基于门控循环单元的非均衡数据驱动异常用电检测方法
2023-10-28孟宋萍田晨璐
孟宋萍,彭 伟,田晨璐
(山东建筑大学 信息与电气工程学院,济南 250101)
0 引言
随着人们生产、生活对电能的依赖性增强,对于其质量与可靠性的需求也在增长。而国内的能源结构及分布制约了我国相关行业的发展[1]。为了应对发展中面临的问题,大力发展智能电网成为了其中的解决方案之一。
智能电网的发展,使得用电过程中的问题尤其是异常用电问题暴露出来。异常用电作为一种非法行为,一直受到相关部门的控制。但是随着智能电网的发展,异常用电的技术手段越来越多,越来越不易被发现,异常用电的检测问题日益严重。
在美国,每年因异常用电损失60亿美元[2],而我国每年损失大概200亿元[3]。异常用电行为在带来损失的同时也给电网的安全、稳定的运行带来了一定难度[4]。智能电表的普及,一方面阻止了某些异常用电行为的发生[5],另一方面提供了大量的用电数据用于分析检测,一定程度上降低了异常用电造成的损失。但是目前异常用电所造成的能源浪费在经济损失上仍占很大的比例,对于异常用电的检测方法也存在一定的提升空间。
随着智能电表的普及,大量的用电数据为数据驱动的异常用电检测方法提供了数据支持。数据驱动的异常用电检测方法主要可以分为基于聚类、基于回归以及基于分类的三类。其中,回归和分类属于有监督学习方法,聚类属于无监督学习方法。
基于聚类的异常用电检测方法是将相似的用电数据通过特定算法划分成一个类别。文献[6]通过最优路径森林聚类方法实现对异常用电的检测,并且与k-均值聚类和高斯混合模型等聚类方法进行了对比,验证了该方法的优越性。文献[7]采用了模糊C-均值聚类来检测用户中的异常用电行为,并且可以根据模糊程度来判断其异常的程度。基于聚类的异常用电检测方法好处是不需要带标签的数据即可实现异常用电检测。但是,其缺点是聚类方法对参数的依赖性较高,参数选取通常比较困难。
基于回归的异常用电检测方法是根据历史用电数据以及各类用电影响因素对未来用电量进行预测,再根据预测量与实际用电量对比来确定是否存在异常用电行为。文献[8]使用了差分整合移动平均自回归模型和神经网络对天然气的用量进行了预测并且判断是否存在异常。文献[9]中的作者采用基于线性回归的方法来确定单个房屋的异常,并从房屋数据中清除此类异常,从而提供能源消耗模式的精确评估。但是,在实际生活中,用户的用电量与各种因素相关比如温度,天气状况等,并且随机性较强,因此很难依靠基于回归的方法实现较高精度的检测。
基于分类的异常用电检测方法可以将其分为机器学习方法和深度学习方法。经典的机器学习方法在异常用电检测中发挥了重要作用。文献[10-11]中,作者提出了基于K-近邻(KNN,K-nearest neighbor)的算法来检测异常用电。文献[12-13]中,作者使用支持向量机来诊断由窃电而导致的异常。文献[14]中,作者改进了决策树模型,利用异常类和正常类的密度来检测消费数据中的异常。集成方法也为异常用电检测贡献了力量。文献[15]中,作者提出了梯度树增强(GBT,gradient boosting tree)方法来检测异常用电行为。文献[16]中,作者提出了以随机森林作为分类器的模型来检测异常用电。
随着深度学习进入大众的视野,基于深度学习的方法也被成功应用于异常用电检测中。在文献[17]中,作者设计了一种基于循环神经网络的异常检测系统,该系统可以从数据中去除季节性因素,从而能更好地捕捉数据的真实分布。文献[18]中,作者使用循环神经网络和K-均值的混合模型识别异常消费。文献[19-20]中,作者提出了基于自动编码器和长短期记忆网络的方法识别用电数据中的异常。文献[21]中,作者提出了变分循环自编码器来检测异常。文献[22]中,作者将随机森林与卷积神经网络结合来检测窃电行为。而在文献[23-24]中,作者提出了基于卷积神经网络的模型,并且将用电数据转成二维数据来学习数据特征。
尽管异常用电检测已经取得了很多成果,但是仍然存在着很多问题。其中最重要的问题就是用电数据存在严重的非均衡性。因为用电数据涉及到用户的隐私,所以用户一般不会公开其用电数据。即便公开,可以得到的也是正常的用电数据,异常数据几乎没有。如果数据集中正常数据的数量远远大于异常数据数量,那么在训练检测模型时,模型更倾向于学习正常数据,不能学到异常数据的数据特征,导致检测效果较差。
合成少数类过采样技术的广泛应用为解决该问题提供了思路。合成少数类过采样技术通过线性插值合成新样本,实现少数类样本和多数类样本数量的均衡。文献[25]中,作者使用合成少数类过采样技术生成岩石可灌浆性分类数据。文献[26]中,作者使用合成少数类过采样技术扩充冷水机组故障数据。因此,在本文,可以借助上述思想,使用边界合成少数类过采样技术(BSMOTE,borderline synthetic minority oversampling technique)对异常数据进行扩充,得到数据平衡的数据集,然后再用于异常用电的检测中。
另外,由于用电数据是典型的时间序列数据,因此如何选择分类器也是一个重要问题。门控循环单元(GRU,gated recurrent units)是循环神经网络的变体,通过其内部的门结构可以实现对时间序列数据长期特性的记忆,并且可以缓解梯度消失的问题。文献[27]中,作者使用门控循环单元解决时间序列中长时间依赖问题用于手势识别。在文献[28]中,作者使用门控循环单元用于语音识别。受上述工作的启发,在本文,使用GRU作为用电数据的分类器,实现对异常用电的检测。
为了解决上述非均衡数据以及时间序列特性问题,提出了基于门控循环单元和边界合成少数类过采样技术的异常用电检测方法 (GRU-BSMOTE),本文的贡献及创新点如下。
1)使用BSOMTE解决数据非均衡问题。使用BSMOTE对实现对少数类异常数据的有效扩充,使其数量与正常数据保持一致。该过程能够有效缓解因异常数据不足导致的模型训练不佳的问题。
2)为了更好地捕获用电数据的时间序列特征,使用GRU对用电数据进行分类。GRU能够有效学习数据的时间特征,在减少训练时间的情况下解决长时间依赖和梯度消失的问题。
3)为了验证该方法的有效性,基于非均衡数据集做了详细的对比实验。实验结果表明,该方法能够实现在不同扩充比例情况下对数据的有效扩充,并且能以更高的准确率实现对异常用电的检测。
1 基本方法介绍
1.1 边界合成少数类过采样技术
在实际应用中,常见的数据非均衡问题的解决方法有3种,分别是数据过采样、欠采样和模型算法的改进。欠采样是指少数类样本数量不影响模型训练的情况下,对多数样本欠采样,实现样本数据的均衡。过采样是指少数类样本数量不足以支持模型的训练时,对少数类样本过采样,使其与多数类样本数量保持一致。模型算法的改进主要是提升模型对于少数类样本的学习能力。基于上述方法综合考虑后,在本文使用过采样技术对异常用电数据进行扩充。
在各种过采样方法中,合成少数类过采样技术(SMOTE,synthetic minority oversampling technique)是一种常用的方法,通过合成少数类样本来均衡数据集中各类样本的分布,提高非均衡数据集的分类精度。合成少数类过采样技术的原理是在相距较近的少数类样本之间生成新样本,没有充分考虑近邻样本的分布特点,存在一定的盲目性,非常容易造成数据类别之间的重复。而位于边界中的样本又对于模型进行分类决策有着重要作用。因此,本文使用边界合成少数类过采样技术对数据进行处理,实现对于非均衡数据集分类精度的提升。边界合成少数类过采样技术是在少数类样本的边界样本中合成新样本,可以有效避免上述问题的发生,提高生成新样本的质量,提高模型学习各类样本特征的能力,其原理如图1所示,并且详细介绍了其步骤。
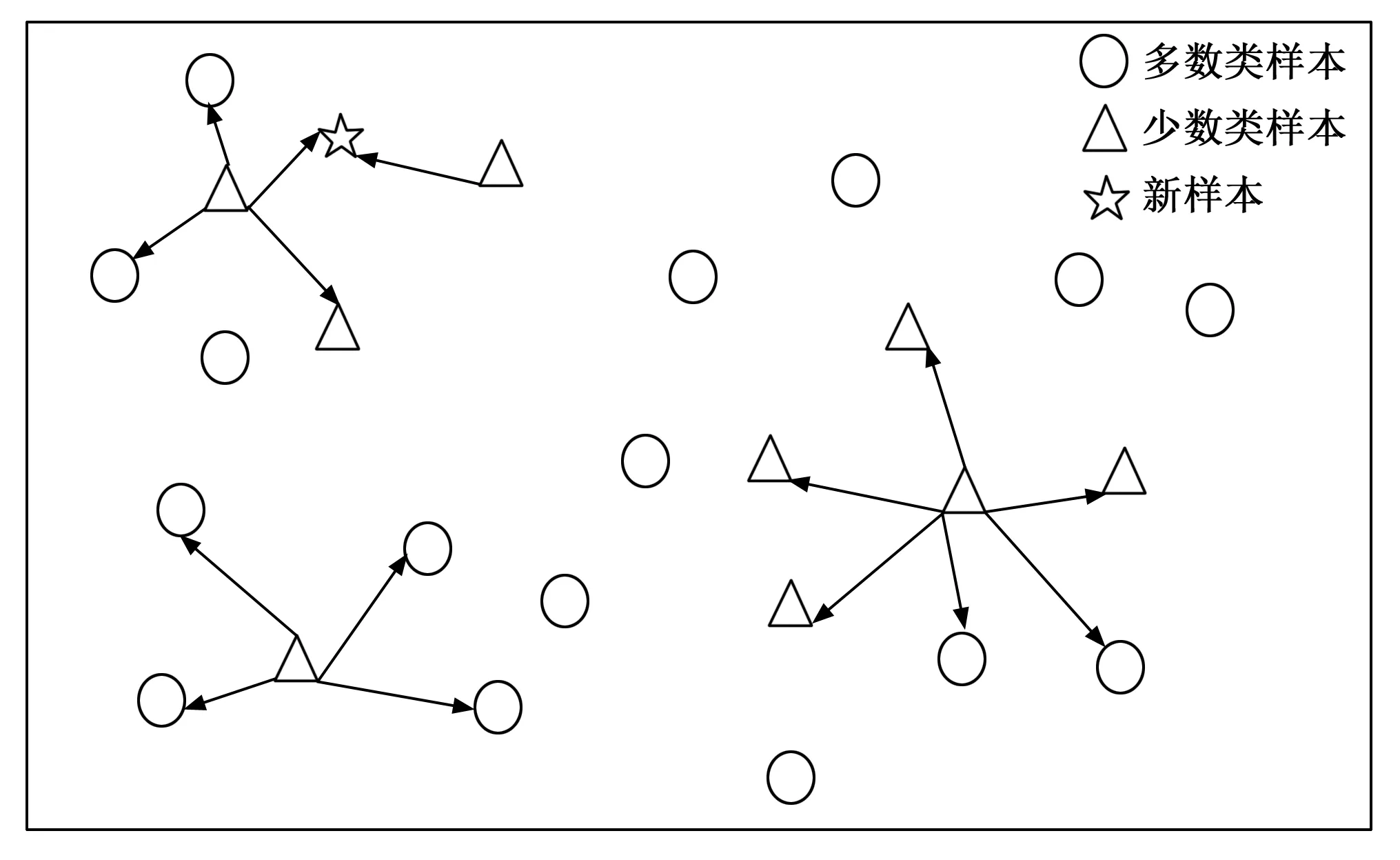
图1 边界合成少数类过采样技术原理图
步骤1:计算少数类样本的每个样本点pi与所有样本的欧式距离,得到该样本的m近邻。
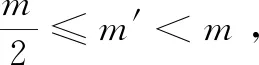
由于数据各个类别的边界数据对于模型的训练分类效果有着重要的作用,因此,边界合成少数类过采样技术在边界样本中合成新样本,合成的少数类新样本的分布更加合理,更加有利于模型区分各类数据,实现分类准确率及精度的提高。
1.2 门控循环单元
长短期记忆网络(LSTM,long short-term memory)作为特殊的循环神经网络,主要是为了解决长时间依赖以及梯度消失等问题。长短期记忆网络拥有3个由Sigmoid和点积操作构成的门结构,通过3个门结构的配合实现对时间序列中信息的丢弃和保留。虽然长短期记忆网络对于长期记忆问题非常有效,但是因为其引入了很多内容,导致其参数变多,使得训练过程难度加大。
门控循环单元是将长短期记忆网络简化改进后的处理时间序列数据的模型。门控循环单元同样能解决长时间依赖以及梯度消失的问题,并且与长短期记忆网络不同的是,门控循环单元只有两个门结构,在输出时也取消了二阶非线性函数。在保证学习效果的基础上,门控循环单元可以有效减少训练时间。在本文,使用门控循环单元作为分类器实现对用电数据的分类。门控循环单元的原理如图2所示,并且详细介绍了其原理。

图2 门控循环单元原理图
如图2所示,门控循环单元中的门结构都是由点积操作和Sigmoid构成,通过二者的配合可以实现对信息的丢弃和保留。门控循环单元的两个门结构分别是重置门和更新门。
首先,重置门rt可以表示为:
rt=Sigmoid(xtWxr+ht-1Whr+br)
(1)
其中:xt是输入,ht-1是上一节点的隐藏状态,Wxr和Whr是权重矩阵,br是偏置。Sigmoid的取值是0~1,因此可以充当门控信号,决定丢弃多少信息保留多少信息。
然后,更新门zt可以写做:
zt=Sigmoid(xtWxz+ht-1Whz+bz)
(2)
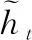
(3)
其中:ht-1包含了过去的信息,rt是重置门,⊙是按元素相乘。tanh激活函数可以将数据缩放到-1~1的范围内。
最后,最终的隐藏状态ht可以表示为:
(4)
其中:zt的取值是0~1,当zt趋于1时,表示长期依赖一直存在。当zt趋于0时,表示忘记隐藏信息中的不重要信息。门控循环单元的关键在于使用了同一个门控zt即可实现对信息的遗忘和选择记忆。
总之,门控循环单元中的重置门决定了如何将当前输入信息与前面的记忆信息结合,更新门决定了前面的记忆有多少保存到当前时间。通过上述操作,可以解决对时间序列数据长期依赖问题,并且可以缓解梯度消失。
2 基于门控循环单元的非均衡数据异常用电检测方法
异常用电检测中的数据非均衡问题是指数据集中异常用电数据数量远远小于正常数据。在模型训练时,很难根据少量的异常数据学习到其特征,也就是说模型很难对异常数据进行检测识别,导致异常用电检测的效率低。
智能电表收集到的用户用电数据是典型的时间序列数据,选择怎样的模型对其进行分类尤为重要。循环神经网络是常用于时间序列数据分类或者预测问题的模型。虽然循环神经网络处理时序数据具有一定优势,但是它却无法解决时间序列中长时间依赖关系的问题,并且存在严重的梯度消失问题。
在本文,为了缓解非均衡数据导致的模型训练不佳的问题,使用BSMOTE对少数类数据进行扩充,得到平衡的数据集对模型进行训练。然后,为了更好的发掘时间序列数据的特性,解决时间序列中长期记忆以及梯度消失的问题,使用GRU构建用电数据与用电行为的映射关系。该方法的整体框架如图3所示,下面介绍了该方法的详细步骤。

图3 非均衡数据异常用电检测流程图
步骤1:对数据进行清洗,去除其中的异常值并且对使用平均值来代替其中的缺失值。
步骤2:由于用电数据存在严重的非均衡问题,即正常用电数据的数量远远大于异常用电数据,使用BSMOTE对少数类数据进行扩充,得到平衡数据集。
步骤3:将平衡数据集划分为训练数据集和测试数据集。使用训练数据集对门控循环单元进行训练、更新模型参数。测试数据集用于验证模型的训练效果。
值得注意的是,由于对异常用电检测模型训练使用的是由BSMOTE与真实数据构成的训练数据集,在测试时,一方面需要测试模型对于异常检测的准确率,另一方面也需要测试BSMOTE合成的数据是否可以用于异常用电检测模型的训练。因此,测试集数据应该全部是由真实数据构成,不仅可以测试模型的性能,还能够测试合成数据是否符合真实用电数据特性。
3 实验
3.1 实验数据和评价指标
在本文使用的数据集来自文献[29],该数据集来自国外一家省级电力公司,其中包括了正常用电数据以及五类异常用电数据。在数据集中随机选取正常以及五类异常数据将其绘制在图4中。

图4 数据展示
如图4所示,正方形点所在的线代表了正常用电数据,其余5个线条代表了五类异常数据。其中,异常1表示用电量异常减少;异常2代表用户的主线路发生故障;异常3代表用户的支路线路发生故障;异常4代表用户用电量异常增加;异常5代表用户用电量在任意时间内异常增加。
另外,为了衡量模型应对非均衡数据的能力,使用了准确率(Acc,accuracy),精确度(P,precision),召回率(R,recall),和F1分数(F1,F1-score)4个指标。
准确率是预测正确的样本数量占总样本数量的比值,其公式如下:
(5)
其中:TP代表样本实际是正类,模型将其预测为正类。TN代表样本实际是负类,模型将其预测为负类。FP代表样本实际是负类,但是模型却将其预测为正类。FN代表样本实际是正类,但是模型将其预测为负类。
精确度是指所有预测为正类的样本中,实际也为正类的概率,计算公式为:
(6)
召回率是指实际为正类样本,预测结果也是正类的概率,计算公式为:
(7)
在应用中,精确度和召回率都希望很高,但是实际上二者是存在矛盾的,无法做到二者都最高,因此为了衡量二者的平衡,定义了F1分数。F1分数可以同时考虑精确度和召回率,也就是说精确度和召回率的平衡点是F1分数,其计算公式为:
(8)
3.2 对比方法及实验设置
在本文,将门控循环单元与经典分类模型支持向量机(SVM,support vector machine)以及时间序列模型长短期记忆网络做了对比。
SVM作为典型的分类模型在故障诊断[30]和功率预测[31]方面取得了成功应用。SVM通过寻找最优分类面实现对数据的分类。不仅可以对线性数据进行分类,借助核技巧将非线性数据映射到高维空间,使得SVM也可以处理非线性数据。
为了解决循环神经网络的无法学习到长期依赖以及梯度消失问题,LSTM被提出[32]。LSTM的优点是其拥有3个门结构,分别为遗忘门,输入门和输出门。每个门结构都是由一个Sigmoid层和点积操作组成。通过3个门结构的组合可以决定信息被保留多少和被丢弃多少。
本文搭建了循环层为2的堆叠GRU用于构建用电数据与用电行为的映射关系,其中隐藏层节点数为32,损失函数设置为交叉熵损失函数,优化器设置为Adam。在对比实验中,构建了一个双向LSTM模型,隐藏层节点数设置为72。在使用非线性多维支持向量分类器对用电数据进行分类时,惩罚系数设置为1,核函数设置为高斯径向基函数(RBF,radial basis function),参数gamma设置为‘auto’。
本文的所有实验都是在一台标准PC机上使用Python 3.7实现的,CPU为Intel酷睿i7-7700HQ,运行频率为2.80 GHz,内存为16.0 GB。
3.3 实验结果分析
3.3.1 验证BSMOTE的有效性
为了验证BSMOTE生成数据是否与真实数据相似可以用于模型的训练,使用生成数据作为训练集,真实数据作为测试集做了对比实验。另外,为了验证均衡数据集有利于模型的训练,还将扩充后的均衡数据集与非均衡数据集做了对比,并且考虑了不同数量真实数据的情况下即不同扩充比例的情况下,扩充后的均衡数据集的表现。扩充比例是指训练数据集中生成数据与真实数据的比值。实验结果如表1所示。

表1 不同训练数据集异常用电检测结果
从表1可以看出,当测试数据是真实数据时,异常用电的检测结果较好。当扩充比例为11∶1时,4个指标均在99%以上;当扩充比例为5∶1时,4个指标均为98.27%;当扩充比例为3∶1时,检测准确率为97.97%;当扩充比例为2∶1时,4个指标均在98%以上;当扩充比例为1∶1时,异常用电检测精确度为98.59%。上述数据说明使用BSMOTE生成的数据与真实数据是非常相似的,BSMOTE在异常用电数据的扩充上是成功的。
另外,也可以看出不论生成数据与真实数据的比值是多少,与非均衡数据集相比,均衡数据集效果优于非均衡数据集。
详细来讲,在扩充比例为11∶1时,与非均衡数据集相比,准确率提高了9.38%,精确度提高了16.85%,召回率提高了26.28%,F1分数提高了21.85%。在扩充比例为5∶1时,与非均衡数据集相比,准确率提高了8.56%,精确度提高了9.61%,召回率提高了12.54%,F1分数提高了11.10%。在扩充比例为3∶1时,与非均衡数据集相比,准确率提高了7.51%,精确度提高了7.32%,召回率提高了8.31%,F1分数提高了7.83%。在扩充比例为2∶1时,与非均衡数据集相比,准确率提高了6.75%,精确度提高了6.34%,召回率提高了5.91%,F1分数提高了6.12%。在扩充比例为1∶1时,与非均衡数据集相比,准确率提高了5.38%,精确度提高了4.72%,召回率提高了4.86%,F1分数提高了4.79%。
上述数据说明均衡的数据更有助于模型的训练,有助于模型容易学习到不同类别数据的特征,提高模型的分类精度。
3.3.2 数据生成方法对比结果
为了验证BSMOTE方法的有效性,在不同扩充比例下将其与生成对抗网络(GAN,generative adversarial networks)做了对比。GAN是一种采用对抗的思想来生成数据的方法,已经在图像生成等多个方面取得了成功应用。GAN是由生成器和判别器构成。生成器负责生成与原始数据相似的数据,判别器负责判断该数据是生成数据还是真实数据。通过生成器和判别器的博弈,可以得到与原始数据相似的生成数据。
在该实验中,均衡数据集是由BSMOTE和GAN扩充得到的,且扩充前原始数据保持一致。并且考虑了不同扩充比例后即训练数据中生成数据与真实数据的比值不同的情况下的分类效果,实验结果如表2所示。

表2 不同数据生成方法对比结果
从表2中可以看出,BSMOTE生成数据训练的模型检测效果优于GAN。当扩充比例为11∶1时,BSMOTE与GAN相比4个指标平均提高了6.28%;当扩充比例为5∶1时,BSMOTE与GAN相比4个指标平均提高了5.86%;当扩充比例为3∶1时,BSMOTE与GAN相比4个指标平均提高了4.32%;当扩充比例为2∶1时,BSMOTE与GAN相比4个指标平均提高了5.12%;当扩充比例为1∶1时,BSMOTE与GAN相比4个指标平均提高了5.25%。
3.3.3 验证GRU的有效性
为了验证GRU对于用电数据分类的有效性,将其与SVM和LSTM做了对比。在该实验中,3个模型所使用的数据集是BSMOTE扩充后的均衡数据集。实验中训练与测试数据集均一致,验证在该条件下不同方法的异常用电检测性能。并且在该实验中,还考虑了不同扩充比例时的分类效果,实验结果如表3所示。

表3 不同分类方法检测结果
从表3中可以得出,本文提出的方法的结果优于其他方法。当扩充比例为1∶11时,GRU与LSTM相比4个评价指标提高了3.40%~3.52%,与SVM相比提高了1.52%~3.46%。当扩充比例为1∶5时,GRU与LSTM相比4个评价指标提高了5.4%~5.52%,与SVM相比提高了3.00%~6.49%。当扩充比例为1∶3时,GRU与LSTM相比4个评价指标提高了4.69%~5.20%,与SVM相比提高了2.82%~6.46%。当扩充比例为1∶2时,GRU与LSTM相比4个评价指标提高了5.64%~5.85%,与SVM相比提高了3.00%~6.77%。当扩充比例为1∶1时,GRU与LSTM相比4个评价指标提高了5.60%~5.67%,与SVM相比提高了3.16%~7.54%。
4 结束语
本文提出了基于门控循环单元的非均衡数据驱动的异常用电检测方法。使用边界合成少数类过采样技术解决实际应用中异常用电数据过少导致的非均衡数据问题。 边界合成过采样技术在数据类别边界生成数据,能够实现对少数类数据的有效扩充并且能够使得模型更容易学习不同类别数据的特征。为了更好地捕获用电数据的时间序列特征,采用GRU实现对用电数据的分类。经过详细的实验验证,表明该方法能够实现不同扩充比例情况下地数据有效扩充,并且能够以更高的准确率检测异常用电行为。在未来的研究中,将会致力于研究如何在保证检测准确率的基础上,简化模型,降低模型参数,并且进一步减少模型的训练时间。
