基于内在动机的深度强化学习探索方法综述
2023-10-27曾俊杰徐浩添尹全军
曾俊杰 秦 龙 徐浩添 张 琪 胡 越 尹全军
(国防科技大学系统工程学院 长沙 410073)
强化学习(reinforcement learning,RL)是监督学习、无监督学习之外的另一机器学习范式,通过设置反映目标任务的奖励函数,驱动智能体在与环境的交互与试错中学习能使累计收益最大化的策略[1].强化学习一般采用马尔可夫决策过程(Markov decision process,MDP)进行问题形式化描述.MDP 可表示为五元组M=(S,A,P,R,γ),其中S表示一个有限的状态集合;A表示一个有限的动作集合;P:S×A→PS表示状态转移分布,即P(s,a)为智能体在状态s∈S下采取动作a∈A的后继状态的概率分布;R:S×A→PR表示奖励分布,即R(s,a)为智能体在状态s下采取动作a能够获得的奖励值的概率分布;γ ∈[0,1]为折扣因子.
初始时,智能体处于按照某种规则设定的初始状态s0∈S,然后采取动作a0将环境状态转移至s1~P(s0,a0),并获得即时奖励r0~R(s0,a0).按此步骤,循环往复.强化学习智能体的目标是学习一个策略π:S→PA,表示从状态到动作概率的映射.在该策略下定义的价值函数为Vπ(st),动作价值函数为Qπ(st,at),其中st∈S和at∈A为时刻t下的状态和动作.价值函数公式为
其中期望值E在P和R的概率分布下计算得到.所有可行策略中的最优策略记为
在最优策略下的价值函数为最优价值函数,记为
深度强化学习(deep reinforcement learning,DRL)是在强化学习提供的最优决策能力的基础上,结合深度学习(deep learning,DL)强大的高维数据表征能力来拟合价值函数或策略,进而基于交互样本训练得到最优价值函数或最优策略,被认为是结合感知智能和认知智能的有效方法.
深度强化学习在游戏人工智能、机器人、自然语言处理、金融等诸多领域取得了超越人类的性能表现[2-3],但在具备稀疏奖励、随机噪声等特性的环境中,难以通过随机探索方法获得包含有效奖励信息的状态动作样本,导致训练过程效率低下甚至无法学习到有效策略[4].具体来说,一方面现实应用中往往存在大量奖励信号十分稀疏甚至没有奖励的场景.智能体在这类场景探索时需要执行一系列特定的动作,以到达少数特定的状态来获得奖励信号,这使得在初始时缺乏所处环境知识的智能体很难收集到有意义的奖励信号来进行学习.例如,多自由度机械臂在执行移动物体任务中,需要通过系列复杂的位姿控制将物体抓取并放置到指定位置,才能获得奖励.另一方面,现实环境往往具有高度随机性,存在意料之外的无关环境要素(如白噪声等),大大降低了智能体的探索效率,使其难以构建准确的环境模型来学习有效策略.例如,部署应用在商场的服务机器人在执行视觉导航任务时,既要受到商场中大量的动态广告图片或视频的传感干扰,又可能面临动作执行器与环境交互时的结果不确定性,同时长距离的导航任务也使其难以获得有效正奖励信号.因此深度强化学习领域亟需解决探索困难问题,这对提高DRL 的策略性能和训练效率都十分重要.
针对奖励稀疏、随机噪声等引起的探索困难问题,研究者们提出了基于目标、不确定性度量、模仿学习等的探索方法,但对任务指标的提升效果有限,并增加了额外的数据获取的代价.近年来,源自心理学的内在动机(intrinsic motivation)概念因对人类发育过程的合理解释,逐渐被广泛应用在DRL 的奖励设计中以解决探索问题,成为了ICML,ICLR,NeurIPS,ICRA 等顶级学术会议上的热点方向,受到来自清华、斯坦福、牛津、谷歌等顶级高校与研究机构的关注.虽然已有文献[5-8]介绍内在动机在深度强化学习领域的研究现状,但据我们所知,尚没有文献全面深入研究各类基于内在动机的DRL 探索方法,并逐步深入讨论其应用于贴近真实世界的复杂动态场景中所面临的关键问题以及未来的发展方向.我们从出发点、研究角度分析了相关综述文献与本文的主要区别,如表1 所示.

Table 1 Similarities and Differences of Our Paper Compared with Published Related Papers表1 本文与已发表相关论文的异同
基于上文梳理的深度强化学习面临的探索困难问题,本文首先介绍3 种经典探索方法以及它们在高维或连续场景下的局限性,接着全面梳理3 类不同的基于内在动机的DRL 探索方法的基本原理、优势和缺陷,随后介绍上述基于内在动机的方法在不同领域的应用情况,最后总结亟需解决的关键问题以及发展方向.
1 经典探索方法
为提高智能体在未知环境中的探索效率,研究者们提出了简单的随机扰动方法,例如 ε-贪婪方法.除此之外,研究者们在小规模状态动作空间下提出了许多具有理论保证的经典探索方法,并推导出对应的累计后悔值或样本复杂度的理论上界.根据统计学中认识世界不确定性的观点,本文将它们分为频率派方法与贝叶斯派方法.
1.1 随机扰动方法
随机扰动方法可按照加入噪声的位置差异分为2 类: 一是在动作选择的过程中增加随机性或噪声,如在ε-贪婪算法中,以1-ε的概率选择当前估值最高的动作,以 ε的概率在所有动作中随机选择.在此基础上,Boltzmann 策略在学习初期设置较大的 ε值以促进探索,使 ε值随学习过程逐渐减小,当策略收敛后完全利用当前模型以持续获得最大奖励.类似地,深度确定性策略梯度算法[9]对策略网络输出的动作加入随机噪声过程进行扰动,以此增加探索.二是在拟合策略的网络参数上加入噪声,比如参数空间噪声模型[10]和NoisyNet 模型[11]等.
1.2 频率派方法
频率派基于实际数据样本的估计来衡量状态的不确定性,在数据量有限的情况下一般采用带有置信水平的区间估计方法.以随机多臂赌博机(multiarm bandit,MAB)问题为例[12],假设某赌博机有K∈N+条垂臂,每次可拉下其中1 条i∈{1,2,…,K},即动作at∈{1,2,…,K}.每条垂壁对应的奖励值符合概率分布ri~Ri,期望为ui,基于当前样本的均值为ui.记当前总步数为T,nt(a)为到时刻t为止动作a被选中的次数,因此有=T.根据大数定理,有=u(a).又根据Hoeffding 集中不等式,u(a)所在的区间的置信度为,如式(4)所示:
据此提出的UCB 算法按照“面对不确定性的乐观”(optimism in the face of uncertainty,OFU)哲学[13],在时刻t遵循原则选择动作:
除MAB 问题外,大量研究成果将带有置信水平的区间估计作为工具扩展到不同的MDP 场景中,推导出不同的值函数更新策略以及对应的样本复杂度.例如,MBIE-EB(model-based interval estimationexploration bonus)[14]在回合制MDP 的背景下,通过推导状态动作对奖励值和状态转移向量的上置信界,提出在状态动作值更新公式中加入探索奖励:
其中 β是该算法的输入,是一个常量,n(s,a)是对状态动作对(s,a)的已访问次数.
此外,依托基于模型的RL 方法有UCRL2[15]和UCBVI[16]等基于UCB 的探索方法,依托无模型的RL方法包括UCB-H 和UCB-B 等[17].
1.3 贝叶斯派方法
贝叶斯学派观点认为,面对未知环境人们维护着对于所有可能模型的概率分布以表达其不确定性,随着观测证据的增多,后验分布一般比先验分布更能反映不同备选模型与真实模型的接近程度.由于在选择动作时不仅依据观测状态,也必须考虑对信念状态的更新,贝叶斯强化学习方法被认为有助于提高探索效率,防止陷入局部最优,且同时考虑利用现有策略最大化累积收益[18].其在无折扣MDP 下对应的贝尔曼最优方程为
其中s和s′为前状态与后继状态,b和b′为前信念状态与后继信念状态,H表示从s开始接下来H个步长.然而,信念状态的数量与观测状态和动作数量成指数关系,难以用值迭代等方法精确计算得到最优贝叶斯策略.为此,研究者们设计了许多近似或采样方法以在多项式步数内得到贝叶斯意义上的次优策略.例如,基于启发式贝叶斯的BEB(Bayesian exploration bonus)[18]算法,通过在式(7)对应的更新公式右侧加入探索奖励:
贝叶斯方法中另一类经典方法是汤普森采样框架[19],它以状态转移概率等系统参数的先验概率分布为起始,通过迭代逐步接近真实的模型参数.在此框架基础上,研究者们提出了各种利用采样方法近似求解贝叶斯MDP 模型的方法[20-21].
1.4 小结
随机扰动方法缺少对具体状态和动作探索作用的评估,难以依据对状态的某种度量引导探索过程,因此无法形成有启发性的探索过程,也被称为无指导探索[22].频率派方法或贝叶斯派方法,大多仅是在小规模场景中推导出了样本复杂度或期望后悔值的上界,具有一定理论保证,但很难直接应用到更加复杂的环境如具有动态性和不确定性的实际场景.例如MEIB-EB[14]和BEB[18]算法都需要对状态动作对有准确的计数,在小规模的状态和动作空间条件下是可行的,但无法应用于动态、高维或连续场景中,亟需启发性更强、计算效率更高的探索方法.
2 基于内在动机的深度强化学习探索方法
为解决大规模状态动作空间中由稀疏奖励、随机噪声干扰等产生的探索困难问题,研究者们提出了基于目标、不确定性度量和内在动机等深度强化学习探索方法[7-8].基于目标探索的方法通过对兴趣状态进行分析来生成探索性子目标,同时对如何到达子目标的过程进行控制,以提高智能体在复杂环境中的探索效率.这类方法偏规划,重点在于存储状态和轨迹信息,并根据存储的信息规划生成子目标点,然后学习如何到达子目标点.基于不确定性度量的方法通常采用价值函数的贝叶斯后验来显示建模认知不确定性,或者采用分布式价值函数来额外评估环境内在不确定性,以鼓励智能体探索具有高度认知不确定性的状态动作对,并尽量避免访问具有高度内在不确定性的区域.该方法更多偏向于挖掘价值函数中的不确定性,体现的是计算思维.
与基于目标探索的方法和基于不确定性度量的方法相比,本文所关注的基于内在动机的方法从行为学和心理学中内在动机驱动高等生物自主探索未知环境的机理出发,将“新颖性”等多种源自内在动机的启发式概念形式化为内在奖励信号,以驱动智能体自主高效探索环境,体现的是一种更抽象和拟人的思维.具体来说,内在动机源于高等生物在追求提高自主性和能力或掌控力的过程中获得的愉悦感,是驱动无外界刺激条件下探索未知环境的动力.内在动机在DRL 中,可以被映射为内在奖励信号[23],与基于值函数或策略梯度的深度强化学习方法相结合,形成具备强启发性的探索策略,以提高智能体探索复杂未知环境的效率.
如何在内在奖励信号中形式化“新颖性”“好奇心”“学习提升”“多样性”“控制力”等源自内在动机的启发式概念,是设计基于内在动机的DRL 探索方法的关键内容.根据内在奖励信号的不同启发式来源并参考文献[24]中设想的各类基于内在动机的计算框架,本文将基于内在动机的深度强化学习探索方法主要分为3 类: 基于计数的方法、基于知识的方法和基于能力的方法,如图1 所示.
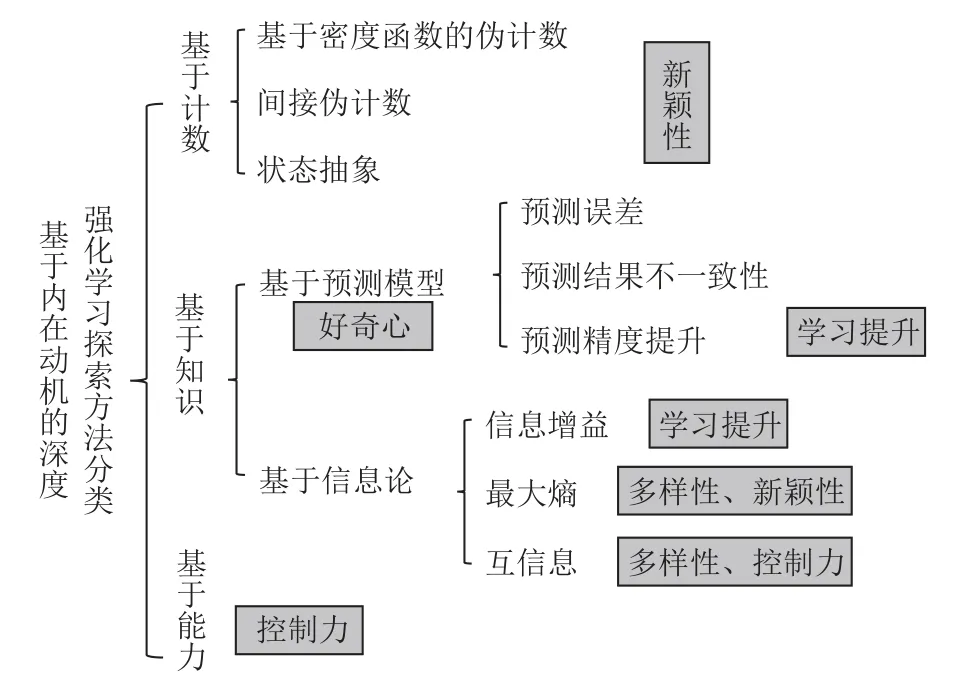
Fig.1 Method classification of exploration approaches in deep reinforcement learning based on intrinsic motivation图1 基于内在动机的深度强化学习探索方法分类
2.1 内在动机的背景
为便于深入理解基于内在动机的DRL 探索方法构建的强启发性探索策略,本节从行为学和心理学的角度阐述了内在动机的概念和功能.
2.1.1 概念
内在动机是源自行为学和心理学的概念,对它的发现和讨论最早见于1950 年Harlow[25]对于猕猴在无任何外界奖励条件下数小时乐此不疲地解决特制机械谜题现象的解释.类似现象的不断发生打破了此前动机理论或驱动力理论的观点,即所有行为都是受生理需求(如饥渴、疼痛、性需求)的直接驱动[26].此后数十年间,心理学家、神经生物学家等对内在动机的机理和功能的研究持续不断[27-28].
总体上说,内在动机来自人们对各类能够提供新颖性、惊奇、好奇心或挑战的活动的最自然的兴趣[29].在进行这类活动时,大脑能够感受到动态的愉悦、兴奋或满足感,驱使人们关注过程本身(例如探索未知环境、了解未知知识、掌握新技能等过程),而非关注外界的奖惩信号.从技能学习角度出发,有研究人员认为对认知的挑战在一定限度内(既不过分困难又不过于容易),学习提升明显的探索任务是最能激发大脑兴趣的场景[30].此外,设定符合发育心理学观点的难度和复杂度递增的学习进程,能够稳步推进对多元化技能和知识的掌握,从而有效提升探索未知环境的效率和能力[31].总而言之,内在动机的本质可以理解为大脑对实现自主性和提高能力或掌控力的追求[32].
2.1.2 功能
内在动机有别于以外在奖励的形式为人们所熟知的外在动机(extrinsic motivation).从进化意义上来说,2 种动机驱动的行为都能够提高生物体对环境的适应能力、增加存活和繁殖的概率,但却具有各自不同的实现途径[33].外在动机以身体恢复内稳态为目标,通过生物体与外部环境的交互来学习特定的策略,以增强个体对外界动态环境的适应力.因此外在动机产生的学习信号强弱与内稳态需求紧密相关.内在动机产生的信号则来源于大脑神经信号,通常不与身体的内稳态、特定任务目标直接相关,会促使生物体在探索环境的过程中获取更丰富的知识,提升自身技能水平,以产生和掌握有助于完成外界任务的复杂长序列行为[34].因此内在动机信号的强弱与获得知识或提升技能的过程密切相关.
2.2 常用测试环境
本节梳理了基于内在动机的DRL 探索方法的常用测试基准环境,以方便比较各类探索方法的性能表现:
1)Atari 街机游戏集[35]①https://github.com/mgbellemare/Arcade-Learning-Environment.该游戏集中共57 个游戏,其中有7 个奖励非常稀疏、探索难度较高的游戏(Atari hard exploration games,Atari-HEG),其包括Atari-MR(Atari Montezuma’s Revenge)和Atari-FW(Atari Freeway)等,如图2(a)(c)所示.
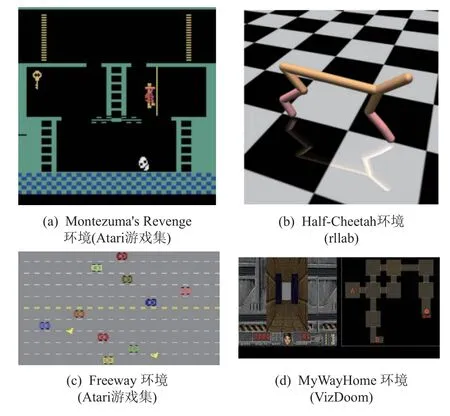
Fig.2 Examples of common test environments图2 常用测试环境示例
2)多自由度的连续控制任务环境rllab[36]②https://github.com/rllab/rllab.该环境包括基本任务(如Pendulum)和多类型的运动控制(如Swimmer,Ant,Half-Cheetah 等),见图2(b).
3)游戏Doom 的3 维仿真环境VizDoom[37]③https://github.com/mwydmuch/ViZDoom.高维的图像输入、部分可观的场景以及结构复杂的迷宫环境,如Doom-MWH(Doom MyWayHome),见图2(d).一般要求在初始环境未知条件下,进行探索或目标驱动的导航.
4)OpenAI Gym[38]①https://gym.openai.com.OpenAI 开发的工具箱,集成了包括Atari、棋类游戏、采用MuJoCo 物理引擎的rllab 任务和Doom 等,并设计了公共接口.
2.3 基于计数的方法
在高维连续环境中,难以采用表格化的方式来表示状态,并且几乎没有任何2 个观测状态完全相同,绝大多数状态的真实访问次数都不会超过1 次,直接采用经典探索理论方法中基于频率派或贝叶斯派的方法,得到的计数值无法有效衡量状态新颖性.针对上述问题,基于计数的方法一方面借鉴了UCB算法的思路,继承了“面对不确定性的乐观”思想,即向访问次数较少的状态或状态动作对赋予更高的奖励,以鼓励智能体尽快探索状态空间的未知部分;另一方面采用基于相似性的状态泛化的解决思路.该类方法的实现途径包括伪计数方法[39]和状态抽象方法[40],其中伪计数方法可细分为基于密度模型的伪计数和间接伪计数方法.
2.3.1 基于密度模型的伪计数方法
由于在高维或连续环境条件下无法对状态或状态动作对的出现次数进行准确计量,那么一个自然的思路便是寻找具有类似性质的变量以代替真实计数.具有开创性和奠基性的工作是Bellemare 等人[39]发表于2016 年的基于密度模型的伪计数(pseudocount,PC)算法.它隐性地利用了状态间的相似性,若当前状态与此前出现过的其他状态较为相似,则将其赋予相近计数值,从而一定程度实现了邻近状态间的泛化,并避免了统计真实次数的需要.其中用到的上下文树切换(context tree switching,CTS)的密度模型[41-42],其本质是生成式模型.式(9)(10)(11)简要说明了PC 的计算过程:
加入额外探索奖励的改进DDQN(double deep qnetwork)[43]算法在探索难度巨大的Atari-MR 游戏中,将分数从此前算法的基本0 分提高到了均值超过3 000分,成为一大突破.该算法可将基于计数的探索方法泛化到大规模状态空间,且存在理论上最优性保证,然而其采用的CTS 模型在可解释性、可扩展性和数据高效性方面受限.
为解决CTS 模型面临的问题,Ostrovski 等人[44]采用基于PixelCNN(pixel convolutional neural networks)[45]的卷积神经网络密度模型替换CTS 模型.PixelCNN估计的计数更为准确和更具可解释性,且提高了训练速度和稳定性.在Atari-MR 场景中,与PC 算法相比,PixelCNN 的预测收益更加平滑,在新颖事件出现时才会给予更强烈的信号,使其得分达到了6 600 分.
然而,PixelCNN 和PC 这2 种算法都是在原始状态空间上构建密度模型来估计计数,对于未访问过的高维复杂状态的泛化性较差.针对此问题,Martin等人[46]提出的 φ-EB(φ-exploration bonus)算法在基于原始状态空间编码得到的特征空间上构建密度函数,提高了训练数据的利用率,增强了在大规模状态空间的泛化性.
总之,这类伪计数方法通过密度模型在一定程度上实现了邻近状态间的计数值泛化,并基于OFU设计额外探索奖励,可有效应对大规模状态空间中的探索困难问题,但是当观察数据更为复杂时,比如VizDoom[37]中以自我为中心的图像观察,会导致其依赖的生成式模型的训练非常困难.
2.3.2 间接伪计数方法
与基于密度模型的伪计数方法不同,间接伪计数方法无需构建状态或观察的生成式模型,可通过设计相关的变量或模型,来间接估计状态或状态动作对的真实访问次数,然后在此基础上设计内在奖励,以启发智能体在复杂环境下进行探索.
例如,UC Berkeley 的Fu 等人[47]提出的EX2(exploration with exemplar models)算法通过训练模板模型作为分类器,输出当前状态与此前访问的各个状态的差异程度以衡量状态的新颖性,并推导出这一输出与状态访问次数间的关系.该算法的优点是不需要依赖密度模型等生成式或预测模型,可以有效应对观察或状态更为复杂的环境,然而其模板模型在训练过程中遇到过拟合和欠拟合问题时,仅能通过手动调节超参数来缓解.基于这一隐式计数的内在奖励,该算法在更为复杂的Doom-MWH 任务的性能表现明显优于其他基于生成式模型的方法.
Choshen 等人[48]提出了DORA(directed outreaching reinforcement action-selection)算法,提出了探索价值(E-value)的概念,可作为泛化的计数器来估计访问次数.类似于动作价值函数的定义,状态动作对(s,a)的探索价值,不仅代表在(s,a)处值得探索的知识,还应反映(s,a)的后续状态序列蕴含的潜在知识.因此,DORA 模仿Q-learning 的状态动作值更新方式设定了E-value 的更新规则.该算法设计的探索价值不仅考虑了当前状态的不确定性,还考虑了后续状态的不确定性,可以更精确地估计访问次数.DORA 算法在Atari-FW 游戏中取得了30 左右的均分,是基于CTS密度模型的伪计数方法[39]得分的2 倍.
Machado 等人[49]受后继表示(successor representation,SR)对环境结构的表达能力的启发[50],采用SR范数的倒数作为内在奖励来鼓励探索.该算法无需依赖任务领域相关知识(如密度模型等)来估计状态计数,对于进一步研究表征学习与探索之间的联系有较好的启发作用.与CTS[39]和PixcelCNN[44]密度模型的伪计数方法相比,该算法在Atari-MR 等探索困难的场景中,取得了性能相当的效果.
总之,间接伪计数方法无需依赖观察或状态的生成式模型,可借鉴其他领域的思想来灵活设计相关变量与模型对状态的真实计数进行估计,大大提高了伪计数方法的泛化性以及处理复杂高维观察的能力,进一步扩展了伪计数方法的应用范围.
2.3.3 基于状态抽象的计数方法
针对大规模或连续状态空间中难以采用真实计数获得启发信息的问题,基于密度模型和间接的伪计数方法采用伪计数方式来估计访问次数,但计数值的估计在绝大多数的情况下存在一定偏差,会影响由此计算得到的内在奖励的准确性.与这2 类方法相比,基于状态抽象的计数方法采用抽象状态的方式压缩状态空间来避免或降低伪计数的偏差.其核心是相似性度量[51],使得在状态转移关系中相近的具体状态可以获得相似的抽象表示[52].
例如,UC Berkeley 的Tang 等人[53]提出#Exploration算法运用Hash 函数将高维状态映射到整数空间,即φ:S→Z,再定义探索奖励为.为在Hash 码上将差异明显的状态区分开,该算法采用局部敏感Hash 中的SimHash 技术,用角距离度量状态间的相似度[54].此外还提出了基于自编码器(autoencoder,AE)学习的AE-SimHash,以适应特征提取较困难的高维状态环境.该算法采用Hash 函数离散化状态空间的方法,可有效解决高维连续状态空间中的状态计数问题,但是其严重依赖Hash 函数的选择来确保合适的离散化粒度.
为解决抽象状态仅依赖观测相似性而忽视了任务相关特征的问题,Choi 等人[40]提出了CoEX(contingency-aware exploration)算法.该算法借鉴了认知科学中常用的概念contingency awareness[55],即大脑在发育过程中逐渐能够意识到自身行为在周围环境中能够产生影响的部分,从而构建了可解释性强的状态抽象模型——注意动力学模型(attentive dynamics model,ADM).该模型主要采用3 类信息构成具体状态的表示 ψ(st),如式(13)所示:
其中:αt表示整个可观区域中智能体的可控部分,一般用2 维坐标表示;c(st)表示在Atari-MR 等游戏中不同房间的标识,与 αt构成了2 层的空间位置表示;表示当前的累积外在奖励,被用于提供智能体行为的上下文.CoEX 算法得到的抽象状态更关注于环境中可控动力学信息,使得智能体能够获取自身位置等任务特征信息.得益于合理的抽象状态表示,在Atari-MR 游戏中,该算法结合PPO(proximal policy optimization)[56]算法,通过20 亿帧的训练,取得了超过11 000 分的成绩,但是其未能有效抽象环境中不可控元素的动力学信息.
受contingency awareness 思想和图像分割方法启发,Song 等人[57]提出了Mega-Reward 算法,认为抽象状态的关键在于提取环境中实体控制特征信息.文献[57]将环境中实体的控制区分为直接控制和隐式控制,前者可直接采用ADM[40]进行抽象,后者需要关系转移模型来建立其与前者的联系.该算法对不同控制力进行量化学习与加权求和得到累计的控制力,并以其数值的时间差分作为内在奖励.虽然该算法与ADM[40]提供了新的状态抽象思路,但 αt等抽象特征都与Atari 游戏全局可观的像素环境紧密相关,通用性较为有限.
2.3.4 小结
表2 简要总结了本节介绍的主要方法.尽管基于计数的方法不仅有较强的理论保证(如MEIB-EB[14]和BEB[18]等),并且能有效扩展到高维环境中(如PC[39],AE-SimHash[53]等),但其对探索效率的作用依赖于一个基本假设,即状态访问次数的增加必然能提升模型估计的确定性.这一假设在静态环境中能够一定程度被满足,但在动态变化的场景或状态/动作空间层次性较强的场景中,访问次数与模型估计精度之间很难具有明确关系[62].因此仅采用基于计数值或蕴含计数信息的变量的函数作为内在奖励,在面对动态场景或动作空间层次性较强的场景时,其探索效率将显著降低.另一方面,这类方法均衡对待所有的状态或区域,忽略了它们在引导探索进程或积累模型知识方面潜在的差异性,这种一致性可能导致计算资源分配的不合理以及影响下游任务完成的效果[6].此外,O’Donoghue 等人[63]指出基于OFU 原则对MDP 进行区间估计可能导致上置信界过分乐观的累计效应,从而影响探索效率.
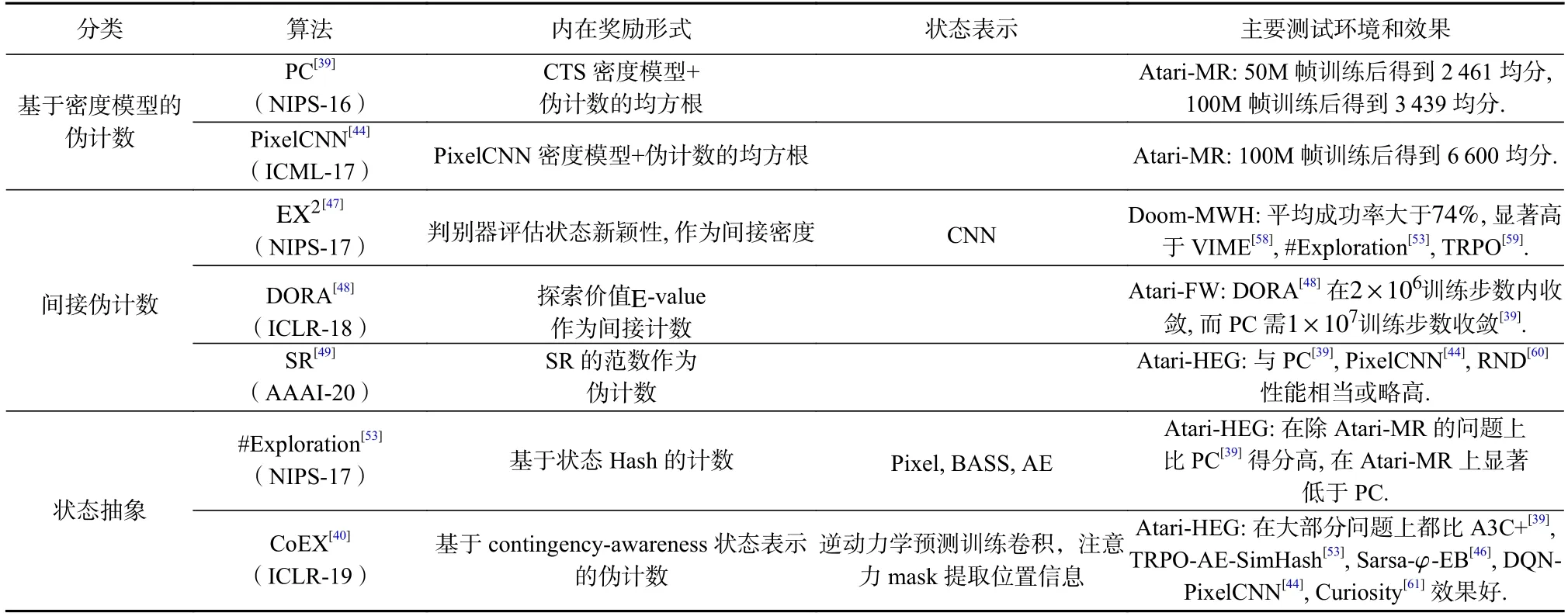
Table 2 Summary of Main Methods Based on Count表2 基于计数的主要方法小结
2.4 基于知识的方法
第2 大类方法认为人们自主探索的一大动力来自于降低外部环境的不确定性[64].人在发育过程中逐渐形成对于环境运行的知识,大脑因此对未来的观测状态存在自上而下的期望,当未来状态与该期望差异明显时,“好奇心”“惊奇”“学习提升”“多样化”等启发性信息将会驱使个体对这一现象进行探究.这种认知现象在自适应共振[65]和内在动机[33]等理论中都有描述.照此不断修正自我认知的DRL 探索方法,称为基于知识的方法[24],大致可以分为基于预测模型[66]和基于信息论的方法.
2.4.1 基于预测模型的方法
现有大量方法为智能体建立和维护一个对动作结果和状态转移进行预测的模型,以模型精度表达外部环境的不确定性.以此预测模型为基础,智能体根据某些新颖性或可预测性的衡量指标学习价值函数或策略.依据产生内在奖励指标的不同,基于预测模型的方法可以分为基于预测误差、预测结果不一致性和预测精度提升的方法.
1)预测误差
早在DRL 成为研究热点之前,基于预测误差的强化学习方法就已受到关注[23,67-68].预测误差是指预测模型的输出与预测对象的真实取值之间的差别,用来形式化“惊奇”“好奇心”等概念,也被称为对抗式好奇心[69].这类方法在预测对象是可学习的、确定性的或带有同质噪声的情况下,学习效率较高[70].然而,在更实际或复杂的场景中,它们容易被环境中的不可控成分(如白噪声)严重影响,而陷入局部状态空间中,导致探索进程受阻.因此这类方法的研究重点在于预测模型的建构(包括对状态的表示和/或对动力学的预测)能否有效反映与探索相关的观测信息.
较早期的工作包括Stadie 等人[71]2015 年提出的模块化框架: 对观测状态进行特征提取 σ:S→Rd,再为智能体建立动力学预测模型 M:σ(S)×A→σ(S).σ(st)由自编码器的隐藏层提供,σ′(st+1)=M(σ(st),at)则由全连接网络训练得到,而内在奖励则是预测误差的函数.虽然该算法实现了构建正向动力学预测模型,以预测误差的形式提供内在奖励,但是其编码器易受来自环境的随机噪声干扰,且在部分Atari 游戏上相对Boltzmann 策略、Thompson 采样和DQN(deep q-network)[72]的优势比较有限.
除正向的动力学预测模型外,Pathak 等人[61]为去除状态表示中与智能体动作无关的随机部分,设计逆动力学模型aˆt=g(ϕ(st),ϕ(st+1);θI)从状态转移中预测动作.其中,ϕ 为状态表示函数,θI为逆动力学模型的网络参数.此模型与正向模型at;θF)联合,以自监督学习方式进行训练,同时以状态预测误差的2 范数平方为内在奖励训练智能体的动作策略.内在奖励生成模型称为ICM(intrinsic curiosity module)算法.在稀疏奖励下的VizDoom[37]环境的导航、空间探索任务下ICM 算法的均分是当时的SOTA 算法VIME[58]的2 倍以上.ICM 算法依靠逆动力学模型可以在一定程度上缓解白噪声问题,但是其仅考虑动作的即时效果,无法解决长周期决策中动作效果延时的问题.
与ICM 算法类似,Kim 等人[73]提出的EMI(exploration with mutual information)算法除构建正向动力学预测模型外,也构建了相似的动作预测模型,但其在状态和动作的嵌入向量基础上人为施加线性的动力学约束和误差.此外,EMI 算法将嵌入特征和动力学模型的学习与内在奖励的生成分离,规避了ICM 算法中逆动力学特征(inverse dynamics features,IDF)预测误差不稳定的问题[61].在探索难度较大的Atari 游戏和机器人控制任务中EMI 算法取得了相较EX2[47],ICM[61],AE-SimHash[53]等方法更优或可比的结果,但是无法有效应对长周期决策问题.
为探究不同的状态特征提取方法和不同测试环境对基于动力学模型的ICM 效果的影响,Burda 等人[74]将像素级特征(pixels)、权重随机初始化后固定其权重的网络的输出特征向量、变分自编码器(variational autoencoders,VAE)[75]和ICM 算法的IDF分别作为ICM 算法中的ϕ(st).在不同类型的54 个测试场景的实验结果表明,利用Pixels 特征难以学到有效的预测模型,基于VAE 的好奇心模块则表现不稳定;但意想不到的是,RF 则在所有环境中取得了与IDF 相当的表现,但其在向未见过的新环境泛化时不如IDF.上述结果说明,即使随机的特征提取也能较好地用于表征状态间的差异,从而表达出环境信息的不确定性.另外,当面对状态转移随机性较强的环境(如存在noisy TV 等白噪声干扰)时,RF 和IDF 的学习效率都受到剧烈影响.
相对IDF 特征,随机网络输出的特征是确定的,不随训练过程而改变,因此能够提供更稳定的预测误差.基于这一观察,Burda 等人[60]提出非动力学的预测误差形式化算法,即预测对象并非状态转移,而是状态的嵌入式特征向量.预测目标产生于随机初始化且权重固定的神经网络f:S→Rk,预测信号则来自于同结构的预测网络fˆ :S→Rk,其训练目标是均方误差的最小化,即将随机网络的权重向预测网络蒸馏.因此这一算法称为随机网络蒸馏(random network distillation,RND).这一预测误差有效避免了动力学预测中的状态迁移随机性、预测目标不稳定以及预测信号与目标间未知的异质性等问题.在多个探索困难的Atari 场景中,包括Atari-MR 等,RND 算法在表现上显著优于基于动力学预测误差的方法,但其训练步长显著增加,达到了1.97×109步.此外,文献[60]承认RND 仅能解决短期决策中的局部探索问题,不能解决长周期的全局探索问题.
针对环境观察中存在白噪声干扰问题,一些研究人员考虑利用时序上邻接状态间天然的相似性,降低新颖性判别时与智能体行为无关的成分[76-77].例如,Savinov 等人[76]提出的EC(episodic curiosity)算法以间隔k步以内的状态对为正样本、k步以外的状态对为负样本训练一个比对网络CNet,用于状态新颖性判别.EC 算法在探索过程中建立情节记忆时,通过CNet判断当前状态与记忆中状态的差异性,若差异显著则加入情节记忆.其内在奖励是CNet输出值的函数.EC 算法可以有效应对干扰,在存在噪声干扰的DMLab 场景中,其均分达到了26,是ICM 算法得分的4 倍以上.然而,EC 算法在计算内在奖励时需要比较当前状态和情节记忆中的每个状态的差异,导致其在大规模状态空间中计算代价过高.Ermolov 等人[77]利用邻近状态对训练了特定的状态隐特征提取网络,从而在特征表示中去除随机成分,以其为基础构建前馈的隐世界模型(latent world model,LWM),将状态预测误差作为内在奖励.得益于时序关系启发式思想的利用,LWM 算法在多个Atari-HEG 环境中取得了优于EMI 算法的分数.
另一个引起关注的问题是,在截断式设定下,开始新情节时,某些尚未探索到的区域直接因基于预测模型的内在奖励较低无法得到访问.为解决此问题,NGU(never give up)[78]算法中设计了双层的内在奖励机制:情节内(per-episode),基于初始清空的情节记忆进行状态相似性比较,鼓励在多个情节中周期性地重访熟悉但尚未充分探索的状态;情节间(inter-episode),训练RND 模型输出预测误差作为降调制因子,逐步降低已熟悉状态的奖励值.得益于该奖励设计,NGU 在Atari-MR 上取得了当时最高的得分表现——16 800 分.
2)预测结果不一致性
1)中提及的基于预测误差的方法仅采用单一预测模型的预测误差作为内在奖励,容易使探索进程受到随机因素影响.最近有研究者提出可以利用多个模型预测结果间的不一致性,表示状态空间的探索程度.
Pathak 等人[79]提出了Disagreement 算法,采用极大似然估计训练一组随机初始化的前向动力学模型,以不同模型预测的下一时刻状态特征的方差作为内在奖励.在探索程度较低的区域,此方差值较大,可激励智能体加强探索;在较为熟悉的区域,这些模型的输出都趋向均值,因此方差较小,从而避免单模型输出与受随机因素的真实观测间差异较大的情况.而Shyam 等人[80]提出的MAX(model-based active exploration)算法则利用模型间的信息熵度量其不一致性.这2 种算法利用多模型集成的方式,可以在一定程度上解决随机噪声干扰的问题,但由于需要训练多个前向动力学模型导致计算复杂度较高.
Ratzlaff 等人[81]利用生成式模型估计智能体对环境动力学信念的贝叶斯不确定性,基于此模型的多次采样近似环境的后验表示,以采样输出的方差作为内在奖励.在机械臂操控、机器人导航等奖励稀疏的连续场景上的实验结果表明,该算法的性能表现优于基于模型集成方法[79-80],且数据利用率更高.
3)预测精度提升
利用基于预测误差值设计的内在奖励启发智能体探索环境容易因预测误差自身的偏差影响探索过程的稳定性.针对此问题,早在1991 年,Schmidhuber[51]提出可以量化预测模型的精度提升,以产生内在奖励信号,在量化内在动机和驱动探索方面更具鲁棒性.具体而言,在对于降低预测误差没有帮助的任务场景(如远远超出当前技能的挑战、早已熟练掌握的任务以及完全随机而不可控不可学习的环境状态),智能体不会陷入其中而会寻找对于学习效果更有提升的状态动作空间.因此这类内在奖励的形式化方法能促进智能体像人类一般具有稳健而循序渐进的心智发育和技能掌握[23,70].
早期的一些工作包括Oudeyer 等人[70]在2007 年提出的基于区域划分的预测误差进步评估方法.Lopes 等人[62]在2012 年以负对数似然作为预测误差,以k步内误差的提升作为精度提升的量化,用它替代BEB[18]算法中的访问计数,在简单环境下的探索效率取得显著提升.近些年,Graves 等人[82]在模型预测的损失函数基础上,渐进地设计了多种损失降低(即精度提升)或模型复杂度(即数据编码的容量)提升的奖励信号.该算法在合成语言建模等任务上显著提升了学习效率,在某些情况下甚至提高了1 倍的学习效率.
4)小结
为方便对比,表3 对各类基于预测模型的主要算法进行了简要总结,列写了它们的内在奖励设计形式、状态表示方法、抗噪能力以及实验效果等.从文献数量和年份来看,预测误差仍然是这类方法中最主要的“好奇心”内在动机形式.其中因为对环境状态的预测天然地容易受到环境噪声的影响,必须辅以谨慎的状态特征提取方法,才能使智能体仅关注具有探索价值的状态子空间.例如,尽管ICM[61]考虑利用逆动力学预测任务,在状态表示中仅保留对智能体有影响的特征,但当噪声与智能体动作存在关联时,ICM 也无法较好地从噪声区域摆脱[74].而LWM[77]所依靠的辅助任务则与状态间的时序关系相关,其特征表示的意义更加明确.另外,RND[60]提供了改变预测对象来提升探索效率的新思路.

Table 3 Summary of Main Algorithms Based on Predictive Models表3 基于预测模型的主要算法小结
从另一个角度看,基于误差的方法依赖于单一预测模型的质量和其预测结果的置信程度,容易受到模型构建方法(例如神经网络)本身固有缺陷(如过拟合、欠拟合等)的影响[79].相较而言,基于多模型[79]和单模型误差的二阶形式(即精度提升)[82]的方法,则能更系统性地避免此问题.目前,运用这种学习提升概念的形式化方法在基于预测模型类方法中研究较少,而在基于信息论的方法中较多.
2.4.2 基于信息论的方法
信息论中以熵(entropy)为基础的一系列概念,天然地为衡量现实世界中的不确定性而生,因此信息度量也成为形式化启发式概念,生成内在奖励的重要工具[83],用于促进智能体高效探索未知区域.以离散变量为例,熵的定义式[84]为
与之紧密相关的互信息(mutual information,MI)则指通过观测随机变量Y而获得关于X的信息量,即2 个变量的相互依赖程度,其定义为
相对熵,又称KL 散度(Kullback-Leibler divergence),表达2 个分布P和Q间的差异,表示为
其中 X 为2 个分布共同的概率空间.
在上述互信息、相对熵等度量基础上,受“学习提升”“多样性”“控制力”等启发式概念的影响,研究者们从不同视角提出了多种内在奖励量化方法[85-87],可大致分为基于信息增益、基于最大熵和基于互信息的探索方法.
1)信息增益
Sun 等人[88]从贝叶斯法则角度指出,估计的环境模型参数分布 Θ在智能体接收到新观测数据时进行更新,可用此时的 Θ′与 Θ间的相对熵表征信息增益(information gain,IG),作为智能体探索过程的学习提升.在此基础上,Houthooft 等人[58]提出最大化动力学上的累计熵减,对应每一时刻,即最大化式(17)所描述的变量.
其中ξt={s1,a1,s2,a2,…,st,at}是当前轨迹.然而,要在高维环境中将此KL 散度作为内在奖励,必须解决后验p(θ|ξt,at,st+1)的近似计算问题.为此,该工作提出VIME(variational information maximizing exploration)算法,将此问题转化为变分推断的ELBO(evidence lower bound)优化问题,并用贝叶斯神经网络对环境模型参数化.在基于稀疏奖励的高维连续控制任务中,VIME 算法性能显著优于基于贝叶斯神经网络预测误差的内在奖励方法.然而,该算法的内在奖励计算需要高额的计算代价,导致其难以应用到复杂场景中.
在VIME 算法的基础上,Chien 等人[89]提出同时最大化ELBO、基于隐状态的预测误差和抽象空间中st+1与at之间的互信息来驱动探索.该算法整合了多种内在奖励,可以有效提升探索过程的样本利用率,其在任务型对话系统PyDial 中的表现优于VIME[58]算法和ICM[61]算法.然而,在稀疏奖励下的超级马里奥兄弟游戏中,其仅取得了与ICM[61]算法相当的表现,且算法复杂度更高.
为解决VIME[58]面临的计算复杂度过高的问题,Achiam 等人[90]采用基于神经网络拟合的全因子高斯分布代替基于贝叶斯网络的环境模型,此外,将“惊奇”定义为真实转移概率和模型之间的KL 散度.由于真实模型无从获得,因此给出2 种近似的内在奖励,分别是“惊奇”(surprisal)和k步学习提升,对应-logPϕ(s′|s,a)和logPϕt(s′|s,a)-logPϕt-k(s′|s,a).与VIME算法相比,文献[90]算法可扩展性好,计算效率显著提升,然而在连续控制任务场景中,该算法性能提升非常有限,甚至在个别任务上表现出了负提升,且还存在内存耗费过高的问题.为解决此问题,Kim 等人[69]采用指数衰减的加权混合方法表示旧的环境模型,该方法虽然在视觉元素多样而复杂的环境中取得显著高于Surprisal[90],RND[60],Disagreement[79],ICM[61]等方法的模型精度,但并未指出如何解决此类环境中面向多类物体的结构化表示学习问题[91].
2)最大熵
除了基于信息增益的方法,受基于计数方法的启发,研究者们还提出了一种思路,即最大化状态分布的熵以激励智能体充分探索不同状态的方法.
Hazan 等人[92]提出MaxEnt 算法将探索策略诱导下的状态分布的信息熵最大化,促使智能体充分访问不同状态;同时指出相关优化思路也可以用于优化其他信息度量,如最小化状态分布与某指定的目标分布间的KL 散度或目标分布与状态分布的交叉熵.对于MaxEnt 算法中涉及的基于状态分布匹配的优化过程,Lee 等人[93]指出可将其作为一种通用框架,将基于预测误差或互信息等度量的方法视为分布匹配框架中的特例.
考虑到MaxEnt 算法在原始状态空间上进行状态分布匹配的优化时存在计算代价过高的问题,Vezzani 等人[94]提出利用相关任务采集到的先期数据,学习与任务相关的状态表示、去除不相关的特征维度,以压缩状态空间,从而提高探索策略效率.
在Vezzani 等人[94]工作的基础上,后续还有一些研究者提出在高维环境中利用状态抽象表示的最大熵方法,包括Novelty[52],APT(active pre-training)[95],RE3(random encoders for efficient exploration)[96]等.其中Novelty 和APT 分别利用前向预测和对比学习等任务辅助完成状态编码,RE3 则直接采用权重随机初始化的卷积网络输出状态的低维特征向量,去除了表示学习的复杂过程.同时,为避免复杂的状态密度建模,Novelty,APT,RE3 算法都采用了k近邻方法对状态熵进行估计.
3)互信息
互信息可以反映2 个变量间的依赖程度.一种很自然地在探索中应用互信息的方式,就是最大化环境动力学模型中,从当前状态动作对到下一个状态的互信息,以增加智能体在探索过程中对环境的认知.根据香农的信息率失真理论[84],Still 等人[97]认为可将从状态st到动作at的映射看作有损压缩,而后解码为下一时刻状态st+1.以信道两端互信息量I({st,at},st+1)的最大化为优化目标,则能使智能体在好奇心驱使下不断追求提升自身对外部环境的预测能力.
另一种在探索过程中应用互信息的方式,是量化重要的内在动机概念Empowerment[98]. 量化Empowerment 并不直接强调提升对观测数据的理解或预测,而是指对动作结果有较强控制能力,能在后续时刻获得更多的状态选择,因此也被称为多样性启发式[99].如果将环境模型中的状态转移考虑为将动作a转换为未来状态s′的信道,信道容量则可看作是Empowerment.直观讲,Empowerment 代表智能体能够通过动作序列a向未来状态注入的最大信息量.Mohamed 等人[100]提出VMI(variational mutual information)算法,以互信息为基础描述为
其中 ω为探索策略.以E(s)为内在奖励,可使智能体能观测到最大数量未来状态的中间状态转移.由于高维条件下没有快速有效的互信息计算方法,该工作借助变分推断近似表达了动作的后验分布,从而推导出了可用深度神经网络优化的变分下界.
在此基础上,若将式(18)中的原子动作a扩展为option(即在原子动作基础上的抽象动作、技能或策略)[101],则有公式[99,102]
其中Z和S分别表示option 的隐变量和状态变量.对其反向形式的最大化优化过程,意味着提高option 的多样性和给定终止状态时option 的确定性(或辨识度);对其正向形式的最大化,则意味着增强option 对环境不确定性的削弱作用.
以反向形式为例,Gregor 等人[99]于2016 年提出了该研究方向的奠基性算法——VIC(variational intrinsic control)算法.该算法将提前预设的动作序列(被称为开环options)扩展为以终止状态区分的options(被称为闭环options).具体来说,在开环options 中智能体在执行option 时,将盲目地遵循对应的动作序列,而不考虑环境状态;而在闭环options 中,智能体的每一次动作选择都是基于当前环境状态慎重考虑的,大大提高了智能体对于环境状态的Empowerment.在实验环境为存在噪声的网格世界中,VIC 算法显著优于开环options,可有效修正环境噪声,但是该算法在2 维网格世界中学习的options 相对较为简单,面临难以应用于复杂环境的问题.为解决该问题,研究者们在其基础上开展了一系列工作.
例如,为克服VIC 集中学习少数技能的问题,Eysenbach 等人[103]提出了DIAYN(diversity is all you need)算法,在最大化I(S;Z)的同时,还将先验p(z)固定为均匀分布,提升了技能丰富性.针对VIC 在随机环境中的偏差问题,Kwon[104]利用转移概率模型和高斯混合模型来构建环境的动力学模型,以达到最大化的Empowerment.Achiam 等人[105]提出了VALOR(variational autoencoding learning of options by reinforcement)算法,其设计了更为通用的框架,将终止状态或单一状态延伸为状态动作轨迹,VIC 和DIAYN 等方法都成为其中特例.针对VIC[99],DIAYN[103],VALOR[105]等方法中存在的状态空间覆盖有限问题,Campos 等人[102]提出一个基于固定状态分布的3 阶段分解方案EDL(explore,discover and learn)以更充分地探索状态空间.另外,为解决VIC[99]等option 发现方法中存在的泛化性差和推断低效问题,Hansen 等人[106]提出将行为互信息与后继特征结合互补,提高option 内插泛化的效率.
目前采用正向形式进行技能学习的方法相对较少.Sharma 等人[107]提出的DADS(dynamics-aware discovery of skills)算法利用条件熵H(s′|s,z)的最小化作为优化目标之一,提高在技能z条件下状态转移的可预测性,从而能够将预训练阶段得到的options 及其对应的动力学过程有效应用到基于模型预测控制的任务规划中.
上述无论是基于反向形式还是正向形式的方法都能一定程度使智能体自主演化出复杂程度递增的生存技能,可为时间跨度更长或结构复杂的下游任务提供有效的初始化基础.
4)小结
表4 简要总结了信息论基础上各类内在奖励设计方法.不难看出,基于信息增益的方法与2.4.1 节中基于预测模型精度提升的方法有较强关联,是用KL散度等指标对学习提升概念更理论化的描述,可以看作预测模型方法的延展.基于最大熵的方法通过最大化原始/抽象状态分布的熵来提高探索效率,可有效结合其他状态表示方法来进一步提高算法性能.基于互信息度量的方法通过量化Empowerment,以多样性启发的方式来鼓励探索,成为解决自动技能发现问题的重要工具.这些方法以自动演化出的原子行为为基础,正逐渐服务于具有更强层次性的技能组织、技能迁移、任务规划等下游场景[107].为提高信息度量指标的计算效率,可对信息度量进行一定程度近似,如变分下界[58]和模型估计的差分[90],但如何进一步提升信息度量的计算或近似效率仍是许多研究者关心的问题.
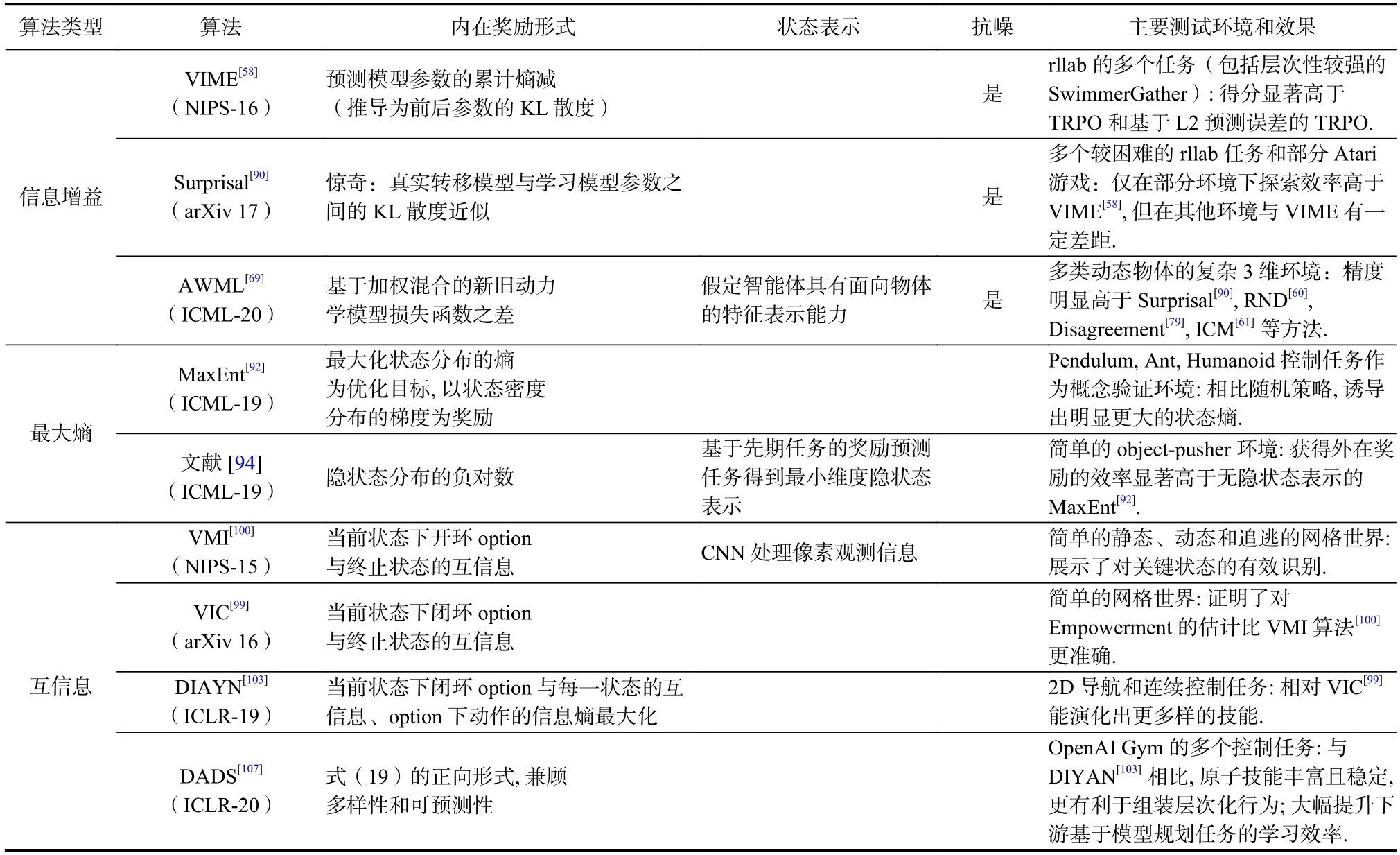
Table 4 Summary of Main Methods Based on Information Theory表4 基于信息论的主要方法小结
2.5 基于能力的方法
基于能力的方法重点在于权衡达到目标的挑战性和能否达成的能力,与其直接相关的心理学理论还包括效能、自我决定和心流等学说[24].Mirolli 等人[108]认为以内在动机为基础的学习是层次化的,不同类型的动机在不同层次上发挥功能性角色.其中基于知识的动机驱动个体在理解未预期事件的过程中,学习如何发现可用技能和训练技能;基于能力的动机则工作在更高层次上,负责在不同场景中对已有能力进行调度使用和效果监测,从而阶段化完成自身设定的子目标和总目标.因此,对此类动机进行量化的核心是对自定目标实现难度的衡量和对动作效果的观测.
在Barto 等人[23]于2004 年提出的IMRL(intrinsically motivated reinforcement learning)算法中,内在奖励基于option 的目标状态而产生,可认为是一种基于能力的内在动机的形式化方法.
与Barto 等人[23]提出的算法相比,Schembri 等人[109]提出了更直接的基于能力的模型.该模型既包含很多由actor-critic 神经网络模型构成的“专家”,采用时序差分的方式学习动作策略;又包含一个“选择者”,以“专家”的时序差分误差为内在动机负责在不同条件下将控制权分配给不同“专家”.在仿真机器人场景下,该模型可用于训练智能体学习多种不同的导航任务.Santucci 等人[110]提出了GRAIL(goaldiscovering robotic architecture for intrisically-motivated learning)算法.该算法采用一个4 层的内在动机学习框架,能够实现对动作效应的观察、基于内在动机的目标选择、为实现目标进行资源调度以及对实现进程的监控等功能.
然而,尽管Oudeyer 等人[24]在2007 年就提出了多种基于能力的内在动机学习的模型设想,但目前将此类动机显式应用到DRL 的方法并不多.一个可能的原因是在高维或动态条件下,该模型涉及对复杂环境和任务空间的分解、层次化和渐进式的技能获得等,需要与多种方法结合来实现.
2.6 小结
与UCB[111]和BEB[18]为代表的传统方法相比,基于内在动机的DRL 方法虽然缺乏对最(次)优性和采样复杂度的严格理论保证,但能一定程度解决公共测试集中高维状态动作空间中的探索,从而帮助学习环境动力学模型或动作策略.具体来说,基于计数的内在动机方法受新颖性的启发,一方面继承了UCB 方法中“面向不确定性的乐观”思想,另一方面采用基于相似性的状态泛化,能够有效应对大规模状态动作空间的探索问题,但其多用于静态环境中,难以有效应对动态性较强和随机噪声干扰较多的环境.
基于知识的方法采用“好奇心”“惊奇”“学习提升”“多样化”等启发性信息来快速积累对于环境演化的知识,以降低外部环境不确定性对决策的影响.对于这类方法而言,复杂动态环境中随机噪声(包括环境白噪声、动作执行中不可预期的噪声等)的处理直接关系探索效率.一方面,可以通过学习隐特征空间一定程度过滤随机成分: 最基本地,采用通用设计的CNN 或自编码器等特征提取模块[47,53];更进一步,设计辅助任务仅学习与任务相关的特征,如ICM[61],CoEX[40]中的逆动力学预测任务,以及奖励预测任务[94]等.然而,当噪声源和智能体的动作存在关联时,上述方法的抗噪能力也十分有限[74].另一方面,多模型集成[79]和信息增益[69]等方法则能够更系统性地评估智能体动作对于提升环境模型表达能力的价值.然而,在高维的连续空间等条件下,此类方法的难点在于计算复杂度和相关信息量估值精度间的平衡.
与基于知识的方法相比,受控制力启发的基于能力的方法从智能体本身出发,工作在更高抽象的层次,负责在不同场景中通过对自定目标实现难度的定量分析,来调度使用已有能力并对效果进行检测,从而实现高效引导探索过程.该类方法研究重点包括如何恰当表达智能体动作或option 与环境状态之间的影响,以及互信息的高效且无偏的估计算法.
3 应用研究
基于内在动机的DRL 探索方法起初应用于游戏领域的智能体策略生成,随着DRL 算法在现实场景中的落地应用,基于内在动机的DRL 探索方法目前也扩展到机器人运动、机械臂操控、空间探索与导航等诸多应用领域.
3.1 机器人运动
在机器人运动领域中,基于内在动机的DRL 探索方法主要应用于奖励稀疏的多自由度复杂运动控制任务中,为受DRL 驱动的机器人增强探索过程的启发性,进一步提高采样效率,从而实现高效学习各关节的控制策略.例如,针对rllab[36]的多足仿真机器人运动任务,Houthooft 等人[58]提出了基于信息增益的VIME 算法,将其与TRPO[59]深度强化学习算法相结合,可高效学习复杂运动控制策略.在S ∈R335,A ∈R35的复杂类人机器人Toddler 的仿真环境中,Achiam等人[105]提出的基于互信息的VALOR 算法经过15 000次迭代能学习到40 种运动技能.针对四旋翼飞行器的激进运动控制任务,Sun 等人[112]提出了基于预测模型的DRL 探索方法,并引入了基于相似性的好奇心模块来加速训练过程,其在模拟环境中训练的策略可以直接迁移到现实世界中应用.在多机器人运动控制任务中,Perovic 等人[113]引入了受人类好奇行为启发的内在奖励来应对稀疏奖励问题,并在构建的3 维物理仿真环境中检验了算法的有效性.
3.2 机械臂操作
在机械臂操作应用中,基于内在动机的DRL 探索方法能够帮助真实机械臂在没有关于自身动作空间先验知识的条件下,尝试对其他物体完成移动、抓取、推动、移动等的操作任务[114].例如,Lee 等人[93]提出的基于最大熵的SMM(state marginal matching)算法,在仿真环境中的Fetch 任务和现实世界的爪形机械臂抓取任务中,能够探索到比PC[39]和ICM[61]算法更高的状态熵,帮助完成复杂的机械臂操作策略学习.在更为复杂的任务设置中,要求现实世界的机械臂抓取随机摆放的多个物体,其动作空间被离散化为224×224×16×16的规模,Pathak 等人[79]提出的基于预测模型的Disagreement 算法在抓取从未见过的物品的准确率上达到了67%.
3.3 空间探索与导航
在空间探索与导航领域,基于内在动机的DRL探索方法除了可用于解决全局可观的Atari 环境中空间探索等相关问题,还可在一定程度上解决类似现实场景中环境初始未知、局部可观条件下的空间探索和目标导向的导航问题.在这类复杂探索与导航问题上,基于内在动机的方法主要用于实现探索效率高的移动策略.例如,在Doom-MWH 任务中,A3C(asynchronous advantage actor-critic)算法结合基于预测误差的ICM 算法,经过预训练和700 万步的再训练后导航成功率能达到66%左右[61],EX2在类似任务中的成功率能达到74%[47].针对复杂环境中机器人无地图导航任务,Shi 等人[115]提出了一种基于预测模型的DRL 探索方法,以基于稀疏的激光测距输入,克服障碍物和陷阱等影响,可将仿真环境中训练得到的策略扩展到真实场景中进行实际应用.下一步,可考虑在基于内在动机探索方法的基础上,结合表示学习方法从局部观测信息中估计当前位置或姿态,以及利用紧凑而准确的空间记忆表示形式来进一步提升在空间探索与导航领域的应用效果.
3.4 小结
基于内在动机的DRL 探索方法通过构建强启发性的探索策略,可有效应对机器人运动、机械臂操控、空间探索与导航等领域面临的探索困难问题.此外,在量化投资、自然语言处理等领域,基于内在动机的DRL 探索方法也发挥着重要作用.例如,针对股票市场的自动金融交易策略学习问题,Hirchoua 等人[116]将PPO 算法与基于好奇心驱动的风险学习的内在奖励相结合进行交易策略学习,并在8 个真实股票交易上对其训练得到的策略的适用性和有效性进行了验证;针对面向目标的对话策略学习问题,Wesselmann等人[117]采用基于好奇心的内在奖励来克服稀疏奖励问题,以改进状态动作空间的探索效率,从而获取更多有关用户目标的知识来训练对话策略.
4 关键问题与发展方向
虽然基于内在动机的DRL 探索方法在机器人运动等诸多应用中取得了较好效果,但将其应用于贴近真实世界的复杂动态场景时,仍面临难以构建有效的状态表示、环境认知效率低、复杂任务空间探索效果差等关键问题.未来基于内在动机的方法可结合表示学习、知识积累、奖励设计、目标空间探索、课程学习、多智能体强化学习等领域方向来开展研究.
4.1 关键问题
4.1.1 有效的状态表示
如何构建有效的状态表示一直是将基于内在动机的DRL 探索方法应用于高维连续状态动作空间所面临的基础且重要的问题.特别是随着场景不断向现实应用逼近,环境中要素的种类和数量越来越多,要素间的关联越来越复杂,往往包含层次性、级联性等关系,并且动态性也越来越显著.在这些情况下,现有方法难以提取与智能体决策直接或间接相关的状态特征,因此很难单纯依靠内在奖励的驱动对上述类型的状态空间进行探索.
在基于状态抽象方法中,Choi 等人[40]提出的注意动力学模型可有效抽取可控区域的动力学信息.而Song 等人[57]提出了Mega-Reward,在直接可控特征信息[40]的基础上,抽取了隐式控制的特征信息.这2 个工作在Atari-MR 上都取得了较好的表现.然而,在机器人导航、自动驾驶等应用中,存在更为复杂的多元异构高维信息,在这类场景下构建有效状态表示是亟需解决的难题.
4.1.2 环境认知效率
对于外部环境形成较为充分的认知是基于知识的方法促使智能体探索的关键所在,但是随着外部环境进一步复杂化,如存在随机噪声干扰、不可控的动态环境要素等,面临环境动力学模型学习效率低等问题.
在基于预测模型的方法中,Burda 等人[60]提出的RND 算法大大提高了预测误差精度,且可以有效应对随机噪声干扰,但是在Atari-MR 等场景中,该算法需要10 亿级的训练步长才能使其环境模型收敛,达到较好表现.与Atari-MR 相比,在星际争霸2 等存在自适应的对手,或更为复杂要素的场景中,如何提高环境认知效率是基于知识的方法所要解决的重要挑战.
4.1.3 复杂任务空间
复杂任务空间往往存在多个可控要素或干扰要素,且其内部呈现结构化特征,宛如“迷宫”,仅依靠内在动机提供的探索方面的引导信息,难以实现对该类任务空间的有效探索.
Savinov 等人[76]提出的EC 算法,依托基于情节记忆的状态新颖度判别方法,可引导智能体完成在仿真3 维场景下的导航任务,但由于情节记忆的容量限制,难以应用于大规模状态空间.在机器人运动、操控、自主导航等复杂现实应用中,如何将情节记忆、先验知识等相关任务空间信息与基于内在动机的方法结合,是提高复杂任务空间探索效果的难点.
4.1.4 小结
基于内在动机的DRL 探索方法在解决复杂现实应用问题时所面临的难以构建有效的状态表示等关键问题,不是单纯依靠内在动机可以解决的,往往需要与其他领域方向有机结合,充分发挥基于内在动机的启发式探索策略的潜力,以应对复杂动态场景中的探索困难挑战.
4.2 发展方向
Silver 等人[118]撰文分析了奖励函数在促进智能体演化出各种形式的智能方面的重要作用.鉴于现实世界任务的复杂性(环境要素多元、空间结构复杂、感知信息高维、任务反馈延迟等),本文对未来基于内在动机方法的研究方向提出6 方面的展望.
4.2.1 表示学习
1)状态表示
本文简述的方法所采用的状态表示方法大多以自动特征提取为主,各个特征无明确语义,不能显式描述环境中的要素及其关系,因此难以针对性提取与智能体决策相关的环境要素来构建有效的状态表示.
在智能体与环境交互获取样本的过程中,算法一方面应关注行为策略的演化,但更应该注重环境的表示学习.具体来说,先识别和分割环境中的各种要素及其关系,然后在此基础上,利用场景中各要素间的层次性、交互关系和局部的动力学等特征信息,构建蕴含丰富环境信息的有效状态表示.近年来出现了一些基于无监督或自监督的方法用于构建这些状态表示,如解耦学习[119]、对比学习[120]以及它们与好奇心探索的结合[121].
目前已有一些研究者认为智能体只会对状态空间中可学习、可控制的部分感兴趣,其他部分由于不会对下游任务产生显著影响,因此不应对其浪费探索时间.研究者们[40,57,61]从控制性角度设计辅助任务进行表示学习,但多以黑盒形式输出隐特征,缺乏对环境中任务相关要素的显式建模.更具可解释性的状态表示与基于内在动机的探索方法的结合,将会使智能体更专注于关键区域的探索,从而提高复杂场景下的策略学习效率.
2)动作表示
动作表示是通过对原子动作的合理抽象,帮助智能体更好地利用探索方法解决复杂问题,典型方法包括分层强化学习(hierarchical reinforcement learning,HRL).
HRL 是一类将复杂问题空间层次化地分解为子问题和子任务的强化学习方法,文献[101]提及的option 框架是其中的典型模型.该框架的底层以状态观测和子目标为输入,输出达成此目标的原子动作序列的抽象表示,即option;框架的上层是基于option而非原子动作的策略,时间尺度相较底层更长.针对这类框架一般无法自动为底层策略的学习提供奖励函数的问题,研究人员提出一系列基于内在动机形成的内在奖励,以提高底层策略的学习效率.例如,Kulkarni 等人[122]提出h-DQN(hierarchical-DQN),其上层的元控制器从预定义的可能目标中为下层的控制器选择当前目标,并以目标达成与否作为标识为控制器生成二元的内在奖励.Vezhnevets 等人[123]提出的FuNs(feudal networks)则采用了端到端的学习方式,不仅使上层的“管理者”可自动生成代表状态空间中优势方向的子目标,还为下层的“工作者”设计状态差分与目标方向的余弦相似度作为内在奖励,以衡量“工作者”对子目标方向的趋近程度.然而,目前研究更多关注在底层策略中利用内在动机提供丰富的奖励信号,后续可结合内在动机解决HRL 中更为关键的自动化学习层次结构问题[124].
4.2.2 知识积累
尽管内在动机为提高DRL 的采样效率提供了有力工具,但由于内在奖励仅能为智能体提供探索方面的指导性信息,难以根据问题性质对智能体行为施加约束和引导,可能使得部分探索动作并不诱导知识的增加.因此,本文认为利用探索过程中的累积知识可以有效辅助智能体以简洁的行为模式进行探索.例如,在最近备受关注的Go-Explore[125]算法将人类面对未知环境的探索经验显式地在智能体行为框架中表达出来,在Atari-MR 等任务中取得了数倍于NGU[78]等此前算法得到的最高分数.另外,该算法对有价值状态的回访得益于其对过往经历的记录和提取.类似地,EC[76]算法借助情节记忆对不同状态间的可达性进行判别来量化状态新颖性,在Doom-MWH中以较小的训练代价得到接近100%的成功率;Chen等人[126]结合空间记忆、模仿学习以及探索覆盖率内在奖励,在逼真的3 维SUNCG 环境中,单纯依赖板载传感器可有效探索未知环境.
除此之外,对问题进行适当地层次划分[127]、区域分割[53]或拓扑提取[128],可以降低子空间探索的难度,产生更流畅的探索行为模式,从而引导智能体更快积累环境空间的知识.例如,Chaplot 等人[127]将端到端的学习方式改进为模块化分层框架,其中全局策略学习空间环境结构,局部策略应对状态估计的误差,显著降低了采样复杂度.
4.2.3 奖励设计
1)任务相关的内在奖励设计
从内在动机的角度出发,源于不同启发思想设计的各种通用的内在奖励函数,在各类公共测试任务中验证了各自效果.在通用内在奖励函数的基础上,研究者在实际应用中可以根据任务特点,设计更能直接反映目前需求的内在动机.例如,Berseth 等人[129]提出的SMiRL(surprise minimizing reinforcement learning)算法以熵的最小化为优化目标,使智能体在非稳定环境中产生趋利避害行为.更一般地,信息增益是不同环境模型的KL 散度,比如环境覆盖任务中的探索面积、追逃任务中与目标态势的差距、多智能体通信中的信息容量等.如果智能体所需达到的目标是复合性的,奖励信号的来源也可以是多源的,可以通过学习自适应的调度策略依据当前环境信息和已有的探索轨迹确定当前阶段的子任务目标和奖励信号.
2)内在奖励的自动化获取
除人工设计奖励外,部分研究者考虑将基于内在动机的内在奖励函数看做函数空间的抽象特征向量,可采用搜索或学习的方法自动获取与任务匹配的内在奖励函数.这类方法的基础是Singh 等人[130]提出的最佳奖励框架,其中将可使RL 智能体获得最大外在奖励的内在奖励定义为最佳内在奖励.在该工作[130]的基础上,研究者们在小规模离散状态动作空间中采用了简单的遍历式搜索的方法确定最优内在奖励,但难以扩展至大规模或连续状态动作空间的场景中.
为解决此问题,研究者们提出了基于策略梯度的内在奖励参数化学习方法,用于优化蒙特卡洛树搜索等规划算法在稀疏奖励场景下的表现[131-132].在此基础上,为解决多智能体场景中基于单一的团队奖励区分不同智能体贡献的问题,Zheng 等人[133]将内在奖励的学习与DRL 智能体的策略学习相融合,以最大化与任务相关的累计外在奖励.该工作采用基于双层优化架构的元强化学习方法,外层对参数化的内在奖励函数进行学习,内层将内在奖励函数作为超参数来优化策略.目前内在奖励自动获取方面的研究大多采用神经网络来拟合内在奖励函数,虽然该方式无需特定问题背景下的领域知识以及心理学相关的设计方法,但是其生成的内在奖励函数可解释性差,后续可以考虑利用基于心理学等方面的设计机理来增强自动化获取的内在奖励函数的可解释性.
4.2.4 目标空间探索
为提高智能体在高维、连续和高度非平稳的目标/任务空间中的探索效率,近年来有大量研究者将内在动机应用于目标空间探索领域.例如,Forestier等人[134]提出了一个机器人控制背景下的基于内在动机的目标探索过程(intrinsically motivated goal exploration processes,IMGEP)机制,即基于已有技能衡量各目标任务可能带来的能力进步,以此组织对目标/任务空间的探索策略.为降低目标空间复杂度,Colas 等人[135]采用灵活的模块化表示方式对目标空间进行编码,在进行模块和目标选择时考虑预估的学习进步的绝对值,因此使智能体选择当前能够取得最大进展的目标或因遗忘而可能表现下降的过往目标.还可以考虑将无监督学习的目标空间表示[136]以及解耦的目标空间表示[91]与内在动机相结合,进一步提高探索效率.
4.2.5 课程学习
研究者们认为自然智能显著超过目前的机器学习系统的一大能力,是通过观察外部环境、自我设定目标而持续不断学习并获得技能和知识的渐进提升[137-138].这种复杂程度和难度递增的学习过程在机器学习领域被称为课程学习(curriculum learning,CL)[139].为降低课程学习对于领域知识的需求,研究者们提出了内在动机与课程学习结合的各种形式.
例如,Jaderberg 等人[140]通过设计辅助的预测任务,为智能体提供额外的内在奖励,在增强对环境理解程度的同时提高了应对后续复杂任务的能力.Graves 等人[82]则提出了基于模型预测能力的提升和模型复杂程度有限提高的2 类内在奖励,以解决课程学习中的任务选择问题.Sukhbaatar 等人[141]提出一个非对称自博弈机制,该机制基于任务难度设计内在奖励,自动形成任务探索的课程表.后续可考虑结合内在动机进一步优化课程学习中难度评分器和训练调度器的性能.
4.2.6 多智能体强化学习
多智能体深度强化学习将DRL 的思想和算法用于多智能体系统的学习和控制中,以开发具有群体智能的多智能体系统来高效优化地完成任务[142].在研究者们重点关注的协同与通信问题中,可结合内在动机的探索方法产生多样化的协同行为,或增加对于环境及其他智能体的认知,来实现更有效的协同与通信.
例如,Iqbal 等人[143]在多智能体协同空间探索的设定下,基于共享信息针对不同的任务需求设计了多种类型的内在奖励,并学习高层控制器在实际任务环境下选择不同奖励训练得到的策略.Jaques 等人[144]基于反事实推理,使智能体能够通过仿真获得自身动作对于其他智能体的因果影响,以此作为内在奖励能够自发地使智能体学习到有意义的通信协议,促进更加有效的相互协同.文献[144]还证明该奖励形式等价于最大化不同智能体动作间的互信息.不仅协同行为可以通过内在奖励生成,Guckelsberger 等人[145]的工作也表明通过最小化Empowerment 等手段也可产生对抗性行为.目前多智能体强化学习领域的探索仍处在起步阶段,可考虑在集中式控制分布式执行架构下结合现有的基于内在动机的方法,提高每个智能体的探索效率,以增加联合动作价值函数估计的准确性.
5 总结
本文首先描述了DRL 方法对高效率探索方法的需求、经典方法的原理和局限性,接着引入了内在动机的概念和功能,在此基础上重点梳理了内在动机与DRL 结合的不同形式,主要包括:1)受新颖性动机驱动的基于计数的内在奖励形式化;2)受好奇心驱动的预测误差的奖励设计;3)受学习提升期望驱动的精度提升和信息增益近似方法;4)以状态多样性为启发式的最大熵方法;5)追求自主性和控制力的互信息量化方法.然后介绍了基于内在动机的DRL 探索技术在机器人运动、机械臂操作、空间探索与导航等领域的应用情况.最后深入分析了基于内在动机的DRL 探索方法在应用于贴近真实的复杂场景时,仍面临着难以构建有效的状态表示、环境认知效率低、复杂目标/任务空间探索效果差等关键问题,并对基于内在动机的探索方法结合表示学习、知识积累、奖励设计、目标空间探索、课程学习、多智能体强化学习等领域进行了展望.
作者贡献声明:曾俊杰、秦龙共同负责调研和论文撰写;徐浩添、张琪对论文提出指导意见并完成论文格式修订;胡越负责论文审阅,并给出详细修改指导意见;尹全军对论文提出指导意见并完成论文格式修订;曾俊杰、秦龙作为共同一作,对本文做出同等贡献.
