基于高斯模糊和BP神经网络的汽车液压转向系统故障诊断
2023-10-28李世超曾良才
郭 媛, 汪 胜, 李世超, 曾良才
(1.冶金装备及其控制教育部重点实验室, 湖北 武汉 430081;2.机械传动与制造工程湖北省重点实验室, 湖北 武汉 430081; 3.武汉科技大学 精密制造研究院, 湖北 武汉 430081)
引言
液压转向系统是汽车中至关重要的组成部分。该系统的故障不仅会影响车辆的行驶稳定性和安全性,还会降低整车的可靠性和经济性。因此,对液压转向系统的故障进行快速、准确的诊断至关重要。
在汽车液压转向系统的故障诊断方面,国内外的学者提出了很多切实可行的诊断方法,常用的方法包括BP神经网络、支持向量机、决策树等,其中,BP神经网络是应用最广泛的一种方法。但直接使用BP神经网络对故障数据进行训练和预测,存在欠拟合或过拟合的风险,而且诊断的正确率较低,诊断精度的稳定性和可靠性也无法保证。基于高斯模糊和BP神经网络的故障诊断方法,能保证故障诊断的精度,具有较高的泛化能力,还能解决过拟合的问题。
该诊断方法可以有效地处理汽车液压转向系统中的信号,提高故障诊断的准确性和效率[1-2]。随着车辆电子化、智能化的发展,汽车液压转向系统采集的数据量越来越大,需要更快、更准确的方式来进行故障诊断。传统的经验式的故障诊断方法需要专业知识和经验丰富的技术人员进行判断,而基于人工智能技术的故障诊断方法可以通过对数据的分析和处理,自动化地进行故障诊断,不需要人为干预,因此在实际应用中具有广阔的发展前景。
汽车液压转向系统中的信号包括压力、流量、温度、噪声、泄漏量等多种类型,这些信号包含了系统的各种状态信息,可以用于故障诊断。然而,由于这些信号的复杂性和多样性,传统的诊断方法很难准确地分析和处理这些信号。因此,需要采用模糊化的方法对这些信号进行处理,将其转化为易于处理的模糊量,再使用BP神经网络进行故障诊断[1-2]。
该诊断方法主要工作包括:首先,采用高斯模糊化处理的方式对汽车液压转向系统的信号进行处理,将其映射为一组多元模糊集合,有效地描述了系统的状态;其次,使用BP神经网络对故障进行分类和回归预测,提高了预测准确性和泛化能力;最后,通过实验验证了该方法的有效性和优越性,可以为汽车液压转向系统的故障诊断提供一种高效、准确的解决方案。
总之,汽车液压转向系统故障诊断研究具有重要的理论和应用价值,人工智能技术的应用可以提高诊断准确度和效率,高斯模糊化处理可以将复杂多变的信号转化为易于处理的模糊量,为进一步提高故障诊断的精度和可靠性奠定了基础。该方法可以为汽车液压转向系统的故障诊断提供一种有效的解决方案[3-4]。
1 液压转向系统数据采集
液压转向系统的故障可以用多种信号来衡量,比如压力[5]、噪声、温度、流速、转速、泄漏量[6]、关键位置的运动、振动、液位等。但是在实际监测过程中,还需考虑采集信号的灵敏度、采集设备的成本、故障和信号的关联度等,综合来看,把监测压力、温度、噪声、流量和泄漏量这5个信号相结合符合预期需求[7]。
如图1所示,该液压转向系统的工作原理是方向盘连接到转阀式全液压转向器6的操纵机构上,通过方向盘使全液压转向器6的阀芯转动,控制压力油(p1)以小流量q通往流量放大器2的阀芯左侧a或右侧b,从而使流量放大器2的阀芯向右移动或向左移动,则p2压力油以大流量Q通往转向缸1的A腔或B腔,实现装载机左右转向[8]。主要液压元器件有过滤器、液压泵、压力控制阀、换向阀、液压缸和油箱等,如图2压力异常故障树所示,液压转向系统一般会出现以下几个常见的故障:液压泵泄漏、液压缸无动作、液压缸爬行、溢流阀故障、管道泄漏和管道堵塞等[9-11]。

1.转向缸 2.流量放大阀 3.滤油器 4.转向泵 5.减压阀 6.全液压转向器图1 汽车液压转向示意图Fig.1 Schematic diagram of vehicle hydraulic steering
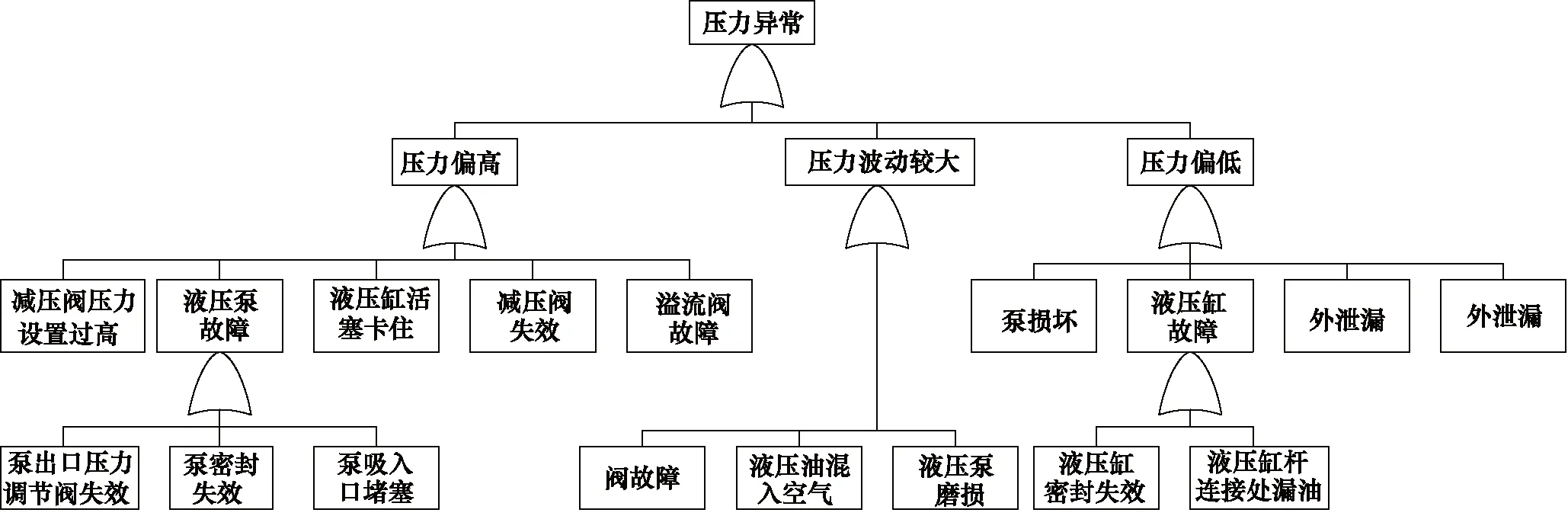
图2 压力异常故障树Fig.2 Pressure abnormal fault tree
以压力异常为例,该汽车转向系统的正常压力为20 MPa,根据故障数据集可把20 MPa设置为压力正常均值,25 MPa设置为压力偏高均值,12 MPa设置为压力偏低均值[12-13]。
2 高斯模糊化处理的方法
在液压系统的故障数据采集过程中,可以明显发现故障类型和故障数据并不是一一对应的关系,而是在一定的范围波动,因此,在对定性和定量分析,需要用高斯隶属函数作为桥梁,高斯隶属函数能把输入的信号按照给定的均值和方差,映射到0~1之间。以压力信号为例,该液压转向系统正常工作压力在18~24 MPa 之间,规定20 MPa为压力正常的高斯隶属函数的均值,12 MPa为压力偏低的均值,25 MPa为压力偏高的均值。结合现场维修的实际数据, 划定方差为7 MPa,以此类推, 可得温度、噪声、流量和泄漏量的均值和方差[14],如表1所示。
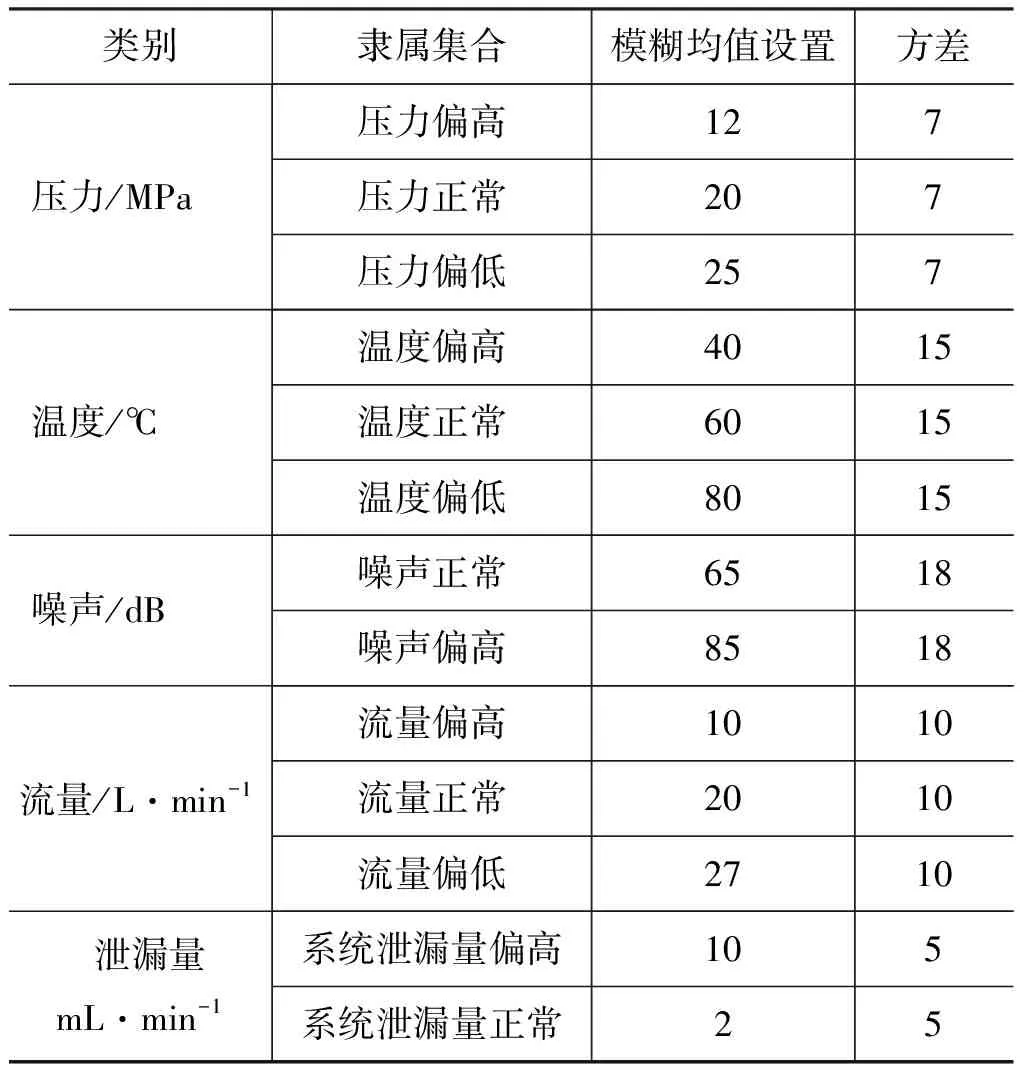
表1 隶属集合设置Tab.1 Membership setsetting
在高斯模糊化处理中,一般用模糊集合理论对不确定和具有模糊性质的对象进行数学表达,将对象的隶属度映射到一个范围内的模糊值上。在对液压转向系统的故障数据处理方面,可以将采集到的原始数据转化为一个个的模糊子集,其中,每个元素在每一个子集中都有一定的隶属度,代表该元素属于该子集的贴近程度。
具体来说,液压转向系统的采集信号包括压力、流量、温度、噪声、泄漏量等,对于每个信号,可以分别将其高斯模糊化处理。以压力信号为例,可以将其划分到多个模糊子集,例如压力偏高、压力正常、压力偏低等,并给出每个子集的隶属度。这样,每个压力采集值就可以被映射为一个包含多个模糊子集的模糊集合,其中每个子集都代表了该采集值在不同子集中的隶属程度。
在将多个采集信号都进行高斯模糊化处理之后,就可以组合成一个多元模糊集合,用于对液压转向系统的状态进行描述。高斯隶属函数的具体公式表达如下:
(1)
式中,μ—— 隶属度函数
x—— 输入值
c—— 高斯函数的中心
σ—— 高斯函数的标准差
将表1的数据代入,各个故障数据的隶属集合图像如图3所示。
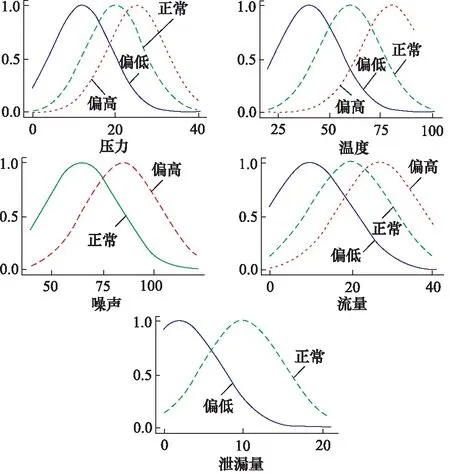
图3 集合隶属曲线Fig.3 Set membership curve
结合液压转向系统故障树和实际的故障数据,可得到原始故障数据作为训练集,如表2所示。
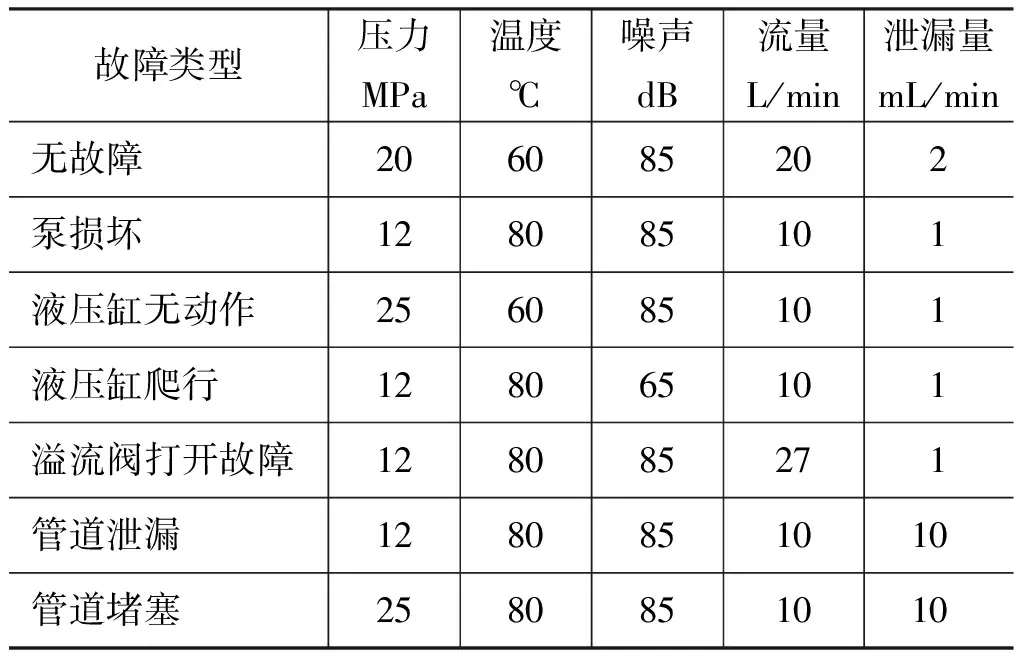
表2 训练集原始数据Tab.2 Raw data of training set
高斯模糊化后的训练集数据,如表3所示。从原始故障数据中取部分数据作为测试集,如表4所示。高斯模糊化后的测试集如表5所示。
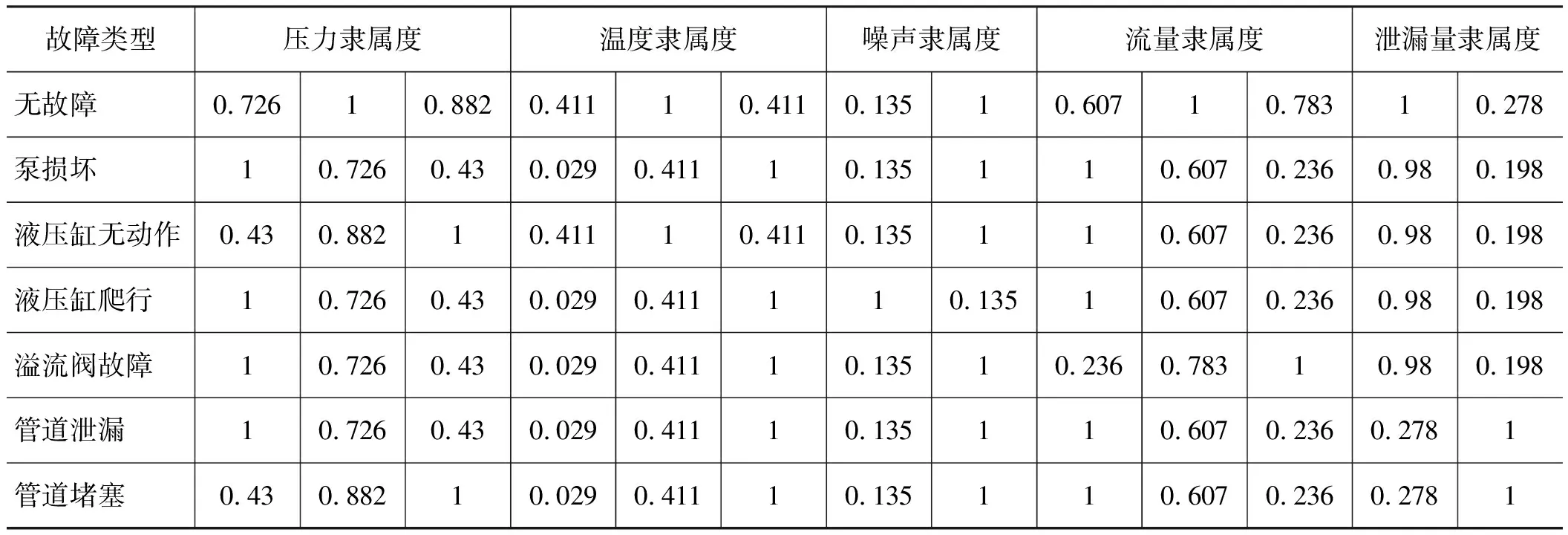
表3 训练集高斯模糊化后的数据Tab.3 Data after gaussian blurring in training set
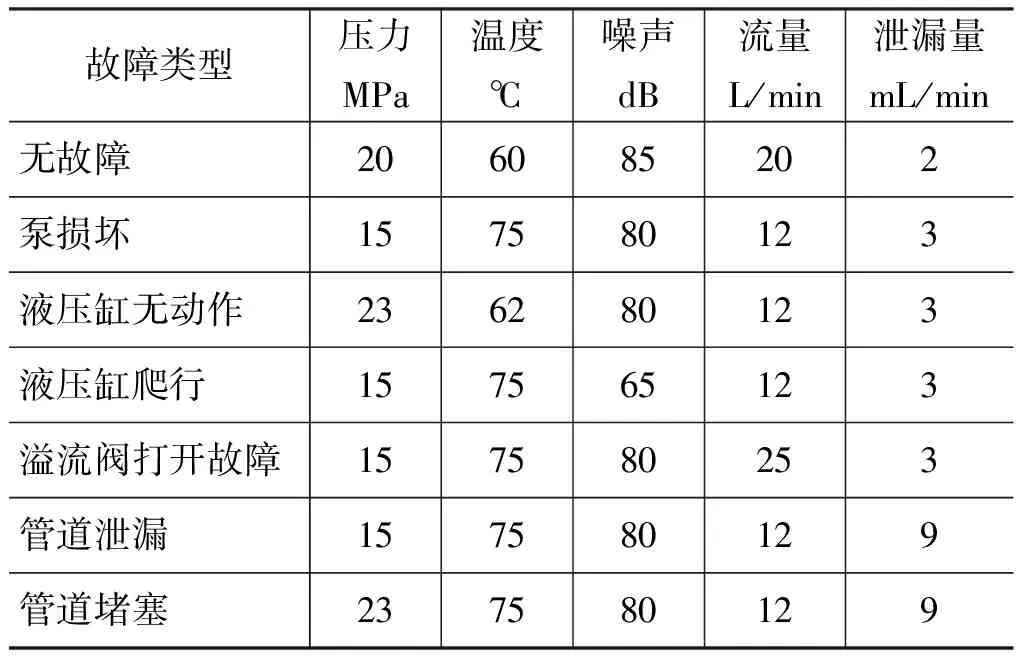
表4 测试集原始数据Tab.4 Raw data of test set
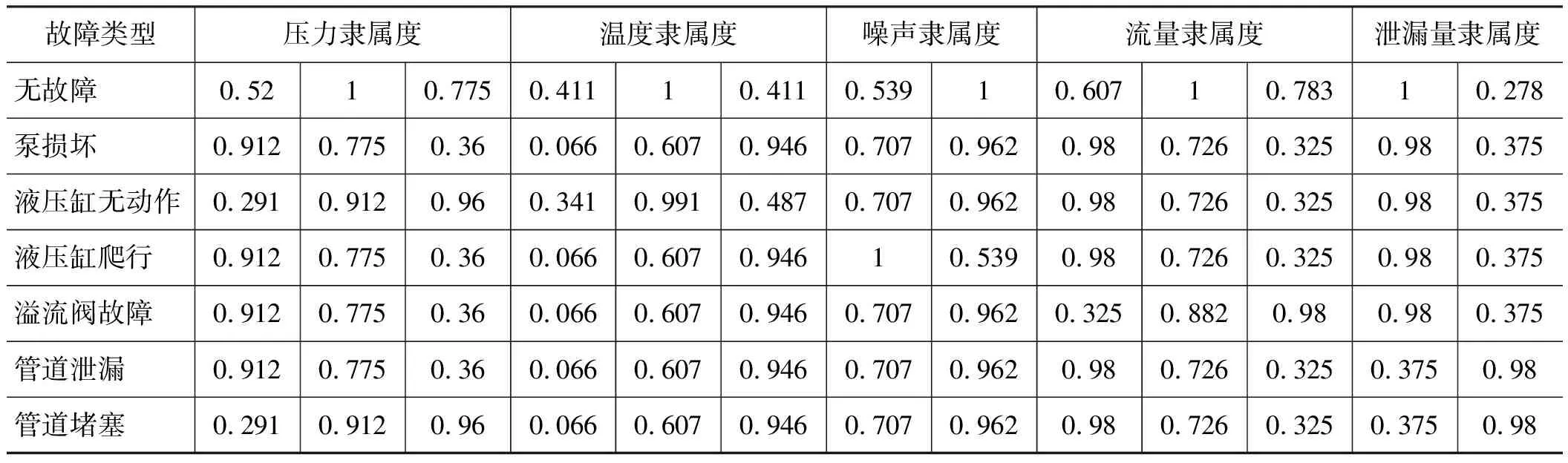
表5 测试集高斯模糊化后的数据Tab.5 Data after gaussian blur of test set
3 BP神经网络的原理和训练方法
3.1 BP神经网络模型
BP神经网络结构一般包含输入层、隐藏层和输出层。理论上,作为非线性系统,3层的BP神经网络能把输入的参数映射到任意目标输出[15],其网络拓扑结构如图4所示。
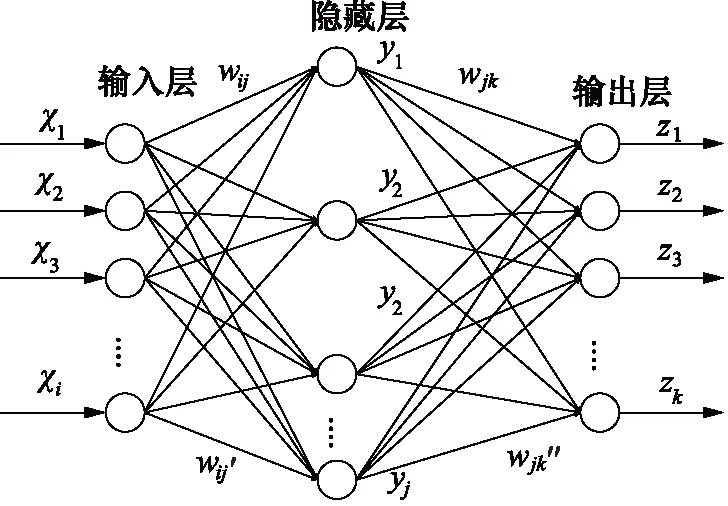
图4 BP神经网络拓扑结构Fig.4 BP neural network topology
输入层接受来自外部的信息输入,隐藏层对输入信号进行加权处理和非线性变化,再通过输出层把信号作分类或者回归输出[16]。设构建BP神经网络的输入层有M个节点、隐藏层有N个节点、输出层有P个节点,训练集的样本数量为K,那么隐藏层第j个节点的输出yj为:
(2)
其中,xi表示输入层第i个节点的输入值,表示隐藏层第j个节点的阈值,wij表示输入层到隐藏层路径节点的权值。同理,可得到输出层的节点输出zk为:
(3)
BP神经网络在训练时的精度可以通过CrossEntropyLoss来呈现为式(4):
(4)
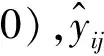
上述是BP神经网络的正向传播过程,其目的就是得到期望输出和实际输出的差值,也就是误差,接下来是反向传播的过程。通过正向传播得到的误差,不断调整输入层、隐藏层和输出层之间的权值和阈值,权重的具体更新公式为:
(5)
式中,E—— 误差
η—— 学习率
zk—— 隐藏层到输出层的实际输出值
而从隐藏层到输入层权重更新公式为:
(6)
其中,yj表示输入层到隐藏层的实际输出值。
同理,阈值Δθj和Δθk的更新方式也和权重的更新方式一致。
3.2 BP神经网络参数选择
在搭建的BP神经网络,输入层的节点数是由待分析数据样本的宽度确定的,原始数据经过高斯模糊化之后,得到输入的节点数为13。输出层的节点数是由最终需确定的状态数决定的,由故障种类得知,一共需确定7个故障状态,因此输出节点数为7。而隐藏层的节点数一般可依据下面的经验公式:
(7)
其中,mi,mh和mo分别表示输入层、隐藏层和输出层的节点数,而x的值可依据具体情况调整。经过多次尝试,最终隐藏层的节点数确定为20。
4 实验
以某汽车的液压转向系统为实验对象,对其系统常见的故障进行模拟实验。通过实际的修理数据结合故障树建立故障训练测试集和测试数据集,如表3和表5所示,故障编码如表6所示。
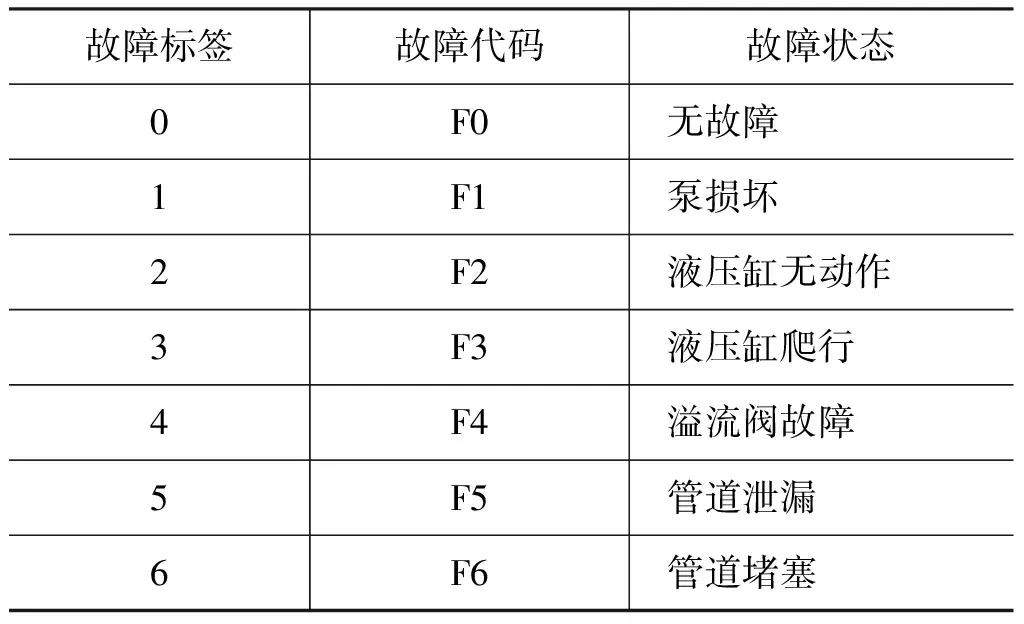
表6 故障编码表Tab.6 Fault code list
实验流程如图5所示。

图5 实验流程图Fig.5 Experimental flow chart
使用python语言搭建故障诊断神经网络模型,将高斯模糊化之后的压力、温度、噪声、流量和泄漏量作为BP神经网络的输入节点,故障标签作为输出节点,输入层和隐藏层使用sigmoid作为激活函数,使用CrossEntropyLoss作为误差判定,为防止过拟合,经过多次测试,学习率取0.01较为合适。优化器选用Adam算法优化器。
4.1 高斯模糊化故障数据实验
搭建BP神经网络完毕后,把高斯模糊化后的训练集(表3)作为训练样本,高斯模糊化后的测试集(表5)作为测试样本,经过测试发现,当隐藏层的节点数取20时,训练的效果最佳。每一个样本数据输入神经网络会得到7个数据,用argmax函数取其中最大值所在的位置作为预测的标签,测试结果如表7所示。
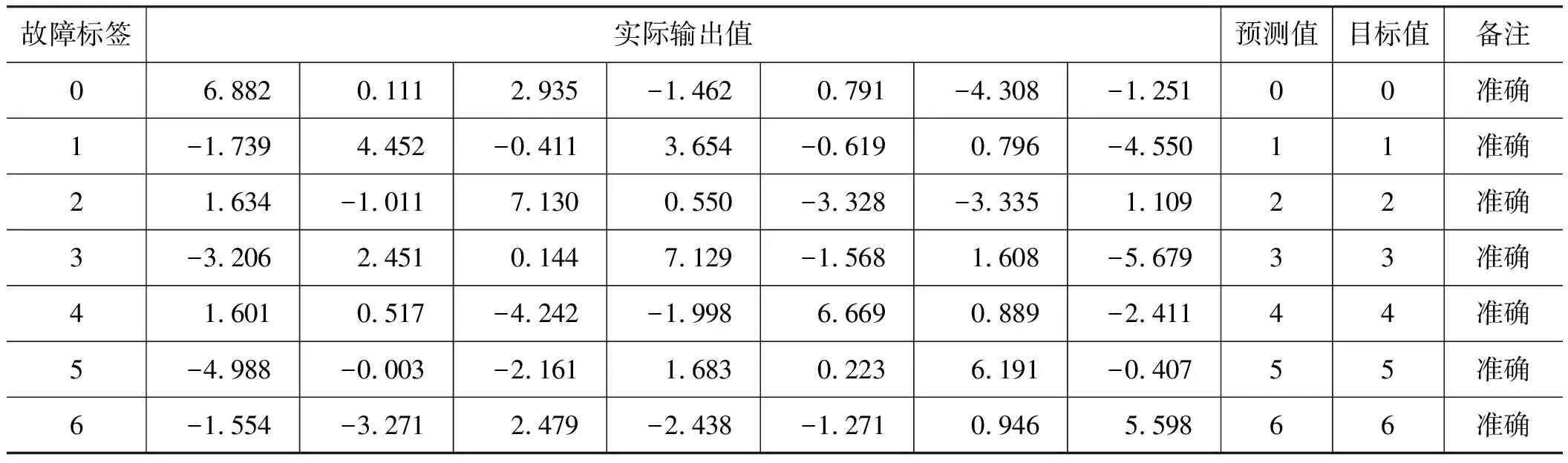
表7 高斯模糊化测试结果Tab.7 Gaussian fuzzing test results
实验过程中的误差E和训练轮次n的关系如图6所示,该图显示,训练轮次在70次附近,误差已接近最小值,在0.03左右,部分数据如表8所示。
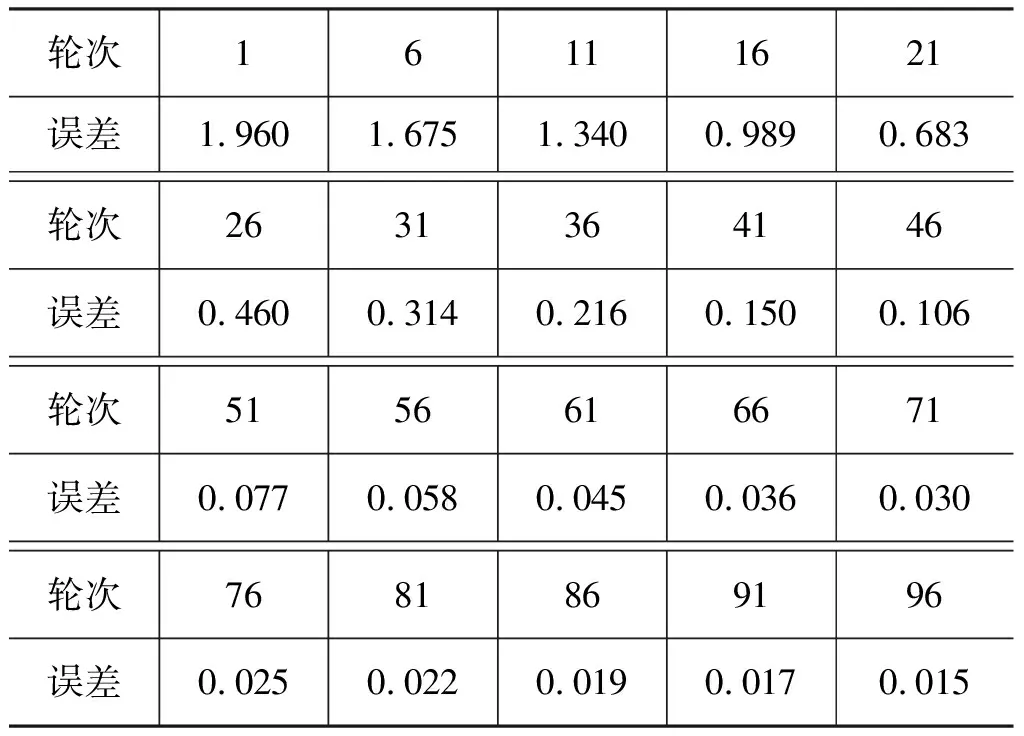
表8 高斯模糊化误差-轮次数据(部分)Tab.8 Gaussian blurring loss-epoch data (partial)
4.2 未高斯模糊化故障数据实验
在相同的条件下, 直接使用未高斯模糊化的数据进行实验,即,使用表2和表4的数据,根据输入的维度,调整神经网络的结构,使得其能输出合适的数据,其他的参数维持不变,得到的实验预测结果如表9所示,误差曲线如图7所示。
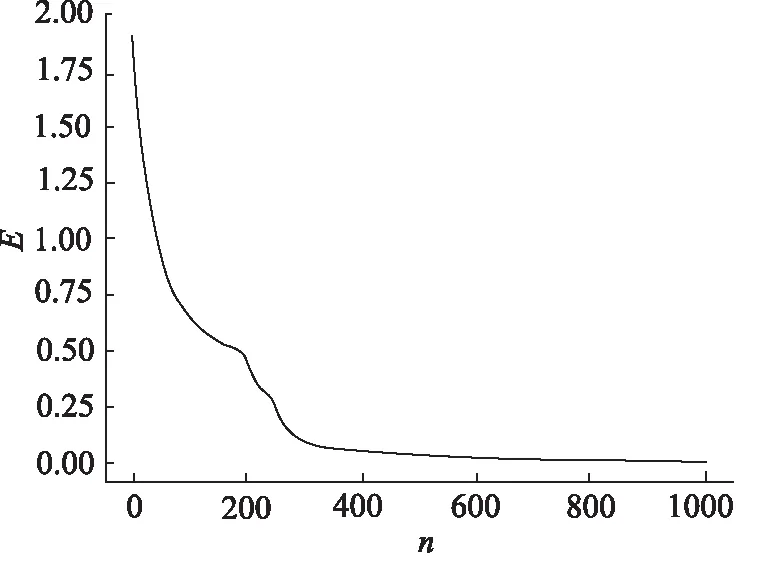
图7 未高斯模糊化数据的误差-轮次曲线Fig.7 Loss-epoch curve of non-gaussian blurred data
从表9中可以看出,故障标签3的预测值和目标值不匹配,正确率只有85.7%,并不能达到100%的正确率。
从高斯模糊化的结果和未高斯模糊化的结果来看,结合图6和图7以及表8和表10的对比,可以分析出,高斯模糊化的结果有显著的优越性,主要体现在以下几点:(1)从准确率来看,高斯模糊化后的预测结果可以保证100%的准确性;(2)从训练轮次来看,高斯模糊化后的数据仅需70轮的训练即可保证结果收敛,并能维持较低的误差,而未高斯模糊化需要训练超过500轮,才能使误差接近高斯模糊化后的水平;(3)从误差图像来看,高斯模糊化的曲线表现更加平稳,而未高斯模糊化的曲线比较容易陷入局部最小值,导致预测失误。
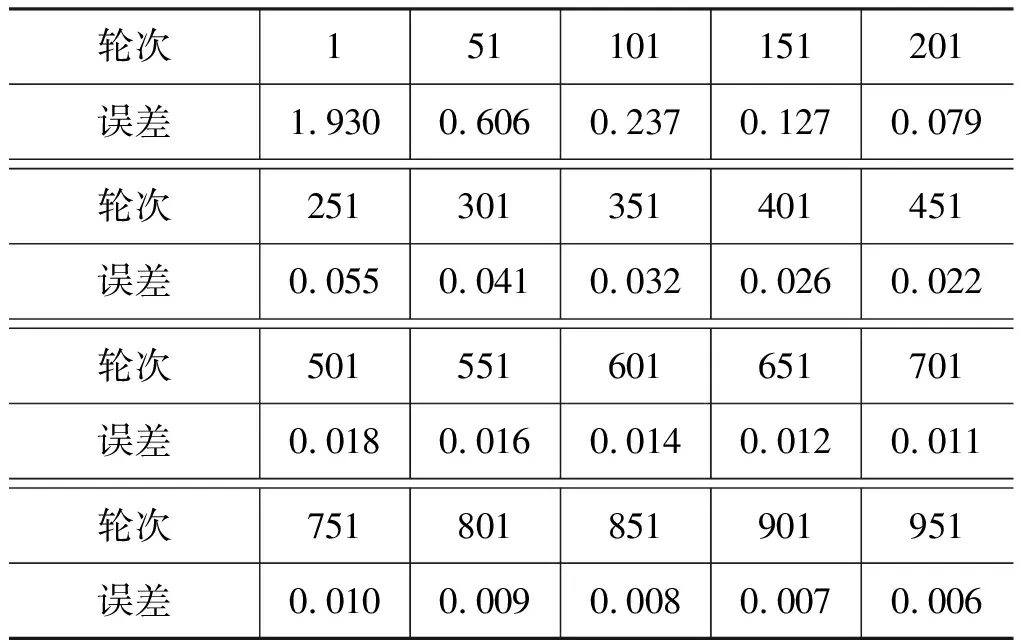
表10 未高斯模糊化误差-轮次数据(部分)Tab.10 Non-gaussian blurring loss-epoch data (partial)
5 结论
综上所述,提出了一种基于高斯模糊化和BP神经网络的汽车液压转向系统故障诊断方法,该方法结合了高斯模糊化处理和神经网络算法,能够有效地提高故障诊断的准确性和泛化能力。通过对照实验的比较,证明了高斯模糊化处理的优越性,其能够减小过拟合的可能性,同时还能减少训练时间和计算量。因此,该方法具有重要的实用价值和推广意义。未来的研究可以进一步优化该方法,提高其准确性和稳定性,以满足实际应用中的需求。
