基于Self-Attention 的方面级情感分析方法研究
2023-10-22蔡阳
蔡 阳
(浙江理工大学计算机科学与技术学院(人工智能学院), 杭州 310018)
0 引 言
互联网的迅速发展使各家电商和社交平台拥有了庞大的用户量,不同用户在平台中活动的同时产生了大量的评论信息。 在这些评论信息中,蕴含着巨大的社会和商用价值,对其进行情感分析以把握用户的情感倾向,可以有助于舆情处理,让商业公司快速分析产品质量并做出改进,也能辅助其进行商业决策。 传统的情感分析方法中,循环神经网络(Recurrent Neural Network,RNN)有着时序性的特点,无法并行计算,且不能直接提取句子的上下文语义特征; 卷积神经网络( Convolutional Neural Network,CNN),在句子的全局特征表达上表现效果欠佳;而自注意力机制(Self-Attention)能很好地解决上述问题,不仅能够做并行计算,在提取句子上下文特征上也展现出了强大的能力,因此本文将基于注意力机制搭建模型来展开研究,用来解决方面级文本评论情感分析问题。
方面级情感分析是判断文本对于给定方面表现出的情感极性,2016 年,Wang 等学者[1]提出一种用于方面级情感分析的模型,通过将方面词向量和输入词向量及LSTM 隐层向量拼接的方式加入方面词的影响,当不同的方面被输入时,该机制能集中在句子的不同部分,在SemEval 2014 数据集上的实验结果达到当时最先进的性能。 2018 年,Huang 等学者[2]提出一种AOA(Attention-Over-Attention)网络,对方面和句子进行联合建模,并明确地捕捉方面和上下文句子之间的交互信息, 在laptop 和restaurant 数据集上的实验结果证明该网络性能优于之前的基于LSTM 的模型。 2019 年,Liu 等学者[3]提出门控交替神经网络(Gated Alternate Neural Network,GANN),该模型中有一个特殊模块GTR(Gate Truncation RNN)被设计用于学习情感线索表示。 2019 年,Zhang 等学者[4]针对LSTM 网络在一定程度上忽略了方面词在句子中的句法依赖性问题,提出了一种邻近加权卷积网络,在SemEval 2014数据集上的实验结果证明了该方法的有效性。 2020年,Xu 等学者[5]提出一种多注意力网络(Multi-Attention Network, MAN),MAN 使用级内和级间注意机制来解决方面术语包含若干词的问题,实验证明MAN 性能优于基准模型。 2020 年,Liu 等学者[6]提出了一种新型记忆网络ReMemNN(Recurrent Memory Neural Network),针对注意机制中弱交互的问题,设计了一种多元素注意机制,以产生强大的注意权重和更精确的方面依赖的情感表示,实验结果表明ReMemNN 的优秀性能与语言无关,与数据集类型无关。 2020 年,Xu 等学者[7]提出了DomBERT(Domain-oriented BERT)模型,在方面情感分析任务中取得了较好的效果。 2020 年,冉祥映[8]将语义注意力机制和基于注意力机制的方面融合,提出了HAN(Hierarchical Attention Network) 模型。 2020年,Cai 等学者[9]为了捕获显式和隐式方面术语的情感极性,提出了一种分层图卷积模型Hier-GCN(Hierarchical Graph Convolutional Network),该模型在4 个基准测试中取得了当时的最佳结果。 2020年,Gan 等学者[10]提出SA-SDCCN(Sparse Attention based Separable Dilated Convolutional Neural Network)模型用于目标情感分析,在3 个基准数据集上进行实验,结果表明其并行性更高的同时降低了计算成本,取得了较先进的性能。 2020 年,Zhou等学者[11]提出一种基于句法和知识的图卷积网络SK- GCN (Syntax - and Knowledge - based Graph Convolutional Network ), 通 过 GCN ( Graph Convolutional Network)利用句法依赖树和常识知识。2021 年,Tian 等学者[12]提出了一种通过类型感知图卷积网络 T - GCN ( Type - aware Graph Convolutional Networks)来显式利用方面情感分析依赖类型的方法,在6 个英语数据集上取得了当时最先进的性能。 2021 年,Yadav 等学者[13]提出了一种基于注意力机制的无位置嵌入模型用于方面级情感分析,在数据集restaurant 14、laptop 14、restaurant 15和restaurant 16 上进行实验,最终准确率分别达到81.37%、75.39%、80.88%和89.30%。 2021 年,Dai等学者[14]首先在方面情感分析任务的几种流行模型上比较了预训练模型的诱导树和依赖解析树,然后通过实验证明纯基于RoBERTa (A Robustly Optimized BERT Pretraining Approach)的模型可以取得接近之前SOTA(State-Of-The-Art)性能的结果。
本文提出了用于方面级情感分析Light -Transformer-ALSC 模型,运用了交互注意力的思想,对方面词和上下文使用不同的注意力模块提取特征,细粒度地对文本进行情感分析,并在SemEval-2014 Task 4 数据集上进行实验以证明其有效性。
1 网络结构
1.1 Light-Transformer-ALSC 网络结构
为了更好地捕获方面词对文本情感极性的影响,本文模型将方面词向量和文本上下文向量分别用不同的注意力模块建模,对建模后的特征向量求和平均作为计算下一轮注意力的查询向量(Query,Q),具体来说,对上下文特征向量的注意力计算使用方面词向量的Query,反之亦同。 经过此轮注意力计算后将2 个向量作拼接,然后通过Softmax计算情感极性。 为了加速模型的训练并缓解训练数据不足的问题,本文模型中使用Glove 预训练词向量,预训练的词向量已经一定程度上学习到了单词之间的语义信息,可以加速模型的收敛过程,模型的整体结构如图1 所示。
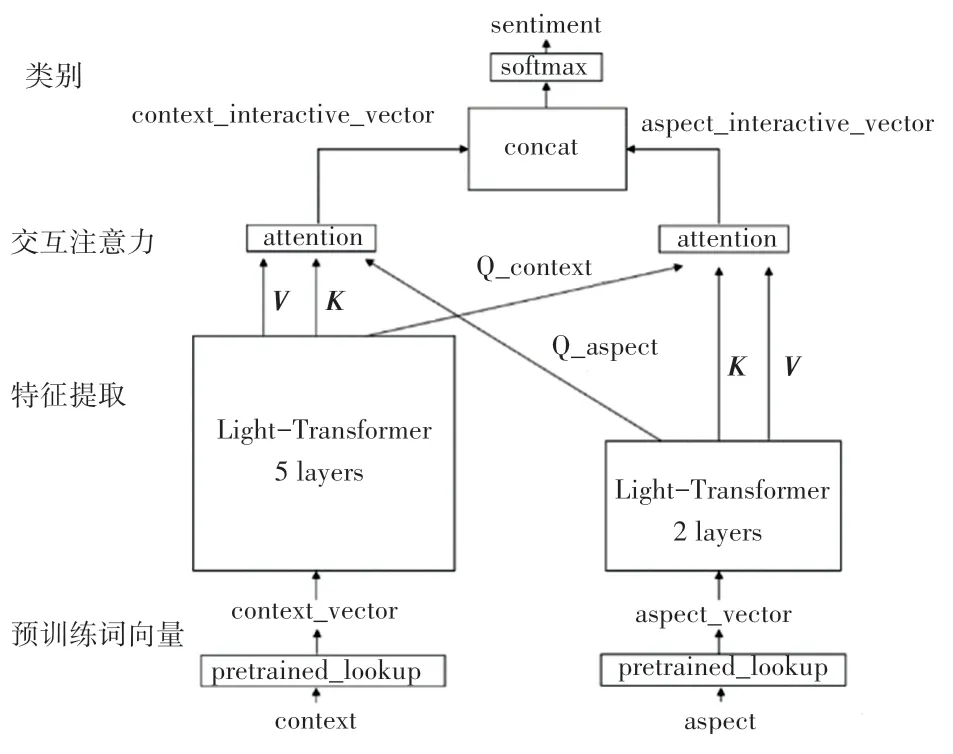
图1 Light-Transformer-ALSC 网络结构图Fig. 1 Structure of Light-Transformer-ALSC network
模型主要包括Light-Transformer 特征提取器、交互注意力、以及特征拼接三大模块。
1.2 Light-Transformer 特征提取器
经过词嵌入处理的文本向量首先会经过特征提取模块初步提取特征,方面词向量和上下文向量由2 个独立的 Light - Transformer 处理, Light -Transformer 基于Transformer 模型并对其进行改造,取消Decoder 模块,减少Encoder 模块至5 层,并对参数量做一定优化。 其结构如图2 所示。
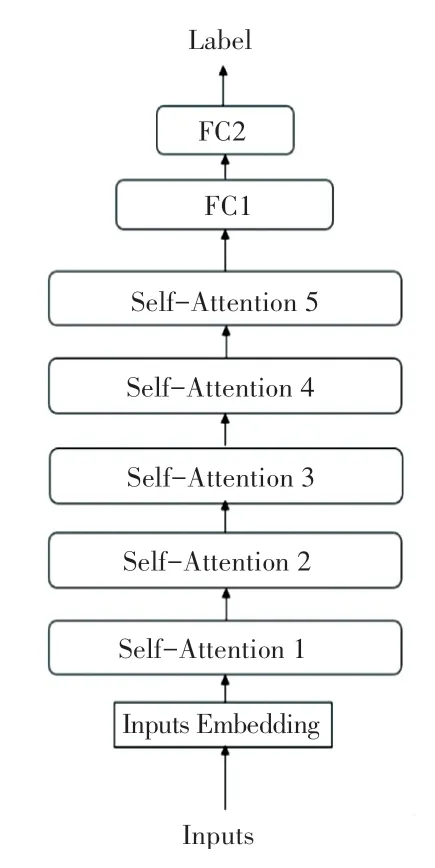
图2 Light-Transformer 结构Fig. 2 The structure of Light-Transformer
模型的特征提取能力主要来自于自注意力模块,是由相同的5 层堆叠在一起组成。 每一层又包括一个多头自注意力子层和一个前馈神经网络子层,每一子层都用残差连接和层归一化增强网络的稳定性,自注意力子层由点积注意力机制(Scaled Dot-Product Attention)和多头注意力机制(Multi-Head Attention) 组成。 首先, 初始化查询矩阵(Query,Q)、 键矩阵(Key,K) 和值矩阵(Value,V)。 每一组Q、K、V被称为一个头(head),可以有多组,这也是多头注意力名称的来源。 假设输入矩阵为X,则上述矩阵可由式(1)进行计算:
点积注意力机制计算见式(2):
多头注意力机制计算见式(3):
其中,headi的计算见式(4):
前馈神经网络子层由2 层全连接神经网络组成,作用是将向量再投影到一个更高维度的空间,在高维空间里可以更方便地提取需要的信息,提取信息后再还原为原来的空间,计算公式具体如下:
经过注意力机制学习后的特征向量会再通过2个全连接层,以获取情感极性。 这一步的目的是将注意力机制学习到的特征向量逐步降维,如式(6)所示:
1.3 交互注意力
模型到目前为止,方面词和上下文向量都还是相互独立的,尚未对彼此产生影响。 为了在建模上下文向量时考虑到方面词的作用,同时在建模方面词向量时引入上下文的作用,这里使用了一种交互注意力机制。 上下文向量的交互注意力catt和方面词向量的交互注意力aatt的计算分别见式(7)、式(8):
其中,、分别是上下文词向量和方面词向量经由2 个Light-Transformer 结构提取的中间向量,αi、βi是注意力权重,αi的计算公式可写为:
其中,Qaspect的计算可按式(10)来进行:
研究推得的γ(,Qaspect) 的计算公式如下:
这里,βi的计算与αi相似。
1.4 特征拼接
将经过交互注意力计算后的上下文向量和方面词向量作拼接,然后通过Softmax函数计算情感极性,拼接示意如图3 所示。

图3 特征拼接示意图Fig. 3 Schematic diagram of feature splicing
2 实验数据
模型在SemEval2014 Task4 数据集上做评估,该数据集是方面级情感分析领域最流行的数据集,其中包含Laptop 和Restaurant 两个不同类型的数据,数据集中共标注有4 种情感类型,分别是:积极(positive)、消极(negative)、中立(neutral)以及冲突(conflict),对数据集中方面项的统计见表1。

表1 方面项统计信息Tab. 1 Statistical information on aspects
由表1 可以看出,情感极性为“冲突”的样本占比很少,会导致样本失衡,因此不考虑情感极性为“冲突”的样本。 接下来对数据集进行处理,处理完毕后的部分数据集如图4 所示, 其中polarity的值为1 表示积极,为- 1 表示消极,为0 表示中立。

图4 部分Restaurant 训练集Fig. 4 Part of the Restaurant training set
3 实验与分析
3.1 实验环境
本文的实验环境见表2。

表2 实验环境Tab. 2 Experimental environment
3.2 评价指标
本文使用准确率指标对实验结果进行评估,首先给出三分类的混淆矩阵见表3。

表3 混淆矩阵Tab. 3 Confusion matrix
由表3 可以得出,准确率可由式(12)来计算求出:
其中,TOTAL为表3 中所有结果的累加。
3.3 实验结果分析
为了验证本文模型的有效性,将其在数据集上的实验结果与其他研究者提出的模型和基线模型进行比较,见表4。 本次研究中选择的对比模型详见如下。
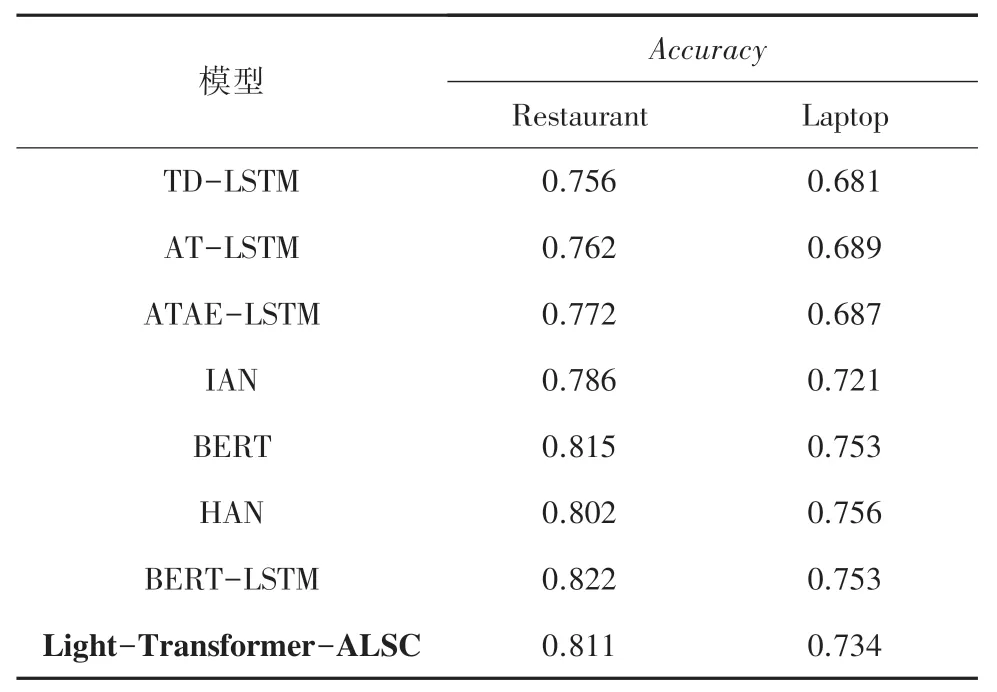
表4 模型对比Tab. 4 Comparison of the models
(1)TD-LSTM 与TC-LSTM 模型[15]:TD-LSTM对目标词的上下文分别建模,具体来说,使用2 个LSTM,一个LSTML 提取输入文本第一个词到目标词的特征信息,一个LSTMR 提取目标词到输入文本最后一个词的特征信息,将建模后的向量拼接再进行分类。 TC-LSTM 在TD-LSTM 的基础上于输入端加入了方面词的信息,具体方式为将方面词向量做平均,拼接到输入文本中。
(2)AT-LSTM 模型[16]:将方面词向量和LSTM的隐藏层做拼接,再使用注意力机制提取特征信息,将经过注意力提取的向量用作最终分类。
(3)ATAE-LSTM 模型[9]:基于LSTM 网络,将方面词向量和文本词向量及LSTM 的隐藏层向量先后做拼接,然后通过注意力机制提取拼接后的向量信息,获得输出类别。
(4)BERT-LSTM 模型[17]:探索了BERT 中间层信息的作用,使用LSTM 连接[CLS]标识符的所有中间层标识,用最后一个LSTM 单元的输出做分类。
(5)IAN 模型[18]:提出交互注意力网络,对目标词和上下文分别建模,最终得到的目标词向量和上下文向量融合了二者的交互信息,在此基础上将这2 个向量用于分类输出类别。
从表4 的对比结果可以看出,本文模型的效果优于大部分仅基于LSTM 的模型。 除基于BERT 的模型外,在Laptop 数据集上的准确率提高了1.3%~5.3%、在Restaurant 数据集上准确率提高了2.5%~5.5%;对比基于BERT 的模型,在准确率接近的情况下模型参数量大大减少,本文模型参数量约为4M(这里,1M =1 ×106),而BERT 约为110M(这里,BERT-base,12 层)。 同时,实验结果也表明了BERT 模型强大的特征提取能力,复杂模型如果能有效处理过拟合问题会具有更好的效果。
4 结束语
本文基于Self-Attention 机制搭建模型用于方面级情感分析任务,模型使用2 个不同的注意力模块对方面词和上下文分别建模,接着用建模后得到的向量计算交互注意力,再把计算后的向量拼接用作最终分类。 通过在SemEval2014 Task4 数据集上做实验并同其他研究者提出的模型进行对比,验证了本文模型的有效性。
