基于FuseNet 的多模态融合图像分割网络
2023-10-22黄孝慈
张 涛, 黄孝慈
(上海工程技术大学机械与汽车工程学院, 上海 201620)
0 引 言
近年来,基于深度学习的图像分割方法[1-3]因其具备的精心设计框架,以及各种细分数据集的可用性已取得了很大进展。 其中,来自各种深层网络学习到的更好的特征表示对该方法的迅猛发展发挥了至关重要的核心作用。 然而,对于许多现实世界的应用、例如医疗和制造业,收集和标记数据非常耗时,需要用到专业的注释员。 这个问题的直观解决方法是在现有模型的源数据集上训练未标记目标域。 然而,由于源域和目标域中的各种数据分布而导致的域转移问题往往会阻碍该解决方法的实现。此外,方法在实现过程中没有在语言表达的指导下明确定位参考对象,只利用耗时的后处理DCRF 生成最终的细化分割。 对于开放集[4-5]图像分割任务,现已获得了广泛的应用,例如交互式图像编辑和语言引导的人机交互。 除了传统的图像分割,由于图像和语言之间的语义差异,语言相关的图像分割更具挑战性。 此外,文本表达不仅限于实体(例如,“人”、“马”),还可能包含描述性词语,如对象属性(例如“红色”、“年轻”)、动作(例如“站立”、“保持”)。
以前的研究主要集中在如何融合图像特征和语言特征。 一个简单的解决方案[6]是利用串联和卷积的方法融合视觉和语言表达,以产生最终的分割结果。 但是,由于视觉和文本信息是单独建模的,这种方法不能有效地建模图像和语言之间的对齐。 为了进一步模拟多模态特征之间的上下文,一些先前的方法[7]提出了跨模态注意,自适应地关注图像中的重要区域和语言表达中的信息关键词。 最近,Hu等学者[8]利用卷积神经网络(convolutional neural networks ,CNNs)和长-短期记忆网络(long shortterm memory, LSTM)[9]的视觉和语言特征串联来生成分割模板。 为了获得更精确的结果,文献[10]融合了多层次的视觉特征,以细化分割掩模的局部细节。
综上所述,尽管这些方法都已获得了长足的发展,但网络体系结构和实验实践却已逐步变得更加复杂。 这也导致算法的分类与比较显得更加困难。因此,针对这一现状,研究中从另一个角度考虑解决这个问题。 这里将图像分割任务分解为2 个子序列任务,分别是:词向量特征提取和精细分割掩模生成。 在本文提出的模型中,主要由以下核心部件组成:
(1)多模态融合模块。 视觉特征和语言特征分别由卷积神经网络(SegNet)和LSTM 网络提取,然后融合生成多模态特征。
(2)定位模块。 使用基于注意力机制构建的transformer 将会自适应地获取图像中的重要区域和语言表达中的信息关键词之间的相关性。
(3)Segmentation Mask 模块。 使用多采样率和有效卷积特征层,从而在多尺度上捕获对象和图像上下文,并将反卷积特征图的采样率提高,由此获得更精确的分割结果。 最后,使用交叉熵损失函数训练网络。
1 FuseNet 算法基础
1.1 语言特征提取
给定一个背景词向量X=[x1,x2,…,xm],其中xi是第i个标记。 首先应用表查找来获得单词嵌入,之后将其初始化为一个300 维的通道嵌入向量,每个通道表示一个词向量的维度,再通过GLOVE进行输入[11]。 为了模拟相邻单词之间的相互依赖关系,使用标准的LSTM 来处理初始嵌入文本向量:
其中,ht1和ht2分别表示LSTM 向前和向后获得的文本向量。 全局文本通过所有单词之间的平均池化获得,其定义如下:
1.2 视觉特征提取
给定输入图像I∈H×W×3,利用视觉主干提取多级视觉特征,即和这里,H是原始图像的高度,W是原始图像的宽度,d是特征通道的尺寸。 对于图像中的每个像素,研究假设这些像素对应于场景中的静态部分,即图像中的背景变化仅由相机运动引起。 将最终卷积层所获得的视觉特征通过MLP 反向投影成高维3D 像素点,有利于像素分类并用于后续的定位环节。 3D 像素点投影如图1 所示。
图1 3D 像素点投影Fig. 1 3D pixel projection
2 FuseNet 总体架构
整体模型架构如图2 所示,本文中模型的输入由图像I和背景词向量X组成。 为了模型的轻量化,解码器模块具有相对于编码器模块的对称结构,其中输入和输出通道的数量相反。 研究中,使用SegNet 和LSTM 分别提取I和X的特征,随后送入多模态融合模块,融合生成多模态特征。 其次,使用基于注意力机制构建的transformer 将会自适应地获取图像中的重要区域和语言表达中的信息关键词之间的相关性。 最后,使用多采样率和有效卷积特征层,有利于在多尺度上捕获对象和图像上下文,并使反卷积特征图的采样率得以提升,从而获得更精确的分割结果。

图2 整体模型架构Fig. 2 Overall model architecture
2.1 多模态融合模块
由图2 可知,研究中通过融合Fe1和Ptext获得多模态张量,公式如下:
其中,g表示ReLU激活函数;和分别是Fm1和Fe1的特征向量;We1和Wt是将视觉和词文本表示转换为相同特征维度的2 个转换矩阵。 然后,多模态张量Fm2和Fm3通过以下方式获得:
其中,μ∈[2,3],上采样的步长为2×2。 在下面的过程中,使用Fm3作为输入来生成分割掩码。以往的研究通常采用多次注意力机制来获得分割结果。 在本文中,先是根据词向量进行定位、再做分割,可以取得良好的性能,对此将展开研究论述如下。
2.2 定位模块
在多模态任务中,一个主要的挑战是建立图像和文本之间的关系模型。 近年来,注意力机制已成为功能强大的一种优秀技术,可以在图像分割中提取与语言表达相对应的视觉内容。 特征Fm3包含丰富的多模态信息,必须进一步建模以获得图像中的相关区域。 定位的目的是为了将每个像素与语言表达所涉及的全局分布的视觉区域关联起来,这些区域的反应分数高于不相关区域,用于增强全方位推理,同时防止模型过度拟合图像。 研究中将全局文本Ptext视为编码器输出,解码器遵循变压器的标准架构,使用多头注意力机制将多模态特征Fm3转换为一个粗略的分段掩码热图Mmask,因此可得:
其中,响应分数越高的区域就越有可能对应于语言表达(见图1)。
解码器需要一个序列作为输入,因此可将Fm3的空间维度压缩为一维,从而生成特征映射。 由于transformer 架构是置换不变的,就可使用固定位置编码对其进行补充,这些编码被添加到每个注意层的输入中。
2.3 Segmentation Mask 模块
给定由式(8)中生成的视觉对象,Segmentation Mask 模块的目标是生成最终的精细分割掩模。 研究中,先将原始多模态特征Fm3和视觉对象Mmask连接起来,并利用分割模块来细化粗分割结果:
其公式定义如下:
其中,Segmentation Mask 模块的主要结构以及分割过程如图3 所示。 Segmentation Mask 模块的卷积特征层使用了多采样率和全局池化的方式,以便于从多尺度上捕获对象特征和图像上下文。 请注意,为了获得更精确的分割结果,通过反卷积的方式将特征图的采样率增加了4 个因子。 这样,预测的掩码

图3 Segmentation Mask 模块Fig. 3 Segmentation Mask module
2.4 模型训练
在模型训练期间采用交叉熵损失函数,其定义如下:
其中,ge和pe分别表示下采样中的地面真相掩码和预测掩码Hmask的元素。
3 实验和结果分析
3.1 数据集
在本小节中,简要介绍用于验证本模型的数据集,即广泛使用的Cityscapes 数据集[12]。 Cityscapes由5 000 幅真实的城市交通场景图像组成,分辨率为2 048×1 024,并带有密集像素注释。 该数据集中2 975个图像用于培训,500 个图像用于验证,1 525个图像用于测试。 城市景观标注了33 个类别,其中19 个用于培训和评估。 不含地面真相的训练集用于训练模型,验证集用于评估模型。 GTA5[13]是一种合成数据集,其图像从游戏视频中收集,并通过计算机图形技术自动生成相应的语义标签。 其中,包括由9 633个像素级标签合成的图像。 在2 种不同的环境下评估了本文提出的FuseNet 图像分割框架,并按照以前的方法[14],将Cityscapes 视为目标域,GTA5 视为源域(GTA5-Cityscapes)。
3.2 实施细节
本文使用Pytork 库实现了提出的方法,并在NVIDIA 2080TI GPU 上进行了训练。 所有网络都使用了随机梯度下降(stochastic gradient descent,SGD)优化器进行训练。 初始学习速率和动量分别设置为2.5e-4和0.9,并采用幂为0.9 的多项式衰减策略来调整学习速率,接下来将最大迭代次数设置为150 000次。 输入图像的大小调整为416×416,输入句子的最大长度设置为15。 使用1 024 维的LSTM 来提取文本特征。 过滤维度设置为1 024。该解码器具有1 层网络、4 个头和1 024 个隐藏单元。 用平均交集(mIoU) 来评估本文提出方法的性能。
3.3 定量结果
首先,在GTA5-Cityscapes 中验证本文方法的有效性,相应的比较结果见表1。 表1 中,每类的最佳结果以粗体突出显示。 从表1 中可以看出,本文得到的mIoU(52.1%)获得了最佳值,这大大优于其余方法,同时比仅在源数据上训练的模型增加了15.5%,表现出了优越性能。 本文提出的方法在建筑物、墙壁、道路等类别上取得了更显著的改进。 这些物体具有刚体,并且在不同的源域中形状相似。mIoU的值越高, 也就证明了本文所提出的Segmentation Mask 模块在学习视觉和语言模态之间语义对齐方面的有效性更强。 总地来说,本文提出的分割框架优于其他大部分模型。

表1 FuseNet 在GTA5-Cityscapes 上与其他先进模型的对比结果Tab. 1 Comparison results of FuseNet with other advanced models on GTA5-Cityscapes
本文收集含有不同类别的图像进行运行时间分析,对比结果如图4 所示。 每次分析重复400 次,然后取平均值。 研究比较了4 种最先进的方法,包括Source only、CRST、MLSL、UIA 模型。 模型运行时间分析结果如图4 所示。 由图4 可知,Source only 和CRST 的推理时间大致与图像中的类数成正比,本文的方法和MLSL 模型的推理时间与图像中的类数是不变的,并且本文提出的模型比现有的方法快得多。 值得注意的是,本文的方法没有使用任何对抗性学习或任何其他复杂的技巧,这可归因于源域组合训练可以在一定程度上提高目标域的性能,源域之间的协作学习比目标域上的协作学习带来了更多的改进。

图4 模型运行时间分析Fig. 4 Analysis of model running time
图5 显示了训练过程中分割精度和损失值的变化。 2 幅图中的结果可以反映模型随着迭代次数的增加而收敛。 如果损失值在几个时期后略有增加,则该模型将被视为收敛条件。 在训练过程中经过1 500次迭代后,该框架达到了收敛条件,并在对比实验中获得了最佳结果,这也验证了表1 的结论。 在第5 阶段,5 种方法(包括FuseNet、MLSL、CRST、UIA 和Source only)的准确度分别为83.3%、78.2%、65.5%、62.9%和61.4%。 经过1 500个阶段后,本文方法取得了最好的性能并稳定增长,其损失值为-4.61,达到了收敛条件。 损失值的变化和最终结果表明,本方法在收敛速度和准确度上优于其他基线方法。

图5 训练过程中分割精度和损失值的变化Fig. 5 Change of segmentation accuracy and loss value during training
3.4 定性结果
为了直观地评估定性结果,本文提出的基于现有的MLSL 模型,对含有多类别的图像进行了图像分割,分割结果如图6 所示。 图6(a)~(c)中,从左至右分别是:Language:马路,车辆,天空,树,标志,墙壁;Language:马路,车辆,行人,树,栅栏,墙壁;Language:马路,车辆,树,天空,墙壁。 所有这些图像均来自GTA5-Cityscapes。 从这些定性结果中,可以看到本文的模型根据输入语言所指定的类别对各类型图像都能够以精确分割,所分割出来的事物类型往往是最贴近真值的。 本文的模型可以利用依赖于语言和transformer 中复杂的特征注意力模型,自适应地提取语言表现中的信息关键词,与图片中的重要区域之间的信息关联,从而得到了最匹配的特征分布,加快了推理定位对象的多模态信息融合过程,再通过更精细化的特征分割模块,最后使模型达到了更高的准确度和更好的结构化分割输出。
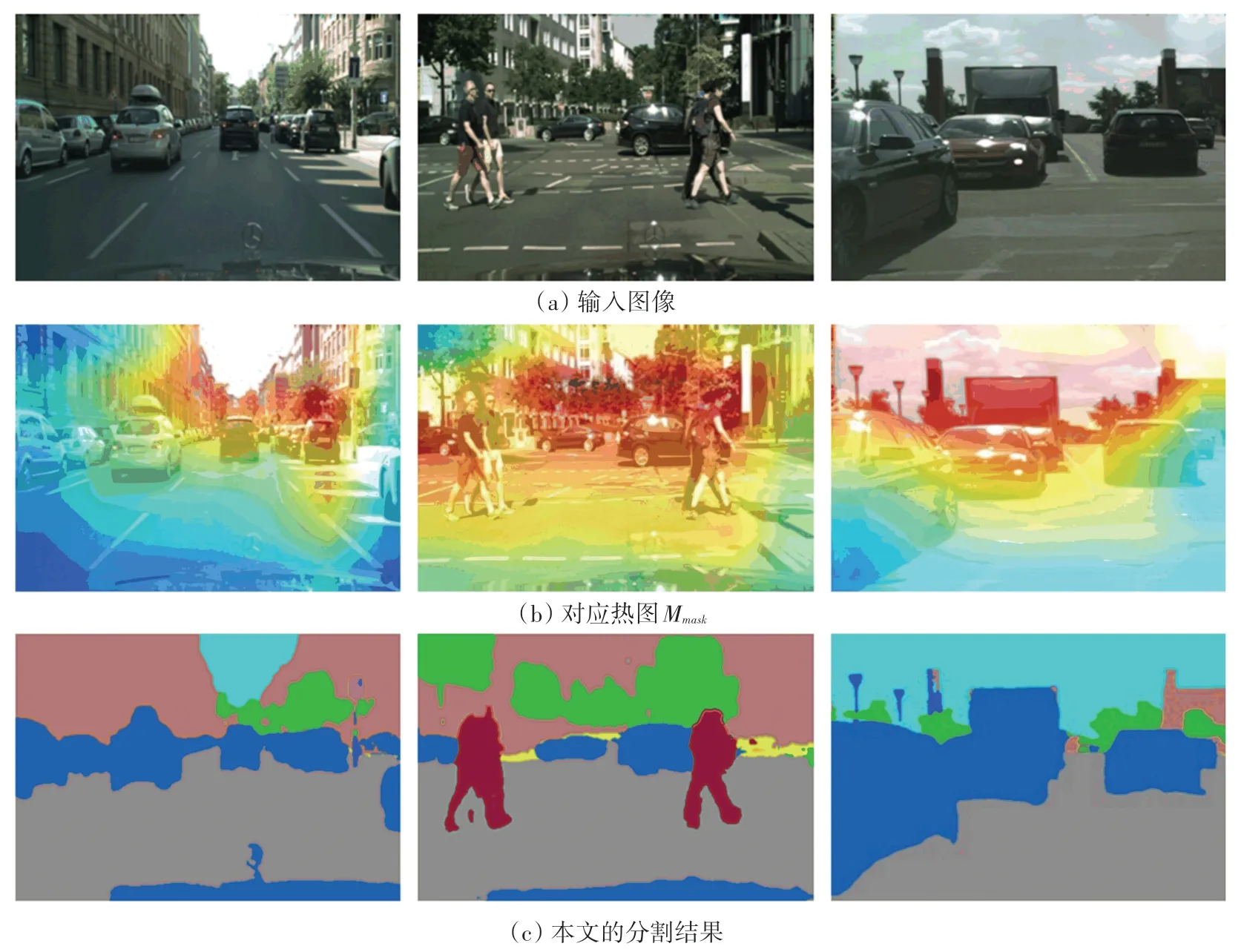
图6 GTA5-Cityscapes 上不同数量的标记目标图像上的定性结果Fig. 6 Qualitative results of different number of marker target images on GTA5-Cityscapes
4 结束语
在本文中,提出了一种新颖的用于图像分割的自适应框架(FuseNet)。 其目的是在输入图像中将语言表达的类别对应的图像进行分割。 在研究工作中,为这项任务开发了一种简单而有效的方法。 将该任务分解为2 个子序列任务:词向量特征提取和精细分割掩模生成。 首先将提取到的语言和视觉特征送入多模态融合模块,融合生成多模态特征。 其次,使用基于注意力机制构建的transformer 将会自适应地获取图像中的重要区域和语言表达中的信息关键词之间的相关性,用于捕获和传输像素级的语义信息。 最后,使用多采样率和有效卷积特征层,从而在多尺度上捕获对象和图像上下文,并将反卷积特征图的采样率提高以获得更精确的分割结果。 通过对类别先验的显式建模,减少冗余类别的重复匹配,研究得到了比之前最好的结果更高的分割性能。从上述实验中也证实了本文方法的每个组成部分的有效性。 此外,只使用了简单的视觉和语言特征提取主干。 更复杂的网络结构有可能进一步提高性能,这将在未来的工作中加以解决。
