试飞数据查询引擎设计
2023-10-28邓国宝查晓文薛博文
邓国宝,查晓文,刘 涛,冯 灿,薛博文
(中国商飞试飞中心 测试工程部,上海 200120)
0 引言
试飞数据主要包括飞行试验采集的时序数据和业务流程生成的试飞任务信息数据。飞行试验采集的时序数据具有参数量多、数据体量、数据种类多样化、数据随机性变化、数据多地产生、数据时效性需求高及数据价值大等特征。国产民机在试飞试验阶段,累积了大量的试飞数据,规模达到了PB级[1-2]。
早期国内外试飞数据主要采用文本形式存储,数据快速应用存在较大困难,数据有效关联受到很大限制,造成统文本文件的数据管理模式难以满足日益增长的数据存储与高效应用需求[3]。波音、空客等国外主制造商采用信息化技术,建立了AnalytX、Skywise等数据管理平台,改进数据存储方式,研制了数据查询工具,提升数据应用效率[4-5]。
试飞数据查询引擎融合新一代信息技术,设计新型数据存储格式、创新试飞数据关联方式、提升试飞数据查询能力,提供更高效的试飞任务信息数据与飞行试验数据融合应用服务,解决多源异构试飞数据复杂管理与试飞数据用户快速高效应用的难题[6-8]。
1 系统结构及原理
如图1所示,试飞数据查询引擎是试飞数据平台数据交互中枢系统,快速获取平台多类数据组件数据,开展数据加工处理后,向数据应用提供服务。试飞数据平台采用三层架构,具有数据层、服务层和应用层等功能,提供综合数据管理与应用服务[9]。试飞数据平台采用分布式架构搭建大数据集群和云计算集群,提供动态弹性的计算、存储、网络等基础设施及服务(IaaS,infrastructure as a service),以及数据库、计算引擎、容器等平台及服务(PaaS,platform as a service),研制基于浏览器/服务器模式(B/S,browser/server)的试飞数据分析应用软件,提供试飞数据分析应用及服务(SaaS,software as a service),形成试飞数据平台三层架构技术支撑[10]。

图1 试飞数据查询引擎系统结构
试飞数据查询引擎基于大数据交互查询presto组件,设计数据集成、数据查询、数据处理等功能。Presto 是一个用于分析的ANSI SQL查询引擎,支持计算和存储的分离,并基于内存计算,减少磁盘IO消耗。Presto可以适配多种不同的数据源,具备多个数据源连接和交互功能,拥有跨数据源和内存计算的优势,实现多个数据源之间的联表查询[11-14]。
数据集成根据具备Presto 跨数据源连接功能,形成订阅多类数据库数据能力,获取存储在MySQL、Hive、数据仓库里的结构化数据,以及获取对象存储、ES、Redis等组件内的数据,并开展数据表关联与融合[15]。
数据查询根据试飞业务需求粒度,基于试飞数据各类形态,设计精细度逐次变化的查询模式。数据查询模式包括概览查询、高保真查询、特征查询、精细查询,满足不同数据应用场景需求。概览查询实现任务总览功能,试飞数据查询引擎直接获取存储到数据仓库应用数据层数据,传输到数据应用软件中进行快速预览。高保真查询实现一定状态下的数据预览功能,访问hive数据库中的数据,经过用户自定义函数(UDF,user-defined function)聚合处理。特征查询实现试飞业务特定条件查询,根据预设试飞参数和规则条件,以及基于试飞有任务特征的数据查询,提取特征属性,转化为规则或条件,开展数据查询。精细查询实现试飞数据原子粒度精细查询[16-17]。
数据计算主要采用采用UDF函数形式,编写规则代码,封装为业务分析函数,实现数据整合与加工。数据计算主要包括时间对齐计算、插值拟合计算、参数合并计算和数值通用计算等简单计算,较为复杂计算采用向试飞数据平台大数据计算引擎提交计算请求,获取大数据引擎计算结果的方式。数据服务以统一应用程序编程接口(API,application programming interface)形式响应数据应用软件订阅数据需求[18-20]。
2 系统硬件设计
试飞数据查询引擎设计立足试飞数据平台资源,采用存算分离技术和异构计算技术,研制数据调度和融合功能,实现试飞数据快速查询与计算,其系统硬件设计如图2所示。
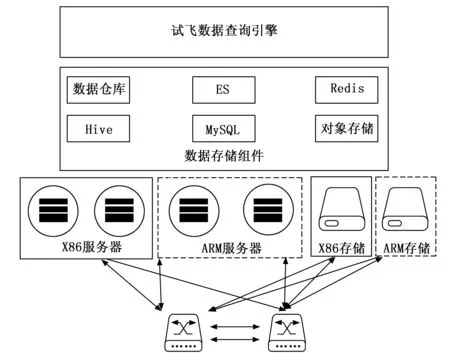
图2 硬件设计
存算分离技术是指存储(云盘/对象存储等)和计算(弹性伸缩)分离至彼此独立的计算域和存储域,并通过以太网或专用存储网络(例如光纤通道)将二者互连,实现了存储资源的灵活扩展和高效共享。满足云和互联网存储域服务兼顾资源利用率、可靠性、性能、效率等众多诉求,充分利用理论上无限的IaaS层的资源来构建,实现资源的池化和按需分配,实现更佳的弹性伸缩能力,从而提高资源的利用率更高的可用性和降低成本。随着高速网络技术和新硬件的发展,数据平台主流方式将计算,内存,和存储资源分别以资源池的方式做解耦合,这些云上IaaS资源以池化形式供应给用户使用,并且通过高速网络来进行链接。
试飞数据查询引擎基于存算分离技术,设计资源分配策略,根据查询任务灵活申请租户资源,确保查询事务正确执行,确保查询事务高效执行,确保系统高可用。试飞数据存储于试飞数据平台对象存储组件,以及基于对象存储的Hive等分布式数据库,并采用备份机制。试飞数据查询引擎获取对象存储的元数据信息,快速获取所需数据块并加载到内存中。试飞数据查询充分发挥分布式计算引擎优势,按需弹性拓展计算单元,分配计算任务至计算单元,在内存中开展大规模并行计算,汇聚计算结果,统一输出查询数据。
试飞数据查询引擎采用X86服务器和ARM服务器混合部署的异构计算技术,定制研发不同计算内核功能模块,屏蔽底层硬件差异带来的计算性能影响,实现计算性能一致性。根据试飞数据计算场景,批处理任务采用X86服务器集群,基于X86的复杂指令集(CISC,complex instruction set computing)特征,完成复杂数据计算功能。流处理场景采用ARM服务器集群,基于精简指令集(RISC,reduced instruction set computing)特征,完成通用计算,发挥其低功耗优势,降低常规计算维护成本。
3 系统软件设计
3.1 软件设计思路和编程方法
如图3所示,试飞数据查询引擎采用大数据分布式交互查询关键技术,基于试飞数据处理与分析平台多种功能数据存储与计算组件,设计数据查询接口,制定资源分配策略,开发试飞数据计算UDF函数,分层加工处理与存储数据,具备多源数据汇聚,多维信息关联查询,多层数据灵活钻取,多功能自定义函数集成,多类指标数据自适应输出等功能。

图3 试飞数据查询引擎软件设计
试飞数据查询引擎基于试飞数据平台交互分析组件Presto研制数据查询功能,采用ANSI SQL和Java等数据开发语言编写数据查询语句和数据计算自定义函数。
试飞数据查询引擎根据Presto组件子功能模块,细分为试飞数据查询为4个过程,即为试飞数据查询入口过程、试飞数据查询服务过程、试飞数据查询与计算过程以及试飞数据源连接过程。
试飞数据查询入口采用Presto的客户端(Client)接收试飞数据应用软件发起的数据查询请求,包括试飞业务结构化数据、试飞试验数据、试飞分析结果数据等数据类型。
试飞数据查询服务采用Presto的coordinator接收查询请求,解析查询任务,生成查询计划,优化查询策略、编排查询任务,获取数据存储元信息并开展解析,并提交给worker,执行数据查询。也接收work查询数据结果,以数据服务形式反馈给客户端。
试飞数据查询与计算采用Presto的worker节点负责查询处理和计算功能。按照分布式系统特点,配置多个worker执行数据查询任务,当 Worker启动时,会通过REST API通信方式广播自己去发现 Coordinator,并告知 Coordinator 它是可用,随时可以接受 Task。根据试飞数据特征和业务逻辑,设计了试飞概览查询worker、试飞数据精细查询worker、试飞数据高保真查询worker、试飞数据特征查询worker,以及试飞数据计算worker等多功能计算节点。各个worker节点间采用RestAPI形式实现数据通信,融合数据处理结果,生成结果数据集。
试飞数据源连接采用Presto的connector负责 Presto 和试飞数据存储组件中的数据源连接。Connector 将 Presto 适配到试飞数据源,驱动数据库连接程序,如Hive或关系数据库。 Presto 包含几个内置连接器:JMX 的连接器 ,它是一个提供对内置系统表访问的系统连接器;Hive连接器和一个用于提供 TPC-H 基准数据的TPCH连接器,以及根据试飞连接场景开发的对象存储和数据仓库连接器等第三方连接器,实现Presto 访问各种试飞数据源中的数据。
试飞数据仓库是试飞数据查询引擎关键数据源,大多数试飞数据应用都从试飞数据仓库中进行数据获取。试飞数据仓库的贴源数据层(ODS,operation data store),基于Hive进行数据存储,数据细节层(DWD,data warehouse details)存储经过一定规则处理后的事件数据集、数据服务层(DWS,data warehouse service)存储经过聚合处理后的统计信息或试飞任务执行结果数据集。维表层(DIM,dimension)存储试飞数据维度信息,包含试飞数据业务元数据、技术元数据等元数据信息,支持试飞数据查询引擎快速解析查询任务。
3.2 软件实现流程
试飞数据查询引擎核心查询功能包括概览查询、高保真查询、特征查询、精细查询,以及查询后数据计算,设计了统一查询功能接口和各类查询实现流程。
3.2.1 概览查询
如图4所示,概览查询查询数仓的ODS层中存储全部参数的按秒聚合数据,每次查询会一次查询并加载该段时间的全部参数的数据,对于采样频率小的参数或参数量不多,且在时间跨度不大的情况下,基于presto的查询结果输出和展示会很快。但对于高频参数(采样频率大于512的参数),单秒的按秒聚合值包含的数据相对于低频参数就会比较大,若参数量增多和时间范围扩大,大数据量的情况下对网络传输和集群查询性能都会有较大的影响。
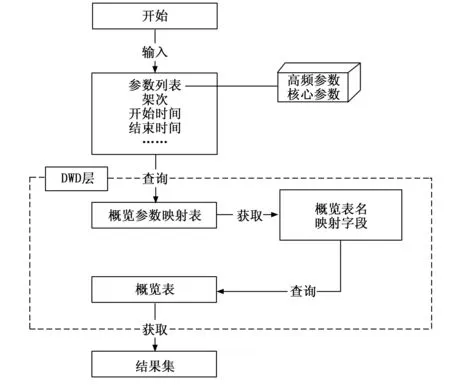
图4 概览查询流程图
基于对查询性能的优化,在数仓的DWD层中创建概览表,用于存储单秒内的聚合值。对于核心参数(查询使用频率较高的参数),在概览表中存储一秒内的最大值及对应的时间(精确到秒);对于高频参数,在概览表中存储一秒内的初始值、最大值、最小值、结束值,将4个值合并为一条数据,并结合对应的时间进行存储。
概览查询先根据参数查询数仓DIM层的概览参数映射表,获取到每个参数存储的概览表名和对应的映射字段,然后查询概览表获取概览数据。概览查询主要用于多参数在长历程时间段中的查询,包括高频参数和核心参数。通过概览查询获取参数的整体变化趋势,存储的聚合值也可获取该参数是否存在波峰或波谷的情况。
3.2.2 高保真查询
如图5所示,高保真查询根据显示器分辨率,选择合适的数据点,表征数据特征。由于试飞数据采样率都比较高,且试验历程都在数小时,在数据选段过程中需要逐步缩小数据范围查看细节数据,且随着数据量增大,对网络传输性能和浏览器的展示性能都会产生负面的影响。基于此进行考虑,从查询服务获取数据后,根据传入的屏幕分辨率进行缩放数据,将总的数据条数降频为指定分辨率下的条数。

图5 高保真数据查询流程
比如对于1 080*1 920的分辨率下,水平方向含有像素数为1 920个。若返回数据集中每个参数对应的数据条数小于1 920条,则可直接返回界面进行展示;若大于1 920条,则需要对每个参数的数据条数对齐到1 920条。对齐方式为1分别除以原始条数和分辨率对应的水平像素数,依次遍历像素数对应的单位间隔,获取原始条数中该区间的最大值,直到遍历结束。
按屏幕分辨率进行缩放后的数据可以减少大数据量对网络带宽和浏览器负载的影响,提高数据的返回效率,保证用户在保持数据准确性的同时,提高查询效率。
高保真查询获取DIM层的参数映射表保存所有架次的参数映射信息,DIM层的参数映射表存储参数对应的原参数字段名、hive映射字段、hive表名、创建时间等信息。在数仓的ODS层的数据表存储每个架次所有参数对应的按秒聚合数据。查询时根据用户传入的参数名、架次信息及其他查询参数,先从数仓DIM层的参数映射表中查询对应参数在hive存储的表和映射字段名,拼接封装查询的sql。通过presto在数仓ODS层对应的表中查询指定参数的数据,并根据屏幕分辨率传递的高保真显示要求输出聚合处理数据。
3.2.3 精细查询
精细查询实现精细度较高甚至原子粒度数据查询,如图6所示。在数仓的ODS层的数据表存储每个架次所有参数对应的按秒聚合数据,但部分参数长度过长,无法直接作为字段进行存储,需要在DIM层创建参数映射表保存所有架次的参数映射信息,DIM层的参数映射表存储参数对应的原参数字段名、hive映射字段、hive表名、创建时间等信息。查询时根据用户传入的参数名、架次信息及其他查询参数,先从数仓DIM层的参数映射表中查询对应参数在hive存储的表和映射字段名,拼接封装查询的sql。通过presto在数仓ODS层对应的表中查询指定参数的数据。
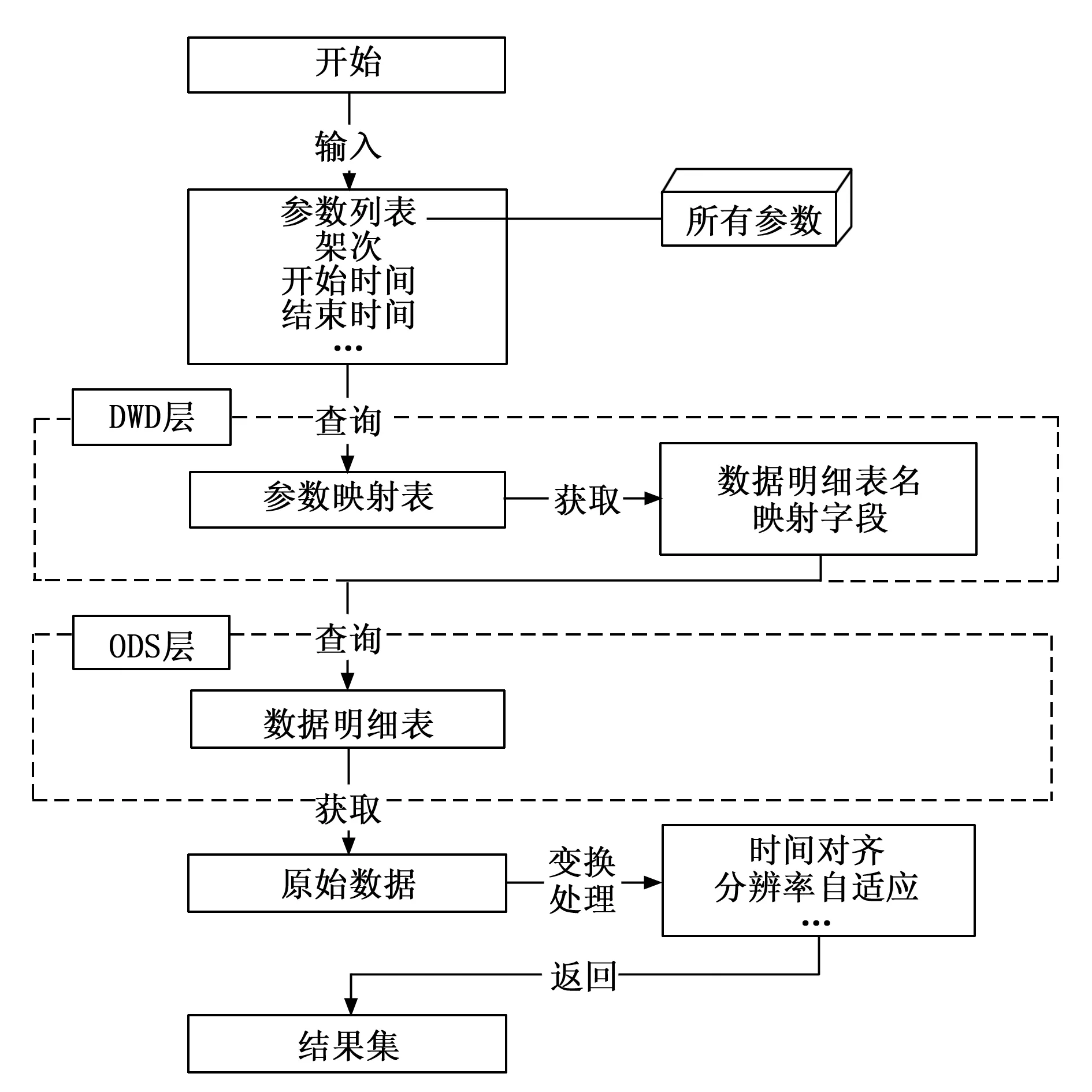
图6 精细查询流程
在数仓ODS层的原始数据是以按秒聚合的形式进行存储,即一条数据包含该参数对应频率秒内的全部数据。时间列中存储的时间精确到秒级,不包含微秒的数据,需要根据规则计算按秒聚合中每条数据对应的微秒值。微秒计算方式为1 000 000除以对应频率后取整,取整方式为去除小数点,然后将长度补全为6位,不足六位的左边补零,并依次遍历获取每条数对应的微秒值。
3.2.4 特征查询
如图7所示,特征查询在满足原始数据查询和基于一定规则过滤数据查询的情况下,实现对查询的数据提取特征,获取特征数据段。在数仓的DWD层,会创建概览表保存核心参数和高频参数在不同架次中的秒内聚合值(最大值、最小值),以及各类主题分析结果明细表。对于获取波峰波谷类型的特征数据,通过查询概览表中的数据,可以直接获取架次中指定参数的该类特征数据。对于获取分析类型的数据,可通过查询对应主题的分析结果明细表中获取分析结果特征数据。

图7 特征查询流程
同时也支持通过对ODS层中原始数据查询后,使用算法平台自定义特征查询。如对于FFT变换,查询服务先查询DWD层的分析结果明细表中是否存在已有分析的数据,若有则直接进行查询后获取结果返回,反之则通过presto查询ODS层中存储的按秒聚合数据,将原始数据输入算法平台调用FFT变换算子,获取变换后的结果进行返回。
试飞数据查询引擎数据计算功能包括时间对齐、插值计算、数值计算以及参数合并等计算方式。
时间对齐为了满足多个参数值在界面上的统一展示,对于相同频率的参数,可直接对查询结果进行返回。对于不同频率参数的数据查询结果,需要将不同频率参数的数据进行升频或降频成相同频率,保证多个参数的数据保持在一个频率上,即同一时间段内,参数对应的数据条数保持一样。如3个参数分别为16频率、32频率和64频率,需要将频率为16的参数升频到32频率,频率为64的参数降频到32频率,即一秒内的数据都是32条。时间对齐服务通过参数映射表获取参数列表中每个参数对应的原始频率,将不同频率参数的数据进行遍历,对单秒内聚合的数据进行时间对齐,将每秒内的数据对齐到同一目标频率中。时间对齐的逻辑为先将1分别除以原始频率和目标频率,获取两个频率的单位时间段,遍历原始频率和目标频率,选择在对应时间段内的区域数据。
插值计算服务通过参数、架次和时间范围等信息获取到原始数据后,可支持调用平台算法模块中生成的接口进行二次计算,如插值计算和拟合计算等操作。可将平台通过离线服务包的方式,将自己建好的算法流程打包成sdk并集成到查询服务中,后续对获取的数据调用生成的sdk进行计算。
数值计算支持根据用户的实际需求自定义UDF函数,将编写好的UDF函数打包到 presto集群中进行部署后,结合sql进行使用。可支持对秒内的数据按值进行过滤,如筛选秒内值中大于某个值的数据及其对应的微秒数,对于32频率的参数,一秒内的单位为1 000 000/32=31 250,则t0=000 000,t1=31 250,t2=62 500,t3=125 000…
将获取微秒值的处理逻辑封装为udf函数,打包到presto集群中,后续的查询结合udf函数获取按秒聚合数据中,每条数据对应的微秒值,和时间列进行拼接后返回。支持对查询结果进行变换处理,如时间对齐、分辨率自适应等操作。同时支持对查询数据导出为文本文件,进行持久化保存。
参数合并对所有参数的时间对齐后数据保持相同的条数。此时可根据业务需求进行参数之间的计算,对多个参数进行合并,如相加、相减等操作。
4 实验结果与分析
4.1 实验步骤和方法
试飞数据查询引擎按照试飞数据平台数据查询流程,开展数据查询功能和性能验证,并进行高保真查询性能验证。主要步骤如下:
第一步:数据查询输入
数据查询输入如表1所示。

表1 查询对象和条件输入
第二步:提交查询请求
通过Https接口协议,提交到Presto查询引擎,执行数据查询,运行时间对齐UDF函数。
第三步:输出查询结果
查询结果如表2所示。

表2 查询结果输出
4.2 实验数据
试飞数据查询引擎完成数据查询和时间对齐,分别在单表和多表情况下,将对应参数的频率对齐到32频率中,实验结果如表3所示。
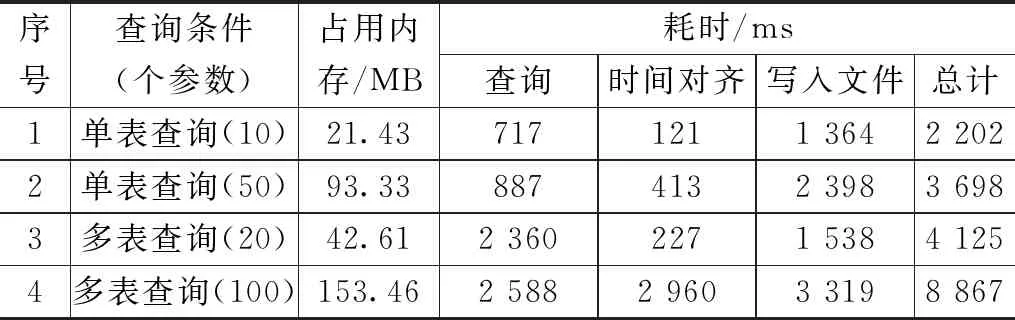
表3 数据查询与时间对齐耗时
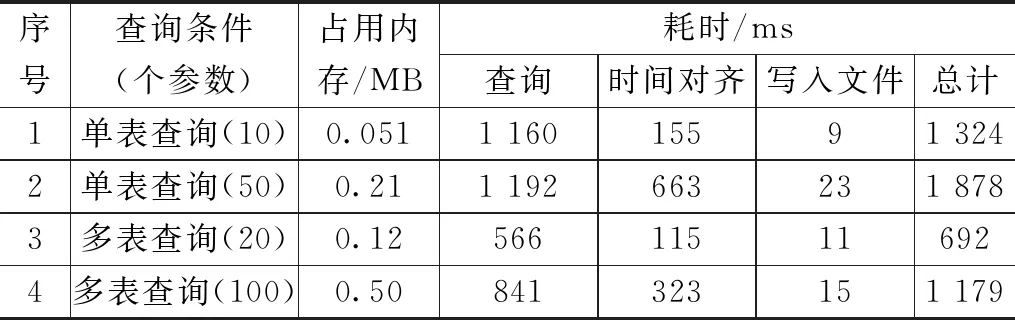
表4 高保真数据查询对比
试飞数据查询引擎在指定1 080 P显示分辨率条件下,开展数据对齐到1 920分辨率查询性能测试,即每次输出1 920个数据点。
4.3 实验分析
试飞数据查询引擎查询性能达到了秒级响应,满足主要查询场景需求。但是随着查询参数增多、数据量增多,查询响应时间会增加,造成数据应用软件获取数据等待时间长的问题,因此需要基于试飞数据平台云资源优势,优化查询条件,控制查询复杂度,采用分布式并行查询方式,提升查询性能。
5 结束语
试飞数据查询引擎立足试飞数据平台优势,应用数据平台三层架构资源,设计硬件系统存算分离和异构计算资源分配策略,设计面向数据用户的多类查询场景,研究新型数据存储方式,开发数据处理自定义函数,完成数据查询功能验证,发挥试飞数据查询引擎作为融合试飞数据平台数据功能层、服务功能层与应用功能层综合应用工具的核心定位,满足试飞数据应用要求。
鉴于试飞数据种类多样化,数据随机性变化,数据多地产生等特点,需要持续优化试飞数据查询引擎架构设计,丰富试飞数据查询引擎功能,提升试飞数据查询引擎性能,主要解决问题如下:
1)丰富数据接口设计,兼容更多试飞数据类型和数据存储组件,拓展试飞数据查询引擎应用场景;
2)优化数据查询架构,发挥试飞数据平台云原生应用与大数据计算优势,持续调优查询策略,提升并发查询能力;
3)深入试飞任务过程,不断开发集成数据计算UDF函数,提供更精准、更高效数据保真度。
试飞数据查询引擎是试飞数据平台核心组件,有力支持试飞数据查询应用,方便快捷响应试飞数据分析应用软件需求,丰富试飞数据平台三层架构内涵,拓展试飞数据应用外延,助力打造试飞数据数据应用生态。试飞数据查询引擎可以归集通用功能,整合为一款工业大数据管理与应用领域通用工具,推广至试验数据等诸多领域,挖掘数据价值。
