基于上下文感知并面向多样性的API 推荐
2023-10-27赖宝强赵瑞莲郭俊霞
赖宝强 李 征 赵瑞莲 郭俊霞
(北京化工大学信息科学与技术学院 北京 100029)
基于软件复用和模块化开发的原则,现代软件系统的开发通常需要使用外部库.开发者基于一些基础库、第三方库或者一些常用框架,能够快速地构建编程环境、实现编程任务、提高开发效率.有研究表明[1],在超过5 000 个软件项目的研究中,45%的应用程序编程接口(application programming interface,API)是直接从第三方库导入的.
因此,在软件开发过程中,开发者常常面临API使用问题.在不熟悉的编程任务面前,开发者可能不知道使用哪些API 能对编程任务更有帮助.除此之外,如果缺乏相关的编程经验,开发者也可能不了解一些API 的具体使用方法.在这些情况下,开发者可能会查阅官方帮助文档,或者通过代码开源平台和相关论坛查询、搜索代码示例,从而学习API 的使用.然而当前很多官方文档存在质量问题[2-3],且通常只提供API 的描述信息而不提供代码示例[4].利用一些非正式的平台或者论坛进行检索和学习也会面临许多障碍[5],并且这些返回的搜索结果可能是错误的、不完整的[6].开发者需要花大量时间去筛选和测试才能找到自己需要的API 及其使用示例.
近年来,研究者们提出了各种方法为开发者推荐合适的API 及其使用模式,从而促进开发者对API的学习和使用.API 使用的模式推荐方法通常是从大型代码库中挖掘API 的使用模式,然后通过有显式或者无显式的查询匹配这些使用模式[7],最终推荐符合条件的API 元素或者代码片段.
API 使用模式推荐的关键是API 的预测与推荐.主要有基于序列模式挖掘的方法、基于自然语言处理的方法以及基于机器学习的方法.基于序列模式挖掘的方法主要是利用序列模式挖掘算法挖掘API调用序列[8-10],根据API 使用频率进行预测,但是得到的模式通常包含很多重复子序列和无关子项,造成结果的冗余,即存在模式爆炸问题[11].此后有研究人员提出使用图结构来表示API 调用序列[12],并利用NGram 语言模型思想计算子图的生成概率,从而预测对应的API.但是当上下文信息变得复杂时,子图的生成效率变低,也容易出现长距离依赖问题.有研究人员提出基于神经网络的方法来解决自然语言处理的长依赖问题.例如利用深度学习模型RNN 学习API 调用序列[13-14],从而预测下一步API 出现的概率.也有利用图深度学习模型GCN 融合拓扑信息和API文本属性[15]学习图结构的表示,从而预测潜在的API.这些方法主要利用API 上下文结构信息学习API 的特征表示,然而API 之间细粒度的关系表示还不够充分,导致难以区分API 之间的差异性.
文献[8-15]方法在基于上下文的API 推荐场景中,以当前正在编写程序的项目或者方法中的API调用信息作为上下文,然后利用上下文的结构信息或语义信息对API 进行预测.利用结构信息的方法通常结合API 调用序列或者上下文结构进行分析,然后基于API 使用频率对候选API 进行预测.利用语义信息的方法主要对上下文的语义特征进行分析,然后根据候选API 与上下文的语义相似性进行预测,最后根据候选API 预测值大小进行排序推荐.然而这些方法形成的推荐列表,由于上下文信息考虑不充分,会导致推荐列表中冗余项和同质化内容的出现,影响推荐性能.主要有3 种情况出现:
1)基于API 序列结构的方法通常只考虑API 之间的调用关系,导致一些与上下文语义不相关的API也被预测和推荐.例如,假定API 元素A,B,C能够组成2 组序列模式L1=(A,B)和L2=(A,C),结合上下文的API 调用序列进行预测,当推荐A时,根据使用频率,B,C也将被预测成为候选API.如果L1与上下文语义相关,那么C为冗余项.当冗余项变得越来越多时,一些使用频率较高但与上下文语义无关的API因为预测值大而排在推荐列表前面,推荐性能受到影响.
2)基于上下文结构的方法通常会考虑上下文的语义关系而不考虑API 之间的调用关系,导致推荐结果容易出现模式冗余.例如,由1)中2 组序列模式L1=(A,B)和L2=(A,C)可知,如果L1和L2都与上下文语义相关,那么将同时推荐L1和L2组成的API 使用模式.由于B,C不是有效的使用关系,同时推荐B,C容易造成模式冗余,其中,C为模式L1的冗余项,B为模式L2的冗余项.这种情况造成一些不存在使用关系的API 作为使用模式被推荐在列表中也会影响推荐性能.
3)当前基于语义信息的推荐方法通常考虑的是项目与API 或者方法与API 的语义关系,缺乏API 之间细粒度关系的考量.当推荐列表中存在能够实现相同功能的API 时,且这些API 之间具有类似的属性,那么API 之间差异性小,由于不区分API 之间的差异性,容易造成部分结果同质化.当一些具有类似属性的同质化API 也被推荐系统考虑而占用了推荐列表位置时,会影响推荐性能.
针对这3 种情况,本文从不同粒度考虑API 的使用关系,充分利用上下文结构和语义信息,对现有不同粒度的研究方法进行改进,使它们能够利用更多的特征信息,得到更好的推荐结果;然后再对这些方法推荐的相关结果配以关联性分析结果后进行重排,减少推荐列表中前排冗余项和同质项,从而增加推荐列表中有效API 的比例,提高推荐准确率和平均精度.本文以图模型为对象,提出一种基于上下文感知并面向多样性的API 推荐方法,(context-aware based API recommendation with diversity,CAPIRD).
本文的主要贡献有4 点:
1)提出一种名为AHC (GAPI hierarchy call graph)的API 层次调用图模型,从不同粒度上表示API 的上下文关系,为相关性和关联性的分析服务;
2)基于AHCG 模型分别构造项目上下文和方法上下文的协同信号,进而感知相似的API 上下文,缩小候选API 的范围,减少上下文冗余项的出现,并度量相关性;
3)基于AHCG 模型构建API 关联图,考虑细粒度的API 结构关系,挖掘已选API 的关联模式,减少模式冗余项的产生,并度量关联性;
4)提出一种相关性与关联性的线性组合算法,并从标准模式中学习最佳权重组合,对候选API 进行重排推荐,降低推荐列表中同质化API 出现的可能性,提高推荐结果的准确率.
1 相关工作
研究人员提出了许多API 推荐方法和工具,来帮助开发者搜索和学习API 的使用.根据API 推荐场景,目前主要有2 类方式,即有显式查询推荐和无显式查询的推荐[7].
1.1 有显式查询的API 推荐
有显式查询方法主要是根据关键字或者自然语言显式地表达开发者的意图,然后进行代码或API的搜索,最终推荐相关的API 使用模式.例如,RACK[16],NLP2API[17]通过自然语言查询Stack Overflow 上Q&A中的API 使用知识.DeepAPI[14]将用户查询作为源语言,API 调用序列作为目标语言,利用RNN 编码-解码器模型解决问题.CODEnn[18]将自然语言描述和代码片段嵌入到高维的向量空间,使用户可以通过自然语言查询相关的代码片段.BIKER[19]融合Stack Overflow 上的Q&A 和API 文档来弥补自然语言和代码之间的词法和知识代沟.SSAPIR[20]将API 描述信息和查询信息构建为同一向量空间模型,利用TF-IDF算法计算向量空间中每个词袋的语义特征,然后基于语义相似度匹配API 使用模式.GeAPI[21]使用图嵌入技术学习API 图的语义表示,根据用户查询返回相似的子图.PreMA[22]提取了API 文档中的功能性词汇用于计算用户查询和功能语句的相似性.BRAID[23]利用开发者的反馈信息,通过主动学习和学习排序(LTR)技术,使得推荐结果更稳定.
1.2 无显式查询的API 推荐
无显式查询方法主要是从API 上下文中研究开发者的编程意图,从而挖掘或者预测相关的API 信息.一些经典的工具如MAPO[8],UPMiner[9],PAM[10],分别通过序列挖掘算法、聚类算法和EM 算法挖掘API 调用序列并用于API 推荐.文献[24]通过将API使用对象和共现关系构建为关系网,将网络中相似对象的使用作为相似API 使用模式.SALAD[25]使用隐马尔可夫模型学习API 调用序列,从而根据上下文中的API 调用序列预测下一步候选API 被使用的概率.FOCUS[26]将客户端方法视为用户,将API 调用视为物品,利用协同过滤算法推荐相似的API 使用模式.HiRec[27]通过分析API 调用之间的层次结构,利用层次推理模型预测可能匹配的API.APIRec-CST[28]利用门控图神经网络(GG-NNs)学习结构信息的向量表示,利用序列神经网络(如LSTM)学习文本信息的向量表示,连接GG-NNs 和LSTM,然后对目标Hole 位置的API 进行预测.GAPI[15]融合API 调用的结构信息和API 的文本属性,利用图学习技术从API的调用关系中捕捉高阶协同信号,从而发现与API上下文相似的候选API.
2 相关定义
API 使用模式推荐示意如图1 所示,假设开发者编写到光标处时遇到API 使用问题,不知道调用哪些API 或者怎么使用这些API 才能完成当前客户端方法myWork 中的剩余编程任务.记开发者编程现场的上下文信息为Q.相关定义为:

Fig.1 Illustration of API usage patterns recommendation图1 API 使用模式推荐示意图
定义1.实体.表示遇到API 使用问题时所涉及的研究对象,有3 种,即项目实体、方法实体和API 实体.
开发人员在编程环境中正在编写的项目称为活动项目,正在编写的客户端方法称为活动方法,活动方法所在项目即为活动项目.
定义2.上下文信息.用来刻画某状态下的实体关系和属性信息,用四元组Q=(E,V,R,T)来表示.其中,E表示上下文中所研究的实体;V表示上下文中实体的属性;R表示实体间的关系;T表示时间,反映某一时刻编程现场的上下文信息.
定义3.上下文相关性.表示上下文信息与API存在逻辑关系,定义为R1={(Q,i)|sim1(Q,i)≥λ1,i∈Ei}.其中,Q表示上下文信息,i表示API 实体,Ei表示API实体集合,λ1表示阈值,sim1表示逻辑推断函数.
定义4.API 关联性.表示API 之间的逻辑联系,通过API 实体之间的共同使用关系或属性信息标识,其定义为R2={(mi,mj)|sim2(mi,mj)≥λ2,mi,mj∈Ei},R2表示API 实体mi和mj具有相似的使用关系或语义信息,mi和mj存在关联性.其中,Ei表示API 实体集合,λ2表示阈值,sim2表示相似性函数.
定义5.API 层次调用图(API hierarchy call graph,AHCG).定义GAHCG={V,E},其中节点集合V有3 种类型的节点,包括项目、方法和API;边集合E表示项目和方法,以及方法和API 之间的层次关系.项目节点包括语料库项目和客户端项目;方法节点表示项目中定义的方法声明;API 节点表示方法中的API 调用,其包括内置API 调用、第三方API 调用和本地方法调用.
3 面向多样性的API 推荐框架
基于开发者活动项目的上下文信息,本文提出CAPIRD,整体框架如图2 所示.CAPIRD 模型主要由4 个模块组成:元数据结构提取模块、相关性分析模块、关联性分析模块和重排推荐模块.元数据结构提取模块主要是从项目源码库中提取项目、方法与API 的层次结构,并基于这些信息构建AHCG 图;相关性分析模块主要从项目和方法粒度上,计算上下文的特征表示,然后基于特征相似性感知相似的上下文,进而推断与上下文相关API,并度量相关性;关联性分析模块从API 的粒度上,构建API 之间的细粒度使用关系,然后从中挖掘频繁使用模式作为API关联图以获得更充分的API 结构关系,并从图中度量关联性;API 多样性重排从多样性角度将相关性和关联性进行线性组合,提升推荐性能.

Fig.2 The overall framework of CAPIRD图2 CAPIRD 的整体框架
3.1 AHCG 图模型构建
AHCG 图用来表达API 与项目和方法之间的层次关系,从而能够更好地利用元数据集中API 的结构信息对客户端项目进行建模,并从不同粒度上表达API 在项目中的结构特性.
利用静态分析工具解析每个项目的类文件信息,将提取的方法名称、方法参数、方法体、API 名称、API 参数作为元数据集.对于给定项目元数据集,AHCG 图的构建过程为:
1)确定图的项目节点集合P.确定元数据集中涉及的项目文件,并对不同项目进行编号,添加到P中.
2)确定方法节点集合U,以及项目和方法的关系边E1.从项目起始编号开始,获取项目所有类中定义的方法声明,然后对这些方法进行编号,添加到U中,最后再建立该项目和方法的关系边.例如,项目p解析后提取了方法u,那么p和u存在一条边,即e1=(p,u),e1∈E1.
3)确定API 节点集合I,以及方法和API 的关系边E2.从方法起始编号开始,依次提取方法中涉及的API 调用.然后判断该API 是否存在,不存在,则添加新的API 节点编号到I中;否则从I中取出已存在的API 节点编号.最后建立方法和API 的关系边.例如方法u中提取了API 节点i,那么u和i存在一条边,即e2=(u,i),e2∈E2.
根据1)~3)步骤构建的结果示例如图3 所示,节点Pi(i=0,1,2,3)表示项目节点,节点Uj(j=0,1,…,4)表示方法节点,节点Ik(k=1,2,…,7)表示API 节点,关系边E1和E2都表示层次关系.E1表示P到U这一类边的集合,E2表示U到I这一类边的集合.
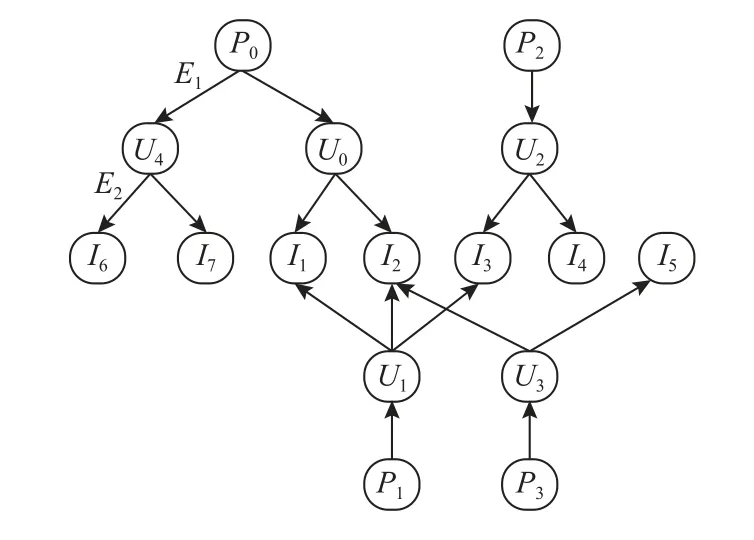
Fig.3 Illustration of AHCG model construction图3 AHCG 模型构建示意
3.2 相关性分析
相关性分析模块主要是基于上下文相似性对API进行预测,并尽可能减少冗余项的出现.上下文信息的分析包括活动项目上下文和活动方法上下文的分析.
2 个项目的相似性可由项目特征项的集合进行计算[29],因此可以根据活动项目上下文的特征集合感知相似的项目集合,从而缩小候选API 搜索范围.此外,为了给活动方法提供相关的API 使用建议,还需要研究活动方法上下文的API 使用信息.
基于AHCG 的图模型可知,项目节点和方法节点这2 类节点包含的API 使用信息规模不同,因此针对这2 类节点的上下文信息,分别使用不同的特征提取方法提取特征.然后从相似项目集合中计算活动方法与目标API 的相似性.
3.2.1 基于项目上下文的特征提取
项目上下文反映项目中的API 使用情况,本文通过评估不同项目中API 的被使用情况反映项目上下文的特征,利用TF-IDF 算法进行计算.其中,特征TF表示API 在当前项目中的使用频率,特征IDF反映API 在整个项目源码库中的普遍性.
从AHCG 中的项目节点开始,通过层次遍历能够得到API 节点集合.给定项目的API 节点集合p={i1,i2,…,in},API 节点ik的特征TF计算如式(1)所示:
其中n表示集合p中API 节点的数量,表示API 节点ik的出现次数.
API 节点ik的特征IDF计算如式(2)所示:
其中|P|表示AHCG中项目节点的数量,表示AHCG中使用了ik的项目节点数量.
在整个项目源码库的体系下,API 节点ik在项目p中的被使用情况的计算公式为
给定项目集合p,那么p的特征可以用API 被使用情况的向量表示,即ϕp=
3.2.2 基于方法上下文的特征提取
方法上下文反映了方法中的API 使用情况,同时以方法为单位的程序在一定程度上隐含了代码的语义信息,因此考虑方法和API 的文本属性应该能够增强上下文的语义表示.图卷积神经网络(GCN)[30]利用图结构信息和节点属性信息,能够学习图的特征表示.本文利用GCN 进行方法上下文的特征提取,其网络结构主要由3 部分组成:输入层、图卷积层和输出层.
1)输入层.AHCG 图的结构信息、节点初始化特征表示为e0,如式(4)所示.
其中x代表节点文本属性信息,Θin是编码函数Encode(·)待学习的参数,e0是编码后的节点向量表示,分为方法u节点表示和APIi节点表示.
2)图卷积层.其主要目的是聚合邻居节点的协同信号,从而实现消息传递.主要任务是协同信号的获取和节点向量的更新.
协同信号的获取公式为
根据聚合函数的消息传递机制,AHCG 中节点最新的特征表示通过与邻居节点的聚合更新得到,如式(6)所示:
其中聚合函数f(·)使用ReLU 函数实现.
3)输出层.其获得方法节点u和API 节点i的最终特征表示如式(7)所示.通过线性转换层输出k层卷积层的节点表示,然后对API 节点进行预测.
其中连接函数concat(·)将每一层节点的特征表示顺序连接.
3.2.3 相关性度量
相关性度量的主要目的是根据上下文提取的不同粒度特征对目标API 进行预测,预测值越大,则API 与上下文越相关.因此,定义函数context(·)作为相似性度量的计算方法,从而适应不同粒度的研究方法.输入是上下文信息Q和目标APIi,返回值是Q与i的相关性,如式(8)所示:
若Q是项目上下文信息,context(·)采用缺失评分算法[31]实现API 的预测并返回预测结果;若Q是方法上下文信息,根据式(7)中方法节点u和API 节点i的向量内积进行预测,即
3.3 关联性分析
关联性分析模块的主要目的是从相似上下文中获取API 关联信息,并分别从结构和语义上分析API之间的相似性.从另一个角度看,相似API 可以反映相似的上下文[32],因此相似的上下文中有可能隐含相似API.本文基于活动方法上下文和AHCG 图模型构建API 关联图,增强细粒度的API 结构表征,并从中挖掘API 的关联模式;再基于关联模式,分别从结构关系和语义信息上度量API 之间的关联强度.
基于AHCG 图模型,API 关联性分析模块的分析对象是方法节点和API 节点.
3.3.1 关系构建
基于方法特征的向量表示,利用余弦相似性计算活动方法与其他方法的相似性,将相似性值大于0 的方法作为相似方法.将这些相似方法中使用的API 作为节点、共现关系作为边,构建API 关联图.如图4 左图所示,节点I 表示API,边表示2 个API 在方法中具有共同使用关系,边权重表示2 个API 在方法中的共现次数.为了挖掘目标API 在相似上下文中的关联程度,本文基于AHCG 图模型将关联关系保存在图数据库中,如式(9)所示:

Fig.4 Illustration of subgraph mining for associated target nodes图4 关联目标节点的子图挖掘示意图
其中Ui为AHCG 中第i个相似的方法节点,表示节点Ui构建的API 关联图,和分别表示Ui中的API 节点和共现关系构成的边.
3.3.2 关联模式挖掘
基于AHCG 图模型,本文将API 之间关联关系的发现转化为频繁子图的挖掘.为了避免图匹配过程的子图同构问题[33]和挖掘的模式出现冗余问题,本文锁定目标节点避免子图任意扩展,将挖掘的关联模式覆盖在目标节点关联的子图上避免冗余输出,进而提出关联目标节点的子图挖掘方法.首先将目标节点作为初始节点,基于AGM 算法[34]思想,通过添加新节点产生候选子图,为防止候选子图任意扩展,对目标节点的高阶邻居节点进行剪枝,使挖掘的子图作为目标节点关联的子图.记录目标节点关联新节点的2 阶子图的支持度,丢弃支持度不符合条件的候选2 阶子图,针对图4(a)关联图的挖掘结果如图4 右图所示.
具体的关联目标节点的子图挖掘算法如算法1所示,主要有4 个步骤:
1)首先设定支持度阈值,然后从相似的数据集合中构建关联图数据库,将不同的API 节点进行编号;
2)在目标节点上添加新节点进行子图扩展,对目标节点的高阶邻居进行剪枝,只保留与目标节点有直接关联关系的目标子图;
3)计算目标节点与新节点构成的2 阶子图的支持度,将未达到阈值的子图丢弃;
4)将满足条件的2 阶子图添加到目标子图上,当所有节点都被访问时,生成最终的关联目标节点的子图d(i),其中i表示目标API 节点.
最终,API 关联子图d中包含了API 之间各种可能的使用模式,可以为开发者展示更多可能性.
算法1.关联目标节点的子图挖掘算法.
输入:上下文信息Q,API 节点i,支持度minsup;
输出:节点i关联的子图Gi.
3.3.3 关联性度量
关联性度量的主要目的是度量2 个API 之间的相似性,分别从结构关系和语义关系上进行度量.关联性越强,说明2 个API 相似的可能性越大.本文定义函数correlation(·)作为关联性度量的计算方法,从而融合不同类型关系表示的研究方法.输入是2 个API 节点i和j,返回值是i和j的关联性,如式(10)所示:
若度量API 的结构关系,correlation(·)计算节点i与j的权重系数,由节点i和j的2 阶子图的支持度与图数据库数量的比值得出;若度量API 的语义关系,利用图嵌入技术[15]将图d中i节点的特征表示zi和节点j的特征表示zj进行内积,从而计算2 个节点的语义相似性,即
3.4 API 多样性重排推荐
API 多样性重排推荐的目的是优化有效API 在推荐列表中的排名,减少冗余项和同质化内容的产生,使得推荐结果在保障推荐性能的前提下具有更好的多样性.
根据最大边缘相关(MMR)算法[35]的思想,通过结合查询内容的相关性和推荐内容的新颖性能够增加推荐结果的多样性.新颖性反映了推荐内容之间的差异性程度,若推荐内容之间差异性小容易造成内容同质化,即相同结构关系或功能属性的API 同时被推荐.适当调整一些同质化内容在推荐列表中的排名,能够改变推荐内容的多样性.
本文在保持上下文相关性的同时,协调推荐内容之间的差异性来增加推荐结果的多样性.推荐内容之间的差异性可以通过API 之间的关联性进行度量,调整相关性和关联性权重能够使推荐列表展示更多可能的情况.因此,重排推荐的目标是找到合适的平衡参数,从而降低推荐列表中同质化内容出现的可能性,提升有效API 被推荐的可能性.相关性分析模块和关联性分析模块分别度量了上下文与API之间的相关性和与API 的关联性.利用式(11)之间将相关性和关联性进行线性组合来度量每个API 被推荐的可能性:
其中Q表示上下文信息,R表示候选API 集合,S表示R中已被选择的API 集合,RS表示R中未被选择的API 集合;1用于上下文信息和API 之间相关性的度量,用于API 之间关联性的度量,参数 λ用来度量sim1和sim2的权重.
根据式(11),当参数 λ=1 时,MMR表示标准的相关性API 推荐结果;当参数 λ=0 时,MMR表示最大的多样性推荐结果.这些API 推荐结果是一种线性组合,本文利用算法2 所示方法从标准模式的训练数据集中获取能够平衡相关性和关联性的最佳参数.
算法2.Top-N参数优化算法.
输入:上下文信息Q,API 候选集合R;
输出:Top-N(N=1,5,10,15,20)的最佳参数topNLambdas.
给定训练数据集,首先计算相关性条件下的性能指标,并以该指标作为该训练集的基准.然后结合API 多样性重排算法计算不同参数下Top-N的评价指标,迭代计算每一次参数采样的评分,选择评分最优时Top-N取得的参数作为该数据集的最佳参数.
4 实验与结果
为了验证所提API 推荐方法的有效性,本文使用真实的软件项目模拟开发者的编程场景,并在3个不同的数据集上进行实验验证,且与方法FOCUS和GAPI 进行对比实验.
本文实验的硬件和系统环境为Intel Xeon Gold 6148 处理器、256.0 GB RAM、Nvidia V100 GPU 的Linux 64 位服务器;Intel®CoreTMi7-10700 2.90 GHz 处理器、16.0 GB RAM 的Windows 10 64 位操作系统;使用的软件环境有JDK 1.8,Python3,PyTorch 等.
4.1 数据集
本文采用文献[26]中所使用的开源数据集,其中数据集SHL 是从Github 软件遗产存储库中任意提取的610 个Java 项目;数据集SHS 是在SHL 中筛选出的200 个最小项目;数据集MV 是从Maven 中央仓库中提取的1 600 个JAR 项目,且不同版本的同一JAR 项目只保留其中一个版本.
基于原始数据集,首先解析项目源码库构建元数据集,并从中构建AHCG 模型,提取初始特征.表1详细统计了上述3 个数据集的相关信息,包括用于上下文模型输入的项目特征和方法特征.其中项目特征指每个项目中API 的TF-IDF 特征,由于每个项目的API 不同,本文统计了每个项目平均调用的API数作为该数据集的平均项目特征数.方法特征采用文献[15]的方法,利用驼峰式拆分法将方法名称和API 名称拆分为单词序列并作为节点的文本属性,这些单词在相同的向量空间中进行编码和对齐,方法节点的特征维度与单词数有关,因此统计数据集中不同单词数作为方法特征数.

Table 1 Meta Datasets Statistics for Experiments表1 实验元数据集统计数据
4.2 实验设置
为了评价本文方法的有效性并与其他方法形成对比,遵循前人的研究方法对实验进行离线评估.实验将软件项目中的部分代码抽取出来,从而模拟开发者编程现场及API 上下文的使用情况.具体规则是:将项目节点P下的方法节点U按照编号顺序排成数组,然后按照不同比例划分为训练集和测试集.测试集中每个方法节点下的API 节点按照编号顺序排成数组,然后保留前4 个API 节点来模拟开发者已完成的代码,剩余的API 节点作为该测试方法的标准数据,用以验证在当前开发情景下的推荐性能.本文使用10 折交叉验证法,将数据集划分成10 份.每一份进行1 轮训练与验证,并且每一轮验证的时候,将其中9 份数据作为训练集,1 份作为测试集.最后取这10 轮测试结果的平均值作为该数据集的最终实验结果.
4.3 评价指标
API 使用模式推荐场景中,一般通过Top-N的API排名情况评价推荐结果的有效性.本文使用成功率(S@k),精确度(P@k),召回率(R@k)和平均精度(MAP)来评价方法在Top-N上的推荐性能.给定测试集合M,其中的测试项表示方法节点,用来模拟当开发者遇到API 使用问题时,给该方法节点对应的方法声明提供API 使用建议,推荐列表中将包含开发者接下来可能调用的API.设RECk(q)表示本文CAPIRD模型在一个测试项q中输出Top-N的API 推荐结果集合,GT(q)表示一个测试项q的标准API 集合.
S@k反映测试集预测成功的比例.
其中count表示满足条件的测试项数量.
P@k反映在推荐列表中有效API 的占有比例.
R@k反映推荐列表中有效API 的数量在标准列表中的比例.
MAP的计算公式为
4.4 基线方法
为了更好地评价本文方法,设计了2 个对比实验,分别与相同场景下的2 个基线方法进行比较.
1)FOCUS.FOCUS 发表于2019 年,是近3 年高被引用的方法.FOCUS 基于项目上下文,使用协同过滤技术挖掘并推荐API 使用模式.它将方法声明视为用户,将API 调用视为物品.因此,FOCUS 能够推荐相似项目中类似的API 使用模式,从而缩小搜索范围,减少冗余.
2)GAPI.GAPI 发表于2021 年,是目前公开文献中在相同实验数据集下实验效果最好的方法.GAPI是一种基于方法上下文和GNN 技术的API 使用模式推荐方法.它利用项目中方法与API 的交互关系,融合API 文本属性,从拓扑网络上学习API 的Embedding 表示,从而给相似的方法推荐相似的API使用模式.
4.5 实验结果分析
从推荐性能和多样性表现2 个方面进行实验设计,针对提出的2 个研究问题,依次进行实验验证与分析.
问题1:本文CAPIRD 模型在API 推荐性能上表现如何.
为了检验CAPIRD 在API 推荐上的效果,本文在3 个数据集上分别比较Top-N推荐结果在不同指标上的性能表现.实验前,对比实验设置了相同的实验环境;实验时,针对不同类型上下文的基线方法FOCUS 和GAPI,在CAPIRD 相关性分析中实现不同类型基线方法的相关性计算,计算结果作为基线各自的相关性分析结果,并将该结果作为后续重排模块的参数优化基准.然后再融合CAPIRD 方法的关联性推荐和重排推荐,最终将推荐结果分别记为CAPIRD-FOCUS 和CAPIRD-GAPI.根据最终结果验证CAPIRD 融合基线方法在API 多样性推荐上的有效性.在3 个数据集上S@k和MAP的实验结果分别如表2~4 所示.
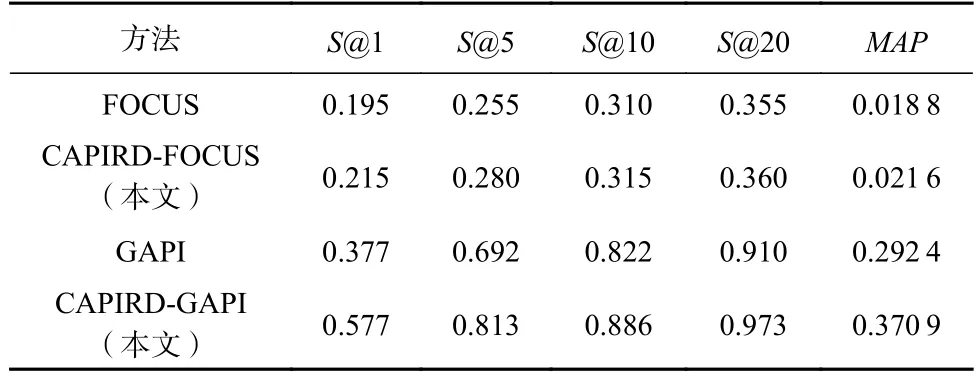
Table 2 Comparison Result of S@k and MAP on SHS Data Set表2 SHS 数据集上S@k 和MAP 对比结果
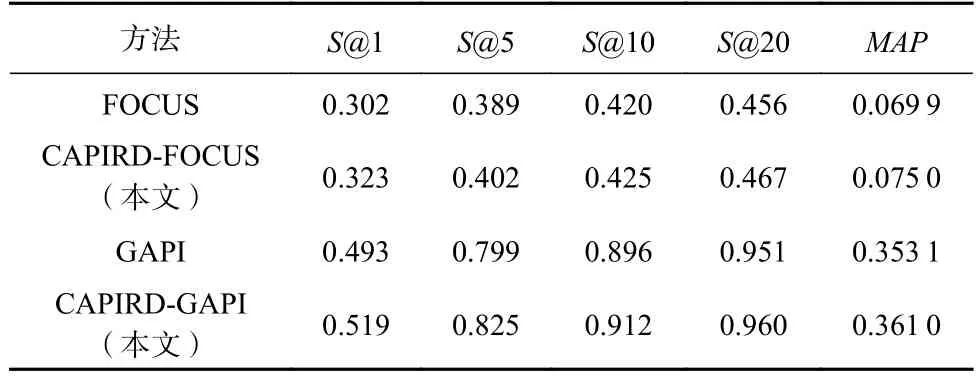
Table 3 Comparison Results of S@k and MAP on SHL Data Set表3 SHL 数据集上S@k 和MAP 对比结果
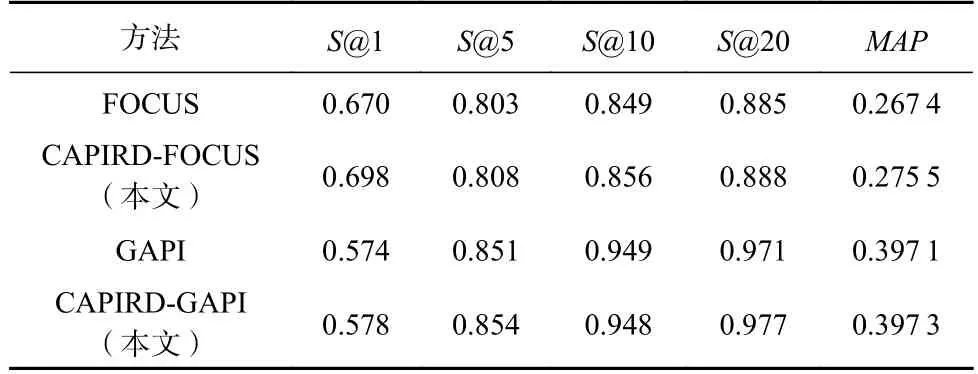
Table 4 Comparison Results of S@k and MAP on MV Data Set表4 MV 数据集上S@k 和MAP 对比结果
由表2~4 结果中的MAP指标可以看出,CAPIRD 在MAP的表现明显优于基线方法.尤其是在SHS 数据集上,在GAPI 方法的基础上融合本文方法后,MAP由0.292 4 提升至0.370 9,其推荐的平均精度提升约27%,在S@1 上由0.377 提升至0.577,提升了约53%.而在数据集MV 上相对来说并不太显著,尤其是在以图学习模型为基础的GAPI 上MAP及S@k 上提升相对较小.这是因为随着数据量的增加,图学习机制作用显著,能够捕捉更多高阶协同信号,使得API 推荐的多样性也增加.而融合本文方法依然有小幅度提升,说明CAPIRD 依然能够在保持原有多样性推荐结果的基础上,通过增加候选结果的差异性,使得推荐性能较原推荐性能有所提升.在以传统协同过滤算法为基础的FOCUS 上融合CAPIRD 后的MAP提升在3%~15%,在大数据集上相对稳定.因此,在3 类不同的数据集上,本文CAPIRD 模型在MAP指标上都得到了有效提升.
在实际的开发场景中,假设开发人员遇到API使用问题,当系统为其提供合适的API 推荐列表时,那么开发人员更希望列表中靠前的API 是对其有帮助的.为了体现CAPIRD 模型在这种场景中的推荐性能优势,需要分析S@1 和S@5,同时结合S@20 的成功率和MAP,分析模型的有效性.
由表2~4 所示,CAPIRD 模型在S@1 和S@5 相比S@20 具有显著效果.在S@1 上,CAPIRD 模型在所有数据集上平均提升约13%,说明第1 个推荐的API 与上下文最相关且又能够区别于其他已使用的API,因此也更可能是开发者在当前编程场景下想使用的API.S@5 在所有数据集上平均提升约6%,其中CAPIRD 在SHS 数据集和基线方法GAPI 比,S@5 由0.692 提升到0.813,提升约17.5%.
在S@20 上,所有数据集相差不大,平均提升仅约2%,说明在Top-20 推荐列表中,CAPIRD 模型推荐的API 与基线方法推荐的API 差异不大,而结合CAPIRD 改变了原有推荐结果的排序,在所有数据集的MAP指标上平均提升约9%.说明Top-20 推荐列表中有效API 的排名得到提升,达到本文多样性重排推荐的预期.因此,CAPIRD 模型在API 使用模式推荐场景中能够有效提高S@k,同时提高有效API在推荐列表中的排名.
问题2:CAPIRD 模型中决定相关性和关联性推荐所占比重的参数对结果的影响如何.
在API 多样性重排模块,本文利用MMR 算法将相关性和关联性进行线性组合.以方法CAPIRD-FOCUS为例,当参数λ=1时,方法CAPIRD-FOCUS 与基线方法FOCUS 的结果是一样的,因为此时关联性度量的权重为0.实验通过调整参数 λ,使得关联度的权重发生变化,观察在不同参数 λ下模型的表现能力.采用等间距的控制重排采样样本调节参数 λ,观察MAP在不同参数 λ下的影响.MAP在不同数据集上的变化趋势如图5~7 所示.
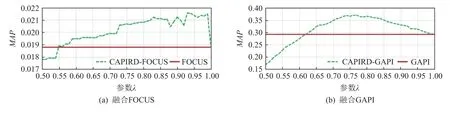
Fig.5 The changes of MAP on SHS data set图5 MAP 在SHS 数据集上的变化
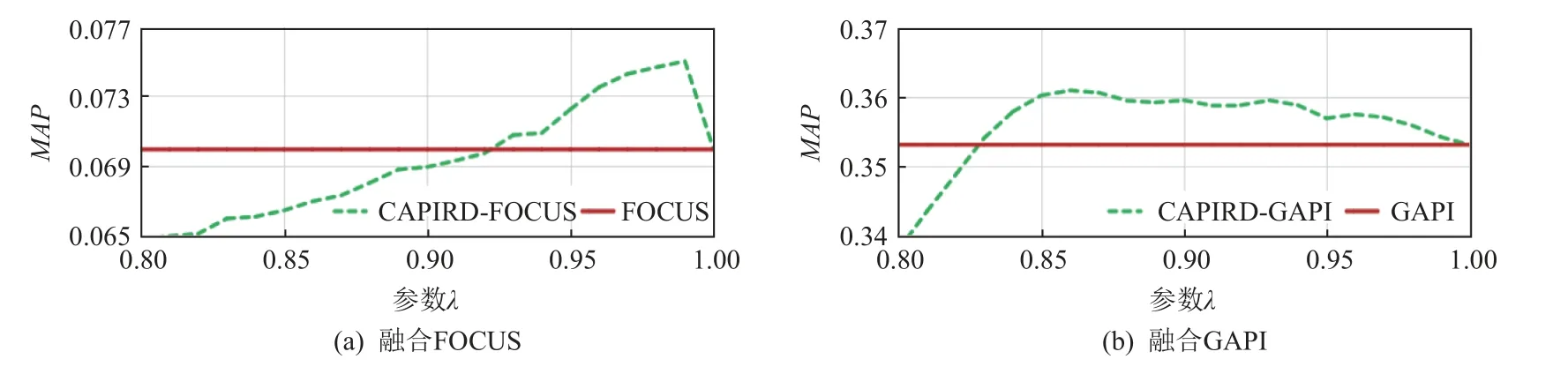
Fig.6 The changes of MAP on SHL data set图6 MAP 在SHL 数据集上的变化
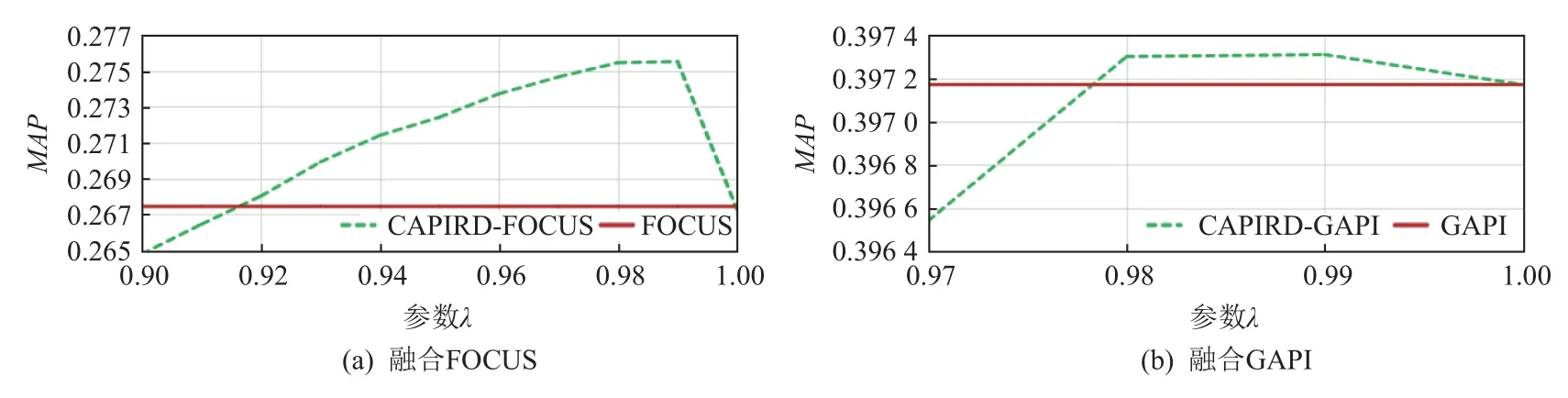
Fig.7 The changes of MAP on MV data set图7 MAP 在MV 数据集上的变化
图5~7 中,横轴表示参数 λ的取值,纵轴表示该数据集上的MAP.实线表示基线方法,由于不需要进行重排,因此基线的曲线不发生变化.虚线表示增加重排后的结果,在3 个不同数据集上其对应曲线都发生了变化.
图5~7 中,虚线对应曲线整体上都表现出了类似的变化趋势,即随着 λ的增大,对应的MAP值整体呈现先增后减的趋势.虚线对应曲线位于实线对应曲线上方的部分表示增加重排后的MAP优于基线方法的MAP.由图5~7 中的6 个曲线图可以看出,MAP在这个部分能够达到某个峰值,该峰值对应λ的值为该样本空间内的最佳参数.例如在图5(b)的曲线图中,λ取值在0.7~0.8 之间时,MAP的值达到峰值.说明 λ在该区间内,关联性的度量发挥了最大作用.
当 λ发生变化即关联性的权重发生变化,MAP也发生变化,说明推荐列表中候选API 的排名也发生了变化.进一步观察3 类数据集最佳参数的取值,发现随着测试集数据量的增加,达到最佳参数的取值越接近1,说明数据量越大,要达到MAP最优时的关联性权重越小.这是由于数据量变大时,API 之间关联性的差异性变小,使得MAP提升的表现并不明显,但是推荐结果仍发生变化.
综合以上分析,本文提出的CAPIRD 模型,能够通过关联性分析增加候选API 的多样性,同时也能够保证推荐结果的有效性,提高推荐性能.
5 结论
本文为了提高API 推荐性能,提出了基于上下文感知并面向多样性的API 推荐方法CAPIRD.CAPIRD 是一种结合上下文相关性和API 关联性的推荐方法.通过相关性分析,发现上下文相关API,然后度量相关性值;通过关联性分析,挖掘API 的关联模式,发现与目标API 关联的其他API,然后度量关联性值;最后利用MMR 算法线性组合相关性和关联性,协调纯相关API 与纯关联API 的比重,增加候选API 中的差异性,提高推荐性能.
采用3 个数据集进行验证实验,在与2 个基线方法的对比实验中,CAPIRD 在MAP,S@1,S@5 都有提升,其中在MAP的平均提升率约为9%,S@1 的平均提升率约13%.实验结果充分表明,CAPIRD 在API使用模式推荐场景中具有更好的表现.
CAPIRD 利用的上下文信息有限,如何更充分地利用上下文信息来推断开发者的编程意图,是未来工作需要探索和思考的.
作者贡献声明:赖宝强负责论文方法的设计与实现,并撰写论文;李征负责论文整体结构的审核;赵瑞莲负责论文的指导与校对;郭俊霞提供方法和实验指导,并修改和审核论文.
