一种基于确定度的交互式迭代数据清洗方法
2023-10-22孙辞海王洪亚郭开彦程炜东
孙辞海, 王洪亚, 郭开彦, 程炜东
(1 东华大学计算机科学与技术学院, 上海 201620; 2 上海对外经贸大学统计与信息学院, 上海 201620)
0 引 言
检测和修复脏数据是数据分析中的挑战之一,低质量的数据将导致分析不准确和决策不可靠。 更多的数据来源和更多的数据量意味着数据质量问题的多样性和复杂性更大,以及以成本效益的方式来保持数据质量的复杂性更高。 因此,各种数据清洗方法相继被提出,以便自动地或半自动地识别错误,并在可能的情况下对其加以纠正。
在过去几年里,出现了大量基于完整性约束[1-4]、统计[5]或机器学习[6]的数据清理方法。 尽管这些方法具有适用性和通用性,但却无法确保修改数据的正确性。 为了提高这些方法的准确性,常用的方法有引入表格主数据[7]和领域专家[8-10]等。然而这些方法需要的资源是稀缺的,通常也很昂贵。为了解决这些问题,结合知识库[11]和众包的方法被提出,而知识库的构建、存储、维护以及众包的使用仍需要一定的成本。 为了结合以上方法的优点,规避其缺点,实现高效率、低成本、结果有一定保证的清洗方法,本文应用了主动学习技术,在使用机器学习的数据清洗方法基础上,部分利用用户交互,仅将最不确定的预测值交予用户检查清洗。 与其他修复方法类似,本文在清洗时遵循了保守修复原则,通过引入确定度指标,将建议修改数据和原始数据在确定程度上进行比较来决定是否修复,此方法可以避免错误修改对数据的破坏。 此外,为了提升方法的通用性,本文还在多个属性上建模,适用于多个属性上存在错误的情况。
本文主要贡献如下:
(1)运用主动学习的方法,在使用机器学习的数据清洗方法基础上,部分利用用户交互,在迭代的清洗过程中不断提升数据质量。 首先本文构建一个预测模型用于提供建议修改数据,经过筛选后将一部分交付人工检查清洗,然后将人工清洗干净的数据反馈给预测模型重新建模,提升预测能力,在不断迭代中,提升模型清洗能力,实现高效率、低成本、且清洗结果有一定保证的清洗方法。
(2)提出了基于确定度的预测模型。 此模型以概率分类器为基础(本文使用朴素贝叶斯分类器),然后在分类器上应用BvSB 准则[12],计算预测结果确定度,用以表示分类器对其预测结果的正确性的确定程度;同时模型还对原始数据应用BvSB 准则,计算原始数据确定度,用以表示原始数据对其自身的正确性的确定程度。 当预测值与原数据不同时,从两者中选择确定度大的作为模型输出。 这样,在确定度的指导下,分类器的预测结果有一定的概率保证,且对分类器建议修改加上一个限制条件,需要修改数据的确定度高于保留原始数据的确定度时才能做修改,从而减少错误的修改事件。
(3)提出了基于确定度增益的筛选规则。 上述2 种确定度越接近,是否修改的分歧也就越大,出错的概率也就越高,把这部分数据交付人工查看可避免错误的修改。 因此对2 种确定度做差,求得确定度增益,有效地反映了这种分歧。
(4)在多属性错误下构建了基于确定度的清洗模型,保证了清洗的通用性。 在各数据集上进行了大量的实验,并与相关的清洗技术进行了对比,表明了本方法的有效性。
1 研究目的和相关工作
纠正错误数据是一个耗时、耗力且十分乏味的过程。 为了提升清洗的效率,很多修复脏数据的技术采用基于约束的修复方法[13-14],通过检测数据是否满足一系列的约束(完整性约束、条件函数依赖等),以此有效地识别脏数据,然而这些方法在纠正脏数据上却有所欠缺,甚至在纠正过程中引入新的错误数据[7]。 众包和知识库的应用可以弥补修复的不确定性,提升修复的质量。
1.1 使用统计方法进行数据清洗
为了提升数据清洗的效率和正确性,出现了多种使用统计方法的技术,机器学习即是其中之一。
文献ERACER[5]提出了2 种统计的、数据驱动的方法来推断关系数据库中缺失的数据值。 一种是使用卷积或回归的新颖的近似框架;另一种是使用贝叶斯网络的基线精确方法。 在传感器网络文献[15-16]中也有一些统计的异常值检测和修复技术的例子。 文献SCARE[6]使用机器学习方法在高效清洗的同时,提高了清洗的可靠性。
SCARE 方法的创新点有:
(1)使用概率分类器技术对干净数据集的概率分布进行建模,模型被用于计算脏数据集的似然。其核心思想是要在一定的修改(修改可能错误的值)次数内最大化似然,从而达到准确修复脏数据的目的。
(2)考虑到脏数据的多个属性上可能被认为存在脏值,所以构建了多属性概率分类器解决了此问题。
然而,SCARE 在实际应用中还存在一些不足:首先,在构建概率分类器时,干净数据集要么是与脏数据集同源(例如相同表的2 个划分),要么使用现存的统计方法[17-18]得到,然而脏数据集很多时候没有同源的干净数据集,且使用统计方法得到的干净数据集不一定可靠。 其次,在定义修改次数时,SCARE 假设已知脏数据集中每一个元组出错的概率,这是不容易实现的。 缺乏人的参与也使得数据清理效果不够理想。
此外,为了进一步提升数据的可靠性,一些方法就使用主动学习技术[19-21],将需要处理的资源选择性地交付人工处理,在保证数据质量和清洗效率的同时,减少了人力资源的消耗。 主动学习的基本思想就是将部分人处理过的数据作为基础数据,训练监督模型(如SVM 和随机森林等),从众多待处理数据中选出更有价值的资源交付人工处理。 如何从众多数据中筛选出最有价值的数据是使用主动学习进行数据清洗的重点。
综合前文分析可知,本文假设初始只有一个数据质量未知的脏数据集,应用主动学习技术,加入人工参与,由人工清洗得到干净数据集,在迭代清洗中使用尽可能少的干净数据集构建高质量的清洗模型,在减少人的参与度的同时可提升数据的可靠性。
1.2 主动学习算法
主动学习[22]是机器学习的子领域,其关键思想是:若机器学习算法可以选择用于训练的数据,那么就可以在更少的训练集上实现更高的准确率。 因此,主动学习经常被用于标注问题。 主动学习通过在庞大的未被标注的数据中,挑选合适的数据交予人工标注,使用尽可能少的标注数据,训练出高准确度的模型。
一般地,主动学习的框架如图1 所示。 首先,使用少量的已标注数据集构建一个分类器。 接着,分类器从未标注数据中选取样例进行识别,若识别错误则筛选后进行人工标注。 然后,将标注的数据补充到已标注数据集中,使用此新的数据集构建新的分类器。 最后,迭代标注,直到达到设定的某个终止条件。
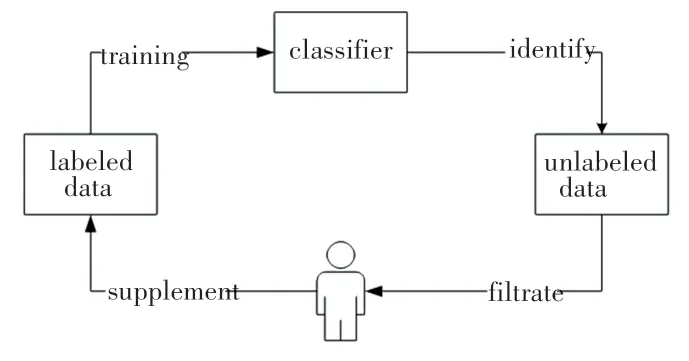
图1 主动学习框架Fig. 1 Active learning framework
与数据标注直接插入正确标记类似,数据清洗是先发现脏数据再替换为正确数据,两者都是为了得到正确值,且人工标注和人工清洗都是耗时耗力的,因此自然地想到将主动学习应用到数据清洗中,实现高效、低消耗的清洗。 在应用机器学习方法进行数据清洗时,有3 个问题:
(1) 在初始仅有一个数据质量未知的脏数据时,构建初始分类器所需的训练集难以得到。
(2) 机器学习具有一定的错误率,正确数据可能会被修改错误。
(3) 机器学习清洗的结果有时是不可解释的。主动学习可以很好地与数据清洗结合并有效地解决以上问题。 首先,主动学习有人参与,可人工清洗小部分数据用于构建初始模型。 然后,主动学习应用高价值筛选方法,可以把模型容易出错的数据筛选出来交予人工检查清洗。 最后,由人工对模型的清洗能力进行评估,可以验证模型的可靠性,对清洗质量把关。
2 问题定义
对数据集D,具有关系型模式G(表格、csv 文件等具有的模式),A表示G的属性集合。 在A中集合F={E1,…,EK} ∈A,表示脏属性集,F对应的值很可能由离散型的脏数据构成,因此可能被修改。A的补集R=A-F={W1,…,WL} 为干净属性集,R对应的值由干净数据构成。 对于A中某个属性Ei,其值域可表示为dom(Ei)。 这样,D中某个元组t可分为2 部分:干净部分t[R]=t[W1,…,WL] 和可被修改部分t[F]=t[E1,…,EK]。t[R] 和t[F] 将简写为r和f,即t=<r,f >。 另外,D在主动学习应用下,按照数据是否被人检查并清洗干净可被划分为2 部分:检查为正确的或已经纠正的干净数据Dc⊂D;未检查的或不可确认的数据De=D-Dc。 与其它清洗方法往往需要一个完整的、大量的干净数据用于寻找统计规律不同,本文的任务是在没有任何干净数据前提下,对一个干净程度未知的数据集进行清洗,即D=De。 具体地,首先从De中人工清洗少部分数据得到Dc,然后对Dc构建清洗模型,最后针对可能存在错误的元组<r,f >∈De,把r带入到模型中,尽可能预测出f可能正确的值f '。
3 基于确定度的交互式迭代清洗方法
3.1 基于主动学习的交互式迭代清洗结构
为提高清洗效率和可靠性,减少资源消耗,本文结合了机器学习和人工参与,使用主动学习方法,在迭代过程中完成数据清洗。
基于主动学习的交互式迭代清洗结构如图2 所示。 其清洗过程可描述如下:
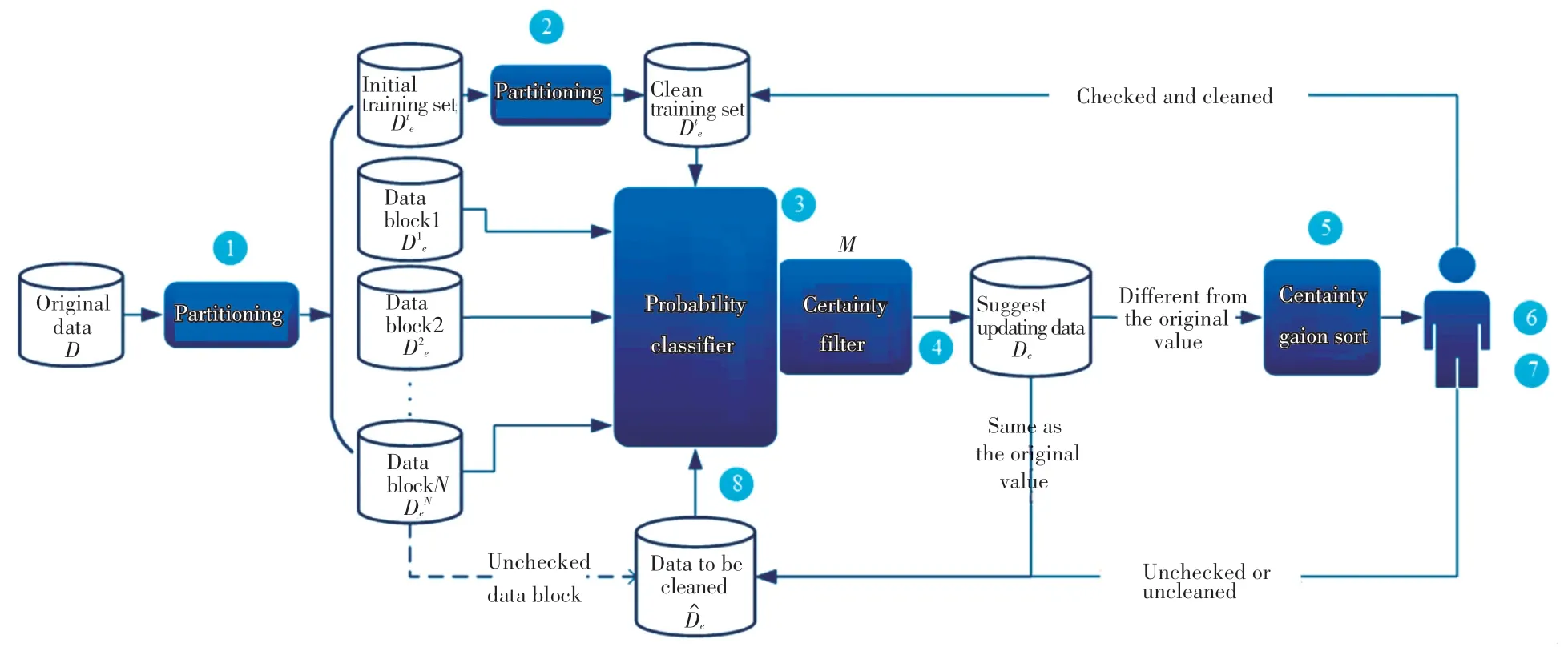
图2 基于主动学习的交互式迭代清洗结构Fig. 2 Interactive iterative cleaning structure based on active learning
(1)划分:因为使用主动学习技术的数据清洗方法是迭代清洗的,所以将初始数据集D划分成多个小块是必要的。 本文假设初始数据集D干净与否未知,也就是均为脏数据(D=De),整个数据都需要被清洗,且没有其它干净数据集作为参考,所以D会被划分为2 部分。 一部分为初始脏训练集,由人工清洗后用于构建预测模型;另一部分为若干脏数据块{,…,},都是待清洗数据,将在迭代中被清洗。
(2)预清洗:模型的构建需要干净数据集支撑,预清洗将从初始脏数据集De中得到干净训练集。因为有人工参与,将划分出的初始脏训练集交予人工进行清洗可得到一个干净训练集Dtc。 得益于主动学习技术,初始的很小,所以人工清洗工作量也很小,但同时也导致初期的模型清洗能力不强,在基于主动学习的迭代清洗中,会不断将人工清洗的数据补充到。 另外,在人工检查清洗过程中,将统计样本中每个脏属性的正确值所占比例。作为数据集D的固有特征,近似地表示某个脏属性下值正确的概率,将被用于计算原始数据的确定度(在3.2 节详细介绍)。
(3)构建确定度预测模型:确定度预测模型M由2 部分组成。 一部分为一个概率分类器,从中学习概率分布,用于计算每种结果被预测出的概率;另一部分为一个确定度筛选规则,基于BvSB 准则,计算分类器预测结果的确定度,同时使用计算原始数据的确定度,通过比较预测结果和原始数据的确定度,选出最确定的数据作为M的最终输出。由于采用了基于确定度的对比修复方法,使得数据修改的条件更严格,以此减少错误的修改操作。
(4)修改推荐:研究选择某一个数据块(i=1,2,…,N)作为M的输入,对中的每一个元组t=<r,f >,在概率分类器中可得到一个建议修改元组t'=<r,f' >。 根据确定度公式(在3.2 节详细介绍)计算t'的确定度C,同时原始元组t计算原始确定度Cinit。 当t≠t'时,选择确定度最大的值作为M的输出。 并将其插入到建议更新数据集中。当t=t'时,会将t直接插入待清洗的数据集中,考虑到前期迭代时模型的推荐能力不强,即使预测值和原始值一致,也可能是错误的,因此将这部分数据汇总,在最后一轮清洗中,使用推荐能力更好的模型进行二次清洗。
(5)增益排序:对的每一条数据t', 根据确定度增益公式(在3.2 节详细讨论)计算其确定度增益Cgain。 然后,使用确定度增益将进行升序排序,并依次交予人工查看。 当人工认为的干净程度已达到预期,会停止检查剩余数据。 确定度增益是预测值确定度和原始值确定度的差值,代表了选择2 个预选结果的分歧程度。 因此,优先推荐增益小的数据交予人工查看,可辅助调解修改分歧,并对模型清洗能力做评估,验证清洗的有效性,保证修复数据的可靠性。
(6)人工检查:人工检查并清洗过的数据会反馈给干净训练集, 这部分数据是分歧大的数据,加入到可完善数据的概率分布,因此与单纯的扩充训练集相比,基于确定度增益的数据反馈方法可以更快地提升M的清洗能力;人工未检查或检查后无法给出正确值的数据会输出到中,等待最后轮的二次清洗。 到此,一轮清洗结束,当人工对M清洗能力不满意时,将继续清洗下一个脏数据块。
(7)迭代终止:在依次检查数据块的过程中,当人工认为M建议修改的多个数据块的干净程度已达到预期,即M已经符合清洗要求,则停止迭代,并把剩余未检查的数据块汇总于中。 此时,最终轮的准备完毕,包括一个已经清洗干净的, 一个已经建模为人工满意的清洗模型M,以及一个是人工未检查或人工检查后不可修正的脏数据。
(8)最终轮清洗:把输入到高质量的模型M中,再次执行一遍整个清洗流程,直到人工对最后一批建议修改数据的干净程度表示满意,然后将人工检查清洗过的数据、人工未检查和不确定的数据、三者汇总,得到最终的清洗结果。
3.2 确定度和确定度增益
本文基于主动学习技术进行数据清洗,引入了确定度指标,用于构建预测模型。 分别在分类器预测值和原始数据上都应用了确定度,这样数据修改更加谨慎,可减少错误的修改操作。
3.2.1 2 类确定度
概率分类器可以对每种结果给出一个分类概率,以表示结果出现的可能性,然而可能性最高的2个结果概率相近时,分类器对结果的判断是不确定的,最终结果将很难保证其正确性。 在概率的基础上应用确定度,不仅对结果有一定的概率保证,还提供了评估结果正确性的依据。
分类器一般运用于二分类问题,而脏数据值域一般多于2 类,且基于熵的确定度计算方法并不适用于多类分类问题[12],因此本文选用BvSB 准则计算预测值的确定度C。 设元组t=<r,e >属于最优修改值和次优修改值的后验概率分别为P(ebest |r) 和P(esecond-best |r),其中e∈dom(Ei),选择ebest的确定度计算公式如下
在数据清洗中,因为数据的修改是有风险的,所以人们希望尽可能少地修改数据。 本文在分类器提供建议修改值时,考虑到D的错误率,给出原始数据的确定度Cinit。 在人工清洗得到初始干净训练集时,统计得到样本的脏属性对应值的干净程度。反映了t=<r,e >中的e∈dom(Ei) 正确的概率,而dom(Ei) 中其它的某个值正确的概率为根据BvSB 准则可计算原始值e的确定度Cinit。 原始数据的确定度仅与Ei的类别个数和样本的干净程度有关,所以Ei属性上所有值的原始确定度可表示为:
3.2.2 数据元组最终确定度计算
本文不仅要采纳分类器提供的建议,还要考虑是否保留原始值。 综合数据集自身的正确率、尽量少修改的原则以及分类器的预测,最终的建议修改值e'会从建议修改值ebest和原始值e中选择确定度最大的值。e'筛选公式如下:
3.2.3 确定度增益
本文还引入确定度增益指标,用于从模型建议修改数据中筛选出容易错误的数据,并将这部分数据交予人工检查。 确定度可以作为筛选数据的依据,但本文除了使用建议修改的确定度,还使用了保持原始数据不变的确定度。 因此,本文将2 种确定度作差表示确定度增益Cgain,那么更新元组为<r,e' >的确定度增益为:
由式(4)可知,确定度增益表示了数据是否修改的分歧程度,建议修改值的确定度和原始数据的确定度越相近,确定度增益越小,对数据是否修改的分歧越大。 本文通过确定度增益对建议修改数据进行排序,可以有效筛选分歧大的数据,在尽量少的人力资源消耗下,更快地提升模型清洗能力。
3.3 多属性建模和修改值预测
分类器一般是预测单属性的结果,但脏数据不会仅在一个属性上出现,因此需要在多属性上建模来清洗多属性上的错误。 本文构建了基于确定度的多属性清洗模型。 为了构建多属性模型,需要在每个属性上构建一个单属性模型,有2 种选择。 一种是直接构建干净属性集到每个脏属性集上的映射模型,可表示为Mi:R→Ei,i=1,…,K;另一种是预测Ei时,考虑到Ei可能与{E1,…,Ei-1} 存在依赖关系,输入除了干净属性集还包括已预测的脏属性集{E1,…,Ei-1},此时K个模型就可表示为Mi:{R,E1,…,Ei-1}→Ei,i=1,…,K。 本文将使用第二种建模方法,充分利用属性间依赖关系,提升清洗能力。
对于元组t=<r,f >,为了预测修改元组t'=<r,f ' >,需要构建K个模型{M1,…,MK} 分别预测K个属性上的值。 预测f '[E1] 时,直接将r带入M1即可。 预测f '[E2] 时,因为本文将原始值考虑在内,并非简单地将f '[E1] 和r作为输入。 当f '[E1]=t[E1] 时,因为预测结果和原始值相同,可直接将<r,f '[E1]>作为输入,而当f '[E1] ≠t[E1] 时,除了将<r,f '[E1]>作为输入,把f '[E1]看作正确值,还会考虑原始值t[E1] 为正确值, 将<r,t[E1]>作为输入。 对之后的属性进行预测也会考虑预测值与原始值是否相同而进行相应的处理。 因此,多属性预测的过程可描述为一个K+1层二叉树,如图3 所示。 从根节点出发,预测每一层的结果。 对于第k-1 层的某节点,其左儿子节点为建议修改值f '[Ek],右儿子节点为原始值t[Ek],若f '[Ek]=t[Ek],则仅有一个左儿子节点。
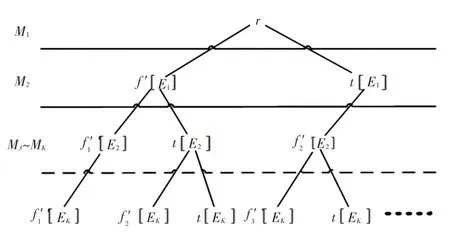
图3 多属性预测过程Fig. 3 Multi-attribute prediction process
在多属性上,每个属性上预测值的确定度将整合在一起,作为一条建议修改数据的确定度。 本文定义建议修改值f '的确定度为所有f '[Ei] 的确定度的乘积,公式如下:
原始确定度同理可得:
由图3 可知,r作为确定度模型M的输入,最多有2K种结果,然而由于很多时候建议修改值与原始值相同,实际的最终结果数会小于2K。 假设对元组t=<r,f >,有N个建议更新值在最确定优先原则下,最终预测结果为:
确定度增益计算公式为:
在多属性预测过程中,分类器预测值的确定度在2 种特殊情况下会做特殊处理。
(1)f '[Ei]=t[Ei] 时,即预测值和原始值相同时,本文遵循最确定优先的原则,选择确定度最大的作为f '[Ei] 的确定度。
(2)t[Ei] ∉Dtc时,即原始值不在干净训练集中时,分类器的结果将永远不会预测为t[Ei],因此t[Ei] 是尽可能要交予人工检查清洗的。 此时设置f '[Ei] 确定度为一个极小值,表示预测结果是极不确定的,在分类器给出的建议中,包含t[Ei] 的结果将不会被优先选择。 同时,减少原始值确定度,避免其值过高而被直接保留。
对一个元组t=<r,f >,r作为输入,多属性模型预测和确定度计算过程见算法1, 初始为getPredictions(M1,r,1.0,C I1,t=rf)。

4 实验结果与分析
本文在3 个数据集上进行了实验,主要与其他相关工作进行比较,在多个指标上多角度地验证了方法的有效性。
(1)数据集:本文使用UCI 机器学习资源库上(http://archive.ics.uci.edu/ml/)的3 个数据集。
①USCensus1990 数据集:美国1990 年人口普查的部分数据,被用于评估确定度的有效性。
②Bank 数据集:葡萄牙一家银行机构的营销数据,被用于评估确定度增益的有效性。
③Adult 数据集:美国成人收入普查数据,被用于评估不同人参与度对清洗效果的影响。 实验所用的数据信息见表1。

表1 实验数据集信息Tab. 1 The information of experimental data set
在实验中,数据会被划分为多块,其中一块(300 条数据)被清洗干净用于训练初始模型,其他数据块(100 条数据/块)在迭代中被清洗。
(2)评价指标:本文使用了以下4 个评价指标用于评估本文清洗方法。
①数据质量(Quality,简记为Q): 正确记录占所有需要清洗的记录的比例,可表示为:
其中, #recodesright是清洗后正确的记录数;#rows为数据行数; #columnserror是错误数据所在列的个数。
②参与度(Engagement,简记为E): 人工检查的记录占需要清洗的记录的比例,可表示为:
其中,#recodeschecked是被人工检查过的记录数。
③精度(Precision ,简记为P): 在所有修改过的记录中,修改正确的记录占有的比重,可表示为:
其中, #recodesupdate是被修改的记录数,#recodesupdate-right是被修改的记录中正确的记录数。
④召回率(Recall,简记为R):所有错误的记录中,被修改正确的记录占的比重,可表示为:
其中,#recodeserror是数据中所有错误的记录数。
(3)默认参数:以下是本实验会使用的参数和说明。
①初始正确率Pright≈70%: 默认保留数据质量在70%左右,即向数据插入30%左右的脏数据。其中,15%通过在干净数据加上额外后缀(如BvSB)生成脏数据,另一部分15%则用域空间的其它值替换。
②迭代终止的条件默认为: 固定迭代40 次。
③人满意度
(a)对每块数据清洗的满意度:对每一块数据,每检查#columnserror× 2 个记录,若脏记录所占比例小于0.2,即表示用户对当前数据块清洗程度表示满意,则不再检查剩余数据。
(b)对模型清洗能力的满意度:对每一块数据,用户检查记录数小于#columnserror× 6, 表示为用户对每次迭代的模型满意;当连续3 次迭代均满足上述条件,即连续3 次迭代模型效果都令用户满意,则表示用户对模型的清洗能力满意,此时则终止迭代并准备最后一轮清洗。
(4)相关技术命名:以下是本实验将要进行比较的相关技术的命名和说明。
①ADC:本文方法,使用基于确定度的分类器预测正确数据,加上使用确定度增益的数据筛选方法。
②ADC_C:ADC 仅使用基于确定度的概率分类器进行预测。
③SCARE_P:SCARE 使用概率分类器进行预测且未使用水平划分的方法,用于与ADC_C 比较以评估基于确定度的分类器进行预测的效果。
④ADC_R:ADC 未使用确定度增益排序,对分类器预测值采用随机推荐方式交予人工检查,用于与ADC 比较以评估确定度增益对清洗效果的影响。
4.1 评估确定度
为了评估基于确定度的分类器预测方法的有效性,本文使用USCensus1990 数据集进行实验,在每一次迭代中,观察分类器预测值的效果,通过比较ADC_C 和SCARE_P 在数据质量、精度、召回率上的效果,以评估应用确定度方法的有效性。 使用确定度方法和使用似然方法的效果对比如图4 所示。 由图4 可看到,ADC_C 和SCARE_ P 都能有效地提升数据质量。 在迭代清洗中,对于每一块数据的召回率,ADC_C 均远高于SCARE_ P,即ADC_C 能修复更多的脏数据。 在精度上,ADC_C 与SCARE_ P 交错分布,总体上ADC_C 是低于SCARE_ P 的,所以ADC_C 修改的错误率更高。 2 种方法在召回率和精度上各有优劣,而对于数据质量指标,ADC_C 普遍高于SCARE_ P,因为30%的错误率使得ADC_C中原数据的确定度不高,建议修改值很多,所以修改覆盖的错误数据更多,召回率更高,同时更新错误的数据也更多,精度变低。 ADC_C 与SCARE_ P 相比,虽然精度总体偏低,却相差不大,而召回率是远高于SCARE_ P 的,即ADC_C 能找到并修改正确更多的脏数据,因此ADC_C 能获得更高的数据质量。

图4 使用确定度方法和使用似然方法的效果比较Fig. 4 Comparison of the effects between using the certainty method and using the likelihood method
4.2 评估确定度增益
本节将使用Bank 数据集进行实验,从2 方面评价确定度增益筛选方法。 首先,评价确定度增益对清洗质量的影响,说明确定度增益筛选法可以有效提升数据质量。 然后,评价确定度增益对模型提升的影响,说明确定度增益筛选法可以更有效地提升模型清洗能力。
4.2.1 评估对清洗质量的影响
为了评估确定度增益对清洗质量的影响,本文模拟真实的清洗过程,使用人工满意度替换固定迭代次数作为迭代终止条件,对比ADC 与ADC_R 在相同的人满意度下清洗的质量。 表2 展示了清洗结果。
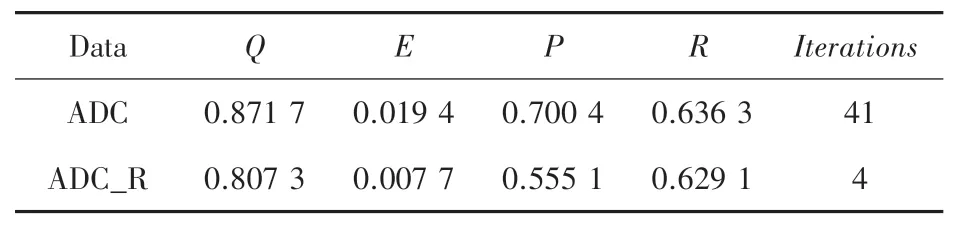
表2 基于确定度增益筛选法和随机筛选法的清洗效果对比Tab. 2 Comparison of cleaning effect between certainty gain filter method and random filter method
由表2 可知,ADC 的数据质量高于ADC_R 的数据质量,说明了在以人工为主的清洗过程中确定度增益对提升数据质量很有效。 然而,ADC 的人工参与度明显高于ADC_R,即ADC 需要更多的人力资源,这是因为确定度增益筛选法将分类器更容易出错的数据筛选出来优先交予人工检查,所以人工需要检查更多的建议修改数据才能会对当前这一轮清洗感到满意,这样清洗迭代次数也就变多。 在精度和召回率方面,召回率两种方法相近,即找出的脏数据数量都差不多,而精度上ADC 远高于ADC_R,这是因为ADC 使用的更多的人力资源把分类器容易预测错误的数据清洗了,减少了错误的修改,以此就避免了数据质量的下降。 如果比较参与度差值(0.011 7)和数据质量差值(0.064 4),可以发现人工的参与能得到更多的数据质量提升,说明确定度增益筛选法可以很好地利用人力资源,从而达到事半功倍的效果。
4.2.2 评估确定度增益对模型提升的影响
本文将一个固定1 000 行的脏数据带入每一轮清洗中,对比观察ADC 和ADC_R 在每一次迭代后分类器的清洗能力。 基于确定度增益筛选和随机筛选的模型提升对比如图5 所示。 由图5 可知,ADC和ADC_R 在数据质量、精度和召回率上均处于上升趋势,说明增加训练集的数据量可提升分类器的预测能力。 但是,ADC 的上升趋势明显高于ADC_R,这说明了确定度增益筛选法可以更快地提升分类器的预测能力,因为筛选出的数据更有益于弥补缺失的概率分布,使得分类器预测能力能得到更快提升。

图5 基于确定度增益筛选和随机筛选的模型提升对比Fig. 5 Comparison of model enhancement between certainty gain filter method and random filter method
4.3 评估不同的参与度对清洗效果的影响
为了评估不同的参与度对清洗效果的影响,本文中使用adult 数据进行实验,并以多个迭代次数(10~90 次迭代)近似表示不同的参与度。 不同参与度对清洗效果的影响如图6 所示。 由图6 可知,随着人工参与度稳步上升,数据质量也在不断提升。但是,数据质量在快速提升后逐步放缓,这是因为模型的提升达到了瓶颈。 通过计算相邻2 次迭代数据质量的差值,得到数据质量增量,参与度增量同理可得。 将2 个增量进行比较可以发现,随着人工参与度不断提升,数据质量提升收益不断降低,在接近70 次迭代时,人力资源消耗不能换回等价的数据质量提升。 实验结果表明,投入过多的人力资源并不能线性提高数据品质,这也是所有自动清洗技术的瓶颈和面临的挑战。
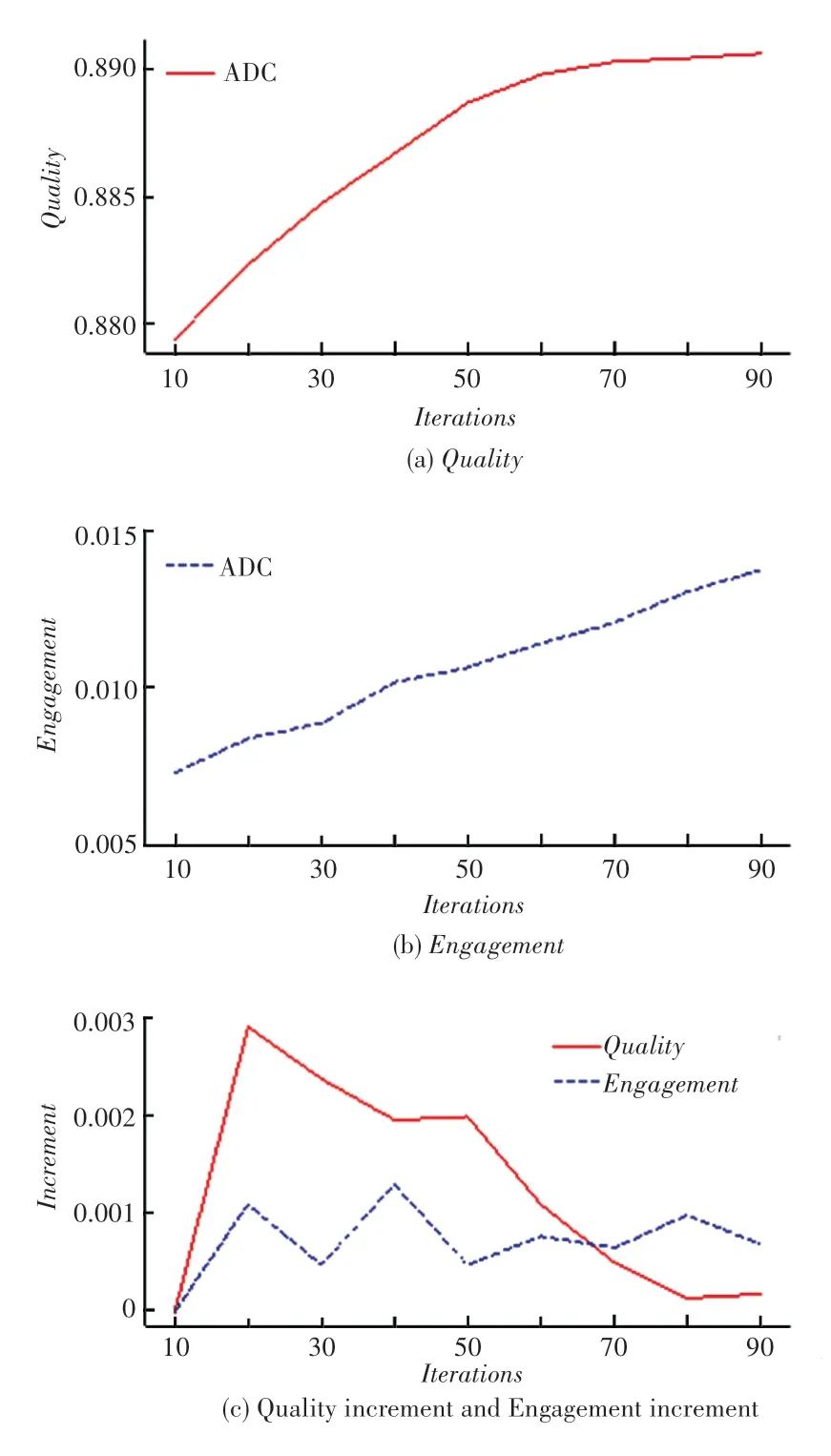
图6 不同参与度对清洗效果的影响Fig. 6 Influence of different engagement on cleaning effect
4.4 评估不同干净程度的清洗效果
本文在3 个数据集上进行实验,用以评估本文方法在数据的不同干净程度下的清洗效果。 不同干净程度的脏数据对清洗效果的影响见表3。 3 个数据集在清洗后数据质量的提升相当。 通过统计方法进行清洗具有一定的错误率,受此影响,随着脏数据干净程度的提升,清洗难度将加大,除了要清洗固有错误数据,还要避免将干净数据修改错误。 由表3可知,随着干净程度的增加,数据质量仍能提升,只是限于模型清洗能力的限制,提升的程度在不断减少。 在参与度方面,USCensus1990 明显小于其他2个数据集,这是因为USCensus1990 数据量更大,在检查相当的数据量时,USCensus1990 参与度自然变少,而数据质量提升却与其它2 个数据集相当,这说明本文对更大数据量的数据能节省更多的人力资源,并收获很好的质量提升。

表3 不同干净程度的脏数据对清洗效果的影响Tab. 3 The influence of dirty data with different degree of cleanliness on cleaning effect
5 结束语
本文运用主动学习的方法,在使用机器学习的数据清洗方法基础上,部分利用用户交互,在高效的迭代清洗过程中提升数据质量,且清洗结果也有一定的可靠性。 在基于主动学习的清洗框架上,本文提出确定度指标,构建了基于确定度的分类器,把建议修改值的确定度和原始数据的确定度进行对比,以此谨慎地对数据进行修改,减少错误修改事件的发生。 同时,本文还提出了确定度增益指标,将最有分歧的建议修改数据筛选出来交予人工检查清洗,这不仅减少了人力资源消耗,还能更快地提升模型清洗能力,且修复了分类器容易预测错误的数据。最后,本文在多个数据集上进行实验,使用多个评价指标验证了本方法的有效性。
