基于CatBoost的供水量组合预测模型探讨
2023-10-28朱俊杰叶文静曹萃文顾幸生
朱俊杰,叶文静,曹萃文,顾幸生
(1. 上海南汇自来水有限公司,上海 201399;2. 华东理工大学 能源化工过程智能制造教育部重点实验室,上海 200237)
中国淡水资源总量丰富但人均水资源不足,水质污染以及庞大人口基数等因素使得国内的水资源供需关系日益紧张,因此,做好水资源的规划和管理势在必行。短期供水量预测模型是指在地区历史供水数据和发展趋势的基础上,根据历史数据预测未来的供水量,短期供水量预测模型可以为供水系统制定合理的供水调度方案提供必须的理论数据基础。传统的供水量预测模型主要依靠经验公式和统计方法,如回归分析模型[1]和时间序列模型[2]等,该类方法在数据充足、变化较为平稳的情况下能够得到较为准确的预测结果,但在供水系统变化复杂的情况下预测能力受到限制,无法进行精确预测[3-4]。近年来,研究学者开始利用人工智能和机器学习技术改进供水量预测模型,如人工神经网络模型[5]、支持向量机模型[6]、支持向量回归模型[7]等。目前,在供水量预测问题中基于神经网络模型和机器学习模型的研究最多并取得了一定的成果[8-9]。
针对目前的供水量预测模型在数据波动剧烈时预测效果较差的问题,本文在已有研究基础上,提出了基于CatBoost的城市供水量组合预测模型。该模型采用K近邻算法(K Nearest Neighbor, KNN)[10]对供水量异常数据识别和校正后,采用先进的支持向量回归(SVR)[11],极端梯度提升算法(XGBoost)[12],轻量级梯度提升机(LightGBM)[13]和CatBoost[14]模型预测供水量数据;为了融合各模型的优点并提高模型的预测精度,将各单一模型的预测结果作为输入特征,采用CatBoost模型对供水量数据进行进一步预测并得到最终的供水量预测结果。与其他模型的对比仿真实验表明,该模型可以获得更高的预测精度和更好的预测效果。
1 相关模型原理
1.1 KNN算法
KNN算法是一种简单的机器学习算法,常用于分类和回归问题中,该算法检测异常数据的原理: 首先计算一个样本与其他所有样本之间的距离并找到离它最近的k个样本,随后计算该样本点与k个样本的平均距离,根据平均距离与阈值的比较结果判断该数据是否是异常数据,如果平均距离大于阈值,则认为该样本是异常样本,否则为正常样本。KNN算法不需要假设数据的分布,在低维数据的异常数据识别中效果显著,广泛应用在故障诊断等领域中。
1.2 CatBoost模型
2017年Yandex首次提出CatBoost模型[14]。CatBoost模型是一种基于梯度增强决策树(GBDT)的新型改进机器学习类模型,与GBDT模型相比,CatBoost模型使用了Ordered Boosting方法并采用对称树作为基树模型;与基于二叉树作为基模型的模型相比,CatBoost可以更好地改善模型的预测性能并且在一定程度上弱化GBDT模型容易过拟合的问题。相比于传统的GBDT模型,CatBoost模型具有更高的预测精度和更好的泛化能力,并已在诸多领域中得到了应用,但该模型还未在供水量预测问题中得到应用。
2 基于CatBoost的城市供水量组合预测模型
2.1 异常数据识别
在供水系统中,供水量数据的监测和记录过程会受到多种人为和环境因素的影响,如人为误操作、设备故障、水源质量变化等,从而导致数据出现异常。异常数据会扰乱正常数据的分布规律,降低模型的预测精度,甚至产生不合理的预测结果。因此,在进行供水量预测前对历史供水量数据进行异常数据识别检测是必要的。本文基于时供水量数据的周期变化特点,将供水量数据分为24个子集,在每个子集中分别使用KNN算法检测识别异常数据,并校正异常数据采用该时刻以往1周内的平均值。
2.2 输入特征选择
分析和选择模型的输入特征并使用强相关输入特征有利于提高模型的预测准确性并减少建模时间。以往研究表明,使用历史供水量数据作为输入特征可以建立准确的供水量预测模型[15],因此本文也采用历史供水量数据作为组合模型的输入。在{qVt-24×7-10,qVt-24×7-9, …,qVt-24×7+9,qVt-24×7+10}、 {qVt-24×1-10,qVt-24×1-9, …,qVt-24×1+9,qVt-24×1+10}、 {qVt-10,qVt-9, …,qVt-1}以及时刻t中使用随机森林算法筛选出相关性最强的10个输入特征,其中qVt表示时刻t的供水量。根据重要性得分最终选择{qVt-24×7,qVt-24×7+1,qVt-24×1+10,qVt-24×1,qVt-24×1+9,qVt-24×7+10,qVt-1,qVt-24×7+2,qVt-24×7-1,qVt-6}为模型的输入特征。
2.3 组合模型建模步骤
组合模型的建立主要包括异常值处理、单一模型预测和组合预测三个部分,组合模型的结构如图1所示,主要的建模步骤如下:
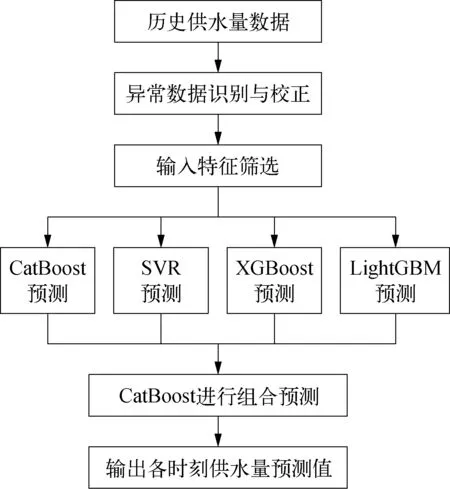
图1 组合模型结构示意
1)根据时刻特征,将供水量数据分为24个子集并分别采用KNN算法识别和校正异常数据。
2)采用随机森林算法筛选出相关性最强的10个输入特征,并将供水量数据划分为训练集和测试集。
3)利用训练集数据分别训练SVR,XGBoost,LightGBM和CatBoost模型并预测供水量数据。
4)为避免组合模型中各比例参数选择的不合理,将上述4个模型的预测值和时刻t作为输入特征,真实供水量数据作为输出值,采用CatBoost模型进行训练并得到最终的供水量预测结果。
2.4 超参数调优
超参数的选择对模型的性能至关重要,历史供水量数据中的异常数据量数目未知,因此KNN算法中异常数据比例需要人为设定,异常数据比例分别尝试设置为0.01,0.02,…,0.20。SVR模型采用随机搜索方法对超参数进行寻优调整;XGBoost,LightGBM,CatBoost模型使用Optuna优化框架对每个模型的重要超参数进行参数调整和确定。
2.5 评价指标
本文使用平均绝对百分比误差(eMAPE)、均方根误差(eRMSE)、绝对平均误差(eMAE)以及R2作为模型预测评价指标,4种指标的计算如式(1)~式(4)所示:
(1)
(2)
(3)
(4)
3 仿真实验与分析
3.1 供水量数据分析
本文收集了某独立供水区域2022-05-01—2022-09-30的历史供水量数据,采样间隔为1 h。以2022-05-01—2022-09-23的供水量数据作为模型的训练集数据用于模型的训练,2022-09-24—2022-09-30的供水量数据作为测试集数据验证模型的性能。该时段供水量数据变化曲线如图2所示,每个时刻的供水量数据箱型图如图3所示。观察图2和图3可以发现,由于人为记录错误、水管爆管等因素的影响,收集到的时供水量数据存在较大波动且具有较多离群值。异常数据的存在对模型的训练会造成干扰,因此在预测供水量前进行异常数据识别和校正是必要的。
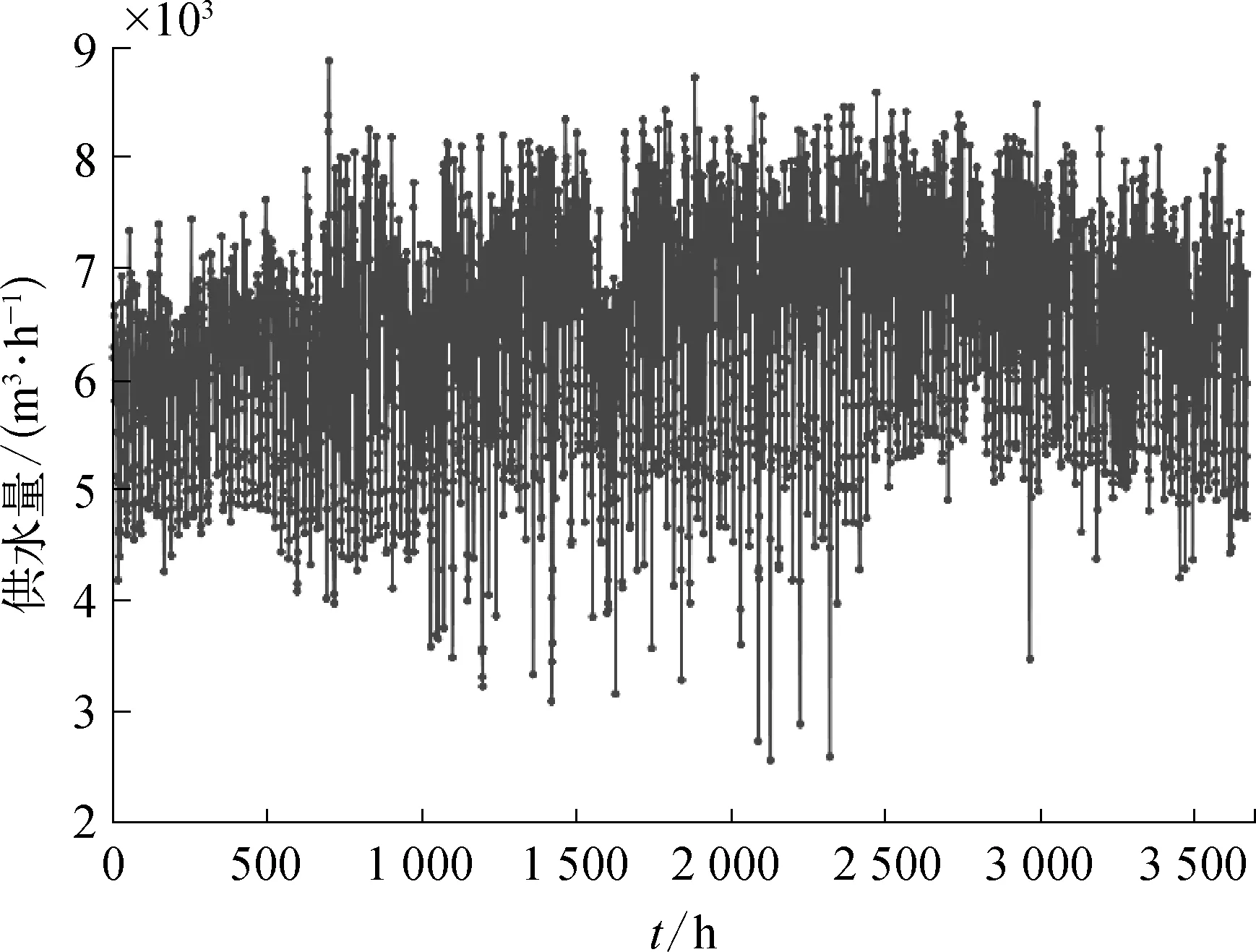
图2 某时段供水数据变化曲线示意
3.2 KNN算法异常数据识别分析
采用KNN算法分别识别每个时刻的异常数据,异常数据识别结果如图4所示。观察图4可以发现,KNN算法能够较为准确地识别出供水量数据中的异常数据。在识别出异常数据后,采用该时刻以往1周内的数据平均值进行校正,从而为供水量模型提供更优的数据。
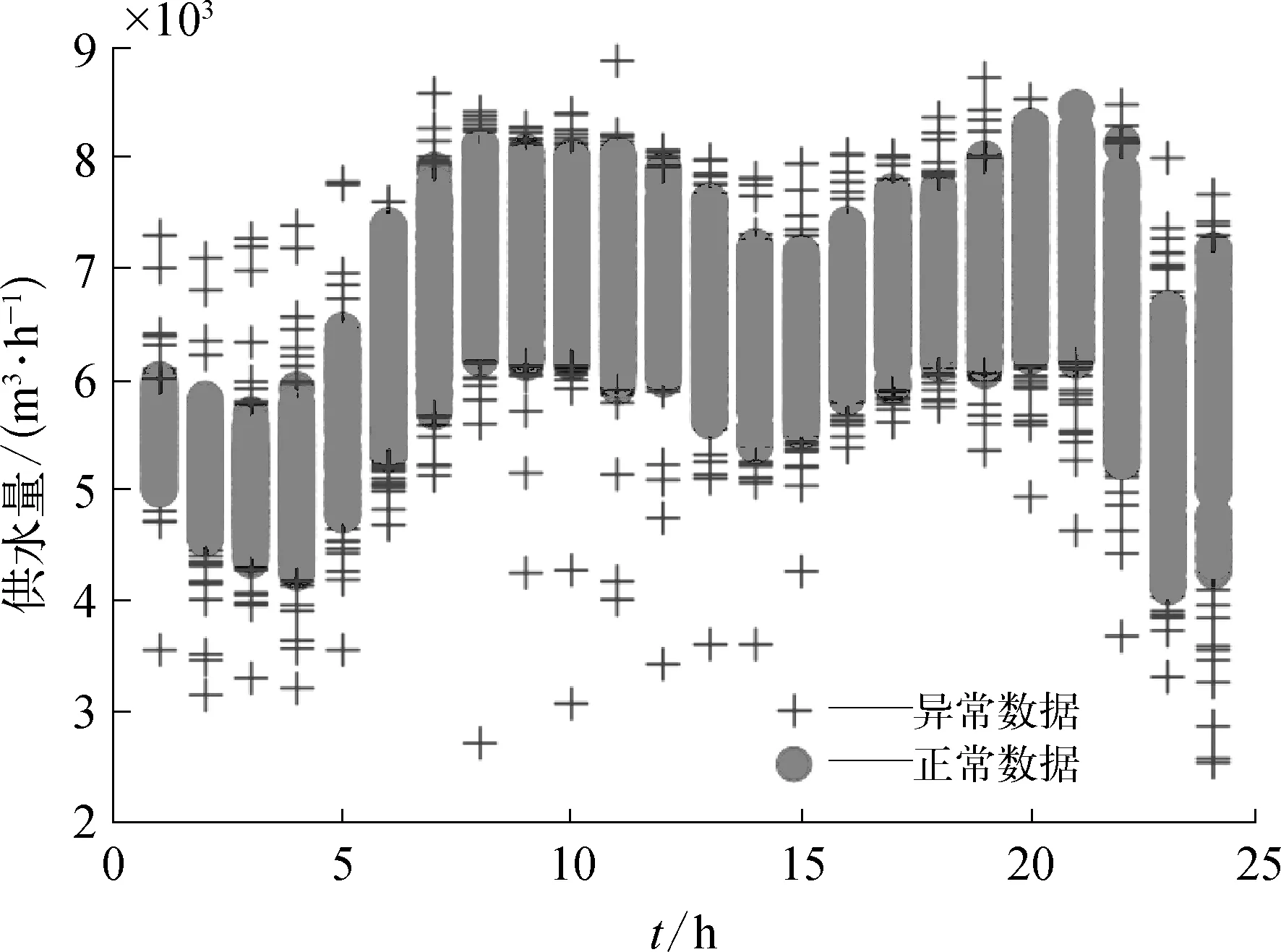
图4 异常数据识别结果示意
3.3 组合模型有效性分析
为了测试分析KNN算法异常数据识别和组合预测对供水量预测的作用和效果,本文分别采用CatBoost,KNN+CatBoost,KNN+SVR,KNN+XGBoost,KNN+LightGBM以及组合模型进行仿真实验。各模型供水量预测结果如图5所示,根据预测结果计算得到的评价指标见表1所列。
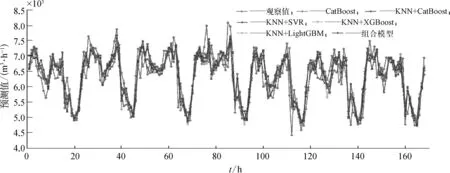
图5 各模型供水量预测结果示意
由表1可以发现,与CatBoost模型相比,KNN+CatBoost模型的预测结果在4个指标中结果最好,eRMSE指标从538.577 3下降到429.667 7,R2从0.601 1提高到0.722 1。实验结果表明,经过KNN算法异常数据识别和校正后的预测结果指标比基于原始数据的预测结果指标更好,eMAPE,eMAE,eRMSE和R2都有明显改善,验证了采用KNN算法识别异常数据从而提高模型预测精度的有效性。在KNN+CatBoost,KNN+SVR,KNN+XGBoost和KNN+LightGBM模型中,综合4种评价指标,KNN+CatBoost模型表现最优,其次是KNN+LightGBM和KNN+XGBoost模型,KNN+SVR预测指标结果表现最差,预测评价指标结果表明CatBoost模型在供水量预测中的突出表现。与上述5种模型相比,组合模型预测效果最好,eMAPE,eMAE,eRMSE和R2都有较为明显的改善和提升。分析发现,在组合模型中采用了CatBoost算法将SVR,CatBoost,XGBoost和LightGBM模型的预测结果进行组合以便在不同的样本中最大程度地发挥各模型的优点,从而进一步提高预测效果。表1的实验结果验证了组合模型在供水量预测中的有效性。
观察分析表1中各模型的运行时间可以发现,未进行KNN异常值识别的CatBoost模型运行时间最短,在1 s内;加入了KNN异常数据检测的模型运行时间为1.175 9 s,这是因为需要将数据划分为24个子集分别训练并采用KNN算法识别异常数据,所以加入KNN算法异常数据识别的模型,增加了算法的运行时间。而组合模型由于融合了KNN,SVR,CatBoost,XGBoost和LightGBN模型,在所有比较模型中运行时间最长,达到了2.688 9 s。所有的模型运行时间都小于3 s,在可接受范围内。
4 结束语
针对目前的供水量预测模型在数据波动剧烈时预测效果较差的问题,本文在已有的研究基础上,提出了基于CatBoost的城市供水量组合预测模型。该模型采用KNN算法对供水量数据中的异常数据进行识别和校正后,采用CatBoost模型对SVR,XGBoost,LightGBM和CatBoost模型得到的预测结果进行进一步组合并得到最终的供水量预测值,本文结论如下:
1)在对波动剧烈的数据进行分析和预测时,采用KNN算法对异常数据进行识别和校正后能够显著提高模型的预测精度。
2)SVR,CatBoost,LightGBM和XGBoost模型在供水量预测中,CatBoost模型的表现最好,预测精度最高。
3)提出的基于CatBoost的城市供水量组合预测模型能够在单一预测模型的基础上进一步提高预测精度,得到更好的供水量预测结果。
