一个句子,句子S=(x1,x2,…,xn)中包含n个字符,给定一个目标三元组集合,集合Y={(s1,r1,o1),(s2,r2,o2),…,(sm,rm,om)|si,oi∈E,ri∈R}包含m个三元组,其中E和R分别为实体集和关系集。整个任务的算法流程图如图2 所示。在实体关系联合抽取中将抽取出每一个句子的所有实体-关系三元组作为任务目的。

图2 算法流程图Fig.2 Chart of algorithm flow
2.2 句子编码器
为了加强句子中每个字符之间的感知,更好地获得句子的上下文表征,本文采用来源于Transformer 双向编码器的Bert 为输入模型中的句子进行编码,其中,Bert结构如图3所示,计算方法如式(3)和(4)所示:
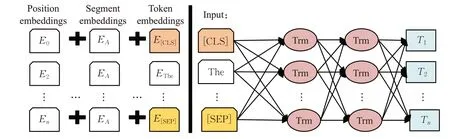
图3 Bert网络结构模型Fig.3 Network structure model of Bert
其中,S为输入句子中字词索引的one-hot 矩阵,Ws为字词的embedding 矩阵,Wp为所有位置索引p的位置嵌入矩阵。hα为输入句子在第α层的上下文表示。编码后得到的每个字符的上下文特征为,其中n为句子的字符个数,d为隐藏单元数量。
2.3 实体解码器
实体解码器的目标是得到实体信息。在解码实体的过程中采用多头注意力机制[25]来进一步提取特征。同时,基于一个二进制分类器,从输入的句子中检测到主体实体,其中包括主体实体的开始位置和结束位置,然后将检测到的候选实体作为下一阶段解码任务的先验知识。首先,将经过Bert编码得到的特征通过多头注意力机制进行建模,过程如式(5)所示:
其中,表示第i个token经过Bert编码和多头注意力机制后得到的向量表示。然后经过全连接层得到输出代表标签的数量的维度,以此来标记主体实体的开始位置和结束位置。计算方法如式(6)和(7)所示:
2.4 关系集合预测网络
非自回归解码器由N个transformer 层构成,对关系的预测本身是无序的,因此采用该解码模块可以不考虑三元组的顺序问题。采用集合预测方法生成三元组的条件概率如式(8)所示:
其中,PL(m|S)表示目标三元组集合的大小,m表示三元组个数,P(Yi|S,Yi≠j;θ)表示Yi不仅与给定句子S有关,还与其他三元组Yj≠i有关。
由于将解码得到的实体嵌入到了预测三元组的解码器中,同时又受到SPN 模型[9]和DSPNEF 模型[26]的启发,将式(8)中条件概率公式展开为式(9)所示:
其中,ki是经过transformer层得到的第i个三元组的嵌入信息,最后通过前馈神经网络将ki解码成预测的实体-关系三元组。为加强实体信息在三元组预测中的作用,本文将得到的实体信息拼接到Bert 编码的输出中,构建实体信息增强的原始数据信息表示。
在具体操作中,首先需要将三元组初始化,同时设定PL(m|S)的大小为m,其中m的个数远大于句子中真实三元组的数量。初始化过程表示为式(10)所示:
其中,表示第i个三元组的嵌入信息,gi表示初始化的三元组,Wg∈Rm×d表示训练权重,bg表示偏置项。初始化的三元组首先经过多头自注意力的建模,建模过程如式(11)所示:
其中,ci表示融合了其他三元组特征的第i个三元组经过多头自注意力的输出。然后,通过多头间注意力将新的句子信息融合到初始建模的三元组中,具体过程如式(12)所示:
其中,表示第i个三元组经过多头间注意力的输出,te表示给定句子中带有上下文信息的Bert 编码器的输出,es=sstart+send表示主体实体,eo=ostart+oend表示客体实体。最后,采用前馈神经网络将关系解码出来,计算方法如式(13)所示:
其中,pr为预测的关系类型,Wr∈Rt×d表示可训练的权重。并且通过四个分类器分别预测主体和客体的开始位置和结束位置索引,计算方法如下式所示:
2.5 损失函数
3 实验数据与分析
3.1 数据集
为完成实体关系联合抽取任务并解决重叠问题,本文在三个公开数据集上评估本文模型:NYT 数据集、WebNLG数据集和ACE2005数据集。
NYT 数据集是由远程监督生成的新闻语料库,数据集中包括了24种预定义的关系。WebNLG数据集起初是为自然语言生成准备的,数据集包括了246种预定义的关系。这两个数据集都按照三元组的不同重叠程度划分出了三种类型[8],即正常类(Normal)、单实体重叠(SEO)和实体对重叠(EPO),需要注意的是一个句子既可以属于SEO类型也可以属于EPO类型。本文采用SPN[9]中的数据集。
ACE2005 数据集包含7 种实体类型和6 种关系类型,有英语、阿拉伯语和普通话三种语言文本,并对实体、关系和事件进行了注释。可以进行实体识别、值、关系和事件等系统性能的评估。本文将ACE2005英文文本数据集进行预处理,实现抽取与重构。具体是:抽取非结构化数据中的“sentence”信息;“entity_mentions”中的实体名称和具体实体类型,“relation_mentions”中的18种具体关系类型,并将这两部分重构,形成新的三元组。最后,对处理后的数据进行Normal、SEO和EPO三种分类统计。各数据集的统计数据如表2所示。

表2 数据集统计信息Table 2 Statistics of dataset
3.2 评价指标
本文采用评价模型性能的指标分别为:精准率(Precision)、召回率(Recall)、F1 值。当预测产生的实体-关系三元组与真实的实体-关系三元组完全一致时,作为正确识别的三元组。
3.3 基线模型
为验证本文模型的有效性,将本文模型与以下基线模型进行比较:
(1)CasRel[8]:提出一种级联二进制标记方案,首先识别主体实体,然后基于特定关系识别客体实体,直接抽取出实体-关系三元组。
(2)SPN[9]:提出一种基于Transformer的非自回归解码器的集合预测网络,同时设计一种基于集合的损失,直接预测三元组。
(3)PURE[15]:提出一种基于两个独立编码器的流水线方法,采用实体模型构建关系模型的输入。
(4)Model[17]:提出一种新的基于注意的递归神经网络,用于实体提及和关系的联合提取。
(5)Multi-turn QA[19]:提出一种新的实体关系提取范式,将实体和关系的提取转化为从上下文中识别答案范围的多轮问答任务。
(6)Model[21]:提出一种可以直接建模所有可能跨度的模型,打破了无法轻松定义和实现span-level 特征的局限性。
(7)HSL[22]:采取一种新的标记方案,基于GLU Dilated CNN编码和Bi-LSTM模型分层次解码标记的主体实体和客体实体。
(8)CopyR[23]:提出一种基于序列到序列学习和复制机制方案,采用统一解码和分离解码两种策略抽取实体和关系信息。
(9)CopyMTL[24]:提出一种带有复制机制的多任务学习框架,可以预测多标记实体,有效缓解重叠问题。
(10)GraphRel[26]:提出一种基于图卷积神经网络(GCN)的实体关系联合抽取模型,首先采用Bi-LSTM和GCN 抽取顺序和区域依赖词特征,然后基于预测的第一阶段关系构建完整的关系图,进一步考虑实体和关系之间的交互。
3.4 实验结果及分析
实验环境在Windows 系统下使用PyTorch 深度学习框架,使用CUDA框架10.2。GPU为NVIDIA GeForce RTX 3060,内存16 GB。实验复现了SPN[9]模型,在一定条件下本文模型与复现优秀模型有一定优势,但与优秀模型中的最好结果有一定差距,baseline 中展示复现结果,参数设置batch_size 为8,eopch 为100,NYT 数据集上初始化三元组个数为15,解码层个数为3,na_rel_coef为1,max_grad_norm为1,encoder_lr为1E-5,decoder_lr为2E-5,WebNLG数据集上初始化三元组个数为10,解码层个数为4,na_rel_coef为0.25,max_grad_norm为20,encoder_lr为2E-5,decoder_lr为5E-5。除此之外,还复现了用Bert进行编码的PURE[15]模型。
3.4.1 模型性能的实验评估
如表3所示,本文模型在NYT数据集上准确率达到80.5%,比SPN 模型提升了1.7 个百分点,F1 值达到73.6%,比SPN 模型提升了0.4 个百分点。在WebNLG数据集上召回率达到88.6%,比SPN 模型提升了1.6 个百分点,F1值达到88.6%,比SPN模型提升了0.5个百分点。在ACE2005 数据集上准确率比Model[21]模型提升了1.1个百分点,比PURE模型提升了2.7个百分点。

表3 模型在数据集上的实验结果Table 3 Experimental results of model on datasets 单位:%
如表4所示,展示了本文方法对实体识别和关系抽取的作用。本文模型在NYT 数据集上,对关系的抽取表现较好,这种优势主要体现在准确率(P)指标上;在WebNLG 数据集上,在实体和关系的抽取上都表现较好,这种优势主要体现在关系实体识别和关系抽取的召回率(R)指标上。
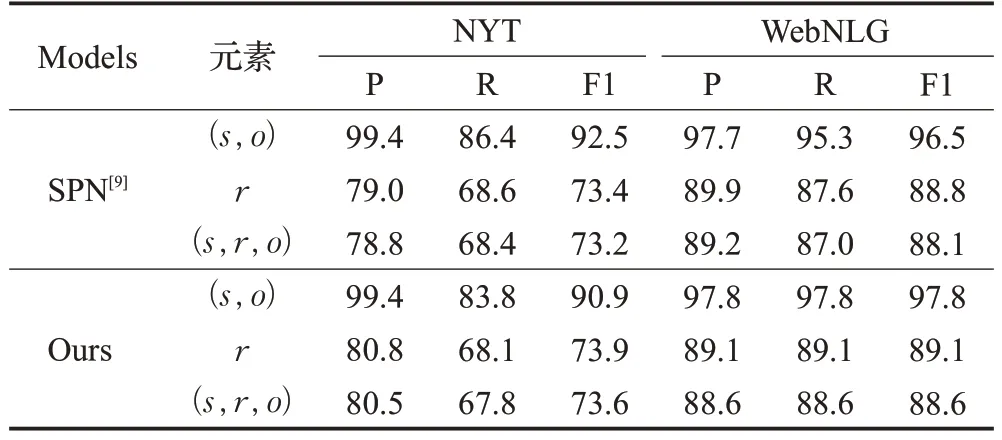
表4 模型在三元组上的实验结果Table 4 Experimental results of model on triples 单位:%
3.4.2 重叠问题的实验评估
为了验证模型在解决重叠问题上的效果,本文在NYT数据集和WebNLG数据集上做进一步的实验。
如表5 所示,对于NYT 数据集,本模型在抽取正常类(Normal)三元组时效果与其他模型差距不大,在抽取单实体重叠类(SEO)时略高于SPN模型,在抽取实体对重叠类(EPO)三元组时比SPN 模型提升了0.5 个百分点;对于WebNLG数据集,本模型在抽取正常类(Normal)三元组时效果不理想,比SPN模型的F1值低了1.9个百分点,在抽取单实体重叠类(SEO)和实体对重叠类(EPO)三元组时比SPN模型分别提升了0.5个百分点。
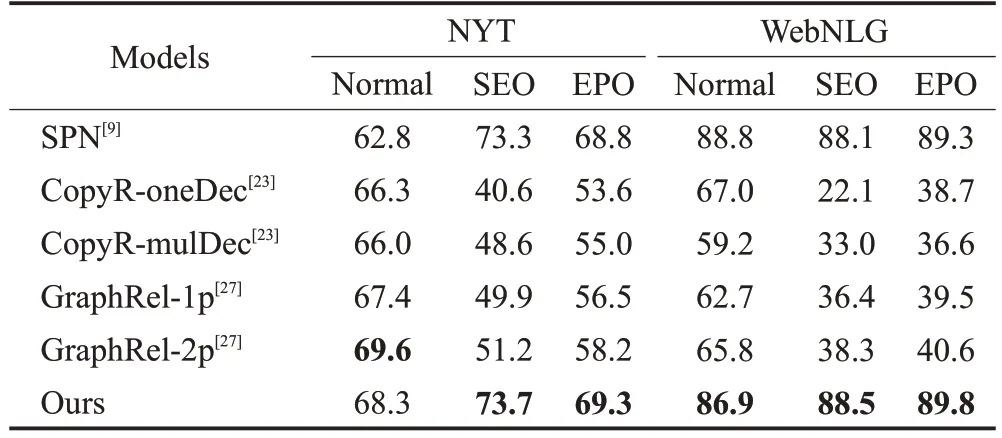
表5 模型和其他方法在测试集上的F1得分Table 5 F1 scores of model and other methods on test set 单位:%
如图4 所示,从(a)(b)(c)中看出,部分模型在处理重叠问题时出现下降趋势,说明SEO 问题和EPO 问题相比于Normal 问题是较为复杂的问题,本文模型在处理这类问题时有一定优势,且对SEO 问题和EPO 问题的处理更好一些。
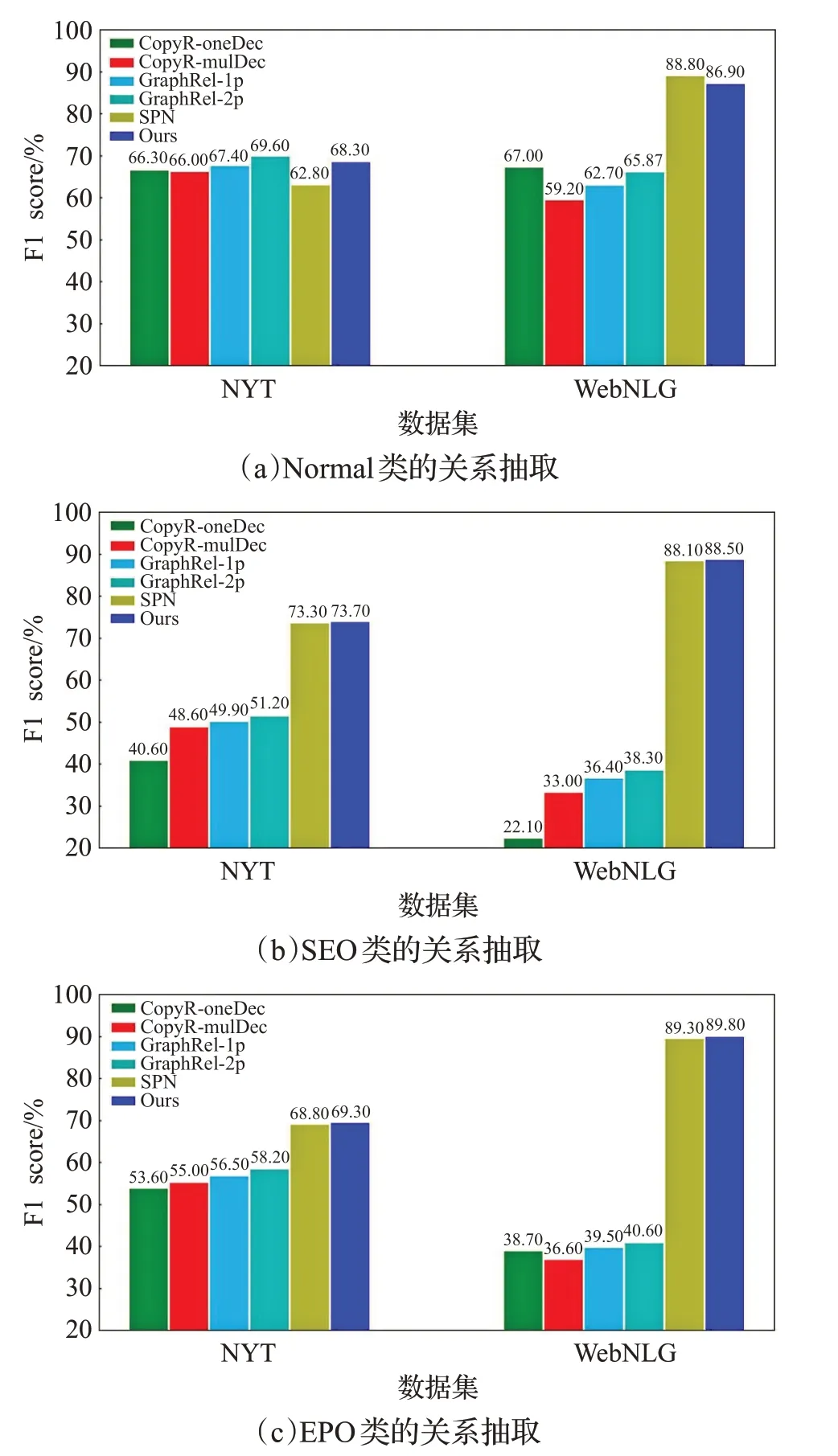
图4 不同重叠模式的句子中提取关系三元组的F1得分Fig.4 F1 score for extracting relational triples from sentences with different overlapping patterns
为了探究本文模型在不同数据集上的性能,分别在NYT 数据集、WebNLG 数据集和ACE2005 数据集上就Normal、SEO 和EPO 三个问题进行实验结果分析。实验结果如表5所示。
从表6 可以看出,在解决关系抽取中的重叠问题时,本文模型在WebNLG数据集上综合表现最优,在NYT数据集上综合表现次之,且二者都远高于在ACE2005数据集上的表现。在ACE2005 数据集中,解决Normal类问题的F1 得分远高于SEO 类和EPO 类,结合表2 中的数据集统计信息发现,在训练集和测试集中所有存在EPO类问题的句子均包含于存在SEO类问题的句子,考虑是因为该数据集中句子含有复杂的三元组信息较少,导致了模型在ACE2005数据集上的表现不理想。
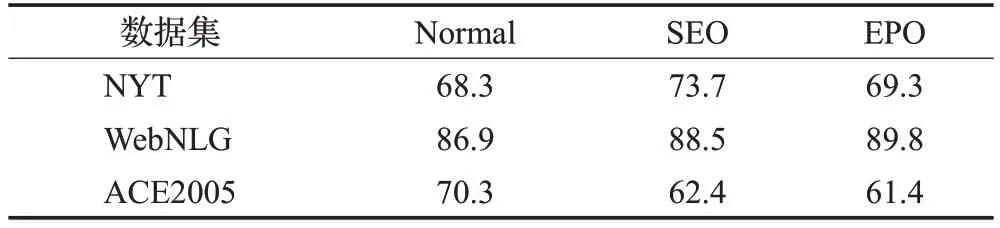
表6 不同数据集上三类问题的F1得分Table 6 F1 scores for three types of problems on different data sets 单位:%
3.4.3 不同数量的三元组的实验评估
为了进一步验证重叠问题中模型对句子中不同数量三元组的性能,本文将在NYT 数据集和WebNLG 数据集上继续实验。
如表7 所示,当句子含有多个三元组的情况下,本文模型效果整体接近优秀模型,在NYT数据集上,当三元组个数为1、2、4 个时,本文模型效果均优于SPN 模型,当三元组个数为3个和4个时,本文模型效果稳定略低于SPN模型;在WbNLG数据集上,当三元组个数为1个、2 个和大于5 个时,本文模型效果均优于SPN 模型,当三元组个数为3 个和4 个时,本文模型效果稳定略低于SPN模型。

表7 句子中不同数量三元组的F1得分Table 7 F1 scores for different number of triples in sentence 单位:%
如图5所示,在(a)代表的NYT数据集上,模型在处理句子中包含多个三元组的问题时,模型效果与句子中包含三元组的个数成反比,在(b)代表的WebNLG 数据集上,本文模型与SPN 模型在效果中整体优于其他模型,并且本文模型在现有的数据中呈现出随着三元组个数的增加则模型效果更好的情况,说明本文模型可以更好地抽取复杂场景中的三元组。
为探究本文模型在不同数据集上的性能,本文首先统计了NYT、WebNLG 和ACE2005 三个数据集中三元组个数分别为1、2、3、4、5及以上的句子总数,然后对句子中包含不同数量三元组的文本数据进行实验评估。数据统计如表8所示,实验结果如表9所示。

表8 不同数据集包含不同数量三元组的数据统计Table 8 Data statistics for different data sets containing different number of triples
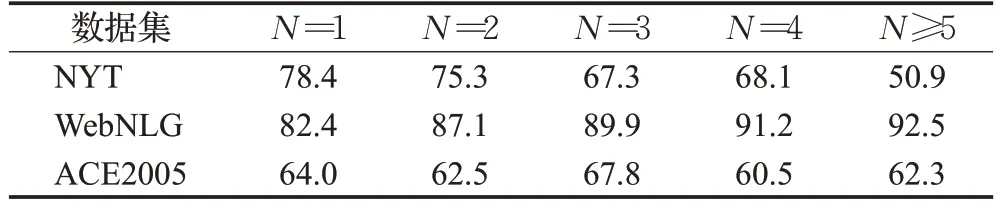
表9 不同数据集包含不同数量三元组的F1得分Table 9 F1 scores for different data sets containing different number of triads 单位:%
如表8所示,ACE2005数据集比NYT数据集和WebNLG数据集中可训练的包含多个三元组的样本数量少。
从表9 可以看出,对于不同数量的三元组,模型在NYT 数据集和WebNLG 数据集上表现较优,且随着三元组数量的不断增多,模型表现更好。相比于模型在ACE2005数据集上表现不理想的情况,考虑数据自身如表8所示,在训练集和测试集中包含的多个三元组数量较少,导致训练和评估不足,影响了模型的效果。
4 结束语
本文提出一种融合双阶段解码的实体关系联合抽取模型,在实体解码阶段主要抽取实体集合,在关系集合预测网络阶段主要融合上级解码结果并抽取数据中的关系三元组。
实验结果表明,模型在NYT 和WebNLG 公开数据集上效果较好,在ACE2005公开数据集上的表现一般,验证了模型的有效性。模型又在三个数据集上分别对Normal、SEO 和EPO 三类问题以及不同数量的三元组进行验证,其中,在NYT和WebNLG数据集上整体表现良好,验证了模型为解决三元组重叠问题的可靠性。对比SPN 模型原文,复现效果与原文有一定差距,且本文模型在NYT数据上的表现与WebNLG数据集上的表现也有一定差距,主要考虑参数设置等带来的影响。在ACE2005数据集上的抽取效果不理想,由于该数据集处理重叠问题的Baseline较少,考虑到可能是复杂样本数据量较少的原因。
