基于改进粒子群优化T-S ANFIS算法的诊断油浸式变压器故障研究
2023-10-28乐效鹏李嘉诚
乐效鹏,史 兵,李嘉诚
(常州大学 机械与轨道交通学院,江苏 常州 213164)
0 引言
油浸式变压器是电力系统中常用的重要设备,其安全运行对于电网稳定具有至关重要的作用[1-2]。然而,由于长期使用和各种外部因素的影响,油浸式变压器容易出现各种故障,如低能放电、高温过热、绕组短路等[3-5],这些故障若得不到及时准确的诊断,将导致设备失效或严重事故。
文献[6]通过在线实时监测和分析油色谱,成功实现了对油浸式变压器内部故障的诊断和运行状态的评估。文献[7]提出了一种反向传播(BP,back propagation)神经网络综合蜂群算法的方式,并构建了基于BP的变压器故障诊断模型,有效提高了故障诊断的精确度。文献[8]应用多层动态自适应优化参数法对最小二乘支持向量机(LSSVM,least squares support vector machine)进行参数优化,并将其用于油浸式变压器故障诊断中,成功证明了该算法的有效性。文献[9]将BP神经网络与改进的自适应提升算法相结合,构建了变压器故障的串联诊断模型,并通过实验证明该模型对变压器故障诊断的准确性有较好的提高。文献[10]采用Pearson相关系数对特征气体集进行滤波和优化,结合Lasso回归建立特征的多维线性模型,并通过实例验证了动态模型对变压器故障诊断的可行性。文献[11]使用Rdpid Miner服务器构建数据挖掘分析工具并与光谱技术结合,通过连续迭代以确定变压器故障诊断准确性的最佳吸收波长组合。文献[12]利用飞蛾火焰优化算法(MFO,moth flame optimizer)对概率神经网络的平滑因子进行优化,通过实验数据仿真,证明了模型对变压器故障诊断的准确率有较好提升。文献[13]采用KPCA算法对数据进行降维处理,并利用DBSO算法对CatBoost模型进行优化和故障诊断,实验证明优化后的模型与其他预处理方法相比,在变压器故障诊断的准确性及效率方面都有显著的提高。文献[14]使用公共向量方法对变压器油中溶解气体进行数据分析,通过电气测试实验证明了其在诊断精度和运行时间方面的优越性能。文献[15]先采用粗糙集理论对故障数据进行优化处理,再利用天牛须算法优化BP神经网络模型进行诊断研究,经实验证明了方法的可行性和有效性。文献[16]提出了一种基于改进天鹰算法(MAO,modified aquila optimizer)优化核极限学习机(KELM,Kemel based extreme learning machine)的诊断方法,有效提升了故障诊断的收敛速度。文献[17]提出用MPC优化贝叶斯网络的变压器故障诊断方法,实验表明改进方法后的故障诊断正确率更高。
综上所述,现阶段国内外均已研究出多种油浸式变压器的故障诊断模型,提升故障诊断的精度及效率仍是目前研究的重点方向。基于此,本文提出了一种改进的粒子群算法,它能够有效地解决自适应模糊神经网络参数寻优能力较弱、收敛速度较慢以及粒子群后期容易陷入局部最优等问题。改进算法应用收敛域和欧式距离判别雷同粒子以一定的概率重新随机初始化粒子,使粒子后期能够跳出潜在的局部最优位置,提高算法找到更优解的可能性。此外,动态惯性权重和学习因子线性调整策略的引入进一步增强了算法的全局搜索能力和收敛速度。利用改进粒子群算法(IPSO,improved particle swarm optimization)优化T-S型自适应模糊神经网络(T-S ANFIS,T-S adaptive neuro fuzzy inference system)的故障诊断模型对变压器的稳定运行有重要的现实意义,同时也为其它相关领域提供了新的优化思路。
1 粒子群算法及其改进
1.1 粒子群算法
粒子群算法(PSO,particle swarm optimization)基于对鸟群的集体智能行为进行研究,是一种重要的优化方法[18]。PSO算法将优化问题抽象为一组粒子在搜索空间中的运动,通过随机赋值位置和速度来初始化种群。在探索空间深处时,粒子依靠经历和周围环境的变化来调整位置和行进速率。粒子通过跟踪个体极值(Pbest,particle best)和全局极值(Gbest,global best)来更新自身状态,从而更好地掌握最优解的位置。该算法具有出色的全局搜索性、高效的收敛性以及简单的实施方式,已经广泛应用于图像处理、机器学习和参数优化等多个领域[19]。
设一个D维搜索空间,由n个粒子组成种群X=(X1,X2,…,Xn)。种群中第i个粒子位置Xi=(Xi1,Xi2,…,XiD),通过目标函数计算每个粒子对应的适应度值。种群中第i个粒子速度Vi=(Vi1,Vi2,…,ViD),粒子i的最优位置为Pi=(Pi1,Pi2,…,PiD),整个种群的历史最优位置为Gi=(Gi1,Gi2,…,GiD)。标准粒子群算法中,粒子速度和位置的更新是关键,其更新公式如下:
(1)
(2)
式中,d=1,2,…,D;i=1,2,…,n;Vid为粒子速度;w为惯性权重;c1、c2为区间范围[0,2]内的加速度常系数;r1、r2为区间范围[0,1]内的随机数。
粒子群算法的性能受粒子行为和参数设置的影响。不当的参数设置可能使粒子速度过快或过慢,导致搜索效果变差。调节参数虽简单,但却对算法性能至关重要。参数包括:种群规模n,惯性权重w,加速度常系数c1和c2,最大迭代次数T。合理的参数设置可以平衡全局和局部搜索,从而提高算法性能。
1.2 改进粒子群算法
粒子群算法因易于理解和调节参数较少等优点被广泛应用,但该算法也存在一些缺点。在优化过程中,算法响应速度快且有效,但当粒子接近最优点时,粒子的速度会变得很小,导致群体呈现出“趋同性”,使得算法易于陷入局部最优解。此外,个体容易受到全局影响而离开当前搜索区域,从而影响之前的局部搜索结果,降低搜索精度[20]。此外,由于迭代公式的简单,所以参数的调整对算法的收敛过程有着重要的影响。为了改善基本粒子群算法存在的问题,本文提出一种改进粒子群算法,该算法引入动态惯性权重w和学习因子c1、c2的线性变化公式,以及后期收敛域和雷同粒子判别,以提高种群的多样性和算法的寻优能力,避免陷入局部最优解。
1.2.1 惯性权重w的动态调整
在标准粒子群算法中,惯性权重w通常为固定值1,不易于迭代后期的局部收敛。然而,动态调整惯性权重可以避免在搜索初期和搜索后期惯性权重取值单一不当的问题。在探索初期采用较大的惯性权重,强化全局搜索能力,提高算法的收敛速度和搜索范围;在搜索后期逐渐减小惯性权重,强化局部搜索能力。采用动态非线性减小的方法可以更加精准地调节惯性权重,避免算法过早陷入局部最优解,提高算法的收敛精度。惯性权重w的动态改进公式如下:
(3)
式中,wmax为惯性权重的最大值,wmin为惯性权重的最小值;Fi为粒子i的适应度值,Favg为当前所有粒子的平均适应度值,Fmin为当前所有粒子的最小适应度值;Rand为(0,1)间的随机数,K为粒子在第t次迭代时与粒子总迭代次数T的比值:K=t/T。
1.2.2 学习因子c1、c2的线性变化
在标准粒子群算法中,固定学习因子c1和c2可能导致全局搜索和局部搜索能力的平衡存在问题,使得收敛速度过快或过慢。而随着迭代次数的增加,线性调整学习因子c1和c2可以较好地解决这一问题。初试迭代阶段,较大的c1和较小的c2有助于全局搜索和加快搜索速度。随着迭代次数的增加,较小的c1和较大的c2有利于避免陷入局部极值点。学习因子c1、c2的线性改进公式为:
(4)
(5)
式中,c1为自我学习因子,c2为群体学习因子;K为粒子在第t次迭代时与粒子总迭代次数T的比值:K=t/T。
1.2.3 收敛域及雷同粒子判别
为了保证粒子种群的丰富性,并防止在后期出现局部优化,将粒子的个体最优位置与种群的全局最优位置进行比较,当满足式(5)时即判定部分粒子进入全局最优的收敛域;此时,未进入收敛域内且适应度函数值处于种群前5%的粒子的参数取种群后20%粒子参数的平均值。在收敛域内,若其他粒子与最优粒子间的欧式距离小于1则被认定为雷同粒子,赋予雷同粒子随机参数跳出收敛域,以保证种群的多样性和后期跳出局部最优。
(6)
式中,Gbest为种群的全局最优位置,Pbest为粒子的个体最优位置。
2 T-S型自适应模糊神经网络
T-S型自适应模糊神经网络是一种将T-S模糊推理系统和神经网络结合的自适应推理网络。该网络能够将输入空间划分成多个模糊子集,并对每个子集进行建模,最终得到一个整体的模糊推理结果[21-22]。其学习算法包括前向传播和反向传播两个部分,通过调整样本量和网络参数,可以实现前向传播并获取准确的输出结果。在T-S型自适应模糊神经网络中,每个隶属度函数都由若干个参数决定,这些参数需要通过学习来确定。采用梯度下降法虽然可以有效地减小误差函数,但由于它不具有凸性,因此很容易导致局部最优解的出现[23-24]。为了解决这一挑战,研究人员提出了许多相关的解决方案,例如采用粒子群算法以达到更好的结果。
T-S型自适应模糊神经网络是一种集成了传统神经网络优势的改良型结构,分为前件网络和后件网络两部分,结构如图1所示。

图1 T-S型自适应模糊神经网络结构
系统的前件网络由四层架构组成,包括输入层、模糊层、规则层以及去模糊层,这些层的结合使前件网络能够有效地运行。
第一层为输入层,用于处理输入向量X=(X1,X2,…,Xn),并将其传递到下一层。本文系统的输入层的节点个数为5,分别对应油浸式变压器内部五种气体含量:氢气、甲烷、乙烷、乙烯和乙炔。
第二层为模糊层,用于对输入数据进行模糊化,并计算不同输入分量属于各语言变量值模糊集合的隶属度μmn。根据实验需求和仿真经验,采用高斯函数作为隶属度函数,通过改进粒子群算法对高斯函数中的参数cmn和bmn进行优化。根据油浸式变压器故障分类需求,将模糊分割数设定为7,则本层对应的节点数量为35。
(7)
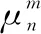
第三层为规则层,将各节点的隶属度进行模糊计算,并采用加权法求得每个规则的适应度。在模糊网络中,只有在靠近输入点的语言变量值才具有较高的隶属度值,因此只有少数节点会产生较高的输出值,这点类似于局部逼近网络。
(8)
系统的后件网络由r个具有相同结构的子网络构成,网络间通过交互作用实现数据传输。
子网络的第一层为输入层,其中第0个节点X0的输入值为1,用于在模糊规则后件中提供常数项。
子网络的第二层共有m个结点,每个节点代表一条规则,该层的作用是计算每一条规则的后件,规则推理结果由yrm来表示:
(9)

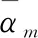
(10)
比较推理结果中的最大值作为整个系统的输出,即为油浸式变压器故障类型对应编号。
3 基于IPSO优化T-S ANFIS的变压器故障诊断模型
3.1 基于IPSO优化T-S ANFIS的网络训练过程
在T-S ANFIS网络中,改进粒子群算法被应用于网络的参数优化。通过初始化种群粒子的参数集,并设定粒子的位置和速度,以及规定种群规模和迭代次数等参数,粒子群适应度值可以被计算出来。通过比较当前位置和历史最佳位置的适应度值,可以找到全局最佳位置。最后,利用改进方法更新粒子群的位置和速度,循环迭代至满足算法的终止条件。改进算法可以有效地提高ANFIS网络的训练效率,以便更好地对变压器进行故障诊断。基于IPSO优化T-S ANFIS网络的算法流程如图2所示,网络训练的具体过程步骤如下。
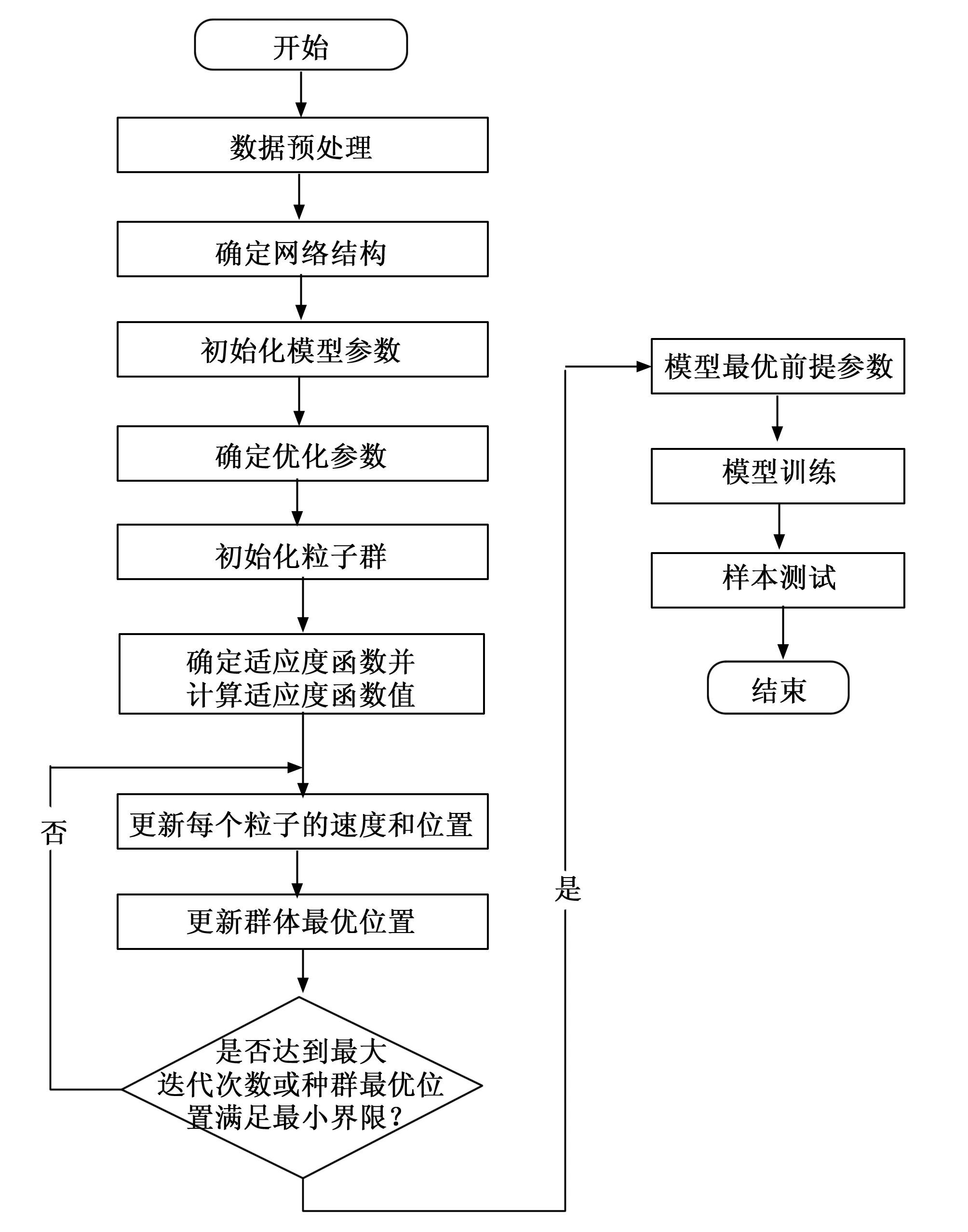
图2 基于IPSO优化T-S ANFIS网络的算法流程图
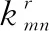
步骤2:粒子适应度值计算。将ANFIS网络不正确分类的样本数作改进为粒子群的适应度函数,计算初始化粒子的适应度值,从中寻找个体极值Pbest和Gbest群体极值。
步骤3:粒子评价。对于每个粒子,比较其当前位置的适应度值和其历史最佳位置的适应度值,如果当前位置更优,则更新其历史最佳位置。将所有粒子的历史最佳位置进行比较,找到适应度函数值最小的位置,并将其设为全局最佳位置。

步骤5:终止条件判断。当达到预设的最大迭代次数或最小误差要求时,停止迭代,输出最优解作为网络模型的前提参数,否则跳转到步骤2。
步骤6:将粒子群优化的前提参数代入T-S ANFIS进行模型训练。训练完成后,输入测试样本对模型的故障诊断准确度及速度进行实验。
3.2 数据预处理
通过数据预处理,可以有效地剔除不必要的信息,并且通过优化来提高原始数据的准确性。通过这种方式,可以消除外部因素和测量过程中的不确定性,从而提升数据的准确性和可靠性。本系统选取油浸式变压器中的5种主要特征气体:氢气、甲烷、乙烷、乙烯和乙炔作为实验数据,并利用式(11)对特征气体数据进行归一化处理,以此来提取出有助于变压器故障诊断的有效参数。选取7组典型的油浸式变压器故障测试样本气体归一化体积分数数据见表1。

表1 故障特征气体归一化体积分数
(11)
式中,Xn表示归一化后的变压器故障气体含量,n=1,2,…,5;Qn表示变压器故障的特征气体原始含量,Q1到Q5依次表示特征气体中的氢气、甲烷、乙烷、乙烯和乙炔。
3.3 模型评价标准
基于上述实现方式,归一化的数据输入粒子群优化后的模糊神经网络进行故障诊断,输出诊断的变压器故障类型,并对模型诊断结果进行评估。本文选取平均绝对误差(MAE)作为算法优化诊断模型的评价指标,误差表达式为:
(12)
式中,Ek和Rk分别表示故障诊断类型编号和实际诊断类型编号;若Ek与Rk的编号值一致,则两者差值记为0,否则记为1;n表示测试样本的数量。
4 仿真实验分析
本文使用IPSO优化构建T-S ANFIS神经网络模型,选取了油浸式变压器中油色谱数据5种主要特征气体:氢气、甲烷、乙烷、乙烯、乙炔。气体数据经过归一化处理后,作为神经网络的特征输入量。神经网络的特征输出为7种变压器诊断类型,分别为:正常(输出1)、低能放电(输出2)、高能放电(输出3)、低温过热(输出4)、高温过热(输出5)、中温过热(输出6)和中低温过热(输出7)。
从变压器研究资料中收集500组油色谱数据,其中正常52组,占10.4%;低能放电82组,占16.3%;高能放电134组,占26.9%;低温过热17组,占3.4%;高温过热153组,占30.7%;中温过热13组,占2.5%;中低温过热49组,占9.8%;按比例选取400组作为训练样本,100组作为测试样本。实验中粒子群规模设置为50,最大迭代次数设置为500;惯性权重按公式(3)动态调整,其中惯性权重的最大值和最小值分别设置为0.9和0.1;学习因子c1、c2按式(4)、式(5)线性变化,并引入收敛域和欧式距离判别雷同粒子以一定的概率重新随机初始化粒子,使用Matlab进行仿真测试。当达到最大迭代次数500次或误差达到预设阈值0.01时,输出全局最优位置作为对应的T-S ANFIS网络的前提参数。
在输入、输出相同的情况下,对改进粒子群算法的策略进行消融实验。对惯性权重动态调整公式、学习因子线性调整公式以及算法引入的收敛域和欧式距离判别雷同粒子进行改进算法的控制变量实验,控制粒子群改进策略优化ANFIS进行故障诊断的结果对比如表2所示。在测试条件相同的情况下,IPSO算法优化的故障样本诊断最优率约为98%,高于标准ANFIS网络和标准PSO优化的ANFIS网络,具体故障样本诊断结果如表3所示;基于IPSO优化T-S型ANFIS网络、标准PSO优化T-S型ANFIS网络、标准T-S型ANFIS网络对100组测试样本的故障诊断最优结果对比如表4所示;三种方法的仿真耗时如图3所示,最优故障诊断分类分别如图4~6所示。
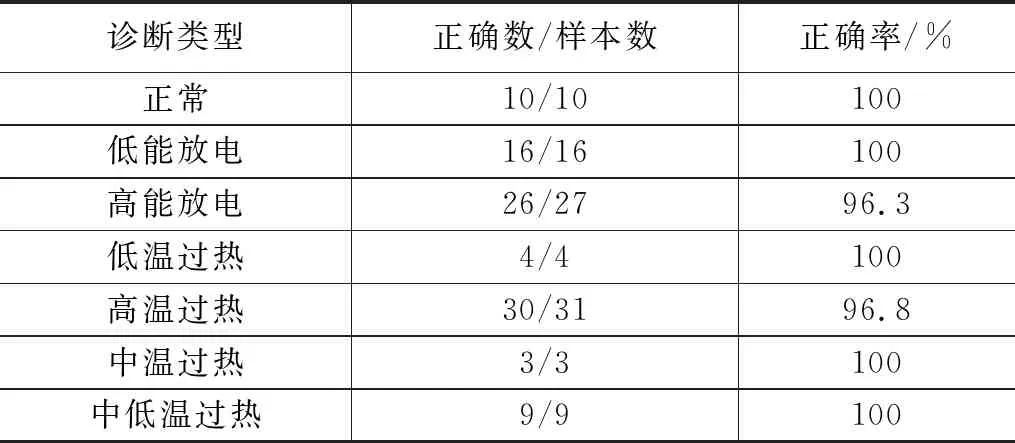
表3 IPSO优化算法训练故障样本诊断最优结果
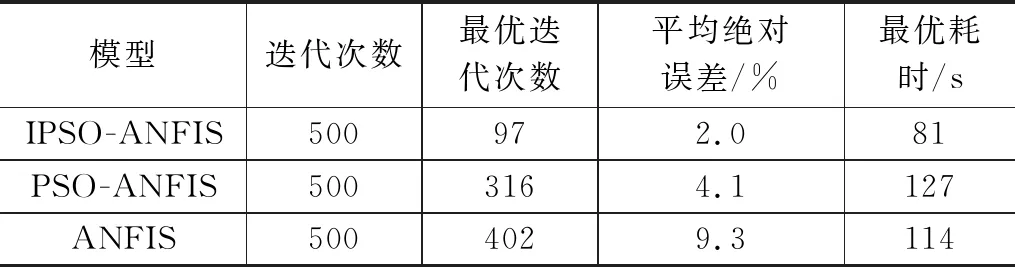
表4 IPSO-ANFIS、PSO-ANFIS、ANFIS故障诊断最优结果对比
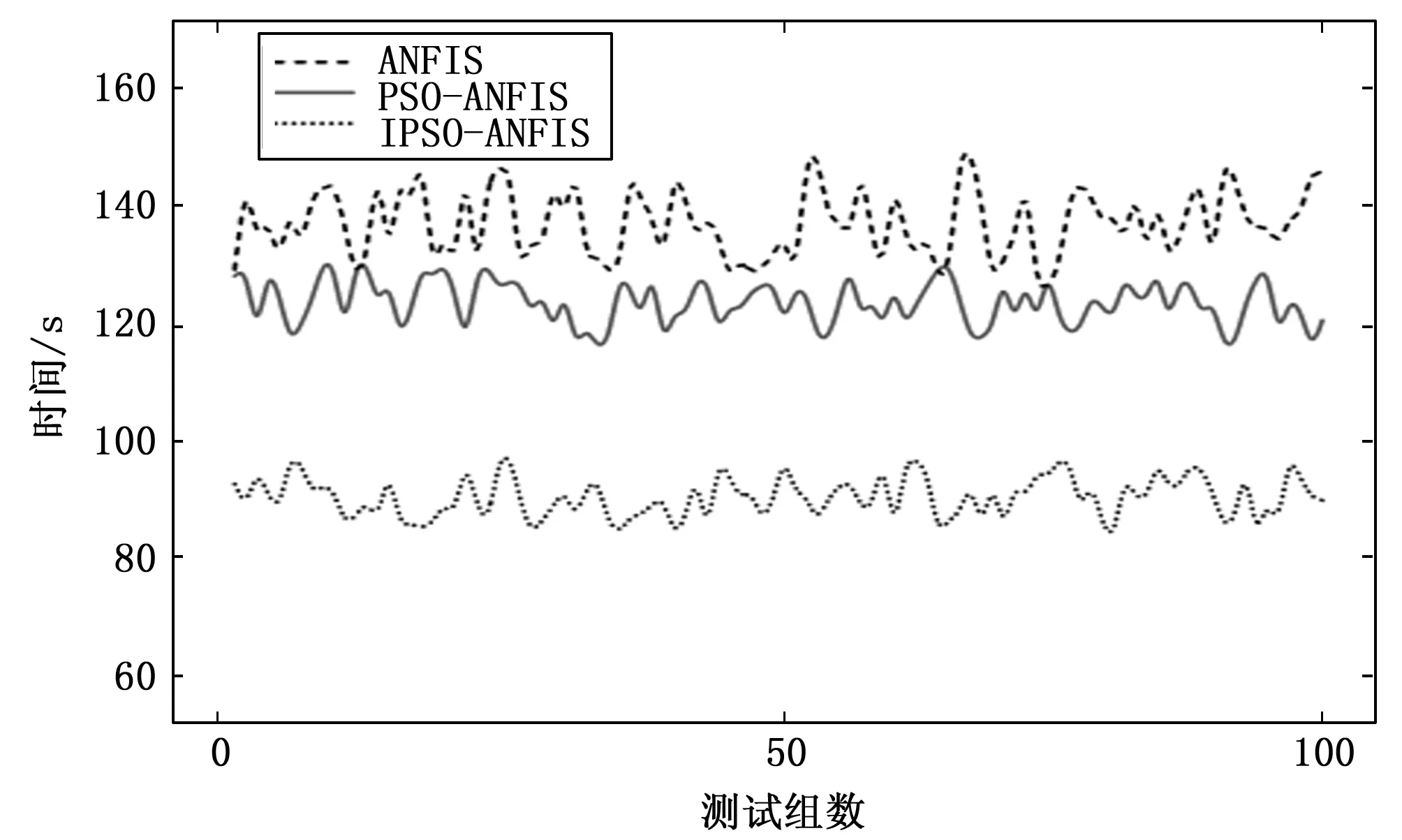
图3 网络仿真耗时对比图

图4 ANFIS最优故障诊断分类图

图5 PSO-ANFIS最优故障诊断分类图
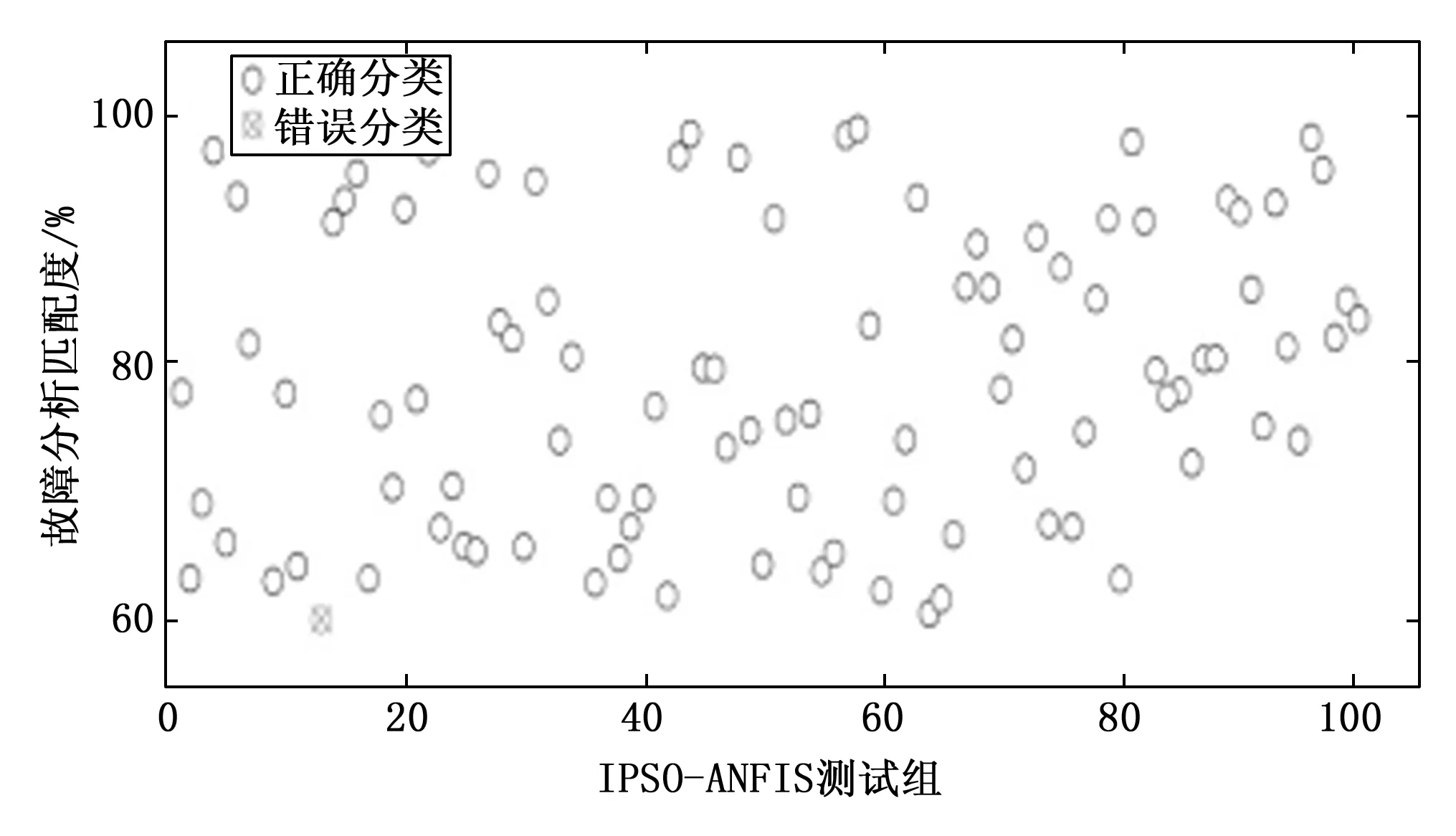
图6 IPSO-ANFIS最优故障诊断分类图
综合以上仿真结果,可作如下分析:
1)根据表2的数据可知,IPSO算法引入收敛域和欧式距离判别雷同粒子,对雷同粒子赋予随机参数,使粒子后期跳出可局部最优位置,增强了种群的多样性,降低了故障诊断的误差率,同时提高算法找到更优解的可能性。为了提高算法的收敛性和精度,迭代过程中对惯性权重进行动态调整,并令学习因子进行线性变化,这样粒子在迭代初期能进行较好的全局搜索,而到迭代后期则能更加精确的进行局部搜索。对惯性权重和学习因子的公式改进,减少了模型诊断的耗时,提高了算法的搜索能力。
2)根据表3和表4的数据可知,在优化ANFIS网络的前提参数时,需要结合理论依据和人工经验,经过反复测试,才能找出合适的参数值。标准PSO算法虽然在一定程度上解决了最优前提参数匹配的问题,但其存在迭代效率低和易于陷入局部最优的缺点。而IPSO优化网络参数训练故障样本诊断的最优正确率约为98%,优化网络的耗时较短,诊断的故障分析匹配度高于另外两种标准网络。
3)IPSO算法在最优故障诊断分类的识别效果明显优于标准PSO,所以在油浸式变压器故障诊断方面,基于IPSO优化T-S型ANFIS网络诊断故障样本具有较好地运行效率与精度。
5 结束语
本文提出了一种改进的粒子群算法,它能够有效地解决自适应模糊神经网络参数寻优能力较弱、收敛速度较慢以及粒子群后期容易陷入局部最优等问题,该算法结合了动态惯性权重和学习因子线性调整策略,并引入收敛域和欧式距离判别雷同粒子,以增加种群的多样性,让粒子群可以更快地跳出局部最优,从而较好地提高了算法的全局搜索能力与收敛速度。采取参数调整,可以有效避免陷入局部最优,提高了变压器故障诊断的精度及效率,对变压器及电力系统的安全稳定运行有重要的现实意义,同时也为其它相关领域提供了一种新的优化方法和思路。因此,IPSO算法在ANFIS网络参数优化方面具有明显优势,特别是在故障样本诊断方面的应用效果非常显著。然而,要注意IPSO算法中的参数设置问题和不同问题领域中的适用性问题。未来研究可以探索更先进的优化算法,进一步提高网络的诊断准确性和鲁棒性。
