Semantic Path Attention Network Based on Heterogeneous Graphs for Natural Language to SQL Task
2023-10-29ZHOUHaoran周浩冉SONGHuiGONGMengmeng龚蒙蒙
ZHOU Haoran(周浩冉), SONG Hui(宋 晖), GONG Mengmeng(龚蒙蒙)
College of Computer Science and Technology, Donghua University, Shanghai 201620, China
Abstract:The natural language to SQL (NL2SQL) task is an emerging research area that aims to transform a natural language with a given database into an SQL query. The earlier approaches were to process the input into a heterogeneous graph. However, previous models failed to distinguish the types of multi-hop connections of the heterogeneous graph, which tended to ignore crucial semantic path information. To this end, a two-layer attention network is presented to focus on essential neighbor nodes and mine enlightening semantic paths for feature encoding. The weighted edge is introduced for schema linking to connect the nodes with semantic similarity. In the decoding phase, a rule-based pruning strategy is offered to refine the generated SQL queries. From the experimental results, the approach is shown to learn a good encoding representation and decode the representation to generate results with practical meaning.
Key words:semantic path; two-layer attention network; semantic linking
0 Introduction
Natural language to SQL (NL2SQL) task is an emerging research area that aims to transform a natural language with a given database into an SQL query. NL2SQL techniques are gradually applied to the commercial relational database management system to develop natural language interfaces to relational databases.
With the introduction of the single table query task WIKISQL[1], the X-SQL[2]model has achieved performance beyond the human level in this task. However, researchers improve the encoding and decoding methods[3-4], and there is still a big gap for multi-table query tasks.
Existing encoding methods, such as relation-aware schema encoding and linking for text-to-SQL(RAT-SQL)[3], construct graph neural networks to characterize the relationship between question tokens (nodes) and database tokens (table, column). Line graph enhanced text-to-SQL(LGESQL)[4]establishes extra line graphs for edges to obtain structural relationships. These methods only established edges for the identical tokens, ignoring the ones with semantic similarity. Moreover, the lack of attention to nodes’ relation through multi-hops leads to a partial loss of semantic information. For example, the models do not perform well when the gold column names are not mentioned in the question sentences. In fact, they can be found by linking the table names mentioned in the question to those columns.
The decoding methods are based on abstract syntax tree structures to generate SQL queries. RAT-SQL and LGESQL adopt top-down decoding and have linear time complexity with a slow generation speed. Semi-autoregressive bottom-up parser(SMBOP)[5]proposed a bottom-up approach to generate syntax trees in decoding and improve the time complexity to logn.However, it generates some SQL queries that are syntactically incorrect. A fixed number of tables and columns at the beginning leads to predicted redundant tables in SQL query.
To solve the above-identified problems, a multi-table semantic parsing model named semantic path attention network based on heterogeneous graphs(SPAN) is proposed in this paper. To better characterize the multi-hop relationship among question tokens, table names and column names, the concept of the semantic path is introduced. Six types of semantic paths are constructed to connect three types of token nodes. A two-layer heterogeneous graph attention network(HAN)[6]is employed to calculate the attention of semantic paths based on node attention, which adds the information of various semantic paths to the current node in the graph. By considering the synonymous tokens in question sentences and databases, the similarity between tokens is characterized as weights of edges. Based on SMBOP, a novel pruning strategy is designed to improve the correctness of generated SQL queries at both key word levels and syntax levels. The model is tested on the SPIDER dataset[7].
The main contributions of this paper are as follows.
1) A multi-table NL2SQL model SPAN which fuses the nodes information with a two-level heterogeneous graph through node-level attention and semantic-level attention is proposed in the encoding phase.
2) Weighted edges are built between nodes with semantic similarity in the encoded network graph, which enables the model to identify synonyms and homonyms in the text of question words, table names, and column names.
3) A rule-based pruning strategy is proposed to correct invalid key words in the generated results. SQL clauses with logical errors and unnecessary multi-table join queries are discarded.
1 Related Work
Research on semantic parsing models for NL2SQL has flourished since the proposal of the single-table dataset WIKISQL[1]. So far, schema-aware denoising[8](SeaD) has achieved 93.0% accuracy in the WIKISQL dataset. However, in the SPIDER[7]dataset which is a multi-table task, existing models can still not achieve this performance due to the complex relationships between tables. Most existing technologies use the encoder-decoder architecture to solve the multi-table problem. Encoding and decoding methods are the hotspots of current research.
1.1 Encoding issues
The encoding method of the early NL2SQL semantic parsing model was carried out by the seq2seq. The method has significant limitations in the face of complex datasets.
In RAT-SQL[3], a graph-based idea was used to handle the encoding problem by considering the question words and the database words as nodes in a graph. A schema linking strategy is proposed to establish relationships between nodes in a graph. This strategy is based on string matching rules to develop full or partial matches among question words, table names and column names. This strategy is imperfect and fails when some semantically similar words are compared. For example, string matching cannot connect the words “year old” in the question and the column name “age”. There is also a problem that each node in the model encoding cannot effectively distinguish the importance of the surrounding nodes. It results in the node feature being affected due to the interference of too much irrelevant information. LGESQL also encodes based on heterogeneous graphs. To discriminate important surrounding nodes and capture edges semantic information, two relational graph attention network(RGAT) modules[9]are proposed in LGESQL to train on nodes and edges, respectively. But it fails to focus on long path nodes and ignores the information of semantic paths. Bridging textual and tabular data for cross-domain text-to-SQL semantic parsing (BRIDGE)[10]only uses the bidirectional encoder representation from transformer (BERT)[11]framework for encoding work. BERT uses question words, table names and column names as inputs for training. Since BRIDGE does not take full advantage of the relations between words, it does not achieve a good level of performance.
In general, encoding methods in NL2SQL tasks are primarily based on the structure of heterogeneous graphs. In the past, information on the long-distance path needed to be obtained by multi-hops. The learning of features may be affected by noise interference, and this information will be ignored. To cope with this problem, a semantic path approach combined with a two-layer attention mechanism is used to fuse this richly heterogeneous information.
1.2 Decoding issues
In the decoding phase, RAT-SQL generates SQL queries in a depth-first traversal order like a syntax tree[12]. It outputs the nodes of each step by decoding the information of the previous step by long short term memory[13](LSTM). LGESQL is similar to RAT-SQL in decoding, except that the syntax tree rules are optimized. The disadvantage of decoding methods is that they consume too much time and huge search space, which leads to low efficiency. BRIDGE uses a pointer network[14]approach to decode. This generation method still needs to consume a lot of time to complete the search work. The decoding method of SMBOP is different from the previous top-down decoding methods. It proposes a bottom-up method to generate the syntax tree. The generation of each step only needs to merge the subtrees of the previous step, and the time complexity reaches the log(n) level. The current mainstream decoding method is to build a syntax tree for result generation. In terms of efficiency, the bottom-up approach is the choice to save time and improve efficiency.
2 SPAN Model
2.1 Problem definition
The task of the SPAN model is generally described as follows. Given a query databaseS=T∪Cand a natural language questionX={x1,x2, …,x|x|} with |X| tokens, whereXandSare inputs.Tstands for table names.Crepresents the column names. The model automatically parses its corresponding SQL queryY.
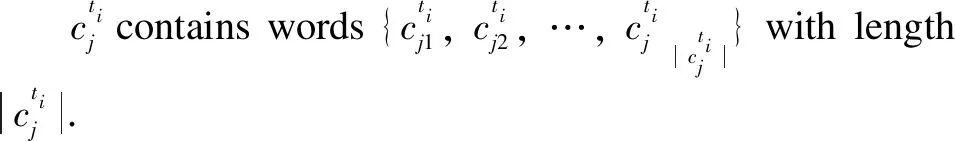
2.2 Encoder
The semantic linking is calculated to build a heterogeneous graph and semantic paths. With semantic linking graphs and feature representation as input, a node-level graph attention network and a semantic level graph attention network are trained to represent the features of question tokens, table names and column names. The specific model encoding structure is shown in Fig.1.
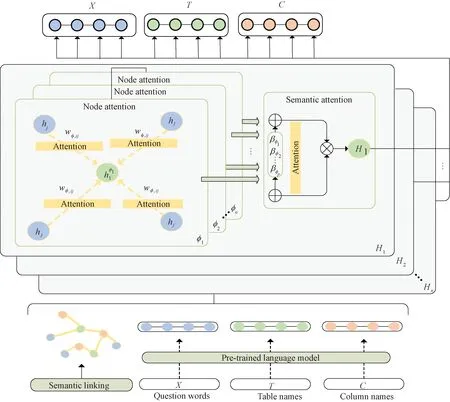
Fig.1 SPAN model encoding structure
The input of the encoding part of the model is divided into the representation of each feature node and the construction of the heterogeneous graph. The representation of the feature node is represented by the large-scale pre-training language model, and the heterogeneous graph is constructed according to different types of nodes and edges. The semantic paths are the ones that are found in the heterogeneous graph by definition before training.
2.2.1Semanticlinkinggraph
A heterogeneous graph[15]is denoted asG=(V,E), where the nodeVconsist of a question tokenxi, a column nameciand a table nameti;Edenotes the edges of the nodesV.The edge types between the question token and the table name have partial and full matches. The edge types between the question and the column are not only partial matching and full matching but also value matching, which means that question token belongs to the column value type. The edge types between the table name and the column name are primary keys, foreign keys, and ownership relationships.
The linking strategy based on string matching rules ignores words with semantic similarities, such as the question words “year old” and the column name “age”. The connections between tokens are established based on cosine similarity.
(1)
whereV1,iandV2,iare the vectors of the two nodes;iis the sequence numbers of the node;nis a dimension ofV.
2.2.2Semanticpath


Table 1 Six semantic paths
DenoteNφ,ias the semantic-path based neighbor. The semantic-path based neighbors of nodeiare defined as a set of nodes connecting nodeivia a semantic-path form. The neighbors of the same node on different paths may be different.
2.2.3Two-layerattentionnetwork
The semantic path attention network consists of two parts: the node-level attention part learns the attention between the central node and the neighboring nodes obtained based on semantic paths; the semantic-level attention part learns the attention value of different semantic paths.
2.2.3.1 Node-level attention
Neighbors of different relation types in a heterogeneous graph should have various influences, and the node-level attention is used to discover useful neighbor nodes. Each node obtains different weights from neighboring nodes and then aggregates this neighbor information. The feature of each nodeiishi.Self-attention is used to learn the weightwφ,ijbetween the neighborsNφ,iof nodeiunder this semantic pathφ.The feature of central nodeiis calculated by the node level attention layer to obtain its new featurehφ,iunder multiple semantic pathφ.
aφ,ij=attention(hi,hj;φ),
(2)
whereaφ,ijdenotes the neural network which performs the node-level attention between nodeiand nodej. The attention weight is shared for nodej(neighbors of nodeiunder a semantic path). But the weights of nodeito nodejare not shared with nodejto nodei.
(3)
(4)
wherehφ,idenotes the representation of nodeiafter aggregating neighbor node information under the semantic pathφ.The calculation is a process of capturing semantic information, and the obtained representation has semantic information.
(5)
Using a single attention mechanism may overfit or pay too much attention to a type of neighbor nodes. Thus a multi-head attention mechanism is used. The model addresses these issues by integrating the results of multiple independent attentions.
2.2.3.2 Semantic level attention
Different semantic paths correspond to different semantic information. A semantic-level attention mechanism is used to aggregate semantic information from different semantic paths by taking the output of the node-level attention as the input.
(6)
wherewφpis the importance of the semantic pathφp;Wdenotes the weight matrix;qTis the parameter matrix vector;Vis the node in this semantic path;bis the offset vector.
(7)
We perform softmax calculation. The weight of each semantic pathβφpcan be obtained. The larger the weight value, the greater the influence of the semantic path.
(8)
wherepis the number of semantic paths required for nodei;Hiis the fusion representation of each semantic path information.
2.3 Decoder and pruning
SQL queries are generated based on the decoding structure of SMBOP[5]. SMBOP generates a linear algebra syntax tree[16]. The terminal nodes of the tree are database column names or values, and the non-terminal nodes are SQL operators, which are either monadic or binary operations. A new pruning strategy is added in the decoding stage. In the initial stage, the column names and the table names are predicted to narrow the search space, and cross-entropy is used to calculate the loss between the ground truth and the prediction. Then during the decoding process, the key words of the SQL queries are modified according to the rules. Finally, the predicted SQL query is obtained.
Inspired by pruning methods reported in Refs. [4, 17-18], pruning is performed in both the initial and the decoding stages.
2.3.1Initialstageofdecoding
The predicted column names and table names are directly used as the terminal nodes of the syntax tree. In this way, some invalid predictions can be removed in advance to improve accuracy.
(9)
s′i=(∑jγh,jiXjWh,sv)Wso,
(10)
wheresidenotes as the encoded schema (table name, column name);s′iis the information after contextualizing with the questionxands′iis used to compute the probability of each database constant being selected;Wh,sq,Wh,sk,Wh,svandWsoare the weight matrices;Xjrepresents the vector of the questions;dis the dimension of the word embedding vector.
The biaffine[19]binary classifier is used to decide whether to select the node as a leaf node:
P(si|X)=σ(siUs′Ti+[si;s′i]Ws+b),
(11)
whereWandUare the weight matrices;bis the bias vector;σis the activation function. The loss function of this task is
L=-∑si[Si,goldlogP+(1-Si,gold)log(1-P)],
(12)
whereSi,goldindicates whether the column actually appears in the query.
2.3.2Decodingprocess
Rules are used to constrain SQL queries to weed out invalid generation.
For example: “select tid.cid from tables”
SQL simple syntax check:tidmust containcid.
Logic syntax check:tablesmust contain the table corresponding totid.
Construct an external knowledge base to check whether the special columns are correct.
A knowledge base is defined in advance to contain a large number of words and those words or symbols with similar semantics. When the predicted SQL contains a key word in the knowledge base, the word bag corresponding to the key word is queried in the knowledge base. If the question sentence does not contain a similar word from the word package, the key word is corrected. We will consider replacing or abandoning this prediction field.
The examples of knowledge base are shown in Table 2.

Table 2 Examples of knowledge base
3 Experiments and Analyses
3.1 Experiment setup
The AllenNLP[20]framework is used for experiments in the environment of Python 3.8. The dimension of the token vector of the question and the database is 1 024, and grammar-augmented pre-training for table semantic parsing(GRAPPA)[22]is used to encode the tokens. The threshold of semantic similarity judgment is 0.2. When the semantic similarity is greater than 0.2, a related situation arises. The multi-head attention numberKis 8. The semantic-level attention vector dimension is 512. Beam size during decoding is 30. The decoding step during inference is 9. The head number of the multi-head attention in the decoding step is 8, and the hidden dimension is 256. The batch size during training is 10. About 200 rounds are trained, and the learning rate is 0.000 186.
3.2 Datasets
The SPIDER dataset[7]is composed of 10 181 questions and 5 693 unique queries involving more than 200 tables in the database and 138 different domains. The dataset has complex SQL queries and semantic parsing tasks close to real-world scenarios. Many of the models mentioned above are based on the SPIDER dataset for experiments, and the model is applied to the dataset.
3.3 Evaluation index
Exact set match without values (EM) and execution with values(EX). EM refers to similarity between the corresponding components in the gold SQL and the predicted SQL. If their corresponding components are consistent, this case is right; otherwise, it is false, regardless of the order of the components. EX refers to executing the gold SQL and the predicted SQL in the database, respectively. By comparing the two results, the prediction is considered correct when the results are the same. We use the verification script officially provided by the SPIDER dataset to verify and evaluate the model of the experiment. The above two indicators are used to evaluate.
3.4 Analysis of experimental results
To compare the model performance, models in Table 3 were trained and predicted in the same experimental environment. The Dev datasets are SPIDER. EX of the SMBOP model is 74.6% and EM of the SMBOP is 74.1%. EX of the SPAN model reaches 76.1%. EM of the SPAN model achieves 75.8%.

Table 3 Comparison of experimental results for each model
As shown in Table 3, five mainstream models are compared. The SPAN model is a great improvement over RAT-SQL(69.7%). However, the performance improvement of SPAN is less than that of the LGESQL model(75.1%). With the employment of semantic linking information, SPAN further captures distant path representation and distinguishes different types of paths.
3.5 Ablation studies
Ablation experiments were conducted by using several models to investigate the contribution of various encoding and decoding combinations. The result is shown in Table 4.

Table 4 Ablation experiment result
1) Compare SPAN encoding with other encoding approaches. SPAN performance(76.1%) improves greatly in EX, and in EM compared to the model without encoding (GRAPPA’s initial word vector, 68.6%). This indicates that the two-layer attention network with semantic-path based encoding is more effective than the simple encoding of RAT-SQL, and the two-layer attention network can obtain more information.
2) Adding the semantic linking on top of RAT encoding could compensate for the unlinkable relations in the original method and rich the heterogeneous graph.
3) The addition of the pruning method results in a less improvement on EX and EM for RAT-SQL. The improvement is low on EX and EM for SPAN encoding. The pruning method is not significant for performance enhancement, but it is valuable in practical applications to improve the execution effect and avoid some obvious misrepresentations.
3.6 Case studies
Four examples generated with SPAN and SMBOP were given to illustrate the model effect as shown in Figs.2 and 3.
As is shown in Fig.2, different models have different perceptions of the same column. In example 1, the original model could not predict “country”, but selected “ID” due to other information. SPAN can effectively learn that the “country” column is also important, so it can select the correct column in the “where” condition. The word in the question can be effectively associated with the ground truth.

Fig.2 Effect of encoding
In example 2, the question words “mobile phone number” strongly correlates with the column “cell_mobile_number”. SMBOP cannot recognize their connection, but the improved linking rules proposed in this paper can link the two. Even though the gold value and the question word are somewhat different, the SPAN model can still find them.
It can be found in example 3, redundancies occur because too many irrelevant tables are predicted. We can find that generation errors can be reduced by applying the pruning rules. In example 4, there are obvious key word errors in the example. “Reversed lexicographical” means that a descending arrangement is needed to get. The previous model may have been overfitted, resulting in redundancy. It is also overly rigid in some reversed semantics.

Fig.3 Effect of pruning strategy
4 Conclusions
In this work, a multi-table semantic parsing model SPAN for the natural language processing (NLP) task is proposed, which explores semantic paths based on a two-layer attention network in the encoding phase. It enriches the heterogeneous graph structure by establishing weighted edges with the semantic similarity. The rule-based pruning of the decoding process corrects the predicted SQL. Experimental results fully illustrate that inspiring semantic information in complex semantic NL2SQL tasks is beneficial to the model performance. However, the SPAN model is unable to generate words out of the question and the database. In future work, the predictive generation of words external to this section to refine the representation of the model will be studied.
猜你喜欢
杂志排行

Journal of Donghua University(English Edition)的其它文章
- Oscillation Reduction of Breast for Cup-Pad Choice
- Effect of Weft Binding Structure on Compression Properties of Three-Dimensional Woven Spacer Fabrics and Composites
- Optimization for Microbial Degumming of Ramie with Bacillus subtilis DZ5 in Submerged Fermentation by Orthogonal Array Design and Response Surface Methodology
- pth-Moment Stabilization of Hybrid Stochastic Differential Equations by Discrete-Time Feedback Control
- Device Anomaly Detection Algorithm Based on Enhanced Long Short-Term Memory Network
- Image Retrieval Based on Vision Transformer and Masked Learning