基于增大感受野的场景文本检测算法
2023-10-22方承志罗佳辉
杨 豪, 方承志, 罗佳辉, 雷 蕾
(南京邮电大学电子与光学工程学院、 柔性电子(未来技术)学院, 南京 210023)
0 引 言
文字作为传递信息的主要途径,被广泛地运用在自然场景中。 快速、准确地提取自然场景中的文字是一个不小的挑战,这对后续的文本翻译、场景理解起着至关重要的作用。 随着深度神经网络的兴起,自然场景文本检测已然吸引了学界关注,并陆续进行了相关研究。 文本检测已经成为未来发展的一个热点方向。
现阶段自然场景文本检测算法已经从传统的方法转向了基于深度学习的方法。 深度学习的方法的快捷之处在于:直接检测单词,没有过多的中间步骤,而且可以通过模型自行提取特征。 目前基于深度学习的方法,大致可以分成2 类。 一是基于位置回归[1]的方法;二是基于分割的方法。 其中,基于回归的方法源于一般的目标检测算法,通过改变矩形框的形状来应对文本方案。 Faster-RCNN[2]和Ma 等学者[3]设计了旋转矩形框来检测那些任意方向的文本。 但是回归的方法也存在一些缺陷,因为默认每个格子只检测一个物体,对于文本这样靠得比较近且跨度比较大的目标以及标点等小目标效果不好。 例如,Shi 等学者[4]在2017 年提出的SegLink(Detecting oriented text in natural images by linking segments)在检测跨度很大的文本行时效果不好。基于分割的文本检测方法是将文本检测转换成语义分割问题。 PixelLink[5]就是采用了分割的方法,在预测中可以得出哪些像素属于文本。 CRAFT[6]通过评定每个字符和字符之间的联系来有效地检测文本区域。 但分割的方法也存在缺陷,需要复杂的后期处理,速度较慢,且过多的后处理操作,导致在其他场景中一些参数很难被确定。 例如Li 等学者[7]在2019 年提出的PSENet(Shape robust text detection with progressive scale expansion network)需要大量的后处理去解决相邻文本实例不能准确分割的问题。
研究可知,EAST[8]算法可以有效地解决上述问题,通过结合分割和回归的方法,解决了繁琐的后处理问题,实现了端到端的文本检测,去掉了冗余和耗时的中间步骤,只包含2 个部分,全卷积神经网络[9](Fully convolutional networks,FCN)生成文本行参数部分和非极大值抑制(Non maximum suppression,NMS)部分。 但同时,EAST 中也展现出一些局限性,能够检测的最大文本实例的大小与网络的感受野成正比,从EAST 实验结果上也反映出对于一些长度是宽度的5 倍、甚至更长的文本,由于跨度较大导致效果不好,这是由于分割的方法在特征提取阶段,使用卷积和下采样的方式提取特征,多次的卷积和下采样会带来感受野过小的问题,导致EAST 算法在检测长文本时出现断裂、漏检等问题。
针对这一问题,本文基于EAST 算法,引入了Strip Pooling[10]的思想,加入了MPM(Mixed Pooling Module)[10]网络模块,采用1×N或N×1 的池化核,在垂直和水平方向对特征图进行池化,增大特征图感受野的同时,可以在捕捉文本、尤其是长文本的过程中,避免混入来自无关区域的干扰信息。 同时加入了Coordinate Attention[11]模块,通过将位置信息嵌入到通道注意力中,强化感兴趣的部分, 该模块仍然采用1×N或N×1 的池化核,使网络更准确地定位感兴趣的目标。 在训练过程中,为了解决正负样本不平衡问题,引入Dice loss[12]训练网络,且重新定义了边界框的损失函数,用CIoU loss代替了原来的IoU loss,考虑了边界框中心点的距离和宽高比,使模型可以更快、更好地训练。
1 EAST 网络结构
EAST 是一个高效且准确的场景文本检测网络,直接通过单一的神经网络预测出图像中的任意方向的四边形文本行,网络只包含FCN 阶段和NMS阶段,使得网络非常简洁、优雅,真正地实现了端到端的文本检测。 结构如图1 所示。 由图1 可知,主要包含特征提取层、特征融合层和输出层三大部分。对此拟做研究分述如下。

图1 EAST 网络结构Fig. 1 EAST network structure
(1)特征提取层。 采用PVANet 网络,对输入图片进行特征提取,从4 个卷积层抽取特征图,卷积层的尺寸依次减半,可以提取出不同尺寸的特征图,用于后面的特征融合。
(2)特征融合层。 采用U-Net 模型,对提取的最后一层特征图进行上采样,以便和上一层的特征图进行通道合并,重复操作,卷积核的个数逐层递减为128、64、32,最后到输出层。
(3)输出层。 通过1×1 的卷积输出一个1 通道的检测框置信度的分数特征图和一个5 通道的旋转矩形特征图,其中旋转矩形特征图包含1 个角度特征图和4 个边界特征图。
2 引入Strip Pooling 改进网络模型
本文引入Strip Pooling 和改进损失函数来重新定义EAST 网络,可以有效地解决因为感受野的问题而导致检测长文本时出现错误等情况。 本文的网络结构如图2 所示。
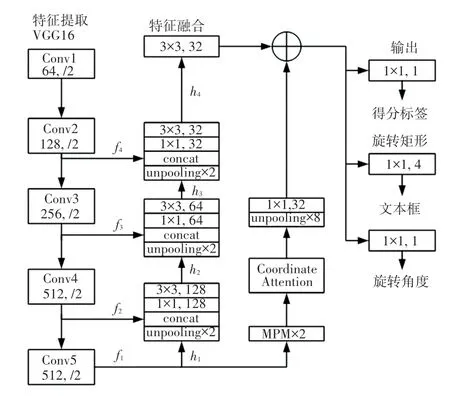
图2 改进的EAST 网络结构Fig. 2 Improved EAST network structure
2.1 感受野
在卷积神经网络中,感受野是卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小,2 层3×3 卷积的感受野演变过程如图3所示。 2016 年Luo 等学者[13]提出(Understanding the effective receptive field in deep convolutional neural networks)实际感受野要小于理论感受野。

图3 感受野演变过程Fig. 3 Receptive field evolution process
输入图片在一层一层的映射后,输出的特征图受到卷积核尺寸的制约,映射的区域大小有限,当映射区域不能完全覆盖长文本区域时,对长文本的检测就会出现检测框断裂、扭曲等问题,使得检测效果不尽人意,扩大感受野的大小是当前该类算法迫切需要解决的问题。 2019 年提出的(Feature pooling in scene character recognition: a comprehensive study)[14]中表明,池化操作可以有效地扩大感受野。
2.2 MPM 网络模块
MPM 网络模块由一个SPM(Strip Pooling Module)模块和一个PPM(Pyramid Pooling Module)[15]模块组成,可以同时捕获像素之间远程和短程的依赖关系。
空间池化已经被证明在像素级预测方面,对捕获远程上下文信息和扩大感受野非常有效。 除了常规形状的空间池化外,针对文本文字的特殊形状,引入了新的池化策略Strip Pooling,考虑了一个长而窄的核,即1×N或N× 1 的池化核,这可以有效地解决因使用方形池化核而引入一些不需要的干扰信息。
在扩大感受野的任务上,无论是卷积、还是池化,通常都会在一个方形窗口内对输入特征进行映射,这就对于去捕捉一些在现实场景中广泛存在的细长物体、例如长文本形成了限制。 引入的Strip Pooling 使用一个长核,沿着一个空间维度进行编码,从而能够有效地捕获该空间的远程依赖关系;在另一个空间维度上,使用一个窄核,便于捕获局部上下文信息,这可以有效地防止不相干区域的信息干扰标签的预测。 在检测文本行的边缘时,3×3 的方形池化核会突破文本行边缘从而引入不相关的背景像素,Strip Pooling 核在边缘上以一种窄核的形状进行池化,从而可以避免背景像素的干扰。 Strip Pooling 核的长核部分比3×3、5×5 这种方核范围长,有效地扩大了感受野,使得长的文本行也能被有效地检测。 对于离散分布在图像中的文本行,方形的池化核并不能灵活地进行特征映射,长核的存在可以捕获这些孤立区域的关系,从而有效地解决这一问题。
在Strip Pooling 的基础上,引入SPM 模块。SPM 模块如图4 所示,由2 条路径组成,可以沿着水平或垂直空间维度进行编码,然后合并2 个维度上的每个空间位置,进行特征细化。

图4 Strip Pooling Module 结构图Fig. 4 Structure diagram of the Strip Pooling Module
SPM 沿着水平或垂直维度进行池化,输入一个二维张量x∈H×W, 在Strip Pooling 中,对一列或一行中的所有特征值进行平均池化。 因此,水平条带池化后的输出yh∈H为:
同时,垂直条带池化后的输出yv∈W为:
窄边更专注于捕获局部细节,长而窄的池化核容易建立离散区域之间的远程依赖关系,这些特性不同于依赖正方形核的传统空间池化。 图4 描述了SPM 的结构,设x∈C×H×W为输入张量,将x输入到2 个平行路径中,每个路径包含一个水平或垂直的Strip Pooling 层,再经过一个核的大小为3 的一维卷积层,用于调和当前位置和局部空间的特征,就可以得到yh∈C×H和yv∈C×W,之后在各自的方向上扩展到和输入特征图一样的大小,组合yh和yv得到y∈C×H×W,有助于后续得出包含更多全局信息的输出z∈C×H×W:
然后,输出z为:
其中Scale(·,·) 是指元素级乘法;σ是Sigmoid 激活函数;f是1×1 卷积。 输出特征图中的每个像素都与其有相同水平坐标或垂直坐标的像素建立了依赖关系,避免了在彼此远离的位置之间建立过多不必要的连接。
金字塔池化模块(PPM)可以捕获短程的依赖关系,有利于扩大感受野,但受限于标准的池化核,对长文本的处理效果不好。 将PPM 和SPM 结合如图5 所示,形成了MPM 网络,可以通过各种池化操作聚合不同类型的上下信息,以便更有效地检测包括长文本在内的各种类型的文本文字。 由图5(a)可看到,对于PPM 模块采用一个轻量化的模块,避免引入大量参数,有2 个空间池化层,池化后的特征图尺寸分别为2×2 和4×4,然后是卷积层,卷积核的尺寸为3×3,用于多尺度的特征提取,还包含一个二维卷积层,用于保存原始特征图的空间信息,随后将这3 条子路径合并输出。

图5 PPM 模块和SPM 模块Fig. 5 PPM module and SPM module
MPM 是一个轻量化的模型,本文加入了2 个MPM 模块,且加入的参数量只有原始PPM 的1/3,可以发挥更好的性能。
2.3 Coordinate Attention
Hu 等学者[16]在2020 年提出的SENet(Squeezeand excitation-networks)表明,通道注意力机制对提高模型性能具有显著效果。 但忽略了位置信息,而这些位置信息对于生成空间选择性注意图非常重要,将位置信息嵌入到通道注意力中, 得到Coordinate Attention,与普通二维全局池化不同之处在于位置信息的嵌入,引入Strip Pooling,将通道注意力分解为2 个一维特征进行编码,分别沿水平或垂直的空间方向聚集特征,以便更精确地检测长文本。
Coordinate Attention 模块如图6 所示,可以捕获有助于最终分类决策的跨通道信息,还可以捕获方向感知和位置敏感的信息,有利于精确地定位长文本。

图6 Coordinate Attention 结构图Fig. 6 Coordinate Attention structure diagram
对于输入X,利用Strip Pooling 原理,得到2 个维度的输出(h) 和(w), 这是一对具有方向感知能力的特征图,可通过通道合并、将其聚合,再通过1×1卷积变换函数F1:
其中, [·,·] 表示沿通道合并;δ表示非线性激活函数;f∈C/r×(H+W)为2 个方向上编码空间信息的中间特征图,r为通道数缩减比,以降低模型的复杂度。 沿着空间维度将f分成独立的垂直和水平方向上的张量fh∈C/r×H和fw∈C/r×W,再通过1×1 卷积Fh和Fw扩展通道数,以便和输入X的通道数一致,得到:
其中,σ为sigmoid激活函数。 最后,输出Y为:
这个编码过程使得Coordinate Attention 模块可以更准确地定位长文本的位置,整个模型就能更好地识别文本。
2.4 改进损失函数
输出层由2 个部分组成,一个1 通道的分数图和一个5 通道的旋转矩形框,为了优化回归任务,替换了原有的损失函数,得到了不错的效果。
自然场景文本检测不同于一般的物体检测,文字占比少,容易被背景所干扰,导致正负样本极度不平衡,为了解决这一问题,使用Dice loss代替原文使用的类平衡交叉熵, 其表达式为:
其中,yi与分别为像素i的标签值与预测值,N为像素点的总数。Dice loss是一种用于评估2 个样本相似性的度量函数,对正负样本严重不平衡的场景有着不错的性能。
为了精确地定位矩形框,重新定义了损失的计算方式,采用CIoU loss。 相比常用的IoU loss,CIoU不仅考虑了边界框的重叠区域和中心点的距离,还考虑了宽高比,其表达式为:
其中,ρ2(·,·) 为欧几里得距离的平方;b和bgt分别为预测框和标签框的中心点坐标;c为包含预测框和标签框的最小矩形的对角线长度;IoU为原文中的交并比,其公式具体如下:
其中,Α为预测框;Β为标签框;IoU表示预测框和标签框的交集和并集的比值。υ为预测框和标签框的宽高比的距离,其公式具体如下:
其中,wgt、hgt、w、h分别为标签框和预测框的宽和高。α为权重系数,其公式具体如下:
这样设计的好处是CIoU不仅具有IoU的非负性的特点,还解决了IoU的致命缺点,当标签框和预测框的IoU为0,网络可以继续训练。 中心点距离的引入,可以使标签框覆盖预测框或预测框覆盖标签框时,loss不是一个定值,且网络更倾向于移动预测框的位置来减少loss。 宽高比的引入,使得预测框的大小更加接近标签框。 旋转角度损失采用原文的损失函数。
3 实验结果与分析
3.1 实验环境
本文的实验仿真在Linux 操作系统上进行,开发语言为Python3.8,使用带有GPU 版本的Pytorch深度学习框架。 硬件配置GPU 为RTX3090,显存为24 GB。
3.2 实验结果
本文的实验采用ICDAR2013、ICDAR2015 和MSRA-TD500 数据集,ICDAR 数据集为ICDAR 挑战赛所用的数据集。 ICDAR2015 数据集包含1 500张图片,其中1 000张图片用于训练集,其余500 张图片用于测试集。 MSRA-TD500 数据集包含500张自然场景图片。 本文将改进的模型和原模型、其他模型做比较,分别从准确率P(Precision)、召回率R(Recall)、F值三个方面评估检测模型的性能。
本文加入了2 个MPM 模块,相比加入一个MPM 模块性能提升了0.9 个百分点,见表1。 轻量化的模型优势在于不需加入太多的参数,就可以更好地发挥出模型的性能。

表1 ICDAR2015 数据集上的指标Tab. 1 Metrics on the ICDAR2015 dataset%
加入2 个MPM 模块在ICDAR2013、ICDAR2015和MSRA-TD500 数据集上对比其他检测模型的实验结果见表2~表4。 由表2 ~表4 分析可知,本文的方法相较于原方法和其他方法,都有了一定的提升,且本文的方法在ICDAR2015 数据集上F值达到了83.67 %,在MSRA-TD500 数据集上F值达到了75.17 %。

表2 ICDAR2013 数据集上的指标Tab. 2 Metrics on the ICDAR2013 dataset%

表3 ICDAR2015 数据集上的指标Tab. 3 Metrics on the ICDAR2015 dataset%
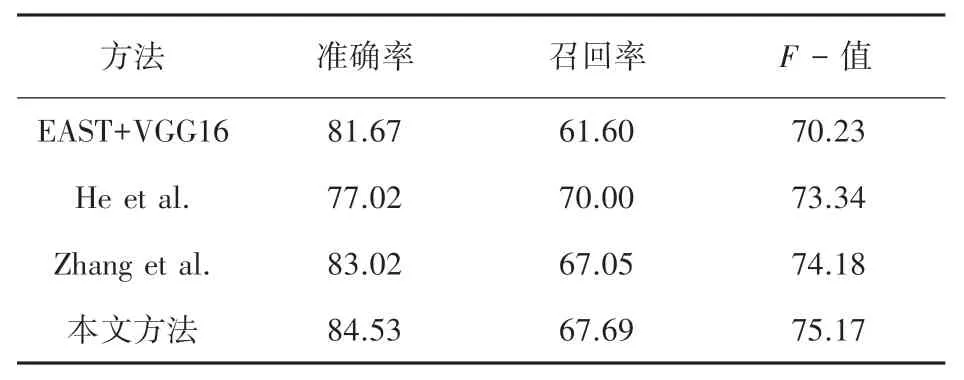
表4 MSRA-TD500 数据集上的指标Tab. 4 Metrics on the MSRA-TD500 dataset%
对比原来的EAST 算法和改进的EAST 算法的检测效果,如图7 所示。 由图7 可知,对于长文本的检测,效果有了不错的提升,改善了长文本检测时文本框断裂、扭曲等情况。

图7 原图和改进效果图Fig. 7 The original renderings and the improved effect renderings
采用本文的基于Strip Pooling 的EAST 算法比经典的EAST 算法具有更高的准确率、召回率和F值。 对比其他算法,F值也提高了一到两个百分点,检测效果得到了提升。 本文的算法在长文本的检测中展现了显著优势,对于商场标语、横幅标语、店铺名这些要求细而长的文本,改进的算法利用其优势可以快速而准确地检测出来,不会出现检测框断裂、漏检等情况;对于短小文本,改进的算法依然能够有效地检测出来,并没有损失其准确性。
4 结束语
本文基于EAST 算法,引入Strip Pooling 池化核优化模型,有效地解决了EAST 模型在检测长文本时,由于感受野过小导致文本框断裂、扭曲等情况。加入MPM 模块和Coordinate Attention 模块,利用不同尺寸的池化核、尤其是Strip Pooling 池化核,捕获远程和短程的信息,不仅扩大了感受野,还避免了一些背景信息对文本的干扰。 实验证明,该方法有效地提升了EAST 这类算法检测长文本的能力。
