基于改进林分密度指数的栎类天然林最大密度线*
2023-10-27龙时胜曾思齐杨盛扬
龙时胜 曾思齐 杨盛扬
(1. 中南林业科技大学 长沙 410004;2. 南方森林资源经营与监测国家林业和草原据重点实验室 长沙 410004)
林分自稀疏,指在林分生长过程中林木株数随林分年龄增长自然减少(部分生长较弱的林木逐渐被淘汰)的现象。森林中林分自稀疏是因生长空间内的资源有限造成的,当资源不足以满足林分正常生长需求时,林分会通过自稀疏来调整林分密度从而达到一种生长与枯损之间的动态平衡(Pretzschet al.,2005;Yanget al.,2017)。林分自稀疏规律研究,重点在于林分最大密度线的构建,最大密度线是反映林分最大密度与林木平均大小(胸径、材积、生物量等)之间关系的重要定量依据(李凤日,1995;贾茜等,2021),研究林分最大密度线及自稀疏规律,对模拟森林生长动态及确定合理的经营措施具有重要意义。
构建林分最大密度线模型通常以平均树木大小与林分最大密度的关系为基础,但表达平均树木大小的变量较多,如平均胸径、平均树高、平均生物量等(Hart,1926;Reineke,1933;Yodaet al.,1963;Duceyet al.,2010)。在Zeide(1987;1991;1995)的一系列研究中,采用推理和经验证据对自稀疏和林分密度进行分析,认为胸径是反映林分最大密度的首选,林分平均树高与林分最大密度无关;但Hart(1926)则认为林分平均树高与林分密度密切相关。尽管存在争议,但以往研究均是基于人工纯林得出的结论,该结论是否适用于天然混交林还未可知。
模拟林分最大密度线模型的方法不同,也可能导致模型参数存在较大差异。最小二乘法回归(least square regression)是模拟林分最大密度线模型的常用方法,其结果依赖于数据点选取是否合理。目前,数据点选取常采用视觉法(Yodaet al.,1963)、死亡率法(Westoby,1984)、等距区间法(Newton,2006)和相对密度法(Solomonet al.,2002),但是无论如何选取数据点,均无法避免一定程度的主观性,从而导致模拟的林分最大密度线缺乏一定程度的客观性;同时,这4种常用方法在天然混交林中的适用性研究未见报道。为了克服数据点选取偏于主观的问题,Bi等(2000)将2种经济计量方法,即分位数回归(quantile regression)和随机前沿分析(stochastic frontier analysis)引入到自稀疏边界线估计中(Zhanget al.,2005),此后,这2种方法成为最常用的估算二维或更高维度上的最大密度线技术(Condéset al.,2017;Andrewset al.,2018);然而,同时应用这2种方法并进行比较的研究还较少(Sunet al.,2019),尤其在天然混交林中。
栎类是我国天然林的重要组成部分(朱光玉等,2018),开展栎类经营已成为我国天然次生林经营的风向标(官秀玲等,2019),栎类质量好坏对区域森林生态功能的发挥起着关键性作用。鉴于此,本研究以湖南栎类天然林为研究对象,对现有林分密度指数进行改进,采用分位数回归和随机前沿分析构建栎类天然林最大密度线,探究栎类天然林自稀疏规律,以期从理论上丰富种群生态学,为天然林林分密度管理与控制提供理论参考。
1 研究区概况与方法
1.1 研究区概况
湖南省地处我国中部、长江中游,108°47′—114°15′E,24°39′—30°08′N。地貌轮廓为东、南、西三面环山,中部丘岗起伏,北部湖盆平原展开,形成朝东北开口的不对称马蹄形地形。地貌类型多样,有半高山、低山、丘陵、岗地、盆地和平原。地带性土壤主要为红壤(占全省土地总面积的36.6%)、黄壤(占全省土地总面积的15.4%),非地带性土壤主要有潮土、水稻土、石灰土和紫色土等。属亚热带季风气候,大部分地区日均气温稳定,无霜期253~311天,年均降雨量1 200~1 700 mm。境内栎类资源丰富,广泛分布于全省各市、县,总面积8.65×104hm2,总蓄积6.16×106m3(国家林业和草原局,2019)。常见栎类树种有青冈栎(Cyclobalanopsis glauca)、细叶青冈(Cyclobalanopsis gracilis)、麻栎(Quercus acutissima)、白栎(Quercus fabri)等。
1.2 数据分析与整理
数据源于湖南省栎类天然林连续清查样地,初选样地274块,对样地进行筛选并剔除异常数据后(3倍标准差),确定265块样地作为研究对象。样地共同特征为:郁闭度0.60以上,样地内林木总株数800株·hm-2以上,栎类株数占比超过15%,样地内乔木为实生起源,且生长发育过程相对稳定。每块样地大小为25.82 m×25.82 m,包括2期重复测量,分别为2004和2014年。所有样地2004年林木总株数为31 466株,其中栎类6 154株,占林木总株数的19.6%。样地内每株胸径5 cm以上的树木均挂铝牌标识,以防误测。测量的立地因子包括海拔(用GPS测量)、坡度(用罗盘仪测量)、坡向(GPS)、土壤等,测树因子包括每株树的树种、胸径(用围尺测量)、相对坐标、林分平均优势树高(测量主林层5株优势树种平均木,取树高算术平均值)和每公顷株数。样地的基本属性见表1。
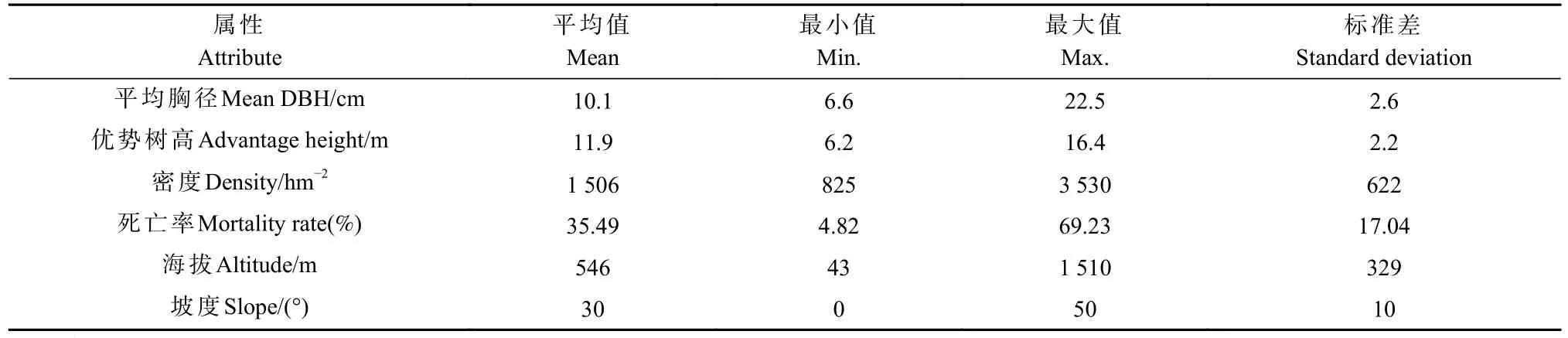
表1 栎类天然林样地的基本属性①Tab. 1 Basic attribute of oak natural forest plots
考虑到不同林分类型栎类天然林在林分密度和自稀疏进程方面可能存在差异,本研究将栎类天然林划分为以下3种林分类型:1) 栎类相对纯林,即栎类蓄积占林分总蓄积65%及以上的林分,现有样地中,栎类相对纯林样地总数32块,占总样地的12.1%;2) 针栎混交林,即栎类和针叶树种蓄积占林分总蓄积65%及以上,且栎类蓄积占比超过15%、针叶树种蓄积占比低于65%的林分,现有样地中,针栎混交林样地总数109块,占总样地的41.1%;3) 阔栎混交林,即栎类和阔叶树蓄积占林分总蓄积65%及以上,且栎类蓄积占比超过15%、阔叶树种蓄积占比低于65%的林分,现有样地中,阔栎混交林样地总数124块,占总样地的46.8%。
1.3 研究方法
1.3.1 最大密度线模型 1) Reineke林分密度模型Reineke(1933)指出,在完全郁闭的同龄林中,单位面积林木株数(N)和平均胸径(D¯)在ln-ln坐标上呈线性关系。Reineke林分密度模型常用来模拟人工纯林最大密度线。对于给定的林分平均胸径D¯,单位面积林木株数N是一定的,其关系式为:
式中:φ1为依赖物种的恒定值;φ2为大小与密度之间的异速指数。Reineke(1993)认为,φ2为恒定值-1.605,而部分研究表明,φ2随立地、树种、生长阶段的变化而变化(Schumaher,1939;李凤日等,1995;贺姗姗,2009)。
2) 改进林分密度模型 Reineke林分密度模型主要反映林分密度与林分平均胸径之间的关系,一些学者认为林分密度与林分高呈正比(Hart,1926;Briegleb,1952),一些学者则认为林分高与林分密度无关(Zeide,1987;1991;1995)。如图1a,在人工纯林中,林分平均木i的高度与相邻木一致,平均木i的高度增加只会抬高树冠高度,不会增加单位面积获取的光照,也不会增加林分密度(Haroldet al.,1996)。该类结论或许适用于人工纯林,但是否适用于天然混交林还未可知。
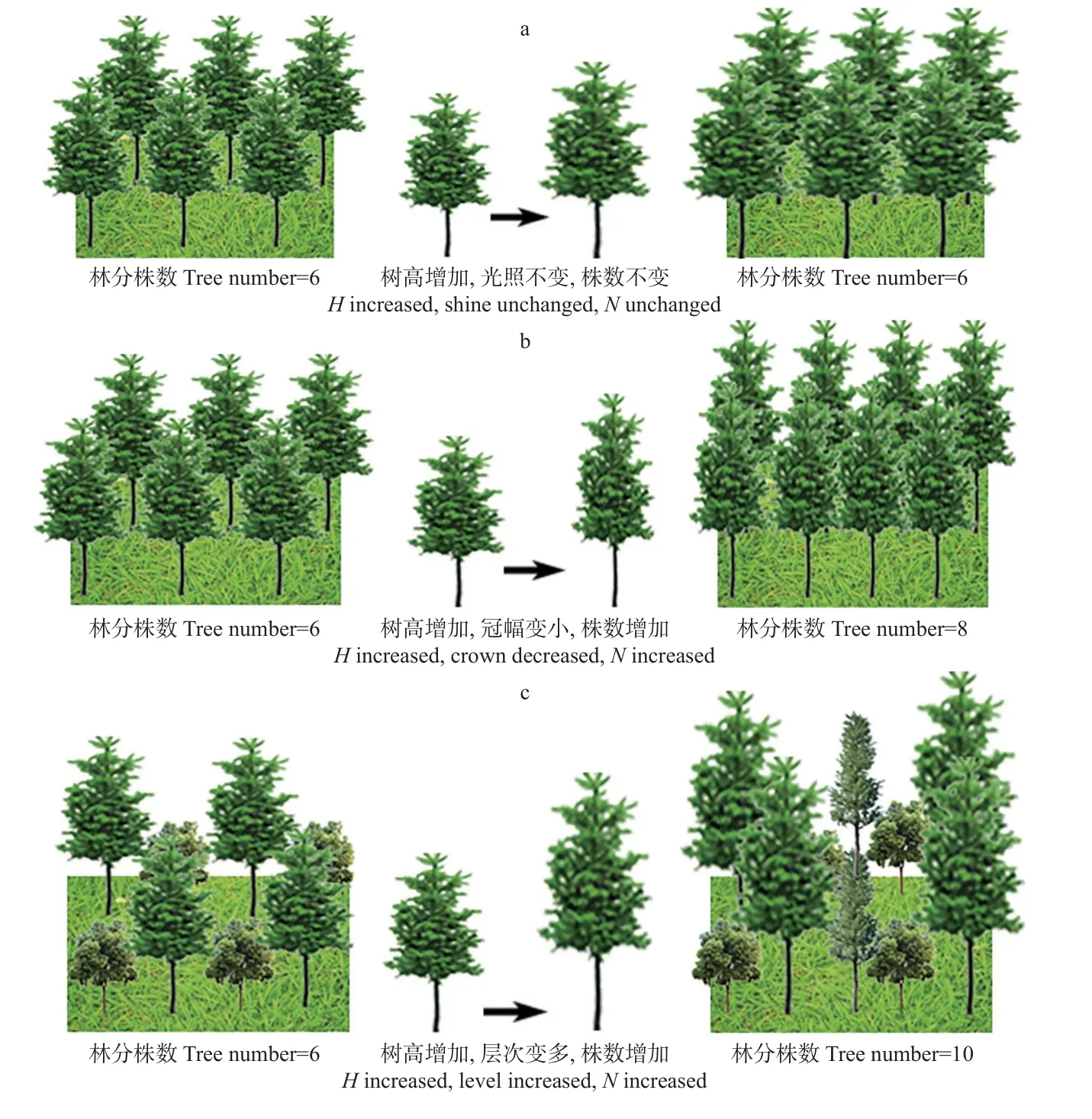
图1 树高对林分密度的影响Fig. 1 The effect of tree height on stand densitya.树高对光照和株数的影响The effect of tree height on light and tree number;b.树高对冠幅和株数的影响The effect of tree height on crown and tree number;c.树高对分层和株数的影响The effect of tree height on hierarchy and tree number.
树高对天然林林分密度的影响,具体体现在以下2方面:
(1)树高影响树冠大小。当其他因素(如胸径和木材质量)一致时,树高与冠幅大小呈负相关关系,即树高增加会导致树冠变窄(Zeide,1995)。如图1b,当树木i的胸径不变、树高增加时,其冠幅会变小以维持结构稳定性。当树木i的树冠尺寸变小时,相邻木之间树冠重叠度减少,竞争减弱,死亡率降低,且单株林木水平方向占用的生长空间变小,单位面积可容纳株数增加,林分最大密度可能提高。
(2)树高影响林木分层。天然林中树高不一,往往存在明显分层现象。如图1c,当林分树高较小时,林分中林木可能仅有2个层次,此时可容纳的林木株数为8;当林分树高增加后,林分垂直生长空间变大,树木分层数增加,可容纳的林木株数变多,林分密度增加(N=10)。
由此可知,天然林林分密度可能受林分胸径和树高的共同影响,其最大密度线模型应考虑以胸径和树高作为自变量。
Yoda 等(1963)提出生态领域的“-3/2准则”,也被称为自稀疏规则。该准则描述了完全郁闭的同龄林中,林分内平均生物量(w)和单位面积植物数量的幂函数关系,即:
式中:k1为依赖物种的恒定值;a为大小与密度之间的异速指数。Yoda等(1963)认为a为恒定值-3/2,与物种、立地、年龄和初始密度无关。
由Yoda的“-3/2准则”可知,林分平均生物量w与林分密度N相关。相关研究表明,林分生物量w是与胸径D和树高H相关的幂函数(刘兴良等,2006;李轩然等,2007),即:
对于式(2)和式(3),有:
式(4)中,可将N看作与D、H相关的函数,对式(4)变形,则有:
由于k1、k2、a、b、c均为常数, 可假设k=则式(5)简化为:
式(6)两侧取自然对数,得到:
因此,将树高和林分平均胸径作为自变量的式(7)可用于构建天然林最大密度线,即改进的林分密度指数,其中H为林分优势树种平均高,D为林分平均胸径,N为林分最大密度。
1.3.2 最大密度线模型拟合方法 1) 分位数回归分位数回归模型中第τ个分位数模型参数可通过最小化残差绝对值的非对称损失函数估计:
式中:yi为因变量向量;xi为自变量向量;τ为待估分位数值;γ为系数向量,其中分位数回归得到的模型系数γ会因分位数τ的选取不同而有所差异(Scharfet al.,1998)。
采用分位数回归拟合林分最大密度线模型的关键在于确定何种大小的分位数τ来拟合模型。大多数研究在拟合最大密度线模型时发现,合适的分位点一般为0.90、0.95或0.99(高慧淋等,2016;田德超等,2019)。为确保研究的全面性和准确性,本研究选取分位点τ为0.05~0.99,增量为0.05,共计20个分位点进行拟合,并重点对0.90、0.95、0.99这3个分位点的最大密度线模型进行分析。
2) 随机前沿分析 随机前沿分析是一种测试协变量的有效且强大的统计技术,较多学者已运用随机前沿功能对部分树种最大密度线进行研究(Biet al.,2000;Weiskittelet al.,2009;孙洪刚等, 2010)。方程原始形式为:
式中:Yi为因变量第i次的观测值;为不同自变量的观测值;A和βi为方程预测系数;evi和e-µi为误差组成部分,其中νi→N(0,σν2),µi→N(0,σν2),0≤µi≤∞,0≤e-µi≤1。
将式(9)取对数,得到:
式中:zi=logY;α=logA;wi为自变量第i个向量的对数形式;β为参数向量;εi为复合误差项(εi=νi-µi),并呈负均值的非对称分布。2个误差项νi、µi可组合成3种随机前沿分析方法:正态-半正态分布(NH)、正态-指数分布(NE)和正态-截尾正态分布(NT)。使用StataSE 15的随机前沿分析模块估计模型系数。
2 结果与分析
2.1 分位数回归拟合结果
以Reineke林分密度模型和改进林分密度模型为基础,采用分位数回归拟合栎类天然林最大密度线模型,结果见图2。从模型系数95%置信区间分布可以看出,置信区间基本位于零值线一侧,说明Reineke林分密度模型和改进林分密度模型的模型系数均具有显著意义。Reineke林分密度模型的截距随分位数增加而增大,而改进林分密度模型的截距不受分位数大小影响(图2a)。2类模型的胸径系数随分位数增加缓慢增大后趋于相等,改进林分密度模型的树高系数随分位数增加呈降低趋势(图2b)。一般来说,Reineke林分密度模型的胸径系数反映林分自稀疏速率,截距反映林分密度的最大承载力。对比2类模型的系数变化可知,改进林分密度模型的胸径系数与Reineke林分密度模型一致,主要反映林分到达最大密度后的自稀疏速率。与Reineke林分密度模型不同的是,改进林分密度模型的截距和树高系数共同反映林分密度的最大承载力,其最大承载力是动态的,且随着优势树高增大而增加。
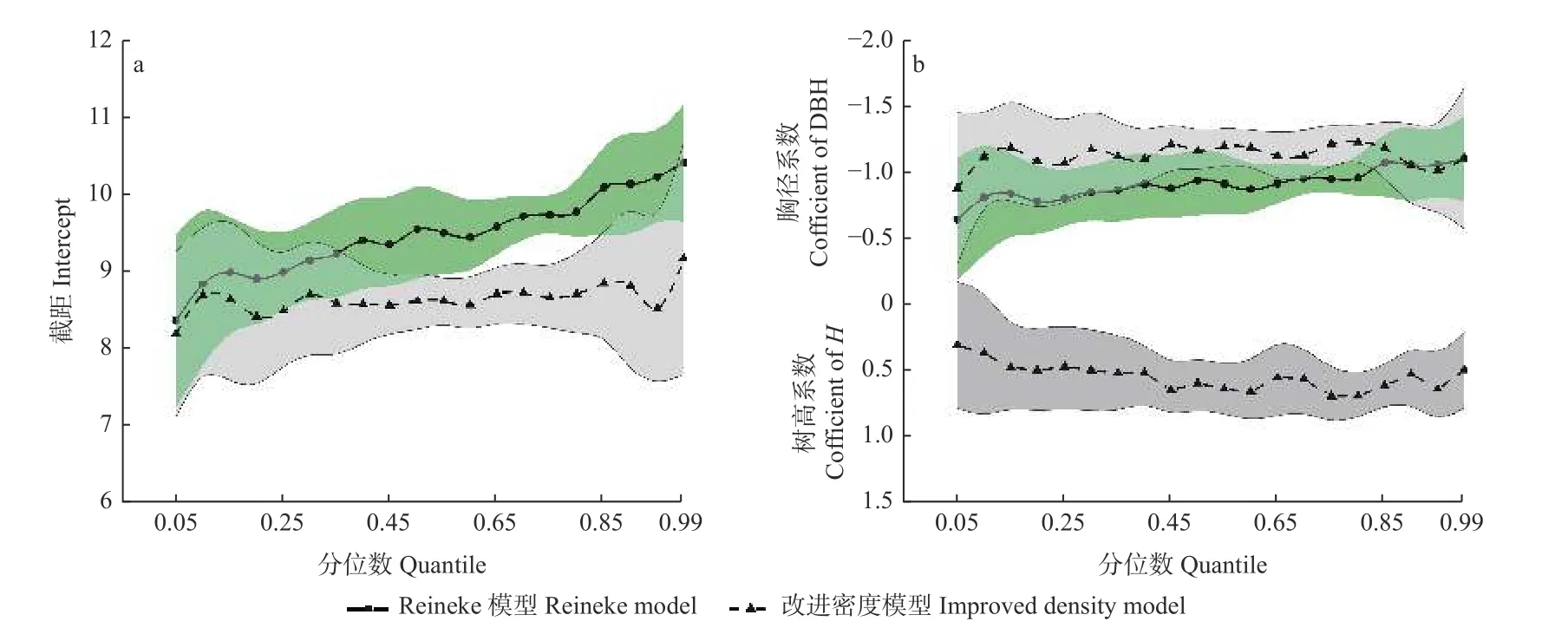
图2 2类模型在不同分位点的模型系数Fig. 2 Model coefficients of the two models at different quantile values阴影填充部分为相关模型系数95%置信区间。The shadow filling part is the 95% confidence interval of the relevant model coefficients. a. 模型截距在不同分位点的数值Numerical values of model intercept at different quantiles;b.模型胸径和树高系数在不同分位点的数值Numerical values of model diameter at breast height and tree height coefficients at different quantiles.
进一步拟合Reineke林分密度模型和改进林分密度模型在0.90、0.95、0.99分位点的模型系数,并对2类模型在不同分位点的残差进行对比分析,结果见图3。Reineke林分密度模型和改进林分密度模型的残差平均绝对值均随分位点增加而增大,方差分析结果显示3个分位点的残差平均绝对值无显著差异(P>0.05);同时,3个分位点的残差方差、偏度和峰度基本相等,无显著差异(P>0.05),说明Reineke林分密度模型和改进林分密度模型在大于0.90的分位点上基本稳定。对比2类模型的残差分布可知,在同一分位点上,改进林分密度模型的残差平均绝对值、残差方差和残差峰度均小于Reineke林分密度模型,但二者之间无显著差异(P>0.05)。由此可知,采用分位数回归拟合栎类天然林最大密度线模型时,Reineke林分密度模型和改进林分密度模型的拟合效果无显著差异。

图3 2类模型在不同分位点的残差分布Fig. 3 Residual distribution of the two models at different quantile values
2.2 随机前沿分析拟合结果
采用随机前沿分析拟合Reineke林分密度模型和改进林分密度模型的模型参数,结果见表2。分别以误差分布组合为正态-半正态分布、正态-指数分布拟合模型时,改进林分密度模型的AIC均显著小于Reineke林分密度模型(LR testP<0.001);以误差分布组合为正态-截尾正态分布拟合模型时,2类模型均无法收敛。采用随机前沿分析拟合栎类天然林最大密度线模型时,改进林分密度模型的拟合精度显著高于Reineke林分密度模型。进一步对比AIC可发现,以误差分布组合为正态-半正态分布拟合的改进林分密度模型效果最佳。
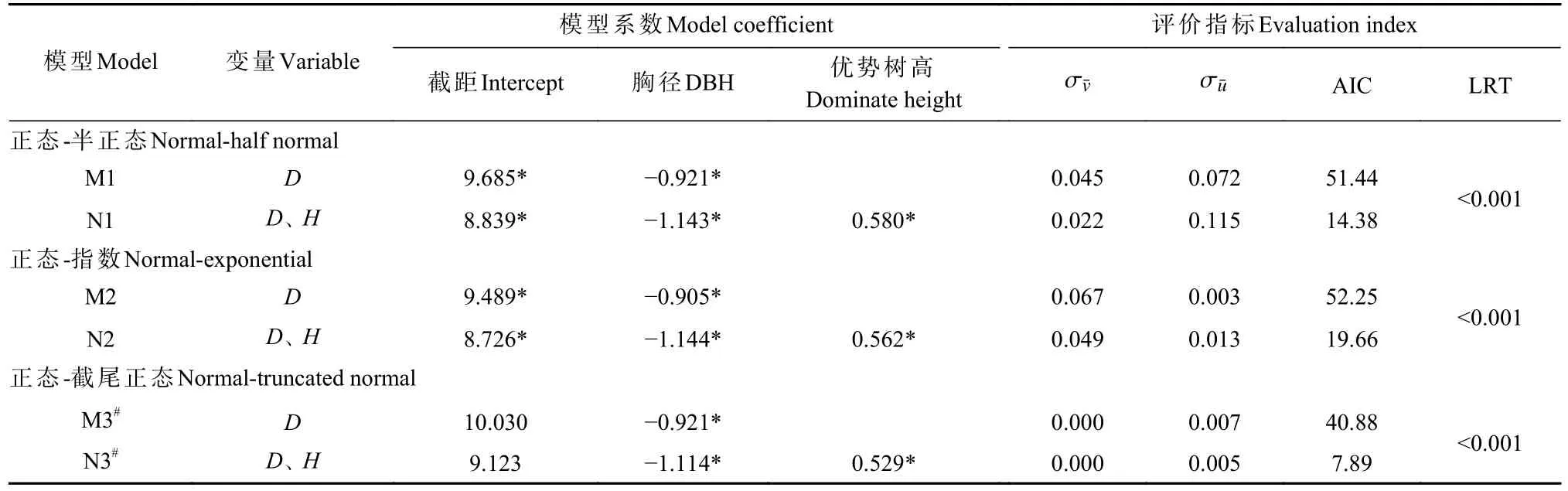
表2 随机前沿分析拟合结果①Tab. 2 Fitting results of stochastic frontier analysis
2.3 分位数回归与随机前沿分析拟合结果比较
以改进林分密度模型为基础,分别采用0.90分位点的分位数回归和以误差分布组合为正态-半正态分布的随机前沿分析拟合模型参数,并对比2类模型的残差分布情况,结果见图4。随机前沿分析拟合的最大密度线模型残差绝对平均值显著小于分位数回归(P<0.05),且残差方差和峰度同样小于分位数回归,这说明拟合栎类天然林最大密度线模型时,随机前沿分析在拟合精度和模型稳定性方面均优于分位数回归。
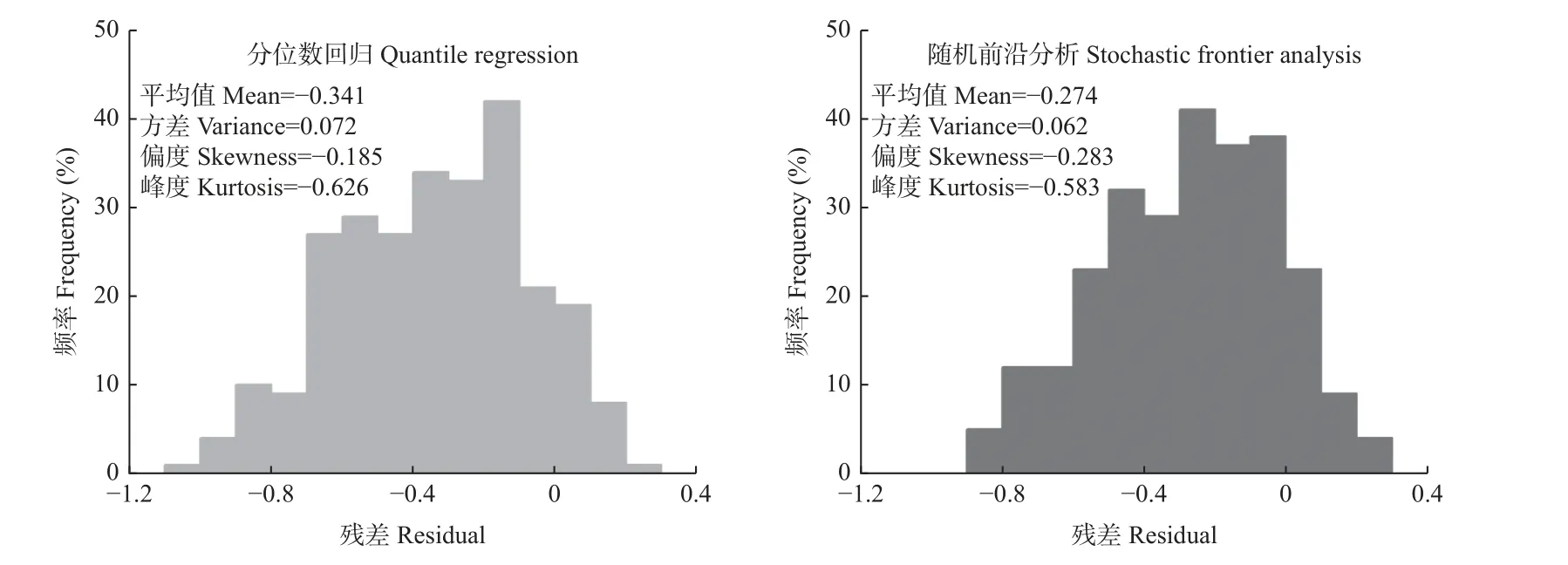
图4 2种方法拟合的最大密度线模型残差分布Fig. 4 Residual distribution of the maximum density model fitted by two methods
2.4 不同类型林分的最大密度线
采用随机前沿分析构建不同类型林分的改进密度模型,结果见表3。不同类型林分与整体林分的模型系数存在较大区别;3种类型林分的最大密度线模型系数均具有显著性意义(P<0.05);对比不同类型林分的模型系数可发现,栎类相对纯林的胸径系数绝对值明显大于针栎和阔栎混交林,优势高系数也有明显区别。
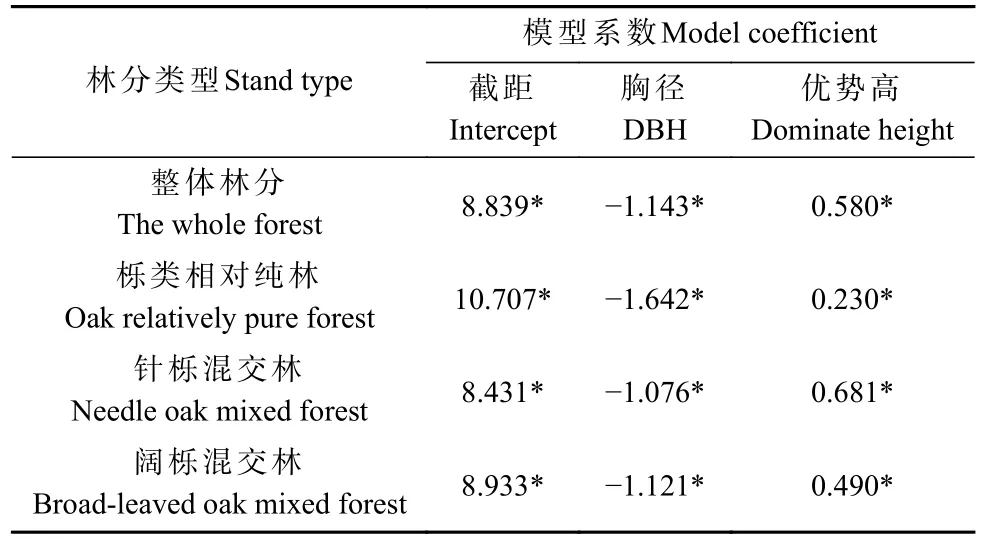
表3 不同类型林分的最大密度线模型①Tab. 3 Maximum density models for different types of stands
3 讨论
3.1 栎类天然林自稀疏的影响因素
现有林分密度指数大多以1个变量构建林木大小与林分密度的关系,如Reineke林分密度指数、自稀疏法则等(Reineke,1933;Yodaet al.,1963),说明人工纯林的林分密度结构较为简单,可用单一变量反映林分自稀疏特点。而天然混交林的胸径结构和树高结构复杂多变,林分密度结构可能受多个因素的综合影响。本研究尝试在Reineke林分密度指数中引入林分优势高变量,并采用随机前沿分析对2类林分密度模型进行对比分析,结果(表2)发现,引入优势高变量的林分密度模型在拟合精度上显著高于Reineke林分密度模型,说明栎类天然林最大密度线受林分优势高和林分胸径的显著影响。
对比Reineke林分密度模型和改进林分密度模型的模型系数(表2)和变化情况(图2)可以发现,二者在表达栎类天然林最大密度时具有以下区别:1)Reineke林分密度模型反映的林分密度最大承载力是固定的,而改进林分密度模型反映的林分密度最大承载力是动态的;2) Reineke林分密度模型以平均胸径为唯一自变量,改进林分密度模型以平均胸径和林分优势高为自变量。由此可知,林分自稀疏速率主要受林分胸径影响,而林分密度的最大承载力则受林分优势高影响,天然林林分优势高越大,林分可容纳的株数越多。究其原因,林分优势高越大,树木树冠越小,水平方向上单位面积内可容纳的树木数量增加;优势高越大,天然林分层数量越多,垂直方向上可容纳的树木数量同样增加。区别于人工纯林,天然混交林的林分自稀疏主要由平均胸径和林分优势树高决定。
3.2 林分自稀疏速率的影响因素之一
受生态学特性的影响,林分内同种(或同属)树木之间的竞争往往比异种树木之间更为激烈(刘振国等,2005;熊登煜等,2012;张忠华等,2016)。分析不同类型栎类林分最大密度线(表3)可知,栎类相对纯林的胸径系数绝对值明显大于针栎和阔栎混交林,说明栎类相对纯林在达到林分最大密度状态后,林分内树木的稀疏速率明显大于针栎和阔栎混交林。栎类相对纯林的树种大部分为栎类,同属物种对生长空间的竞争更加激烈,较多树木可能获取不到足够的生长空间而加快死亡,其自稀疏速率也更快。
进一步绘制不同类型林分的最大密度线,如图5所示。随林分平均胸径增加,3种类型林分的最大密度均减少,相比于针栎和阔栎混交林的最大密度线,栎类相对纯林的最大密度线更为陡峭,进一步说明栎类相对纯林的自稀疏速率更快;不同优势高的林分对应不同的最大密度线,而不同树高林分的曲线走向基本一致,说明栎类天然林的自稀疏速率不受林分树高影响。同时,依据图5中不同类型林分的最大密度线,可准确把握不同大小林分可容纳的最大林木株数,也可判别现实林分处于何种自稀疏状态(未稀疏或已稀疏)。
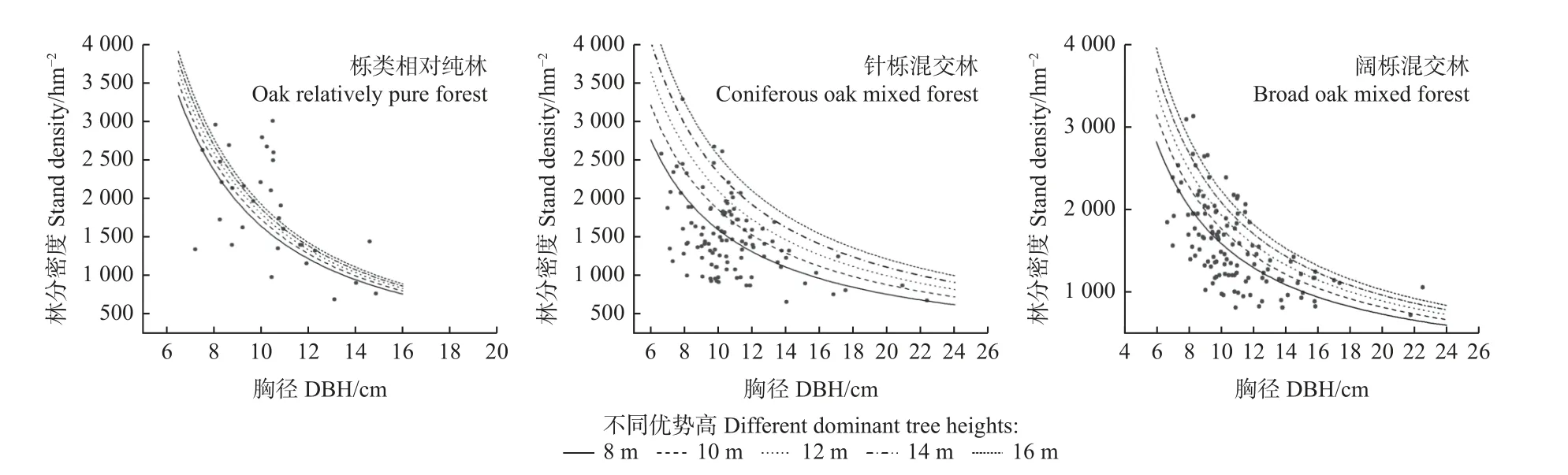
图5 不同类型林分的最大密度线Fig. 5 Maximum density line of different types of stands
3.3 天然林最大密度线模型的拟合方法
相较传统普通最小二乘法,尽管分位数回归和随机前沿分析已成为拟合最大密度线的常用方法,但传统方法仍然值得讨论分析,因为传统方法(死亡率法、区间法、相对密度法)是基于林分生长动态建立最大密度线模型,弥补了分位数回归和随机前沿分析缺少生态学解释的缺点。传统方法中,视觉法依赖于研究者的经验判断,主观性过强,会导致模型结果不稳定。Westoby(1984)认为,当人工林种群死亡率在20%左右时,可认为林分开始自稀疏,该结论是可信的,因为人工林郁闭后的死亡主要是密度影响的结果。但是,处于郁闭状态的混交林林分,死亡树木较多一部分是光照缺乏或生长受限的底层木,依此计算的林分死亡率与林分最大密度不是直接的因果关系,依靠死亡率选取拟合自稀疏模型的数据点,在混交林中的适用性不强。Solomon等(2022)认为,相对密度高于一定阈值的林分一定经历了自稀疏,选取合理的相对密度阈值是拟合天然林最大密度线模型的关键。区间法能够避免主观性过强、拟合精度不高的缺点,比较客观合理,但是该方法选取的样地可能包含一些密度较低的林分,此类林分未发生自稀疏,最终会导致依赖区间法拟合的自稀疏线斜率低于预期值。
对比随机前沿分析和分位数回归拟合最大密度线模型的效果发现(图4),随机前沿分析拟合最大密度线模型的残差绝对平均值显著小于分位数回归,且残差分布优于分位数回归,说明拟合栎类天然林最大密度线模型时,随机前沿分析在拟合精度和模型稳定性方面均优于分位数回归。该结论与Tian等(2021)的研究相似,随机前沿分析方法是目前拟合林分最大密度线模型的最佳选择,分位数回归方法也可提供有价值的补充。
4 结论
结合平均胸径和林分优势树种平均高构建的改进林分密度模型,在拟合栎类天然林最大密度线模型时,其拟合精度和稳定性优于Reineke林分密度模型,且改进林分密度模型具有生物学意义。随机前沿分析和分位数回归不依赖于传统方法的数据点选取,构建最大密度线的过程更为客观。随机前沿分析方法在栎类天然林最大密度线模型拟合方面具有最佳效果,分位数回归方法也可提供有价值的补充。
栎类天然混交林林分自稀疏过程主要受平均胸径和优势树种平均高的共同影响,平均胸径越大,林分自稀疏速率越快;林分优势树种平均高越大,林分可容纳株数越多。同时,栎类天然林中不同类型林分的自稀疏速率也存在显著差异,栎类相对纯林的自稀疏速率更快。
