基于最大均值差异迁移学习的飞机燃油泵故障诊断
2023-10-28张小军
刘 振, 张小军,2, 潘 俊, 叶 茂, 苗 扬,2
(1.北京工业大学 材料与制造学部, 北京 100124; 2.北京工业大学 先进制造北京市重点实验室, 北京 100124;3.中国航空工业集团 南京机电液压工程研究中心,江苏 南京 211102; 4.上海机电工程研究所,上海 200050)
引言
飞机燃油系统是为飞机动力系统和其他辅助动力系统储存、供给燃油的装置,是整个飞机系统中极为重要的一部分。其中,燃油泵是飞机燃油系统的核心,它是否具有良好的健康状态决定着飞机是否能够正常安全地飞行。因此,为了保障飞机燃油系统的正常工作,对燃油泵的健康监测是十分必要的。
目前,许多研究人员对飞机燃油系统故障进行了研究。姜伟华[1]通过小波分析法对油位传感器的数据进行处理,通过寻找系数的极大值来确定故障严重程度;龙浩等[2]通过构建专家系统和推理机对飞机燃油系统进行故障诊断,并通过仿真实验验证了专家系统的智能性及提出的重构方案的有效性;冯惊雷等[3]利用粗糙集理论中的决策表简化方法,将条件属性进行约简,建立了一种新的飞机燃油系统故障分类规则的形成方法;周云龙等[4-5]提出了一种EMD和边际谱带能量结合的方法,提取实验压力信号的低频和高频特征,并用BP网络进行识别,在此基础之上,通过将小波去噪与EMD能量熵相结合形成一个新方法,并将其引入到离心泵汽蚀故障诊断中,并取得了较好的效果;李伟光等[6]针对柔性薄壁轴承在发生故障产生的非平稳、非线性信号,采用希尔伯特-黄变换方法进行分析,同时针对噪声信号会污染整个希尔伯特谱的问题,提出了一种基于SVR谱的PCA降噪算法。郭衍峰等[7]对燃油系统活门进行仿真,证实了在流量和压力增大时活门关闭容易出现结构变形,导致活门出现卡死或者无法关闭的现象。
近年来,随着计算机技术、传感器技术的发展,数据驱动的机械智能故障诊断受到了广泛的关注。机器学习因其强大的故障分类和预测能力被应用到许多领域的故障诊断当中,如风力发电机、机床、机器人等。WANG Ziwei等[8]提出了一种基于小波包和随机森林的旋转机械故障诊断方法,通过小波包分解提取故障特征参数,将5个无量纲指标作为输入,并利用随机算林算法进行分类,取得了较好的结果;YANG Xiaoan等[9]采用统计分析、FFT、VMD三种方法多角度挖掘轴承的多域故障特征信息,并用拉普拉斯积分算法去除冗余信息,最后通过基于粒子群优化的支持向量机分类模型对故障进行分类,并得到了较高的诊断精度;CHEN Qiuan等[10]为解决传统机器学习算法对多类型并发故障的诊断准确率较低的问题,提出了分层机器学习算法,第一层利用传统机器学习模型识别具有明显可分特征的故障,并过滤出具有不可分特征的故障,第二层模型识别上一层过滤掉的故障,并在齿轮箱仿真实验中验证了算法的有效性。JIANG Yuncheng等[11]利用SVM实现了飞机燃油系统间歇故障的检测与诊断。
要训练出性能良好的故障诊断模型,需要有充足的故障数据进行训练,同时也要保障用于模型训练的数据与检测对象有着相似的分布。但在飞机燃油泵的故障诊断当中,故障数据存在以下几个问题:
(1) 燃油泵数据有较强的噪声干扰。飞机燃油系统的工作环境异常复杂,燃油泵的数据信息采集常常伴随着其他器件信息的干扰,在提取可用故障信息时造成了较大的阻碍;
(2) 故障数据比较稀缺。飞机燃油泵的一些故障具有随机性、偶发性的特点。因此,历史故障数据是非常有限的,所以导致机器学习模型的训练数据十分有限,从而达不到较好的故障分类准确度;
(3) 源域和目标域数据之间存在较大的分布差异。由于燃油泵的现存数据有限,不足以完成模型训练与测试的任务,所以需要借助其他结构类似的燃油泵的故障数据作为训练数据。而其他燃油泵与飞机燃油泵的工况不同,这就导致两种泵的故障信息的特征分布并不完全一致,所以如何消除该分布差异产生的影响是本研究需要解决的问题。
迁移学习的提出很好的解决了源域与目标域分布差异问题,其主要目的是充分利用源域的知识来提高在目标域的学习性能。典型的迁移学习方法主要有基于实例的、基于特征的、基于参数的和基于关系的算法[12],最初用在计算机视觉、自然语言处理上[13-14]。目前,已有很多学者将迁移学习应用到多种设备的故障诊断领域,并取得了较好的效果[15-17]。QIU Zaihui[18]、MIAO Yang等[19]为解决飞机燃油泵、海水轴向柱塞液压泵故障数据不足的问题,利用Tradaboost迁移学习算法将油泵数据作为辅助数据训练模型,完成目标泵的故障诊断,证实了迁移学习的可行性。
一般来说,飞机燃油泵与其他类似结构的燃油泵具有相似的力学性质与工作状态,其故障数据中能体现出部分相似的特征。利用迁移学习把在其他类似结构燃油泵上学习到的知识应用到飞机燃油泵上,在此基础之上,本研究提出了一种基于最大均值差异迁移学习的飞机燃油系统故障诊断算法,主要工作如下:
(1) 利用小波包分解提取燃油泵的故障信息特征,同时将这些特征作为故障诊断模型的输入;
(2) 通过SMOTE过采样算法对故障信息进行扩充,增加源域、目标域的数据量,以减少在模型训练阶段数据稀缺所导致的问题;
(3) 将最大均值差异(MMD)作为描述源域与目标域分布差异的度量准则。选取1维卷积神经网络(1D-CNN)中的部分层作为域自适应层,将最大均值差异算法嵌入到域自适应层当中,从而解决源域与目标域间的分布差异问题。
1 小波包分解原理
小波变换具有灵活的时频分辨率特性,但在高频区域变现不佳。小波包的提出[20]弥补了这一缺陷。小波包函数是一个有3个指标的函数:
(1)
其中,整数j和k分别是索引尺度和平移操作。前2个小波包函数分别是常用的尺度函数和母小波函数:
(2)
(3)
对于n=2,3,…的小波包函数由下面的递归关系定义:
(4)
(5)
h(k)和g(k)是与预定的尺度函数和母小波函数相关的正交镜像滤波器。为了测量信号中特定的时频信息,只需取信号和特定基函数的内积。函数f的小波包系数可以通过下式得出:
(6)
计算离散时间信号的小波包分解涉及到对离散时间信号应用2个滤波器[x1,x2,…,xn],然后递归到中间信号。小波包分解原理如图1所示。

S0,0.分解前的信号 Si,j.第i层第j个节点的分解信号图1 小波包分解原理Fig.1 Wavelet packet decomposition principle
2 SMOTE过采样
合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别而不够泛化,SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中,具体如图2所示,算法流程如下:

图2 SMOTE原理Fig.2 Principle of SMOTE
(2) 根据样本不平衡比例设置一个采样比例,以确定采样倍率N,对于每一个少数类样本x,从其K近邻中随机选择n个样本,即xn;
(3) 对于每一个随机选择出的xn,分别与初始样本按如下公式来创建新样本:
xnew=x+λ(xn-x)
(7)
其中,λ为0~1之间的随机数。
3 最大均值差异
3.1 域差异
在传统的机器学习中,一般假设源域和目标域的数据分布是相同的,这是一个理想的状态,但是在实际工况中,两者的数据分布是不同的。以本研究的飞机燃油泵为例,不同型号的燃油泵所面临的工况环境、噪声情况以及运行形况都是不同的,这就导致即使是相同的故障模式,在不同的燃油泵中提取的信息会有明显的差异。为解决这个问题,引入迁移学习的概念,即从已有的数据中学习经验知识,将此经验知识运用到未知的数据当中。如图3所示, 左图为没有迁移学习的情况下,分类会有分错的现象;右图是有迁移学习的情况下的分类结果,相比于左图,在数据分布有差异的前提下,分类效果更好。

图3 域差异问题Fig.3 Problem of domain discrepancy
3.2 最大均值差异

我们总是喜欢苛责别人的过错,用各种条件去要求他人,自己却不遵守准则。我们能轻易发现他人的错误,却很少能揪出自己的不足。这正是因为我们缺失了责己的自觉性。


(8)
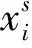
4 基于最大均值差异迁移学习的故障诊断算法
卷积神经网络(Convolutional Neural Network,CNN)在提取数据信息的深层特征方面有着较大优势,但这种优势仅在源域和目标域数据分布极为相似时才能体现。源域和目标域分布有差异时,CNN无法将相同故障数据的不同特征分布一一对应起来,这导致了其迁移性能较弱,对于最终不同故障模式的判别有着非常严重的影响。MMD可以很好的解决这一问题,所以,本研究将MMD作为衡量深层特征分布差异的模块嵌入到CNN的部分层中,构建了基于最大均值差异迁移学习的智能诊断算法(M-CNN),该算法的网络结构如图4所示。

图4 M-CNN结构图Fig.4 Structure of M-CNN
M-CNN由若干层组成,每一层由一个一维卷积层、一个最大池化层和一个批归一化层(BN)组成。在中间层,通过MMD模块进行域分布信息的交互,再使用AdaptiveAvgPool层将经过卷积之后的高维矩阵展平成一个一维数据列,最后通过Linear层对一维数据列压缩,分别输出类别标签和分类损失。
5 实验分析
5.1 实验设置
实验平台原理如图5所示,本平台可模拟燃油泵从储油箱向供油箱输送燃油的任务。如图6a和图6b分别为储油箱输油管和供油箱。
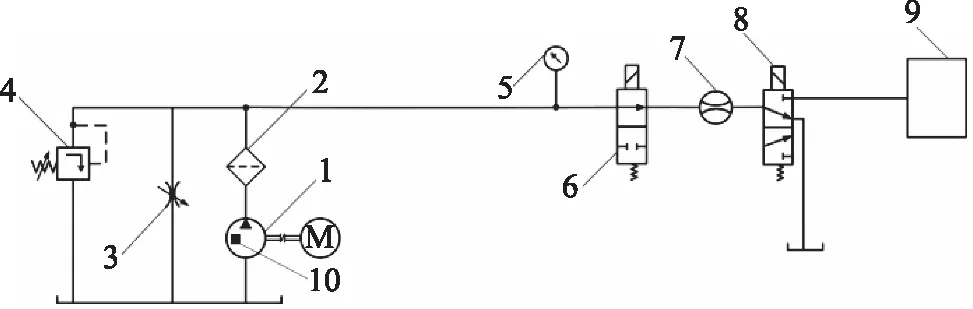
1.齿轮燃油泵 2.过滤器 3.节流阀 4.安全阀 5.压力传感器 6.开关阀 7.流量计 8.换向阀 9.油耗单元 10.传感器图5 实验原理图Fig.5 Schematic diagram of experiment

图6 实验装置Fig.6 Installation diagram of experiment
本实验使用加速度传感器和压力传感器,加速度传感器以磁吸方式安装在电机壳顶部和侧面,压力传感器安装在燃油泵的出油口处。采集燃油泵健康状态与8种故障状态的信号,采样频率为2 kHz。详细信息如表1所示。

表1 故障类别明细
将实验采集的9种数据进行小波包去噪,使用SMOTE算法增加数据量,再将这些数据作为输入送入网络进行训练,具体实验流程如图7所示。

图7 实验流程图Fig.7 Experimental flow chart
5.2 网络设置
本研究所运行算法在Windows10系统上运行,处理器为AMD Ryzen 7 4800H,显卡为GTX 1650Ti,网络模型在Pytorch深度学习框架中搭建。
本研究的具体网络参数如表2所示。

表2 网络具体参数Tab.2 Network specific parameter
在网络的训练中,优化器选取SGD,学习率设置为0.01,动量设置为0.5,损失函数选用交叉熵损失函数,训练集和测试集的batch_size分别设置为64和16,共训练100轮。
5.3 结果分析
为了验证验证M-CNN的迁移性能,选用了以下2个模型进行对比分析:
(1) BP神经网络,BP神经网络是一种多层的前馈神经网络,其主要的特点是信号前向传播,而误差是反向传播的。
(2) 长短期记忆神经网络(LSTM),LSTM是一种特殊的循环神经网络。
对比模型在实验设置上与M-CNN保持一致,均采用大量训练数据和少量目标数据作为训练集,将其余目标数据作为测试集,学习率及训练集、测试集的batch_size设置为0.01,64,16。
将经过小波包分解后的实验数据分别送入BP神经网络、LSTM,CNN以及M-CNN中进行训练,分别得到4种模型的损失曲线,具体如图8所示。

图8 模型训练损失图Fig.8 Variation plot of model training loss
由图可以看出,BP,LSTM和CNN在训练过程中,损失由1.7~2.6下降至0.6附近,并出现较大波动。相较于BP,LSTM和CNN, M-CNN在训练过程中更快的收敛,损失也从2.3迅速下降,最在0.1附近趋近稳定。
模型训练结束后,对4种模型进行测试,分别得到模型对应的混淆矩阵。混淆矩阵体现了模型在分类过程中判断正确的概率以及判断错误为其他类别的概率,具体如图9所示。

图9 模型混淆矩阵结果Fig.9 Results of confuses matrix
由图9可以看出,BP神经网络和LSTM存在很多分错类别的现象,尽管有一些类别判断正确,但判断正确的准确率也相对较低;CNN的表现略好于BP和LSTM,很多故障类别都判断正确且正确率较高,这种现象主要归功于CNN在处理非线性信息的能力以及深层特征挖掘的能力,但也有一些类别存在分错、正确率低的现象,因为本实验的训练集和测试集相同故障的数据分布不同,并且CNN没有处理域分布不同数据的能力,所以导致了这种结果。反观M-CNN,由于MMD模块的引入,能很好的处理存在分布差异的数据,区分每一类别的正确率都比较高,这也体现出M-CNN在处理多分类任务且数据分布存在差异的问题时有着较强的能力。
混淆矩阵体现了4种模型在某一类别的判断能力,为了更好的评估模型,还需要从测试集整体上来分析。本研究引入正确率、精确度、召回率、F1分数4个模型评价指标来评估M-CNN的能力:
(1) 准确率:预测正确的结果占总样本的百分比;
(2) 精确度:在被所有预测为正的样本中实际为正样本的概率;
(3) 召回率:在实际为正的样本中被预测为正样本的概率;
(4) F1分数:同时考虑精确率和召回率,让两者同时达到最高,取得平衡。
具体结果如表3所示。

表3 各模型评价指标结果Tab.3 Evaluation index results of each model
从表3可以看出,M-CNN在准确率、精确度、召回率和F1分数4个指标的表现均远优于BP、LSTM和CNN,所以,更能说明M-CNN在多分类问题、数据分布差异问题上表现优异。
6 结论
本研究提出了一种基于最大均值差异的迁移学习算法用来处理一维数据信息,实现故障模式的判别。主要工作总结如下:
(1) 利用小波包算法去除数据的噪声,避免了在模型训练过程中噪声的干扰;
(2) 通过SMOTE过采样,对小样本数据进行扩充,使得模型得到充分的训练,实现更好的分类效果;
(3) 构建了基于最大均值差异的迁移学习算法(M-CNN),将MMD模块嵌入CNN中,用来解决数据分布差异问题。同时将此方法与BP神经网络、LSTM和CNN进行实验对比,结果表明,M-CNN的准确率为99.40%,远优于其他3种算法,体现了其处理多分类、域差异问题的良好能力。
